

Nikolai Samokhvalov'un “PostgreSQL'i ayarlamaya yönelik endüstriyel yaklaşım: veritabanları üzerinde deneyler” raporunun metnini okumanızı öneririm.
Shared_buffers = %25 – çok mu yoksa az mı? Yoksa doğru mu? Oldukça eski olan bu önerinin sizin özel durumunuz için uygun olup olmadığını nasıl anlarsınız?
Postgresql.conf parametrelerini "bir yetişkin gibi" seçme konusuna yaklaşmanın zamanı geldi. Kör "otomatik ayarlayıcıların" yardımıyla veya makalelerden ve bloglardan alınan güncel olmayan tavsiyelerle değil, aşağıdakilere dayanarak:
- Otomatik olarak, büyük miktarlarda ve "savaşmaya" mümkün olduğunca yakın koşullar altında gerçekleştirilen, veritabanları üzerinde kesin olarak doğrulanmış deneyler,
- DBMS ve işletim sisteminin özelliklerinin derinlemesine anlaşılması.
Nancy CLI'yi kullanma (), farklı durumlarda, farklı projelerde belirli bir örneğe (kötü şöhretli paylaşılan_bufferlara) bakacağız ve altyapımız, veritabanımız ve yükümüz için en uygun ayarı nasıl seçeceğimizi bulmaya çalışacağız.

Veritabanları ile yapılan deneylerden bahsedeceğiz. Bu altı aydan biraz fazla süren bir hikaye.

Biraz benim hakkımda. Postgres'te 14 yıldan fazla deneyim. Çok sayıda sosyal ağ şirketi kuruldu. Postgres her yerde kullanıldı ve kullanılıyor.
Ayrıca Meetup'ta RuPostgres grubu dünyada 2. sırada. Yavaş yavaş 2 kişiye yaklaşıyoruz. RuPostgres.org.
Highload da dahil olmak üzere çeşitli konferansların bilgisayarlarında en başından beri veritabanlarından, özellikle de Postgres'ten sorumluyum.

Ve son birkaç yılda Postgres danışmanlık uygulamalarıma buradan 11 saat diliminde yeniden başladım.

Ve bunu birkaç yıl önce yaptığımda, muhtemelen 2010'dan beri Postgres ile aktif manuel çalışmamda bir miktar ara verdim. Bir DBA'nın çalışma rutininin ne kadar az değiştiğine ve hala ne kadar el emeğinin kullanılması gerektiğine şaşırdım. Ve hemen burada bir şeylerin ters gittiğini düşündüm, her şeyi daha fazla otomatikleştirmem gerekiyor.
Ve her yer uzak olduğundan müşterilerin çoğu bulutların içindeydi. Ve açıkçası pek çok şey zaten otomatikleştirildi. Bu konuda daha sonra daha fazla bilgi vereceğiz. Yani, tüm bunlar, çok sayıda veritabanının yönetilebilmesi için bir dizi aracın, yani neredeyse tüm DBA eylemlerini otomatikleştirecek bir tür platformun olması gerektiği fikriyle sonuçlandı.

Bu rapor şunları içermeyecektir:
- “Gümüş kurşunlar” ve benzeri ifadeler - 8 GB veya %25 paylaşılan_buffer'ları ayarlayın, sorun olmayacak. Shared_buffers hakkında fazla bir şey olmayacak.
- Sert "iç organlar".

Ne olacak
- Uyguladığımız ve geliştirdiğimiz optimizasyon prensipleri olacak. Yol boyunca ortaya çıkan her türlü fikir ve çoğunlukla Açık Kaynakta yarattığımız çeşitli araçlar olacak, yani Açık Kaynakta temel oluşturuyoruz. Üstelik biletlerimiz var, tüm iletişim pratikte Açık Kaynaktır. Şu anda ne yaptığımızı, bir sonraki sürümde ne olacağını vb. görebilirsiniz.
- Ayrıca bu ilkeleri, bu araçları küçük girişimlerden büyük şirketlere kadar birçok şirkette kullanma konusunda da deneyim olacak.

Bütün bunlar nasıl gelişiyor?

