


Tôi đã xem được một số tài liệu thú vị về trí tuệ nhân tạo trong trò chơi. Với phần giải thích những điều cơ bản về AI bằng các ví dụ đơn giản và bên trong có nhiều công cụ và phương pháp hữu ích để phát triển và thiết kế nó một cách thuận tiện. Làm thế nào, ở đâu và khi nào sử dụng chúng cũng ở đó.
Hầu hết các ví dụ đều được viết bằng mã giả nên không cần có kiến thức lập trình nâng cao. Dưới phần cắt có 35 trang văn bản có hình ảnh và ảnh gif, vì vậy hãy chuẩn bị sẵn sàng.
CẬP NHẬT. Tôi xin lỗi, nhưng tôi đã tự dịch bài viết này trên Habré rồi. . Bạn có thể đọc phiên bản của anh ấy , nhưng không hiểu sao bài viết lại bị bỏ qua (tôi đã sử dụng tìm kiếm nhưng đã xảy ra lỗi). Và vì tôi đang viết trên một blog dành riêng cho việc phát triển trò chơi nên tôi quyết định để lại phiên bản dịch của mình cho người đăng ký (một số điểm được định dạng khác, một số điểm đã được cố tình bỏ qua theo lời khuyên của nhà phát triển).
AI là gì?
AI của trò chơi tập trung vào những hành động mà một đối tượng nên thực hiện dựa trên các điều kiện của nó. Điều này thường được gọi là quản lý "tác nhân thông minh", trong đó tác nhân là nhân vật của người chơi, phương tiện, robot hoặc đôi khi là thứ gì đó trừu tượng hơn: toàn bộ nhóm thực thể hoặc thậm chí là một nền văn minh. Trong mỗi trường hợp, nó là một vật phải nhìn thấy môi trường của nó, đưa ra quyết định dựa trên môi trường đó và hành động phù hợp với môi trường đó. Đây được gọi là chu trình Nhận thức/Suy nghĩ/Hành động:
- Ý nghĩa: Tác nhân tìm hoặc nhận thông tin về những thứ trong môi trường của nó có thể ảnh hưởng đến hành vi của nó (các mối đe dọa ở gần, các vật phẩm cần thu thập, những địa điểm thú vị để khám phá).
- Hãy suy nghĩ: Đặc vụ quyết định cách phản ứng (xem xét liệu nó có đủ an toàn để thu thập vật phẩm hay không hoặc liệu anh ta nên chiến đấu/ẩn náu trước).
- Hành động: tác nhân thực hiện các hành động để thực hiện quyết định trước đó (bắt đầu di chuyển về phía kẻ thù hoặc đối tượng).
- ...bây giờ tình thế đã thay đổi do hành động của các nhân vật nên chu trình lặp lại với dữ liệu mới.
AI có xu hướng tập trung vào phần Sense của vòng lặp. Ví dụ, ô tô tự hành chụp ảnh đường đi, kết hợp chúng với dữ liệu radar và lidar rồi diễn giải chúng. Điều này thường được thực hiện bằng máy học, xử lý dữ liệu đến và mang lại ý nghĩa cho dữ liệu đó, trích xuất thông tin ngữ nghĩa như “có một chiếc ô tô khác ở phía trước bạn 20 thước”. Đây là những vấn đề được gọi là phân loại.
Trò chơi không cần một hệ thống phức tạp để trích xuất thông tin vì hầu hết dữ liệu đã là một phần không thể thiếu của nó. Không cần chạy thuật toán nhận dạng hình ảnh để xác định xem có kẻ thù phía trước hay không—trò chơi đã biết và cung cấp thông tin trực tiếp vào quá trình ra quyết định. Vì vậy, phần Nhận thức của chu trình thường đơn giản hơn nhiều so với phần Suy nghĩ và Hành động.
Hạn chế của AI trong trò chơi
AI có một số hạn chế cần phải được quan sát:
- AI không cần phải được đào tạo trước, như thể nó là một thuật toán học máy. Thật vô nghĩa khi viết một mạng lưới thần kinh trong quá trình phát triển để giám sát hàng chục nghìn người chơi và tìm hiểu cách tốt nhất để đấu với họ. Tại sao? Vì game chưa ra mắt và chưa có người chơi.
- Trò chơi phải vui nhộn và đầy thử thách, vì vậy các đặc vụ không nên tìm ra cách tiếp cận tốt nhất để chống lại mọi người.
- Các đặc vụ cần trông thực tế để người chơi có cảm giác như đang đấu với người thật. Chương trình AlphaGo hoạt động tốt hơn con người, nhưng các bước được chọn lại rất xa so với cách hiểu truyền thống về trò chơi. Nếu trò chơi mô phỏng đối thủ là con người thì cảm giác này sẽ không tồn tại. Thuật toán cần phải được thay đổi để đưa ra những quyết định hợp lý hơn là những quyết định lý tưởng.
- AI phải hoạt động trong thời gian thực. Điều này có nghĩa là thuật toán không thể độc quyền sử dụng CPU trong thời gian dài để đưa ra quyết định. Thậm chí 10 mili giây cũng là quá dài, bởi hầu hết các trò chơi chỉ cần 16 đến 33 mili giây để thực hiện tất cả quá trình xử lý và chuyển sang khung đồ họa tiếp theo.
- Lý tưởng nhất là ít nhất một phần của hệ thống phải được điều khiển bằng dữ liệu để những người không phải là lập trình viên có thể thực hiện các thay đổi và điều chỉnh có thể diễn ra nhanh hơn.
Hãy xem xét các phương pháp tiếp cận AI bao trùm toàn bộ chu trình Nhận thức/Suy nghĩ/Hành động.
Đưa ra quyết định cơ bản
Hãy bắt đầu với trò chơi đơn giản nhất - Pong. Mục tiêu: di chuyển mái chèo sao cho bóng nảy ra khỏi nó thay vì bay qua nó. Nó giống như quần vợt, bạn sẽ thua nếu không đánh được bóng. Ở đây AI có một nhiệm vụ tương đối dễ dàng - quyết định nên di chuyển nền tảng theo hướng nào.

Câu điều kiện
Đối với AI trong Pong, giải pháp rõ ràng nhất là luôn cố gắng đặt bệ dưới quả bóng.
Một thuật toán đơn giản cho việc này, được viết bằng mã giả:
mọi khung hình/cập nhật trong khi trò chơi đang chạy:
nếu quả bóng ở bên trái của mái chèo:
di chuyển mái chèo sang trái
ngược lại nếu quả bóng ở bên phải của mái chèo:
di chuyển mái chèo sang phải
Nếu nền tảng di chuyển với tốc độ của quả bóng thì đây là thuật toán lý tưởng cho AI trong Pong. Không cần phải phức tạp hóa bất cứ điều gì nếu không có quá nhiều dữ liệu và các hành động có thể thực hiện được cho đại lý.
Cách tiếp cận này đơn giản đến mức toàn bộ chu trình Nhận thức/Suy nghĩ/Hành động hầu như không đáng chú ý. Nhưng nó ở đó:
- Phần Sense nằm trong hai câu lệnh if. Trò chơi biết quả bóng ở đâu và nền tảng ở đâu, vì vậy AI sẽ tìm kiếm thông tin đó.
- Phần Think cũng được bao gồm trong hai câu lệnh if. Chúng thể hiện hai giải pháp, trong trường hợp này là loại trừ lẫn nhau. Kết quả là một trong ba hành động được chọn - di chuyển bệ sang trái, di chuyển sang phải hoặc không làm gì nếu nó đã được định vị chính xác.
- Phần Hành động được tìm thấy trong câu lệnh Di chuyển mái chèo sang trái và Di chuyển mái chèo sang phải. Tùy thuộc vào thiết kế trò chơi, họ có thể di chuyển nền tảng ngay lập tức hoặc ở một tốc độ cụ thể.
Những cách tiếp cận như vậy được gọi là phản ứng - có một bộ quy tắc đơn giản (trong trường hợp này là các câu lệnh if trong mã) phản ứng với trạng thái hiện tại của thế giới và thực hiện hành động.
Cây quyết định
Ví dụ về Pong thực sự tương đương với một khái niệm AI chính thức được gọi là cây quyết định. Thuật toán sẽ đi qua nó để đi tới một “chiếc lá”—một quyết định về hành động cần thực hiện.
Hãy tạo sơ đồ khối của cây quyết định cho thuật toán của nền tảng của chúng tôi:
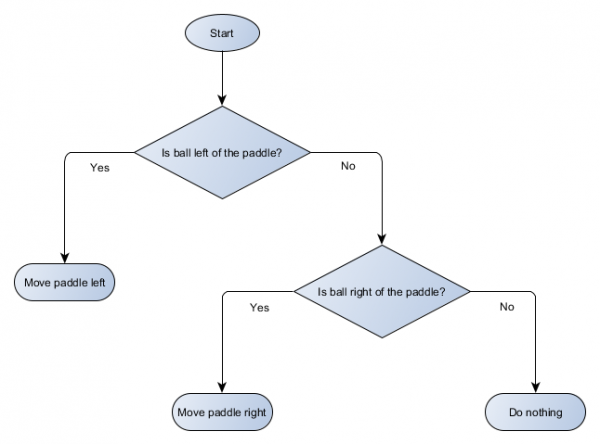
Mỗi phần của cây được gọi là một nút - AI sử dụng lý thuyết đồ thị để mô tả các cấu trúc đó. Có hai loại nút:
- Nút quyết định: lựa chọn giữa hai phương án dựa trên việc kiểm tra một số điều kiện, trong đó mỗi phương án được biểu diễn dưới dạng một nút riêng biệt.
