

ในบทความนี้ เราจะพูดถึงการอ้างอิงฟังก์ชันในฐานข้อมูล ว่าคืออะไร ใช้ที่ใด และมีอัลกอริทึมใดบ้างสำหรับการค้นหาการอ้างอิงเหล่านี้
เราจะพิจารณาความสัมพันธ์เชิงฟังก์ชันในบริบทของฐานข้อมูลเชิงสัมพันธ์ โดยคร่าวๆ แล้ว ในฐานข้อมูลประเภทนี้ ข้อมูลจะถูกเก็บไว้ในตาราง จากนี้ไป เราจะใช้แนวคิดโดยประมาณที่ไม่สามารถใช้แทนกันได้ในทฤษฎีเชิงสัมพันธ์อย่างเคร่งครัด เราจะเรียกตารางเองว่ารีเลชัน เรียกคอลัมน์ว่าแอตทริบิวต์ (ชุดของแอตทริบิวต์คือโครงร่างของรีเลชัน) และเรียกชุดค่าแถวบนชุดย่อยของแอตทริบิวต์ว่าทูเพิล
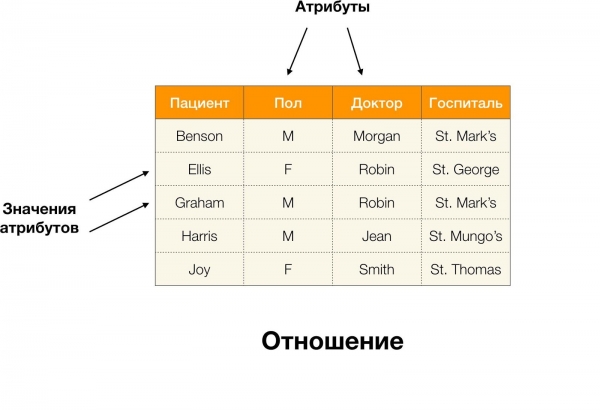
เช่นในตารางด้านบน (เบนสัน, เอ็ม, เอ็ม ออร์แกน) เป็นทูเพิลของแอตทริบิวต์ (คนไข้, พอล, คุณหมอ).
หากจะเขียนอย่างเป็นทางการกว่านี้ มีดังนี้:  [ผู้ป่วย, เพศ, แพทย์] = (เบนสัน, เอ็ม, เอ็ม ออร์แกน).
[ผู้ป่วย, เพศ, แพทย์] = (เบนสัน, เอ็ม, เอ็ม ออร์แกน).
ตอนนี้เราสามารถแนะนำแนวคิดเรื่องการพึ่งพาการทำงาน (FD):
คำจำกัดความ 1. ความสัมพันธ์ R สอดคล้องกับ FD X → Y (โดยที่ X, Y ⊆ R) ก็ต่อเมื่อสำหรับทูเพิลใดๆ  ,
,  ∈ R เป็นที่พอใจ: ถ้า
∈ R เป็นที่พอใจ: ถ้า  [X] =
[X] =  [X] แล้ว
[X] แล้ว  [Y] =
[Y] =  [Y] ในกรณีเช่นนี้ เราจะกล่าวได้ว่า X (ตัวกำหนดหรือชุดคุณลักษณะที่กำหนด) กำหนด Y (ชุดที่ขึ้นอยู่กับปัจจัยอื่น) ในเชิงฟังก์ชัน
[Y] ในกรณีเช่นนี้ เราจะกล่าวได้ว่า X (ตัวกำหนดหรือชุดคุณลักษณะที่กำหนด) กำหนด Y (ชุดที่ขึ้นอยู่กับปัจจัยอื่น) ในเชิงฟังก์ชัน
กล่าวอีกนัยหนึ่ง การมีอยู่ของกฎหมายของรัฐบาลกลาง X → Y หมายความว่าถ้าเรามีทูเพิลสองตัวใน R และมีคุณสมบัติตรงกัน Xแล้วมันจะตรงกันในคุณสมบัติ Y.
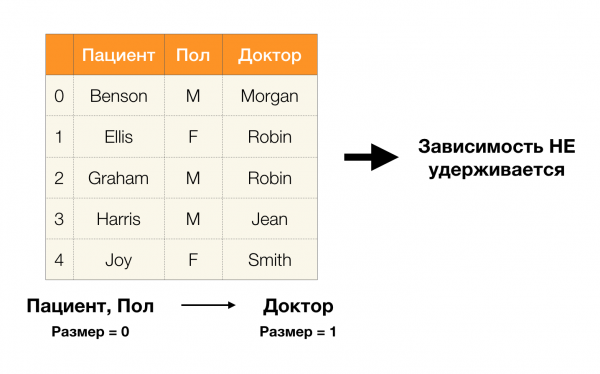
ทีนี้มาเรียงลำดับกันก่อน มาดูคุณสมบัติกัน อดทน и พอล ซึ่งเราต้องการทราบว่ามีความสัมพันธ์กันระหว่างแอตทริบิวต์เหล่านี้หรือไม่ สำหรับชุดแอตทริบิวต์ดังกล่าว อาจมีความสัมพันธ์ต่อไปนี้:
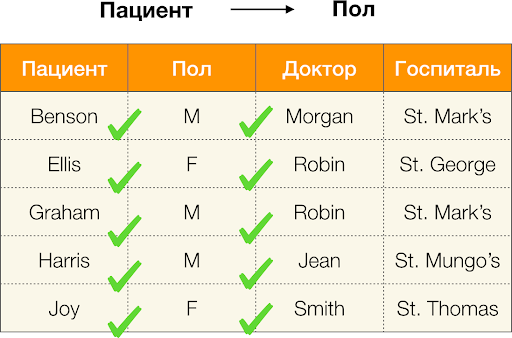
- ผู้ป่วย → เพศ
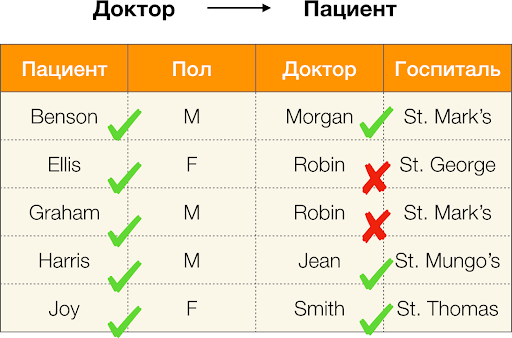
- เพศ → ผู้ป่วย
ตามคำจำกัดความข้างต้น เพื่อให้การอ้างอิงแรกสามารถคงค่าเฉพาะของคอลัมน์แต่ละคอลัมน์ได้ อดทน ต้องตรงกันเพียงค่าคอลัมน์เดียวเท่านั้น พอลและสำหรับตารางตัวอย่าง ก็เป็นกรณีนี้ อย่างไรก็ตาม มันไม่ได้ทำงานในทางกลับกัน หมายความว่าการอ้างอิงที่สองไม่เป็นไปตามข้อกำหนด และแอตทริบิวต์ พอล ไม่ใช่ตัวกำหนดสำหรับ อดทน. เช่นเดียวกัน หากเราใช้การพึ่งพา แพทย์ → คนไข้, จะเห็นได้ว่ามีการละเมิดเนื่องจากค่า นกเล็กชนิดหนึ่ง คุณลักษณะนี้มีความหมายที่แตกต่างกันหลายประการ เอลลิสและเกรแฮม.
