


Pri Badoo nenehno spremljamo nove tehnologije in ocenjujemo, ali se jih splača uporabiti v našem sistemu. Eno od teh študij bi radi delili s skupnostjo. Posvečen je Lokiju, sistemu združevanja dnevnikov.
Loki je rešitev za shranjevanje in pregledovanje dnevnikov, ta sklad pa ponuja tudi prilagodljiv sistem za njihovo analizo in pošiljanje podatkov v Prometheus. Maja je bila izdana še ena posodobitev, ki jo ustvarjalci aktivno promovirajo. Zanimalo nas je, kaj Loki zmore, kakšne zmožnosti ponuja in v kolikšni meri lahko deluje kot alternativa ELK, skladu, ki ga uporabljamo zdaj.
Kaj je Loki
Grafana Loki je sklop komponent za celoten sistem za delo s hlodovino. Za razliko od drugih podobnih sistemov Loki temelji na ideji indeksiranja samo metapodatkov dnevnika - oznak (enako kot v Prometheusu) in stiskanja samih dnevnikov v ločene dele.
,
Preden se lotimo tega, kaj lahko storite z Lokijem, želim pojasniti, kaj mislimo z "idejo indeksiranja samo metapodatkov." Primerjajmo pristop Loki in pristop k indeksiranju v tradicionalnih rešitvah, kot je Elasticsearch, na primeru vrstice iz dnevnika nginx:
172.19.0.4 - - [01/Jun/2020:12:05:03 +0000] "GET /purchase?user_id=75146478&item_id=34234 HTTP/1.1" 500 8102 "-" "Stub_Bot/3.0" "0.001"Tradicionalni sistemi razčlenijo celotno vrstico, vključno s polji z velikim številom edinstvenih vrednosti user_id in item_id, ter vse shranijo v velikih indeksih. Prednost tega pristopa je, da lahko hitro izvajate zapletene poizvedbe, saj so skoraj vsi podatki v indeksu. Toda to ima svojo ceno, saj indeks postane velik, kar pomeni zahteve po pomnilniku. Posledično je indeks dnevnika s celotnim besedilom po velikosti primerljiv s samimi dnevniki. Za hitro iskanje po njem je treba indeks naložiti v pomnilnik. In več kot je dnevnikov, hitreje raste indeks in porabi več pomnilnika.
Pristop Loki zahteva, da se iz niza izvlečejo le potrebni podatki, katerih število vrednosti je majhno. Na ta način dobimo majhen indeks in lahko iščemo podatke tako, da jih filtriramo po času in po indeksiranih poljih, nato pa preostanek pregledamo z regularnimi izrazi ali iskanjem po podnizu. Postopek se ne zdi najhitrejši, a Loki zahtevo razdeli na več delov in jih izvede vzporedno ter v kratkem času obdela veliko količino podatkov. Število drobcev in vzporednih zahtev v njih je nastavljivo; tako je količina podatkov, ki jih je mogoče obdelati na časovno enoto, linearno odvisna od količine zagotovljenih virov.
Ta kompromis med velikim, hitrim indeksom in majhnim, vzporednim indeksom brutalne sile omogoča Lokiju nadzor nad ceno sistema. Lahko ga je prilagodljivo konfigurirati in razširiti glede na potrebe.
Sklad Loki je sestavljen iz treh komponent: Promtail, Loki, Grafana. Promtail zbira dnevnike, jih obdela in pošlje Lokiju. Loki jih hrani. In Grafana lahko zahteva podatke od Lokija in jih prikaže. Na splošno lahko Loki uporabljate ne le za shranjevanje dnevnikov in iskanje po njih. Celoten sklad ponuja odlične možnosti za obdelavo in analizo vhodnih podatkov na način Prometheus.
Opis postopka namestitve najdete .
Iskanje po dnevnikih
Po dnevnikih lahko iščete v posebnem vmesniku Grafana - Raziskovalcu. Poizvedbe uporabljajo jezik LogQL, ki je zelo podoben PromQL, ki se uporablja v Prometheusu. Načeloma si ga lahko predstavljamo kot porazdeljeno grep.
