

มาดูพื้นฐานของการบันทึกใน Docker และ Kubernetes แล้วพิจารณาเครื่องมือสองรายการที่สามารถใช้ได้อย่างปลอดภัยในการผลิต: Grafana Loki และสแต็ก EFK (Elasticsearch + Fluent Bit + Kibana)
เนื้อหาของบทความก็บีบมาจาก . หากคุณมีความปรารถนา และยิ่งไปกว่านั้นคือความต้องการด้านการผลิต คุณสามารถเข้ารับการฝึกอบรมเต็มรูปแบบได้ - สมัครเข้าร่วมหลักสูตร .

เข้าสู่ระบบนักเทียบท่า
ที่ระดับ Kubernetes แอปพลิเคชันจะทำงานในพ็อด แต่ในระดับที่ต่ำกว่า แอปพลิเคชันเหล่านั้นมักจะทำงานใน Docker ดังนั้น คุณจึงต้องกำหนดค่าการบันทึกในลักษณะการรวบรวมบันทึกจากคอนเทนเนอร์ Docker เปิดตัวคอนเทนเนอร์ ซึ่งหมายความว่าคุณต้องเข้าใจวิธีการทำงานของการบันทึกในระดับ Docker
ฉันหวังว่าผู้อ่านทุกคนจะรู้: ควรเขียนบันทึกแอปพลิเคชันไปที่ stdout/stderr ไม่ใช่ในคอนเทนเนอร์ บันทึกถูกรวบรวมโดย Docker Daemon และใช้งานได้กับบันทึกที่ส่งไปยัง stdout/stderr ทุกประการ นอกจากนี้ การเขียนบันทึกภายในคอนเทนเนอร์ยังเต็มไปด้วยปัญหา: คอนเทนเนอร์ขยายใหญ่ขึ้นจากบันทึกที่กำลังเติบโต (เนื่องจากมีแนวโน้มว่าไม่มี Logrotate ในคอนเทนเนอร์) และ Docker Daemon ไม่ทราบถึงบันทึกนี้
นักเทียบท่ามีไดรเวอร์หรือปลั๊กอินบันทึกหลายตัวสำหรับรวบรวมบันทึกคอนเทนเนอร์ Docker Community Edition (CE) ฟรีมีไดรเวอร์บันทึกน้อยกว่า Docker Enterprise Edition (EE) เชิงพาณิชย์

ฉันไม่เคยใช้ Docker EE ในทางปฏิบัติเลย: ที่ Southbridge เราพยายามปฏิบัติตามโซลูชัน Open Source และลูกค้าไม่ต้องการคุณสมบัติเพิ่มเติมส่วนใหญ่ของ Docker EE
บันทึกไดรเวอร์ใน Docker CE:
ในประเทศ - การเขียนบันทึกไปยังไฟล์ Docker Daemon ภายใน
json-ไฟล์ — สร้าง json-log ในโฟลเดอร์ของแต่ละคอนเทนเนอร์
วารสาร - ส่งบันทึกไปยังเจอร์นัล
การตั้งค่าการบันทึกนักเทียบท่าจะอยู่ในไฟล์ daemon.json
ช่อง “log-driver” ระบุปลั๊กอิน และช่อง “log-opts” ระบุการตั้งค่า ในตัวอย่างข้างต้น มีการระบุปลั๊กอิน “json-file” ขีดจำกัดขนาดบันทึกคือ “max-size”: “10m”; จำกัด จำนวนไฟล์ (การตั้งค่าการหมุน) - "max-file": "3"; ตลอดจนค่าต่างๆ ที่จะแนบไปกับบันทึก

