

Bu not, R - data.table için tablolu veri işleme kitaplığını kullananların ilgisini çekecektir ve çeşitli örneklerde kullanımının esnekliğini görmekten memnun olabilir.
İyi bir örnekten ilham aldık ve makalesini zaten okumuş olduğunuzu umuyorum, kod optimizasyonuna ve performansa dayalı olarak daha derinlere inmeyi öneriyorum. veri tablosu.
Giriş: data.table nereden geliyor?
Kütüphaneyi biraz uzaktan, yani data.table nesnesinin (bundan sonra DT olarak anılacaktır) elde edilebileceği veri yapılarını tanımaya başlamak en iyisidir.
sıra
Kod
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Böyle bir yapı bir dizidir (?temel::dizi). Diğer dillerde olduğu gibi burada da diziler çok boyutludur. Ancak ilginç olan, örneğin iki boyutlu bir dizinin, matris sınıfından özellikler devralmaya başlamasıdır. (?taban::matris) ve tek boyutlu bir dizi, ki bu da önemlidir, bir vektörden miras almaz (?temel::vektör).
Herhangi bir nesnede bulunan veri türünün, işlev kullanılarak kontrol edilmesi gerektiği anlaşılmalıdır. temel::typeofgöre dahili tür açıklamasını döndüren R Dahili - orijinalle ilişkili dilin genel protokolü C.
Bir nesnenin sınıfını belirlemek için başka bir komut temel::sınıf, vektörler söz konusu olduğunda, vektör türünü döndürür (adı dahili olandan farklıdır, ancak aynı zamanda veri türünü anlamanıza da olanak tanır).
Liste
Matris olarak da bilinen iki boyutlu bir diziden listeye gidebilirsiniz (?temel::liste).
Kod
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Aynı anda birkaç şey olur:
- Matrisin ikinci boyutu çöker, yani aynı anda hem liste hem de vektör elde ederiz.
- Böylece liste bu sınıflardan miras alır. Bir liste öğesinin dizi matrisinin bir hücresindeki bir (skaler) değere karşılık geleceği akılda tutulmalıdır.
Liste aynı zamanda bir vektör olduğundan bazı vektör fonksiyonları ona uygulanabilir.
Veri çerçevesi
Bir listeden, matristen veya vektörden veri çerçevesine (?base::data.frame).
Kod
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
İlginç olan şey: veri çerçevesi listeden miras alıyor! Veri çerçevesi sütunları liste hücreleridir. Bu daha sonra listelere uygulanan işlevleri kullandığımızda önemli olacaktır.
veri tablosu
DT'yi alın (?veri.tablo::veri.tablo) itibaren olabilir veri çerçevesi, liste, vektör veya matris. Mesela şöyle (yerinde).
Kod
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Bir veri çerçevesi gibi bir DT'nin de bir listenin özelliklerini devralması kullanışlıdır.
CE ve bellek
R tabanındaki diğer tüm nesnelerin aksine, CE'ler referans yoluyla iletilir. Yeni bir hafıza alanına kopyalama yapmanız gerekiyorsa, bir işleve ihtiyacınız vardır. veri.tablo::kopyala ya da eski nesneden seçim yapmanız gerekiyor.
Kod
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Bu, girişi tamamlıyor. DT, esas olarak veri çerçevesi sınıfının nesneleri üzerinde gerçekleştirilen işlemlerin genişletilmesi ve hızlandırılması nedeniyle ortaya çıkan R'deki veri yapılarının gelişiminin bir devamıdır. Aynı zamanda diğer ilkellerden miras da korunur.
data.table özelliklerinin kullanımına ilişkin bazı örnekler
Liste gibi...
Bir veri çerçevesinin veya DT'nin satırları üzerinde yineleme yapmak iyi bir fikir değildir, çünkü dildeki döngü kodu R çok daha yavaş C, ancak genellikle çok daha küçük olan sütunlar arasında geçiş yapmak oldukça mümkündür. Sütunları incelerken, her sütunun genellikle bir vektör içeren bir listenin öğesi olduğunu unutmayın. Ve vektörler üzerindeki işlemler, dilin temel işlevlerinde iyi bir şekilde vektörleştirilmiştir. Listelerde ve vektörlerde ortak olan seçim işleçlerini de kullanabilirsiniz: '[[', '$'.
Kod
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
vektörleştirme
Büyük bir CE'nin satırlarının üzerinden geçme ihtiyacı varsa en iyi çözüm, vektörleştirmeli bir fonksiyon yazmak olacaktır. Ancak bu işe yaramazsa, o zaman döngünün içinde DT hâlâ döngüden daha hızlı Rtarihinde gerçekleştirildiğinden C.
100K satırlı daha büyük bir örnek üzerinde deneyelim. Vektör sütununda yer alan kelimelerin ilk harfini çıkaracağız w.
Güncellenmiş
Kod
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
İlk önce satırlar üzerinde yineleme yaparak çalıştırın:
Birim: milisaniye
ifade dk.