Iskalni vmesnik izgleda takole:
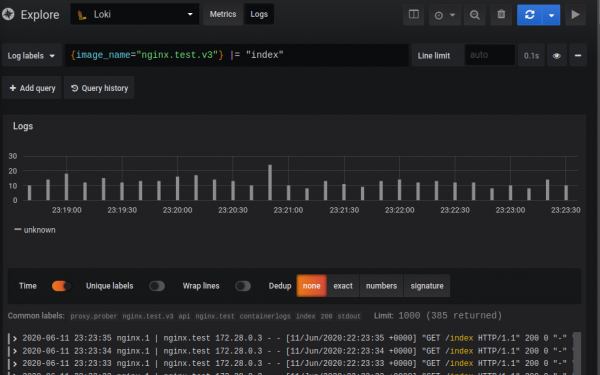
Sama zahteva je sestavljena iz dveh delov: izbirnika in filtra. Izbirnik je iskanje z uporabo indeksiranih metapodatkov (oznak), ki so dodeljeni dnevnikom, filter pa je iskalni niz ali regularni izraz, ki filtrira zapise, ki jih definira izbirnik. V navedenem primeru: V zavitih oklepajih je izbirnik, vse za njim je filter.
{image_name="nginx.promtail.test"} |= "index"Zaradi načina delovanja Lokija ne morete izvajati poizvedb brez izbirnika, vendar lahko oznake naredite tako splošne, kot želite.
Izbirnik je vrednost ključ/vrednost v zavitih oklepajih. Izbirnike lahko kombinirate in določite različne iskalne pogoje z uporabo operatorjev =, != ali regularnih izrazov:
{instance=~"kafka-[23]",name!="kafka-dev"}
// Найдёт логи с лейблом instance, имеющие значение kafka-2, kafka-3, и исключит dev Filter je besedilo ali regexp, ki izloči vse podatke, ki jih prejme izbirnik.
Možno je pridobiti ad-hoc grafe na podlagi prejetih podatkov v metričnem načinu. Na primer, lahko ugotovite, kako pogosto se vnos, ki vsebuje indeks niza, pojavi v dnevnikih nginx:
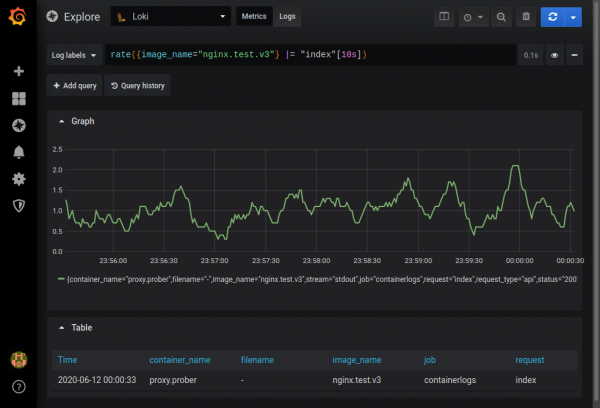
Popoln opis zmogljivosti najdete v dokumentaciji .
Razčlenjevanje dnevnika
Obstaja več načinov zbiranja dnevnikov:
- Uporaba Promtaila, standardne komponente sklada za zbiranje dnevnikov.
- Neposredno iz docker vsebnika z uporabo
- Uporabite Fluentd ali Fluent Bit, ki lahko pošilja podatke Lokiju. Za razliko od Promtaila imajo že pripravljene razčlenjevalnike za skoraj vse vrste dnevnikov in lahko obravnavajo tudi večvrstične dnevnike.
Običajno se za razčlenjevanje uporablja Promtail. Dela tri stvari:
- Poišče vire podatkov.
- Nanje prilepi etikete.
- Pošlje podatke Lokiju.
Trenutno lahko Promtail bere dnevnike iz lokalnih datotek in iz dnevnika systemd. Nameščen mora biti na vsakem stroju, s katerega se zbirajo hlodi.
Obstaja integracija s Kubernetesom: Promtail samodejno prek API-ja Kubernetes REST prepozna stanje gruče in zbira dnevnike iz vozlišča, storitve ali poda ter takoj objavi oznake na podlagi metapodatkov iz Kubernetesa (ime poda, ime datoteke itd.) .
