

Bir zamanlar blogumuzda gündeme getirilen konunun devamı olarak Makine öğreniminin buna nasıl ve hangi biçimde uygulanabileceğinden bahsedelim. Deneyiminiz ve buna göre seçilen çözümler Apex Oyun Araçları AI uzmanı Jakob Rasmussen.

Son yıllarda makine öğreniminin oyun endüstrisini nasıl kökten değiştireceği hakkında çok fazla konuşma yapılıyor çünkü bu teknoloji halihazırda diğer birçok dijital uygulamada bir atılım haline geldi. Ancak oyunların bir araba sürüş simülatöründen, bir drone kontrol programından veya bir görüntüdeki yüz tanıma algoritmalarından çok daha karmaşık olduğunu unutmayın.
Şimdilik, oyun endüstrisinde sonlu durum makine yöntemi, davranış ağaçları ve giderek daha yakın zamanda Yardımcı Program Tabanlı Yapay Zeka (yardımcı program tabanlı sistemler) gibi geleneksel yapay zeka yöntemlerinin kullanılması hala yaygındır. Bu tür yapay zekalara aynı zamanda tasarım tabanlı (yapay tasarım zekası) veya uzman sistemler de denir. Ancak bu sistemlerin, oyuncu davranışını taklit edebilecek gerçekten gelişmiş rakipler yaratmaya giderek daha az uygun hale geldiği, özellikle de oyuncular için, giderek daha açık hale geliyor. Bu özellikle yaratıcı çözümler için geçerlidir. Bu durum, yapay zeka geliştiricilerinin olası tüm taktik ve davranış stratejilerini dikkate alıp bunları geleneksel yapay zeka sistemlerinde başarılı bir şekilde uygulayamamasıyla açıklanabilir. Oyuncular için bu genellikle davranışlarını hatırlaması kolay bir rakibe karşı sıkıcı ve öngörülebilir bir oyunla sonuçlanır.
Bu sonucun pek çok nedeni var ancak en önemlilerinden biri yapay zekanın öğrenememesi. Dolayısıyla düşmanın yapay zekasını oluştururken doğal olarak birçok uygulamada kendini kanıtlamış olan makine öğrenmesine geçme kararı akla geliyor. Ancak dikkate alınmaya değer birkaç nüans var. Bu nedenle, oyun yapay zekası her duruma uyum sağlayabilmeli ve sağladığı avantajları kullanabilmeli, ayrıca rakiplerin farklı oyun tarzlarına (canlı oyuncular ve diğer yapay zeka) uyum sağlayabilmelidir.
Şimdi işler nasıl?
Birleşik Krallık merkezli yapay zeka şirketi DeepMind yakın zamanda yapay zekaların kendi başlarına oyun oynamayı nasıl öğrenebileceğini, kuralları içselleştirebileceğini ve oyunu yenmenin veya yenmenin yollarını bulabileceğini gösterdi; ancak şu ana kadar yalnızca ilk oyunlar gibi basit oyunları kullanıyorlar - örneğin satranç ve Japon mantık oyunu Go. Onlar için elde edilen sonuçlar, yapay zekanın sahada olup bitenlere ilişkin yeterli bir değerlendirme oluşturabildiğini gösteriyor. Yapay zekanın rakibin farklı oyun tarzlarına uyarlanmasından bahsedecek olursak, sonuçlar şu ana kadar pek etkileyici değil.
Günümüzde sinir ağları görüntüleri tanımayı ve araba sürmeyi çoktan öğrendi. Ancak bu işlevler, sonuç olarak oldukça derin ve hacimli olsalar bile, nispeten basit mimariler kullanılarak gerçekleştirilebilir. Bu nedenle, Facebook'ta görüntü tanımaya yönelik yapay zekanın yaklaşık 100 katman derinliği vardır, bu nedenle büyük bir ağ oluşturan nöronlar arasındaki ilişkilerin sayısı ve karmaşıklığı açısından biyolojik bir beyne benzemektedir.
Oyun Yapay Zekası
Makine öğreniminin oyun endüstrisindeki uygulamasına ilişkin olarak, bu tür mimariyi kullanmanın her zaman mümkün olmaması nedeniyle bir takım sınırlamalar bulunmaktadır. Bunlar, bilgisayarın karmaşık oyun yapısını idare etme yeteneğini ve oyun hikayesi anlatımı ve oynanışa uygunluğunu belirleyen, özellikle CPU ile ilgili sistem gereksinimlerini içerir.
