


Tunakutana mara kwa mara na hifadhidata ya Apache Cassandra na hitaji la kuiendesha ndani ya miundombinu inayotegemea Kubernetes. Katika nyenzo hii, tutashiriki maono yetu ya hatua muhimu, vigezo na ufumbuzi uliopo (ikiwa ni pamoja na muhtasari wa waendeshaji) kwa kuhamia Cassandra hadi K8s.
"Yeyote anayeweza kutawala mwanamke anaweza pia kutawala serikali"
Cassandra ni nani? Ni mfumo wa hifadhi uliosambazwa ulioundwa kudhibiti idadi kubwa ya data huku ukihakikisha upatikanaji wa juu bila nukta moja ya kushindwa. Mradi hauhitaji utangulizi mrefu, kwa hivyo nitatoa tu sifa kuu za Cassandra ambazo zitakuwa muhimu katika muktadha wa kifungu fulani:
- Cassandra imeandikwa katika Java.
- Topolojia ya Cassandra inajumuisha viwango kadhaa:
- Node - mfano mmoja uliotumika wa Cassandra;
- Rack ni kundi la matukio ya Cassandra, iliyounganishwa na baadhi ya tabia, iko katika kituo cha data sawa;
- Datacenter - mkusanyiko wa makundi yote ya matukio ya Cassandra yaliyo katika kituo kimoja cha data;
- Cluster ni mkusanyiko wa vituo vyote vya data.
- Cassandra hutumia anwani ya IP kutambua nodi.
- Ili kuharakisha shughuli za kuandika na kusoma, Cassandra huhifadhi baadhi ya data kwenye RAM.
Sasa - kwa uwezekano halisi wa kuhamia Kubernetes.
Orodha ya kuangalia kwa uhamisho
Kuzungumza juu ya uhamiaji wa Cassandra kwenda Kubernetes, tunatumai kuwa kwa hatua hiyo itakuwa rahisi zaidi kudhibiti. Nini kitahitajika kwa hili, ni nini kitasaidia na hili?
1. Hifadhi ya data
Kama ilivyoelezwa tayari, Cassanda huhifadhi sehemu ya data katika RAM - in Inakumbukwa. Lakini kuna sehemu nyingine ya data ambayo imehifadhiwa kwenye diski - kwa fomu SSTable. Huluki imeongezwa kwa data hii Kumbukumbu ya Kujitolea - rekodi za shughuli zote, ambazo pia zimehifadhiwa kwenye diski.
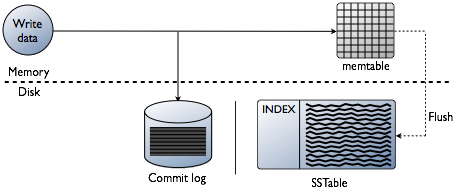
Andika mchoro wa shughuli katika Cassandra
Katika Kubernetes, tunaweza kutumia PersistentVolume kuhifadhi data. Shukrani kwa mifumo iliyothibitishwa, kufanya kazi na data katika Kubernetes inakuwa rahisi kila mwaka.
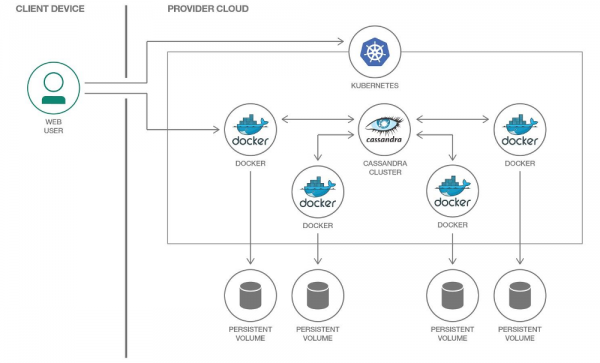
Tutatenga PersistentVolume yetu wenyewe kwa kila ganda la Cassandra
Ni muhimu kutambua kwamba Cassandra yenyewe inamaanisha urudiaji wa data, ikitoa mifumo iliyojumuishwa kwa hii. Kwa hivyo, ikiwa unaunda nguzo ya Cassandra kutoka kwa idadi kubwa ya nodi, basi hakuna haja ya kutumia mifumo iliyosambazwa kama Ceph au GlusterFS kwa uhifadhi wa data. Katika kesi hii, itakuwa busara kuhifadhi data kwenye diski ya mwenyeji kwa kutumia au kuweka hostPath.