Nalepke lahko obesite tudi na podlagi podatkov iz dnevnika s cevovodom. Promtail cevovoda je lahko sestavljen iz štirih vrst stopenj. Več podrobnosti v , takoj bom opazil nekaj odtenkov.
- Stopnje razčlenjevanja. To je stopnja RegEx in JSON. Na tej stopnji podatke iz dnevnikov ekstrahiramo v tako imenovani ekstrahirani zemljevid. Iz JSON lahko ekstrahiramo tako, da polja, ki jih potrebujemo, preprosto kopiramo v ekstrahirani zemljevid ali prek regularnih izrazov (RegEx), kjer so imenovane skupine "preslikane" v ekstrahirani zemljevid. Izvlečen zemljevid je shramba ključ-vrednost, kjer je ključ ime polja, vrednost pa njegova vrednost iz dnevnikov.
- Stopnje transformacije. Ta stopnja ima dve možnosti: transform, kjer nastavimo pravila transformacije, in izvor - izvor podatkov za transformacijo iz ekstrahirane karte. Če v ekstrahiranem zemljevidu ni takega polja, bo ustvarjeno. Na ta način je mogoče ustvariti oznake, ki ne temeljijo na ekstrahirani karti. Na tej stopnji lahko manipuliramo s podatki v ekstrahiranem zemljevidu z uporabo dokaj zmogljivega . Poleg tega ne smemo pozabiti, da se ekstrahirani zemljevid v celoti naloži med razčlenjevanjem, kar omogoča na primer preverjanje vrednosti v njem: “{{if .tag}tag value exists{end}}”. Predloga podpira pogoje, zanke in nekatere nizovne funkcije, kot sta Replace in Trim.
- Stopnje ukrepanja. Na tej točki lahko naredite nekaj z ekstrahirano vsebino:
- Iz ekstrahiranih podatkov ustvarite oznako, ki jo bo indeksiral Loki.
- Spremenite ali nastavite čas dogodka iz dnevnika.
- Spremenite podatke (besedilo dnevnika), ki bodo šli v Loki.
- Ustvarite meritve.
- Faze filtriranja. Stopnja ujemanja, kjer lahko pošljemo vnose, ki jih ne potrebujemo, v /dev/null ali jih posredujemo v nadaljnjo obdelavo.
Na primeru obdelave običajnih dnevnikov nginx bom pokazal, kako lahko razčlenite dnevnike z uporabo Promtaila.
Za preizkus vzemimo kot nginx-proxy spremenjeno sliko nginx jwilder/nginx-proxy:alpine in majhen demon, ki se lahko vpraša prek HTTP-ja. Demon ima več končnih točk, na katere lahko zagotovi odgovore različnih velikosti, z različnimi statusi HTTP in z različnimi zamiki.
Zbirali bomo dnevnike iz docker kontejnerjev, ki jih lahko najdete na poti /var/lib/docker/containers/ / -json.log
V docker-compose.yml konfiguriramo Promtail in podamo pot do konfiguracije:
promtail:
image: grafana/promtail:1.4.1
// ...
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- promtail-data:/var/lib/promtail/positions
- ${PWD}/promtail/docker.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
// ...
Dodajte pot do dnevnikov v promtail.yml (v konfiguraciji je možnost "docker", ki naredi isto v eni vrstici, vendar ne bi bilo tako jasno):
scrape_configs:
- job_name: containers
static_configs:
labels:
job: containerlogs
__path__: /var/lib/docker/containers/*/*log # for linux onlyKo je ta konfiguracija omogočena, bodo dnevniki iz vseh vsebnikov poslani v Loki. Da bi se temu izognili, spremenimo nastavitve testnega nginxa v docker-compose.yml - dodamo polje oznake za beleženje:
proxy:
image: nginx.test.v3
//…
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}"Urejanje promtail.yml in nastavitev Pipeline. Vnos vključuje dnevnike naslednje vrste:
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /api/index HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.096"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.66740443Z"}
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /200 HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.000"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.702925272Z"}Stopnja cevovoda:
- json:
expressions:
stream: stream
attrs: attrs
tag: attrs.tagEkstrahiramo polja stream, attrs, attrs.tag (če obstajajo) iz dohodnega JSON-a in jih postavimo v ekstrahirani zemljevid.