İlk olarak, bir DBA'nın ana görevi, örneklerin oluşturulmasını, yedeklemelerin dağıtılmasını vb. sağlamanın yanı sıra darboğazları bulmak ve performansı optimize etmektir.
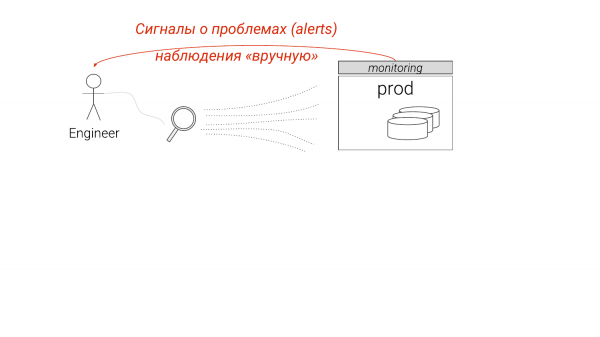
Artık bu şekilde ayarlandı. İzlemeye bakıyoruz, bir şeyler görüyoruz ama bazı detayları kaçırıyoruz. Genellikle ellerimizle daha dikkatli kazmaya başlarız ve bununla öyle ya da böyle ne yapacağımızı anlarız.
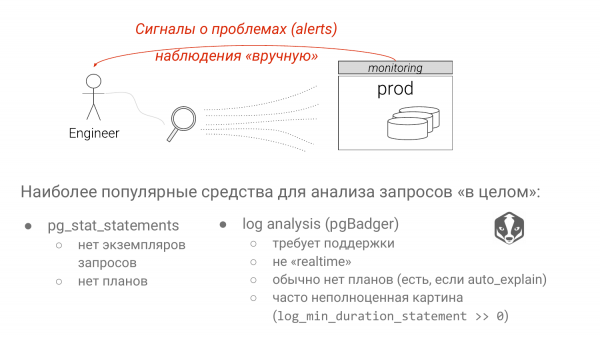
Ve iki yaklaşım var. Pg_stat_statements, yavaş sorguları tanımlamak için varsayılan çözümdür. Ve Postgres günlüklerinin pgBadger kullanılarak analizi.
Her yaklaşımın ciddi dezavantajları vardır. İlk yaklaşımda tüm parametreleri attık. Ve eğer SELECT * FROM tablosundaki grupları görürsek, burada sütun "?" işaretine eşittir. veya Postgres 10'dan bu yana “$”. Bunun bir dizin taraması mı yoksa sıralı bir tarama mı olduğunu bilmiyoruz. Bu büyük ölçüde parametreye bağlıdır. Orada nadiren karşılaşılan bir değeri değiştirirseniz, bu bir dizin taraması olacaktır. Orada tablonun %90'ını kaplayan bir değeri koyarsanız sıra taraması belli olacaktır çünkü Postgres istatistikleri bilir. Ve bu, pg_stat_statements'ın büyük bir dezavantajıdır, ancak bazı çalışmalar devam etmektedir.
Log analizinin en büyük dezavantajı kural olarak "log_min_duration_statement = 0" değerini göze alamamanızdır. Ve bunun hakkında da konuşacağız. Buna göre resmin tamamını göremezsiniz. Ve çok hızlı olan bazı sorgular büyük miktarda kaynak tüketebilir, ancak eşiğinizin altında olduğu için bunu göremezsiniz.
DBA'lar buldukları sorunları nasıl çözüyorlar?
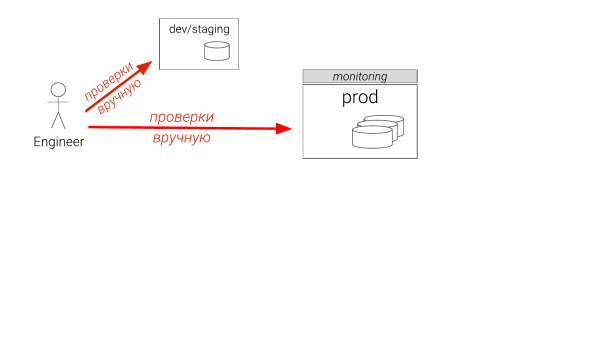
Mesela bir sorun bulduk. Genellikle ne yapılır? Eğer bir geliştiriciyseniz, o zaman bazı örneklerde aynı boyutta olmayan bir şey yapacaksınız. Eğer bir DBA iseniz, o zaman sahnelemeniz vardır. Ve yalnızca bir tane olabilir. Ve altı ay gerideydi. Ve üretime geçeceğinizi düşünüyorsunuz. Ve hatta deneyimli DBA'lar bile üretimin bir kopyasını kontrol ediyor. Ve geçici bir dizin oluştururlar, yardımcı olduğundan emin olurlar, onu bırakırlar ve geliştiricilere verirler, böylece onu geçiş dosyalarına koyabilirler. Bu şu anda yaşanan saçmalıklardan biri. Ve bu bir sorundur.
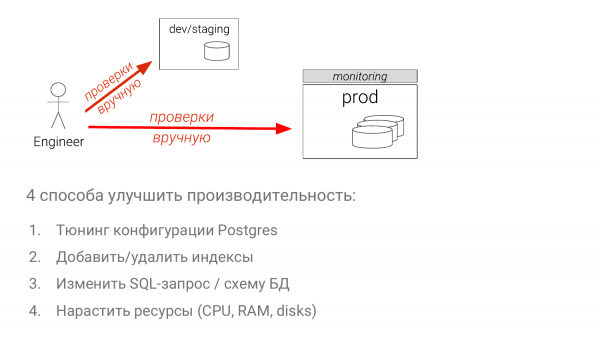
- Yapılandırmaları ayarlayın.
- Dizin kümesini optimize edin.
- SQL sorgusunun kendisini değiştirin (bu en zor yoldur).
- Kapasite ekleyin (çoğu durumda en kolay yol).

Bu şeylerle ilgili çok şey oluyor. Postgres'te çok sayıda tanıtıcı var. Bilinecek çok şey var. Bu konferansın organizatörleri sayesinde Postgres'te pek çok indeks var. Ve tüm bunların bilinmesi gerekiyor ve DBA olmayanların DBA'lar kara büyü yapıyormuş gibi hissetmesine neden olan da budur. Yani tüm bunları normal bir şekilde anlamaya başlamak için 10 yıl çalışmanız gerekiyor.
Ve ben bu kara büyüye karşı bir savaşçıyım. Teknoloji olsun diye her şeyi yapmak istiyorum ve tüm bunlarda sezgi yok.
Gerçek hayat örnekleri

Bunu kendi projem de dahil olmak üzere en az iki projede gözlemledim. Başka bir blog yazısı bize default_statistict_target için 1 değerinin iyi olduğunu söylüyor. Tamam, hadi üretimde deneyelim.

