

Hammaga salom, mening ismim Aleksandr, men CIAN kompaniyasida muhandis bo'lib ishlayman va tizim boshqaruvi va infratuzilma jarayonlarini avtomatlashtirish bilan shug'ullanaman. Oldingi maqolalardan biriga sharhlarda bizdan kuniga 4 TB jurnalni qayerdan olishimiz va ular bilan nima qilishimizni aytib berishni so'rashdi. Ha, bizda juda ko'p jurnallar mavjud va ularni qayta ishlash uchun alohida infratuzilma klasteri yaratilgan, bu bizga muammolarni tezda hal qilish imkonini beradi. Ushbu maqolada men uni bir yil davomida doimiy ravishda o'sib borayotgan ma'lumotlar oqimi bilan ishlash uchun qanday moslashtirganimiz haqida gapiraman.
Biz qayerdan boshladik?
So'nggi bir necha yil ichida cian.ru-dagi yuk juda tez o'sdi va 2018 yilning uchinchi choragiga kelib, resurs trafiki oyiga 11.2 million noyob foydalanuvchiga yetdi. O'sha paytda, tanqidiy daqiqalarda biz jurnallarning 40 foizini yo'qotdik, shuning uchun biz hodisalarni tezda bartaraf eta olmadik va ularni hal qilish uchun ko'p vaqt va kuch sarfladik. Biz ham ko'pincha muammoning sababini topa olmadik va u bir muncha vaqt o'tgach takrorlanadi. Bu jahannam edi va bu haqda nimadir qilish kerak edi.
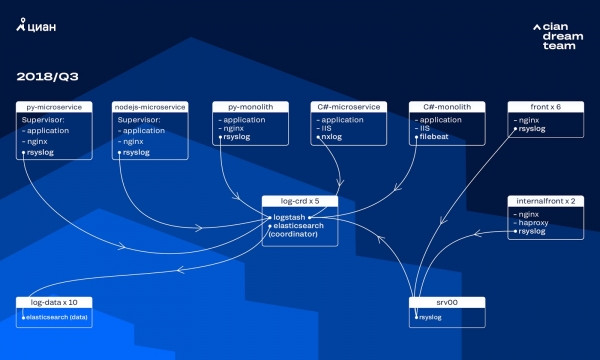
O'sha paytda biz jurnallarni saqlash uchun standart indeks sozlamalari bilan ElasticSearch 10 versiyasiga ega 5.5.2 ta ma'lumot tugunlari klasteridan foydalanganmiz. U bir yildan ko'proq vaqt oldin mashhur va arzon echim sifatida taqdim etilgan: keyin jurnallar oqimi unchalik katta emas edi, nostandart konfiguratsiyalar bilan chiqishning ma'nosi yo'q edi.
Kiruvchi jurnallarni qayta ishlash Logstash tomonidan beshta ElasticSearch koordinatoridagi turli portlarda amalga oshirildi. Bitta indeks, hajmidan qat'i nazar, beshta parchadan iborat edi. Soatlik va kunlik aylanish tashkil etildi, natijada har soatda klasterda 100 ga yaqin yangi shardlar paydo bo'ldi. Juda ko'p jurnallar bo'lmasa-da, klaster yaxshi ishladi va hech kim uning sozlamalariga e'tibor bermadi.
Tez o'sishning qiyinchiliklari
Yaratilgan jurnallar hajmi juda tez o'sdi, chunki ikkita jarayon bir-birining ustiga chiqdi. Bir tomondan, xizmatdan foydalanuvchilar soni o'sdi. Boshqa tomondan, biz C# va Python-da eski monolitlarimizni ko'rib, mikroservis arxitekturasiga faol o'tishni boshladik. Monolit qismlarini almashtirgan bir necha o'nlab yangi mikroservislar infratuzilma klasteri uchun sezilarli darajada ko'proq jurnallarni yaratdi.
Aynan miqyoslash bizni klasterni amalda boshqarib bo'lmaydigan darajaga olib keldi. Jurnallar soniyasiga 20 ming xabar tezligida kela boshlaganida, tez-tez foydasiz aylanish parchalar sonini 6 mingtaga ko'paytirdi va har bir tugunda 600 dan ortiq bo'lak bor edi.
Bu operativ xotirani taqsimlash bilan bog'liq muammolarga olib keldi va tugun ishdan chiqqanida, barcha parchalar bir vaqtning o'zida ko'chib o'tadi, bu esa trafikni oshiradi va qolgan tugunlarni yuklaydi, bu esa klasterga ma'lumotlarni yozishni deyarli imkonsiz qiladi. Va bu davrda biz jurnallarsiz qoldik. Va agar muammo bo'lsa server Biz klasterning umumiy hajmining 1/10 qismini yo'qotayotgan edik. Kichik indekslarning ko'pligi murakkablikni yanada oshirdi.