- regex:
expression: ^(?P<image_name>([^|]+))|(?P<container_name>([^|]+))$
source: "tag"Če nam je uspelo v ekstrahirani zemljevid vstaviti polje oznake, potem z uporabo regexp ekstrahiramo imena slike in vsebnika.
- labels:
image_name:
container_name:Dodeljujemo oznake. Če sta ključa image_name in container_name najdena v ekstrahiranih podatkih, bosta njuni vrednosti dodeljeni ustreznim oznakam.
- match:
selector: '{job="docker",container_name="",image_name=""}'
action: dropZavržemo vse dnevnike, ki nimajo nameščenih oznak image_name in container_name.
- match:
selector: '{image_name="nginx.promtail.test"}'
stages:
- json:
expressions:
row: logZa vse dnevnike, katerih ime_slike je nginx.promtail.test, ekstrahirajte polje dnevnika iz izvornega dnevnika in ga postavite v ekstrahiran zemljevid s tipko vrstice.
- regex:
# suppress forego colors
expression: .+nginx.+|.+[0m(?P<virtual_host>[a-z_.-]+) +(?P<nginxlog>.+)
source: logrowPočistimo vnosno vrstico z regularnimi izrazi in izvlečemo navideznega gostitelja nginx in vrstico dnevnika nginx.
- regex:
source: nginxlog
expression: ^(?P<ip>[w.]+) - (?P<user>[^ ]*) [(?P<timestamp>[^ ]+).*] "(?P<method>[^ ]*) (?P<request_url>[^ ]*) (?P<request_http_protocol>[^ ]*)" (?P<status>[d]+) (?P<bytes_out>[d]+) "(?P<http_referer>[^"]*)" "(?P<user_agent>[^"]*)"( "(?P<response_time>[d.]+)")?Razčleni dnevnik nginx z uporabo regularnih izrazov.
- regex:
source: request_url
expression: ^.+.(?P<static_type>jpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|pdf|txt|tar|wav|bmp|rtf|js|flv|swf|html|htm)$
- regex:
source: request_url
expression: ^/photo/(?P<photo>[^/?.]+).*$
- regex:
source: request_url
expression: ^/api/(?P<api_request>[^/?.]+).*$Razčlenimo request_url. Z regexp določimo namen zahteve: do statičnih podatkov, do fotografij, do API-ja in nastavimo ustrezen ključ v izvlečenem zemljevidu.
- template:
source: request_type
template: "{{if .photo}}photo{{else if .static_type}}static{{else if .api_request}}api{{else}}other{{end}}"Z uporabo pogojnih operaterjev v predlogi preverimo nameščena polja v ekstrahiranem zemljevidu in nastavimo zahtevane vrednosti za polje request_type: photo, static, API. Če ne uspe, dodeli drugo. request_type zdaj vsebuje vrsto zahteve.
- labels:
api_request:
virtual_host:
request_type:
status:Oznake api_request, virtual_host, request_type in status (status HTTP) nastavimo glede na to, kar smo uspeli vnesti v ekstrahirani zemljevid.
- output:
source: nginx_log_rowSpremeni izhod. Zdaj gre očiščen dnevnik nginx iz ekstrahiranega zemljevida v Loki.
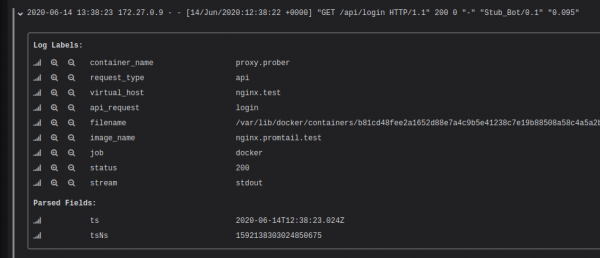
Po zagonu zgornje konfiguracije lahko vidite, da so vsakemu vnosu dodeljene oznake na podlagi podatkov iz dnevnika.
