

บทความนี้ประกอบด้วยสองส่วน:
- คำอธิบายสั้นๆ เกี่ยวกับสถาปัตยกรรมเครือข่ายการตรวจจับและการแบ่งส่วนวัตถุในภาพ พร้อมลิงก์ไปยังแหล่งข้อมูลที่ผมเข้าใจง่ายที่สุด ผมพยายามเลือกวิดีโออธิบาย โดยเฉพาะอย่างยิ่งในภาษารัสเซีย
- ส่วนที่สองพยายามที่จะเข้าใจทิศทางการพัฒนาของสถาปัตยกรรมเครือข่ายประสาทและเทคโนโลยีที่ใช้สถาปัตยกรรมดังกล่าว

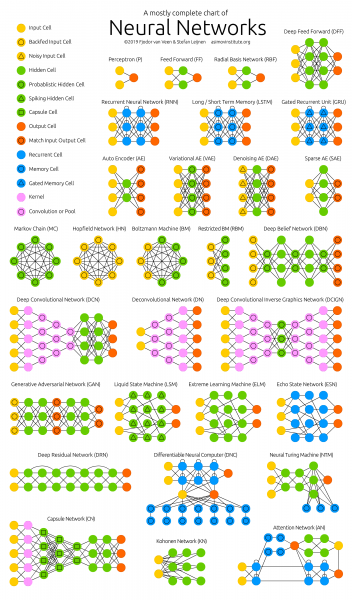
รูปที่ 1 – การทำความเข้าใจสถาปัตยกรรมเครือข่ายประสาทไม่ใช่เรื่องง่าย
ทุกอย่างเริ่มต้นจากการที่ผมสร้างแอปสาธิตสองแอปสำหรับการจำแนกและตรวจจับวัตถุบนโทรศัพท์ของผม Android:
- เมื่อข้อมูลถูกประมวลผลบนเซิร์ฟเวอร์และส่งไปยังโทรศัพท์ การแบ่งประเภทภาพหมีสามประเภท ได้แก่ หมีสีน้ำตาล หมีสีดำ และหมีเท็ดดี้
- เมื่อประมวลผลข้อมูลบนโทรศัพท์ การตรวจจับวัตถุสามประเภท: เฮเซลนัท มะเดื่อ และอินทผลัม
มีความแตกต่างระหว่างงานการจำแนกภาพ การตรวจจับวัตถุในภาพ และ ดังนั้น จึงมีความจำเป็นที่จะต้องเรียนรู้ว่าสถาปัตยกรรมเครือข่ายประสาทแบบใดที่ตรวจจับวัตถุในภาพ และแบบใดที่สามารถแบ่งส่วนวัตถุได้ ผมได้ค้นพบตัวอย่างสถาปัตยกรรมต่อไปนี้พร้อมลิงก์ไปยังแหล่งข้อมูลที่เข้าใจง่ายที่สุด:
- ชุดสถาปัตยกรรมที่ใช้ R-CNN (Rกองทหารที่มี Cการปฎิวัติ Nยูรัล Nคุณสมบัติของเครือข่าย): R-CNN, R-CNN ที่รวดเร็ว , ในการตรวจจับวัตถุในภาพ กล่องขอบเขตจะถูกแยกออกมาโดยใช้กลไก Region Proposal Network (RPN) ในขั้นต้น มีการใช้กลไก Selective Search ที่ช้ากว่าแทน RPN กล่องขอบเขตที่แยกออกมาจะถูกป้อนเข้าสู่เครือข่ายประสาทเทียมทั่วไปเพื่อจำแนกประเภท สถาปัตยกรรม R-CNN ใช้ลูป "for" ที่ชัดเจนเพื่อวนซ้ำผ่านกล่องขอบเขต โดยสามารถรันได้มากถึง 2000 ครั้งผ่านเครือข่าย AlexNet ภายใน ลูป "for" ที่ชัดเจนเหล่านี้ทำให้การประมวลผลภาพช้าลง จำนวนลูปที่ชัดเจนและการทำงานผ่านเครือข่ายประสาทเทียมภายในจะลดลงในแต่ละเวอร์ชันใหม่ของสถาปัตยกรรม และมีการเปลี่ยนแปลงอื่นๆ อีกมากมายเพื่อเพิ่มความเร็วและแทนที่งานการตรวจจับวัตถุด้วยการแบ่งส่วนวัตถุใน Mask R-CNN