ดังนั้น ความสัมพันธ์เชิงฟังก์ชันช่วยให้เราสามารถระบุความสัมพันธ์ที่มีอยู่ระหว่างชุดแอตทริบิวต์ของตารางได้ จากนี้ไป เราจะพิจารณาความสัมพันธ์ที่น่าสนใจที่สุด หรือพูดให้ชัดเจนกว่านั้นคือ X → Yว่าพวกเขาคือ:
- ไม่ใช่เรื่องเล็กน้อย นั่นคือ ฝั่งขวาของการพึ่งพาไม่ใช่เซตย่อยของฝั่งซ้าย (ย ̸⊆ เอ็กซ์);
- น้อยที่สุด คือ ไม่มีการพึ่งพากันเช่นนั้น Z → Yที่ Z ⊂ X.
การอ้างอิงที่กล่าวถึงมาจนถึงตอนนี้มีความเข้มงวด หมายความว่าไม่อนุญาตให้มีการละเมิดใดๆ ในตาราง อย่างไรก็ตาม ยังมีการอ้างอิงบางอย่างที่อนุญาตให้ค่าทูเพิลมีความไม่สอดคล้องกัน การอ้างอิงเหล่านี้ถูกจัดประเภทเป็นคลาสแยกต่างหาก เรียกว่า approximate และอนุญาตให้มีการละเมิดโดยทูเพิลจำนวนหนึ่ง จำนวนนี้ถูกกำหนดโดยเลขชี้กำลังความคลาดเคลื่อนสูงสุด emax ตัวอย่างเช่น อัตราความผิดพลาด  = 0.01 อาจหมายความว่าการอ้างอิงอาจถูกละเมิดโดย 1% ของทูเพิลในชุดแอตทริบิวต์ที่กำลังพิจารณา นั่นคือ สำหรับ 1000 เรคคอร์ด ทูเพิลสูงสุด 10 ทูเพิลอาจละเมิด FD เราจะพิจารณาเมตริกที่แตกต่างออกไปเล็กน้อย โดยพิจารณาจากค่าที่แตกต่างกันเป็นคู่ของทูเพิลที่เปรียบเทียบ สำหรับการอ้างอิง X → Y เกี่ยวกับทัศนคติ r คำนวณได้ดังนี้:
= 0.01 อาจหมายความว่าการอ้างอิงอาจถูกละเมิดโดย 1% ของทูเพิลในชุดแอตทริบิวต์ที่กำลังพิจารณา นั่นคือ สำหรับ 1000 เรคคอร์ด ทูเพิลสูงสุด 10 ทูเพิลอาจละเมิด FD เราจะพิจารณาเมตริกที่แตกต่างออกไปเล็กน้อย โดยพิจารณาจากค่าที่แตกต่างกันเป็นคู่ของทูเพิลที่เปรียบเทียบ สำหรับการอ้างอิง X → Y เกี่ยวกับทัศนคติ r คำนวณได้ดังนี้:

มาคำนวณหาค่าความผิดพลาดกัน แพทย์ → คนไข้ จากตัวอย่างข้างต้น เรามีทูเพิลสองตัวที่มีค่าต่างกันในแอตทริบิวต์ อดทนแต่ก็สอดคล้องกัน หมอ:  [แพทย์, คนไข้-โรบิน เอลลิส) และ
[แพทย์, คนไข้-โรบิน เอลลิส) และ  [แพทย์, คนไข้-โรบิน เกรแฮม). ตามคำจำกัดความของข้อผิดพลาด เราจะต้องคำนึงถึงคู่ที่ขัดแย้งกันทั้งหมด ซึ่งหมายความว่าจะมีอยู่สองคู่: (
[แพทย์, คนไข้-โรบิน เกรแฮม). ตามคำจำกัดความของข้อผิดพลาด เราจะต้องคำนึงถึงคู่ที่ขัดแย้งกันทั้งหมด ซึ่งหมายความว่าจะมีอยู่สองคู่: ( ,
,  ) และการผกผันของมัน (
) และการผกผันของมัน ( ,
,  ). แทนค่าลงในสูตรจะได้ดังนี้
). แทนค่าลงในสูตรจะได้ดังนี้

ทีนี้ลองมาตอบคำถามที่ว่า "ทั้งหมดนี้มีประโยชน์อะไร" กัน จริงๆ แล้ว FD มีหลายประเภท ประเภทแรกคือ dependencies ที่ผู้ดูแลระบบกำหนดไว้ในขั้นตอนการออกแบบฐานข้อมูล ซึ่งโดยปกติแล้วจะมีจำนวนน้อย เข้มงวด และส่วนใหญ่ใช้สำหรับการปรับมาตรฐานข้อมูลและการออกแบบ schema เชิงสัมพันธ์
