

V tomto článku si povieme niečo o funkčných závislostiach v databázach – čo sú, kde sa používajú a aké algoritmy existujú na ich nájdenie.
Funkčné závislosti budeme uvažovať v kontexte relačných databáz. Veľmi zhruba povedané, v takýchto databázach sú informácie uložené vo forme tabuliek. Ďalej používame približné pojmy, ktoré nie sú zameniteľné v striktnej relačnej teórii: samotnú tabuľku budeme nazývať vzťah, stĺpce - atribúty (ich množinu - schému vzťahov) a množinu hodnôt riadkov na podmnožine atribútov. - n-tica.
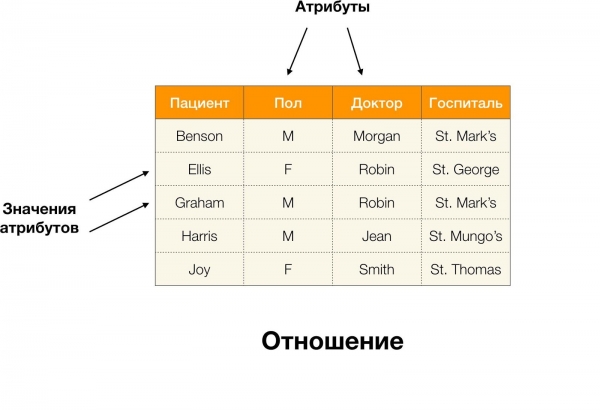
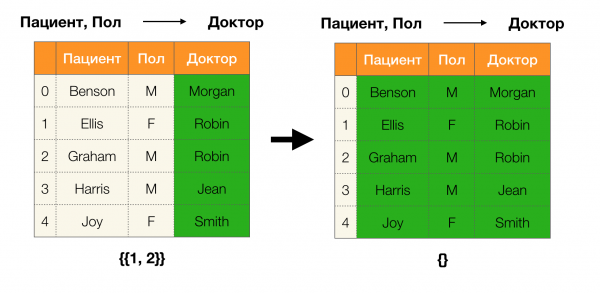
Napríklad v tabuľke vyššie (Benson, M, M organ) je množina atribútov (Pacient, Paul, Lekár).
Formálnejšie je to napísané takto:  [Pacient, pohlavie, lekár🇧🇷 (Benson, M, M organ).
[Pacient, pohlavie, lekár🇧🇷 (Benson, M, M organ).
Teraz môžeme predstaviť koncept funkčnej závislosti (FD):
Definícia 1. Vzťah R spĺňa federálny zákon X → Y (kde X, Y ⊆ R) práve vtedy, ak pre ľubovoľné n-tice  ,
,  ∈ R platí: ak
∈ R platí: ak  [X] =
[X] =  [X] teda
[X] teda  [Y] =
[Y] =  [Y]. V tomto prípade hovoríme, že X (determinant alebo definujúca množina atribútov) funkčne určuje Y (závislú množinu).
[Y]. V tomto prípade hovoríme, že X (determinant alebo definujúca množina atribútov) funkčne určuje Y (závislú množinu).
Inými slovami, prítomnosť federálneho zákona X → Y znamená, že ak máme v sebe dve n-tice R a zhodujú sa v atribútoch X, potom sa budú zhodovať v atribútoch Y.
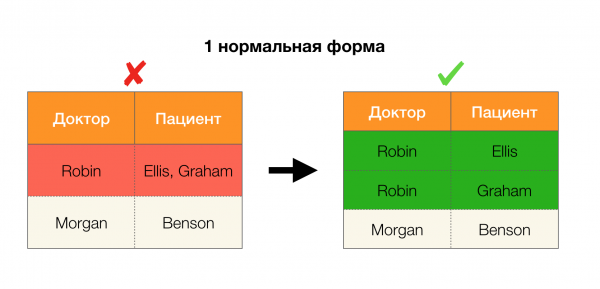
A teraz po poriadku. Pozrime sa na atribúty trpezlivý и Paul u ktorých chceme zistiť, či medzi nimi existujú závislosti alebo nie. Pre takýto súbor atribútov môžu existovať nasledujúce závislosti:
- Pacient → Pohlavie
- Pohlavie → Pacient
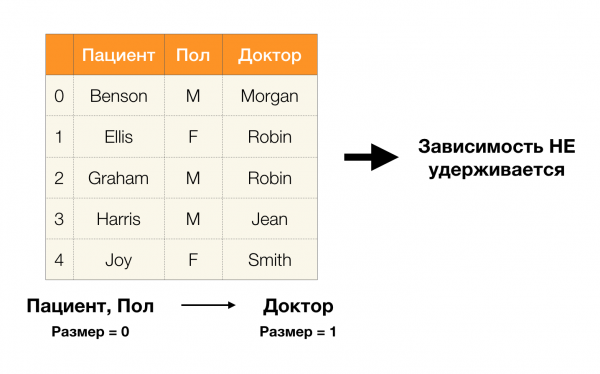
Ako je definované vyššie, aby sa zachovala prvá závislosť, každá jedinečná hodnota stĺpca trpezlivý musí sa zhodovať iba jedna hodnota stĺpca Paul. A pre príklad tabuľky je to skutočne tak. To však nefunguje v opačnom smere, to znamená, že druhá závislosť nie je splnená a atribút Paul nie je určujúcim faktorom pre Pacient. Podobne, ak vezmeme závislosť Lekár → Pacient, môžete vidieť, že je porušená, pretože hodnota červienka tento atribút má niekoľko rôznych významov - Ellis a Graham.
