

Bu makalede veritabanlarındaki işlevsel bağımlılıklardan, bunların ne olduğundan, nerede kullanıldıklarından ve bunları bulmak için hangi algoritmaların mevcut olduğundan bahsedeceğiz.
İlişkisel veritabanları bağlamında işlevsel bağımlılıkları ele alacağız. Çok kabaca söylemek gerekirse, bu tür veritabanlarında bilgiler tablolar halinde depolanır. Daha sonra, katı ilişkisel teoride birbirinin yerine geçemeyen yaklaşık kavramları kullanıyoruz: tablonun kendisine bir ilişki, sütunlara - nitelikler (onların kümeleri - bir ilişki şeması) ve bir öznitelik alt kümesindeki satır değerleri kümesini diyeceğiz. - bir demet.
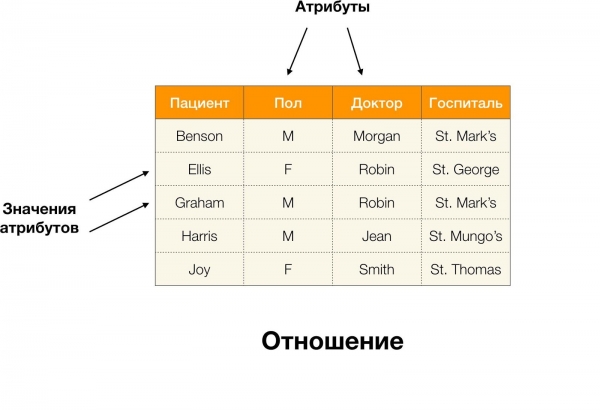
Örneğin yukarıdaki tabloda, (Benson, M, M organı) bir dizi niteliktir (Hasta, Paul, Doktor).
Daha resmi olarak bu şu şekilde yazılır:  [Hasta, Cinsiyet, Doktor] = (Benson, M, M organı).
[Hasta, Cinsiyet, Doktor] = (Benson, M, M organı).
Artık fonksiyonel bağımlılık (FD) kavramını tanıtabiliriz:
Tanım 1. R ilişkisi, X → Y federal yasasını (burada X, Y ⊆ R) ancak ve ancak herhangi bir demet için karşılar  ,
,  ∈ R şunu tutar: eğer
∈ R şunu tutar: eğer  [X] =
[X] =  [X], o zaman
[X], o zaman  [E] =
[E] =  [Y]. Bu durumda, X'in (belirleyici veya tanımlayıcı nitelikler kümesi) işlevsel olarak Y'yi (bağımlı küme) belirlediğini söylüyoruz.
[Y]. Bu durumda, X'in (belirleyici veya tanımlayıcı nitelikler kümesi) işlevsel olarak Y'yi (bağımlı küme) belirlediğini söylüyoruz.
Başka bir deyişle, federal bir yasanın varlığı X → Y bunun anlamı eğer iki tane demetimiz varsa R ve özellikler bakımından eşleşiyorlar X, o zaman niteliklerde çakışacaklar Y.
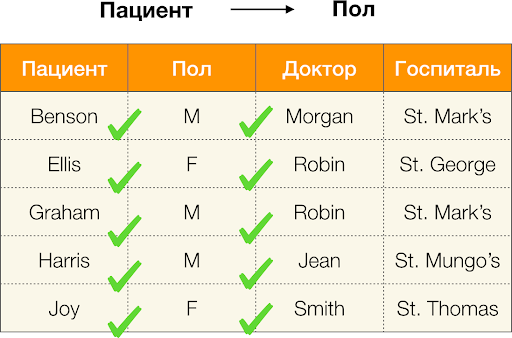
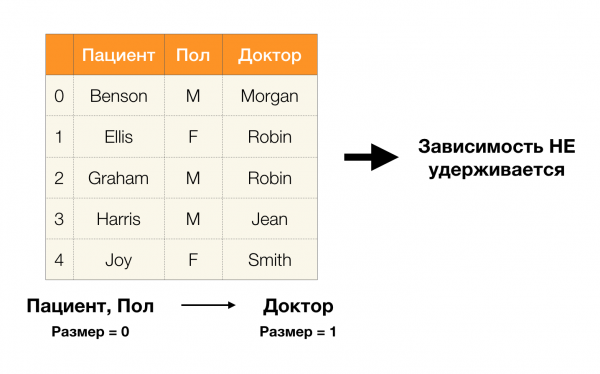
Ve şimdi sırayla. Niteliklere bakalım Hasta и Cinsiyet bunun için aralarında bağımlılık olup olmadığını öğrenmek istiyoruz. Böyle bir nitelik kümesi için aşağıdaki bağımlılıklar mevcut olabilir:
- Hasta → Cinsiyet
- Cinsiyet → Hasta
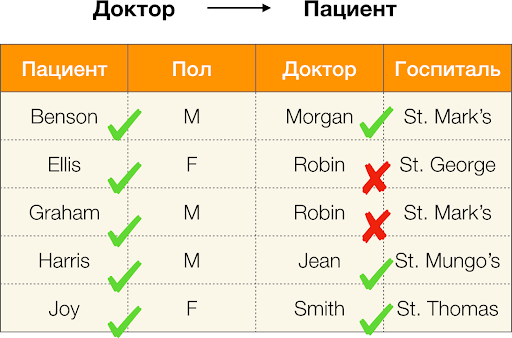
Yukarıda tanımlandığı gibi, ilk bağımlılığın geçerli olabilmesi için her benzersiz sütun değeri Hasta yalnızca bir sütun değeri eşleşmelidir Cinsiyet. Örnek tablo için durum gerçekten de budur. Ancak bu ters yönde çalışmaz, yani ikinci bağımlılık tatmin edilmez ve nitelik Cinsiyet için belirleyici değildir Hasta. Benzer şekilde bağımlılığı alırsak Doktor → Hastadeğeri nedeniyle ihlal edildiğini görebilirsiniz. narbülbülü bu özelliğin birkaç farklı anlamı vardır - Ellis ve Graham.
