

Pozdravljeni, Habr! Pri podjetju Dodo Pizza Engineering imamo radi podatke (in kdo jih danes ne mara?). Zdaj bo zgodba o tem, kako zbrati vse podatke v svetu Dodo Pizza in vsakemu zaposlenemu v podjetju omogočiti priročen dostop do tega niza podatkov. Naloga pod zvezdico: ohraniti živce ekipe Data Engineering.
Kot pravi Plyushkins zbiramo vse vrste informacij o delu naših picerij:
- zapomni si vsa uporabniška naročila;
- vemo, koliko časa je trajala priprava prve pice v Syktyvkarju;
- zdaj vidimo, koliko časa traja, da se pica ohladi na grelni polici v Voronežu;
- Hranimo podatke o odpisih izdelkov;
- in mnogi mnogi drugi.
Za delo s podatki v Dodo Pizza je zdaj odgovornih več ekip, ena od njih je ekipa Data Engineering. Zdaj se oni (to je mi) soočajo z nalogo, da vsakemu zaposlenemu v podjetju omogočijo udoben dostop do tega niza podatkov.
Ko smo začeli razmišljati, kako bi to naredili, in začeli razpravljati o problemu, smo našli zelo zanimiv pristop k upravljanju podatkov – (sledite povezavi in našli boste ogromen, super članek). Njene ideje se zelo dobro ujemajo z našo predstavo o tem, kako želimo zgraditi naš sistem. Nadalje v članku bomo ponovno razmislili o pristopu in o tem, kako vidimo njegovo implementacijo v podjetju Dodo Pizza Engineering.
Kaj mislimo s "podatki"
Najprej opredelimo, kaj mislimo s podatki v Dodo Pizza Engineering:
- Dogodki, ki jih pošiljajo storitve (imamo skupno vodilo, zgrajeno z RabbitMQ);
- Zapisi v bazi podatkov (za nas sta to MySQL in CosmosDB);
- Clickstream iz mobilne aplikacije in spletne strani.
Da bi podjetje Dodo Pizza lahko uporabljalo in se zanašalo na te podatke, je pomembno, da so izpolnjeni naslednji pogoji:
- Biti morajo popolni. Prepričani moramo biti, da podatkov ne spreminjamo, medtem ko se obdelujejo, shranjujejo in prikazujejo. Če podjetja ne morejo zaupati našim podatkom, ne bodo koristili.
- Imeti morajo časovni žig in ne smejo biti prepisani. To pomeni, da se želimo kadar koli vrniti nazaj in si ogledati podatke iz tega časovnega obdobja. Ugotovite na primer, koliko pic je bilo prodanih 8. julija 2018.
- Biti morajo zanesljivi. V procesu zbiranja in shranjevanja podatkov ne smemo izgubiti ne le celovitosti, ampak tudi zanesljivosti. Ne moremo izgubiti podatkov, časovnih odsekov, saj z njimi izgubimo zaupanje naših strank (tako zunanjih kot notranjih).
- Biti morajo s stabilnim vezjem - za te podatke pišemo zahteve. Res ne bi radi, da bi se s spremembami v programski kodi, s preoblikovanjem tako zelo spremenilo, da bi naše poizvedbe prenehale delovati. Oseba, ki piše poizvedbe, ne bo nikoli vedela, da ste opravili preoblikovanje, dokler se vse ne pokvari. O tem ne bi rad slišal od strank.
Glede na vse te zahteve smo prišli do zaključka, da so podatki v Dodu izdelek. Enako kot javni API storitve. V skladu s tem bi morala ista ekipa, ki je lastnik storitve, imeti podatke. Prav tako morajo biti spremembe podatkovne sheme vedno združljive za nazaj.