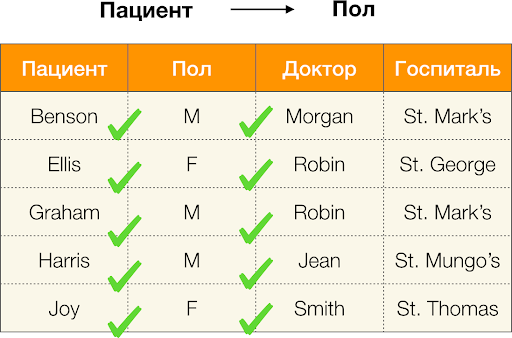
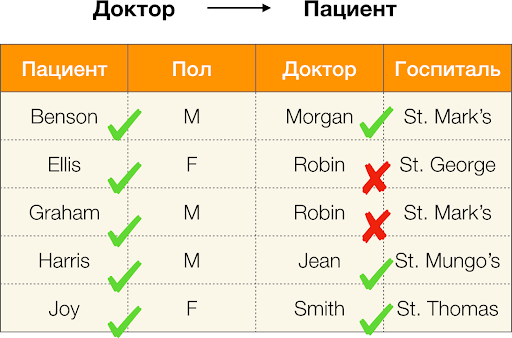
Funkčné závislosti teda umožňujú určiť existujúce vzťahy medzi súbormi atribútov tabuľky. Odtiaľ budeme uvažovať o najzaujímavejších súvislostiach, alebo skôr také X → Yčo oni sú:
- netriviálne, to znamená, že pravá strana závislosti nie je podmnožinou ľavej (Y ̸⊆ X);
- minimálna, to znamená, že takáto závislosť neexistuje Z → YŽe Z ⊂ X.
Závislosti zvažované až do tohto bodu boli prísne, to znamená, že nezabezpečili žiadne porušenia na stole, ale okrem nich existujú aj také, ktoré umožňujú určitú nekonzistenciu medzi hodnotami n-tic. Takéto závislosti sú umiestnené v samostatnej triede, ktorá sa nazýva približná, a je dovolené ich narušiť pre určitý počet n-tic. Toto množstvo je regulované indikátorom maximálnej chyby emax. Napríklad chybovosť  = 0.01 môže znamenať, že závislosť môže byť porušená o 1 % dostupných n-tic na uvažovanom súbore atribútov. To znamená, že na 1000 záznamov môže federálny zákon porušiť maximálne 10 n-tic. Budeme uvažovať o mierne odlišnej metrike založenej na párovo odlišných hodnotách porovnávaných n-tic. Pre závislosť X → Y na postoji r uvažuje sa to takto:
= 0.01 môže znamenať, že závislosť môže byť porušená o 1 % dostupných n-tic na uvažovanom súbore atribútov. To znamená, že na 1000 záznamov môže federálny zákon porušiť maximálne 10 n-tic. Budeme uvažovať o mierne odlišnej metrike založenej na párovo odlišných hodnotách porovnávaných n-tic. Pre závislosť X → Y na postoji r uvažuje sa to takto:

Vypočítajme chybu pre Lekár → Pacient z vyššie uvedeného príkladu. Máme dve n-tice, ktorých hodnoty sa v atribúte líšia trpezlivý, ale zhodujú sa ďalej Doktor:  [Doktor, pacient] = (Robin, Ellis) A
[Doktor, pacient] = (Robin, Ellis) A  [Doktor, pacient] = (Robin, Graham). Po definovaní chyby musíme vziať do úvahy všetky konfliktné páry, čo znamená, že budú dva: (
[Doktor, pacient] = (Robin, Graham). Po definovaní chyby musíme vziať do úvahy všetky konfliktné páry, čo znamená, že budú dva: ( ,
,  ) a jeho inverzný (
) a jeho inverzný ( ,
,  ). Dosadíme to do vzorca a získame:
). Dosadíme to do vzorca a získame:

Teraz sa pokúsme odpovedať na otázku: "Prečo je to všetko?" V skutočnosti sú federálne zákony odlišné. Prvým typom sú tie závislosti, ktoré určuje administrátor vo fáze návrhu databázy. Zvyčajne je ich málo, sú prísne a hlavnou aplikáciou je normalizácia údajov a návrh relačných schém.
Druhým typom sú závislosti, ktoré predstavujú „skryté“ dáta a predtým neznáme vzťahy medzi atribútmi. To znamená, že na takéto závislosti sa v čase návrhu nemyslelo a už sa našli pre existujúci súbor údajov, takže neskôr, na základe množstva identifikovaných federálnych zákonov, možno vyvodiť akékoľvek závery o uložených informáciách. Presne s týmito závislosťami pracujeme. Zaoberá sa nimi celá oblasť dolovania dát s rôznymi vyhľadávacími technikami a algoritmami vybudovanými na ich základe. Poďme zistiť, ako môžu byť nájdené funkčné závislosti (presné alebo približné) v akýchkoľvek údajoch užitočné.