Ve işte buradayız, iki yıl sonra aracımızı kullanarak, bugün bahsettiğimiz veritabanları üzerinde yapılan deneyler yardımıyla, olanı ve olanı karşılaştırabiliyoruz.
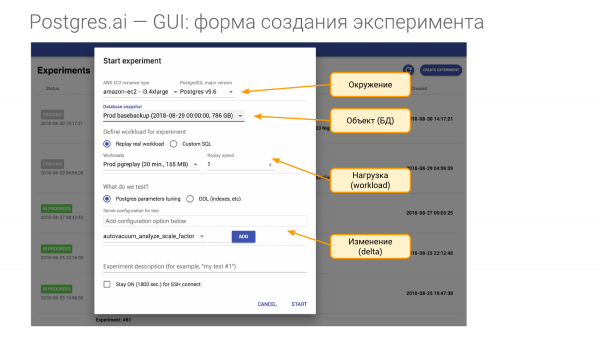
Bunun için de bir deney oluşturmamız gerekiyor. Dört bölümden oluşur.
- Birincisi çevredir. Bir parça donanıma ihtiyacımız var. Ve bir şirkete gelip sözleşme imzaladığımda onlara üretimdeki donanımın aynısını bana vermelerini söylüyorum. Ustalarınızın her biri için bunun gibi en az bir donanıma ihtiyacım var. Ya bu Amazon ya da Google'daki bir örnek sanal makinedir ya da tam olarak aynı donanıma ihtiyacım var. Yani çevreyi yeniden yaratmak istiyorum. Çevre kavramına da Postgres'in ana versiyonunu dahil ediyoruz.
- İkinci bölüm araştırmamızın konusunu oluşturmaktadır. Bu bir veritabanıdır. Birkaç şekilde oluşturulabilir. Sana nasıl yapılacağını göstereceğim.
- Üçüncü kısım ise yük. Bu en zor an.
- Dördüncü bölüm ise neyi kontrol edeceğimiz yani neyi neyle karşılaştıracağımızdır. Diyelim ki yapılandırmada bir veya daha fazla parametreyi değiştirebiliriz veya bir dizin vb. oluşturabiliriz.
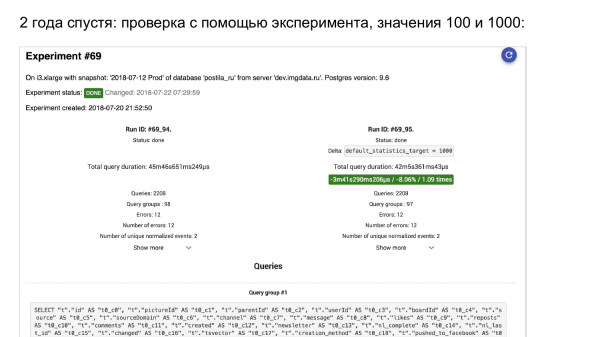
Bir deney başlatıyoruz. İşte pg_stat_statements. Solda yaşananlar. Sağda - ne oldu.
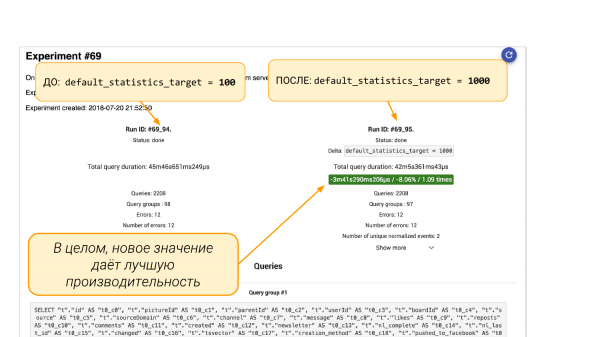
Solda default_statistics_target = 100, sağda =1 Bunun bize yardımcı olduğunu görüyoruz. Genel olarak her şey %000 oranında iyileşti.
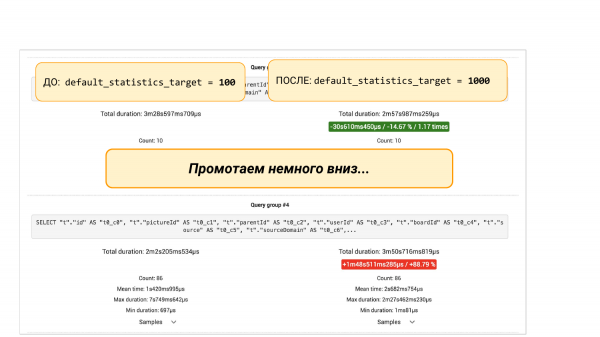
Ancak aşağıya doğru kaydırırsak pgBadger'dan veya pg_stat_statements'tan gelen istek grupları olacaktır. İki seçenek var. Bazı taleplerin %88 oranında düştüğünü göreceğiz. Ve işte mühendislik yaklaşımı geliyor. Daha derine inebiliriz çünkü neden battığını merak ediyoruz. İstatistiklere ne olduğunu anlamalısınız. İstatistiklerde neden daha fazla bölüm daha kötü sonuçlara yol açıyor?
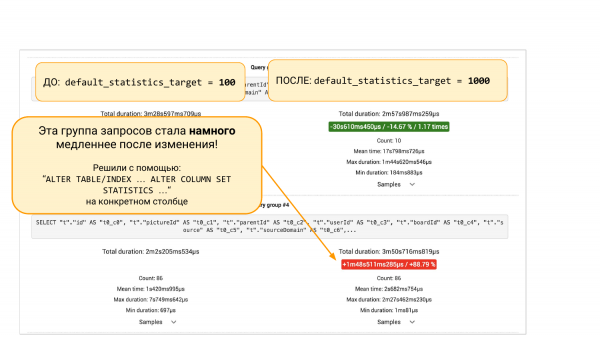
Veya kazamayız, ancak “TABLAYI DEĞİŞTİR ... SÜTUNU DEĞİŞTİR” yapıp 100 kovayı bu sütunun istatistiklerine geri döndürebiliriz. Ve sonra başka bir deneyle bu yamanın yardımcı olduğundan emin olabiliriz. Tüm. Bu, büyük resmi görmemize ve sezgiler yerine verilere dayalı kararlar almamıza yardımcı olan bir mühendislik yaklaşımıdır.


Diğer bölgelerden birkaç örnek. Yıllardır testlerde CI testleri yapılıyor. Ve aklı başında hiçbir proje otomatik testler olmadan yaşayamaz.
Diğer sektörlerde; havacılıkta, otomotiv sektöründe aerodinamiği test ettiğimizde deneyler yapma fırsatı da buluyoruz. Çizimden bir şeyi doğrudan uzaya fırlatmayacağız ya da bir arabayı hemen piste çıkarmayacağız. Mesela rüzgar tüneli var.
Diğer sektörlere ilişkin gözlemlerden sonuçlar çıkarabiliriz.

Öncelikle özel bir ortamımız var. Üretime yakın ama yakın değil. Ana özelliği ucuz, tekrarlanabilir ve mümkün olduğunca otomatik olmasıdır. Ayrıca ayrıntılı analiz yapmak için özel araçların da olması gerekir.
Büyük olasılıkla, bir uçağı fırlatıp uçtuğumuzda, kanat yüzeyinin her milimetresini inceleme fırsatımız rüzgar tünelinde olduğundan daha az oluyor. Daha fazla teşhis aracımız var. Uçağa taşımaya gücümüzün yetmediği daha ağır şeyleri havada taşımaya gücümüz yetiyor. Postgres'te de aynı durum var. Bazı durumlarda denemeler sırasında tam sorgu günlüğünü etkinleştirebiliriz. Ve bunu üretimde yapmak istemiyoruz. Bunu auto_explain kullanarak etkinleştirmeyi bile planlayabiliriz.
Ve söylediğim gibi, yüksek düzeyde otomasyon, düğmeye basıp tekrarlamamız anlamına geliyor. Bu şekilde olması gerekiyor ki, çok fazla deneme olsun, yayında olsun.
Nancy CLI - “veritabanı laboratuvarının” temeli

Biz de bu şeyi yaptık. Yani neredeyse bir yıl önce Haziran ayında bu fikirlerden bahsetmiştim. Ve zaten Açık Kaynakta Nancy CLI olarak adlandırılan şeye sahibiz. Bu, bir veritabanı laboratuvarı oluşturmanın temelidir.
— Gitlab'da Açık Kaynak'tadır. Söyleyebilirsin, deneyebilirsin. Slaytlarda link verdim. Üzerine tıklayabilirsiniz ve orada olacaktır her bakımdan.
Tabii ki hala geliştirilme aşamasında olan birçok şey var. Orada pek çok fikir var. Ancak bu neredeyse her gün kullandığımız bir şey. Ve bir fikrimiz olduğunda - neden 40 satırı sildiğimizde, her şey IO'ya düşüyor, o zaman bir deney yapabilir ve neler olduğunu anlamak için daha ayrıntılı olarak bakabilir ve ardından bunu anında düzeltmeye çalışabiliriz. Yani bir deney yapıyoruz. Örneğin, bir şeye ince ayar yapıyoruz ve sonunda ne olacağını görüyoruz. Ve bunu üretimde yapmıyoruz. Bu fikrin özü budur.
Bu nerede işe yarayabilir? Bu yerel olarak çalışabilir, yani bunu her yerde yapabilirsiniz, hatta bir MacBook'ta bile çalıştırabilirsiniz. Bir liman işçisine ihtiyacımız var, hadi gidelim. Bu kadar. Bazı durumlarda bunu bir donanım üzerinde veya sanal bir makinede herhangi bir yerde çalıştırabilirsiniz.
Ayrıca Amazon'da EC2 Bulut Sunucusunda noktalar halinde uzaktan çalıştırma fırsatı da var. Ve bu çok güzel bir fırsat. Örneğin dün i500 örneği üzerinde en küçüğünden başlayıp i3-3-xlarge ile biten 16'den fazla deney gerçekleştirdik. Ve 500 deneyin bize maliyeti 64 dolardı. Her biri 15 dakika sürdü. Yani orada spotlar kullanıldığı için çok ucuz - Amazon'un saniye başına faturalandırması olan% 70 indirim. Çok şey yapabilirsin. Gerçek araştırma yapabilirsiniz.
Ve Postgres'in üç ana sürümü desteklenmektedir. Bazı eskileri ve yeni 12. versiyonu da bitirmek o kadar da zor değil.