Swali lingine ni ikiwa unataka kuunda mazingira tofauti kwa watengenezaji kwa kila tawi la kipengele. Katika kesi hii, mbinu sahihi itakuwa kuinua node moja ya Cassandra na kuhifadhi data katika hifadhi iliyosambazwa, i.e. Ceph na GlusterFS zilizotajwa zitakuwa chaguzi zako. Kisha msanidi atakuwa na uhakika kwamba hatapoteza data ya majaribio hata ikiwa nodi moja ya nguzo ya Kuberntes itapotea.
2. Ufuatiliaji
Chaguo ambalo halijapingwa la kutekeleza ufuatiliaji katika Kubernetes ni Prometheus (Tulizungumza juu ya hili kwa undani ). Je, Cassandra anaendeleaje na wasafirishaji wa vipimo vya Prometheus? Na, ni nini muhimu zaidi, na dashibodi zinazolingana za Grafana?
Mfano wa kuonekana kwa grafu huko Grafana kwa Cassandra
Kuna wasafirishaji wawili tu: и .
Tulijichagulia ya kwanza kwa sababu:
- JMX Exporter inakua na kuendeleza, wakati Cassandra Exporter haijaweza kupata usaidizi wa kutosha wa jamii. Cassandra Exporter bado haitumii matoleo mengi ya Cassandra.
- Unaweza kuiendesha kama javaagent kwa kuongeza bendera
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - Kuna moja kwa ajili yake , ambayo haioani na Cassandra Exporter.
3. Kuchagua Kubernetes primitives
Kulingana na muundo hapo juu wa nguzo ya Cassandra, wacha tujaribu kutafsiri kila kitu kilichoelezewa hapo kwa istilahi ya Kubernetes:
- Nodi ya Cassandra → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → bwawa kutoka StatefulSets
- Nguzo ya Cassandra → ???
Inabadilika kuwa huluki fulani ya ziada inakosekana kudhibiti nguzo nzima ya Cassandra mara moja. Lakini ikiwa kitu haipo, tunaweza kuunda! Kubernetes ina utaratibu wa kufafanua rasilimali zake kwa kusudi hili - .
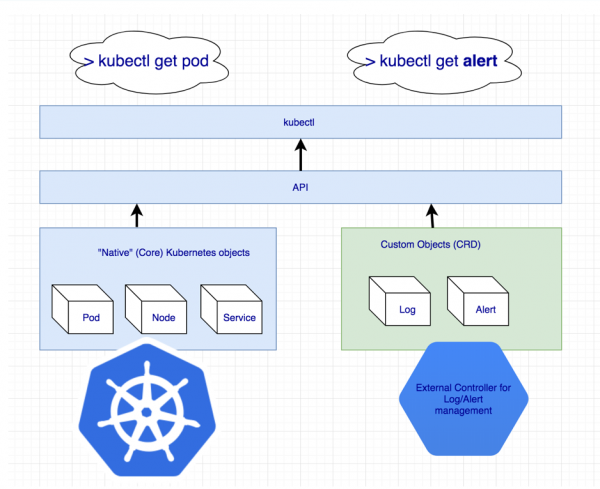
Kutangaza rasilimali za ziada kwa kumbukumbu na arifa
Lakini Rasilimali Maalum yenyewe haimaanishi chochote: baada ya yote, inahitaji mtawala. Huenda ukahitaji kutafuta msaada ...