- (You Only LOOK Once) เป็นเครือข่ายประสาทเทียมตัวแรกที่สามารถจดจำวัตถุแบบเรียลไทม์บนอุปกรณ์พกพา คุณสมบัติที่โดดเด่นคือความสามารถในการแยกแยะวัตถุได้ภายในครั้งเดียว (เพียงแค่ดูครั้งเดียว) กล่าวคือ สถาปัตยกรรม YOLO ไม่ได้ใช้ลูป "for" ที่ชัดเจน ซึ่งช่วยให้เครือข่ายทำงานได้อย่างรวดเร็ว ยกตัวอย่างเช่น นี่คือการเปรียบเทียบ: NumPy ไม่ได้ใช้ลูป "for" ที่ชัดเจนเมื่อดำเนินการกับเมทริกซ์ แต่ลูปเหล่านี้ถูกนำไปใช้ใน NumPy ในระดับที่ต่ำกว่าของสถาปัตยกรรมผ่านภาษา C YOLO ใช้ตารางของหน้าต่างที่กำหนดไว้ล่วงหน้า เพื่อป้องกันไม่ให้วัตถุเดียวกันถูกตรวจจับซ้ำหลายครั้ง จึงใช้อัตราส่วนการทับซ้อนของหน้าต่าง (IoU) Iจุดตัด oVer Union) สถาปัตยกรรมนี้ใช้งานได้ในวงกว้างและมีความสูง :สามารถฝึกโมเดลบนรูปถ่ายได้ แต่ยังคงทำงานได้ดีกับภาพวาดที่วาดด้วยมือ
- (Sแหล่งไฟ Sฮอตมัลติบ็อกซ์ Dเครือข่ายประสาทเทียม YOLO ใช้ "แฮ็ก" ที่ประสบความสำเร็จมากที่สุดของสถาปัตยกรรม YOLO (เช่น การระงับแบบไม่สูงสุด) และเพิ่มแฮ็กใหม่เพื่อให้ทำงานได้เร็วขึ้นและแม่นยำยิ่งขึ้น จุดเด่นของเครือข่ายนี้คือความสามารถในการแยกแยะวัตถุในการประมวลผลครั้งเดียวโดยใช้ตารางหน้าต่างที่กำหนด (กล่องเริ่มต้น) บนพีระมิดภาพ พีระมิดภาพถูกเข้ารหัสในเทนเซอร์แบบคอนโวลูชันโดยใช้การดำเนินการคอนโวลูชันและพูลลิ่งแบบต่อเนื่อง (ด้วยการใช้พูลลิ่งสูงสุด มิติเชิงพื้นที่จะลดลง) ซึ่งทำให้สามารถตรวจจับวัตถุทั้งขนาดใหญ่และขนาดเล็กในการประมวลผลเครือข่ายครั้งเดียว
- โมบายSSD (โทรศัพท์มือถือเน็ตV2+ SSD) เป็นการผสมผสานสถาปัตยกรรมเครือข่ายประสาทสองแบบ เครือข่ายแรก ทำงานได้อย่างรวดเร็วและเพิ่มความแม่นยำในการจดจำ ใช้ MobileNetV2 แทน VGG-16 ซึ่งเดิมใช้ใน เครือข่าย SSD ที่สองจะกำหนดตำแหน่งของวัตถุในภาพ
- – เครือข่ายประสาทเทียมขนาดเล็กมากแต่แม่นยำ ไม่สามารถแก้ปัญหาการตรวจจับวัตถุได้ด้วยตัวเอง อย่างไรก็ตาม สามารถใช้ร่วมกับสถาปัตยกรรมต่างๆ ได้ และเหมาะสำหรับการใช้งานบนอุปกรณ์พกพา คุณสมบัติที่โดดเด่นของเครือข่ายนี้คือข้อมูลจะถูกบีบอัดเป็นตัวกรองคอนโวลูชันแบบ 1x1 จำนวนสี่ตัวก่อน จากนั้นจึงขยายเป็นตัวกรองคอนโวลูชันแบบ 1x1 จำนวนสี่ตัว และแบบ 3x3 จำนวนสี่ตัว หนึ่งในกระบวนการบีบอัดและขยายข้อมูลดังกล่าวเรียกว่า "Fire Module"
- (การแบ่งส่วนภาพเชิงความหมายด้วยเครือข่ายคอนโวลูชันเชิงลึก) – การแบ่งส่วนวัตถุในภาพ คุณสมบัติที่โดดเด่นของสถาปัตยกรรมนี้คือคอนโวลูชันแบบขยาย ซึ่งรักษาความละเอียดเชิงพื้นที่ไว้ ตามด้วยขั้นตอนการประมวลผลภายหลังโดยใช้แบบจำลองความน่าจะเป็นแบบกราฟิก (ฟิลด์สุ่มแบบมีเงื่อนไข) ซึ่งขจัดสัญญาณรบกวนเล็กน้อยในการแบ่งส่วนและปรับปรุงคุณภาพของภาพที่แบ่งส่วน เบื้องหลังชื่ออันทรงพลังอย่าง "แบบจำลองความน่าจะเป็นแบบกราฟิก" คือตัวกรองแบบเกาส์เซียนแบบง่ายที่ประมาณค่าด้วยห้าจุด