Bir nesneyi üç şekilde tanımlayabiliriz. Bu:
- Döküm/sql dosyası.
- Ana yol PGDATA dizinini klonlamaktır. Kural olarak yedekleme sunucusundan alınır. Normal ikili yedeklemeleriniz varsa oradan klon yapabilirsiniz. Eğer bulutlarınız varsa Amazon ve Google gibi bir bulut ofisi bunu sizin için yapacaktır. Gerçek üretimi klonlamanın en önemli yolu budur. Bu şekilde ortaya çıkıyoruz.
- Ve son yöntem, Postgres'te bir şeyin nasıl çalıştığını anlamak istediğinizde araştırmaya uygundur. Bu pgbench. Pgbench kullanarak oluşturabilirsiniz. Bu sadece bir "db-pgbench" seçeneğidir. Ona hangi ölçekte olduğunu söyle. Ve belirtildiği gibi her şey bulutta üretilecek.

Ve yükleyin:
- Yükü bir SQL iş parçacığında çalıştırabiliriz. Bu en ilkel yoldur.
- Ve yükü taklit edebiliriz. Ve bunu her şeyden önce aşağıdaki şekilde taklit edebiliriz. Tüm günlükleri toplamamız gerekiyor. Ve bu acı verici. Sana nedenini göstereceğim. Ve Nancy'de yerleşik olan pgreplay'i kullanarak oynuyoruz.
- Veya başka bir seçenek. Belli bir çaba harcayarak yaptığımız sözde zanaat yükü. Savaş sistemindeki mevcut yükümüzü analiz ederek en önemli talep gruplarını çıkarıyoruz. Ve pgbench kullanarak bu yükü laboratuvarda taklit edebiliriz.

- Ya bir tür SQL gerçekleştirmemiz gerekiyor, yani bir tür geçişi kontrol ediyoruz, orada bir dizin oluşturuyoruz, orada ANALAZE'i çalıştırıyoruz. Boşluktan önce ve boşluktan sonra ne olduğuna bakıyoruz. Genel olarak herhangi bir SQL.
- Yapılandırmada bir veya daha fazla parametreyi değiştiririz. Örneğin terabaytlık veritabanımız için Amazon'daki 100 değeri kontrol etmemizi söyleyebiliriz. Ve birkaç saat içinde sonuca ulaşacaksınız. Kural olarak, terabaytlık bir veritabanını dağıtmanız birkaç saat sürecektir. Ancak geliştirilmekte olan bir yama var, bir serimiz mümkün, yani aynı pgdata'yı aynı sunucuda sürekli olarak kullanabilir ve kontrol edebilirsiniz. Postgres yeniden başlatılacak ve önbellekler sıfırlanacak. Ve yükü taşıyabilirsin.

- Pg anlık görüntülerinden başlayarak bir dizi farklı dosya içeren bir dizin gelirstat***. Ve buradaki en ilginç şey pg_stat_statements, pg_stat_kcacke. Bunlar istekleri analiz eden iki uzantıdır. Ve pg_stat_bgwriter yalnızca pgwriter istatistiklerini değil, aynı zamanda kontrol noktası ve arka uçların kendilerinin kirli arabellekleri nasıl değiştirdiği hakkında da bilgi içerir. Ve bunların hepsini görmek ilginç. Örneğin, paylaşılan_buffer'ları ayarladığımızda herkesin ne kadar değiştirdiğini görmek çok ilginç.
- Postgres günlükleri de geliyor. İki günlük – bir hazırlık günlüğü ve bir yük oynatma günlüğü.
- Nispeten yeni bir özellik FlameGraphs'tır.
- Ayrıca, yükü oynatmak için pgreplay veya pgbench seçeneklerini kullandıysanız çıktıları yerel olacaktır. Gecikmeyi ve TPS'yi göreceksiniz. Nasıl gördüklerini anlamak mümkün olacak.
- Sistem bilgisi.
- Temel CPU ve IO kontrolleri. Bu, Amazon'daki EC2 bulut sunucusu için daha fazladır; bir iş parçacığında 100 aynı örneği başlatmak ve orada 100 farklı çalıştırma çalıştırmak istediğinizde, 10 denemeniz olur. Ve zaten birileri tarafından baskı altına alınan kusurlu bir örnekle karşılaşmadığınızdan emin olmalısınız. Diğerleri bu donanım üzerinde aktif ve sizin çok az kaynağınız kaldı. Bu tür sonuçları atmak daha iyidir. Ve Alexey Kopytov'un sysbench'inin yardımıyla, gelecek ve diğerleriyle karşılaştırılabilecek birkaç kısa kontrol yapıyoruz, yani CPU'nun nasıl davrandığını ve IO'nun nasıl davrandığını anlayacaksınız.

Farklı firmaları örnek alarak teknik zorluklar nelerdir?

Diyelim ki gerçek yükü günlükleri kullanarak tekrarlamak istiyoruz. Açık Kaynak pgreplay'de yazılmış olması harika bir fikir. Biz onu kullanıyoruz. Ancak bunun iyi çalışması için parametreler ve zamanlamayla birlikte tam sorgu günlüğünü etkinleştirmeniz gerekir.
Süre ve zaman damgasıyla ilgili bazı zorluklar var. Bütün mutfağı boşaltacağız. Asıl soru, bunu karşılayıp karşılayamayacağınızdır?

Sorun şu ki, mevcut olmayabilir. Öncelikle günlüğe hangi akışın yazılacağını anlamalısınız. Eğer pg_stat_statements'ınız varsa bu sorguyu kullanarak (link slaytlarda mevcut olacaktır) saniyede yaklaşık olarak kaç byte yazılacağını anlayabilirsiniz.
Talebin uzunluğuna bakıyoruz. Hiçbir parametrenin olmadığı gerçeğini göz ardı ediyoruz, ancak isteğin uzunluğunu biliyoruz ve saniyede kaç kez yürütüldüğünü biliyoruz. Bu şekilde saniyede yaklaşık kaç bayt olduğunu tahmin edebiliriz. İki kat hata yapabiliriz ama bu şekilde düzeni mutlaka anlayacağız.
Bu isteğin saniyede 802 kez yürütüldüğünü görüyoruz. Ve görüyoruz ki bytes_per sec – 300 kB/s artı veya eksi olarak yazılacak. Ve kural olarak böyle bir akışı karşılayabiliriz.