4. Utambulisho wa maganda
Katika aya iliyo hapo juu, tulikubaliana kwamba nodi moja ya Cassandra itakuwa sawa na ganda moja katika Kubernetes. Lakini anwani za IP za maganda zitakuwa tofauti kila wakati. Na kitambulisho cha node katika Cassandra inategemea anwani ya IP ... Inatokea kwamba baada ya kila kuondolewa kwa pod, kikundi cha Cassandra kitaongeza node mpya.
Kuna njia ya kutoka, na sio moja tu:
- Tunaweza kuweka rekodi kwa vitambulishi vya seva pangishi (UUID ambazo hutambulisha matukio ya Cassandra kwa njia ya kipekee) au kwa anwani za IP na kuzihifadhi zote katika baadhi ya miundo/jedwali. Mbinu hiyo ina hasara kuu mbili:
- Hatari ya hali ya mbio kutokea ikiwa nodi mbili zitaanguka mara moja. Baada ya kupanda, nodi za Cassandra zitaomba wakati huo huo anwani ya IP kutoka kwa meza na kushindana kwa rasilimali sawa.
- Ikiwa nodi ya Cassandra imepoteza data yake, hatutaweza tena kuitambua.
- Suluhisho la pili linaonekana kama udukuzi mdogo, lakini hata hivyo: tunaweza kuunda Huduma na ClusterIP kwa kila nodi ya Cassandra. Matatizo na utekelezaji huu:
- Ikiwa kuna nodi nyingi kwenye nguzo ya Cassandra, tutalazimika kuunda Huduma nyingi.
- Kipengele cha ClusterIP kinatekelezwa kupitia iptables. Hili linaweza kuwa tatizo ikiwa nguzo ya Cassandra ina nodi nyingi (1000... au hata 100?). Ingawa inaweza kutatua tatizo hili.
- Suluhisho la tatu ni kutumia mtandao wa nodi za nodi za Cassandra badala ya mtandao uliojitolea wa maganda kwa kuwezesha mpangilio.
hostNetwork: true. Njia hii inaweka vikwazo fulani:- Ili kuchukua nafasi ya vitengo. Ni muhimu kwamba nodi mpya lazima iwe na anwani ya IP sawa na ile ya awali (katika mawingu kama AWS, GCP hii ni vigumu kufanya);
- Kutumia mtandao wa nodi za nguzo, tunaanza kushindana kwa rasilimali za mtandao. Kwa hivyo, kuweka ganda zaidi ya moja na Cassandra kwenye nodi moja ya nguzo itakuwa shida.
5. Hifadhi rudufu
Tunataka kuhifadhi toleo kamili la data ya nodi moja ya Cassandra kwenye ratiba. Kubernetes hutoa kipengele rahisi kutumia , lakini hapa Cassandra mwenyewe anaweka spoke katika magurudumu yetu.
Acha nikukumbushe kwamba Cassandra huhifadhi baadhi ya data kwenye kumbukumbu. Ili kufanya nakala kamili, unahitaji data kutoka kwa kumbukumbu (Memtables) nenda kwa diski (SSTables) Kwa wakati huu, node ya Cassandra inachaacha kukubali miunganisho, ikizima kabisa kutoka kwa nguzo.
Baada ya hayo, chelezo huondolewa (snapshot) na mpango huo umehifadhiwa (nafasi muhimu) Na kisha inageuka kuwa nakala rudufu haitupa chochote: tunahitaji kuokoa vitambulisho vya data ambavyo nodi ya Cassandra iliwajibika - hizi ni ishara maalum.