Böylece işlevsel bağımlılıklar, tablo öznitelikleri kümeleri arasındaki mevcut ilişkilerin belirlenmesini mümkün kılar. Buradan itibaren en ilginç bağlantıları, daha doğrusu bu tür bağlantıları ele alacağız. X → YOnlar ne:
- önemsiz değil, yani bağımlılığın sağ tarafı sol tarafın bir alt kümesi değil (Y ̸⊆ X);
- minimal yani böyle bir bağımlılık yok Z → YO Z ⊂ X.
Bu noktaya kadar dikkate alınan bağımlılıklar katıydı, yani tabloda herhangi bir ihlal sağlamadılar, ancak bunlara ek olarak tuple'ların değerleri arasında bir miktar tutarsızlığa izin verenler de var. Bu tür bağımlılıklar yaklaşık olarak adlandırılan ayrı bir sınıfa yerleştirilir ve belirli sayıda kayıt için ihlal edilmesine izin verilir. Bu miktar maksimum hata göstergesi emax ile düzenlenir. Örneğin hata oranı  = 0.01, bağımlılığın, dikkate alınan özellikler kümesindeki mevcut tanımlamaların %1'i kadar ihlal edilebileceği anlamına gelebilir. Yani 1000 kayıt için en fazla 10 kayıt Federal Yasayı ihlal edebilir. Karşılaştırılan demetlerin ikili olarak farklı değerlerine dayalı, biraz farklı bir metrik ele alacağız. Bağımlılık için X → Y tutum hakkında r şöyle değerlendiriliyor:
= 0.01, bağımlılığın, dikkate alınan özellikler kümesindeki mevcut tanımlamaların %1'i kadar ihlal edilebileceği anlamına gelebilir. Yani 1000 kayıt için en fazla 10 kayıt Federal Yasayı ihlal edebilir. Karşılaştırılan demetlerin ikili olarak farklı değerlerine dayalı, biraz farklı bir metrik ele alacağız. Bağımlılık için X → Y tutum hakkında r şöyle değerlendiriliyor:

Hatayı hesaplayalım Doktor → Hasta yukarıdaki örnekten. Değerleri özelliğe göre farklılık gösteren iki demetimiz var Hasta, ancak çakışıyor Doktor:  [Doktor, Hasta] = (Robin, Ellis) Ve
[Doktor, Hasta] = (Robin, Ellis) Ve  [Doktor, Hasta] = (Robin, Graham). Bir hatanın tanımına göre, tüm çakışan çiftleri dikkate almalıyız, bu da onlardan iki tane olacağı anlamına gelir: (
[Doktor, Hasta] = (Robin, Graham). Bir hatanın tanımına göre, tüm çakışan çiftleri dikkate almalıyız, bu da onlardan iki tane olacağı anlamına gelir: ( ,
,  ) ve tersi (
) ve tersi ( ,
,  ). Bunu formülde yerine koyalım ve şunu elde edelim:
). Bunu formülde yerine koyalım ve şunu elde edelim:

Şimdi şu soruyu cevaplamaya çalışalım: “Tüm bunlar neden?” Aslında federal yasalar farklıdır. İlk tür, yönetici tarafından veritabanı tasarımı aşamasında belirlenen bağımlılıklardır. Genellikle sayıları azdır ve katıdırlar ve ana uygulama alanı veri normalizasyonu ve ilişkisel şema tasarımıdır.
İkinci tür ise “gizli” verileri ve nitelikler arasındaki önceden bilinmeyen ilişkileri temsil eden bağımlılıklardır. Yani, bu tür bağımlılıklar tasarım sırasında düşünülmemişti ve bunlar mevcut veri seti için bulunuyordu; böylece daha sonra, belirlenen birçok federal yasaya dayanarak, depolanan bilgiler hakkında herhangi bir sonuç çıkarılabilir. Bizim üzerinde çalıştığımız şey tam olarak bu bağımlılıklardır. Bunlar, çeşitli arama teknikleri ve temelleri üzerine inşa edilmiş algoritmalar ile bütün bir veri madenciliği alanı tarafından ele alınmaktadır. Herhangi bir veride bulunan işlevsel bağımlılıkların (kesin veya yaklaşık) nasıl yararlı olabileceğini bulalım.

Günümüzde bağımlılıkların ana uygulamalarından biri veri temizlemedir. “Kirli verileri” tanımlamak ve ardından düzeltmek için süreçler geliştirmeyi içerir. "Kirli verilerin" öne çıkan örnekleri kopyalar, veri hataları veya yazım hataları, eksik değerler, güncelliğini yitirmiş veriler, fazladan boşluklar ve benzerleridir.