Ancak! Gerçek şu ki, farklı kayıt sistemleri var. Ve insanların varsayılanı genellikle "sistem günlüğü"dür.
Ve eğer sistem günlüğünüz varsa, bunun gibi bir resminiz olabilir. Pgbench'i alıp sorgu günlüğünü etkinleştireceğiz ve ne olacağını göreceğiz.
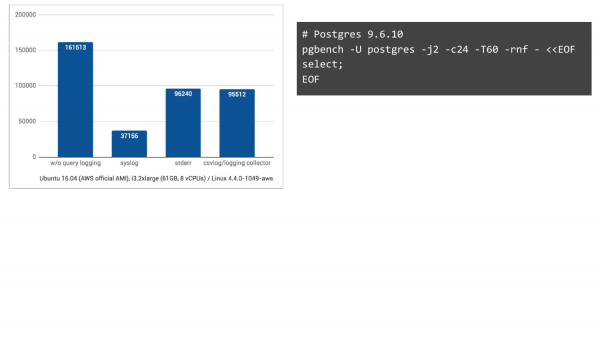
Kayıt tutmadan, soldaki sütun bu şekilde. 161.000 TPS elde ettik. Syslog ile ise bu şu şekilde. Ubuntu 16 Nisan'da Amazon'da 37.000 TPS (saniye başına işlem) elde ediyoruz. Diğer iki kayıt yöntemine geçtiğimizde ise durum çok daha iyi. Dolayısıyla bir düşüş bekliyorduk, ancak bu kadar büyük bir düşüş beklemiyorduk.
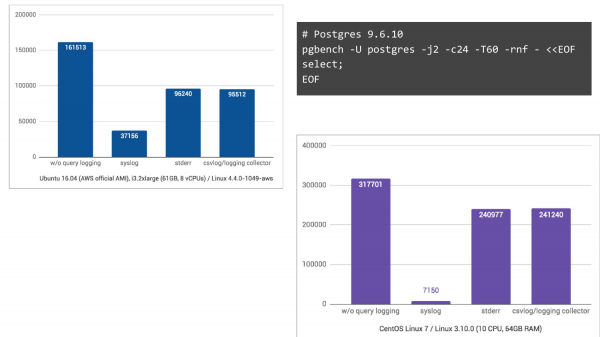
Ve CentOS Günlükleri kolay arama için ikili biçime dönüştüren, journald kullanan 7 sürümü ise tam bir kabus ve TPS'de 44 katlık bir düşüşe neden oluyor.
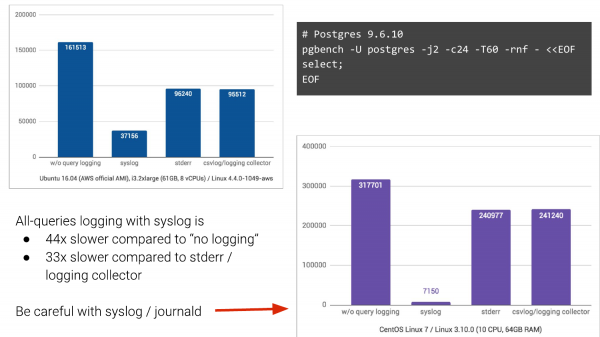
Ve insanların yaşadığı şey budur. Ve çoğu zaman şirketlerde, özellikle de büyük şirketlerde, bunu değiştirmek çok zordur. Sistem günlüğünden uzaklaşabiliyorsanız lütfen ondan uzaklaşın.

- IOPS'yi değerlendirin ve akışı yazın.
- Kayıt sisteminizi kontrol edin.
- Tahmini yük aşırı büyükse numune almayı düşünün.

pg_stat_statements'ımız var. Dediğim gibi orada olması gerekiyor. Ve her istek grubunu özel bir şekilde bir dosyada alıp tanımlayabiliriz. Ve sonra pgbench'in çok kullanışlı bir özelliğini kullanabiliriz - bu, "-f" seçeneğini kullanarak birkaç dosya ekleme yeteneğidir.
Çok fazla "-f"yi anlıyor. Ve sonundaki “@” yardımıyla her dosyanın hangi paylaşıma sahip olması gerektiğini anlayabilirsiniz. Yani vakaların %10'unda şunu yapın, %20'sinde bunu yapın diyebiliriz. Bu da bizi üretimde gördüklerimize daha da yaklaştıracak.

Üretimde elimizde olanı nasıl anlayacağız? Hangi paylaşım ve nasıl? Bu biraz ayrı bir konu. Bir ürünümüz daha var . Ayrıca Açık Kaynakta bir temel. Ve şimdi onu aktif olarak geliştiriyoruz.
Biraz farklı nedenlerle doğdu. Bu nedenlerden dolayı izleme yeterli değildir. Yani geliyorsunuz, temele bakıyorsunuz, var olan sorunlara bakıyorsunuz. Ve kural olarak bir health_check yaparsınız. Deneyimli bir DBA iseniz, health_check'i yaparsınız. İndekslerin vb. kullanımına baktık. OKmeter'iniz varsa harika. Bu Postgres için harika bir izleme. OKmeter.io – lütfen kurun, orada her şey çok iyi yapılıyor. Ücretli.
Eğer bir tane yoksa, o zaman genellikle fazla bir şeyin yok demektir. İzlemede genellikle CPU, IO ve ardından rezervasyonlar vardır ve hepsi bu. Ve daha fazlasına ihtiyacımız var. Otomatik vakumun nasıl çalıştığını, kontrol noktasının nasıl çalıştığını görmemiz gerekiyor, io'da kontrol noktasını bgwriter'dan ve arka uçlardan vb. ayırmamız gerekiyor.
Sorun şu ki, büyük bir şirkete yardım ettiğinizde bir şeyi hızlı bir şekilde uygulayamıyorlar. OKmeter'i hemen satın alamazlar. Belki altı ay sonra satın alırlar. Bazı paketleri hızlı bir şekilde teslim edemiyorlar.
Ve hiçbir şeyin kurulmasını gerektirmeyen, yani üretimde hiçbir şey kurmanıza gerek olmayan özel bir araca ihtiyacımız olduğu fikrini ortaya attık. Dizüstü bilgisayarınıza veya çalıştıracağınız gözlem sunucusuna yükleyin. Ve pek çok şeyi analiz edecek: işletim sistemi, dosya sistemi ve Postgres'in kendisi, doğrudan üretime çalıştırılabilecek bazı hafif sorgular yapacak ve hiçbir şey başarısız olmayacak.
Biz buna Postgres kontrolü adını verdik. Tıbbi açıdan bu, düzenli bir sağlık kontrolüdür. Otomotiv temalıysa bakım gibidir. Aracınızın markasına göre altı ayda bir ya da yılda bir bakımını yaptırıyorsunuz. Üssünüzün bakımını yapıyor musunuz? Yani düzenli olarak derinlemesine araştırma yapıyor musunuz? Yapılmalıdır. Yedekleme yaparsanız bir kontrol yapın, bu daha az önemli değildir.
Ve böyle bir aracımız var. Sadece üç ay önce aktif olarak ortaya çıkmaya başladı. Hala genç ama orada çok şey var.