Dolayısıyla, birçok oyunda, karmaşık bir yapay zeka sistemini uygulamak için gerekli donanımı, örneğin Facebook'taki görüntü tanıma ağları için var olan bir sunucu kümesini bile organize etmenin mümkün olmadığı ortaya çıktı. Bazen birkaç yapay zekanın aynı anda çalışması gerekir; üstelik yalnızca bilgisayarlarda değil, mobil cihazlarda ve daha az üretken platformlarda da. Tüm bunlar, makine öğrenimi mimarisinin boyutuna ve karmaşıklığına kısıtlamalar getiriyor çünkü tüm hesaplamaların yaklaşık 1 veya 2 milisaniyelik bir çerçeve süresiyle de yapılması gerekiyor. Elbette çeşitli optimizasyon teknolojilerini kullanabilir ve yükü çerçeveler arasında dağıtabilirsiniz ancak yine de bu sınırlamalardan tamamen kurtulamazsınız.
Oyunun zorluğu yapay zeka için ciddi sorunlara neden olabiliyor. Aslında StarCraft II gibi oyunlarda oyun mekaniği Atari oyunlarına göre kat kat daha karmaşıktır. Bu nedenle, belirli bir kare hızında ve bilinen sistem gereksinimlerinde, makine öğreniminin mutlaka oyunun tüm durumunu inceleyebilmesini ve onunla etkileşime girebilmesini beklememelisiniz. Oyuncunun oyunun ilk aşamalarında sıklıkla sezgilerle yönlendirildiği gibi, yapay zekanın da daha sonraki geçişi basitleştirmek için başlangıçta oyunun durumunu işlemeyi öğrenmesi gerekiyor. Örneğin sonunculardan birinde haritalar yalnızca geliştiricilerin önemli olduğunu düşündüğü bilgileri gösteriyor: Bir durumda, AI tüm harita alanının uzaklaştırılmış bir görünümünü kullandı, ikincisinde ise oyuncu gibi kamerayı hareket ettirebildi ve ardından algısını kullandı. ekrandaki bilgilerle sınırlıydı.
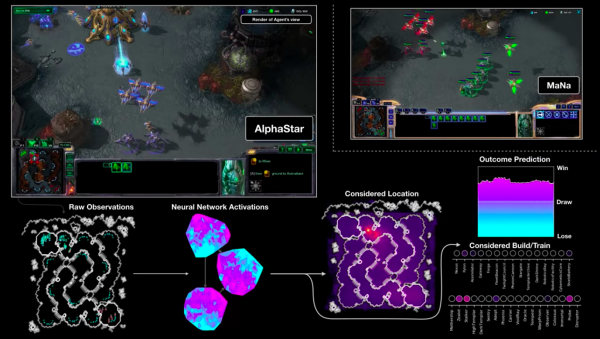
StarSraft II'de AlphaStar AI ile oyuncu arasındaki görselleştirme: ekran görüntüsü ham gözlemleri, sinir ağı etkinliğini, bazı olası eylemlerini ve koordinatlarını ve maçın beklenen sonucunu gösterir
Bu özellikle oyunlar söz konusu olduğunda önemli bir husustur. Genellikle, makine öğrenimi problemlerini çözmek için genel kabul görmüş yöntemler, oyun yapay zekası için geçerli değildir. Örneğin, Atari oyunlarında olduğu gibi genellikle kazanmasına veya kazanmak için ne gerekiyorsa yapmasına gerek yoktur. Yapay zekanın rolü çoğu zaman oyunu daha heyecanlı hale getirmektir. Sorumlu olduğu karaktere uygun bir rol oynaması ve davranması gerekebilir. Bu nedenle, oyun yapay zekaları oyun tasarımına ve hikaye anlatımına daha fazla bağlıdır ve belirli bir hedefe ulaşmak için davranışlarını kontrol etmek için gerekli araçlara sahip olmalıdır. Makine öğrenimi saf haliyle buna her zaman uygun değildir, bu da başka bir şey aramanız gerektiği anlamına gelir.