การตั้งค่าไดรเวอร์บันทึกบางอย่างสามารถตั้งค่าได้ผ่านยูทิลิตีคำสั่ง วิธีนี้จะสะดวกหากจำเป็นต้องเปิดใช้คอนเทนเนอร์แยกต่างหากพร้อมกับไดรเวอร์บันทึกอื่น
นี่คือลักษณะรูปแบบการบันทึกใน Docker:
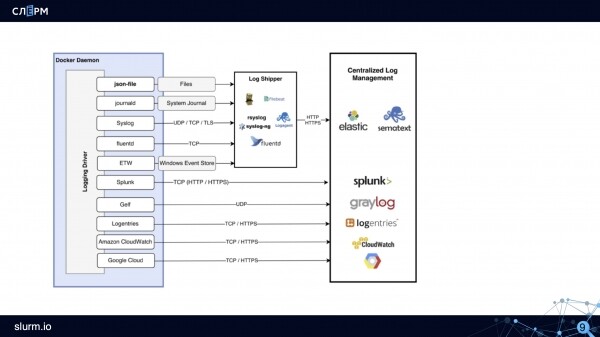
วิธีการทำงานของโครงร่าง: โปรแกรมควบคุมบันทึก เช่น ไฟล์ json จะสร้างไฟล์ ผู้รวบรวมบันทึก (Rsyslog, Fluentd, Logagent และอื่นๆ) รวบรวมไฟล์เหล่านี้และถ่ายโอนเพื่อจัดเก็บไปยัง Elastic, Sematext หรือพื้นที่จัดเก็บข้อมูลอื่นๆ
คุณสมบัติของการบันทึกใน Kubernetes
รูปแบบการบันทึกที่เรียบง่ายใน Kubernetes มีลักษณะดังนี้ มีพ็อด มีคอนเทนเนอร์ทำงานอยู่ในนั้น คอนเทนเนอร์ส่งบันทึกไปที่ stdout/stderr จากนั้นนักเทียบท่าจะสร้างไฟล์และเขียนบันทึก ซึ่งสามารถหมุนเวียนได้
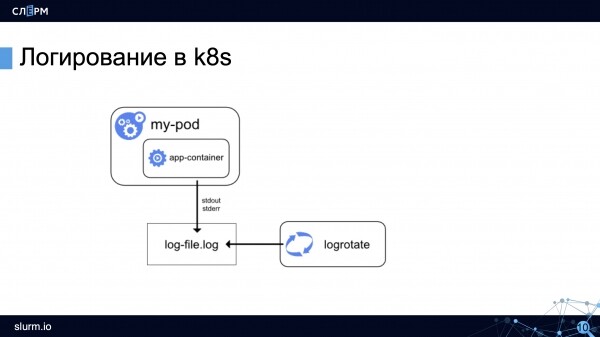
มาดูคุณสมบัติของการบันทึกใน Kubernetes กัน
บันทึกบันทึกระหว่างการปรับใช้. นี่เป็นข้อกำหนดเบื้องต้นสำหรับการตั้งค่าการบันทึกที่ถูกต้อง หากคุณไม่บันทึกบันทึกระหว่างการปรับใช้ เมื่อแอปพลิเคชันเวอร์ชันใหม่เปิดตัว บันทึกของเวอร์ชันก่อนหน้าจะถูกเขียนทับ และการรีบูตคอนเทนเนอร์จะเต็มไปด้วยการสูญเสียบันทึกด้วย Kubernetes มีคีย์ — ก่อนหน้า ซึ่งช่วยให้คุณดูบันทึกของแอปพลิเคชันได้จนถึงการรีสตาร์ท Pod ครั้งล่าสุด แต่ไม่ลึกกว่านี้
รวบรวมบันทึกจากทุกกรณี. หากไมโครเซอร์วิสโฮสต์อยู่ในคลาวด์ ผู้ให้บริการคลาวด์จะรับผิดชอบในการตรวจสอบระบบ หากไมโครเซอร์วิสอยู่บนฮาร์ดแวร์ของคุณเอง นอกเหนือจากบันทึกจากคอนเทนเนอร์แล้ว คุณต้องรวบรวมบันทึกของระบบด้วย
ก่อนหน้านี้ ไม่มีเครื่องมือที่สะดวกสำหรับการรวบรวมบันทึกจากทั้งระบบและไมโครเซอร์วิส โดยทั่วไปแล้ว เครื่องมือหนึ่งจะรวบรวมบันทึกของระบบ (เช่น Rsyslog) และอีกเครื่องมือหนึ่งจะรวบรวมบันทึกจาก Docker (เช่น journal-bit ที่กำหนดค่าไดรเวอร์บันทึกของ Docker เป็น journald) เราลองใช้ journal-bit เพื่อรวบรวมบันทึกจากทั้งคอนเทนเนอร์ (โดยระบุในไดรเวอร์บันทึกของ Docker ว่าควรเขียนบันทึกไปยัง journald) และจากระบบ (ใน CentOS เวอร์ชัน 7 มี systemd และ journald อยู่แล้ว วิธีแก้ปัญหานี้ใช้ได้ผล แต่ไม่ใช่ทางออกที่ดีที่สุด หากมีไฟล์บันทึกจำนวนมาก journal-bit จะเริ่มทำงานช้าลง และข้อความบางส่วนอาจสูญหายไป