En "etkili" sorgu gruplarını toplama - Postgres-checkup'ta K003'ü rapor edin
Ve bir grup rapor var K. Şu ana kadar üç rapor. Ve böyle bir K003 raporu var. Toplam_zamana göre sıralanmış pg_stat_statements'ın en üst kısmı var.
İstek gruplarını total_time'a göre sıraladığımızda sistemimize en çok yüklenen yani daha fazla kaynak tüketen grubu en üstte görüyoruz. Sorgu gruplarını neden adlandırıyorum? Çünkü parametreleri attık. Bunlar artık istek değil, istek gruplarıdır, yani soyutlanmışlardır.
Yukarıdan aşağıya doğru optimizasyon yaparsak kaynaklarımızı hafifletir ve yükseltme yapmamız gereken anı geciktiririz. Bu paradan tasarruf etmenin çok iyi bir yoludur.
Belki de bu, kullanıcılarla ilgilenmenin pek iyi bir yolu değildir, çünkü bir kişinin 15 saniye beklediği nadir ama çok sinir bozucu durumlar görebiliriz. Toplamda o kadar nadirdirler ki onları göremiyoruz ama kaynaklarla uğraşıyoruz.

Bu tabloda ne oldu? İki anlık fotoğraf çektik. Postgres_checkup size her ölçüm için bir delta verecektir: toplam süre, çağrılar, satırlar, paylaşılan_blks_read vb. İşte bu kadar, delta hesaplandı. pg_stat_statements ile ilgili en büyük sorun, ne zaman sıfırlandığını hatırlamamasıdır. pg_stat_database hatırlıyorsa pg_stat_statements hatırlamaz. Bakıyorsunuz 1 diye bir rakam var ama nereden saydığımızı bilmiyoruz.
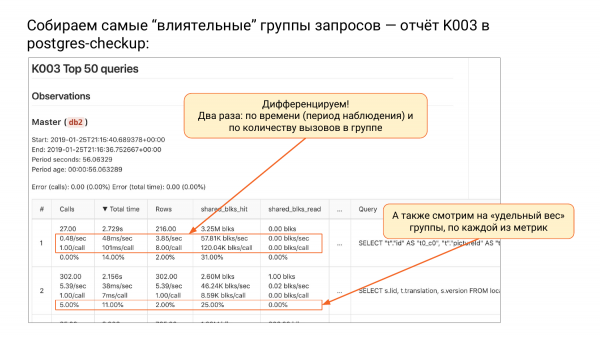
Ve burada biliyoruz ki, burada iki anlık görüntümüz var. Bu durumda deltanın 56 saniye olduğunu biliyoruz. Çok kısa bir boşluk. Toplam_zamana göre sıralandı. Ve sonra farklılaştırabiliriz, yani tüm metrikleri süreye böleriz. Her bir metriği süreye bölersek saniyedeki çağrı sayısını elde ederiz.
Sonra, saniye başına toplam_zaman benim favori ölçümümdür. Saniye cinsinden ölçülür, yani sistemimizin bu grup istekleri saniyede kaç saniyede yerine getirdiği. Orada saniyede bir saniyeden fazlasını görüyorsanız birden fazla çekirdek vermeniz gerekiyor demektir. Bu çok iyi bir ölçüm. Mesela bu arkadaşın en az üç çekirdeğe ihtiyacı olduğunu anlayabilirsiniz.
Bu bizim bilgi birikimimiz, hiçbir yerde böyle bir şey görmedim. Lütfen unutmayın - bu çok basit bir şeydir - saniyede saniye. Bazen CPU'nuz %100 olduğunda saniyede yarım saat, yani sadece bu istekleri yapmak için yarım saat harcarsınız.
Daha sonra saniyede satır sayısını görüyoruz. Saniyede kaç satır döndüğünü biliyoruz.
Ayrıca ilginç bir şey daha var. Shared_buffer'ların kendisinden saniyede kaç tane paylaşılan_buffer okuduğumuz. İsabetler zaten oradaydı ve satırları işletim sistemi önbelleğinden veya diskten aldık. İlk seçenek hızlıdır, ikincisi ise duruma göre hızlı olabilir veya olmayabilir.
İkinci farklılaştırma yöntemi ise bu gruptaki taleplerin sayısını bölmektir. İkinci sütunda her zaman sorgu başına bölünmüş bir sorgunuz olacaktır. Ve sonra ilginçtir - bu istekte kaç milisaniye vardı. Bu sorgunun ortalama olarak nasıl davrandığını biliyoruz. Her istek için 101 milisaniye gerekiyordu. Bu anlamamız gereken geleneksel ölçüdür.
Her sorgu ortalama kaç satır döndürdü? Bu grubun 8 geri döndüğünü görüyoruz. Ortalama olarak önbellekten ne kadar alınıp okunduğu. Her şeyin güzel bir şekilde önbelleğe alındığını görüyoruz. İlk grup için sağlam vuruşlar.
Ve her satırdaki dördüncü alt dize, toplamın yüzde kaçını gösterir. Çağrılarımız var. 1 diyelim ve bu grubun ne gibi katkılar sağladığını anlayabiliyoruz. Bu durumda ilk grubun %000'den daha az katkı sağladığını görüyoruz. Yani o kadar yavaş ki genel resimde göremiyoruz. İkinci grup ise aramalarda %000'tir. Yani tüm çağrıların %0,01'i ikinci gruptan geliyor.
Total_time da ilginçtir. Toplam çalışma süremizin %14'ünü ilk grup taleplere harcadık. Ve ikincisi için -% 11 vb.
Detaylara girmeyeceğim ama incelikler var. Üstte hata gösteriyoruz, çünkü karşılaştırma yaptığımızda anlık görüntüler havada uçuşabiliyor, yani bazı istekler düşüp ikincide artık mevcut olamayabilir, bazılarının ise yenileri çıkabiliyor. Ve orada hatayı hesaplıyoruz. 0'ı görüyorsanız bu iyidir. Hiçbir hata yok. Hata oranı %20'ye kadar çıkıyorsa sorun yok.