Ena stvar, ki jo morate imeti v mislih, je, da lahko pridobivanje oznak z velikim številom vrednosti (kardinalnost) znatno upočasni Loki. To pomeni, da v indeks ne smete dati na primer user_id. Več o tem v članku “" Vendar to ne pomeni, da ne morete iskati po user_id brez indeksov. Pri iskanju morate uporabiti filtre (»zgrabiti« podatke), indeks pa tukaj deluje kot identifikator toka.
Vizualizacija dnevnikov
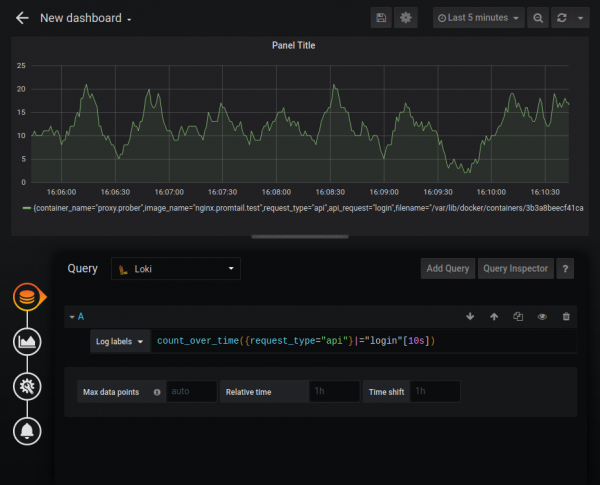
Loki lahko deluje kot vir podatkov za grafe Grafana z uporabo LogQL. Podprte so naslednje funkcije:
- hitrost — število zapisov na sekundo;
- štetje skozi čas — število zapisov v podanem obsegu.
Obstajajo tudi funkcije združevanja Sum, Avg in druge. Ustvarite lahko precej zapletene grafe, na primer graf števila napak HTTP:
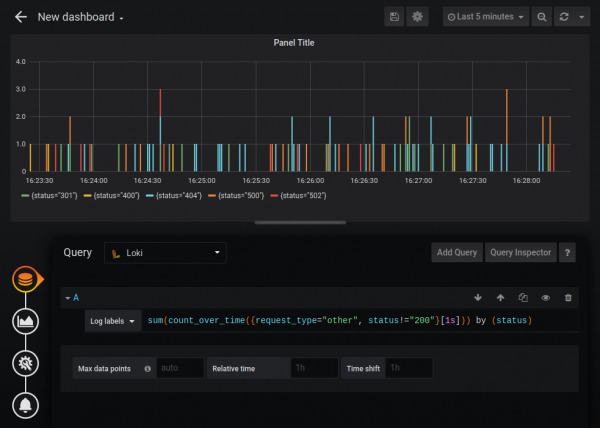
Standardni vir podatkov Loki je v primerjavi z virom podatkov Prometheus nekoliko okrnjen (na primer, ne morete spremeniti legende), vendar lahko Loki povežete kot vir s tipom Prometheus. Nisem prepričan, ali je to dokumentirano vedenje, a sodeč po odgovoru razvijalcev “”, je na primer popolnoma zakonit in Loki je popolnoma združljiv s PromQL.
Dodajte Loki kot vir podatkov z vrsto Prometheus in dodajte URL /loki:

In lahko naredimo grafe, kot da bi delali z metriko iz Prometheusa:
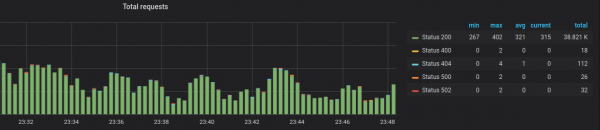
Mislim, da je neskladje v funkcionalnosti začasno in da bodo razvijalci to v prihodnosti popravili.