ประเภทที่สองคือการอ้างอิงที่แสดงถึงข้อมูล "ที่ซ่อนอยู่" และความสัมพันธ์ระหว่างแอตทริบิวต์ที่ไม่เคยรู้จักมาก่อน การอ้างอิงเหล่านี้ไม่ได้ถูกพิจารณาในขั้นตอนการออกแบบ แต่ถูกค้นพบสำหรับชุดข้อมูลที่มีอยู่แล้ว ทำให้เราสามารถสรุปข้อมูลที่จัดเก็บไว้โดยอ้างอิงจากการอ้างอิงเชิงฟังก์ชันจำนวนมากที่ระบุได้ การอ้างอิงเหล่านี้คือการอ้างอิงที่เราใช้ การอ้างอิงเหล่านี้เป็นหัวข้อของสาขาหนึ่งที่เรียกว่าการทำเหมืองข้อมูล (data mining) ซึ่งมีเทคนิคการค้นหาและอัลกอริทึมที่หลากหลายที่สร้างขึ้นจากการอ้างอิงเหล่านี้ ลองมาสำรวจกันว่าการอ้างอิงเชิงฟังก์ชันที่ค้นพบ (แบบที่แน่นอนหรือแบบโดยประมาณ) ในข้อมูลใดๆ ก็ตามจะมีประโยชน์อย่างไร

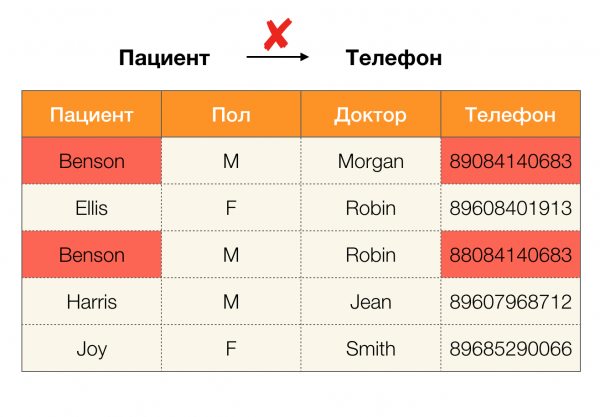
ปัจจุบัน การล้างข้อมูลเป็นหนึ่งในแอปพลิเคชันหลักของการพึ่งพา ซึ่งเกี่ยวข้องกับการพัฒนากระบวนการสำหรับการระบุและแก้ไข "ข้อมูลสกปรก" ตัวอย่างทั่วไปของ "ข้อมูลสกปรก" ได้แก่ ข้อมูลซ้ำซ้อน ข้อผิดพลาดหรือการพิมพ์ผิดของข้อมูล ค่าที่หายไป ข้อมูลที่ล้าสมัย ช่องว่างเพิ่มเติม และอื่นๆ
ตัวอย่างข้อผิดพลาดของข้อมูล:
ตัวอย่างของการซ้ำซ้อนในข้อมูล:
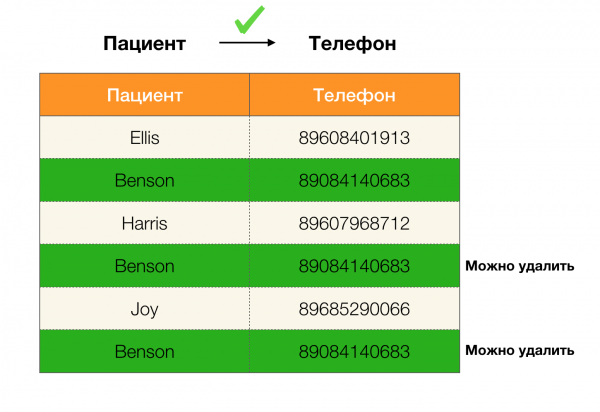
ตัวอย่างเช่น เรามีตารางและชุดข้อกำหนดตามกฎหมายที่ต้องปฏิบัติตาม การล้างข้อมูลในกรณีนี้เกี่ยวข้องกับการแก้ไขข้อมูลเพื่อให้เป็นไปตามข้อกำหนดตามกฎหมาย จำนวนการแก้ไขควรน้อยที่สุด (มีอัลกอริทึมเฉพาะสำหรับขั้นตอนนี้ ซึ่งเราจะไม่กล่าวถึงในบทความนี้) ด้านล่างนี้เป็นตัวอย่างการแปลงข้อมูลดังกล่าว ด้านซ้ายคือความสัมพันธ์ดั้งเดิม ซึ่งเห็นได้ชัดว่าไม่เป็นไปตามข้อกำหนดตามกฎหมายที่กำหนด (ตัวอย่างของการละเมิดข้อกำหนดตามกฎหมายข้อหนึ่งจะถูกเน้นด้วยสีแดง) ด้านขวาคือความสัมพันธ์ที่อัปเดต ซึ่งเซลล์สีเขียวแสดงค่าที่เปลี่ยนแปลง หลังจากขั้นตอนนี้ การอ้างอิงที่จำเป็นจะยังคงอยู่
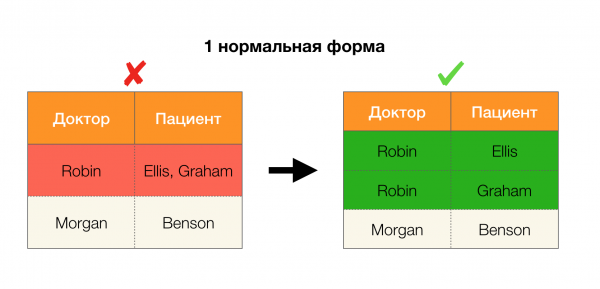
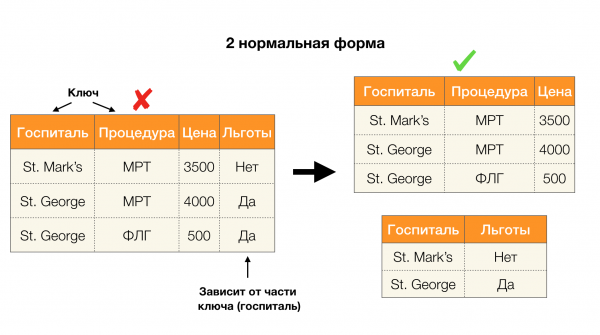
อีกหนึ่งแอปพลิเคชันยอดนิยมคือการออกแบบฐานข้อมูล ในที่นี้ เราจะกล่าวถึงฟอร์มปกติและนอร์มัลไลเซชัน นอร์มัลไลเซชันคือกระบวนการปรับความสัมพันธ์ให้สอดคล้องกับชุดข้อกำหนด ซึ่งแต่ละข้อกำหนดถูกกำหนดโดยฟอร์มปกติในแบบของตัวเอง เราจะไม่อธิบายข้อกำหนดของฟอร์มปกติต่างๆ (สามารถทำได้ในหลักสูตรฐานข้อมูลสำหรับผู้เริ่มต้น) แต่เราจะเน้นย้ำว่าแต่ละรูปแบบใช้แนวคิดของการอ้างอิงเชิงฟังก์ชันในแบบของตัวเอง เพราะโดยพื้นฐานแล้ว ฟอร์มปกติคือข้อจำกัดด้านความสมบูรณ์ที่นำมาพิจารณาในระหว่างการออกแบบฐานข้อมูล (ในบริบทนี้ ฟอร์มปกติบางครั้งเรียกว่าซูเปอร์คีย์)