- ฉันพยายามหาอุปกรณ์ (ช็อตเดียว ปรับแต่งment เครือข่ายประสาทสำหรับวัตถุ เดชอุดมส่วน) แต่เข้าใจน้อยมาก
- ฉันยังดูวิธีการทำงานของเทคโนโลยี "ความสนใจ" ด้วย: , , คุณลักษณะที่โดดเด่นของสถาปัตยกรรม "ความสนใจ" คือการเลือกพื้นที่ที่มีความสนใจเพิ่มขึ้นโดยอัตโนมัติในภาพ (RoI Regions of Iความสนใจ) โดยใช้เครือข่ายประสาทเทียมที่เรียกว่า Attention Unit บริเวณความสนใจมีลักษณะคล้ายกับกล่องขอบเขต แต่ต่างจากกล่องขอบเขตตรงที่บริเวณความสนใจไม่ได้ถูกตรึงไว้ในภาพและอาจมีขอบเขตที่เบลอได้ จากนั้นจึงดึงคุณลักษณะต่างๆ ออกมาจากบริเวณความสนใจและป้อนเข้าสู่เครือข่ายประสาทเทียมแบบวนซ้ำที่มีสถาปัตยกรรม เครือข่ายประสาทเทียมแบบวนซ้ำสามารถวิเคราะห์ความสัมพันธ์ระหว่างคุณลักษณะต่างๆ ในลำดับได้ เดิมทีเครือข่ายประสาทเทียมแบบวนซ้ำถูกใช้เพื่อแปลข้อความเป็นภาษาอื่น และปัจจุบันใช้เพื่อการแปล и .
เมื่อเราศึกษาสถาปัตยกรรมเหล่านี้ ฉันตระหนักว่าฉันไม่เข้าใจอะไรเลยและไม่ใช่ว่าเครือข่ายประสาทของฉันมีปัญหาเกี่ยวกับกลไกการให้ความสนใจ การสร้างสถาปัตยกรรมทั้งหมดนี้ก็เหมือนกับการแฮ็กกาธอนขนาดใหญ่ ที่ผู้เขียนแข่งขันกันแฮ็ก การแฮ็กเป็นวิธีแก้ปัญหาการเขียนโปรแกรมที่ยากได้อย่างรวดเร็ว กล่าวคือ ไม่มีการเชื่อมโยงเชิงตรรกะที่มองเห็นได้หรือเข้าใจได้ระหว่างสถาปัตยกรรมเหล่านี้ สิ่งที่เชื่อมโยงสถาปัตยกรรมเหล่านี้เข้าด้วยกันคือชุดแฮ็กที่ประสบความสำเร็จสูงสุดที่พวกเขาหยิบยืมมาจากกันและกัน บวกกับเป้าหมายร่วมกันสำหรับสถาปัตยกรรมทั้งหมด (การย้อนกลับของข้อผิดพลาด) ไม่ ไม่ชัดเจนว่าต้องเปลี่ยนแปลงอะไรบ้างหรือจะเพิ่มประสิทธิภาพความสำเร็จที่มีอยู่ได้อย่างไร
เนื่องจากแฮ็กเกอร์ขาดการเชื่อมโยงเชิงตรรกะ จึงทำให้จดจำและนำไปใช้ได้ยากมาก ความรู้ของพวกเขากระจัดกระจาย อย่างน้อยที่สุดก็จำได้แค่จุดที่น่าสนใจและคาดไม่ถึงไม่กี่จุด แต่สิ่งที่เข้าใจและไม่เข้าใจส่วนใหญ่ก็หายไปภายในไม่กี่วัน คงจะดีถ้าคุณสามารถจำชื่อสถาปัตยกรรมได้ภายในหนึ่งสัปดาห์ แต่กลับต้องเสียเวลาทำงานไปหลายชั่วโมงหรือหลายวันกับการอ่านบทความและดูวิดีโอภาพรวม!
