

Not. tercüme: Avrupalı Adevinta şirketinde Baş Yazılım Mühendisi olarak görev yapan Galo Navarro tarafından yazılan bu makale, altyapı operasyonları alanında büyüleyici ve öğretici bir “araştırma”dır. Orijinal başlığı, yazarın en başta açıkladığı bir nedenden dolayı çeviri sırasında biraz genişletildi.
Yazardan not: Bu yazıya benziyor beklenenden çok daha fazla ilgi gördü. Yazının başlığının yanıltıcı olduğu ve bazı okurların üzüldüğü yönünde hâlâ kızgın yorumlar alıyorum. Olanların nedenlerini anlıyorum, bu nedenle tüm entrikayı mahvetme riskine rağmen size bu makalenin neyle ilgili olduğunu hemen anlatmak istiyorum. Ekipler Kubernetes'e geçerken gördüğüm ilginç şey, ne zaman bir sorun ortaya çıksa (geçişten sonra gecikme süresinin artması gibi), suçlanan ilk şeyin Kubernetes olması, ancak daha sonra orkestratörün gerçekten de bunu yapmadığı ortaya çıkıyor. suçlamak. Bu makale böyle bir durumu anlatıyor. Adı, geliştiricilerimizden birinin ünlemini tekrarlıyor (daha sonra Kubernetes'in bununla hiçbir ilgisi olmadığını göreceksiniz). Burada Kubernetes hakkında şaşırtıcı açıklamalar bulamazsınız ancak karmaşık sistemler hakkında birkaç iyi ders bekleyebilirsiniz.
Birkaç hafta önce ekibim tek bir mikro hizmeti, Kubernetes tabanlı bir çalışma zamanı, ölçümler ve diğer özellikleri içeren CI/CD'yi içeren çekirdek bir platforma taşıyordu. Bu taşınma deneme niteliğindeydi; bunu esas almayı ve önümüzdeki aylarda yaklaşık 150 hizmetin daha transferini planladık. Hepsi İspanya'daki en büyük çevrimiçi platformlardan bazılarının (Infojobs, Fotocasa, vb.) işletilmesinden sorumludur.
Uygulamayı Kubernetes'e dağıtıp trafiğin bir kısmını ona yönlendirdikten sonra bizi endişe verici bir sürpriz bekliyordu. Gecikme (Gecikme) Kubernetes'teki talepler EC10'ye göre 2 kat daha fazlaydı. Genel olarak, ya bu soruna bir çözüm bulmak ya da mikro hizmetin (ve muhtemelen tüm projenin) geçişinden vazgeçmek gerekiyordu.
Kubernetes'te gecikme neden EC2'ye göre çok daha yüksek?
Darboğazı bulmak için istek yolunun tamamı boyunca metrikler topladık. Mimarimiz basittir: Bir API ağ geçidi (Zuul), EC2 veya Kubernetes'teki mikro hizmet örneklerine istekleri proxy olarak gönderir. Kubernetes'te NGINX Giriş Denetleyicisi kullanıyoruz ve arka uçlar aşağıdaki gibi sıradan nesnelerdir Spring platformunda bir JVM uygulamasıyla.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Sorun, arka uçtaki başlangıçtaki gecikmeyle ilgili gibi görünüyordu (grafikteki sorun alanını "xx" olarak işaretledim). EC2'de uygulamanın yanıtı yaklaşık 20 ms sürdü. Kubernetes'te gecikme 100-200 ms'ye çıktı.
Çalışma zamanı değişikliğiyle ilgili olası şüphelileri hızla reddettik. JVM sürümü aynı kalır. Konteynerleştirme sorunlarının da bununla hiçbir ilgisi yoktu: uygulama zaten EC2'deki konteynerlerde başarıyla çalışıyordu. Yükleniyor? Ancak saniyede 1 istekte bile yüksek gecikmeler gözlemledik. Çöp toplamaya yönelik duraklamalar da ihmal edilebilir.
Kubernetes yöneticilerimizden biri, DNS sorgularının geçmişte benzer sorunlara yol açması nedeniyle uygulamanın harici bağımlılıkları olup olmadığını merak etti.
Hipotez 1: DNS adı çözümlemesi
Her istek için uygulamamız aşağıdaki gibi bir etki alanındaki bir AWS Elasticsearch örneğine bir ila üç kez erişir elastic.spain.adevinta.com. Konteynerlerimizin içinde , böylece bir alan adını aramanın gerçekten uzun zaman alıp almadığını kontrol edebiliriz.
Kapsayıcıdan DNS sorguları:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecUygulamanın çalıştığı EC2 bulut sunucularından birinden gelen benzer istekler:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecAramanın yaklaşık 30 ms sürdüğü göz önüne alındığında, Elasticsearch'e erişirken DNS çözümlemesinin gerçekten de gecikme artışına katkıda bulunduğu ortaya çıktı.
Ancak bu iki nedenden dolayı garipti:
- Zaten yüksek gecikme sorunu yaşamadan AWS kaynaklarıyla etkileşim kuran tonlarca Kubernetes uygulamamız var. Sebep ne olursa olsun, özellikle bu davayla ilgilidir.