Makine öğreniminin pratik sorunları
Bu sorunlar, makine öğrenimine dayalı yapay zekanın geliştirilmesiyle ortaya çıktı. Yapay zekanın normal oyuncular gibi davranması, yani aynı derecede esnek ve becerikli olması gerekir.
Starcraft II gibi Unleashed da Atari satrancı ve Go'dan çok daha karmaşıktır. Oynanış sezgiseldir ve öğrenmesi kolaydır, ancak bunda gerçekten başarılı olmak için bazı meta yönetim becerileri gerekir. Oyuncu, oyun boyunca labirentler inşa etmeli, canavarları düşmanların üzerine yerleştirmeli ve ekonomi, yapılara saldırı ve savunma konusundaki stratejisini düşünmelidir. Bunu yapmak için, blöf yapması ve diğer insanların hamlelerini önceden hesaplaması ve ayrıca psikolojik metayı yönetmesi gerekiyor - pokeri istatistiksel bir oyundan daha fazlası yapan da budur.

Unleashed'in ekran görüntüsü
Bu amaçlara en uygun mimari arayışında, gibi teknolojiler ve derin öğrenmeyi test etti ve düşman yapay zekası olarak ham hallerinde nasıl performans göstereceklerini test etti.
Berbattı.
Unleashed'ın makine öğrenimini uyarlamanın zor olduğu birçok küresel sorunu çözmesi gerektiği kısa sürede anlaşıldı.
Bunlardan biri etkili bir labirent inşa etmektir. Amacın bir kuleyi savunmak olduğu birçok oyunda olduğu gibi, burada da oyuncuların kulenin etrafına canavarların geçebileceği bir labirent inşa etmeleri gerekiyor. Onların da labirent boyunca yerleştirilen silahlar kullanılarak ortadan kaldırılması gerekiyor. İdeal olarak, canavarlara yeterince hasar vermek ve onların kuleye ulaşmasını engellemek için labirentin mümkün olduğu kadar uzun olması gerekir. Canavarlar bazı silahlara karşı diğerlerinden daha savunmasızdır, bu yüzden daha etkili olabilmeleri için labirente herkesten önce yerleştirilmelidirler. Unleash'in tuhaflığı, ideal bir labirentin olmamasıdır: Oyunda o kadar çok canavar türü vardır ki, bunlardan biri şu ya da bu şekilde labirentin herhangi bir bölümünden kolayca geçecektir. Herhangi bir labirent, diğer oyuncular tarafından başlatılan yeni canavarlara uyarlanmalıdır. Yani mesele sadece yapay zekaya labirentlerin nasıl inşa edileceğini öğretmek değildi; oyunun hem erken hem de geç versiyonlarında karşılaşılabilecek çeşitli senaryolar için etkili labirentlerin nasıl oluşturulacağını öğretmekle ilgiliydi.
Yapay zekanın labirentte hangi canavarların görüneceğini hesaplamayı da öğrenmesi gerekiyordu. Bu labirent inşa etmenin tam tersi bir problemdir. Diğer birçok oyunda olduğu gibi, Unleash'te de sadece bir ordu kurup onu düşmanın kampına göndermek yeterli değil: aynı zamanda düşmanın savunmasını gözetlemeniz ve orduyu, düşmanın zayıf noktalarını vuracak şekilde yapılandırmanız da gerekiyor. mümkün olduğu kadar etkili bir şekilde. Canavar ordusu, labirenti en başarılı şekilde geçebilecek şekilde birbirleriyle etkileşime girmelidir. Bazen canavarların işlevlerine ve rollerine bağlı olarak belirli bir sırayla serbest bırakılması da gerekir. Bu aynı zamanda farklı kombinasyonların sayısını da artırır.