การทดลองยังคงดำเนินต่อไป และในที่สุดก็พบวิธีใหม่ CentOS บันทึกระบบหลัก 7 รายการ (ข้อความ การตรวจสอบ การรักษาความปลอดภัย) จะถูกคัดลอกไปยังโฟลเดอร์ var log ในรูปแบบไฟล์ นอกจากนี้ Docker ยังสามารถตั้งค่าให้บันทึกบันทึกไปยังไฟล์ JSON ได้อีกด้วย ดังนั้นไฟล์เหล่านี้จึงเป็น... CentOS 7 และ Docker สามารถสร้างร่วมกันได้
เมื่อเวลาผ่านไป โซลูชัน ELK Stack ก็ได้รับความนิยม เป็นการผสมผสานระหว่างเครื่องมือหลายอย่าง: Elasticsearch, Logstash และ Kibana
Elasticsearch จัดเก็บบันทึกจากคอนเทนเนอร์ Logstash รวบรวมบันทึกจากอินสแตนซ์ Kibana ช่วยให้คุณประมวลผลบันทึกที่ได้รับและสร้างกราฟตามบันทึกเหล่านั้น ELK Stack ถูกใช้อย่างกว้างขวางมาระยะหนึ่งแล้ว แต่ในความคิดของฉัน เวลามันผ่านไปแล้ว ฉันจะบอกคุณว่าทำไมในภายหลัง
เพิ่มข้อมูลเมตา. พ็อด แอปพลิเคชัน คอนเทนเนอร์สามารถทำงานได้ทุกที่ นอกจากนี้ แอปพลิเคชันหนึ่งสามารถมีได้หลายอินสแตนซ์ บันทึกถูกเขียนในรูปแบบเดียวกัน แต่เราต้องเข้าใจว่ามันคือแบบจำลองใด Pod ตัวใดเขียน และอยู่ในเนมสเปซใด นี่คือสาเหตุที่บันทึกจำเป็นต้องเพิ่มข้อมูลเมตา
แยกวิเคราะห์บันทึก. น่าตลกดี แต่ค่าใช้จ่ายในการบำรุงรักษาระบบบันทึกและการตรวจสอบอาจเกินต้นทุนของแอปพลิเคชันหลักได้ เมื่อคุณมีท่อนไม้นับหมื่นบินต่อวินาที สิ่งนี้อาจดูเป็นเรื่องปกติ แต่คุณยังจำเป็นต้องรู้เส้น วิธีหนึ่งในการค้นหาบรรทัดนี้คือการแยกวิเคราะห์บันทึก
ตามกฎแล้ว ไม่จำเป็นต้องรวบรวมและจัดเก็บบันทึกทั้งหมด ควรส่งเพียงบางส่วนเพื่อจัดเก็บ - ตัวอย่างเช่น บันทึกที่มีสถานะ "คำเตือน" หรือ "ข้อผิดพลาด" หากเรากำลังพูดถึงบันทึกของ nginx หรือตัวควบคุมทางเข้าคุณสามารถส่งเฉพาะไฟล์ที่มีสถานะแตกต่างจาก 200 เพื่อจัดเก็บเท่านั้น แต่นี่ไม่ใช่คำแนะนำที่เป็นสากล: หากคุณสร้างการวิเคราะห์บนบันทึก Nginx เห็นได้ชัดว่าคุ้มค่าที่จะรวบรวมพวกมัน .