- Nút kết thúc: Hành động cần thực hiện thể hiện quyết định cuối cùng.
Thuật toán bắt đầu từ nút đầu tiên (“gốc” của cây). Nó sẽ đưa ra quyết định về nút con nào sẽ đi tới hoặc thực hiện hành động được lưu trữ trong nút đó và thoát ra.
Lợi ích của việc cây quyết định thực hiện công việc tương tự như các câu lệnh if trong phần trước là gì? Ở đây có một hệ thống chung trong đó mỗi quyết định chỉ có một điều kiện và hai kết quả có thể xảy ra. Điều này cho phép nhà phát triển tạo AI từ dữ liệu thể hiện các quyết định trong cây mà không cần phải mã hóa cứng. Hãy trình bày nó dưới dạng bảng:
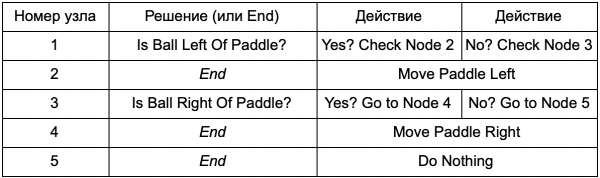
Về phía mã, bạn sẽ có một hệ thống đọc chuỗi. Tạo một nút cho mỗi nút, kết nối logic quyết định dựa trên cột thứ hai và các nút con dựa trên cột thứ ba và thứ tư. Bạn vẫn cần lập trình các điều kiện và hành động, nhưng bây giờ cấu trúc của trò chơi sẽ phức tạp hơn. Tại đây, bạn thêm các quyết định và hành động bổ sung, sau đó tùy chỉnh toàn bộ AI bằng cách chỉnh sửa tệp văn bản định nghĩa cây. Tiếp theo, bạn chuyển tệp cho nhà thiết kế trò chơi, người có thể thay đổi hành vi mà không cần biên dịch lại trò chơi hoặc thay đổi mã.
Cây quyết định rất hữu ích khi chúng được xây dựng tự động từ một tập hợp lớn các ví dụ (ví dụ: sử dụng thuật toán ID3). Điều này làm cho chúng trở thành một công cụ hiệu quả và hiệu suất cao để phân loại các tình huống dựa trên dữ liệu thu được. Tuy nhiên, chúng tôi vượt xa một hệ thống đơn giản để các tổng đài viên lựa chọn hành động.
Tập lệnh
Chúng tôi đã phân tích hệ thống cây quyết định sử dụng các điều kiện và hành động được tạo trước. Người thiết kế AI có thể sắp xếp cây theo cách mình muốn nhưng vẫn phải nhờ đến người lập trình đã lập trình tất cả. Điều gì sẽ xảy ra nếu chúng ta có thể cung cấp cho nhà thiết kế những công cụ để tạo ra các điều kiện hoặc hành động của riêng họ?
Để lập trình viên không phải viết mã cho các điều kiện Is Ball Left Of Paddle và Is Ball Right Of Paddle, anh ta có thể tạo một hệ thống trong đó người thiết kế sẽ viết các điều kiện để kiểm tra các giá trị này. Sau đó, dữ liệu cây quyết định sẽ trông như thế này:
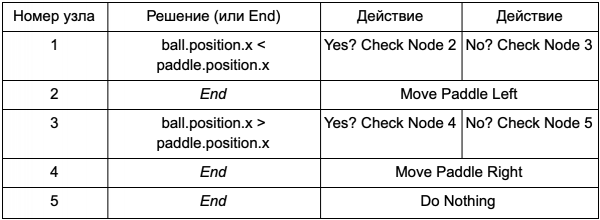
Về cơ bản, điều này giống như trong bảng đầu tiên, nhưng bản thân các giải pháp đều có mã riêng, hơi giống phần điều kiện của câu lệnh if. Về mặt mã, điều này sẽ đọc trong cột thứ hai cho các nút quyết định, nhưng thay vì tìm kiếm một điều kiện cụ thể để thực thi (Is Ball Left Of Paddle), nó sẽ đánh giá biểu thức điều kiện và trả về đúng hoặc sai tương ứng. Việc này được thực hiện bằng ngôn ngữ kịch bản Lua hoặc Angelscript. Bằng cách sử dụng chúng, nhà phát triển có thể lấy các đối tượng trong trò chơi của mình (bóng và mái chèo) và tạo các biến có sẵn trong tập lệnh (ball.position). Ngoài ra, ngôn ngữ kịch bản đơn giản hơn C++. Nó không yêu cầu một giai đoạn biên dịch đầy đủ, vì vậy nó rất lý tưởng để nhanh chóng điều chỉnh logic trò chơi và cho phép những người “không phải là lập trình viên” tự tạo ra các chức năng cần thiết.
Trong ví dụ trên, ngôn ngữ kịch bản chỉ được sử dụng để đánh giá biểu thức điều kiện nhưng nó cũng có thể được sử dụng cho các hành động. Ví dụ: dữ liệu Move Paddle Right có thể trở thành một câu lệnh script (ball.position.x += 10). Vì vậy, hành động đó cũng được xác định trong tập lệnh mà không cần phải lập trình Move Paddle Right.
Bạn có thể tiến xa hơn nữa và viết toàn bộ cây quyết định bằng ngôn ngữ kịch bản. Đây sẽ là mã ở dạng câu lệnh điều kiện được mã hóa cứng, nhưng chúng sẽ nằm trong các tệp tập lệnh bên ngoài, nghĩa là chúng có thể được thay đổi mà không cần biên dịch lại toàn bộ chương trình. Bạn có thể thường xuyên chỉnh sửa tệp tập lệnh trong khi chơi trò chơi để nhanh chóng kiểm tra các phản ứng AI khác nhau.
Phản hồi sự kiện
Các ví dụ trên là hoàn hảo cho Pong. Họ liên tục vận hành chu trình Nhận thức/Suy nghĩ/Hành động và hành động dựa trên tình hình mới nhất của thế giới. Nhưng trong những trò chơi phức tạp hơn, bạn cần phản ứng với từng sự kiện riêng lẻ và không đánh giá mọi thứ cùng một lúc. Pong trong trường hợp này đã là một ví dụ tồi rồi. Hãy chọn một cái khác.
Hãy tưởng tượng một game bắn súng mà kẻ thù bất động cho đến khi phát hiện ra người chơi, sau đó chúng hành động tùy theo “chuyên môn” của mình: có người sẽ chạy đến “lao”, có người sẽ tấn công từ xa. Đây vẫn là một hệ thống phản ứng cơ bản - "nếu người chơi bị phát hiện, hãy làm gì đó" - nhưng nó có thể được chia nhỏ một cách hợp lý thành sự kiện Người chơi đã thấy và Phản ứng (chọn một phản hồi và thực hiện nó).
Điều này đưa chúng ta trở lại chu trình Nhận thức/Suy nghĩ/Hành động. Chúng ta có thể mã hóa phần Sense sẽ kiểm tra mọi khung hình xem AI có nhìn thấy người chơi hay không. Nếu không, sẽ không có gì xảy ra, nhưng nếu nó nhìn thấy thì sự kiện Người chơi đã xem sẽ được tạo. Mã sẽ có một phần riêng có nội dung "khi sự kiện Người chơi đã xem xảy ra, hãy thực hiện", đâu là phản hồi bạn cần để giải quyết các phần Suy nghĩ và Hành động. Do đó, bạn sẽ thiết lập các phản ứng đối với sự kiện Người chơi đã thấy: đối với nhân vật “lao tới” - ChargeAndAttack và đối với xạ thủ - HideAndSnipe. Các mối quan hệ này có thể được tạo trong file dữ liệu để chỉnh sửa nhanh chóng mà không cần phải biên dịch lại. Ngôn ngữ kịch bản cũng có thể được sử dụng ở đây.
Đưa ra những quyết định khó khăn
Mặc dù các hệ thống phản ứng đơn giản rất mạnh mẽ nhưng có nhiều tình huống chúng không đủ. Đôi khi bạn cần đưa ra những quyết định khác nhau dựa trên những gì người đại diện hiện đang làm, nhưng thật khó để tưởng tượng đây là một điều kiện. Đôi khi có quá nhiều điều kiện để thể hiện chúng một cách hiệu quả trong cây quyết định hoặc tập lệnh. Đôi khi bạn cần đánh giá trước tình hình sẽ thay đổi như thế nào trước khi quyết định bước tiếp theo. Cần có những cách tiếp cận phức tạp hơn để giải quyết những vấn đề này.
Máy trạng thái hữu hạn
Máy trạng thái hữu hạn hoặc FSM (máy trạng thái hữu hạn) là một cách để nói rằng tác nhân của chúng tôi hiện đang ở một trong một số trạng thái có thể có và nó có thể chuyển từ trạng thái này sang trạng thái khác. Có một số trạng thái nhất định như vậy—do đó có tên như vậy. Ví dụ điển hình nhất trong cuộc sống là đèn giao thông. Có nhiều chuỗi ánh sáng khác nhau ở những nơi khác nhau, nhưng nguyên tắc thì giống nhau - mỗi trạng thái tượng trưng cho một điều gì đó (dừng lại, đi bộ, v.v.). Đèn giao thông chỉ ở một trạng thái tại một thời điểm nhất định và di chuyển từ trạng thái này sang trạng thái khác dựa trên các quy tắc đơn giản.