Son olarak, oyuncunun hem labirentler yaratması hem de canavarlardan oluşan bir ordu kurması gerektiğinden, yapay zekanın da hücum ve savunmayı nasıl dengeleyeceğini öğrenmesi gerekiyor. Ayrıca, bir oyuncunun ne kadar çok canavar ordusu kurarsa ve ne kadar çok labirent inşa ederse, bunun için o kadar çok kaynağa ihtiyaç duyduğunu da dikkate almak gerekir. Bu nedenle doğru atak stratejisi hem oyun sırasında ekonomi hem de kazanma açısından son derece önemlidir. Rekabetçi olabilmek için yapay zeka, labirentin gücünden ödün vermeden güçlü bir canavar ordusu yaratacak şekilde kaynakları yönlendirebilmelidir. Canavarlara mümkün olduğunca fazla yatırım yapmak uygun maliyetli olabilir ancak düşman canavarların labirenti ele geçirme riskini artırır. Labirentin korunmasını güçlendirmeye güvenirseniz, bu ekonominizi felce uğratabilir. Bu senaryoların hiçbiri zafere yol açmayacak. Bu nedenle, Unleashed'deki optimizasyon sorununun satranç veya Starcraft durumunda olduğundan daha büyük olduğu ortaya çıkıyor ve bir şeyden fedakarlık etme ve kazancınızı birkaç adım önceden hesaplama ihtiyacını da içeriyor.
Yapay zeka eğitilirken, daha önce açıklanmayan birçok sorun ortaya çıkıyor. Böylece, ilk başta yapay zeka, oyunun belirli yönlerini anlamaya başladığı belirli bir gelişim düzeyine ulaştı - örneğin, labirentteki hangi silahların belirli canavar türlerine karşı etkili olduğu veya hangi canavarların en iyi olduğu labirentin belirli bölümlerini geçiyoruz. Ancak öğrenme yavaştı ve monoton stratejilerin geliştirilmesine yol açtı.
Paralel yaklaşımlara duyulan ihtiyaç
Makine öğrenimine dayalı yapay zeka eğitimi yavaş ve özellikle başarılı olmasa da, test ve geliştirmenin diğer aşamaları için daha iyi yapay zeka ve daha güçlü rakip yapay zeka gerekli hale geldi. Bunları uygulamak için, oyunun kalitesini test etmek ve kontrol etmek, oyun içi testler ve silahları ve canavarları dengelemek ve belirli labirentler ve canavarlar oluşturmak için özel yapay zeka oluşturabileceğiniz Yardımcı Program mimarisi kullanıldı. Bununla birlikte, Unleash'in geliştirilmesi sırasında, yaratıcılar bunu tamamlama becerilerini geliştirdiler ve ardından edindikleri bilgileri daha karmaşık bir Yardımcı Yapay Zeka oluşturmak için kullanmaya karar verdiler. Böylece, makine öğrenimine dayalı yapay zeka sistemlerinde ortaya çıkan birçok sorunun, içlerinde gömülü olan bilgiyi kullanan Faydalı sistemlerin yardımıyla (veya tam tersi) kolayca çözülebileceği ortaya çıktı.
Örneğin, dahili testlerin sonuçlarından derlenen bilgi tabanlarına dayanarak Yardımcı Yapay Zeka kullanarak daha verimli labirentler oluşturmak daha iyidir. Bir labirent inşa etme ve içine silah yerleştirme algoritmasını, yaşayan bir oyuncunun kuleyi belirli canavarlara karşı savunmasını kolaylaştıracak şekilde kolayca tanımlayabilir ve programlayabilirsiniz. Ancak, dikkate alınması gereken farklı koşulların ve kombinasyonların sayısı inanılmaz olduğundan, düşman üssünün bilgisine dayalı bir canavar ordusu yaratmak, bu tür yapay zeka için zor bir işti. Bu tür bir yapay zeka mimarisiyle uygun canavar gruplarını bulmak sonsuz zaman alacaktır. Daha sonra, verilen kısıtlamalar göz önüne alındığında, derin öğrenme bu sorun için ideal bir çözüm olacaktır.
Hibrit Yapay Zekalar Oluşturma
Bu nedenle, iki yaklaşımı birleştirmeye ve böylece makine öğrenimi ve Yardımcı Programa dayalı hibrit bir yapay zeka sistemi oluşturmaya karar verildi. Buradaki fikir, çok sayıda kombinasyonun ve oyun durumunun işlenmesinin gerekli olduğu veya ona bir şeyler öğretmenin gerekli olduğu yerlerde makine öğreniminin kullanılmasıydı. Geliştiricilerin kişisel deneyimlerine güvenmenin daha iyi olduğu diğer görevler için Yardımcı Sistemler kullanıldı. Bu yaklaşımın avantajı, gerekirse yapay zekanın davranışının, belirli bir hedefi daha doğru bir şekilde takip etmesini sağlamak için daha iyi kontrol edilebilmesidir. Örneğin, farklı düzeyde saldırganlık oluşturmak amacıyla hücum ve savunmayı dengelemek için Yardımcı Yapay Zeka'yı kullanabilir veya farklı yapay zekalar için farklı labirent konfigürasyonları oluşturarak onlara bireysel oyun tarzları oluşturabilirsiniz. Ayrıca hava veya kara canavarlarını işe alırken farklı tercihler oluşturmak için sinir ağlarına belirli değer sistemleri ayarlayabilir ve böylece bireysel yapay zekaya bireysellik katabilirsiniz. Tasarım kararlarını uygulamaya yönelik çok daha fazla seçenek var ve bunların tümü, bir veya başka türdeki yapay zeka mimarisinin güçlü yönlerini vurguluyor.