Veri hatası örneği:
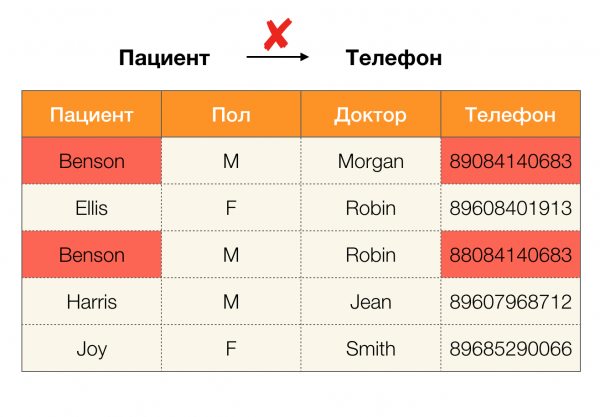
Verilerdeki kopyalara örnek:
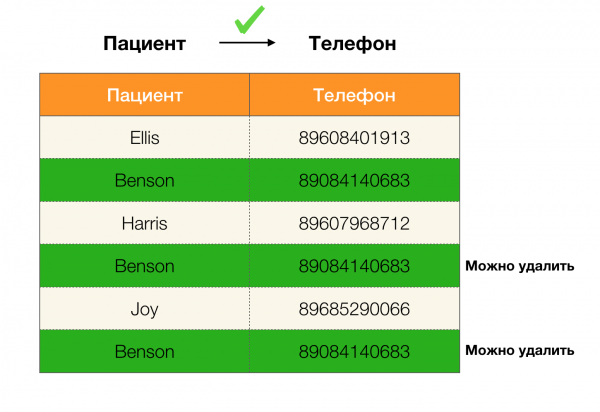
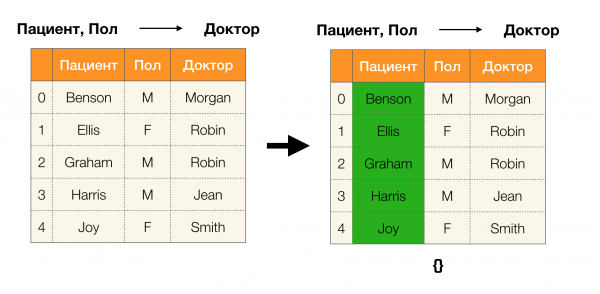
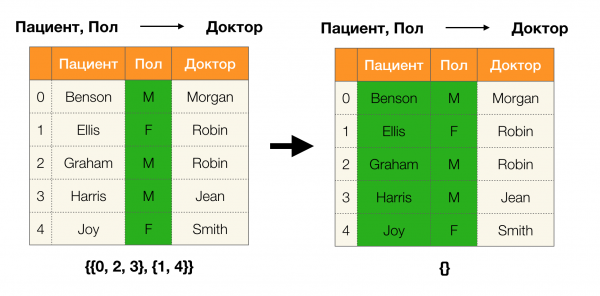
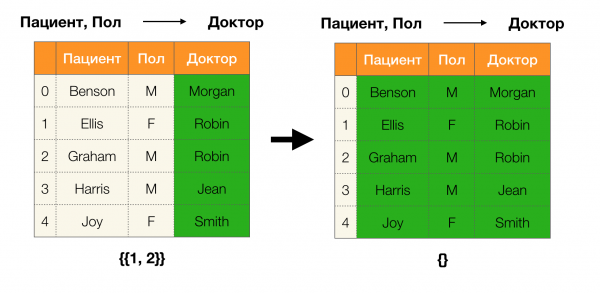
Örneğin, bir tablomuz ve uygulanması gereken bir dizi federal yasamız var. Bu durumda veri temizliği, Federal Yasaların doğru olması için verilerin değiştirilmesini içerir. Bu durumda, değişiklik sayısı minimum düzeyde olmalıdır (bu prosedürün, bu makalede odaklanmayacağımız kendi algoritmaları vardır). Aşağıda böyle bir veri dönüşümünün bir örneği verilmiştir. Solda, açıkça gerekli FL'lerin karşılanmadığı orijinal ilişki bulunmaktadır (FL'lerden birinin ihlaline ilişkin bir örnek kırmızıyla vurgulanmıştır). Sağda, değiştirilen değerleri gösteren yeşil hücrelerle güncellenmiş ilişki bulunmaktadır. Bu işlemden sonra gerekli bağımlılıklar sürdürülmeye başlandı.
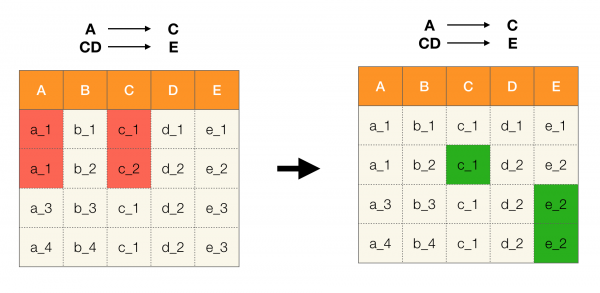
Bir diğer popüler uygulama ise veritabanı tasarımıdır. Burada normal formları ve normalleşmeyi hatırlamakta fayda var. Normalleştirme, bir ilişkiyi, her biri normal form tarafından kendi yöntemiyle tanımlanan belirli bir dizi gereksinime uygun hale getirme sürecidir. Çeşitli normal formların gereksinimlerini açıklamayacağız (bu, yeni başlayanlar için veritabanı kursuna ilişkin herhangi bir kitapta yapılır), ancak yalnızca her birinin işlevsel bağımlılık kavramını kendi yöntemiyle kullandığını not edeceğiz. Sonuçta, FL'ler doğası gereği bir veritabanı tasarlanırken dikkate alınan bütünlük kısıtlamalarıdır (bu görev bağlamında FL'lere bazen süper anahtarlar da denir).