Đó là một câu chuyện tương tự với các NPC trong trò chơi. Ví dụ: chúng ta hãy bảo vệ với các trạng thái sau:
- Tuần tra.
- Tấn công.
- Chạy trốn.
Và những điều kiện để thay đổi trạng thái của nó:
- Nếu người bảo vệ nhìn thấy kẻ thù, anh ta tấn công.
- Nếu người bảo vệ tấn công nhưng không còn nhìn thấy kẻ thù thì anh ta quay lại tuần tra.
- Nếu lính canh tấn công nhưng bị thương nặng, anh ta sẽ bỏ chạy.
Bạn cũng có thể viết câu lệnh if với biến trạng thái người giám hộ và nhiều cách kiểm tra khác nhau: có kẻ thù nào ở gần không, mức độ sức khỏe của NPC là bao nhiêu, v.v. Hãy thêm một vài trạng thái nữa:
- Nhàn rỗi - giữa các cuộc tuần tra.
- Tìm kiếm - khi kẻ thù được chú ý đã biến mất.
- Tìm kiếm sự giúp đỡ - khi kẻ thù bị phát hiện nhưng quá mạnh để chiến đấu một mình.
Sự lựa chọn cho mỗi người trong số họ bị hạn chế - ví dụ, người bảo vệ sẽ không đi tìm kẻ thù giấu mặt nếu anh ta có lượng máu thấp.
Rốt cuộc, có một danh sách khổng lồ các chữ "nếu" , Cái đó " có thể trở nên quá cồng kềnh, vì vậy chúng ta cần chính thức hóa một phương pháp cho phép chúng ta ghi nhớ các trạng thái và chuyển đổi giữa các trạng thái. Để làm điều này, chúng tôi tính đến tất cả các trạng thái và dưới mỗi trạng thái, chúng tôi viết ra danh sách tất cả các chuyển đổi sang trạng thái khác, cùng với các điều kiện cần thiết cho chúng.
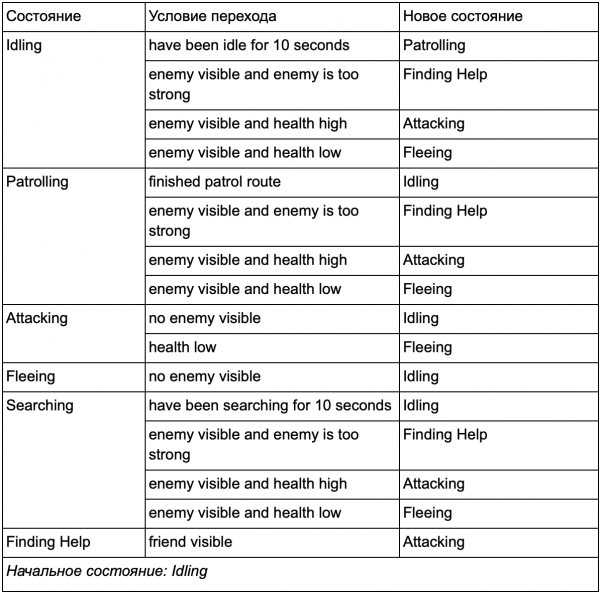
Đây là bảng chuyển trạng thái - một cách toàn diện để biểu diễn FSM. Hãy vẽ sơ đồ và có cái nhìn tổng quan đầy đủ về cách hành vi của NPC thay đổi.
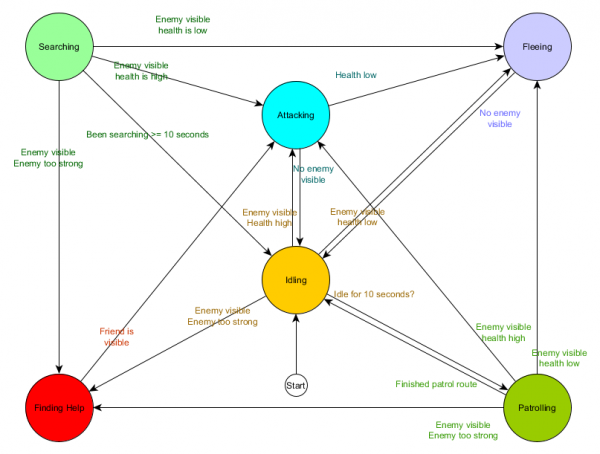
Sơ đồ phản ánh bản chất của việc ra quyết định cho tác nhân này dựa trên tình hình hiện tại. Hơn nữa, mỗi mũi tên biểu thị sự chuyển tiếp giữa các trạng thái nếu điều kiện bên cạnh nó đúng.
Mỗi bản cập nhật, chúng tôi kiểm tra trạng thái hiện tại của tác nhân, xem qua danh sách chuyển đổi và nếu các điều kiện chuyển đổi được đáp ứng, nó sẽ chấp nhận trạng thái mới. Ví dụ: mỗi khung sẽ kiểm tra xem bộ đếm thời gian 10 giây đã hết hạn chưa và nếu vậy thì bộ phận bảo vệ sẽ chuyển từ trạng thái Chờ sang Tuần tra. Theo cách tương tự, trạng thái Tấn công sẽ kiểm tra sức khỏe của đặc vụ - nếu nó ở mức thấp thì nó sẽ chuyển sang trạng thái Chạy trốn.
Đây là việc xử lý các chuyển đổi giữa các trạng thái, nhưng còn hành vi liên quan đến chính các trạng thái đó thì sao? Về việc triển khai hành vi thực tế cho một trạng thái cụ thể, thường có hai loại "hook" trong đó chúng tôi chỉ định hành động cho FSM:
- Các hành động mà chúng tôi thực hiện định kỳ cho trạng thái hiện tại.
- Các hành động chúng ta thực hiện khi chuyển từ trạng thái này sang trạng thái khác.
Ví dụ cho loại đầu tiên. Trạng thái Tuần tra sẽ di chuyển tác nhân dọc theo tuyến đường tuần tra trong mỗi khung. Trạng thái Tấn công sẽ cố gắng bắt đầu một cuộc tấn công vào từng khung hình hoặc chuyển sang trạng thái có thể thực hiện được.
Đối với loại thứ hai, hãy xem xét quá trình chuyển đổi “nếu nhìn thấy kẻ thù và kẻ thù quá mạnh thì chuyển sang trạng thái Tìm Trợ giúp. Tác nhân phải chọn nơi cần đến để được trợ giúp và lưu trữ thông tin này để trạng thái Tìm kiếm Trợ giúp biết nơi cần đến. Sau khi tìm thấy trợ giúp, đặc vụ sẽ quay lại trạng thái Tấn công. Lúc này, anh ta sẽ muốn thông báo cho đồng minh về mối đe dọa nên hành động NotifyFriendOfThreat có thể xảy ra.
Một lần nữa, chúng ta có thể nhìn hệ thống này qua lăng kính của chu trình Nhận thức/Suy nghĩ/Hành động. Sense được thể hiện trong dữ liệu được sử dụng bởi logic chuyển tiếp. Hãy suy nghĩ - chuyển tiếp có sẵn ở mỗi trạng thái. Và Đạo luật được thực hiện bằng các hành động được thực hiện định kỳ trong một trạng thái hoặc khi chuyển tiếp giữa các trạng thái.
Đôi khi các điều kiện chuyển tiếp thăm dò liên tục có thể tốn kém. Ví dụ: nếu mỗi tác nhân thực hiện các phép tính phức tạp trên mỗi khung hình để xác định xem liệu nó có thể nhìn thấy kẻ thù hay không và hiểu liệu nó có thể chuyển từ trạng thái Tuần tra sang Tấn công hay không, việc này sẽ tốn rất nhiều thời gian của CPU.
Những thay đổi quan trọng về tình hình thế giới có thể được coi là những sự kiện sẽ được xử lý khi chúng xảy ra. Thay vì FSM kiểm tra điều kiện chuyển tiếp "nhân viên của tôi có thể nhìn thấy trình phát không?" mỗi khung hình, một hệ thống riêng biệt có thể được cấu hình để kiểm tra ít thường xuyên hơn (ví dụ: 5 lần mỗi giây). Và kết quả là phát hành Player Seen khi kiểm tra thành công.
Điều này được chuyển đến FSM, bây giờ FSM sẽ chuyển đến điều kiện nhận được sự kiện Người chơi đã xem và phản hồi tương ứng. Hành vi kết quả là giống nhau ngoại trừ độ trễ gần như không thể nhận thấy trước khi phản hồi. Nhưng hiệu suất đã được cải thiện nhờ việc tách phần Sense thành một phần riêng biệt của chương trình.
Máy trạng thái hữu hạn phân cấp
Tuy nhiên, làm việc với các FSM lớn không phải lúc nào cũng thuận tiện. Nếu chúng ta muốn mở rộng trạng thái tấn công để tách MeleeAttacking và RangedAttacking, chúng ta sẽ phải thay đổi quá trình chuyển đổi từ tất cả các trạng thái khác dẫn đến trạng thái Tấn công (hiện tại và tương lai).