ไม่แนะนำให้กรองบันทึกอย่างไร้เหตุผล เนื่องจากข้อมูลที่กรองอาจไม่เพียงพอสำหรับการวิเคราะห์ตามปกติ ในทางกลับกัน บางทีการวิเคราะห์ไม่ควรดำเนินการที่ระดับการบันทึก แต่ที่ระดับการรวบรวมตัวชี้วัด จากนั้น คุณจะไม่ต้องจัดเก็บแถวหลายแสนแถวด้วยรหัส 200 วิธีหนึ่งคือการรับข้อมูลเกี่ยวกับการรับส่งข้อมูลและข้อผิดพลาดจากตัววัดตัวควบคุมทางเข้า
โดยทั่วไปคุณต้องคิดให้รอบคอบที่นี่: สิ่งที่คุณต้องการจัดเก็บและนานแค่ไหนเพราะไม่เช่นนั้นสถานการณ์จะเกิดขึ้นเมื่อระบบบันทึกจะใช้ทรัพยากรมากกว่าโครงการหลัก
ยังไม่มีวิธีแก้ปัญหามาตรฐานสำหรับการบันทึก. ต่างจากการตรวจสอบที่มีโซลูชัน Prometheus ที่ใช้กันทั่วไปมากที่สุด ตรงที่ไม่มีมาตรฐานในการบันทึก
ในการบรรยายนี้ เราจะดูเครื่องมือสองอย่าง: เครื่องมือหนึ่งยอดนิยม และเครื่องมือที่สองกำลังได้รับความนิยม นอกจากพวกเขาแล้วยังมีคนอื่นอีก แต่เราจะไม่พูดถึงพวกเขาในบทความนี้
เมื่อคำนึงถึงคุณสมบัติทั้งหมดที่กล่าวถึงข้างต้น ขณะนี้การเข้าสู่ระบบ Kubernetes สามารถแสดงในไดอะแกรมต่อไปนี้:
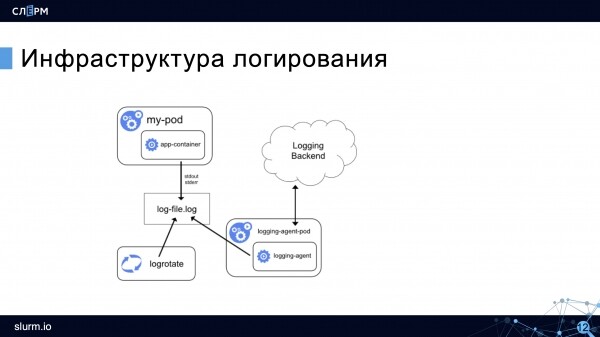
บันทึกและการหมุนเวียนคอนเทนเนอร์ยังคงอยู่ แต่ตัวแทนการรวบรวมจะปรากฏขึ้น ซึ่งจะเลือกบันทึกและส่งไปจัดเก็บ (ในไดอะแกรม - ไปยังแบ็คเอนด์การบันทึก) เอเจนต์ทำงานบนแต่ละโหนดและโดยทั่วไปจะรันบน Kubernetes
ตอนนี้เรามาดูเครื่องมือบันทึก
กราฟาน่า โลกิ
ปรากฏตัวเมื่อเร็ว ๆ นี้ แต่ก็โด่งดังไปแล้ว ข้อดี: ติดตั้งง่าย ใช้ทรัพยากรน้อย ไม่ต้องติดตั้ง Elasticsearch เนื่องจากเก็บข้อมูลไว้ใน TSDB (ฐานข้อมูลอนุกรมเวลา) ในบทความก่อนหน้านี้ ฉันเขียนว่า Prometheus เก็บข้อมูลไว้ในฐานข้อมูลดังกล่าว และนี่คือหนึ่งในหลาย ๆ ความคล้ายคลึงกันระหว่างผลิตภัณฑ์ทั้งสอง นักพัฒนายังอ้างว่า Loki คือ "โพรสำหรับโลกแห่งการตัดไม้"