ลองพิจารณาการประยุกต์ใช้กับรูปแบบปกติทั้งสี่แบบในรูปด้านล่าง จำไว้ว่ารูปแบบปกติของ Boyce-Codd มีข้อจำกัดมากกว่ารูปแบบที่สาม แต่น้อยกว่ารูปแบบที่สี่ เราจะไม่พิจารณารูปแบบที่สี่ในตอนนี้ เนื่องจากการกำหนดรูปแบบนี้จำเป็นต้องเข้าใจความสัมพันธ์แบบหลายค่า ซึ่งบทความนี้ไม่ได้สนใจ
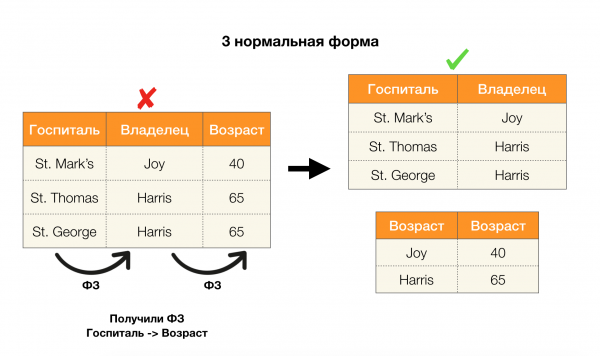
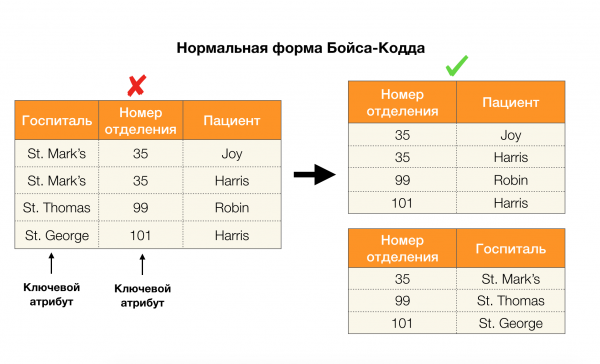
อีกประเด็นหนึ่งที่การอ้างอิงได้ถูกนำมาใช้คือการลดมิติของพื้นที่คุณลักษณะในปัญหาต่างๆ เช่น การสร้างตัวจำแนกประเภทเบย์แบบง่าย การสกัดคุณลักษณะสำคัญ และการกำหนดพารามิเตอร์ใหม่ให้กับแบบจำลองการถดถอย ในบทความต้นฉบับ ปัญหานี้เรียกว่าความซ้ำซ้อนของคุณลักษณะและความเกี่ยวข้องของคุณลักษณะ [5, 6] และได้รับการแก้ไขด้วยการใช้แนวคิดฐานข้อมูลอย่างกว้างขวาง จากการเกิดขึ้นของผลงานเหล่านี้ เราสามารถสรุปได้ว่ามีความต้องการโซลูชันที่รวมฐานข้อมูล การวิเคราะห์ และการนำปัญหาการหาค่าเหมาะที่สุดที่กล่าวถึงข้างต้นมาใช้งานเป็นเครื่องมือเดียวเพิ่มมากขึ้น [7, 8, 9]
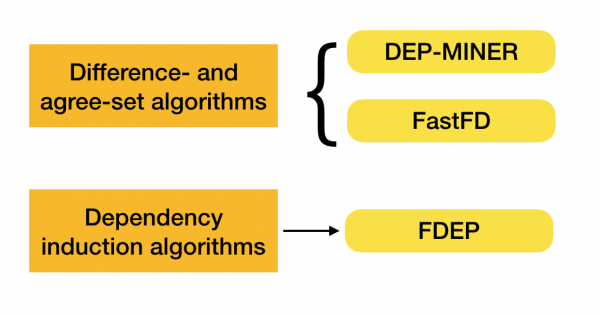
มีอัลกอริทึมมากมาย (ทั้งแบบสมัยใหม่และแบบเก่า) สำหรับการค้นหากฎหมายของรัฐบาลกลางในชุดข้อมูล อัลกอริทึมเหล่านี้สามารถแบ่งออกเป็นสามกลุ่ม:
- อัลกอริทึมการท่องผ่านแลตทิซ
- อัลกอริทึมชุดความแตกต่างและชุดความเห็นพ้อง
- อัลกอริทึมการเหนี่ยวนำการพึ่งพา
ตารางด้านล่างนี้แสดงคำอธิบายสั้นๆ ของอัลกอริทึมแต่ละประเภท:
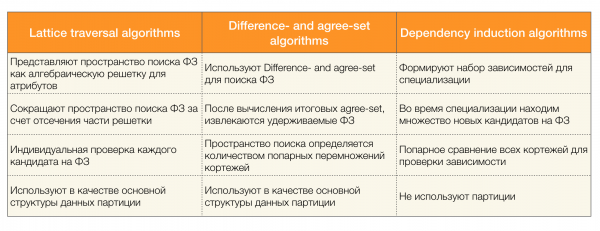
รายละเอียดเพิ่มเติมเกี่ยวกับการจำแนกประเภทนี้สามารถดูได้ใน [4] ตัวอย่างอัลกอริทึมสำหรับแต่ละประเภทแสดงไว้ด้านล่าง:
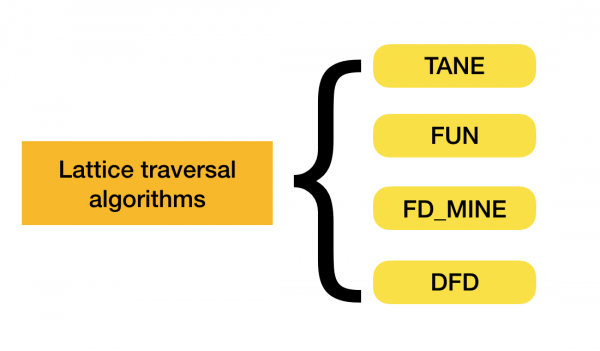
ปัจจุบันมีอัลกอริทึมใหม่ๆ เกิดขึ้น ซึ่งรวมวิธีการต่างๆ เข้าด้วยกันเพื่อค้นหาความสัมพันธ์เชิงฟังก์ชัน ตัวอย่างของอัลกอริทึมเหล่านี้ ได้แก่ Pyro [2] และ HyFD [3] คาดว่าจะมีการวิเคราะห์การทำงานของอัลกอริทึมเหล่านี้ในบทความถัดไปในชุดบทความนี้ ในบทความนี้ เราจะกล่าวถึงเฉพาะแนวคิดพื้นฐานและเล็มมาที่จำเป็นสำหรับการทำความเข้าใจเทคนิคการตรวจจับความสัมพันธ์เชิงฟังก์ชันเท่านั้น