- JVM'nin bellek içi DNS önbelleğe alma işlemini yaptığını biliyoruz. Görsellerimizde TTL değeri yazmaktadır.
$JAVA_HOME/jre/lib/security/java.securityve 10 saniyeye ayarlayın:networkaddress.cache.ttl = 10. Başka bir deyişle, JVM'nin tüm DNS sorgularını 10 saniye boyunca önbelleğe alması gerekir.
İlk hipotezi doğrulamak için DNS'yi aramayı bir süreliğine durdurmaya ve sorunun çözülüp çözülmediğine bakmaya karar verdik. Öncelikle uygulamayı, bir alan adı yerine, Elasticsearch ile doğrudan IP adresiyle iletişim kuracak şekilde yeniden yapılandırmaya karar verdik. Bu, kod değişiklikleri ve yeni bir dağıtım gerektireceğinden, etki alanını basitçe IP adresiyle eşledik. /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comArtık konteyner neredeyse anında bir IP aldı. Bu, bir miktar iyileşme sağladı ancak beklenen gecikme seviyelerine yalnızca biraz yaklaşabildik. Her ne kadar DNS çözümlemesi uzun sürse de gerçek neden hâlâ elimizde değildi.
Ağ üzerinden teşhis
Konteynerden gelen trafiği kullanarak analiz etmeye karar verdik. tcpdumpağda tam olarak neler olduğunu görmek için:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Daha sonra birkaç istek gönderdik ve bunların yakalamalarını indirdik (kubectl cp my-service:/capture.pcap capture.pcap) daha fazla analiz için .
DNS sorgularında şüphe uyandıran hiçbir şey yoktu (daha sonra bahsedeceğim küçük bir şey dışında). Ancak hizmetimizin her isteği ele alma biçiminde bazı tuhaflıklar vardı. Aşağıda, yanıt başlamadan önce isteğin kabul edildiğini gösteren yakalamanın ekran görüntüsü bulunmaktadır:
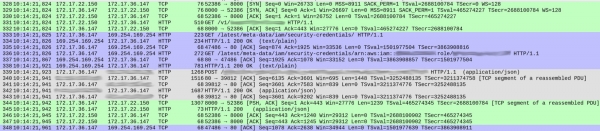
Paket numaraları ilk sütunda gösterilmektedir. Açıklık sağlamak için farklı TCP akışlarını renk kodlu hale getirdim.
328 numaralı paketle başlayan yeşil akış, istemcinin (172.17.22.150) konteynere (172.17.36.147) nasıl TCP bağlantısı kurduğunu gösterir. İlk el sıkışmanın ardından (328-330) 331 numaralı paket getirildi HTTP GET /v1/.. — hizmetimize gelen bir istek. Tüm süreç 1 ms sürdü.
Gri akış (339 numaralı paketten), hizmetimizin Elasticsearch örneğine bir HTTP isteği gönderdiğini gösterir (mevcut bir bağlantıyı kullandığından TCP anlaşması yoktur). Bu 18 ms sürdü.
Şu ana kadar her şey yolunda ve süreler kabaca beklenen gecikmelere karşılık geliyor (istemciden ölçüldüğünde 20-30 ms).
Ancak mavi bölüm 86ms sürüyor. İçinde neler oluyor? 333 numaralı paketle hizmetimiz şu adrese bir HTTP GET isteği gönderdi: /latest/meta-data/iam/security-credentialsve hemen ardından aynı TCP bağlantısı üzerinden başka bir GET isteği /latest/meta-data/iam/security-credentials/arn:...
Bunun izleme boyunca her istekte tekrarlandığını gördük. Konteynerlerimizde DNS çözünürlüğü gerçekten biraz daha yavaştır (bu olgunun açıklaması oldukça ilginç, ancak bunu ayrı bir makaleye saklayacağım). Uzun gecikmelerin nedeninin, her istekte AWS Bulut Sunucusu Meta Veri hizmetine yapılan çağrılar olduğu ortaya çıktı.
Hipotez 2: AWS'ye gereksiz çağrılar
Her iki uç nokta da aittir . Mikro hizmetimiz Elasticsearch'ü çalıştırırken bu hizmeti kullanır. Her iki çağrı da temel yetkilendirme sürecinin bir parçasıdır. İlk istekte erişilen uç nokta, örnekle ilişkili IAM rolünü yayınlar.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleİkinci istek, ikinci uç noktadan bu örnek için geçici izinler ister:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Müşteri bunları kısa bir süre için kullanabilir ve periyodik olarak yeni sertifikalar (alınmadan önce) almalıdır. Expiration). Model basittir: AWS, güvenlik nedeniyle geçici anahtarları sık sık döndürür, ancak istemciler, yeni sertifika almanın getirdiği performans düşüşünü telafi etmek için bunları birkaç dakika önbelleğe alabilir.
AWS Java SDK'nın bu süreci organize etme sorumluluğunu üstlenmesi gerekir ancak bazı nedenlerden dolayı bu gerçekleşmez.