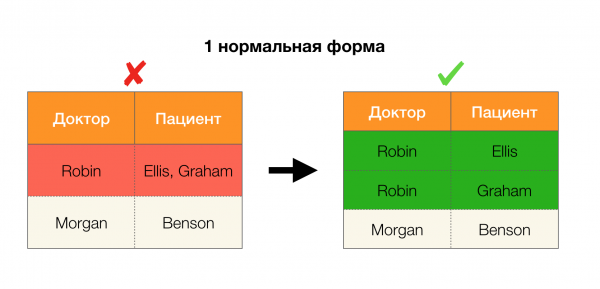
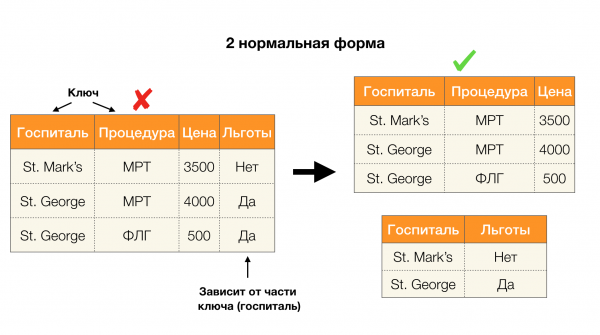
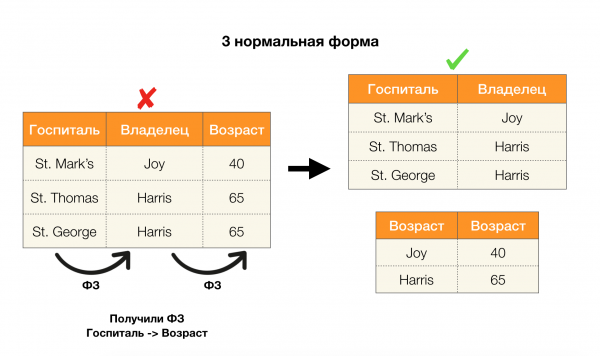
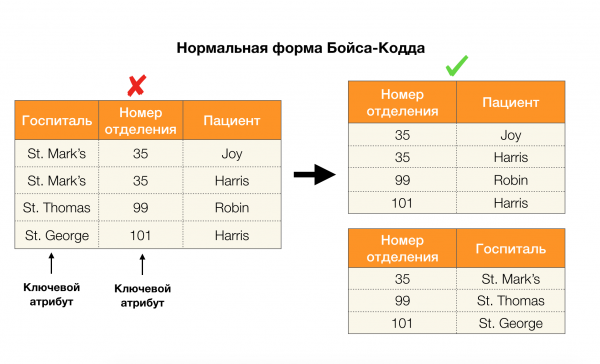
Aşağıdaki resimdeki dört normal form için bunların uygulanmasını ele alalım. Boyce-Codd normal formunun üçüncü formdan daha katı, ancak dördüncü formdan daha az katı olduğunu hatırlayın. İkincisini şimdilik düşünmüyoruz, çünkü formülasyonu çok değerli bağımlılıkların anlaşılmasını gerektiriyor ki bunlar bu makalede ilgimizi çekmiyor.
Bağımlılıkların uygulama bulduğu diğer bir alan, saf bir Bayes sınıflandırıcısı oluşturmak, önemli özellikleri tanımlamak ve bir regresyon modelini yeniden parametrelendirmek gibi görevlerde özellik alanının boyutluluğunu azaltmaktır. Orijinal makalelerde bu göreve yedekliliğin ve özellik uygunluğunun belirlenmesi adı verilmektedir [5, 6] ve veritabanı kavramlarının aktif kullanımı ile çözülmektedir. Bu tür çalışmaların ortaya çıkmasıyla birlikte, bugün yukarıdaki optimizasyon problemlerinin veritabanını, analitiğini ve uygulamasını tek bir araçta birleştirmemize olanak tanıyan çözümlere talep olduğunu söyleyebiliriz [7, 8, 9].
Bir veri kümesinde federal yasaları aramak için birçok algoritma (hem modern hem de çok modern olmayan) vardır.Bu tür algoritmalar üç gruba ayrılabilir:
- Cebirsel kafeslerin geçişini kullanan algoritmalar (Kafes geçiş algoritmaları)
- Mutabık kalınan değerlerin aranmasına dayalı algoritmalar (Fark ve anlaşma kümesi algoritmaları)
- İkili karşılaştırmalara dayalı algoritmalar (Bağımlılık tümevarım algoritmaları)
Her algoritma türünün kısa bir açıklaması aşağıdaki tabloda sunulmaktadır:
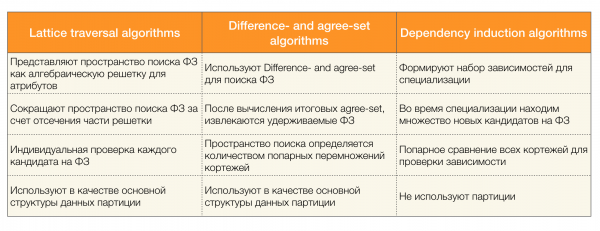
Bu sınıflandırma hakkında daha fazlasını okuyabilirsiniz [4]. Aşağıda her tür için algoritma örnekleri verilmiştir:
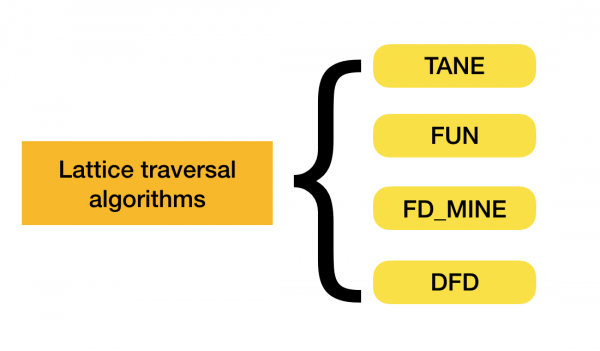
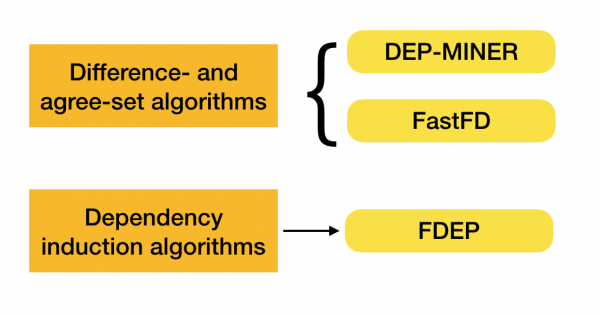
Şu anda, işlevsel bağımlılıkları bulmaya yönelik çeşitli yaklaşımları birleştiren yeni algoritmalar ortaya çıkıyor. Bu tür algoritmaların örnekleri Pyro [2] ve HyFD'dir [3]. Bu serinin ilerleyen makalelerinde çalışmalarının bir analizi bekleniyor. Bu yazıda sadece bağımlılık tespit tekniklerini anlamak için gerekli olan temel kavramları ve lemmayı inceleyeceğiz.