Dnes je jednou z hlavných aplikácií závislostí čistenie dát. Zahŕňa vývoj procesov na identifikáciu „špinavých údajov“ a ich následnú opravu. Výraznými príkladmi „špinavých údajov“ sú duplikáty, chyby údajov alebo preklepy, chýbajúce hodnoty, zastarané údaje, medzery navyše a podobne.
Príklad dátovej chyby:
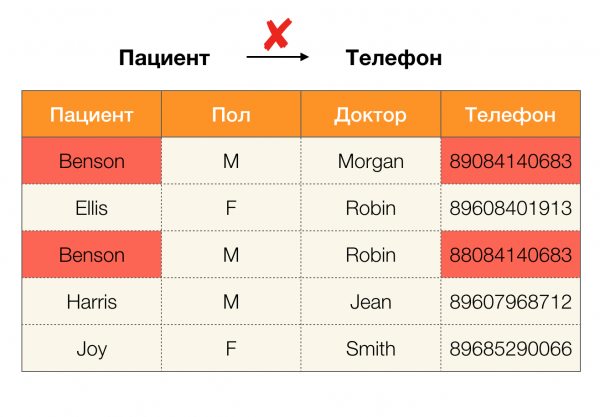
Príklad duplikátov v údajoch:
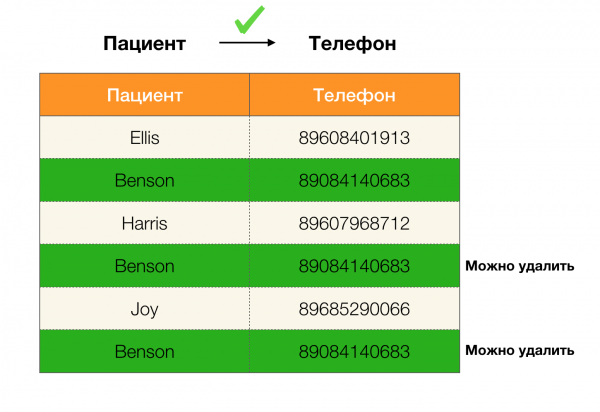
Máme napríklad tabuľku a súbor federálnych zákonov, ktoré sa musia vykonať. Čistenie údajov v tomto prípade zahŕňa zmenu údajov tak, aby boli federálne zákony správne. V tomto prípade by mal byť počet úprav minimálny (tento postup má svoje vlastné algoritmy, ktorým sa v tomto článku nebudeme venovať). Nižšie je uvedený príklad takejto transformácie údajov. Vľavo je pôvodný vzťah, v ktorom evidentne nie sú splnené potrebné FL (príklad porušenia jedného z FL je zvýraznený červenou farbou). Vpravo je aktualizovaný vzťah so zelenými bunkami zobrazujúcimi zmenené hodnoty. Po tomto postupe sa začali udržiavať potrebné závislosti.
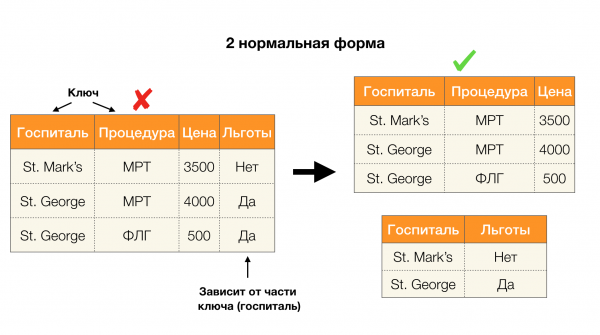
Ďalšou populárnou aplikáciou je návrh databázy. Tu stojí za to pripomenúť normálne formy a normalizáciu. Normalizácia je proces uvádzania vzťahu do súladu s určitým súborom požiadaviek, z ktorých každá je definovaná normálnou formou vlastným spôsobom. Nebudeme popisovať požiadavky rôznych normálnych foriem (to sa robí v ktorejkoľvek knihe na databázovom kurze pre začiatočníkov), ale len poznamenáme, že každá z nich používa koncept funkčných závislostí po svojom. Koniec koncov, FL sú vo svojej podstate obmedzenia integrity, ktoré sa berú do úvahy pri navrhovaní databázy (v kontexte tejto úlohy sa FL niekedy nazývajú superkľúče).
Uvažujme o ich aplikácii pre štyri normálne formy na obrázku nižšie. Pripomeňme, že normálna forma Boyce-Codda je prísnejšia ako tretia forma, ale menej prísna ako štvrtá. O tom druhom zatiaľ neuvažujeme, pretože jeho formulácia si vyžaduje pochopenie viachodnotových závislostí, ktoré nás v tomto článku nezaujímajú.