Usambazaji wa tokeni ili kutambua ni data gani ya nodi za Cassandra zinawajibika
Mfano wa hati ya kuchukua nakala ya Cassandra kutoka Google katika Kubernetes inaweza kupatikana . Jambo pekee ambalo hati haizingatii ni kuweka upya data kwenye nodi kabla ya kuchukua picha. Hiyo ni, nakala rudufu haifanyiki kwa hali ya sasa, lakini kwa hali mapema kidogo. Lakini hii inasaidia si kuchukua node nje ya uendeshaji, ambayo inaonekana kuwa ya mantiki sana.
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Mfano wa hati ya bash ya kuchukua nakala rudufu kutoka kwa nodi moja ya Cassandra
Suluhu zilizo tayari kwa Cassandra huko Kubernetes
Ni nini kinachotumika kwa sasa kupeleka Cassandra huko Kubernetes na ni ipi kati ya hizi inayofaa zaidi mahitaji yaliyotolewa?
1. Suluhisho kulingana na chati za StatefulSet au Helm
Kutumia vitendaji vya msingi vya StatefulSets kuendesha nguzo ya Cassandra ni chaguo nzuri. Kwa kutumia chati ya Helm na violezo vya Go, unaweza kumpa mtumiaji kiolesura rahisi cha kupeleka Cassandra.
Hii kawaida hufanya kazi vizuri ... hadi jambo lisilotarajiwa lifanyike, kama vile kutofaulu kwa nodi. Zana za Kubernetes za kawaida haziwezi kuzingatia vipengele vyote vilivyoelezwa hapo juu. Zaidi ya hayo, mbinu hii ni mdogo sana kwa kiasi gani inaweza kupanuliwa kwa matumizi magumu zaidi: uingizwaji wa nodi, chelezo, urejeshaji, ufuatiliaji, nk.
Wawakilishi:
- ;
- .
Chati zote mbili ni nzuri kwa usawa, lakini zinakabiliwa na matatizo yaliyoelezwa hapo juu.
2. Suluhisho kulingana na Kubernetes Operator
Chaguzi kama hizo zinavutia zaidi kwa sababu hutoa fursa nyingi za kusimamia nguzo. Kwa kubuni opereta wa Cassandra, kama hifadhidata nyingine yoyote, muundo mzuri unaonekana kama Sidecar <-> Controller <-> CRD:
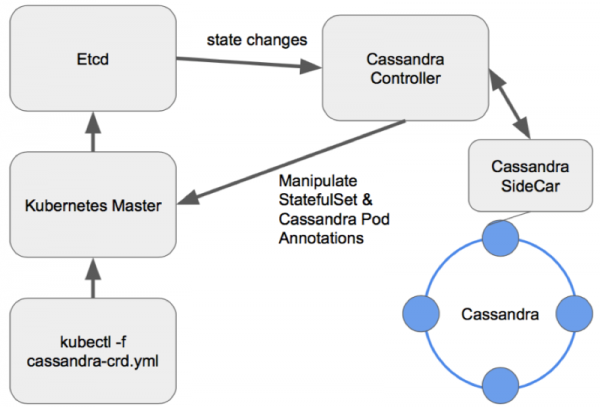
Mpango wa usimamizi wa nodi katika opereta iliyoundwa vizuri ya Cassandra
Wacha tuangalie waendeshaji waliopo.
1. Cassandra-operator kutoka instaclustr
- Utayari: Alfa
- Leseni: Apache 2.0
- Inatekelezwa katika: Java
Hakika huu ni mradi wa kuahidi sana na unaoendelea kutoka kwa kampuni inayotoa upelekaji wa Cassandra unaosimamiwa. Ni, kama ilivyoelezwa hapo juu, hutumia kontena la kando ambalo linakubali amri kupitia HTTP. Imeandikwa katika Java, wakati mwingine hukosa utendakazi wa hali ya juu zaidi wa maktaba ya mteja-kwenda. Pia, operator haungi mkono Racks tofauti kwa Datacenter moja.
Lakini opereta ana faida kama vile usaidizi wa ufuatiliaji, usimamizi wa nguzo wa kiwango cha juu kwa kutumia CRD, na hata uhifadhi wa hati za kutengeneza nakala.