รูปที่ 2 –
ในความเห็นส่วนตัวของผม ผู้เขียนบทความวิทยาศาสตร์ส่วนใหญ่พยายามทุกวิถีทางเพื่อให้แน่ใจว่าแม้แต่ความรู้ที่กระจัดกระจายนี้ก็ยังไม่สามารถเข้าใจได้สำหรับผู้อ่าน แต่วลีกริยาวิเศษณ์แบบกริยาวิเศษณ์ในประโยคสิบบรรทัดที่มีสูตรที่ดึงขึ้นมาจากอากาศนั้น ถือเป็นหัวข้อสำหรับบทความแยกต่างหาก (ปัญหา) ).
ด้วยเหตุนี้ จึงมีความจำเป็นที่จะต้องจัดระบบข้อมูลเกี่ยวกับเครือข่ายประสาทเทียม เพื่อปรับปรุงคุณภาพความเข้าใจและการจดจำ ดังนั้น หัวข้อหลักของการวิเคราะห์เทคโนโลยีและสถาปัตยกรรมเฉพาะของเครือข่ายประสาทเทียมจึงกลายเป็นหัวข้อต่อไปนี้: ค้นหาว่าทั้งหมดนี้จะมุ่งหน้าไปทางไหนและไม่ใช่โครงสร้างของเครือข่ายประสาทใด ๆ เป็นพิเศษอย่างแยกจากกัน
ทั้งหมดนี้จะมุ่งหน้าไปทางไหน? ค้นพบที่สำคัญ:
- จำนวนการเริ่มต้นธุรกิจด้านการเรียนรู้ของเครื่องจักรในช่วงสองปีที่ผ่านมา สาเหตุที่เป็นไปได้: "เครือข่ายประสาทไม่ใช่สิ่งใหม่อีกต่อไป"
- ใครๆ ก็สามารถสร้างเครือข่ายประสาทเทียมที่ใช้งานได้จริงเพื่อแก้ปัญหาง่ายๆ ได้ โดยนำแบบจำลองสำเร็จรูปจาก "สวนสัตว์จำลอง" มาฝึกเลเยอร์สุดท้ายของเครือข่ายประสาทเทียม () บนข้อมูลสำเร็จรูปจาก หรือจาก ในฟรี .
- ผู้ผลิตเครือข่ายประสาทขนาดใหญ่เริ่มสร้าง "สวนสัตว์จำลอง" (โมเดลสวนสัตว์) ด้วยความช่วยเหลือของพวกเขา คุณสามารถสร้างแอปพลิเคชันเชิงพาณิชย์ได้อย่างรวดเร็ว: สำหรับ TensorFlow สำหรับ PyTorch สำหรับ Caffe2 สำหรับ Chainer และ .
- เครือข่ายประสาทที่ทำงานใน ตามเวลาจริง (แบบเรียลไทม์) บนอุปกรณ์เคลื่อนที่ ตั้งแต่ 10 ถึง 50 เฟรมต่อวินาที
- การประยุกต์ใช้เครือข่ายประสาทในโทรศัพท์ (TF Lite) ในเบราว์เซอร์ (TF.js) และใน (ไอโอที, Internet of Tสิ่งต่างๆ) โดยเฉพาะในโทรศัพท์ที่รองรับเครือข่ายประสาทในระดับฮาร์ดแวร์อยู่แล้ว (ตัวเร่งความเร็วประสาท)
- “อุปกรณ์ทุกชิ้น เสื้อผ้า และบางทีแม้แต่อาหารก็จะต้องมี ที่อยู่ IP-v6 และสื่อสารกัน” – .
- จำนวนสิ่งพิมพ์เกี่ยวกับการเรียนรู้ของเครื่องจักรเริ่มเพิ่มขึ้น (เพิ่มขึ้นเป็นสองเท่าทุก ๆ สองปี) ตั้งแต่ปี 2015 เป็นต้นมา เห็นได้ชัดว่าจำเป็นต้องมีเครือข่ายประสาทสำหรับการวิเคราะห์บทความ
- เทคโนโลยีต่อไปนี้กำลังได้รับความนิยม:
- ไพทอร์ช – ความนิยมกำลังเติบโตอย่างรวดเร็วและดูเหมือนว่าจะแซงหน้า TensorFlow แล้ว
- การเลือกไฮเปอร์พารามิเตอร์อัตโนมัติ ออโต้เอ็มแอล – ความนิยมก็เพิ่มขึ้นอย่างต่อเนื่อง
- ความแม่นยำลดลงอย่างค่อยเป็นค่อยไปและเพิ่มความเร็วในการคำนวณ: , อัลกอริทึม การคำนวณที่ไม่แม่นยำ (โดยประมาณ) การหาปริมาณ (เมื่อน้ำหนักของเครือข่ายประสาทถูกแปลงเป็นจำนวนเต็มและหาปริมาณ) เครื่องเร่งอนุภาคในระบบประสาท
- โอน и .