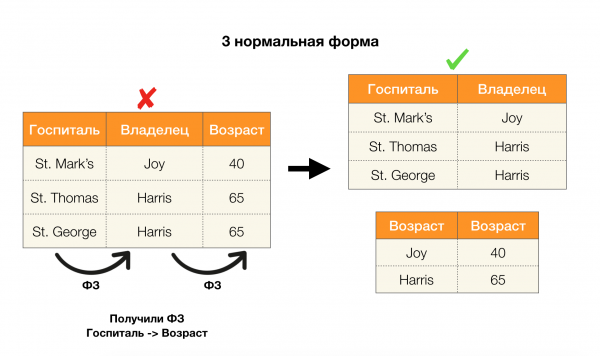
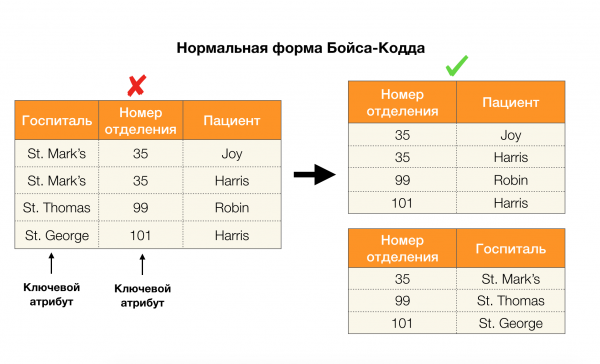
Ďalšou oblasťou, v ktorej závislosti našli svoje uplatnenie, je znižovanie dimenzionality priestoru prvkov v úlohách, ako je vytvorenie naivného Bayesovho klasifikátora, identifikácia významných prvkov a reparametrizácia regresného modelu. V pôvodných článkoch sa táto úloha nazýva stanovenie redundantnosti a relevantnosti vlastností [5, 6] a je riešená aktívnym využitím databázových konceptov. S príchodom takýchto prác môžeme povedať, že dnes je dopyt po riešeniach, ktoré nám umožňujú spojiť databázu, analytiku a implementáciu vyššie uvedených optimalizačných problémov do jedného nástroja [7, 8, 9].
Existuje mnoho algoritmov (moderných aj menej moderných) na vyhľadávanie federálnych zákonov v súbore údajov. Takéto algoritmy možno rozdeliť do troch skupín:
- Algoritmy využívajúce prechod algebraických mriežok (algoritmy prechodu mriežky)
- Algoritmy založené na hľadaní dohodnutých hodnôt (algoritmy množiny rozdielov a súhlasov)
- Algoritmy založené na párových porovnávaniach (algoritmy indukcie závislosti)
Stručný popis každého typu algoritmu je uvedený v tabuľke nižšie:
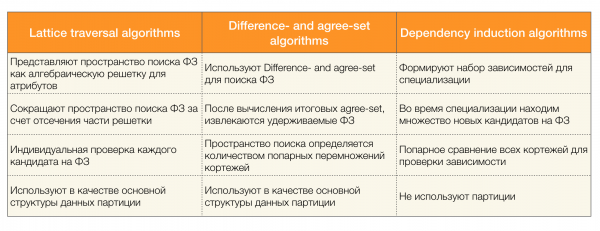
Viac o tejto klasifikácii si môžete prečítať [4]. Nižšie sú uvedené príklady algoritmov pre každý typ:
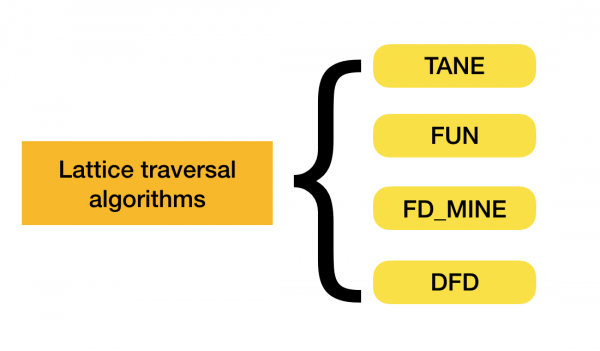
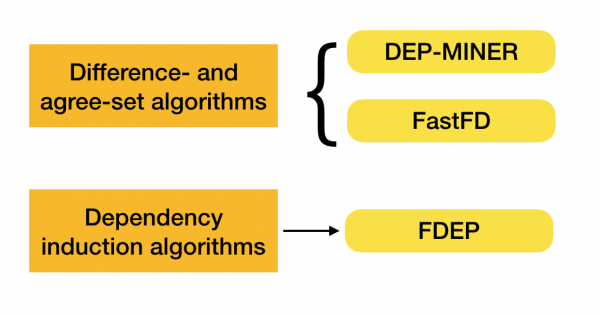
V súčasnosti sa objavujú nové algoritmy, ktoré kombinujú viacero prístupov k hľadaniu funkčných závislostí. Príklady takýchto algoritmov sú Pyro [2] a HyFD [3]. Analýza ich práce sa očakáva v nasledujúcich článkoch tejto série. V tomto článku preskúmame iba základné pojmy a lemu, ktoré sú potrebné na pochopenie techník detekcie závislostí.
Začnime s jednoduchou množinou rozdielov a súhlasov, ktoré sa používajú v druhom type algoritmov. Difference-set je množina n-tic, ktoré nemajú rovnaké hodnoty, kým zhodná množina, naopak, sú n-tice, ktoré majú rovnaké hodnoty. Stojí za zmienku, že v tomto prípade uvažujeme iba o ľavej strane závislosti.
Ďalším dôležitým konceptom, s ktorým sme sa stretli vyššie, je algebraická mriežka. Keďže mnoho moderných algoritmov pracuje na tomto koncepte, musíme mať predstavu o tom, čo to je.
Aby sme mohli zaviesť pojem mriežky, je potrebné definovať čiastočne usporiadanú množinu (alebo čiastočne usporiadanú množinu, skrátene poset).
