

Bu makale zaten yüksek hızlı veri sıkıştırma konusundaki ikinci makaledir. İlk makalede 10 GB/sn hızında çalışan bir kompresör anlatılmıştı. işlemci çekirdeği başına (minimum sıkıştırma, RTT-Min).
Bu sıkıştırıcı, depolama ortamı dökümlerinin yüksek hızda sıkıştırılması ve kriptografinin gücünün arttırılması için adli kopyalayıcıların ekipmanına halihazırda uygulanmıştır; aynı zamanda sanal makinelerin ve RAM takas dosyalarının görüntülerini yüksek hızda kaydederken sıkıştırmak için de kullanılabilir; SSD sürücüler.
İlk makale ayrıca, HDD ve SSD disk sürücülerinin yedek kopyalarını (orta sıkıştırma, RTT-Mid) önemli ölçüde geliştirilmiş veri sıkıştırma parametreleriyle sıkıştırmak için bir sıkıştırma algoritmasının geliştirildiğini duyurdu. Şu anda bu kompresör tamamen hazırdır ve bu makale bununla ilgilidir.
RTT-Mid algoritmasını uygulayan bir kompresör, yüksek hızlı modda çalışan WinRar, 7-Zip gibi standart arşivleyicilerle karşılaştırılabilir bir sıkıştırma oranı sağlar. Aynı zamanda, çalışma hızı en azından bir kat daha yüksektir.
Veri paketleme/paketten çıkarma hızı, sıkıştırma teknolojilerinin uygulama kapsamını belirleyen kritik bir parametredir. Herhangi birinin bir terabayt veriyi saniyede 10-15 MegaByte hızında sıkıştırmayı düşünmesi pek olası değildir (bu tam olarak standart sıkıştırma modundaki arşivleyicilerin hızıdır), çünkü tam işlemci yüküyle neredeyse yirmi saat sürer.. .
Öte yandan aynı terabayt, saniyede 2-3 Gigabayt düzeyindeki hızlarla yaklaşık on dakikada kopyalanabiliyor.
Bu nedenle, büyük hacimli bilgilerin sıkıştırılması, gerçek giriş/çıkış hızından daha düşük olmayan bir hızda gerçekleştiriliyorsa önemlidir. Modern sistemler için bu, saniyede en az 100 Megabayttır.
Modern kompresörler bu hızları yalnızca "hızlı" modda üretebilir. Bu mevcut modda RTT-Mid algoritmasını geleneksel kompresörlerle karşılaştıracağız.
Yeni bir sıkıştırma algoritmasının karşılaştırmalı testi
RTT-Mid kompresörü test programının bir parçası olarak çalıştı. Gerçek bir "çalışan" uygulamada çok daha hızlı çalışır, çoklu iş parçacıklarını akıllıca kullanır ve C# yerine "normal" bir derleyici kullanır.
Karşılaştırmalı testte kullanılan kompresörler farklı prensipler üzerine kurulduğundan ve farklı veri türleri farklı şekilde sıkıştırıldığından, testin objektifliği için "hastanedeki ortalama sıcaklığı" ölçme yöntemi kullanıldı...
İşletim sistemini içeren mantıksal diskin sektör sektör döküm dosyası oluşturuldu. Windows 10Bu, her bilgisayarda bulunan çeşitli veri yapılarının en doğal birleşimidir. Bu dosyayı sıkıştırmak, yeni algoritmanın hızını ve sıkıştırma oranını, modern arşivleme programlarında kullanılan en gelişmiş sıkıştırıcılarla karşılaştırmamızı sağlayacaktır.
İşte döküm dosyası:
Döküm dosyası PTT-Mid, 7-zip ve WinRar sıkıştırıcıları kullanılarak sıkıştırılmıştır. WinRar ve 7-zip kompresörü maksimum hıza ayarlandı.