Hibrit yaklaşım aynı zamanda ekibin Unleash için yapay zekayı geliştirirken karşılaştığı başka bir soruyu da yanıtladı: Tüm girdileri ve çıktıları hesaba katmak için makine öğrenimine dayalı tek bir küresel derin sinir ağı mı kullanmalıyız yoksa yapay zekayı tasarlamak mı daha iyi? hiyerarşik bir yapıya sahip mi?
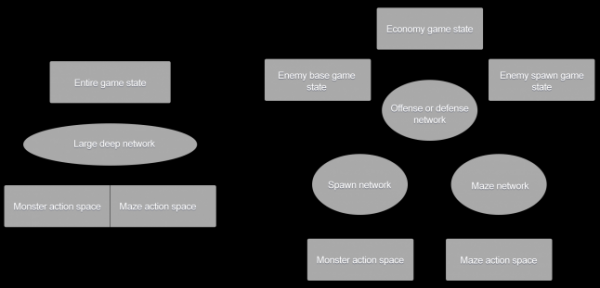
Unleash'te kullanılan iki mimari: solda kendi birleşik mimarisine sahip büyük bir derin sinir ağı, sağda ise her ağın kendi görevinin olduğu hiyerarşik bir sistem var
Yine de, geliştiricilerin kendi deneyimlerini mimarisine dahil etmeyecekleri bir yapay zeka sistemine genel bir yaklaşım oluşturmak istiyorum. Ancak oyuna ne kadar çok giriş yapıldıysa sinir ağı da o kadar büyüdü. Aynı zamanda yapay zekanın eğitimini ayırıp onlara tek bir şeyi öğretmek imkansızdı: savunma ya da saldırı. Daha genel bir yaklaşımın hesaplama sayısında önemli bir artışa yol açacağı yönünde endişeler vardı.
Her bir görevin özel bir sinir ağı tarafından yerine getirileceği hiyerarşik bir mimari oluşturma fikri burada ortaya çıktı. Bu fikre göre yapay zekanın öncelikle saldırı (canavar ordusunun arttırılması) ve savunma (labirent inşa edilmesi) için kaynak tahsisine karar vermesi gerekiyor. Bunu yaptıktan sonra kendi seçimine göre bir sonraki katmana geçer ve oyun durumunun gerekli kısmına erişim kazanır, ardından hangi canavarları seçeceğine ve labirentte hangi silahları kuracağına dair ayrıntılı kararlar verir.
Sonuç ve sonraki adımlar
Utility'nin hibrit yaklaşımında, makine öğrenimi tabanlı ağların dahil edildiği yapay zeka, hiyerarşik bir mimariye benziyor. Ve bu da, farklı sinir merkezlerinin her birinin kendi görevinden sorumlu olduğu biyolojik bir beyne benzer.
Şu anda, Unleash'teki düşman yapay zekasını yenmek çok zor: oyundaki herhangi bir duruma uyum sağlayabiliyorlar, ancak aynı zamanda geliştiriciler kendi takdirlerine bağlı olarak ayarlarını değiştirebiliyorlar. Yazının yazarına göre zamanla hibrit yaklaşımın daha da yaygınlaşması ve pek çok oyunda karşımıza çıkması bekleniyor. Belki bir gün makine öğrenimine dayalı yapay zekayı saf haliyle oyuna dahil etmek mümkün olacaktır. Ancak bunun yine de zaman alacağı açıktır. Şimdilik amaç, karşı karşıya olduğu görevlere uyum sağlayacak bir mimari bulmak ve bunları çözmenin en uygun yollarını bulmaktır.
Kaynak: habr.com