2. Navigator kutoka Jetstack
- Utayari: Alfa
- Leseni: Apache 2.0
- Imetekelezwa katika: Golang
Taarifa iliyoundwa kupeleka DB-kama-a-Huduma. Kwa sasa inasaidia hifadhidata mbili: Elasticsearch na Cassandra. Inayo masuluhisho ya kupendeza kama vile udhibiti wa ufikiaji wa hifadhidata kupitia RBAC (kwa hii ina navigator-apiserver yake tofauti). Mradi wa kuvutia ambao ungestahili kuangaliwa kwa karibu, lakini ahadi ya mwisho ilifanywa mwaka mmoja na nusu iliyopita, ambayo inapunguza wazi uwezo wake.
3. Cassandra-operator na vgkowski
- Utayari: Alfa
- Leseni: Apache 2.0
- Imetekelezwa katika: Golang
Hawakuzingatia "kwa uzito", kwani ahadi ya mwisho kwenye hazina ilikuwa zaidi ya mwaka mmoja uliopita. Utengenezaji wa opereta umeachwa: toleo la hivi punde zaidi la Kubernetes lililoripotiwa kama linavyotumika ni 1.9.
4. Cassandra-operator na Rook
- Utayari: Alfa
- Leseni: Apache 2.0
- Imetekelezwa katika: Golang
Opereta ambaye maendeleo yake hayaendelei haraka kama tungependa. Ina muundo wa CRD uliofikiriwa vizuri kwa usimamizi wa nguzo, hutatua tatizo la kutambua nodi kwa kutumia Huduma na ClusterIP ("hack" sawa)... lakini ni hayo tu kwa sasa. Kwa sasa hakuna ufuatiliaji au chelezo nje ya kisanduku (kwa njia, tuko kwa ajili ya ufuatiliaji ) Jambo la kufurahisha ni kwamba unaweza pia kupeleka ScyllaDB kwa kutumia opereta huyu.
NB: Tulitumia opereta huyu kwa marekebisho madogo katika mojawapo ya miradi yetu. Hakuna matatizo yaliyoonekana katika kazi ya operator wakati wa kipindi chote cha operesheni (~ miezi 4 ya uendeshaji).
5. CassKop kutoka Orange
- Utayari: Alfa
- Leseni: Apache 2.0
- Imetekelezwa katika: Golang
Opereta mdogo zaidi kwenye orodha: ahadi ya kwanza ilifanywa mnamo Mei 23, 2019. Tayari sasa ina katika arsenal yake idadi kubwa ya vipengele kutoka kwenye orodha yetu, maelezo zaidi ambayo yanaweza kupatikana katika hifadhi ya mradi. Opereta imejengwa kwa misingi ya operator-sdk maarufu. Inasaidia ufuatiliaji nje ya boksi. Tofauti kuu kutoka kwa waendeshaji wengine ni matumizi , kutekelezwa katika Python na kutumika kwa mawasiliano kati ya nodi za Cassandra.
Matokeo
Idadi ya mbinu na chaguzi zinazowezekana za kuhamisha Cassandra hadi Kubernetes inajieleza yenyewe: mada iko katika mahitaji.
Katika hatua hii, unaweza kujaribu yoyote ya hapo juu kwa hatari na hatari yako mwenyewe: hakuna hata mmoja wa watengenezaji anayehakikishia uendeshaji wa 100% wa ufumbuzi wao katika mazingira ya uzalishaji. Lakini tayari sasa bidhaa nyingi zinaonekana kuahidi kujaribu kuzitumia katika madawati ya maendeleo.
Nadhani katika siku zijazo mwanamke huyu kwenye meli atakuja kwa manufaa!
PS
Soma pia kwenye blogi yetu:
- «";
- «";
- «";
- «'.
Chanzo: mapenzi.com