İkinci tür algoritmalarda kullanılan basit bir fark ve anlaşma kümesiyle başlayalım. Diferansiyel kümesi aynı değerlere sahip olmayan bir küme kümesidir, oysa uyum kümesi tam tersine aynı değerlere sahip olan kümelerdir. Bu durumda bağımlılığın yalnızca sol tarafını dikkate aldığımızı belirtmekte fayda var.
Yukarıda karşılaşılan bir diğer önemli kavram da cebirsel kafestir. Birçok modern algoritma bu kavram üzerinde çalıştığı için bunun ne olduğuna dair bir fikre sahip olmamız gerekiyor.
Kafes kavramını tanıtmak için, kısmen sıralı bir kümeyi (veya kısmen sıralı kümeyi, poset olarak kısaltılır) tanımlamak gerekir.
Tanım 2. Tüm a, b, c ∈ S için aşağıdaki özellikler karşılanıyorsa, bir S kümesinin ⩽ ikili ilişkisine göre kısmen sıralandığı söylenir:
- Yansımalılık, yani a ⩽ a
- Antisimetri, yani a ⩽ b ve b ⩽ a ise a = b
- Geçişlilik, yani a ⩽ b ve b ⩽ c için a ⩽ c sonucu çıkar
Böyle bir ilişkiye (gevşek) kısmi sıra ilişkisi denir ve kümenin kendisine de kısmen sıralı küme denir. Biçimsel gösterim: ⟨S, ⩽⟩.
Kısmen sıralı bir kümenin en basit örneği olarak, olağan sıra ilişkisi ⩽ ile tüm doğal sayılar N kümesini alabiliriz. Gerekli tüm aksiyomların karşılandığını doğrulamak kolaydır.
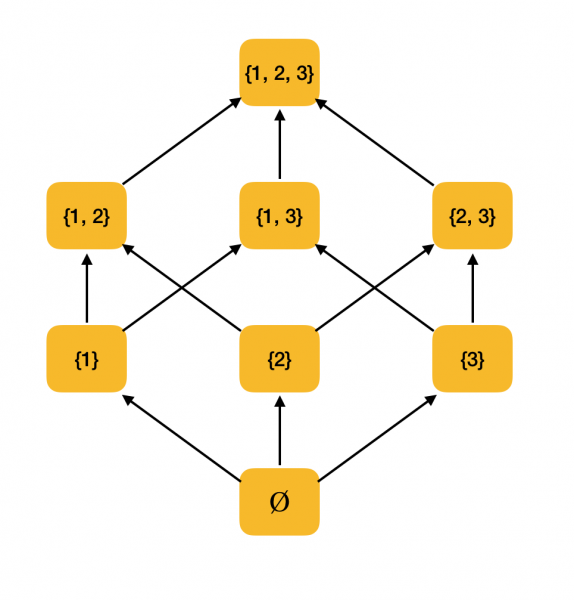
Daha anlamlı bir örnek. Dahil etme ilişkisi ⊆ tarafından sıralanan tüm {1, 2, 3} alt kümelerinin kümesini düşünün. Aslında bu ilişki tüm kısmi sıra koşullarını karşılar, dolayısıyla ⟨P ({1, 2, 3}), ⊆⟩ kısmen sıralı bir kümedir. Aşağıdaki şekil bu kümenin yapısını göstermektedir: Eğer bir öğeye oklarla başka bir öğeye ulaşabiliyorsanız, bunlar bir sıra ilişkisi içindedir.
Matematik alanından iki basit tanıma daha ihtiyacımız olacak - supremum ve infimum.
Tanım 3. ⟨S, ⩽⟩ kısmen sıralı bir küme olsun, A ⊆ S. A'nın üst sınırı bir u ∈ S elemanıdır, öyle ki ∀x ∈ S: x ⩽ u. U, S'nin tüm üst sınırlarının kümesi olsun. U'da en küçük bir eleman varsa, o zaman buna üst denir ve A ile gösterilir.
Tam bir alt sınır kavramı da benzer şekilde tanıtılmıştır.
Tanım 4. ⟨S, ⩽⟩ kısmen sıralı bir küme, A ⊆ S olsun. A'nın infimumu bir l ∈ S elemanıdır, öyle ki ∀x ∈ S: l ⩽ x. L, S'nin tüm alt sınırlarının kümesi olsun. L'nin en büyük elemanı varsa buna infimum denir ve inf A olarak gösterilir.