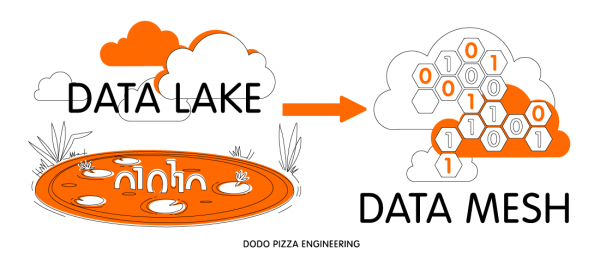
Tradicionalni pristop – Podatkovno jezero
Za reševanje problemov zanesljivega shranjevanja in obdelave velikih podatkov obstaja tradicionalen pristop, sprejet v številnih podjetjih, ki delajo s takšnim zbiranjem informacij - Data Lake. Kot del tega pristopa podatkovni inženirji zbirajo informacije iz vseh komponent sistema in jih dajo v en velik repozitorij (to je lahko na primer Hadoop, Azure Kusto, Apache Cassandra ali celo replika MySQL, če se podatki ujemajo z to).
Nato ti isti inženirji pišejo zahteve v takšno shrambo. Implementacija tega pristopa v Dodo Pizza Engineering pomeni, da bo ekipa Data Engineering imela v lasti podatkovno shemo v analitičnem skladišču.
V tem scenariju ekipa postane zelo žalostna mačka in tukaj je razlog:
- Spremljati mora spremembe VSE storitev znotraj podjetja. In veliko jih je in veliko sprememb (v povprečju združimo ~100 povlečnih zahtev na teden, medtem ko mnoge storitve sploh ne naredijo povlečnih zahtev).
- Pri spreminjanju podatkovne sheme morata lastnik izdelka in ekipa, ki spreminja podatkovno shemo, počakati, da Data Engineering doda kodo, potrebno za podporo spremembam. Hkrati pa smo že dolgo funkcijsko bogati in situacija, ko ena ekipa čaka na drugo, je zelo redka. In ne želimo, da to postane "običajen" del razvojnega procesa.
- Mora biti potopljen v CELOTNO poslovanje podjetja. Veriga picerij je videti kot preprost posel, a se le zdi tako. V eni ekipi je zelo težko zbrati dovolj kompetenc za izgradnjo ustreznega podatkovnega modela za celotno podjetje.
- To je ena sama točka napake. Vsakič, ko morate spremeniti podatke, ki jih vrne storitev, ali napisati zahtevo, so vse te naloge v rokah ekipe Data Engineering. Posledično ima ekipa preobremenjen zaostanek.
Izkazalo se je, da je ekipa na presečišču ogromnega števila potreb in jih verjetno ne bo mogla zadovoljiti. Hkrati boste pod stalnim časovnim pritiskom in stresom. Tega si res ne želimo. Zato moramo razmišljati, kako rešiti te težave in hkrati znati analizirati podatke.
Prehod iz Data Lake v Data Mesh
Na srečo pa nismo bili edini, ki smo si zastavili to vprašanje. Pravzaprav so podoben problem v industriji že rešili (aleluja!). Samo na drugem področju: uvedba aplikacij. Da, govorim o pristopu DevOps, kjer ekipa določi, kako uvesti izdelek, ki ga ustvari.
Podoben pristop k reševanju težav Data Lake je predlagal Zhamak Dehghani, svetovalec ThoughtWorks. Ko je opazovala, kako Netflix in Spotify rešujeta podobne težave, je napisala neverjeten članek (povezava do nje je bila na začetku članka). Glavne ideje, ki smo jih vzeli iz tega:
- Veliko podatkovno jezero razdelite na podatkovne domene, ki so zelo podobne domensko usmerjenim domenam načrtovanja. Vsaka domena je majhen omejen kontekst.