Jurnallarsiz biz voqea sabablarini tushunmadik va ertami-kechmi yana o'sha rakega qadam qo'yishimiz mumkin edi va jamoamiz mafkurasida bu qabul qilinishi mumkin emas edi, chunki bizning barcha ish mexanizmlarimiz teskarisini qilishga mo'ljallangan - hech qachon takrorlanmang. bir xil muammolar. Buning uchun bizga jurnallarning to'liq hajmi va ularni deyarli real vaqtda yetkazib berish kerak edi, chunki navbatchi muhandislar jamoasi ogohlantirishlarni nafaqat ko'rsatkichlardan, balki jurnallardan ham kuzatib borishdi. Muammoning ko'lamini tushunish uchun, o'sha paytda jurnallarning umumiy hajmi kuniga taxminan 2 TB edi.
Biz loglarni yo'qotishni to'liq bartaraf etish va fors-major holatlarida ularni ELK klasteriga etkazib berish vaqtini maksimal 15 daqiqaga qisqartirishni maqsad qilib qo'ydik (keyinchalik biz bu raqamga ichki KPI sifatida tayandik).
Yangi aylanish mexanizmi va issiq-issiq tugunlar
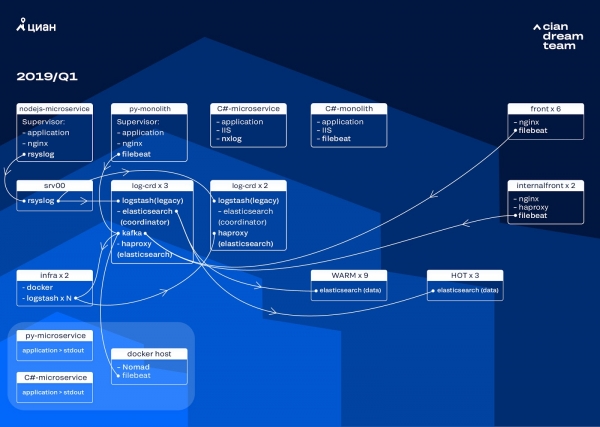
Biz klaster konvertatsiyasini ElasticSearch versiyasini 5.5.2 dan 6.4.3 ga yangilash orqali boshladik. Yana bir bor bizning 5-versiya klasterimiz halok bo'ldi va biz uni o'chirishga va butunlay yangilashga qaror qildik - hali ham jurnallar yo'q. Shunday qilib, biz bir necha soat ichida bu o'tishni amalga oshirdik.
Ushbu bosqichdagi eng keng ko'lamli transformatsiya Apache Kafka-ni oraliq bufer sifatida koordinator bilan uchta tugunlarda amalga oshirish edi. Xabar brokeri bizni ElasticSearch bilan bog'liq muammolar paytida jurnallarni yo'qotishdan qutqardi. Shu bilan birga, biz klasterga 2 ta tugunni qo'shdik va ma'lumotlar markazidagi turli raflarda joylashgan uchta "issiq" tugun bilan issiq-issiq arxitekturaga o'tdik. Biz jurnallarni ularga hech qanday sharoitda yo'qotmaslik kerak bo'lgan niqob yordamida yo'naltirdik - nginx, shuningdek, dastur xato jurnallari. Qolgan tugunlarga kichik jurnallar yuborildi - disk raskadrovka, ogohlantirish va hk. va 24 soatdan keyin "issiq" tugunlardan "muhim" jurnallar uzatildi.
Kichik indekslar sonini ko'paytirmaslik uchun biz vaqtni aylantirishdan aylanish mexanizmiga o'tdik. Forumlarda indeks hajmi bo'yicha aylanish juda ishonchsiz ekanligi haqida juda ko'p ma'lumotlar bor edi, shuning uchun biz indeksdagi hujjatlar soni bo'yicha aylanishdan foydalanishga qaror qildik. Biz har bir indeksni tahlil qildik va aylanish jarayoni ishlashi kerak bo'lgan hujjatlar sonini qayd etdik. Shunday qilib, biz optimal parcha hajmiga erishdik - 50 GB dan oshmaydi.