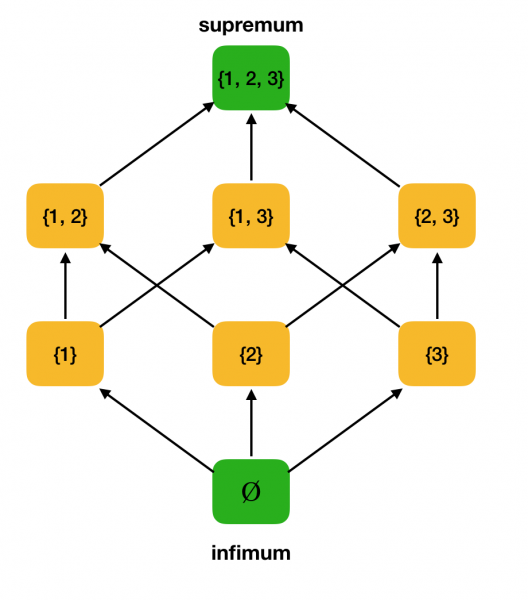
Örnek olarak yukarıdaki kısmen sıralı ⟨P ({1, 2, 3}), ⊆⟩ kümesini düşünün ve içindeki en yüksek ve en düşük değerleri bulun:
Artık cebirsel kafesin tanımını formüle edebiliriz.
Tanım 5. ⟨P,⩽⟩ her iki elemanlı alt kümenin bir üst ve alt sınırı olacak şekilde kısmen sıralı bir küme olsun. O halde P'ye cebirsel kafes denir. Bu durumda sup{x, y} x ∨ y olarak, inf {x, y} ise x ∧ y olarak yazılır.
Çalışma örneğimiz ⟨P ({1, 2, 3}), ⊆⟩'nin bir kafes olup olmadığını kontrol edelim. Aslında, herhangi bir a, b ∈ P ({1, 2, 3}) için a∨b = a∪b ve a∧b = a∩b. Örneğin, {1, 2} ve {1, 3} kümelerini düşünün ve bunların en yüksek ve en yüksek değerlerini bulun. Bunları kesersek, infimum olan {1} kümesini elde ederiz. Üstünlüğü elde ederiz - {1, 2, 3}.
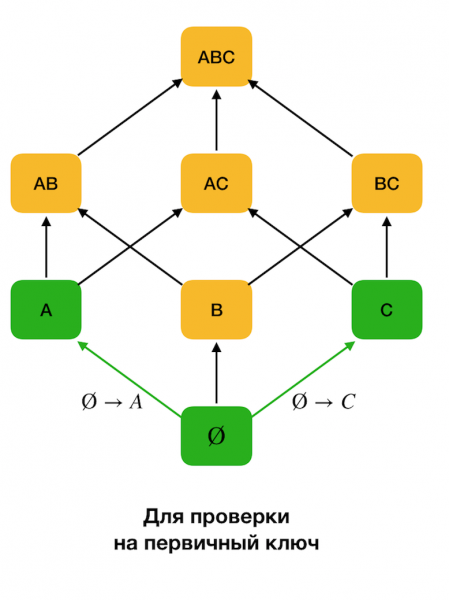
Fiziksel problemleri tanımlamaya yönelik algoritmalarda, arama alanı genellikle bir kafes biçiminde temsil edilir; burada bir öğenin kümeleri (bağımlılıkların sol tarafının bir öznitelikten oluştuğu arama kafesinin ilk düzeyini okuyun) her bir özniteliği temsil eder. orijinal ilişkiden.
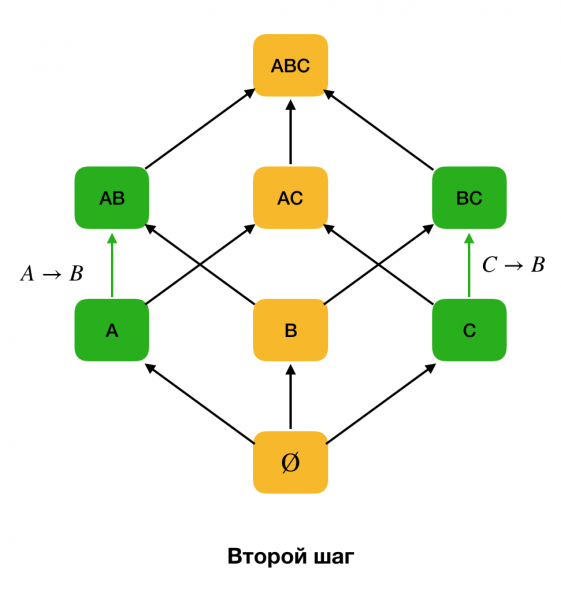
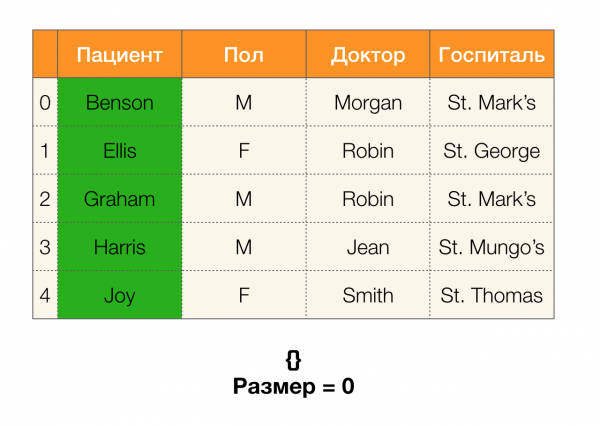
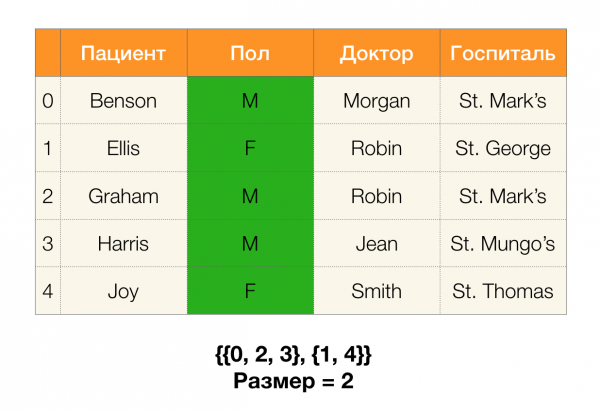
Öncelikle ∅ → formunun bağımlılıklarını ele alıyoruz. Tek nitelik. Bu adım, hangi niteliklerin birincil anahtar olduğunu belirlemenizi sağlar (bu tür nitelikler için belirleyici yoktur ve bu nedenle sol taraf boştur). Ayrıca, bu tür algoritmalar kafes boyunca yukarı doğru hareket eder. Kafesin tamamının geçilemeyeceğini, yani sol tarafın istenen maksimum boyutunun girişe iletilmesi durumunda algoritmanın bu boyuttaki bir seviyeden daha ileri gitmeyeceğini belirtmekte fayda var.