Kompresör çalışıyor 7-zip:
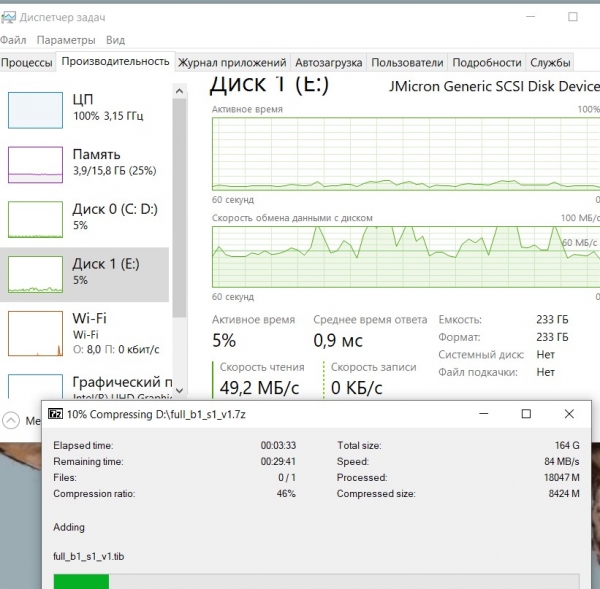
İşlemciyi %100 oranında yüklerken orijinal dökümü okumanın ortalama hızı yaklaşık 60 MegaBytes/sn'dir.
Kompresör çalışıyor WinRAR:
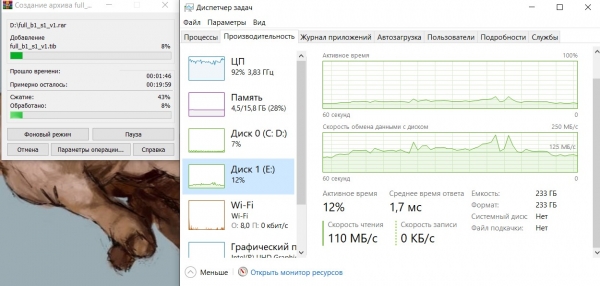
Durum benzer, işlemci yükü neredeyse %100, ortalama döküm okuma hızı yaklaşık 125 Megabayt/sn.
Önceki durumda olduğu gibi arşivleyicinin hızı işlemcinin yetenekleriyle sınırlıdır.
Kompresör test programı şu anda çalışıyor RTT-Orta:
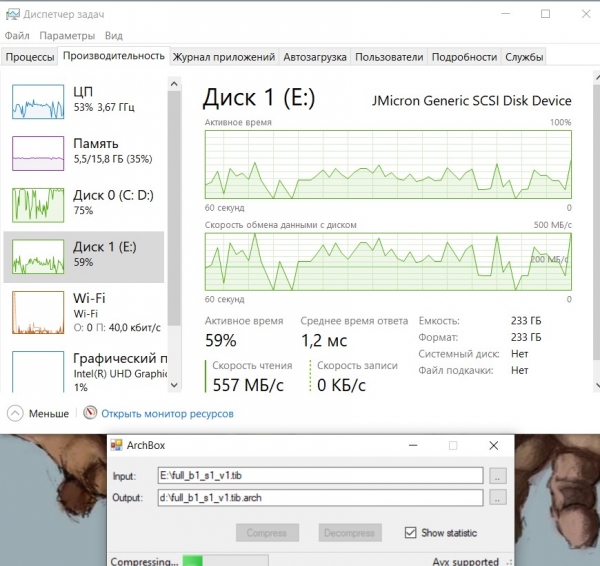
Ekran görüntüsü, işlemcinin %50 oranında yüklendiğini ve sıkıştırılmış verileri yükleyecek hiçbir yer olmadığından geri kalan süre boyunca boşta olduğunu gösteriyor. Veri yükleme diski (Disk 0) neredeyse tamamen yüklenmiştir. Veri okuma hızı (Disk 1) büyük ölçüde değişiklik gösterir ancak ortalama olarak 200 MegaBytes/sn'nin üzerindedir.
Bu durumda kompresörün hızı, sıkıştırılmış verileri Disk 0'a yazabilme özelliğiyle sınırlıdır.
