

Jean-Baptiste Lallement, direktor inženiringa pri Canonicalu, je predstavil projekt Myna, v okviru katerega razvijajo aplikacijo za prepoznavanje govora, namenjeno organiziranju glasovnega vnosa in prepoznavanju ukazov v naravnem jeziku v Ubuntu Namizje. Projekt je distribuiran pod licenco GPLv3, vendar repozitorij trenutno vsebuje le skice, ki opisujejo modularno arhitekturo projekta in njegovo integracijo z Ubuntu.
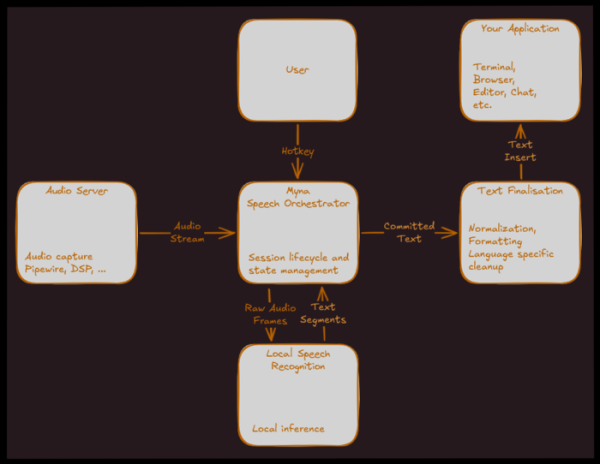
Za izdajo Ubuntu Aplikacija naj bi bila 26.10. oktobra združljiva z glasovnim vnosom. Uporabniška seja vključuje aktiviranje aplikacije s pomočjo bližnjice na tipkovnici, narekovanje na glas in lepljenje prepoznanega besedila v trenutno aplikacijo s simuliranim vnosom s tipkovnico med govorjenjem. Ko je mikrofon aktiviran, se bo na plošči prikazal poseben indikator.
Osnovno testno okolje naj bi bilo GNOME, ki temelji na Waylandu, vendar je aplikacija že od samega začetka zasnovana tako, da se jo da prilagoditi različnim namiznim okoljem.
Myna bo za prepoznavanje govora uporabljala lokalno delujoč model umetne inteligence. Zahteve za aplikacijo vključujejo: možnost delovanja brez povezave; omogočanje mikrofona šele po izrecni aktivaciji načina narekovanja z bližnjico; obdelavo zvoka v pomnilniku, ki se po vsaki uporabi izbriše; in prepoved prenosa zvočnih posnetkov v zunanje storitve.
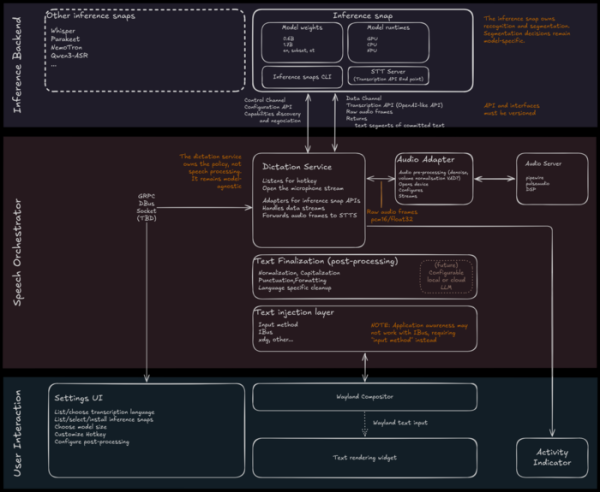
Komponente za prepoznavanje govora, interakcijo z uporabnikom, upravljanje narekovajev in nadomeščanje besedila so razvite v obliki modulov.
Izvedbeno okolje modela umetne inteligence bo zapakirano kot posnetek. Kot možni modeli prepoznavanja so omenjeni Whisper, Parakeet, NemoTron in Qwen3-ASR.
Storitev za upravljanje narekovanja spremlja pritiske bližnjic, aktivira mikrofon, dostopa do modela umetne inteligence v paketu Snap prek API-ja, posreduje zvočni tok iz zvočne storitve vanjo in usklajuje podatkovne tokove.
Zvočna storitev dostopa do zvočne naprave, bodisi neposredno bodisi prek zvočnih strežnikov PulseAudio ali PipeWire, zavira šum in izenačuje glasnost. Besedilo, ki ga ustvari model, se posreduje modulu za naknadno obdelavo za čiščenje, normalizacijo, oblikovanje in ločila. Končno besedilo se vstavi v aplikacijo prek vhodne zamenjave, na primer prek vhodnega protokola Wayland ali IBus.
Ko je začetna funkcionalnost stabilizirana, ni mogoče izključiti implementacije zmogljivosti, kot so delovanje kot glasovni asistent, izvajanje glasovnih ukazov, glasovno upravljanje namizja in prevajanje narekovanega besedila z avtomatskim prepoznavanjem jezika.
Vir: opennet.ru