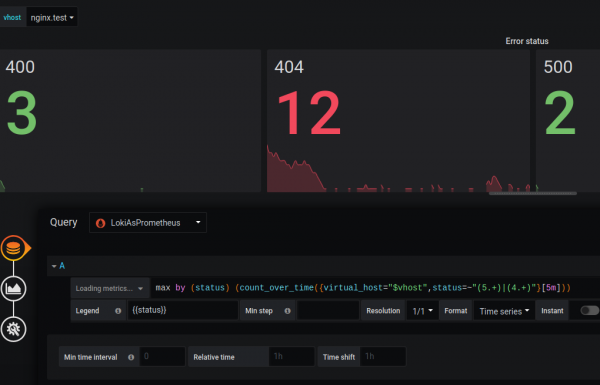
Metrike
Loki ponuja možnost pridobivanja numeričnih meritev iz dnevnikov in pošiljanja v Prometheus. Na primer, dnevnik nginx vsebuje število bajtov na odgovor, kot tudi, z določeno spremembo standardnega formata dnevnika, čas v sekundah, ki je potreben za odgovor. Te podatke je mogoče ekstrahirati in poslati Prometheusu.
Dodajte še en razdelek v promtail.yml:
- match:
selector: '{request_type="api"}'
stages:
- metrics:
http_nginx_response_time:
type: Histogram
description: "response time ms"
source: response_time
config:
buckets: [0.010,0.050,0.100,0.200,0.500,1.0]
- match:
selector: '{request_type=~"static|photo"}'
stages:
- metrics:
http_nginx_response_bytes_sum:
type: Counter
description: "response bytes sum"
source: bytes_out
config:
action: add
http_nginx_response_bytes_count:
type: Counter
description: "response bytes count"
source: bytes_out
config:
action: incMožnost vam omogoča definiranje in posodabljanje meritev na podlagi podatkov iz ekstrahiranega zemljevida. Te metrike niso poslane Lokiju – prikazane so v končni točki Promtail /metrics. Prometheus mora biti konfiguriran za prejemanje prejetih podatkov na tej stopnji. V zgornjem primeru za request_type=»api« zbiramo metriko histograma. S to vrsto metrike je priročno pridobiti percentile. Za statično in fotografijo zberemo vsoto bajtov in število vrstic, v katerih smo prejeli bajte, da izračunamo povprečje.
Preberite več o meritvah .
Odprite vrata na Promtailu:
promtail:
image: grafana/promtail:1.4.1
container_name: monitoring.promtail
expose:
- 9080
ports:
- "9080:9080"Prepričajte se, da so prikazane meritve s predpono promtail_custom:
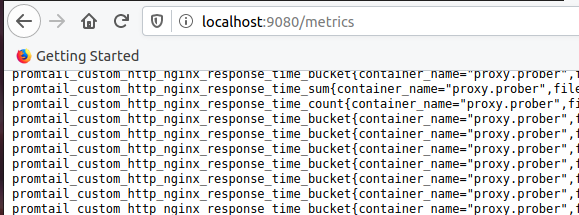
Postavitev Prometheusa. Dodaj obvestilo o delu:
- job_name: 'promtail'
scrape_interval: 10s
static_configs:
- targets: ['promtail:9080']In narišemo graf:
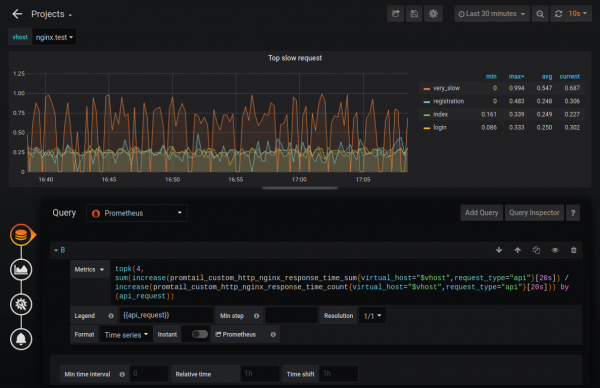
Tako lahko ugotovite na primer štiri najpočasnejše poizvedbe. Nastavite lahko tudi spremljanje teh meritev.