Bạn có thể nhận thấy rằng trong ví dụ của chúng tôi có rất nhiều chuyển tiếp trùng lặp. Hầu hết các chuyển đổi ở trạng thái Chờ đều giống với các chuyển đổi ở trạng thái Tuần tra. Sẽ tốt hơn nếu chúng ta không lặp lại chính mình, đặc biệt nếu chúng ta thêm nhiều trạng thái tương tự hơn. Thật hợp lý khi nhóm Chạy không tải và Tuần tra dưới nhãn chung là "không chiến đấu", trong đó chỉ có một tập hợp chuyển đổi chung sang trạng thái chiến đấu. Nếu chúng ta coi nhãn này như một trạng thái thì Chạy không tải và Tuần tra sẽ trở thành các trạng thái phụ. Một ví dụ về việc sử dụng bảng chuyển tiếp riêng cho trạng thái con không chiến đấu mới:
Các tiểu bang chính:
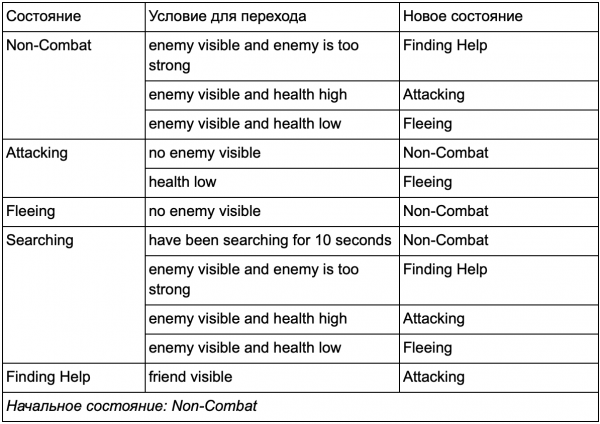
Tình trạng ngoài chiến đấu:

Và ở dạng sơ đồ:
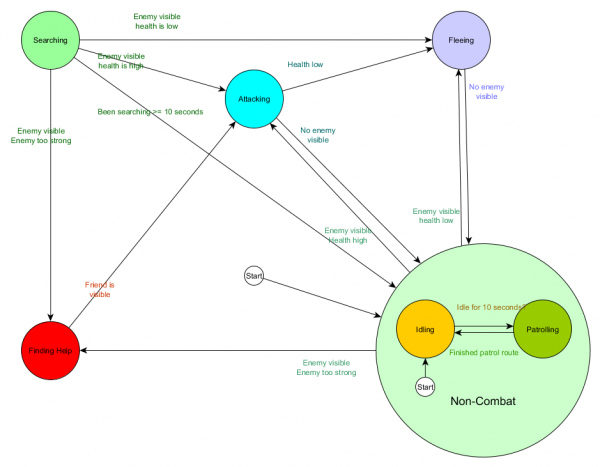
Đó là cùng một hệ thống, nhưng có trạng thái không chiến đấu mới bao gồm Chạy không tải và Tuần tra. Với mỗi trạng thái chứa một FSM với các trạng thái con (và các trạng thái con này lần lượt chứa các FSM của riêng chúng - v.v. miễn là bạn cần), chúng ta sẽ nhận được Máy trạng thái hữu hạn phân cấp hoặc HFSM (máy trạng thái hữu hạn phân cấp). Bằng cách nhóm trạng thái không chiến đấu, chúng tôi loại bỏ một loạt chuyển tiếp dư thừa. Chúng ta có thể làm tương tự cho bất kỳ trạng thái mới nào có các chuyển đổi chung. Ví dụ: nếu trong tương lai chúng tôi mở rộng trạng thái Tấn công sang trạng thái Tấn công cận chiến và Tấn công tên lửa, chúng sẽ là các trạng thái phụ chuyển đổi lẫn nhau dựa trên khoảng cách đến kẻ thù và tính sẵn có của đạn. Kết quả là, các hành vi phức tạp và các hành vi phụ có thể được biểu diễn với tối thiểu các chuyển đổi trùng lặp.
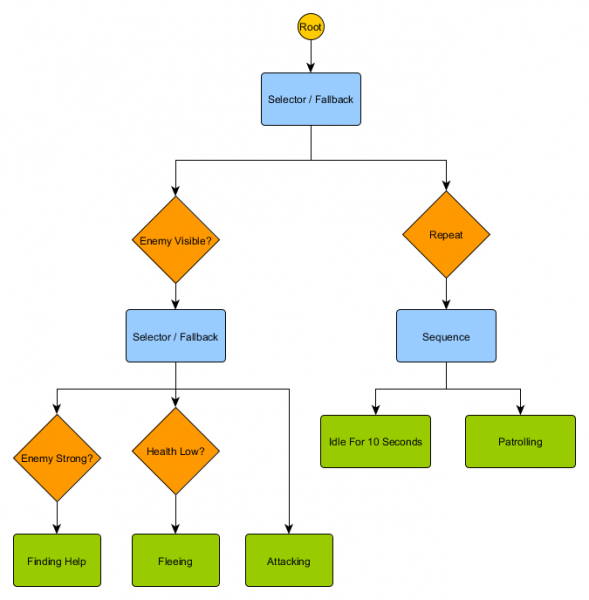
Cây hành vi
Với HFSM, các tổ hợp hành vi phức tạp được tạo ra một cách đơn giản. Tuy nhiên, có một khó khăn nhỏ là việc ra quyết định dưới dạng các quy tắc chuyển tiếp có liên quan mật thiết đến hiện trạng. Và trong nhiều trò chơi, đây chính xác là điều cần thiết. Và việc sử dụng cẩn thận hệ thống phân cấp trạng thái có thể làm giảm số lần lặp lại quá trình chuyển đổi. Nhưng đôi khi bạn cần các quy tắc có hiệu quả cho dù bạn đang ở trạng thái nào hoặc áp dụng ở hầu hết mọi trạng thái. Ví dụ: nếu máu của một đặc vụ giảm xuống 25%, bạn sẽ muốn anh ta bỏ chạy bất kể anh ta đang chiến đấu, nhàn rỗi hay đang nói chuyện - bạn sẽ phải thêm điều kiện này vào từng trạng thái. Và nếu sau này nhà thiết kế của bạn muốn thay đổi ngưỡng sức khoẻ thấp từ 25% thành 10% thì việc này sẽ phải được thực hiện lại.
Lý tưởng nhất là tình huống này đòi hỏi một hệ thống trong đó các quyết định về “trạng thái nào sẽ ở” nằm ngoài chính các trạng thái đó, để chỉ thực hiện các thay đổi ở một nơi và không chạm đến các điều kiện chuyển tiếp. Cây hành vi xuất hiện ở đây.
Có một số cách để triển khai chúng, nhưng bản chất gần như giống nhau đối với tất cả các cách và tương tự như cây quyết định: thuật toán bắt đầu bằng nút “gốc” và cây chứa các nút biểu thị quyết định hoặc hành động. Tuy nhiên, có một số khác biệt chính:
- Các nút bây giờ trả về một trong ba giá trị: Thành công (nếu công việc đã hoàn thành), Thất bại (nếu không thể bắt đầu) hoặc Đang chạy (nếu nó vẫn đang chạy và không có kết quả cuối cùng).
- Không còn nút quyết định nào để lựa chọn giữa hai lựa chọn thay thế. Thay vào đó, chúng là các nút Trang trí, có một nút con. Nếu thành công, họ sẽ thực thi nút con duy nhất của mình.
- Các nút thực hiện hành động trả về giá trị Đang chạy để biểu thị các hành động đang được thực hiện.
Tập hợp các nút nhỏ này có thể được kết hợp để tạo ra một số lượng lớn các hành vi phức tạp. Hãy tưởng tượng bộ bảo vệ HFSM trong ví dụ trước dưới dạng cây hành vi:
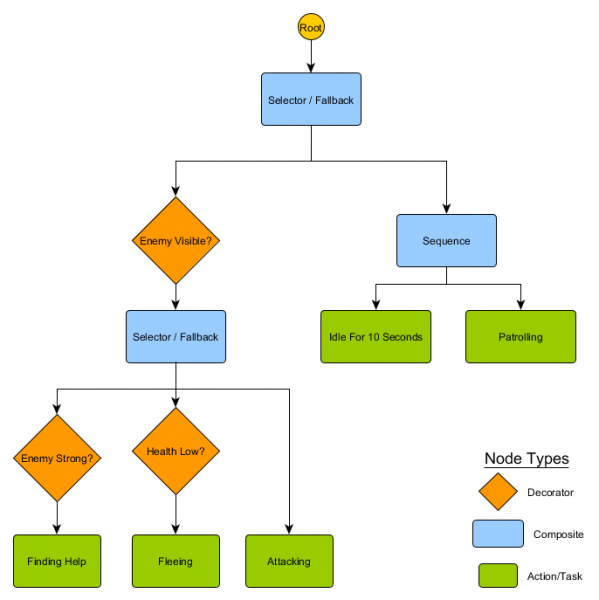
Với cấu trúc này sẽ không có sự chuyển đổi rõ ràng từ trạng thái Chờ/Tuần tra sang Tấn công hoặc bất kỳ trạng thái nào khác. Nếu kẻ thù lộ diện và sức khỏe của nhân vật thấp, việc thực thi sẽ dừng ở nút Chạy trốn, bất kể nó đang thực hiện nút nào trước đó - Tuần tra, Chạy không tải, Tấn công hay bất kỳ nút nào khác.
Cây hành vi rất phức tạp—có nhiều cách để sắp xếp chúng và việc tìm ra sự kết hợp phù hợp giữa trang trí và nút ghép có thể là một thách thức. Ngoài ra còn có các câu hỏi về tần suất kiểm tra cây - chúng ta muốn xem xét từng phần của cây hay chỉ khi một trong các điều kiện đã thay đổi? Làm cách nào để chúng tôi lưu trữ trạng thái liên quan đến các nút - làm cách nào để biết khi nào chúng tôi không hoạt động trong 10 giây hoặc làm cách nào để biết nút nào đang thực thi lần trước để chúng tôi có thể xử lý trình tự một cách chính xác?