เรามาเริ่มต้นด้วยสิ่งที่ง่ายที่สุด: เซตความแตกต่างและเซตที่เห็นด้วย ซึ่งใช้ในอัลกอริทึมประเภทที่สอง เซตความแตกต่างคือเซตของทูเพิลที่มีค่าไม่เท่ากัน ในขณะที่เซตที่เห็นด้วยคือเซตของทูเพิลที่มีค่าเท่ากัน สิ่งสำคัญที่ควรทราบคือในกรณีนี้ เราจะพิจารณาเฉพาะด้านซ้ายของการอ้างอิงเท่านั้น
แนวคิดสำคัญอีกประการหนึ่งที่กล่าวถึงข้างต้นคือแลตทิซเชิงพีชคณิต เนื่องจากอัลกอริทึมสมัยใหม่จำนวนมากอาศัยแนวคิดนี้ เราจึงจำเป็นต้องเข้าใจว่ามันคืออะไร
เพื่อที่จะแนะนำแนวคิดของแลตทิซ จำเป็นต้องมีคำจำกัดความของเซตที่มีการเรียงลำดับบางส่วน (หรือเรียกสั้นๆ ว่า โพเซ็ต)
คำจำกัดความ 2. เซต S จะถูกกล่าวว่ามีการเรียงลำดับบางส่วนโดยความสัมพันธ์แบบไบนารี ⩽ ถ้าสำหรับทุก ๆ a, b, c ∈ S คุณสมบัติต่อไปนี้เป็นจริง:
- การสะท้อนกลับ คือ ⩽ a
- ความไม่สมมาตร นั่นคือ ถ้า a ⩽ b และ b ⩽ a แล้ว a = b
- ความสัมพันธ์แบบสกรรมกริยา กล่าวคือ สำหรับ ⩽ b และ b ⩽ c จะได้ว่า a ⩽ c
ความสัมพันธ์ดังกล่าวเรียกว่า ลำดับย่อย (แบบไม่เข้มงวด) และเซตนี้เองเรียกว่า เซตที่มีลำดับบางส่วน สัญกรณ์เชิงรูปนัย: ⟨S, ⩽⟩
ตัวอย่างง่ายๆ ของเซตที่มีอันดับบางส่วน คือ เซตของจำนวนธรรมชาติ N ทั้งหมดที่มีความสัมพันธ์อันดับปกติ ⩽ การตรวจสอบว่าสัจพจน์ที่จำเป็นทั้งหมดเป็นจริงนั้นทำได้ง่าย
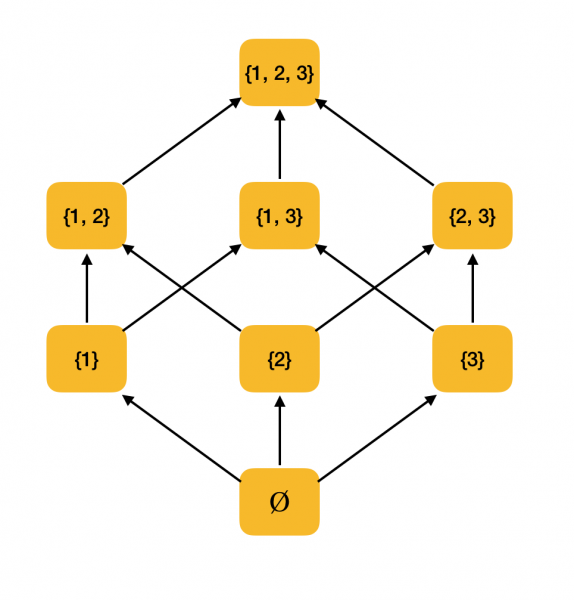
ตัวอย่างที่เป็นรูปธรรมยิ่งขึ้น ลองพิจารณาเซตของเซตย่อยทั้งหมดของ {1, 2, 3} ซึ่งเรียงลำดับตามความสัมพันธ์อินคลูชัน ⊆ อันที่จริง ความสัมพันธ์นี้เป็นไปตามเงื่อนไขทั้งหมดของลำดับย่อย ดังนั้น ⟨P({1, 2, 3}), ⊆⟩ จึงเป็นเซตที่มีลำดับย่อย รูปด้านล่างแสดงโครงสร้างของเซตนี้: หากสามารถเข้าถึงสมาชิกหนึ่งจากสมาชิกอื่นได้โดยการตามลูกศร แสดงว่าสมาชิกเหล่านั้นอยู่ในความสัมพันธ์แบบมีลำดับ
เราจะต้องมีคำจำกัดความง่ายๆ อีกสองคำจากสาขาคณิตศาสตร์: นิยามสูงสุดและนิยามต่ำสุด
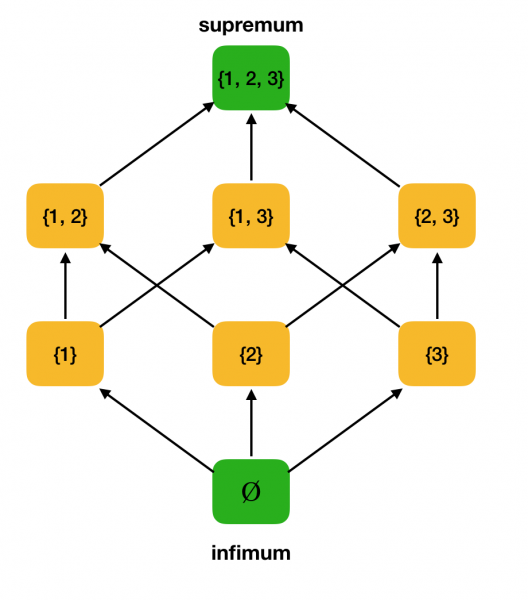
คำจำกัดความ 3. ให้ ⟨S, ⩽⟩ เป็นเซตที่มีอันดับบางส่วน A ⊆ S ขอบเขตบนของ A คือสมาชิก u ∈ S โดยที่ ∀x ∈ S: x ⩽ u ให้ U เป็นเซตของขอบเขตบนทั้งหมดของ S ถ้า U มีสมาชิกที่น้อยที่สุด จะเรียกว่าเซตสูงสุด และแสดงด้วยเซตสูงสุด A
แนวคิดเรื่องขอบเขตล่างที่แน่นอนได้รับการแนะนำในลักษณะเดียวกัน
คำจำกัดความ 4. ให้ ⟨S, ⩽⟩ เป็นเซตที่มีลำดับบางส่วน A ⊆ S ขอบเขตล่างของ A คือสมาชิก l ∈ S โดยที่ ∀x ∈ S: l ⩽ x ให้ L เป็นเซตของขอบเขตล่างทั้งหมดของ S ถ้า L มีสมาชิกที่มากที่สุด จะเรียกว่า infimum และแสดงด้วย inf A