Şimdi ortaya çıkan arşivlerin sıkıştırma oranı:



RTT-Mid sıkıştırıcının en iyi sıkıştırma işini yaptığı görülüyor; oluşturduğu arşiv WinRar arşivinden 1,3 GigaByte ve 2,1z arşivinden 7 GigaByte daha küçüktü.
Arşivi oluşturmak için harcanan süre:
- 7-zip – 26 dakika 10 saniye;
- WinRar – 17 dakika 40 saniye;
- RTT-Orta – 7 dakika 30 saniye.
Böylece, RTT-Mid algoritmasını kullanan optimize edilmemiş bir test programı bile iki buçuk kattan daha hızlı bir arşiv oluşturmayı başardı ve arşivin rakiplerine göre önemli ölçüde daha küçük olduğu ortaya çıktı...
Ekran görüntülerine inanmayanlar, gerçekliğini kendileri kontrol edebilir. Test programı şu adreste mevcuttur: , indirin ve kontrol edin.
Ancak yalnızca AVX-2 destekli işlemcilerde, bu talimatların desteği olmadan kompresör çalışmaz ve algoritmayı eski AMD işlemcilerde test etmezler, AVX talimatlarını yürütme açısından yavaştırlar...
Kullanılan sıkıştırma yöntemi
Algoritma, tekrarlanan metin parçalarını bayt ayrıntı düzeyinde indekslemek için bir yöntem kullanır. Bu sıkıştırma yöntemi uzun zamandır biliniyordu ancak eşleştirme işleminin gerekli kaynaklar açısından çok pahalı olması ve sözlük oluşturmaktan çok daha fazla zaman gerektirmesi nedeniyle kullanılmadı. Yani RTT-Mid algoritması "geleceğe dönüş"ün klasik bir örneği...
PTT sıkıştırıcı, sıkıştırma sürecini hızlandırmamıza olanak tanıyan benzersiz bir yüksek hızlı eşleşme arama tarayıcısı kullanır. Kendi kendine yapılan bir tarayıcı, bu "benim cazibem...", "oldukça pahalı, çünkü tamamen el yapımı" (montajcıda yazılmış).
Maç arama tarayıcısı iki seviyeli olasılık şemasına göre yapılır: ilk olarak, bir eşleşmenin "işaretinin" varlığı taranır ve yalnızca bu yerde "işaret" tanımlandıktan sonra gerçek bir eşleşmeyi tespit etme prosedürü uygulanır. Başladı.
Eşleşme arama penceresi, işlenen veri bloğundaki entropi derecesine bağlı olarak öngörülemeyen bir boyuta sahiptir. Tamamen rastgele (sıkıştırılamaz) veriler için megabayt boyutundadır, tekrarlanan veriler için her zaman bir megabayttan büyüktür.
Ancak birçok modern veri formatı sıkıştırılamaz ve yoğun kaynak kullanan bir tarayıcıyı bunlar üzerinden çalıştırmak yararsız ve israftır, bu nedenle tarayıcı iki çalışma modu kullanır. Öncelikle kaynak metnin tekrarlanma ihtimali olan bölümleri aranır; bu işlem de olasılıksal bir yöntemle gerçekleştirilir ve çok hızlı bir şekilde (4-6 GigaBytes/sn) gerçekleştirilir. Olası eşleşmelerin olduğu alanlar daha sonra ana tarayıcı tarafından işlenir.
Dizin sıkıştırması çok verimli değildir, yinelenen parçaları dizinlerle değiştirmeniz gerekir ve dizin dizisi sıkıştırma oranını önemli ölçüde azaltır.
Sıkıştırma oranını artırmak için, bayt dizelerinin yalnızca tam eşleşmeleri değil, aynı zamanda dize eşleşen ve eşleşmeyen baytlar içerdiğinde kısmi olanlar da dizine eklenir. Bunu yapmak için indeks formatı, iki bloğun eşleşen baytlarını gösteren bir eşleşme maskesi alanı içerir. Daha da fazla sıkıştırma için, kısmen eşleşen birkaç bloğu geçerli bloğun üzerine yerleştirmek için indeksleme kullanılır.