Đây là lý do tại sao có nhiều triển khai. Ví dụ: một số hệ thống đã thay thế các nút trang trí bằng các nút trang trí nội tuyến. Họ đánh giá lại cây khi điều kiện trang trí thay đổi, giúp nối các nút và cung cấp các cập nhật định kỳ.
Hệ thống dựa trên tiện ích
Một số trò chơi có nhiều cơ chế khác nhau. Điều mong muốn là họ nhận được tất cả lợi ích của các quy tắc chuyển đổi chung và đơn giản, nhưng không nhất thiết phải ở dạng cây hành vi hoàn chỉnh. Thay vì có một tập hợp rõ ràng các lựa chọn hoặc một cây các hành động có thể thực hiện, việc kiểm tra tất cả các hành động và chọn hành động phù hợp nhất vào lúc đó sẽ dễ dàng hơn.
Hệ thống dựa trên Tiện ích sẽ giúp giải quyết vấn đề này. Đây là một hệ thống trong đó tác nhân có nhiều hành động khác nhau và chọn hành động nào sẽ thực hiện dựa trên tiện ích tương đối của từng hành động. Trong đó tiện ích là thước đo tùy ý về mức độ quan trọng hoặc mong muốn của tác nhân khi thực hiện hành động này.
Tiện ích được tính toán của một hành động dựa trên trạng thái và môi trường hiện tại, tác nhân có thể kiểm tra và chọn trạng thái khác phù hợp nhất bất cứ lúc nào. Điều này tương tự như FSM, ngoại trừ trường hợp quá trình chuyển đổi được xác định bằng ước tính cho từng trạng thái tiềm năng, bao gồm cả trạng thái hiện tại. Xin lưu ý rằng chúng tôi chọn hành động hữu ích nhất để tiếp tục (hoặc ở lại nếu chúng tôi đã hoàn thành hành động đó). Để đa dạng hơn, đây có thể là lựa chọn cân bằng nhưng ngẫu nhiên từ một danh sách nhỏ.
Hệ thống chỉ định một phạm vi giá trị tiện ích tùy ý—ví dụ: từ 0 (hoàn toàn không mong muốn) đến 100 (hoàn toàn mong muốn). Mỗi hành động có một số tham số ảnh hưởng đến việc tính giá trị này. Quay trở lại ví dụ về người giám hộ của chúng ta:

Sự chuyển đổi giữa các hành động không rõ ràng - bất kỳ trạng thái nào cũng có thể theo sau bất kỳ trạng thái nào khác. Các ưu tiên hành động được tìm thấy trong các giá trị tiện ích được trả về. Nếu kẻ thù có thể nhìn thấy được và kẻ thù đó mạnh và lượng máu của nhân vật thấp thì cả Chạy trốn và Tìm kiếm Trợ giúp sẽ trả về các giá trị cao khác 50. Trong trường hợp này, FindingHelp sẽ luôn cao hơn. Tương tự như vậy, các hoạt động không chiến đấu không bao giờ trả lại quá XNUMX, vì vậy chúng sẽ luôn thấp hơn các hoạt động chiến đấu. Bạn cần tính đến điều này khi tạo hành động và tính toán tiện ích của chúng.
Trong ví dụ của chúng tôi, các hành động trả về một giá trị không đổi cố định hoặc một trong hai giá trị cố định. Một hệ thống thực tế hơn sẽ trả về ước tính từ một phạm vi giá trị liên tục. Ví dụ: hành động Chạy trốn trả về giá trị tiện ích cao hơn nếu sức khỏe của đặc vụ thấp và hành động Tấn công trả về giá trị tiện ích thấp hơn nếu kẻ địch quá mạnh. Do đó, hành động Chạy trốn được ưu tiên hơn Tấn công trong mọi tình huống mà đặc vụ cảm thấy mình không đủ máu để đánh bại kẻ thù. Điều này cho phép các hành động được ưu tiên dựa trên bất kỳ tiêu chí nào, làm cho phương pháp này linh hoạt và thay đổi hơn so với cây hành vi hoặc FSM.
Mỗi hành động có nhiều điều kiện để tính toán chương trình. Chúng có thể được viết bằng ngôn ngữ kịch bản hoặc dưới dạng một chuỗi các công thức toán học. Sim, mô phỏng thói quen hàng ngày của nhân vật, bổ sung thêm một lớp tính toán - tác nhân nhận được một loạt "động lực" ảnh hưởng đến xếp hạng tiện ích. Nếu nhân vật đang đói, họ sẽ càng đói hơn theo thời gian và giá trị tiện ích của hành động EatFood sẽ tăng lên cho đến khi nhân vật thực hiện hành động đó, giảm mức độ đói và đưa giá trị EatFood về XNUMX.
Ý tưởng lựa chọn hành động dựa trên hệ thống xếp hạng khá đơn giản, do đó, hệ thống dựa trên Tiện ích có thể được sử dụng như một phần của quy trình ra quyết định AI, thay vì thay thế hoàn toàn cho chúng. Cây quyết định có thể yêu cầu xếp hạng tiện ích của hai nút con và chọn nút cao hơn. Tương tự, một cây hành vi có thể có một nút Tiện ích tổng hợp để đánh giá tiện ích của các hành động nhằm quyết định thành phần con nào sẽ thực thi.
Chuyển động và điều hướng
Trong các ví dụ trước, chúng ta có một nền tảng mà chúng ta có thể di chuyển sang trái hoặc phải và một người bảo vệ tuần tra hoặc tấn công. Nhưng chính xác thì chúng ta xử lý việc di chuyển của tác nhân trong một khoảng thời gian như thế nào? Làm cách nào để thiết lập tốc độ, làm cách nào để tránh chướng ngại vật và lập kế hoạch lộ trình khi việc đến đích khó hơn việc chỉ di chuyển theo đường thẳng? Hãy nhìn vào điều này.
Управление
Ở giai đoạn đầu, chúng ta sẽ giả định rằng mỗi tác nhân có một giá trị tốc độ, bao gồm tốc độ và hướng di chuyển của nó. Nó có thể được đo bằng mét trên giây, km trên giờ, pixel trên giây, v.v. Nhắc lại vòng lặp Sense/Suy nghĩ/Act, chúng ta có thể tưởng tượng rằng phần Think chọn một tốc độ và phần Act áp dụng tốc độ đó cho tác nhân. Thông thường, các trò chơi có hệ thống vật lý thực hiện nhiệm vụ này cho bạn, tìm hiểu giá trị tốc độ của từng đối tượng và điều chỉnh nó. Do đó, bạn có thể giao cho AI một nhiệm vụ - quyết định tốc độ mà tác nhân nên có. Nếu bạn biết tác nhân nên ở đâu thì bạn cần di chuyển nó đi đúng hướng với tốc độ đã định. Một phương trình rất tầm thường:
mong muốn_travel = điểm đến_vị trí – đại lý_vị trí
Hãy tưởng tượng một thế giới 2D. Tác nhân đang ở điểm (-2, -2), đích đến là ở đâu đó ở phía đông bắc tại điểm (30, 20) và đường dẫn cần thiết để tác nhân đến đó là (32, 22). Giả sử những vị trí này được đo bằng mét - nếu chúng ta lấy tốc độ của tác nhân là 5 mét mỗi giây, thì chúng ta sẽ chia tỷ lệ vectơ dịch chuyển của mình và đạt tốc độ xấp xỉ (4.12, 2.83). Với các thông số này, tác nhân sẽ đến đích sau gần 8 giây.
Bạn có thể tính toán lại các giá trị bất cứ lúc nào. Nếu tác nhân đi được nửa đường đến mục tiêu thì chuyển động sẽ bằng một nửa chiều dài, nhưng vì tốc độ tối đa của tác nhân là 5 m/s (chúng tôi đã quyết định điều này ở trên), tốc độ sẽ như nhau. Điều này cũng có tác dụng với các mục tiêu đang di chuyển, cho phép tác nhân thực hiện những thay đổi nhỏ khi chúng di chuyển.
Nhưng chúng tôi muốn có nhiều biến thể hơn - ví dụ: tăng dần tốc độ để mô phỏng nhân vật chuyển từ đứng sang chạy. Điều tương tự có thể được thực hiện ở cuối trước khi dừng lại. Các tính năng này được gọi là hành vi lái, mỗi tính năng có tên cụ thể: Tìm kiếm, Chạy trốn, Đến nơi, v.v. Ý tưởng là lực tăng tốc có thể được áp dụng cho tốc độ của tác nhân, dựa trên việc so sánh vị trí của tác nhân và tốc độ hiện tại với đích đến trong để sử dụng các phương pháp khác nhau để di chuyển đến mục tiêu.
Mỗi hành vi có một mục đích hơi khác nhau. Tìm kiếm và Đến là những cách để di chuyển một đại lý đến đích. Tránh chướng ngại vật và tách biệt điều chỉnh chuyển động của tác nhân để tránh chướng ngại vật trên đường đến mục tiêu. Sự liên kết và gắn kết giữ cho các tác nhân di chuyển cùng nhau. Bất kỳ số lượng hành vi lái khác nhau nào cũng có thể được tổng hợp để tạo ra một vectơ đường dẫn duy nhất có tính đến tất cả các yếu tố. Một tác nhân sử dụng các hành vi Đến, Tách và Tránh Chướng ngại vật để tránh xa các bức tường và các tác nhân khác. Cách tiếp cận này hoạt động tốt ở những địa điểm mở mà không có những chi tiết không cần thiết.