การพูดนอกเรื่องสั้น ๆ เกี่ยวกับ TSDB สำหรับผู้ที่ยังไม่ได้อ่าน : TSDB ยอดเยี่ยมในการจัดเก็บข้อมูลอนุกรมเวลาจำนวนมาก แต่ไม่ได้ออกแบบมาเพื่อการจัดเก็บข้อมูลระยะยาว หากคุณจำเป็นต้องจัดเก็บบันทึกเป็นเวลานานกว่าสองสัปดาห์ด้วยเหตุผลบางประการ จะเป็นการดีกว่าถ้ากำหนดค่าการถ่ายโอนไปยังฐานข้อมูลอื่น
ข้อดีอีกประการหนึ่งของโลกิก็คือ Grafana ใช้สำหรับการแสดงข้อมูลเป็นภาพ สะดวกมาก: ใน Grafana เราดูข้อมูลการตรวจสอบ และเมื่อเชื่อมต่อ Loki เราจะดูบันทึก คุณสามารถสร้างกราฟโดยใช้บันทึก
สถาปัตยกรรมโลกิมีลักษณะดังนี้:
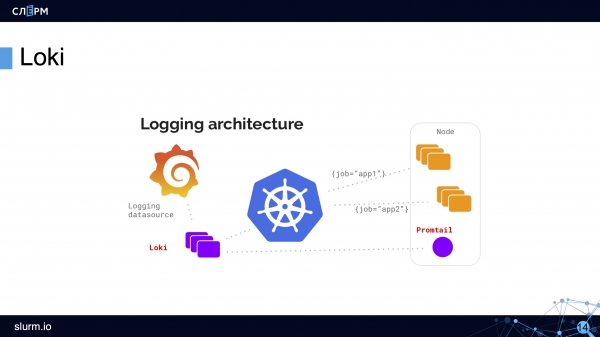
เมื่อใช้ DaemonSet เอเจนต์—Promtail หรือ Fluent Bit—จะถูกปรับใช้บนเซิร์ฟเวอร์ทั้งหมดในคลัสเตอร์ ตัวแทนรวบรวมบันทึก โลกิพาพวกมันไปเก็บไว้ใน TSDB ของเขา ข้อมูลเมตาจะถูกเพิ่มลงในบันทึกทันที ซึ่งสะดวก: คุณสามารถกรองตามพ็อด เนมสเปซ ชื่อคอนเทนเนอร์ และแม้แต่ป้ายกำกับได้
โลกิทำงานบนอินเทอร์เฟซ Grafana ที่คุ้นเคย โลกิยังมีภาษาคิวรีของตัวเองด้วย ซึ่งเรียกว่า LogQL ซึ่งคล้ายกับชื่อและไวยากรณ์ของ PromQL ใน Prometheus อินเทอร์เฟซของ Loki มีช่องข้อความค้นหา ดังนั้นคุณไม่จำเป็นต้องรู้ด้วยใจจริง
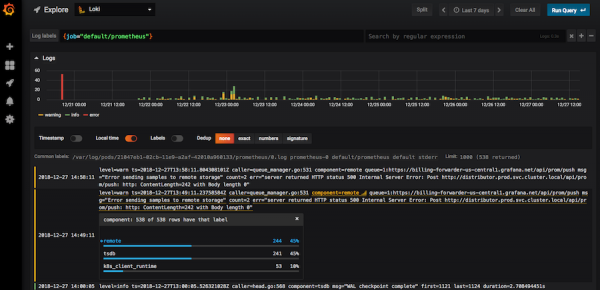
โลกิในอินเทอร์เฟซ Grafana
เมื่อใช้ตัวกรอง คุณสามารถค้นหารหัสในภาษาโลกิ (“400”, “404” และอื่นๆ) ดูบันทึกจากโหนดทั้งหมด กรองบันทึกทั้งหมดที่มีคำว่า "ข้อผิดพลาด" หากคุณคลิกที่บันทึก การ์ดที่มีข้อมูลทั้งหมดเกี่ยวกับกิจกรรมจะเปิดขึ้น