ให้เราพิจารณาเซตที่เรียงลำดับบางส่วน ⟨P ({1, 2, 3}), ⊆⟩ ที่กำหนดไว้ข้างต้นเป็นตัวอย่าง และหาค่าสูงสุดและค่าต่ำสุดในเซตนั้น:
ตอนนี้เราสามารถกำหนดนิยามของโครงตาข่ายพีชคณิตได้
คำจำกัดความ 5. ให้ ⟨P, ⩽⟩ เป็นเซตอันดับบางส่วน โดยที่เซตย่อยสองสมาชิกทุกเซตมีขอบเขตบนและขอบเขตล่างน้อยที่สุด ดังนั้น P จะถูกเรียกว่าแลตทิซพีชคณิต ในกรณีนี้ sup{x, y} เขียนเป็น x ∨ y และ inf {x, y} เขียนเป็น x ∧ y
ลองตรวจสอบว่าตัวอย่างที่เราทำงาน ⟨P({1, 2, 3}), ⊆⟩ เป็นแลตทิซ แท้จริงแล้ว สำหรับทุก a, b ∈ P({1, 2, 3}) a ∨ b = a ∪ b และ a ∧ b = a ∩ b ยกตัวอย่างเช่น พิจารณาเซต {1, 2} และ {1, 3} และหาค่าต่ำสุดและค่าสูงสุด หากตัดกัน เราจะได้เซต {1} ซึ่งเป็นค่าต่ำสุด ค่าสูงสุดหาได้จากการรวมของเซตเหล่านี้: {1, 2, 3}
ในอัลกอริทึมสำหรับการตรวจจับ FD พื้นที่การค้นหาจะแสดงในรูปแบบของแลตทิซ โดยที่ชุดขององค์ประกอบหนึ่งองค์ประกอบ (อ่านระดับแรกของแลตทิซการค้นหา โดยที่ด้านซ้ายของการอ้างอิงประกอบด้วยแอตทริบิวต์หนึ่งรายการ) แสดงถึงแอตทริบิวต์แต่ละรายการของความสัมพันธ์ดั้งเดิม
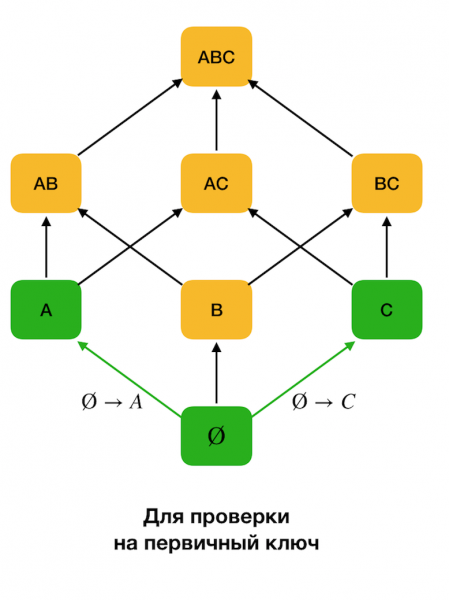
ในตอนเริ่มต้น การอ้างอิงของชนิด ∅ → จะถูกพิจารณา คุณสมบัติเดี่ยว ขั้นตอนนี้ช่วยให้เรากำหนดได้ว่าแอตทริบิวต์ใดเป็นคีย์หลัก (ไม่มีตัวกำหนดสำหรับแอตทริบิวต์ดังกล่าว ดังนั้นด้านซ้ายมือจึงว่างเปล่า) จากนั้นอัลกอริทึมเหล่านี้จะเลื่อนขึ้นไปตามแลตทิซ สิ่งสำคัญคือสามารถเคลื่อนที่ผ่านแลตทิซทั้งหมดได้ ซึ่งหมายความว่าหากส่งขนาดสูงสุดที่ต้องการของด้านซ้ายมือเป็นอินพุต อัลกอริทึมจะไม่ดำเนินการเกินระดับที่มีขนาดนั้น
รูปด้านล่างแสดงวิธีการใช้แลตทิซพีชคณิตในโจทย์การหา FD โดยแต่ละขอบ (เอ็กซ์, เอวาย) เป็นสิ่งที่ต้องพึ่งพา X → Yเช่นเราผ่านระดับแรกไปแล้วและรู้ว่าความเสพติดยังคงอยู่ ก → บี (เราจะแสดงสิ่งนี้เป็นการเชื่อมต่อสีเขียวระหว่างจุดยอด A и B). ซึ่งหมายความว่ายิ่งไปกว่านั้นเมื่อเราเลื่อนขึ้นไปบนกริด เราไม่สามารถตรวจสอบความสัมพันธ์ได้ ก, ค → ขเพราะมันจะไม่น้อยที่สุดอีกต่อไป เช่นเดียวกัน เราจะไม่ตรวจสอบมันหากการพึ่งพานั้นยังคงอยู่ ซี → บี.
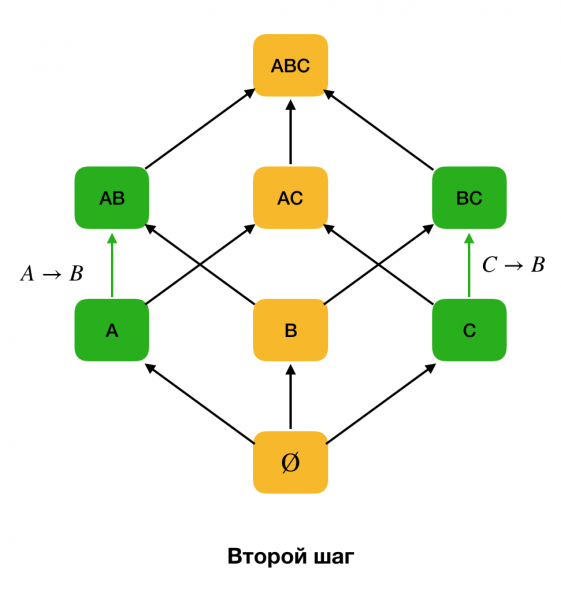
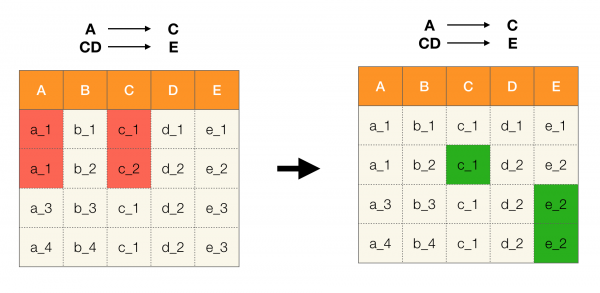