Daha sonra konumuza dönüyoruz. İş yükünü oluşturmamız gerekiyor. Yukarıdan aşağıya alıp %80 veya %90’a ulaşana kadar gidiyoruz. Genellikle bu 10-20 gruptur. Ve pgbench için dosyalar oluşturuyoruz. Orada rastgele kullanıyoruz. Bazen bu ne yazık ki işe yaramıyor. Postgres 12'de bu yaklaşımı kullanmak için daha fazla fırsat olacak.
Ve bu şekilde total_time'da %80-90 kazanıyoruz. “@”dan sonra ne koymalıyım? Çağrılara bakıyoruz, ne kadar ilgi olduğuna bakıyoruz ve buraya ne kadar ilgi borçlu olduğumuzu anlıyoruz. Bu yüzdelerden dosyaların her birinin nasıl dengeleneceğini anlayabiliriz. Bundan sonra pgbench'i kullanıyoruz ve işe gidiyoruz.
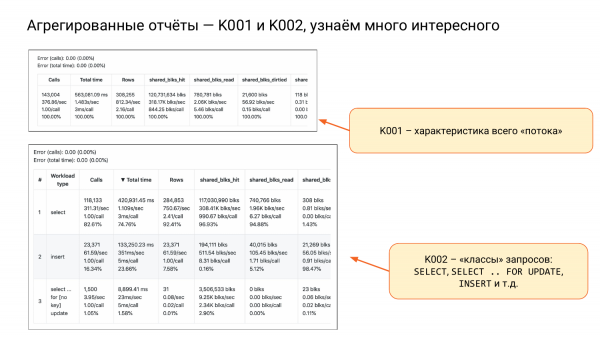
Ayrıca K001 ve K002'miz var.
K001, dört alt dizeden oluşan büyük bir dizedir. Bu, tüm yükümüzün bir özelliğidir. İkinci sütuna ve ikinci alt satıra bakın. Saniyede yaklaşık bir buçuk saniye olduğunu görüyoruz, yani. iki çekirdek varsa o zaman iyi olur. Yaklaşık yüzde 75 kapasite olacak. Ve bu şekilde çalışacak. 10 çekirdeğimiz varsa genellikle sakin oluruz. Bu şekilde kaynakları değerlendirebiliriz.
K002, sorgu sınıfları dediğim şeydir, yani SELECT, INSERT, UPDATE, DELETE. Ve ayrıca GÜNCELLEME İÇİN SEÇİN, çünkü bu bir kilittir.
Ve burada SELECT'in sıradan okuyucular olduğu sonucuna varabiliriz - tüm çağrıların% 82'si, ancak aynı zamanda toplam_zamanın% 74'ü. Yani çok çağrılırlar ancak daha az kaynak tüketirler.
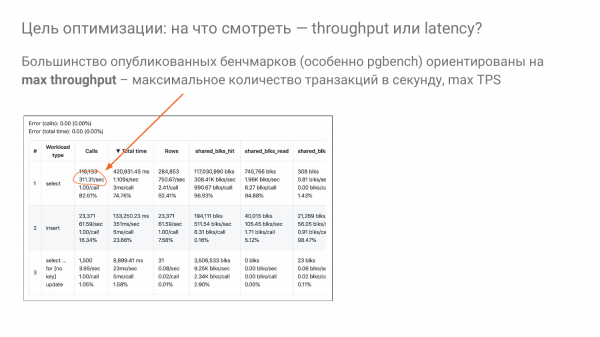
Ve şu soruya dönüyoruz: "Doğru paylaşılan_buffer'ları nasıl seçebiliriz?" Çoğu kıyaslamanın bu fikre dayandığını gözlemliyorum - hadi bakalım verim ne olacak, yani verim ne olacak. Genellikle TPS veya QPS cinsinden ölçülür.
Ve ayarlama parametrelerini kullanarak arabadan saniyede mümkün olduğunca çok işlem sıkıştırmaya çalışıyoruz. İşte seçim için saniyede tam olarak 311.

Ancak hiç kimse tam hızla işe gidip eve dönmüyor. Bu aptalca. Veritabanları ile aynı. Tam hızda araç kullanmak zorunda değiliz ve kimse de bunu yapmıyor. Hiç kimse %100 CPU'ya sahip olan üretimde yaşamıyor. Yine de belki birisi yaşıyor ama bu iyi değil.
Buradaki fikir, genellikle kapasitenin yüzde 20'siyle, tercihen yüzde 50'den fazla olmamak üzere araç kullanmamızdır. Ve her şeyden önce kullanıcılarımız için yanıt süresini optimize etmeye çalışıyoruz. Yani koşullu olarak %20 hızda minimum gecikme olacak şekilde düğmelerimizi çevirmeliyiz. Bu bizim de deneylerimizde kullanmaya çalıştığımız bir fikir.
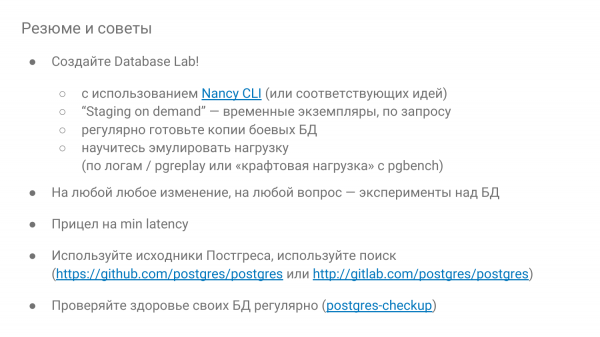
Ve son olarak öneriler:
- Veritabanı Laboratuvarı yaptığınızdan emin olun.
- Mümkünse, bir süre açılması için bunu talep üzerine yapın - oynayın ve atın. Eğer bulutlarınız varsa, o zaman bunu söylemeye gerek yok, yani çok fazla ayakta duruyorsunuz.
- Meraklı ol. Ve eğer bir şeyler yanlışsa, nasıl davrandığını deneylerle kontrol edin. Nancy, üssün nasıl çalıştığını kontrol etmek için kendinizi eğitmek için kullanılabilir.
- Ve minimum yanıt süresini hedefleyin.
- Ve Postgres kaynaklarından korkmayın. Kaynaklarla çalışırken İngilizce bilmeniz gerekir. Orada çok fazla yorum var, her şey orada açıklanıyor.
- Ve veritabanının durumunu düzenli olarak, en az üç ayda bir, manuel olarak veya Postgres kontrolü ile kontrol edin.