Klasterni optimallashtirish
Biroq muammolardan to‘liq xalos bo‘lganimiz yo‘q. Afsuski, kichik indekslar hali ham paydo bo'ldi: ular belgilangan hajmga etib bormadi, aylantirilmadi va uch kundan eski indekslarni global tozalash orqali o'chirildi, chunki biz aylanishni sana bo'yicha olib tashladik. Bu ma'lumotlarning yo'qolishiga olib keldi, chunki klasterdagi indeks butunlay yo'qoldi va mavjud bo'lmagan indeksga yozishga urinish biz boshqaruv uchun ishlatgan kurator mantig'ini buzdi. Yozish uchun taxallus indeksga aylantirildi va aylanma mantiqni buzdi, bu ba'zi indekslarning 600 Gbgacha nazoratsiz o'sishiga olib keldi.
Masalan, aylanish konfiguratsiyasi uchun:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Agar rollover taxallus bo'lmasa, xatolik yuz berdi:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Biz ushbu muammoni hal qilishni keyingi iteratsiyaga qoldirdik va boshqa masalani ko'rib chiqdik: biz Logstash-ning tortish mantig'iga o'tdik, u kiruvchi jurnallarni qayta ishlaydi (keraksiz ma'lumotlarni olib tashlash va boyitish). Biz uni docker-compose orqali ishga tushiradigan docker-ga joylashtirdik, shuningdek, log oqimini operativ monitoring qilish uchun Prometeyga o'lchovlarni yuboradigan logstash-exporter-ni joylashtirdik. Shunday qilib, biz o'zimizga har bir jurnal turini qayta ishlash uchun mas'ul bo'lgan logstash nusxalari sonini muammosiz o'zgartirish imkoniyatini berdik.
Biz klasterni takomillashtirar ekanmiz, cian.ru trafiki oyiga 12,8 million noyob foydalanuvchigacha oshdi. Natijada, bizning o'zgarishlarimiz ishlab chiqarishdagi o'zgarishlardan biroz orqada qolganligi ma'lum bo'ldi va biz "issiq" tugunlar yukni bardosh bera olmasligi va loglarni to'liq etkazib berishni sekinlashtirishi bilan duch keldik. Biz "issiq" ma'lumotni muvaffaqiyatsiz qabul qildik, ammo qolganlarini etkazib berishga aralashishimiz va indekslarni teng taqsimlash uchun qo'lda aylantirishimiz kerak edi.
Shu bilan birga, klasterdagi logstash nusxalarining sozlamalarini o'zgartirish va o'zgartirish mahalliy docker-compose ekanligi va barcha harakatlar qo'lda amalga oshirilganligi sababli murakkablashdi (yangi uchlarni qo'shish uchun hamma narsani qo'lda o'tkazish kerak edi. serverlar va docker-compose up -d hamma joyda).
Jurnalni qayta taqsimlash
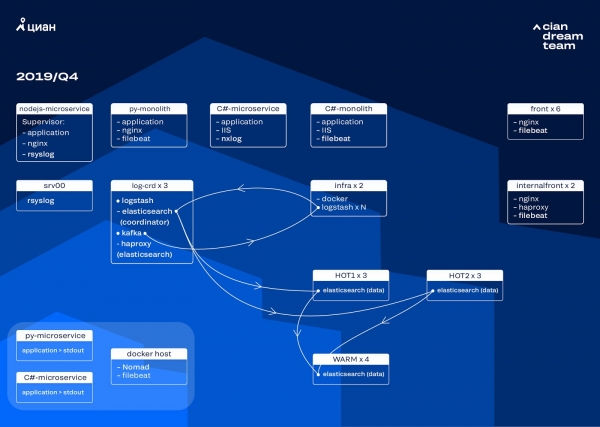
Joriy yilning sentyabr oyida biz hali ham monolitni kesib tashladik, klasterdagi yuk ortib bordi va jurnallar oqimi sekundiga 30 ming xabarga yaqinlashdi.
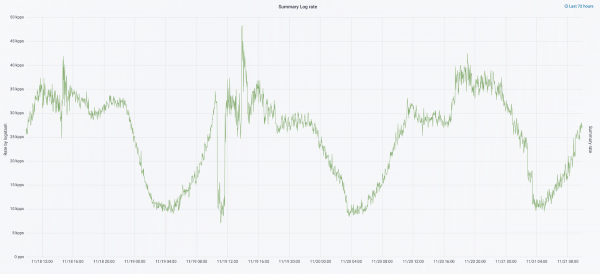
Keyingi iteratsiyani apparat yangilanishi bilan boshladik. Biz besh koordinatordan uchtaga o'tdik, ma'lumotlar tugunlarini almashtirdik va pul va saqlash joyi bo'yicha g'alaba qozondik. Tugunlar uchun biz ikkita konfiguratsiyadan foydalanamiz:
- “Issiq” tugunlar uchun: E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (Hot3 uchun 1 va Hot3 uchun 2).