Bütün bunlar, PTT-Mid kompresöründe sözlük yöntemi kullanılarak yapılan ancak çok daha hızlı çalışan kompresörlerle karşılaştırılabilir bir sıkıştırma oranı elde etmeyi mümkün kıldı.
Yeni sıkıştırma algoritmasının hızı
Kompresör özel önbellek kullanımıyla çalışıyorsa (iş parçacığı başına 4 Megabayt gerekir), bu durumda çalışma hızı 700-2000 Megabayt/sn arasında değişir. sıkıştırılan verinin türüne bağlıdır ve işlemcinin çalışma frekansına çok az bağlıdır.
Sıkıştırıcının çok iş parçacıklı bir uygulamasıyla etkili ölçeklenebilirlik, üçüncü düzey önbelleğin boyutuna göre belirlenir. Örneğin, 9 MegaByte önbellek "yerleşik" olduğunda, ikiden fazla sıkıştırma iş parçacığı başlatmanın bir anlamı yoktur; hız bundan artmayacaktır. Ancak 20 Megabaytlık bir önbellekle zaten beş sıkıştırma iş parçacığını çalıştırabilirsiniz.
Ayrıca RAM'in gecikmesi kompresörün hızını belirleyen önemli bir parametre haline gelir. Algoritma OP'ye rasgele erişim kullanır, bunların bir kısmı önbelleğe girmez (yaklaşık %10) ve OP'den veri bekleyerek boşta kalması gerekir, bu da işlem hızını azaltır.
Giriş/çıkış sistemi, sıkıştırma hızını önemli ölçüde etkiler. RAM'e yapılan giriş/çıkış istekleri, CPU'nun veri isteklerini engeller ve bu da sıkıştırma hızını düşürür. Bu sorun, dizüstü ve masaüstü bilgisayarlar için önemlidir. sunucular Daha gelişmiş bir sistem veri yolu erişim kontrol ünitesi ve çok kanallı RAM sayesinde önemi daha azdır.
Makalede metin boyunca sıkıştırmadan bahsediyoruz; “her şey çikolatayla kaplı” olduğundan dekompresyon bu makalenin kapsamı dışında kalıyor. Sıkıştırmayı açma çok daha hızlıdır ve G/Ç hızıyla sınırlıdır. Tek iş parçacığı içindeki bir fiziksel çekirdek, kolaylıkla 3-4 GB/sn'lik paket açma hızları sağlar.
Bunun nedeni, sıkıştırma sırasında işlemcinin ve önbelleğin ana kaynaklarını "tükenen" açma işlemi sırasında bir eşleşme arama işleminin bulunmamasıdır.
Sıkıştırılmış veri depolamanın güvenilirliği
Veri sıkıştırmayı (arşivleyiciler) kullanan tüm yazılım sınıfının adından da anlaşılacağı gibi, bunlar bilgilerin yıllarca değil, yüzyıllar ve bin yıllar boyunca uzun vadeli depolanması için tasarlanmıştır...
Depolama sırasında depolama ortamı bazı verileri kaybeder; işte bir örnek:

Bu "analog" bilgi taşıyıcısı bin yıllıktır, bazı parçaları kaybolmuştur, ancak genel olarak bilgi "okunabilir"dir...
Modern dijital veri depolama sistemleri ve dijital medyanın sorumlu üreticilerinden hiçbiri, 75 yılı aşkın bir süre boyunca tam veri güvenliği garantisi vermiyor.
Bu da bir sorundur ama ertelenmiş bir sorundur, bunu torunlarımız çözecektir...
Dijital veri depolama sistemleri sadece 75 yıl sonra veri kaybedebilir, verilerdeki hatalar her an ortaya çıkabilir, hatta kayıt sırasında bile ortaya çıkabilir, bu bozulmaları yedeklilik kullanarak ve hata düzeltme sistemleriyle düzelterek en aza indirmeye çalışırlar. Yedekleme ve düzeltme sistemleri, kaybolan bilgileri her zaman geri yükleyemez ve bunu yapmaları durumunda, geri yükleme işleminin doğru şekilde tamamlandığının garantisi yoktur.