โลกิมีเครื่องมือเพียงพอที่ช่วยให้คุณสามารถดึงบันทึกที่จำเป็นออกมาได้ แม้ว่าพูดตามตรงแล้ว ในทางเทคนิคแล้วอาจมีมากกว่านี้ ตอนนี้โลกิกำลังพัฒนาและได้รับความนิยมอย่างแข็งขัน
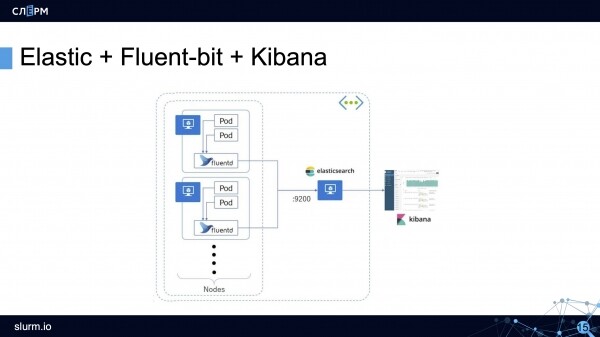
Elastic + Fluent Bit + Kibana (กลุ่ม EFK)
EFK stack เป็นเครื่องมือบันทึกที่คลาสสิกกว่า แต่ก็ได้รับความนิยมไม่น้อย
ในตอนต้นของบทความมีการกล่าวถึง ELK (Elasticsearch + Logstash + Kibana) แต่สแต็กนี้ล้าสมัยเนื่องจาก Logstash ไม่ค่อยมีประสิทธิผลและในเวลาเดียวกันก็ใช้ทรัพยากรมาก แต่พวกเขาเริ่มใช้ Fluentd ที่มีน้ำหนักเบาและมีประสิทธิภาพมากขึ้น และหลังจากนั้นไม่นานก็เข้ามาช่วยเหลือเขา — ตัวแทนรวบรวมที่เบากว่าและมีประสิทธิภาพยิ่งขึ้น
ตามที่นักพัฒนาระบุว่า Fluent Bit มีประสิทธิภาพดีกว่า Fluentd มากกว่า 100 เท่า: “โดยที่ Fluentd ใช้ RAM 20 MB, Fluent Bit จะใช้ 150 KB” - คำพูดโดยตรงจากเอกสารประกอบ เมื่อพิจารณาจากสิ่งนี้ Fluent Bit ก็เริ่มมีการใช้งานบ่อยขึ้น
Fluent Bit มีคุณสมบัติน้อยกว่า Fluentd แต่ครอบคลุมความต้องการขั้นพื้นฐาน ดังนั้นเราจึงใช้ Fluent Bit เป็นส่วนใหญ่
แผนการทำงานของสแต็ก EFK: เอเจนต์รวบรวมบันทึกจากพ็อดทั้งหมด (ตามกฎแล้ว นี่คือ DaemonSet ที่ทำงานบนเซิร์ฟเวอร์ทั้งหมดในคลัสเตอร์) และส่งไปยังพื้นที่จัดเก็บข้อมูล (Elasticsearch, PostgreSQL หรือ Kafka) Kibana เชื่อมต่อกับที่จัดเก็บข้อมูลและดึงข้อมูลที่จำเป็นทั้งหมดจากที่นั่น
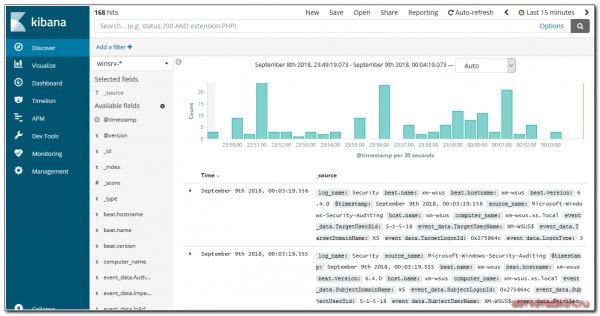
นำเสนอข้อมูลในเว็บอินเตอร์เฟสที่สะดวกสบาย มีกราฟ ฟิลเตอร์ และอื่นๆ อีกมากมาย
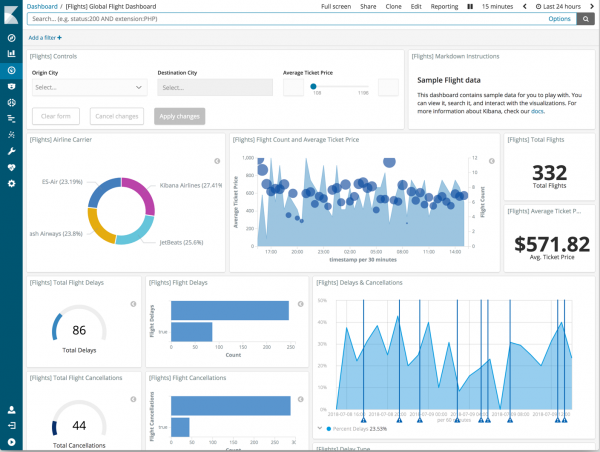