Definícia 2. Množina S je čiastočne usporiadaná podľa binárneho vzťahu ⩽, ak sú pre všetky a, b, c ∈ S splnené nasledujúce vlastnosti:
- Reflexivita, teda a ⩽ a
- Antisymetria, teda ak a ⩽ b a b ⩽ a, potom a = b
- Tranzitivita, teda pre a ⩽ b a b ⩽ c z toho vyplýva, že a ⩽ c
Takýto vzťah sa nazýva (voľný) vzťah čiastočného poriadku a samotná množina sa nazýva čiastočne usporiadaná množina. Formálny zápis: ⟨S, ⩽⟩.
Ako najjednoduchší príklad čiastočne usporiadanej množiny môžeme vziať množinu všetkých prirodzených čísel N s obvyklým vzťahom usporiadania ⩽. Je ľahké overiť, či sú splnené všetky potrebné axiómy.
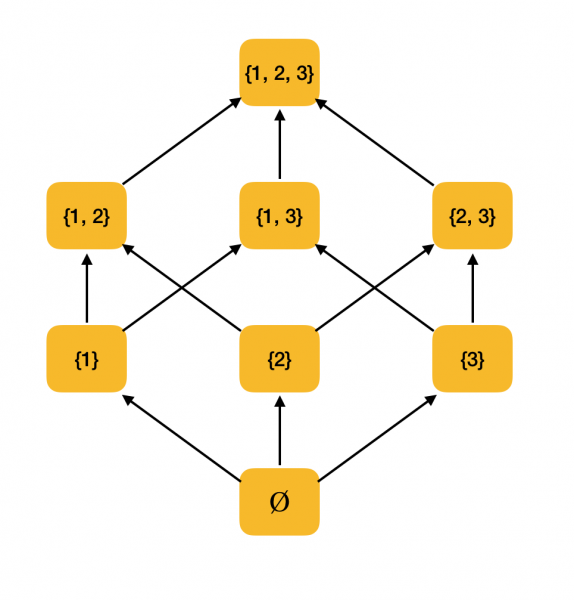
Zmysluplnejší príklad. Uvažujme množinu všetkých podmnožín {1, 2, 3} usporiadaných podľa inklúzneho vzťahu ⊆. Tento vzťah skutočne spĺňa všetky podmienky čiastkového poriadku, takže ⟨P ({1, 2, 3}), ⊆⟩ je čiastočne usporiadaná množina. Na obrázku nižšie je znázornená štruktúra tejto množiny: ak sa dá k jednému prvku dostať šípkami k inému prvku, potom sú vo vzťahu objednávky.
Budeme potrebovať ešte dve jednoduché definície z oblasti matematiky – supremum a infimum.
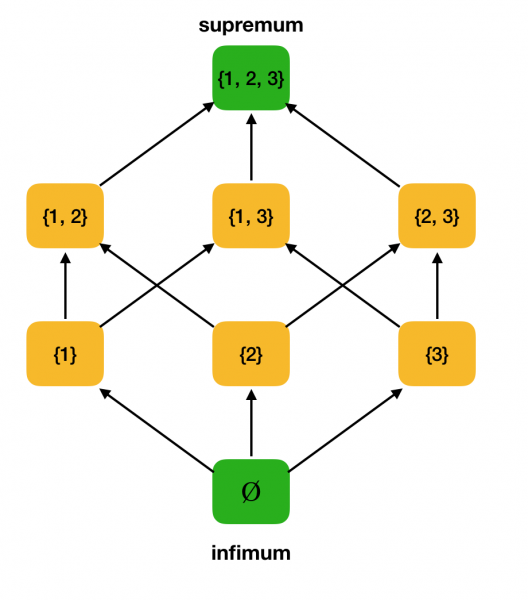
Definícia 3. Nech ⟨S, ⩽⟩ je čiastočne usporiadaná množina, A ⊆ S. Horná hranica A je prvok u ∈ S taký, že ∀x ∈ S: x ⩽ u. Nech U je množina všetkých horných hraníc S. Ak je v U najmenší prvok, potom sa nazýva supremum a označuje sa sup A.
Koncept presnej dolnej hranice sa zavádza podobne.
Definícia 4. Nech ⟨S, ⩽⟩ je čiastočne usporiadaná množina, A ⊆ S. Infimum A je prvok l ∈ S taký, že ∀x ∈ S: l ⩽ x. Nech L je množina všetkých dolných hraníc S. Ak je v L najväčší prvok, potom sa nazýva infimum a označuje sa ako inf A.
Uvažujme ako príklad vyššie čiastočne usporiadanú množinu ⟨P ({1, 2, 3}), ⊆⟩ a nájdite v nej supremum a infimum:
Teraz môžeme formulovať definíciu algebraickej mriežky.
Definícia 5. Nech ⟨P,⩽⟩ je čiastočne usporiadaná množina tak, že každá dvojprvková podmnožina má hornú a dolnú hranicu. Potom sa P nazýva algebraická mriežka. V tomto prípade sa sup{x, y} zapíše ako x ∨ y a inf {x, y} ako x ∧ y.
Overme si, že náš pracovný príklad ⟨P ({1, 2, 3}), ⊆⟩ je mriežka. V skutočnosti pre ľubovoľné a, b ∈ P ({1, 2, 3}) platí a∨b = a∪b a a∧b = a∩b. Uvažujme napríklad množiny {1, 2} a {1, 3} a nájdite ich infimum a supremum. Ak ich pretneme, dostaneme množinu {1}, ktorá bude infimum. Ich spojením získame supremum – {1, 2, 3}.