GitHub'da sorunları araştırdıktan sonra bir sorunla karşılaştık . Hangi yöne daha fazla “kazacağımızı” belirlememize yardımcı oldu.
AWS SDK, aşağıdaki koşullardan biri meydana geldiğinde sertifikaları günceller:
- Son kullanma tarihi (
Expiration) İçine düşmekEXPIRATION_THRESHOLD, 15 dakikaya sabit kodlanmıştır. - Sertifikaları yenilemeye yönelik son denemeden bu yana daha fazla zaman geçti
REFRESH_THRESHOLD60 dakika boyunca sabit kodlanmıştır.
Aldığımız sertifikaların gerçek son kullanma tarihini görmek için yukarıdaki cURL komutlarını hem konteynerden hem de EC2 örneğinden çalıştırdık. Konteynerden alınan sertifikanın geçerlilik süresi çok daha kısa çıktı: Tam 15 dakika.
Artık her şey netleşti: İlk talep için hizmetimiz geçici sertifikalar aldı. 15 dakikadan uzun süre geçerli olmadıkları için AWS SDK, sonraki bir istek üzerine bunları güncellemeye karar verecektir. Ve bu her istekte oldu.
Sertifikaların geçerlilik süresi neden kısaldı?
AWS Bulut Sunucusu Meta Verileri Kubernetes'le değil EC2 bulut sunucularıyla çalışacak şekilde tasarlanmıştır. Öte yandan uygulama arayüzünü değiştirmek istemedik. Bunun için kullandık - her Kubernetes düğümündeki aracıları kullanarak kullanıcıların (uygulamaları bir kümeye dağıtan mühendislerin) bölmelerdeki kapsayıcılara EC2 bulut sunucularıymış gibi IAM rolleri atamasına olanak tanıyan bir araç. KIAM, AWS Örnek Meta Veri hizmetine yapılan çağrıları yakalar ve bunları daha önce AWS'den almış olan önbelleğinden işler. Uygulama açısından bakıldığında hiçbir şey değişmez.
KIAM, bölmelere kısa vadeli sertifikalar sağlar. Bir kapsülün ortalama ömrünün EC2 bulut sunucusununkinden daha kısa olduğu göz önüne alındığında bu mantıklıdır. Sertifikalar için varsayılan geçerlilik süresi .
Sonuç olarak her iki varsayılan değeri üst üste bindirirseniz sorun ortaya çıkar. Bir uygulamaya sağlanan her sertifikanın süresi 15 dakika sonra sona erer. Ancak AWS Java SDK, sona erme tarihine 15 dakikadan az süre kalan tüm sertifikaların yenilenmesini zorunlu kılar.
Sonuç olarak, geçici sertifika her istekte yenilenmeye zorlanır, bu da AWS API'ye birkaç çağrı yapılmasını gerektirir ve gecikmede önemli bir artışa neden olur. AWS Java SDK'sında şunu bulduk: , benzer bir sorundan bahsediyor.
Çözümün basit olduğu ortaya çıktı. KIAM'ı daha uzun geçerlilik süresine sahip sertifikalar talep edecek şekilde yeniden yapılandırdık. Bu gerçekleştikten sonra istekler AWS Meta Veri hizmetinin katılımı olmadan akmaya başladı ve gecikme EC2'dekinden bile daha düşük seviyelere düştü.
Bulgular
Geçişlerle ilgili deneyimlerimize dayanarak, sorunların en yaygın kaynaklarından birinin Kubernetes'teki veya platformun diğer öğelerindeki hatalar olmadığını görüyoruz. Ayrıca taşıdığımız mikro hizmetlerdeki temel kusurları da gidermez. Sorunlar genellikle farklı unsurları bir araya getirdiğimiz için ortaya çıkar.
Daha önce birbirleriyle hiç etkileşime girmemiş karmaşık sistemleri bir araya getirerek bunların tek ve daha büyük bir sistem oluşturmasını bekleriz. Ne yazık ki, ne kadar çok öğe olursa, hata payı da o kadar artar, entropi de o kadar yüksek olur.
Bizim durumumuzda yüksek gecikme; Kubernetes, KIAM, AWS Java SDK veya mikro hizmetimizdeki hataların veya kötü kararların sonucu değildi. Bu, iki bağımsız varsayılan ayarın birleştirilmesinin sonucuydu: biri KIAM'da, diğeri AWS Java SDK'da. Ayrı ayrı ele alındığında her iki parametre de anlamlıdır: AWS Java SDK'daki aktif sertifika yenileme politikası ve KAIM'deki sertifikaların kısa geçerlilik süresi. Ancak bunları bir araya getirdiğinizde sonuçlar tahmin edilemez hale gelir. İki bağımsız ve mantıksal çözümün birleştirildiğinde anlamlı olması gerekmez.
çevirmenden PS
AWS IAM'i Kubernetes ile entegre etmeye yönelik KIAM yardımcı programının mimarisi hakkında daha fazla bilgiyi şu adreste bulabilirsiniz: yaratıcılarından.
Ayrıca blogumuzda okuyun:
- «";
- «";
- «";
- «'.
Kaynak: habr.com