Skaliranje
Loki je lahko v enojnem binarnem načinu ali v razdeljenem načinu (vodoravno razširljiv način). V drugem primeru lahko shrani podatke v oblak, kosi in indeks pa so shranjeni ločeno. Različica 1.5 uvaja možnost shranjevanja na enem mestu, vendar je še ni priporočljivo uporabljati v produkciji.
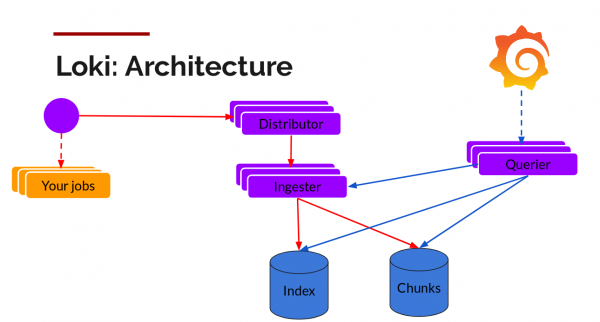
Kose je mogoče shraniti v pomnilnik, združljiv s S3, za shranjevanje indeksov pa je mogoče uporabiti vodoravno razširljive baze podatkov: Cassandra, BigTable ali DynamoDB. Drugi deli Lokija - Distributors (za pisanje) in Querier (za poizvedbe) - so brez stanja in se prav tako spreminjajo vodoravno.
Na konferenci DevOpsDays Vancouver 2019 je eden od udeležencev Callum Styan objavil, da ima njegov projekt skupaj z Lokijem petabajte dnevnikov z indeksom manj kot 1 % skupne velikosti: “".
Primerjava Lokija in ELK
Velikost indeksa
Da bi preizkusil nastalo velikost indeksa, sem vzel dnevnike iz vsebnika nginx, za katerega je bil konfiguriran zgornji cevovod. Dnevniška datoteka je vsebovala 406 vrstic s skupno prostornino 624 MB. Dnevniki so bili ustvarjeni v eni uri, približno 109 vnosov na sekundo.
Primer dveh vrstic iz dnevnika:

Ko ga je indeksiral ELK, je to dalo velikost indeksa 30,3 MB:
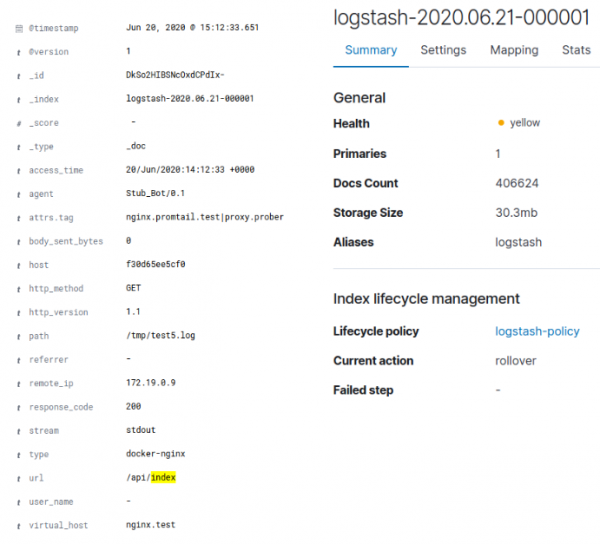
V primeru Lokija je to povzročilo približno 128 KB indeksa in približno 3,8 MB podatkov v kosih. Omeniti velja, da je bil dnevnik umetno ustvarjen in ni vseboval veliko različnih podatkov. Enostaven gzip na izvirnem dnevniku Docker JSON s podatki je dal 95,4-odstotno stiskanje in ob upoštevanju dejstva, da je bil v sam Loki poslan samo očiščen dnevnik nginx, je stiskanje do 4 MB razumljivo. Skupno število edinstvenih vrednosti za oznake Loki je bilo 35, kar pojasnjuje majhno velikost indeksa. Za ELK je bil tudi dnevnik počiščen. Tako je Loki stisnil izvirne podatke za 96 %, ELK pa za 70 %.