V algoritmoch na identifikáciu fyzikálnych problémov je priestor vyhľadávania často reprezentovaný vo forme mriežky, kde množiny jedného prvku (čítaj prvú úroveň mriežky vyhľadávania, kde ľavá strana závislostí pozostáva z jedného atribútu) predstavujú každý atribút. pôvodného vzťahu.
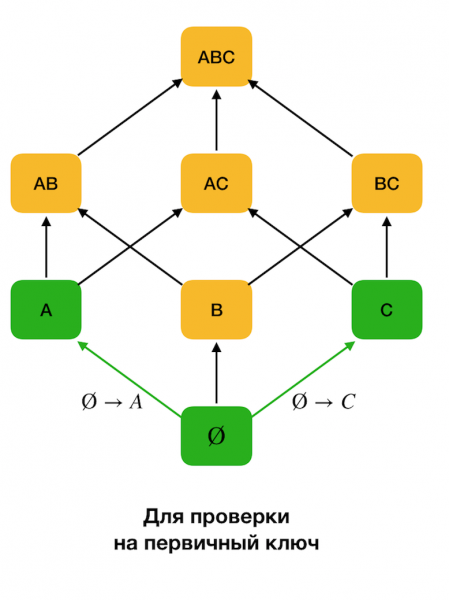
Najprv zvážime závislosti tvaru ∅ → Jediný atribút. Tento krok vám umožňuje určiť, ktoré atribúty sú primárne kľúče (pre takéto atribúty neexistujú žiadne determinanty, a preto je ľavá strana prázdna). Ďalej sa takéto algoritmy pohybujú nahor pozdĺž mriežky. Stojí za zmienku, že nie je možné prejsť celou mriežkou, to znamená, že ak sa na vstup odovzdá požadovaná maximálna veľkosť ľavej strany, algoritmus nepôjde ďalej ako na úroveň s touto veľkosťou.
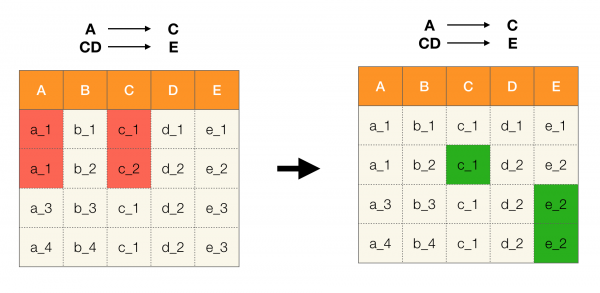
Obrázok nižšie ukazuje, ako možno použiť algebraickú mriežku v probléme nájdenia FZ. Tu každá hrana (X, XY) predstavuje závislosť X → Y. Napríklad sme prešli prvým levelom a vieme, že závislosť je udržiavaná A → B (zobrazíme to ako zelené spojenie medzi vrcholmi A и B). To znamená, že ďalej, keď sa pohybujeme nahor po mriežke, nemusíme kontrolovať závislosť A, C → B, pretože už nebude minimálny. Podobne by sme to nekontrolovali, ak by bola závislosť držaná C → B.
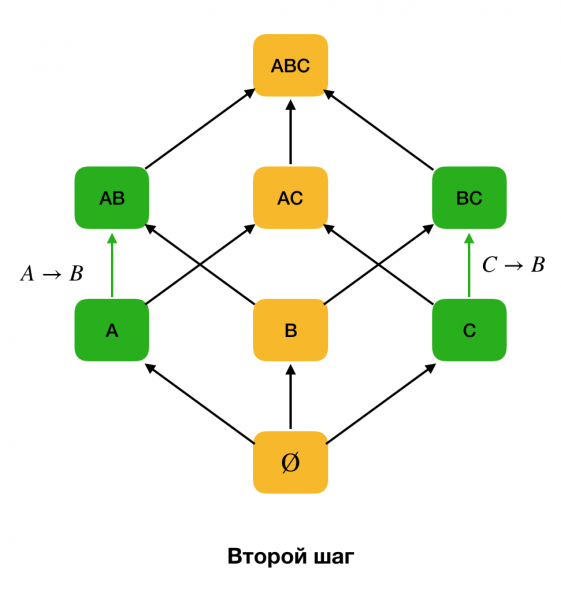
Okrem toho spravidla všetky moderné algoritmy na vyhľadávanie federálnych zákonov používajú dátovú štruktúru, akou je napríklad oddiel (v pôvodnom zdroji - zbavený oddiel [1]). Formálna definícia oddielu je nasledovná:
Definícia 6. Nech X ⊆ R je množina atribútov pre vzťah r. Klaster je množina indexov n-tic v r, ktoré majú rovnakú hodnotu pre X, teda c(t) = {i|ti[X] = t[X]}. Oddiel je množina klastrov s výnimkou klastrov s jednotkovou dĺžkou:

Jednoducho povedané, oddiel pre atribút X je množina zoznamov, kde každý zoznam obsahuje čísla riadkov s rovnakými hodnotami pre X. V modernej literatúre sa štruktúra reprezentujúca oddiely nazýva index zoznamu pozícií (PLI). Klastre jednotkovej dĺžky sú vylúčené na účely kompresie PLI, pretože sú to klastre, ktoré obsahujú iba číslo záznamu s jedinečnou hodnotou, ktorú bude vždy ľahké identifikovať.