Trong những điều kiện khó khăn hơn, việc bổ sung các hành vi khác nhau sẽ hoạt động kém hơn - ví dụ: một đặc vụ có thể bị mắc kẹt trong tường do xung đột giữa Đến và Tránh chướng ngại vật. Do đó, bạn cần xem xét các tùy chọn phức tạp hơn việc chỉ cộng tất cả các giá trị. Cách thực hiện như sau: thay vì cộng kết quả của từng hành vi, bạn có thể xem xét chuyển động theo các hướng khác nhau và chọn phương án tốt nhất.
Tuy nhiên, trong một môi trường phức tạp với những ngõ cụt và những lựa chọn về con đường phải đi, chúng ta sẽ cần một thứ gì đó thậm chí còn cao cấp hơn.
Tìm một con đường
Hành vi lái rất phù hợp cho việc di chuyển đơn giản trong khu vực rộng mở (sân bóng đá hoặc đấu trường), nơi đi từ A đến B là một con đường thẳng và chỉ có những đường vòng nhỏ quanh chướng ngại vật. Đối với các tuyến đường phức tạp, chúng ta cần tìm đường, đó là một cách khám phá thế giới và quyết định tuyến đường xuyên qua nó.
Đơn giản nhất là áp dụng một lưới cho mỗi ô vuông bên cạnh tác nhân và đánh giá xem chúng nào được phép di chuyển. Nếu một trong số đó là đích đến, hãy đi theo lộ trình từ mỗi ô vuông đến ô trước đó cho đến khi bạn đến điểm bắt đầu. Đây là tuyến đường. Nếu không, hãy lặp lại quy trình với các ô vuông khác gần đó cho đến khi bạn tìm thấy điểm đến của mình hoặc hết ô vuông (nghĩa là không có tuyến đường khả thi nào). Đây là cái được chính thức gọi là Tìm kiếm theo chiều rộng hoặc BFS (thuật toán tìm kiếm theo chiều rộng). Ở mỗi bước anh ta nhìn về mọi hướng (do đó là chiều rộng, "chiều rộng"). Không gian tìm kiếm giống như một mặt sóng di chuyển cho đến khi đến vị trí mong muốn - không gian tìm kiếm mở rộng ở mỗi bước cho đến khi bao gồm điểm cuối, sau đó nó có thể được truy ngược về điểm bắt đầu.
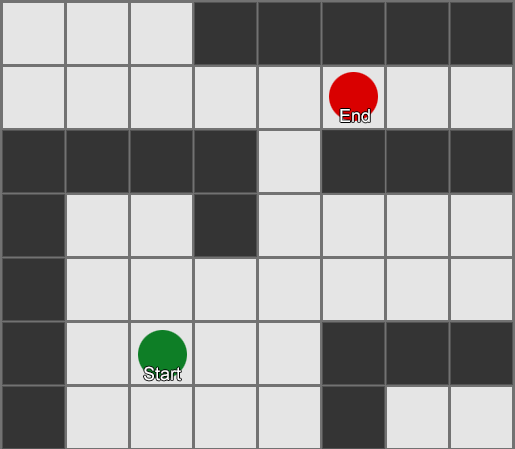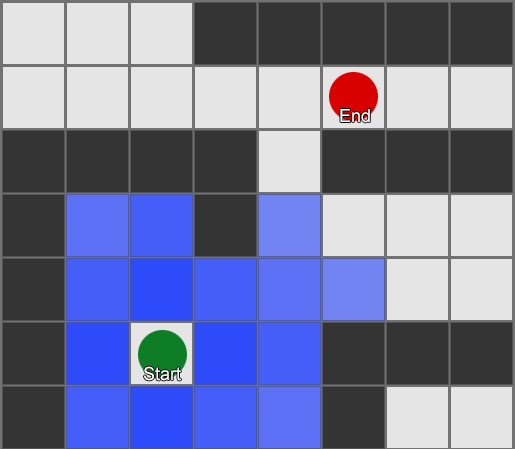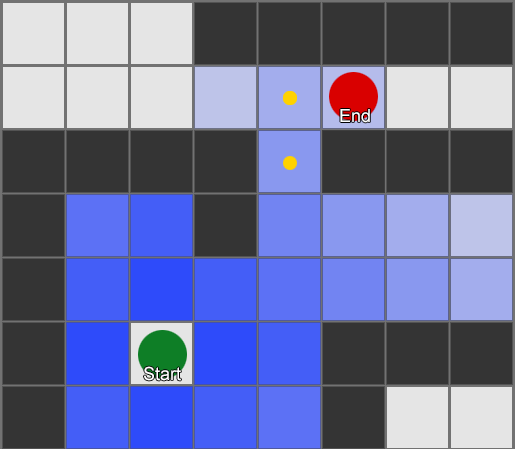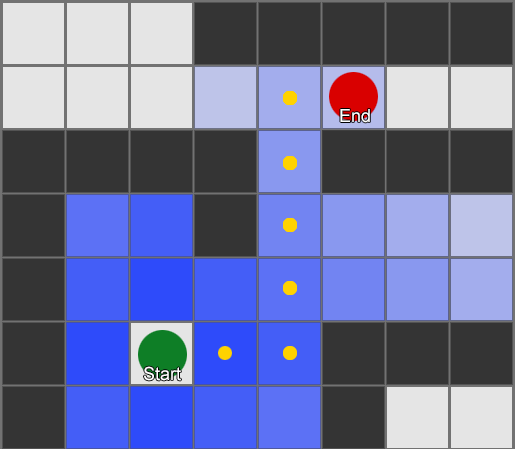
Kết quả là, bạn sẽ nhận được một danh sách các ô vuông dọc theo tuyến đường mong muốn được biên soạn. Đây là đường dẫn (do đó, tìm đường) - danh sách các địa điểm mà tác nhân sẽ ghé thăm khi đi theo đích đến.
Vì chúng ta biết vị trí của mọi hình vuông trên thế giới, chúng ta có thể sử dụng các hành vi điều khiển để di chuyển dọc theo đường đi - từ nút 1 đến nút 2, sau đó từ nút 2 đến nút 3, v.v. Tùy chọn đơn giản nhất là đi về phía trung tâm của hình vuông tiếp theo, nhưng một lựa chọn thậm chí còn tốt hơn là dừng lại ở giữa cạnh giữa hình vuông hiện tại và hình vuông tiếp theo. Bởi vì điều này, đặc vụ sẽ có thể cắt góc ở những khúc cua gấp.
Thuật toán BFS cũng có nhược điểm - nó khám phá nhiều ô vuông theo hướng “sai” cũng như theo hướng “đúng”. Đây là lúc một thuật toán phức tạp hơn được gọi là A* (A star) phát huy tác dụng. Nó hoạt động theo cách tương tự, nhưng thay vì kiểm tra một cách mù quáng các ô lân cận (sau đó là hàng xóm của hàng xóm, rồi hàng xóm của hàng xóm của hàng xóm, v.v.), nó thu thập các nút vào một danh sách và sắp xếp chúng sao cho nút tiếp theo được kiểm tra luôn là nút một trong đó dẫn đến con đường ngắn nhất. Các nút được sắp xếp dựa trên phương pháp phỏng đoán có tính đến hai yếu tố—“chi phí” của tuyến đường giả định đến ô vuông mong muốn (bao gồm mọi chi phí đi lại) và ước tính khoảng cách từ ô vuông đó đến đích (làm thiên vị tìm kiếm trong đúng hướng).
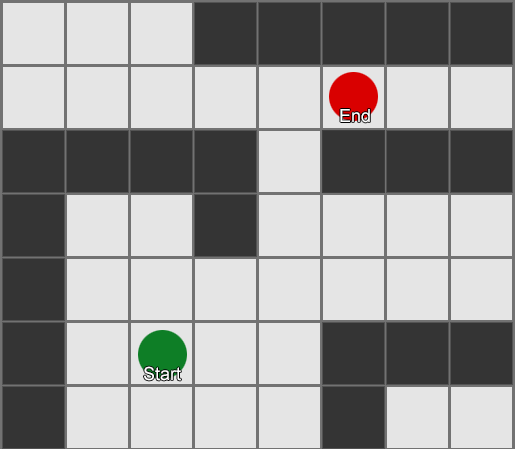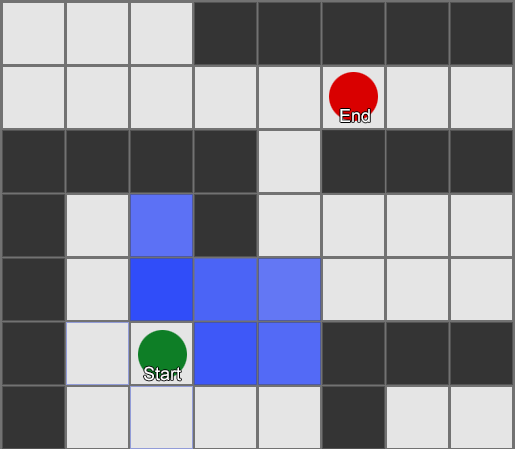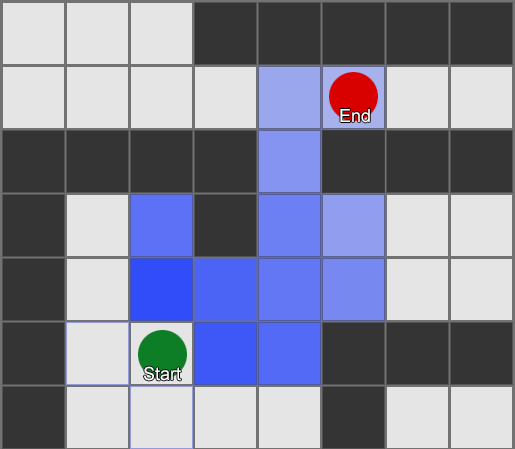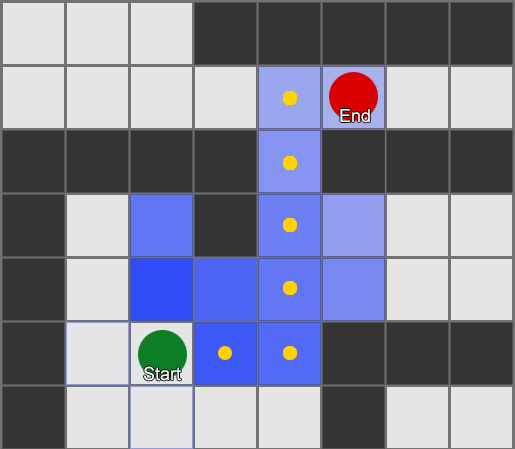
Ví dụ này cho thấy rằng tác nhân khám phá từng ô vuông một, mỗi lần chọn ô liền kề có triển vọng nhất. Đường dẫn kết quả giống như BFS, nhưng có ít ô vuông hơn được xem xét trong quá trình này - điều này có tác động lớn đến hiệu suất trò chơi.