ยิ่งไปกว่านั้น ตามกฎแล้ว อัลกอริทึมสมัยใหม่ทั้งหมดสำหรับการค้นหากฎหมายของรัฐบาลกลางจะใช้โครงสร้างข้อมูลที่เรียกว่า พาร์ติชั่น (ในต้นฉบับคือ พาร์ติชั่นแบบสตริป [1]) นิยามอย่างเป็นทางการของพาร์ติชั่นมีดังนี้:
คำจำกัดความ 6. ให้ X ⊆ R เป็นชุดของแอตทริบิวต์สำหรับความสัมพันธ์ r คลัสเตอร์คือชุดของดัชนีของทูเพิลใน r ที่มีค่า X เท่ากัน นั่นคือ c(t) = {i|ti[X] = t[X]} พาร์ติชันคือชุดของคลัสเตอร์ที่ไม่รวมคลัสเตอร์ที่มีความยาวหนึ่ง:

พูดแบบง่ายๆ ก็คือการแบ่งพาร์ติชั่นสำหรับแอตทริบิวต์ X คือชุดรายการ โดยแต่ละรายการจะมีจำนวนแถวที่มีค่าเท่ากัน Xในวรรณกรรมสมัยใหม่ โครงสร้างที่แสดงถึงพาร์ติชันเรียกว่าดัชนีรายการตำแหน่ง (PLI) คลัสเตอร์ที่มีความยาวหนึ่งจะถูกแยกออกเพื่อวัตถุประสงค์ในการบีบอัดข้อมูลแบบ PLI เนื่องจากคลัสเตอร์เหล่านี้มีเพียงหมายเลขเรกคอร์ดที่มีค่าเฉพาะตัวซึ่งสามารถระบุได้ง่ายเสมอ
มาดูตัวอย่างกัน ลองกลับไปที่ตารางเดิมที่มีผู้ป่วย แล้วสร้างพาร์ติชันสำหรับคอลัมน์ต่างๆ อดทน и พอล (คอลัมน์ใหม่ปรากฏทางด้านซ้ายซึ่งมีการทำเครื่องหมายหมายเลขแถวตารางไว้):
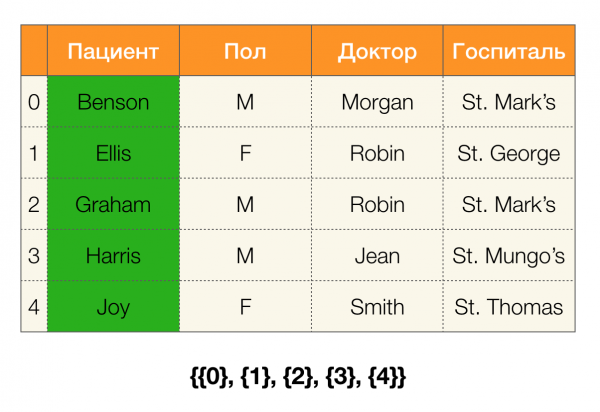
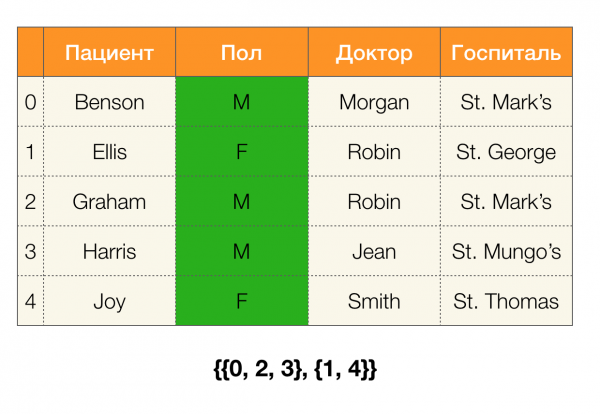
ในกรณีนี้ ตามคำจำกัดความ พาร์ติชั่นสำหรับคอลัมน์ อดทน จะว่างเปล่าจริงๆ เนื่องจากคลัสเตอร์เดี่ยวๆ จะถูกแยกออกจากพาร์ติชัน
พาร์ติชันสามารถหาได้จากแอตทริบิวต์หลายรายการ มีสองวิธีในการทำเช่นนี้ คือ การวนซ้ำในตาราง การสร้างพาร์ติชันโดยใช้แอตทริบิวต์ที่จำเป็นทั้งหมดพร้อมกัน หรือการแบ่งพาร์ติชันโดยใช้แอตทริบิวต์ชุดย่อย อัลกอริทึมการค้นหากฎหมายของรัฐบาลกลางใช้ตัวเลือกที่สอง
พูดแบบง่ายๆ ก็คือ การแบ่งพาร์ติชันตามคอลัมน์ เอบีซี, คุณสามารถแบ่งพาร์ติชั่นได้ AC и B (หรือชุดย่อยที่แยกจากกันชุดอื่นๆ) และตัดกัน การดำเนินการตัดกันของพาร์ติชันสองพาร์ติชันจะระบุคลัสเตอร์ที่ยาวที่สุดที่เหมือนกันในพาร์ติชันทั้งสอง
มาดูตัวอย่างกัน:
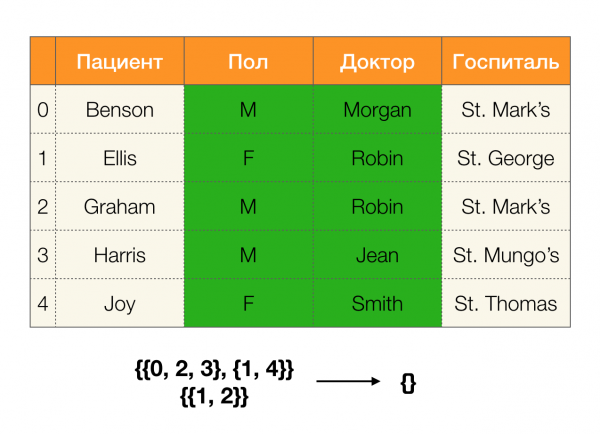

ในกรณีแรก เราได้พาร์ติชันว่าง หากดูตารางอย่างใกล้ชิด คุณจะเห็นว่าไม่มีค่าที่เหมือนกันสำหรับแอตทริบิวต์ทั้งสอง อย่างไรก็ตาม หากเราแก้ไขตารางเล็กน้อย (กรณีทางด้านขวา) เราจะได้อินเตอร์เซกชันที่ไม่ว่าง นอกจากนี้ แถวที่ 1 และ 2 ยังมีค่าแอตทริบิวต์ที่เหมือนกันอีกด้วย พอล и คุณหมอ.
ต่อไปเราจะต้องทำความเข้าใจเกี่ยวกับขนาดพาร์ติชัน อย่างเป็นทางการ:

หากพูดอย่างง่ายๆ ก็คือ ขนาดพาร์ติชันคือจำนวนคลัสเตอร์ที่รวมอยู่ในพาร์ติชัน (โปรดจำไว้ว่าคลัสเตอร์เดี่ยวจะไม่รวมอยู่ในพาร์ติชัน!)