Pozrime sa na príklad. Vráťme sa k tej istej tabuľke s pacientmi a postavme oddiely pre stĺpce trpezlivý и Paul (na ľavej strane sa objavil nový stĺpec, v ktorom sú označené čísla riadkov tabuľky):
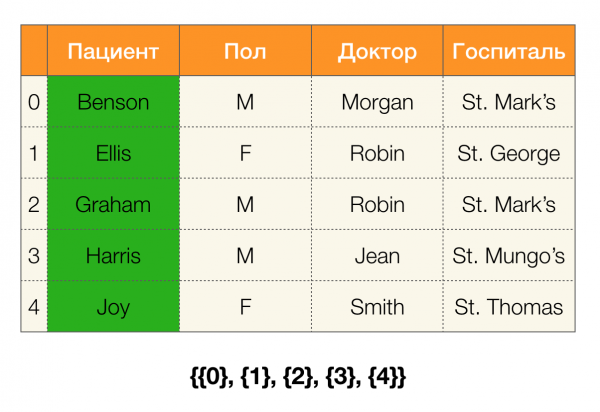
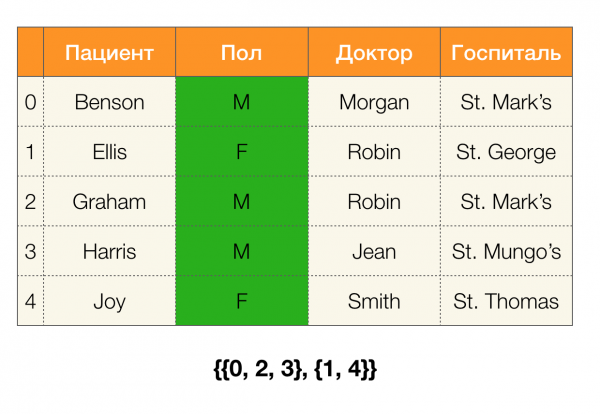
Navyše, podľa definície, oddiel pre stĺpec trpezlivý bude v skutočnosti prázdny, pretože jednotlivé klastre sú vylúčené z oddielu.
Oddiely možno získať niekoľkými atribútmi. A existujú dva spôsoby, ako to urobiť: prejdením tabuľky vytvorte oddiel pomocou všetkých potrebných atribútov naraz alebo ho vytvorte pomocou operácie prieniku oddielov pomocou podmnožiny atribútov. Algoritmy na vyhľadávanie federálnych zákonov používajú druhú možnosť.
Jednoducho povedané, napríklad získať rozdelenie podľa stĺpcov ABC, môžete si vziať oddiely pre AC и B (alebo akúkoľvek inú množinu nesúvislých podmnožín) a navzájom ich pretínajú. Operácia prieniku dvoch partícií vyberie zhluky najväčšej dĺžky, ktoré sú spoločné pre obe partície.
Pozrime sa na príklad:
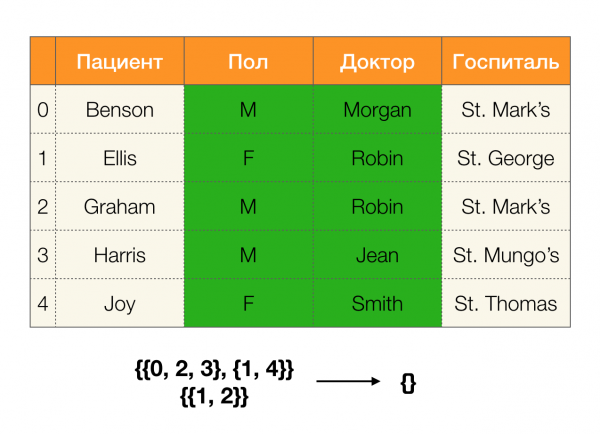

V prvom prípade sme dostali prázdnu priečku. Ak sa pozriete pozorne na tabuľku, potom skutočne neexistujú identické hodnoty pre tieto dva atribúty. Ak tabuľku mierne upravíme (prípad vpravo), dostaneme už neprázdnu križovatku. Okrem toho riadky 1 a 2 v skutočnosti obsahujú rovnaké hodnoty atribútov Paul и Lekár.