{ dt[, `:=`(ilk_l, unlist(strsplit(w, split = " ", sabit = T))[1]), by = 1:nrow(dt)] } 439.6217
lq ortalama medyan uq max neval
+451.9998 460.1593 456.2505 460.9147 621.4042 100
Listeyi bir matrise dönüştürerek ve dilimdeki öğeleri 1 indeksiyle alarak vektörleştirmenin gerçekleştiği ikinci çalıştırma (ikincisi vektörleştirmenin kendisidir). Düzeltme: fonksiyon seviyesinde vektörleştirme strsplitbir vektörü girdi olarak kabul edebilir. Bir listeyi matrise dönüştürme prosedürünün vektörleştirmenin kendisinden çok daha zor olduğu ortaya çıktı, ancak bu durumda vektörleştirilmemiş versiyondan çok daha hızlı.
Birim: milisaniye
ifade min lq ortalama medyan uq maks neval
{ dt[, `:=`(ilk_l, .(ilk_l_f(w))))] } 93.07916 112.1381 161.9267 149.6863 +185.9893 442.5199 100
Ortancaya göre hızlanma 3 kez.
Matrise dönüşüm şemasının değiştirildiği üçüncü çalıştırma.
Birim: milisaniye
ifade min lq ortalama medyan uq maks neval
{ dt[, `:=`(ilk_l, .(ilk_l_f2(w))))] } 32.60481 34.13679 40.4544 35.57115 +42.11975 222.972 100
Ortancaya göre hızlanma 13 kez.
Bu konuyu denemeniz gerekiyor, ne kadar çok olursa o kadar iyi olur.
Metnin de bulunduğu ancak gerçek koşullara yakın olduğu vektörleştirmeye ilişkin başka bir örnek: farklı sözcük uzunlukları, farklı sayıda sözcük. İlk 3 kelimeyi bulmanız gerekiyor. Bunun gibi:
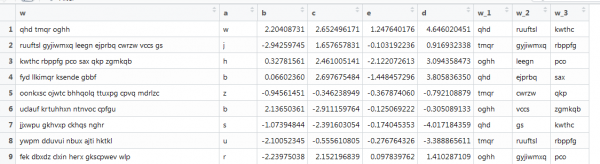
Burada önceki fonksiyon çalışmıyor çünkü vektörler farklı uzunluklarda ve biz matris boyutunu ayarlıyoruz. İnterneti araştırarak bunu tekrarlayalım.
Kod
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Birim: milisaniye
ifade min lq ortalama medyan
{ dt[, `:=`((paste0(“w_”, 1:3))), strsplit(w, split = " ", sabit = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
+1178.738 1356.816 100
Komut dosyası ortalama 1 saniyelik bir hızda çalıştı. Fena değil.
Tek zincirle bağlı...
Zincirlemeyi kullanarak DT nesneleriyle çalışabilirsiniz. Parantez sözdizimini sağa, aslında şekere eklemek gibi görünüyor.
Kod
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Borulardan akıyor...
Aynı işlemler borulama yoluyla da yapılabilir, benzer görünür ancak işlevsel olarak daha zengindir, çünkü yalnızca DT'yi değil herhangi bir yöntemi kullanabilirsiniz. DT'de bir takım filtreler kullanarak sentetik verilerimiz için lojistik regresyon katsayılarını türetelim.
Kod
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
DT'de istatistikler, makine öğrenimi ve daha fazlası
Lambda işlevlerini kullanabilirsiniz, ancak bazen bunları ayrı ayrı oluşturmak, tüm veri analizi hattını yazmak ve devam etmek daha iyidir; bunlar DT'nin içinde çalışır. Örnek, yukarıdaki tüm özelliklerin yanı sıra DT cephaneliğinden birkaç faydalı şeyle zenginleştirilmiştir (örneğin, DT'nin kendisine DT'nin içine bir bağlantı yoluyla erişmek, bazen sıralı olarak değil, öyle olacak şekilde eklemek gibi).
Kod
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
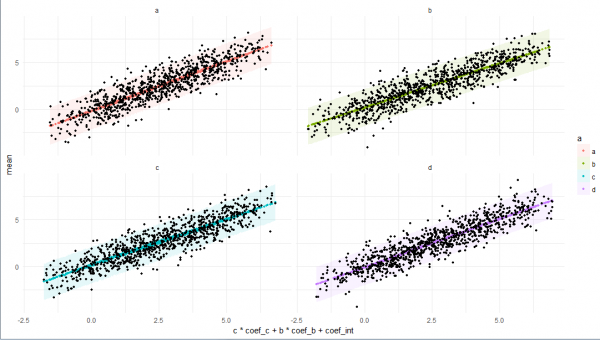
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Sonuç
Umarım data.table gibi bir nesnenin, R sınıflarından kalıtımla ilişkili özelliklerinden başlayıp, düzenli öğelerden kendi özellikleri ve ortamıyla biten eksiksiz, ancak elbette tam olmayan bir resmini oluşturabilmişimdir. . Umarım bu, bu kütüphaneyi daha iyi öğrenmenize ve iş için kullanmanıza yardımcı olur. eğlence.
Teşekkürler!
Tam kod
Kod
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Kaynak: habr.com