คุณสามารถสร้างแดชบอร์ดทั้งหมดได้โดยใช้บันทึก
คุณสมบัติ Bit ได้อย่างคล่องแคล่ว
เนื่องจากโดยทั่วไปแล้ว Fluent Bit นั้นไม่ค่อยมีใครได้ยินมากกว่า Logstash เรามาดูกันดีกว่า Fluent Bit สามารถแบ่งตามตรรกะออกเป็น 6 โมดูล โดยบางโมดูลอาจมีปลั๊กอินที่ขยายขีดความสามารถของ Fluent Bit
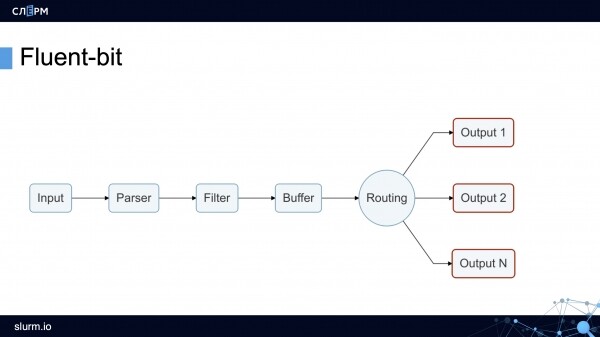
โมดูลอินพุต รวบรวมบันทึกจากไฟล์ บริการ systemd และแม้กระทั่งจาก tcp-socket (คุณเพียงแค่ต้องระบุจุดสิ้นสุด จากนั้น Fluent Bit จะเริ่มไปที่นั่น) ความสามารถเหล่านี้เพียงพอที่จะรวบรวมบันทึกจากทั้งระบบและคอนเทนเนอร์
ในการผลิตเรามักใช้ปลั๊กอินบ่อยที่สุด (สามารถตั้งค่าให้กับโฟลเดอร์ที่มีบันทึกได้) และ (คุณสามารถบอกได้ว่าบริการใดที่จะรวบรวมบันทึกจาก)
โมดูลพาร์เซอร์ นำบันทึกมาสู่รูปแบบทั่วไป ตามค่าเริ่มต้น บันทึก Nginx จะเป็นสตริง เมื่อใช้ปลั๊กอิน สตริงนี้สามารถแปลงเป็น JSON ได้: ตั้งค่าฟิลด์และค่า JSON ใช้งานได้ง่ายกว่าบันทึกสตริงมาก เนื่องจากมีตัวเลือกการเรียงลำดับที่ยืดหยุ่นมากกว่า
โมดูลตัวกรอง. ในระดับนี้ บันทึกที่ไม่จำเป็นจะถูกกรองออก ตัวอย่างเช่น บันทึกเฉพาะที่มีค่า "คำเตือน" หรือป้ายกำกับบางอย่างเท่านั้นที่จะถูกส่งไปจัดเก็บ บันทึกที่เลือกจะเข้าไปในบัฟเฟอร์
โมดูลบัฟเฟอร์. Fluent Bit มีบัฟเฟอร์สองประเภท: บัฟเฟอร์หน่วยความจำและบัฟเฟอร์ดิสก์ บัฟเฟอร์คือการจัดเก็บบันทึกชั่วคราว ซึ่งจำเป็นในกรณีที่เกิดข้อผิดพลาดหรือความล้มเหลว ทุกคนต้องการประหยัด RAM ดังนั้นพวกเขาจึงมักเลือกดิสก์บัฟเฟอร์ แต่คุณต้องคำนึงว่าก่อนที่จะลงดิสก์ บันทึกจะยังคงถูกดาวน์โหลดลงในหน่วยความจำ