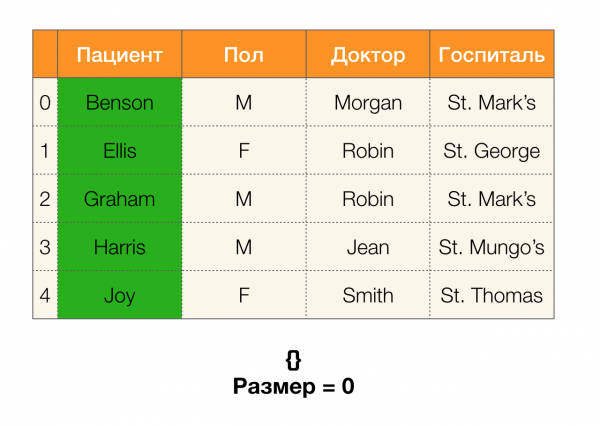
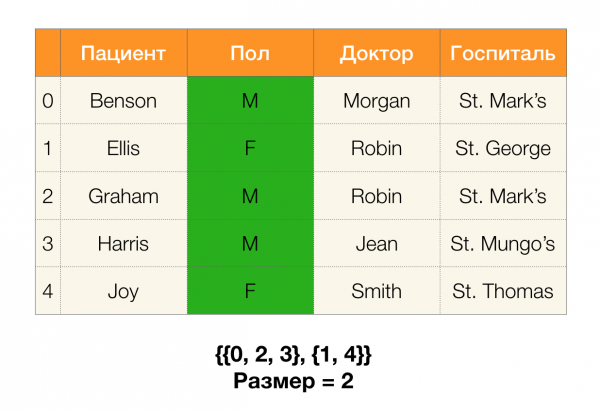
ตอนนี้เราสามารถกำหนดเล็มมาสำคัญตัวหนึ่งได้ ซึ่งช่วยให้เราสามารถกำหนดได้ว่าพาร์ติชันที่กำหนดนั้นมีการอ้างอิงอยู่หรือไม่:
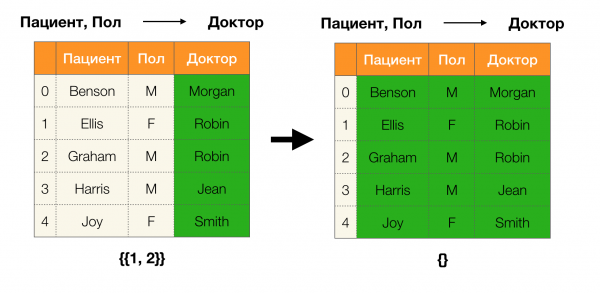
เล็มมา 1ความสัมพันธ์ A, B → C จะเกิดขึ้นได้ก็ต่อเมื่อ

ตามเล็มมา หากต้องการตรวจสอบว่าการอ้างอิงถือครองหรือไม่ จะต้องดำเนินการสี่ขั้นตอนดังต่อไปนี้:
- คำนวณพาร์ติชั่นสำหรับด้านซ้ายของการอ้างอิง
- คำนวณพาร์ติชั่นสำหรับด้านขวาของการอ้างอิง
- คำนวณผลคูณของขั้นตอนที่หนึ่งและขั้นตอนที่สอง
- เปรียบเทียบขนาดของพาร์ติชั่นที่ได้ในขั้นตอนแรกและขั้นตอนที่สาม
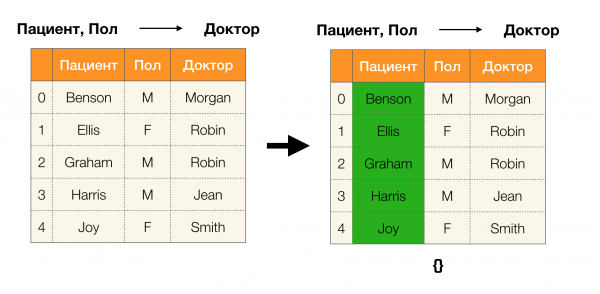
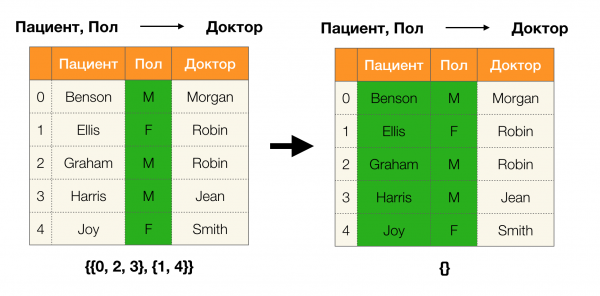
ด้านล่างนี้เป็นตัวอย่างการตรวจสอบว่าความสัมพันธ์เป็นไปตามเล็มมาที่กำหนดหรือไม่:
ในบทความนี้ เราได้พิจารณาแนวคิดต่างๆ เช่น การพึ่งพาเชิงฟังก์ชันและการพึ่งพาเชิงฟังก์ชันโดยประมาณ อภิปรายการประยุกต์ใช้ และอภิปรายอัลกอริทึมที่มีอยู่สำหรับการค้นหาการพึ่งพาเชิงฟังก์ชัน นอกจากนี้ เรายังครอบคลุมแนวคิดพื้นฐานที่สำคัญและใช้งานอยู่ในปัจจุบันสำหรับการค้นหาการพึ่งพาเชิงฟังก์ชันอย่างละเอียด
อ้างอิง:
- Huhtala Y. et al. TANE: อัลกอริทึมที่มีประสิทธิภาพสำหรับการค้นพบความสัมพันธ์เชิงฟังก์ชันและเชิงประมาณ //The computer journal. – 1999. – T. 42. – No. 2. – pp. 100-111.
- Kruse S., Naumann F. การค้นพบความสัมพันธ์โดยประมาณที่มีประสิทธิภาพ // การดำเนินการของมูลนิธิ VLDB – 2018 – T. 11. – ฉบับที่ 7. – หน้า 759-772
- Papenbrock T., Naumann F. แนวทางไฮบริดในการค้นพบการอ้างอิงเชิงฟังก์ชัน // การดำเนินการของการประชุมนานาชาติเรื่องการจัดการข้อมูลปี 2016 – ACM, 2016 – หน้า 821-833
- Papenbrock T. และคณะ การค้นพบการพึ่งพาฟังก์ชัน: การประเมินเชิงทดลองของอัลกอริทึมทั้งเจ็ด // รายงานการประชุมของมูลนิธิ VLDB – 2015. – T. 8. – ฉบับที่ 10. – หน้า 1082-1093
- Kumar A. และคณะ จะเข้าร่วมหรือไม่เข้าร่วม?: คิดให้ดีก่อนเลือกฟีเจอร์การรวมข้อมูล // รายงานการประชุมนานาชาติเรื่องการจัดการข้อมูลปี 2016 – ACM, 2016 – หน้า 19-34
- Abo Khamis M. และคณะ การเรียนรู้ภายในฐานข้อมูลด้วยเทนเซอร์แบบเบาบาง // รายงานการประชุมวิชาการ ACM SIGMOD-SIGACT-SIGAI ครั้งที่ 37 เรื่องหลักการของระบบฐานข้อมูล – ACM, 2018. – หน้า 325-340
- Hellerstein JM และคณะ ไลบรารีการวิเคราะห์ MADlib: หรือทักษะ MAD, SQL //Proceedings of the VLDB Endowment. – 2012. – T. 5. – ฉบับที่ 12. – หน้า 1700-1711.
- Qin C., Rusu F. การประมาณค่าเชิงเก็งกำไรสำหรับการเพิ่มประสิทธิภาพการลดระดับความชันแบบกระจายในระดับเทราสเกล // การดำเนินการของการประชุมเชิงปฏิบัติการครั้งที่สี่เกี่ยวกับการวิเคราะห์ข้อมูลบนคลาวด์ – ACM, 2015. – หน้า 1
- Meng X. et al. Mllib: การเรียนรู้ของเครื่องใน Apache Spark // วารสารวิจัยการเรียนรู้ของเครื่อง – 2016. – T. 17. – ฉบับที่ 1. – หน้า 1235-1241.
ผู้เขียนบทความ: , นักวิจัยใน , и , นักวิจัยใน
ที่มา: will.com