- การสร้าง ตอนนี้แบบเรียลไทม์
- กุญแจสำคัญของ DL คือข้อมูลจำนวนมาก แต่การรวบรวมและติดป้ายกำกับข้อมูลนั้นไม่ใช่เรื่องง่าย ดังนั้น ระบบติดป้ายกำกับอัตโนมัติจึงกำลังพัฒนา () สำหรับเครือข่ายประสาทโดยใช้เครือข่ายประสาท
- ด้วยเครือข่ายประสาท วิทยาการคอมพิวเตอร์จึงกลายมาเป็น วิทยาศาสตร์เชิงทดลอง และก็ลุกขึ้น .
- เงินไอทีและความนิยมของเครือข่ายประสาทเทียมเกิดขึ้นพร้อมๆ กัน เมื่อการประมวลผลกลายเป็นมูลค่าตลาด เศรษฐกิจเปลี่ยนจากเศรษฐกิจที่ใช้ทองคำเป็นสกุลเงิน การคำนวณสกุลเงินทองคำดูบทความของฉันได้ที่ และสาเหตุของการเกิดขึ้นของเงินไอที
อันใหม่ก็ค่อยๆ เกิดขึ้น (การเรียนรู้ของเครื่องจักรและการเรียนรู้เชิงลึก) ซึ่งมีพื้นฐานมาจากการนำเสนอโปรแกรมเป็นชุดของโมเดลเครือข่ายประสาทที่ได้รับการฝึกอบรม
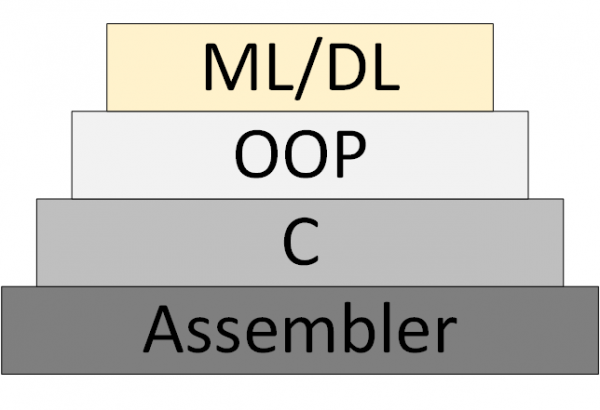
รูปที่ 3 – ML/DL เป็นวิธีการเขียนโปรแกรมแบบใหม่
อย่างไรก็ตามมันไม่เคยปรากฏ ทฤษฎีเครือข่ายประสาทซึ่งเราสามารถคิดและทำงานอย่างเป็นระบบได้ สิ่งที่ปัจจุบันเรียกว่า "ทฤษฎี" แท้จริงแล้วคืออัลกอริทึมฮิวริสติกเชิงทดลอง
ลิงค์ไปยังทรัพยากรของฉันและทรัพยากรอื่น ๆ :
- จดหมายข่าววิทยาศาสตร์ข้อมูล เน้นเรื่องการประมวลผลภาพเป็นหลัก ใครสนใจรับจดหมายข่าวนี้ติดต่อผมได้ที่ (foobar167<gaf-gaf>gmail<dot>com) ผมจะส่งลิงก์บทความและวิดีโอให้เมื่อผมรวบรวมเนื้อหาใหม่ๆ เสร็จ
- ทั่วไป ซึ่งผมผ่านแล้วและที่ผมอยากจะผ่าน
- ซึ่งคุ้มค่าแก่การเริ่มศึกษาเครือข่ายประสาท พร้อมโบรชัวร์ .
- ที่ทุกคนจะพบสิ่งที่น่าสนใจให้กับตัวเอง
- มันกลายเป็นสิ่งที่มีประโยชน์อย่างมาก ช่องวิดีโอสำหรับวิเคราะห์บทความทางวิทยาศาสตร์ วิทยาศาสตร์ข้อมูล ค้นหา ติดตาม และแชร์ลิงก์กับเพื่อนร่วมงานของคุณและผม ตัวอย่าง:
- อาคา พร้อมคำแนะนำทีละขั้นตอนและโค้ดโอเพ่นซอร์ส
ขอบคุณ!
ที่มา: will.com