Aşağıdaki şekil FZ bulma probleminde cebirsel kafesin nasıl kullanılabileceğini göstermektedir. Burada her kenar (X, XY) bir bağımlılığı temsil eder X → Y. Mesela birinci seviyeyi geçtik ve bağımlılığın devam ettiğini biliyoruz bir → B (bunu köşeler arasında yeşil bir bağlantı olarak görüntüleyeceğiz A и B). Bu ayrıca kafes boyunca yukarı doğru hareket ettiğimizde bağımlılığı kontrol edemeyebileceğimiz anlamına gelir. A, C → Bçünkü artık minimal olmayacak. Benzer şekilde, bağımlılığın devam edip etmediğini kontrol etmeyiz C → B.
Ek olarak, kural olarak, federal yasaları aramaya yönelik tüm modern algoritmalar, bölüm gibi bir veri yapısı kullanır (orijinal kaynakta - soyulmuş bölüm [1]). Bir bölümün resmi tanımı aşağıdaki gibidir:
Tanım 6. X ⊆ R, r ilişkisi için bir nitelikler kümesi olsun. Bir küme, X için aynı değere sahip olan, r'deki bir dizi indeks kümesidir, yani c(t) = {i|ti[X] = t[X]}. Bölüm, birim uzunluktaki kümeler hariç, bir küme kümesidir:

Basit bir deyişle, bir öznitelik için bir bölüm X her listenin aynı değerlere sahip satır numaralarını içerdiği bir listeler kümesidir. X. Modern literatürde bölümleri temsil eden yapıya konum listesi dizini (PLI) adı verilir. Birim uzunluktaki kümeler PLI sıkıştırma amacıyla hariç tutulur çünkü bunlar yalnızca benzersiz bir değere sahip bir kayıt numarası içeren ve tanımlanması her zaman kolay olan kümelerdir.
Bir örneğe bakalım. Hastalarla aynı tabloya dönelim ve sütunlar için bölümler oluşturalım Hasta и Cinsiyet (solda, tablo satır numaralarının işaretlendiği yeni bir sütun belirdi):
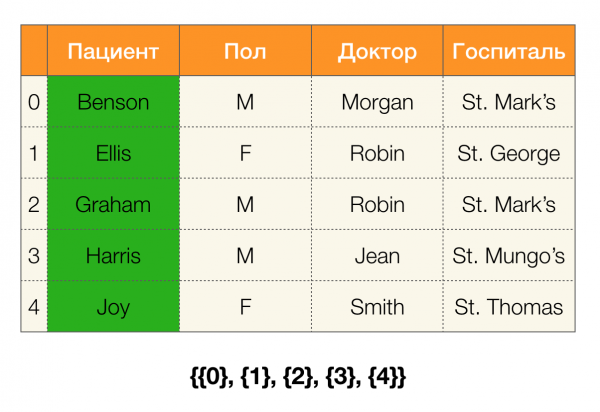
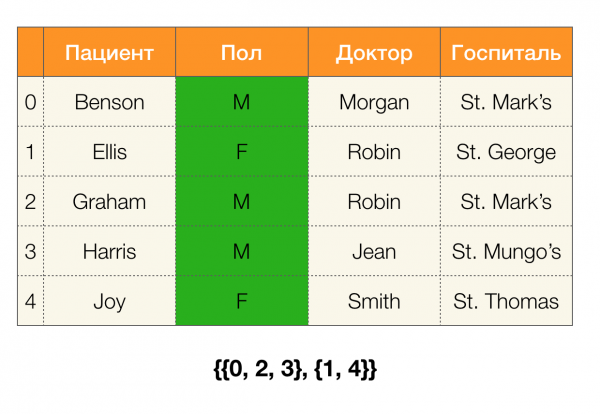
Ayrıca tanıma göre sütunun bölümü Hasta Tekli kümeler bölümün dışında tutulduğu için aslında boş olacaktır.
Bölümler çeşitli niteliklerle elde edilebilir. Ve bunu yapmanın iki yolu vardır: tablonun içinden geçerek, gerekli tüm nitelikleri bir kerede kullanarak bir bölüm oluşturun veya bir öznitelik alt kümesi kullanarak bölümlerin kesişme işlemini kullanarak bunu oluşturun. Federal yasa arama algoritmaları ikinci seçeneği kullanır.