sorular
Çok teşekkürler! Çok ilginç bir şey.
İki parça.
Evet iki parça. Yalnız ben pek anlamadım. Nancy ve ben çalışırken yalnızca bir parametrede veya tüm grupta değişiklik yapabilir miyiz?
Bir delta yapılandırma parametremiz var. Oraya aynı anda istediğiniz kadar dönebilirsiniz. Ancak birçok şeyi değiştirdiğinizde yanlış sonuçlara varabileceğinizi anlamalısınız.
Evet. Neden sordum? Çünkü elinizde tek bir parametre varken deney yapmak zordur. Onu sıkılaştır, nasıl çalıştığını gör. Onu dışarı çıkardım. Daha sonra bir sonrakine başlarsınız.
Aynı anda sıkabilirsiniz ama duruma göre değişir elbette. Ancak bir fikri test etmek daha iyidir. Dün bir fikrimiz vardı. Çok yakın bir durumumuz vardı. İki yapılandırma vardı. Ve neden bu kadar büyük bir fark olduğunu anlayamadık. Ve farkın ne olduğunu tutarlı bir şekilde anlamak ve bulmak için ikilemi kullanmanız gerektiği fikri ortaya çıktı. Parametrelerin yarısını hemen aynı, ardından dörtte birini vb. Yapabilirsiniz. Her şey esnektir.
Ve bir soru daha var. Proje genç ve gelişiyor. Dokümantasyon zaten hazır, detaylı bir açıklama var mı?
Orada özellikle parametrelerin açıklamasına bir bağlantı yaptım. Orada. Ancak pek çok şey henüz orada değil. Benim gibi düşünen insanlar arıyorum. Ve performans sergilerken onları buluyorum. Bu çok havalı. Birisi zaten benimle çalışıyor, biri yardım etti ve orada bir şeyler yaptı. Ve eğer bu konuyla ilgileniyorsanız, neyin eksik olduğuna dair geri bildirimde bulunun.
Laboratuvarı yaptığımızda belki geri dönüş olur. Görelim. Teşekkür ederim!
Merhaba! Rapor için teşekkürler! Amazon desteğinin olduğunu gördüm. GSP'yi desteklemeye yönelik herhangi bir plan var mı?
İyi soru. Biz bunu yapmaya başladık. Paradan tasarruf etmek istediğimiz için bunu şimdilik dondurduk. Yani localhost'ta çalıştırmanın kullanılması desteği var. Kendiniz bir örnek oluşturabilir ve yerel olarak çalışabilirsiniz. Bu arada, biz de bunu yapıyoruz. Bunu Getlab'da, orada GSP'de yapıyorum. Ancak henüz böyle bir düzenleme yapmanın manasını göremiyoruz çünkü Google'ın ucuz noktaları yok. Orada ??? örneklerdir, ancak sınırlamaları vardır. Öncelikle her zaman sadece %70 indirim yapıyorlar ve oradaki fiyatla oynayamazsınız. Belirli noktalarda, atılma ihtimalinizi azaltmak için fiyatı %5-10 oranında artırıyoruz. Yani, lekelerden tasarruf edersiniz, ancak bunlar istediğiniz zaman elinizden alınabilir. Eğer diğerlerinden biraz daha yüksek teklif verirseniz daha sonra öldürülürsünüz. Google'ın tamamen farklı özellikleri var. Ve çok kötü bir sınırlama daha var; sadece 24 saat yaşıyorlar. Bazen de 5 gün boyunca bir deney yapmak istiyoruz. Ancak bunu lekeler halinde yapabilirsiniz; lekeler bazen aylarca sürer.
Merhaba! Rapor için teşekkürler! Kontrolden bahsettiniz. Stat_statements hatalarını nasıl hesaplarsınız?
Çok iyi bir soru. Size çok detaylı bir şekilde gösterebilir ve anlatabilirim. Kısacası, istek grupları kümesinin nasıl yüzdüğüne bakıyoruz: kaç tanesi düştü ve kaç tane yenisi ortaya çıktı. Daha sonra iki ölçüme bakıyoruz: toplam_süre ve çağrılar, yani iki hata var. Ve değişken grupların katkısına bakıyoruz. İki alt grup var: gidenler ve gelenler. Bakalım genel resme katkıları ne olacak?
Enstantaneler arasında iki üç kez oraya dönmesinden korkmuyor musunuz?
Yani tekrar mı kayıt oldular yoksa ne?
Örneğin, bu istek zaten bir kez önlendi, sonra geldi ve tekrar önlendi, sonra tekrar geldi ve tekrar önlendi. Ve burada bir şey hesapladınız ve hepsi nerede?
Güzel soru, bakmamız gerekecek.
Ben de benzer bir şey yaptım. Daha basitti elbette, tek başıma yaptım. Ancak stat_statements'ı sıfırlamam, sıfırlamam ve anlık görüntü sırasında belirli bir kesirden daha az olduğunu anlamam gerekiyordu, bu da orada ne kadar stat_statements birikebileceğinin tavanına hâlâ ulaşmıyordu. Ve benim anladığım kadarıyla büyük ihtimalle hiçbir şey yerinden çıkmamış.
Evet, evet.
Ancak bunu güvenilir bir şekilde nasıl yapacağımı anlamıyorum.
Oradaki query text’i mi yoksa pg_stat_statements ile queryid’i mi kullanıp ona odaklanacağımızı tam olarak hatırlamıyorum maalesef. Eğer queryid'e odaklanırsak, teoride karşılaştırılabilir şeyleri karşılaştırıyoruz.
Hayır, anlık çekimler arasında birkaç kez dışarı çıkmaya zorlanabilir ve tekrar gelebilir.
Aynı kimlikle mi?
Evet.
Bunu inceleyeceğiz. İyi soru. Bunu incelememiz gerekiyor. Ama şimdilik, gördüğümüz şey ya 0 yazıyor...
Bu elbette nadir görülen bir durumdur, ancak stat_statemetns'in orada yer değiştirebileceğini öğrendiğimde şok oldum.
Pg_stat_statements'ta pek çok şey olabilir. track_utility = açıksa setlerinizin de takip edildiği gerçeğiyle karşılaştık.
Evet, tabii ki.
Ve eğer Java hazırda bekletme modunuz varsa, ki bu rastgeledir, o zaman karma tablosu orada bulunmaya başlar. Ve çok yüklü bir uygulamayı kapattığınızda karşınıza 50-100 grup çıkıyor. Ve orada her şey az çok istikrarlı. Bununla mücadele etmenin bir yolu pg_stat_statements.max değerini artırmaktır.
Evet ama ne kadar olduğunu bilmen gerekiyor. Ve bir şekilde ona göz kulak olmamız gerekiyor. İşte bu yaptığım şey. Yani pg_stat_statements.max'ım var. Anlık görüntü sırasında %70'e ulaşmadığımı görüyorum. Tamam, yani hiçbir şey kaybetmedik. Hadi sıfırlayalım. Ve tekrar kurtarıyoruz. Bir sonraki anlık görüntü 70'in altındaysa, büyük olasılıkla yine hiçbir şey kaybetmemişsinizdir.
Evet. Varsayılan sayı artık 5'dir ve bu birçok kişi için yeterlidir.
Genellikle evet.
Video:

Not: Kendi adıma şunu ekleyeyim, eğer Postgres gizli veri içeriyorsa ve test ortamına dahil edilemiyorsa o zaman Postgres'i kullanabilirsiniz. . Şema yaklaşık olarak aşağıdaki gibidir:
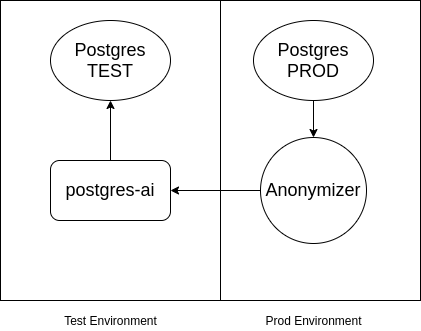
Kaynak: habr.com