Di chuyển không có lưới
Nhưng hầu hết các trò chơi không được bố trí trên một lưới và thường không thể làm được điều đó mà không hy sinh tính hiện thực. Sự thỏa hiệp là cần thiết. Hình vuông nên có kích thước như thế nào? Quá lớn thì chúng sẽ không thể thể hiện chính xác các hành lang hoặc lối rẽ nhỏ, quá nhỏ thì sẽ có quá nhiều ô vuông để tìm kiếm, điều này cuối cùng sẽ tốn rất nhiều thời gian.
Điều đầu tiên cần hiểu là lưới cung cấp cho chúng ta biểu đồ các nút được kết nối. Thuật toán A* và BFS thực sự hoạt động trên biểu đồ và hoàn toàn không quan tâm đến lưới của chúng tôi. Chúng ta có thể đặt các nút ở bất kỳ đâu trong thế giới trò chơi: miễn là có kết nối giữa hai nút được kết nối bất kỳ, cũng như giữa điểm bắt đầu và điểm kết thúc và ít nhất một trong các nút, thuật toán sẽ hoạt động tốt như trước. Đây thường được gọi là hệ thống điểm tham chiếu, vì mỗi nút đại diện cho một vị trí quan trọng trên thế giới và có thể là một phần của bất kỳ số lượng đường dẫn giả định nào.
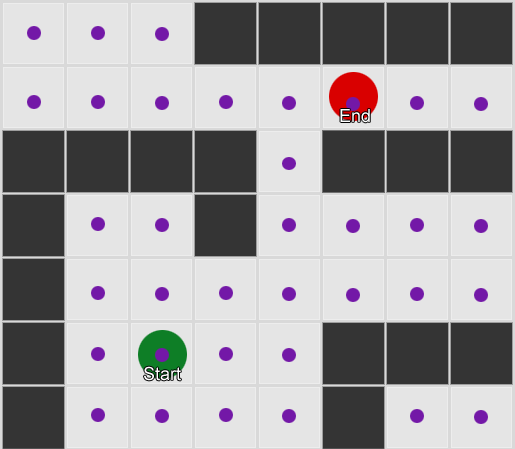
Ví dụ 1: một nút thắt ở mỗi hình vuông. Việc tìm kiếm bắt đầu từ nút nơi đặt tác nhân và kết thúc tại nút của ô vuông mong muốn.
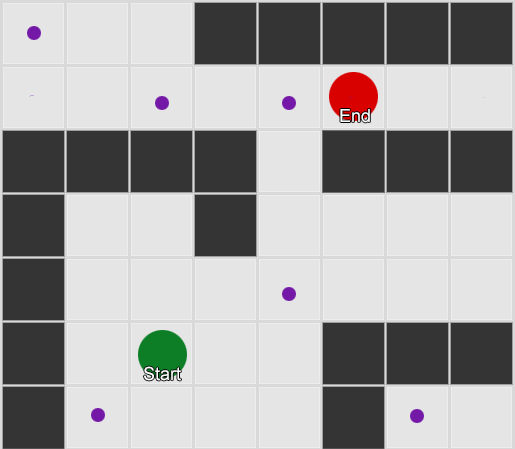
Ví dụ 2: Một tập hợp các nút (điểm tham chiếu) nhỏ hơn. Việc tìm kiếm bắt đầu tại ô vuông của tác nhân, đi qua số nút cần thiết và sau đó tiếp tục đến đích.
Đây là một hệ thống hoàn toàn linh hoạt và mạnh mẽ. Nhưng cần phải cẩn thận khi quyết định vị trí và cách đặt điểm tham chiếu, nếu không các đại lý có thể không nhìn thấy điểm gần nhất và sẽ không thể bắt đầu đường đi. Sẽ dễ dàng hơn nếu chúng ta có thể tự động đặt các điểm tham chiếu dựa trên hình dạng của thế giới.
Đây là nơi lưới điều hướng hoặc navmesh (lưới điều hướng) xuất hiện. Đây thường là một lưới hình tam giác 2D được phủ lên trên hình dạng của thế giới - bất cứ nơi nào đặc vụ được phép đi lại. Mỗi hình tam giác trong lưới trở thành một nút trong biểu đồ và có tối đa ba hình tam giác liền kề trở thành các nút liền kề trong biểu đồ.
Bức ảnh này là một ví dụ từ công cụ Unity - nó đã phân tích hình học trên thế giới và tạo ra một lưới điều hướng (trong ảnh chụp màn hình có màu xanh nhạt). Mỗi đa giác trong một navmesh là một khu vực mà một tác nhân có thể đứng hoặc di chuyển từ đa giác này sang đa giác khác. Trong ví dụ này, các đa giác nhỏ hơn các tầng mà chúng được đặt - điều này được thực hiện để tính đến kích thước của tác nhân, sẽ vượt ra ngoài vị trí danh nghĩa của nó.

Chúng ta có thể tìm kiếm tuyến đường qua lưới này bằng thuật toán A*. Điều này sẽ cung cấp cho chúng ta một tuyến đường gần như hoàn hảo trên thế giới, có tính đến tất cả các hình dạng hình học và không yêu cầu các nút cũng như việc tạo điểm tham chiếu không cần thiết.
Tìm đường là một chủ đề quá rộng mà một phần của bài viết là không đủ. Nếu bạn muốn nghiên cứu nó chi tiết hơn, thì điều này sẽ giúp ích .
Lập kế hoạch
Chúng tôi đã học được bằng cách tìm đường rằng đôi khi chỉ chọn hướng và di chuyển là chưa đủ - chúng tôi phải chọn một tuyến đường và rẽ vài lần để đến đích mong muốn. Chúng ta có thể khái quát hóa ý tưởng này: đạt được mục tiêu không chỉ là bước tiếp theo mà là cả một chuỗi mà đôi khi bạn cần xem trước một vài bước để tìm hiểu xem bước đầu tiên nên là gì. Điều này được gọi là lập kế hoạch. Việc tìm đường có thể được coi là một trong những phần mở rộng của việc lập kế hoạch. Xét về chu trình Nhận thức/Suy nghĩ/Hành động của chúng ta, đây là lúc phần Suy nghĩ lên kế hoạch cho nhiều phần Hành động cho tương lai.
Hãy cùng xem ví dụ về trò chơi board game Magic: The Gathering. Chúng ta bắt đầu với bộ thẻ sau trên tay:
- Đầm lầy - Cung cấp 1 mana đen (thẻ đất).
- Rừng - cho 1 năng lượng xanh (thẻ đất).
- Fugitive Wizard - Cần 1 mana xanh để triệu hồi.
- Elvish Mystic - Cần 1 mana xanh để triệu hồi.
Chúng ta bỏ qua ba lá bài còn lại để dễ dàng hơn. Theo quy định, người chơi được phép chơi 1 lá bài đất mỗi lượt, anh ta có thể “chạm” lá bài này để rút mana từ nó, sau đó sử dụng phép thuật (bao gồm cả triệu hồi một sinh vật) tùy theo lượng mana. Trong tình huống này, người chơi biết chơi Forest, chạm vào 1 mana xanh rồi triệu hồi Elvish Mystic. Nhưng làm thế nào AI của trò chơi có thể tìm ra điều này?
Lập kế hoạch dễ dàng
Cách tiếp cận tầm thường là thử lần lượt từng hành động cho đến khi không còn hành động nào phù hợp. Bằng cách nhìn vào các quân bài, AI sẽ biết Swamp có thể chơi gì. Và anh ấy chơi nó. Lượt này còn hành động nào khác không? Nó không thể triệu hồi Elf Mystic hoặc Fugitive Wizard, vì chúng yêu cầu năng lượng xanh lục và xanh lam tương ứng để triệu hồi chúng, trong khi Swamp chỉ cung cấp năng lượng đen. Và anh ấy sẽ không thể chơi Forest được nữa vì anh ấy đã chơi Swamp rồi. Vì vậy, trò chơi AI đã tuân theo luật lệ nhưng lại làm rất kém. Có thể được cải thiện.