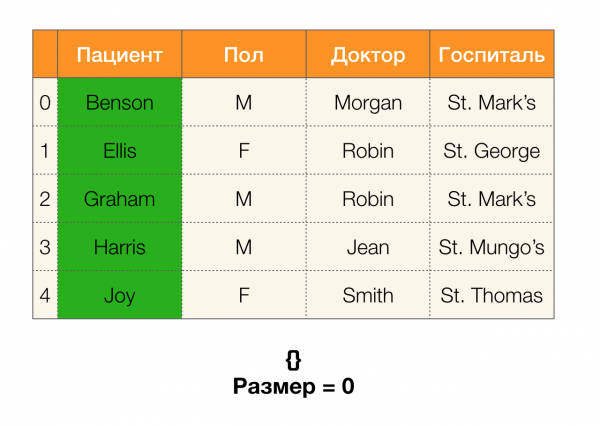
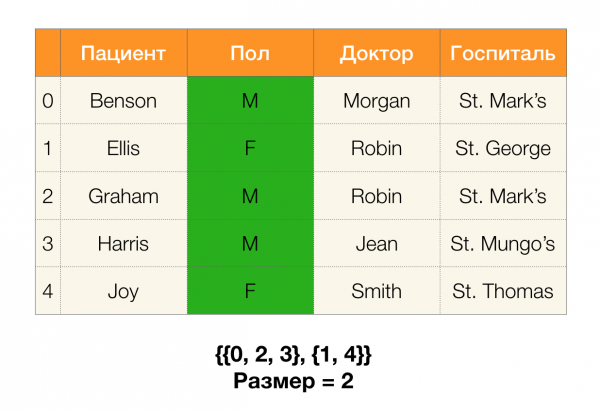
Ďalej budeme potrebovať taký koncept ako veľkosť oddielu. Formálne:

Jednoducho povedané, veľkosť oblasti je počet klastrov zahrnutých v oblasti (nezabudnite, že jednotlivé klastre nie sú zahrnuté v oblasti!):
Teraz môžeme definovať jednu z kľúčových lém, ktorá nám pre dané partície umožňuje určiť, či je závislosť držaná alebo nie:
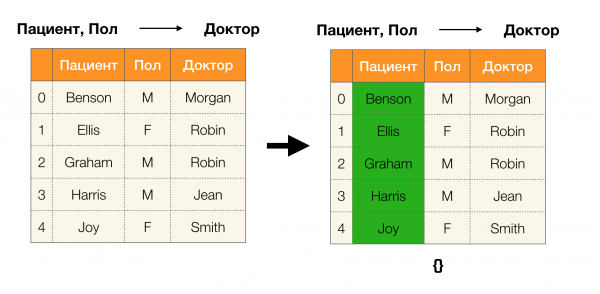
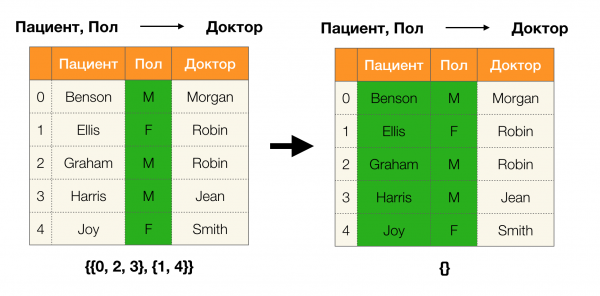
Lema 1. Závislosť A, B → C platí vtedy a len vtedy

Podľa lemy na určenie, či závislosť platí, je potrebné vykonať štyri kroky:
- Vypočítajte oddiel pre ľavú stranu závislosti
- Vypočítajte oddiel pre pravú stranu závislosti
- Vypočítajte súčin prvého a druhého kroku
- Porovnajte veľkosti oddielov získaných v prvom a treťom kroku
Nižšie je uvedený príklad kontroly, či závislosť platí podľa tejto lemy:
V tomto článku sme skúmali pojmy ako funkčná závislosť, približná funkčná závislosť, pozreli sme sa na to, kde sa používajú, ako aj na to, aké algoritmy na vyhľadávanie fyzikálnych funkcií existujú. Podrobne sme tiež preskúmali základné, ale dôležité koncepty, ktoré sa aktívne používajú v moderných algoritmoch na vyhľadávanie federálnych zákonov.
Referencie:
- Huhtala Y. a kol. TANE: Efektívny algoritmus na zisťovanie funkčných a približných závislostí //Počítačový denník. – 1999. – T. 42. – Č. 2. – s. 100-111.
- Kruse S., Naumann F. Efektívne zisťovanie približných závislostí // Proceedings of the VLDB Endowment. – 2018. – T. 11. – Č. 7. – S. 759-772.
- Papenbrock T., Naumann F. Hybridný prístup k objavovaniu funkčných závislostí //Proceedings of the 2016 International Conference on Management of Data. – ACM, 2016. – S. 821-833.
- Papenbrock T. a kol. Objav funkčnej závislosti: Experimentálne vyhodnotenie siedmich algoritmov //Proceedings of the VLDB Endowment. – 2015. – T. 8. – Č. 10. – S. 1082-1093.
- Kumar A. a kol. Pripojiť sa alebo nepripojiť?: Dvakrát si premyslite pripojenie pred výberom funkcie //Proceedings of the 2016 International Conference on Management of Data. – ACM, 2016. – S. 19-34.
- Abo Khamis M. a kol. In-databázové vzdelávanie s riedkymi tenzormi //Zborník z 37. ročníka sympózia ACM SIGMOD-SIGACT-SIGAI o princípoch databázových systémov. – ACM, 2018. – S. 325-340.
- Hellerstein JM a kol. Analytická knižnica MADlib: alebo zručnosti MAD, SQL //Proceedings of the VLDB Endowment. – 2012. – T. 5. – Č. 12. – S. 1700-1711.
- Qin C., Rusu F. Špekulatívne aproximácie pre optimalizáciu zostupu distribuovaného gradientu terascale //Proceedings of the Fourth Workshop on Data analytics in the Cloud. – ACM, 2015. – S. 1.
- Meng X. a kol. Mllib: Strojové učenie v iskre Apache //The Journal of Machine Learning Research. – 2016. – T. 17. – Č. 1. – S. 1235-1241.
Autori článku: , výskumník v , и , výskumník v
Zdroj: hab.com