- Skupine funkcij, ki so odgovorne za domene DDD, so odgovorne tudi za ustrezne podatkovne domene. Shranjujejo shemo, jo spreminjajo in vanjo nalagajo podatke. Hkrati sami vedo vse: kako spremeniti nalaganje podatkov in ne pokvariti ničesar, ko se aplikacija spremeni. Znanje ne izgine. Za odpiranje podatkov jim ni treba iti nikamor. Ekipa sama vodi celoten razvojni cikel od spreminjanja operativnih podatkov do zagotavljanja analitičnih podatkov tretjim osebam. Ena ekipa ima v lasti vse, kar je povezano z domeno (tako poslovno kot podatkovno domeno).
- Podatkovni inženir – vloga v skupini za funkcije. Ni nujno, da je to posameznik, je pa nujno, da ima to kompetenco ekipa.
Medtem je ekipa Data Engineering...
Če si predstavljate, da se vse to uresniči s tleskom prstov, potem morate odgovoriti samo na dve vprašanji:
Kaj bo zdaj naredila ekipa Data Engineering? Dodo Pizza Engineering že ima ekipo za platformo/SRE. Njegov cilj je razvijalcem dati orodja za preprosto uvajanje storitev. Skupina Data Engineering bo opravljala isto vlogo samo za podatke.
Pretvarjanje operativnih podatkov v analitične podatke je kompleksen proces. Dati analitične podatke na razpolago celotnemu podjetju je še težje. S temi težavami se bo ukvarjala ekipa Data Engineering.
Skupini za funkcije bomo zagotovili priročen nabor orodij in praks, da bodo lahko podatke iz svoje storitve objavili preostalemu podjetju. Odgovorni bomo tudi za splošne infrastrukturne dele podatkovnega cevovoda (čakalne vrste, zanesljivo shranjevanje, grozdi za izvajanje transformacij podatkov).
Kako bodo veščine podatkovnega inženirja prikazane v skupini za funkcije? S funkcijo Feature Team je vse bolj zapleteno. Seveda bi lahko poskusili najeti enega podatkovnega inženirja za vsako od naših ekip. Vendar je tako težko. Težko je najti nekoga z dobrim znanjem podatkovne znanosti in ga prepričati, da dela v skupini izdelkov.
Velik plus Dodo je, da obožujemo interno usposabljanje. Zdaj je naš načrt naslednji: ekipa Data Engineering začne objavljati podatke iz nekaterih storitev, joka, si vbrizga, a še naprej jesti kaktus. Ko vemo, da imamo vzpostavljen postopek objave, ga začnemo sporočati ekipi za funkcije.
Za to imamo več načinov:
- , kjer vam bomo predstavili, kako izgleda proces, ki smo ga ustvarili, katera orodja so na voljo in kako jih najučinkoviteje uporabiti.
- Govor na DevForumu nam bo pomagal zbrati povratne informacije od razvijalcev izdelkov. Po tem se bomo lahko pridružili produktnim ekipam in jim pomagali pri reševanju težav z objavo podatkov ter organizirali izobraževanja za ekipe.
Poraba podatkov
Zdaj sem veliko govoril o objavi podatkov. Obstaja pa tudi potrošnja. Kaj pa to vprašanje?
Imamo neverjetno BI ekipo, ki piše zelo kompleksna poročila za družbo za upravljanje. Znotraj Dodo IS je veliko poročil za naše partnerje, ki jim pomagajo pri upravljanju njihovih picerij. V našem novem modelu jih obravnavamo kot porabnike podatkov, ki imajo lastne podatkovne domene. In potrošniki bodo tisti, ki bodo odgovorni za svoje domene. Včasih je mogoče domeno potrošnika opisati v eni poizvedbi v analitično skladišče - in to je dobro. Vendar se zavedamo, da to ne bo vedno delovalo. Zato želimo, da bi platformo, ki jo bomo ustvarili za produktne ekipe, lahko uporabljali tudi porabniki podatkov (navsezadnje bodo v primeru poročil znotraj Dodo IS to iste ekipe).
Tako vidimo delo s podatki v podjetju Dodo Pizza Engineering. Z veseljem bomo prebrali vaše misli o tej zadevi v komentarjih.
Vir: www.habr.com