Basit bir ifadeyle, örneğin sütunlara göre bir bölüm elde etmek için ABCiçin bölümler alabilirsiniz AC и B (veya başka herhangi bir ayrık alt küme kümesi) ve bunları birbirleriyle kesiştirin. İki bölümün kesişimi işlemi, her iki bölüm için ortak olan en büyük uzunluktaki kümeleri seçer.
Bir örneğe bakalım:
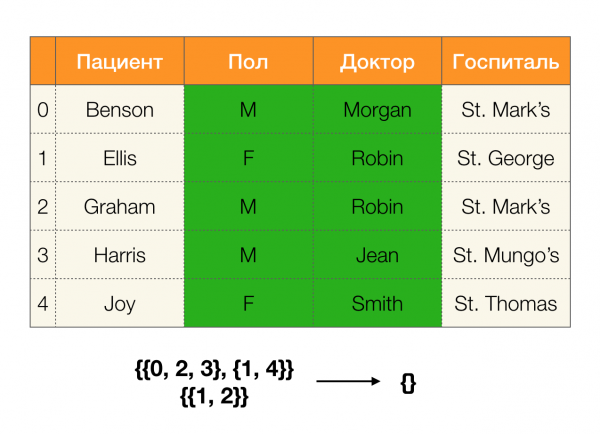

İlk durumda boş bir bölüm aldık. Tabloya yakından bakarsanız aslında iki özellik için aynı değerlerin bulunmadığını görürsünüz. Tabloyu biraz değiştirirsek (sağdaki durum), zaten boş olmayan bir kesişim elde ederiz. Üstelik 1. ve 2. satırlar aslında nitelikler için aynı değerleri içeriyor Cinsiyet и doktor.
Daha sonra bölüm boyutu gibi bir kavrama ihtiyacımız olacak. Resmi olarak:

Basitçe söylemek gerekirse, bölüm boyutu, bölüme dahil edilen kümelerin sayısıdır (bölümde tekil kümelerin yer almadığını unutmayın!):
Artık belirli bölümler için bir bağımlılığın tutulup tutulmadığını belirlememize olanak tanıyan anahtar lemmalardan birini tanımlayabiliriz:
Lemma 1. A, B → C bağımlılığı ancak ve ancak şu durumlarda geçerlidir:

Lemmaya göre, bir bağımlılığın geçerli olup olmadığını belirlemek için dört adımın gerçekleştirilmesi gerekir:
- Bağımlılığın sol tarafı için bölümü hesaplayın
- Bağımlılığın sağ tarafı için bölümü hesaplayın
- Birinci ve ikinci adımın çarpımını hesaplayın
- Birinci ve üçüncü adımlarda elde edilen bölümlerin boyutlarını karşılaştırın
Aşağıda bağımlılığın bu lemmaya göre geçerli olup olmadığını kontrol etmenin bir örneği verilmiştir:
Bu yazımızda fonksiyonel bağımlılık, yaklaşık fonksiyonel bağımlılık gibi kavramları inceledik, bunların nerelerde kullanıldığına ve ayrıca fiziksel fonksiyonları aramaya yönelik hangi algoritmaların mevcut olduğuna baktık. Ayrıca federal yasaların aranmasında modern algoritmalarda aktif olarak kullanılan temel ancak önemli kavramları ayrıntılı olarak inceledik.
Referanslar:
- Huhtala Y. ve ark. TANE: İşlevsel ve yaklaşık bağımlılıkları keşfetmek için etkili bir algoritma // Bilgisayar günlüğü. – 1999. – T.42. – No. 2. – s. 100-111.
- Kruse S., Naumann F. Yaklaşık bağımlılıkların verimli keşfi // VLDB Bağışı Tutanakları. – 2018. – T.11. – No. 7. – s.759-772.
- Papenbrock T., Naumann F. İşlevsel bağımlılık keşfine hibrit bir yaklaşım // 2016 Uluslararası Veri Yönetimi Konferansı Bildirileri. – ACM, 2016. – s. 821-833.
- Papenbrock T. ve ark. İşlevsel bağımlılık keşfi: Yedi algoritmanın deneysel bir değerlendirmesi //VLDB Endowment Bildirileri. – 2015. – T.8. – No. 10. – s. 1082-1093.
- Kumar A. ve ark. Katılmak ya da katılmamak?: Özellik seçiminden önce birleştirmeler hakkında iki kez düşünmek // 2016 Uluslararası Veri Yönetimi Konferansı Bildirileri. – ACM, 2016. – s. 19-34.
- Abo Khamis M. ve ark. Seyrek tensörlerle veritabanı içi öğrenme // 37. ACM SIGMOD-SIGACT-SIGAI Veritabanı Sistemlerinin Prensipleri Sempozyumu Bildirileri. – ACM, 2018. – s. 325-340.
- Hellerstein JM ve diğerleri. MADlib analitik kitaplığı: veya MAD becerileri, VLDB Bağışının SQL //Proceedings'i. – 2012. – T.5. – No. 12. – s. 1700-1711.
- Qin C., Rusu F. Terascale dağıtılmış gradyan iniş optimizasyonu için spekülatif yaklaşımlar // Bulutta Veri analitiği üzerine Dördüncü Çalıştayın Bildirileri. – ACM, 2015. – S. 1.
- Meng X. ve ark. Mllib: Apache Spark'ta makine öğrenimi //Makine Öğrenimi Araştırma Dergisi. – 2016. – T.17. – No. 1. – s. 1235-1241.
Makalenin yazarları: , araştırmacı , и , araştırmacı
Kaynak: habr.com