โมดูลการกำหนดเส้นทาง/เอาต์พุต มีกฎและที่อยู่สำหรับการส่งบันทึก ดังที่กล่าวไปแล้ว สามารถส่งบันทึกไปยัง Elasticsearch, PostgreSQL หรือ Kafka ได้
สิ่งที่น่าสนใจคือสามารถส่งบันทึกจาก Fluent Bit ไปยัง Fluentd ได้ เนื่องจากอันแรกมีน้ำหนักเบากว่าและใช้งานได้น้อยกว่า คุณจึงสามารถรวบรวมบันทึกและส่งไปยัง Fluentd ได้ และด้วยความช่วยเหลือของปลั๊กอินเพิ่มเติม จึงสามารถประมวลผลและส่งไปยังที่เก็บเพิ่มเติมได้
หากคุณวางแผนที่จะใช้ Elasticsearch...
สุดท้ายนี้ มีเคล็ดลับสองประการสำหรับผู้ที่วางแผนจะใช้ Elasticsearch เป็นที่จัดเก็บบันทึกในการผลิต
- ตั้งค่าการแจ้งเตือนโดยใช้ . โปรแกรมนี้แยกข้อความสำคัญออกจากขั้นตอนทั่วไปของบันทึกและแจ้งเตือนไปยังอีเมลหรือช่องทางอื่น จริงมันออกมาไม่นานมานี้ .
- หมุนบันทึกโดยใช้แอปพลิเคชัน หรือการเรียกไปยัง Elasticsearch API โดยหลักการแล้ว Elastic เองก็กำลังดำเนินการตามขั้นตอนสำคัญในการจัดการอายุการใช้งานของดัชนีโดยไม่ต้องใช้เครื่องมือของบุคคลที่สาม โดยทั่วไป ไม่มีประโยชน์ในการจัดเก็บบันทึกเป็นเวลานาน: ไม่น่าจะจำเป็นต้องใช้บันทึกใดๆ หลังจากผ่านไปสองสัปดาห์ หากมีความสำคัญจริงๆ บันทึกจะได้รับการประมวลผลภายในสองสัปดาห์อย่างแน่นอน ทางเลือกสุดท้ายคือสามารถเก็บถาวรบันทึกเก่าและส่งไปที่ไหนสักแห่งเพื่อจัดเก็บข้อมูลระยะยาวได้ ฉันได้ยินเกี่ยวกับบันทึกพิเศษที่กฎหมายกำหนดให้เก็บไว้นานถึง 5 ปี โดยส่วนตัวแล้วฉันไม่เคยพบสิ่งนี้ แต่ฉันจะไม่เปรียบเทียบข้อมูลดังกล่าวกับบันทึกธรรมดาและอาจจัดเก็บแยกกันด้วยซ้ำ
จะยังคง ...
ผู้แต่ง: Marcel Ibraev ผู้ดูแลระบบ Kubernetes ที่ได้รับการรับรอง วิศวกรฝึกหัดในบริษัท วิทยากรและผู้พัฒนาหลักสูตร .
ที่มา: will.com