Poraba pomnilnika
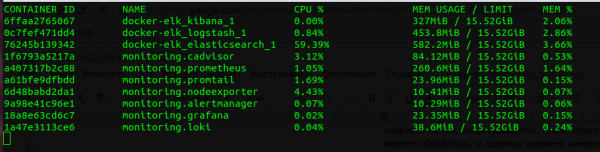
Če primerjamo celoten sklad Prometheus in ELK, potem Loki "poje" nekajkrat manj. Jasno je, da storitev Go porabi manj kot storitev Java in da je primerjava velikosti JVM Heap Elasticsearch in dodeljenega pomnilnika za Loki napačna, vendar je kljub temu vredno omeniti, da Loki uporablja veliko manj pomnilnika. Njegova CPU prednost ni tako očitna, a je tudi prisotna.
Hitro
Loki hitreje "požre" polena. Hitrost je odvisna od mnogih dejavnikov - kakšni so dnevniki, kako sofisticirani smo pri njihovem razčlenjevanju, omrežje, disk itd. - vendar je vsekakor višja od ELK (v mojem testu - približno dvakrat). To je razloženo z dejstvom, da Loki vnese veliko manj podatkov v indeks in zato porabi manj časa za indeksiranje. Pri hitrosti iskanja je ravno obratno: Loki opazno upočasni podatke, večje od nekaj gigabajtov, medtem ko hitrost iskanja ELK ni odvisna od velikosti podatkov.
Iskanje po dnevnikih
Loki je bistveno slabši od ELK v smislu zmožnosti iskanja dnevnikov. Grep z regularnimi izrazi je močan, vendar je slabši od zrele zbirke podatkov. Pomanjkanje poizvedb po obsegu, združevanje samo po oznakah, nezmožnost iskanja brez oznak - vse to nas omejuje pri iskanju informacij, ki nas zanimajo v Lokiju. To ne pomeni, da z uporabo Lokija ni mogoče najti ničesar, ampak definira potek dela z dnevniki, ko prvič najdete težavo v grafikonih Prometheus in nato s temi oznakami poiščete, kaj se je zgodilo v dnevnikih.
vmesnik
Najprej je lep (žal, nisem se mogel upreti). Grafana ima lep vmesnik, vendar je Kibana veliko bolj bogata s funkcijami.
Prednosti in slabosti Lokija
Ena od prednosti je, da se Loki integrira s Prometheusom, tako da dobimo metrike in opozarjanje takoj. Primeren je za zbiranje dnevnikov in njihovo shranjevanje iz Kubernetes Pods, saj ima odkrivanje storitev, podedovano od Prometheusa, in samodejno pripisuje oznake.
Slaba stran je slaba dokumentacija. Nekatere stvari, na primer lastnosti in zmožnosti Promtaila, sem odkril šele med preučevanjem kode, na srečo je odprtokodna. Druga pomanjkljivost so šibke zmožnosti razčlenjevanja. Na primer, Loki ne more razčleniti večvrstičnih dnevnikov. Druga pomanjkljivost je, da je Loki relativno mlada tehnologija (izdaja 1.0 je bila novembra 2019).
Zaključek
Loki je 100% zanimiva tehnologija, ki je primerna za majhne in srednje velike projekte, saj vam omogoča reševanje številnih problemov združevanja dnevnikov, iskanja dnevnikov, spremljanja in analize dnevnikov.
V Badooju ne uporabljamo Lokija, ker imamo sklad ELK, ki nam ustreza in je bil v preteklih letih preraščen z različnimi rešitvami po meri. Za nas je kamen spotike iskanje po dnevnikih. Pri skoraj 100 GB dnevnikov na dan nam je pomembno, da lahko najdemo vse in še malo več in to hitro. Za načrtovanje in spremljanje uporabljamo druge rešitve, ki so prilagojene našim potrebam in med seboj povezane. Sklad Loki ima oprijemljive prednosti, vendar nam ne bo dal več, kot že imamo, in njegove prednosti zagotovo ne bodo odtehtale stroškov selitve.
In čeprav je po raziskavi postalo jasno, da Lokija ne moremo uporabljati, upamo, da vam bo ta objava pomagala pri izbiri.
Repozitorij s kodo, uporabljeno v članku, se nahaja .
Vir: www.habr.com