- "Issiq" tugunlar uchun: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Ushbu iteratsiyada biz oldingi nginx jurnallari bilan bir xil joyni egallagan mikroservislarning kirish jurnallari bilan indeksni uchta "issiq" tugunning ikkinchi guruhiga o'tkazdik. Endi biz ma'lumotlarni "issiq" tugunlarda 20 soat davomida saqlaymiz va keyin ularni jurnallarning qolgan qismiga "iliq" tugunlarga o'tkazamiz.
Biz kichik indekslarning yo'qolishi muammosini ularning aylanishini qayta sozlash orqali hal qildik. Endi indekslar har 23 soatda har qanday holatda, hatto u erda kam ma'lumot bo'lsa ham, aylantiriladi. Bu parchalar sonini biroz ko'paytirdi (ularning taxminan 800 tasi bor edi), ammo klaster ishlashi nuqtai nazaridan bunga chidash mumkin.
Natijada, klasterda oltita "issiq" va faqat to'rtta "iliq" tugun mavjud edi. Bu uzoq vaqt oralig'ida so'rovlarning biroz kechikishiga olib keladi, ammo kelajakda tugunlar sonini ko'paytirish bu muammoni hal qiladi.
Ushbu iteratsiya yarim avtomatik masshtablashning yo'qligi muammosini ham hal qildi. Buning uchun biz Nomad klaster infratuzilmasini joylashtirdik - biz ishlab chiqarishda allaqachon joylashtirganimiz kabi. Hozircha Logstash miqdori yukga qarab avtomatik ravishda o'zgarmaydi, ammo biz bunga kelamiz.
Kelajak uchun rejalar
Amalga oshirilgan konfiguratsiya mukammal darajada o'lchaydi va endi biz 13,3 TB ma'lumotni saqlaymiz - 4 kun davomida barcha jurnallar, bu ogohlantirishlarni favqulodda tahlil qilish uchun zarurdir. Biz ba'zi jurnallarni o'lchovlarga aylantiramiz, biz ularni Grafitga qo'shamiz. Muhandislarning ishini engillashtirish uchun bizda infratuzilma klasteri uchun ko'rsatkichlar va umumiy muammolarni yarim avtomatik tuzatish uchun skriptlar mavjud. Kelgusi yil uchun rejalashtirilgan ma'lumotlar tugunlari sonini ko'paytirgandan so'ng, biz 4 kundan 7 kungacha ma'lumotlarni saqlashga o'tamiz. Bu tezkor ish uchun etarli bo'ladi, chunki biz har doim hodisalarni imkon qadar tezroq tekshirishga harakat qilamiz va uzoq muddatli tekshiruvlar uchun telemetriya ma'lumotlari mavjud.
2019-yil oktabr oyida cian.ru ga trafik oyiga 15,3 million noyob foydalanuvchiga yetdi. Bu loglarni etkazib berish uchun me'moriy yechimning jiddiy sinoviga aylandi.
Endi biz ElasticSearch-ni 7-versiyaga yangilashga tayyorgarlik ko'rmoqdamiz. Biroq buning uchun biz ElasticSearch-da ko'plab indekslarning xaritasini yangilashimiz kerak bo'ladi, chunki ular 5.5 versiyasidan ko'chirilgan va 6-versiyada eskirgan deb e'lon qilingan (ular versiyada shunchaki mavjud emas). 7). Bu shuni anglatadiki, yangilanish jarayonida, albatta, qandaydir fors-major holatlari bo'ladi, bu muammoni hal qilishda bizni jurnallarsiz qoldiradi. 7-versiyadan biz Kibana-ni yaxshilangan interfeys va yangi filtrlar bilan kutmoqdamiz.
Biz asosiy maqsadimizga erishdik: biz jurnallarni yo'qotishni to'xtatdik va infratuzilma klasterining ishlamay qolish vaqtini haftada 2-3 ta avariyadan oyiga bir necha soatlik texnik xizmat ko'rsatish ishlariga qisqartirdik. Ishlab chiqarishdagi bu ishlarning barchasi deyarli ko'rinmas. Biroq, endi biz xizmatimiz bilan nima sodir bo'layotganini aniq aniqlashimiz mumkin, biz buni tezda jim rejimda qila olamiz va jurnallar yo'qolishidan xavotirlanmaymiz. Umuman olganda, biz mamnunmiz, xursandmiz va yangi ekspluatatsiyalarga tayyorlanyapmiz, bu haqda keyinroq gaplashamiz.
Manba: www.habr.com