Bu da büyük bir sorun ama ertelenmiş değil, güncel bir sorun.
Dijital verileri arşivlemek için kullanılan modern sıkıştırıcılar, sözlük yönteminin çeşitli modifikasyonları üzerine kurulmuştur ve bu tür arşivler için bir parça bilginin kaybı ölümcül bir olay olacaktır; hatta böyle bir durum için yerleşik bir terim vardır - "bozuk" bir arşiv. ...
Sözlük sıkıştırmalı arşivlerde bilgi saklamanın düşük güvenilirliği, sıkıştırılmış verilerin yapısıyla ilişkilidir. Böyle bir arşivdeki bilgiler kaynak metni içermez, sözlükteki girişlerin sayısı burada saklanır ve sözlüğün kendisi mevcut sıkıştırılmış metin tarafından dinamik olarak değiştirilir. Bir arşiv parçası kaybolur veya bozulursa, sözlük giriş numarasının neye karşılık geldiği belli olmadığından sonraki tüm arşiv girişleri içerik veya sözlükteki girişin uzunluğu ile tanımlanamaz.
Böyle "bozuk" bir arşivden bilgileri geri yüklemek imkansızdır.
RTT algoritması, sıkıştırılmış verileri depolamak için daha güvenilir bir yönteme dayanmaktadır. Tekrarlanan parçalar için indeks muhasebe yöntemini kullanır. Sıkıştırmaya yönelik bu yaklaşım, depolama ortamındaki bilgilerin bozulmasının sonuçlarını en aza indirmenize ve çoğu durumda bilgi depolama sırasında ortaya çıkan bozulmaları otomatik olarak düzeltmenize olanak tanır.
Bunun nedeni, indeks sıkıştırması durumunda arşiv dosyasının iki alan içermesidir:
- tekrarlanan bölümlerin kaldırıldığı bir kaynak metin alanı;
- dizin alanı.
Bilgi kurtarma için kritik olan indeks alanının boyutu büyük değildir ve güvenilir veri depolama için kopyalanabilir. Bu nedenle, kaynak metnin veya dizin dizisinin bir parçası kaybolsa bile, diğer tüm bilgiler, "analog" bir depolama ortamındaki resimde olduğu gibi sorunsuz bir şekilde geri yüklenecektir.
Algoritmanın dezavantajları
Dezavantajları olmadan avantajları yoktur. İndeks sıkıştırma yöntemi kısa tekrar eden dizileri sıkıştırmaz. Bunun nedeni indeks yönteminin sınırlamalarıdır. Dizinlerin boyutu en az 3 bayttır ve 12 bayta kadar olabilir. Eğer onu tanımlayan indeksten daha küçük boyutta bir tekrarla karşılaşılırsa, bu tür tekrarlar sıkıştırılmış dosyada ne sıklıkta tespit edilirse edilsin dikkate alınmaz.
Geleneksel sözlük sıkıştırma yöntemi, kısa uzunluktaki birden çok tekrarı etkili bir şekilde sıkıştırır ve bu nedenle indeks sıkıştırmaya göre daha yüksek bir sıkıştırma oranına ulaşır. Doğru, bu, merkezi işlemci üzerindeki yüksek yük nedeniyle elde edilir; sözlük yönteminin verileri indeks yönteminden daha verimli bir şekilde sıkıştırmaya başlaması için, veri işleme hızını gerçekte saniyede 10-20 megabayta düşürmesi gerekir. tam CPU yüküne sahip bilgi işlem kurulumları.
Bu kadar düşük hızlar, modern veri depolama sistemleri için kabul edilemez ve pratikten çok "akademik" ilgi çekicidir.
Halihazırda geliştirilmekte olan RTT algoritmasının (RTT-Max) bir sonraki modifikasyonunda bilgi sıkıştırma derecesi önemli ölçüde artırılacaktır.
Her zaman olduğu gibi Devamı...
Kaynak: habr.com