Việc lập kế hoạch có thể tìm thấy danh sách các hành động đưa trò chơi đến trạng thái mong muốn. Giống như mọi ô vuông trên đường đi đều có hàng xóm (trong tìm đường), mọi hành động trong kế hoạch cũng có hàng xóm hoặc người kế thừa. Chúng ta có thể tìm kiếm những hành động này và những hành động tiếp theo cho đến khi đạt được trạng thái mong muốn.
Trong ví dụ của chúng tôi, kết quả mong muốn là “triệu hồi một sinh vật nếu có thể”. Khi bắt đầu lượt, chúng ta chỉ thấy hai hành động có thể được thực hiện theo luật chơi:
1. Chơi Swamp (kết quả: Swamp trong game)
2. Chơi Rừng (kết quả: Rừng trong game)
Mỗi hành động được thực hiện có thể dẫn đến các hành động tiếp theo và đóng lại các hành động khác, tùy thuộc vào luật chơi. Hãy tưởng tượng chúng ta đã chơi Swamp - thao tác này sẽ loại bỏ Swamp ở bước tiếp theo (chúng tôi đã chơi nó) và thao tác này cũng sẽ loại bỏ Rừng (vì theo quy tắc, bạn có thể chơi một thẻ đất mỗi lượt). Sau đó AI bổ sung thêm 1 mana đen là bước tiếp theo vì không còn lựa chọn nào khác. Nếu anh ta tiếp tục và chọn Tap the Swamp, anh ta sẽ nhận được 1 đơn vị mana đen và không thể làm gì với nó.
1. Chơi Swamp (kết quả: Swamp trong game)
1.1 Đầm lầy “Tap” (kết quả: Đầm lầy “đã chạm”, +1 đơn vị mana đen)
Không có hành động nào - END
2. Chơi Rừng (kết quả: Rừng trong game)
Danh sách hành động rất ngắn, chúng tôi đã đi vào ngõ cụt. Chúng tôi lặp lại quá trình cho bước tiếp theo. Chúng ta chơi Forest, mở hành động “nhận 1 mana xanh”, đến lượt nó sẽ mở ra hành động thứ ba - triệu hồi Elvish Mystic.
1. Chơi Swamp (kết quả: Swamp trong game)
1.1 Đầm lầy “Tap” (kết quả: Đầm lầy “đã chạm”, +1 đơn vị mana đen)
Không có hành động nào - END
2. Chơi Rừng (kết quả: Rừng trong game)
2.1 Rừng “Tap” (kết quả: Rừng bị “khai thác”, +1 đơn vị năng lượng xanh)
2.1.1 Triệu hồi Elvish Mystic (kết quả: Elvish Mystic đang chơi, -1 mana xanh)
Không có hành động nào - END
Cuối cùng, chúng tôi đã khám phá tất cả các hành động có thể xảy ra và tìm ra kế hoạch triệu hồi một sinh vật.
Đây là một ví dụ rất đơn giản. Nên chọn phương án tốt nhất có thể, thay vì chỉ chọn bất kỳ phương án nào đáp ứng một số tiêu chí. Nói chung có thể đánh giá các kế hoạch tiềm năng dựa trên kết quả hoặc lợi ích tổng thể của việc thực hiện chúng. Bạn có thể ghi cho mình 1 điểm khi chơi thẻ đất và 3 điểm khi triệu hồi sinh vật. Chơi Swamp sẽ là kế hoạch 1 điểm. Và chơi Forest → Tap the Forest → triệu hồi Elvish Mystic sẽ ngay lập tức được 4 điểm.
Đây là cách lập kế hoạch trong Magic: The Gathering, nhưng logic tương tự cũng được áp dụng trong các tình huống khác. Ví dụ như di chuyển một con tốt để nhường chỗ cho quân tượng di chuyển trong cờ vua. Hoặc nấp sau bức tường để bắn an toàn trong XCOM như thế này. Nói chung, bạn hiểu ý.
Cải thiện quy hoạch
Đôi khi có quá nhiều hành động tiềm năng để xem xét mọi lựa chọn có thể. Quay lại ví dụ với Magic: The Gathering: giả sử rằng trong trò chơi và trong tay bạn có một số thẻ đất và sinh vật - số lượng kết hợp các bước di chuyển có thể lên tới hàng chục. Có một số giải pháp cho vấn đề.
Phương pháp đầu tiên là chuỗi ngược. Thay vì thử tất cả các kết hợp, tốt hơn là bạn nên bắt đầu với kết quả cuối cùng và cố gắng tìm một lộ trình trực tiếp. Thay vì đi từ gốc cây đến một chiếc lá cụ thể, chúng ta di chuyển theo hướng ngược lại - từ lá đến gốc. Phương pháp này dễ dàng hơn và nhanh hơn.
Nếu kẻ địch còn 1 máu, bạn có thể tìm phương án “gây 1 sát thương trở lên”. Để đạt được điều này, một số điều kiện phải được đáp ứng:
1. Phép thuật có thể gây sát thương - nó phải có trong tay.
2. Để sử dụng phép thuật, bạn cần có mana.
3. Để lấy mana, bạn cần chơi bài đất.
4. Để chơi bài đất, bạn cần phải có trên tay.
Một cách khác là tìm kiếm tốt nhất đầu tiên. Thay vì thử mọi con đường, chúng ta chọn con đường phù hợp nhất. Thông thường, phương pháp này đưa ra kế hoạch tối ưu mà không tốn chi phí tìm kiếm không cần thiết. A* là một dạng tìm kiếm đầu tiên tốt nhất - bằng cách kiểm tra các tuyến đường hứa hẹn nhất ngay từ đầu, nó có thể tìm ra đường đi tốt nhất mà không cần phải kiểm tra các tùy chọn khác.
Một lựa chọn tìm kiếm tốt nhất đầu tiên thú vị và ngày càng phổ biến là Monte Carlo Tree Search. Thay vì đoán xem kế hoạch nào tốt hơn các kế hoạch khác khi chọn từng hành động tiếp theo, thuật toán sẽ chọn những người kế thừa ngẫu nhiên ở mỗi bước cho đến khi kết thúc (khi kế hoạch dẫn đến chiến thắng hoặc thất bại). Kết quả cuối cùng sau đó được sử dụng để tăng hoặc giảm trọng số của các tùy chọn trước đó. Bằng cách lặp lại quá trình này nhiều lần liên tiếp, thuật toán sẽ đưa ra ước tính tốt về hành động tiếp theo tốt nhất là gì, ngay cả khi tình huống thay đổi (nếu kẻ thù có hành động can thiệp vào người chơi).
Sẽ không có câu chuyện nào về việc lập kế hoạch trong trò chơi hoàn chỉnh nếu không có Lập kế hoạch hành động hướng tới mục tiêu hoặc GOAP (lập kế hoạch hành động hướng đến mục tiêu). Đây là một phương pháp được sử dụng và thảo luận rộng rãi, nhưng ngoài một số chi tiết khác biệt, về cơ bản nó là phương pháp xâu chuỗi ngược mà chúng ta đã nói đến trước đó. Nếu mục tiêu là "tiêu diệt người chơi" và người chơi đang ở sau chỗ ẩn nấp, kế hoạch có thể là: tiêu diệt bằng lựu đạn → lấy nó → ném nó.
Thường có một số mục tiêu, mỗi mục tiêu có mức độ ưu tiên riêng. Nếu không thể hoàn thành mục tiêu có mức độ ưu tiên cao nhất (không có sự kết hợp hành động nào tạo ra kế hoạch "giết người chơi" vì không nhìn thấy người chơi), AI sẽ quay trở lại các mục tiêu có mức độ ưu tiên thấp hơn.
Đào tạo và thích ứng
Chúng tôi đã nói rằng AI trong trò chơi thường không sử dụng máy học vì nó không phù hợp để quản lý các tổng đài viên trong thời gian thực. Nhưng điều này không có nghĩa là bạn không thể mượn thứ gì đó từ khu vực này. Chúng tôi muốn có một đối thủ trong game bắn súng mà chúng tôi có thể học được điều gì đó từ đó. Ví dụ: tìm hiểu về các vị trí tốt nhất trên bản đồ. Hoặc một đối thủ trong trò chơi đối kháng sẽ chặn các chiêu thức kết hợp thường được sử dụng của người chơi, thúc đẩy anh ta sử dụng các chiêu thức khác. Vì vậy, học máy có thể khá hữu ích trong những tình huống như vậy.
Thống kê và xác suất
Trước khi đi vào các ví dụ phức tạp, hãy xem chúng ta có thể đi được bao xa bằng cách thực hiện một vài phép đo đơn giản và sử dụng chúng để đưa ra quyết định. Ví dụ: chiến lược thời gian thực - làm cách nào để xác định liệu người chơi có thể phát động tấn công trong vài phút đầu tiên của trò chơi hay không và cần chuẩn bị phòng thủ gì để chống lại điều này? Chúng ta có thể nghiên cứu kinh nghiệm trong quá khứ của người chơi để hiểu những phản ứng trong tương lai có thể xảy ra. Đầu tiên, chúng tôi không có dữ liệu thô như vậy, nhưng chúng tôi có thể thu thập nó - mỗi khi AI đấu với con người, nó có thể ghi lại thời gian của cuộc tấn công đầu tiên. Sau một vài phiên, chúng ta sẽ có được thời gian trung bình để người chơi tấn công trong tương lai.
Ngoài ra còn có một vấn đề với các giá trị trung bình: nếu một người chơi lao tới 20 lần và chơi chậm 20 lần, thì các giá trị yêu cầu sẽ nằm ở đâu đó ở giữa và điều này sẽ không mang lại cho chúng ta điều gì hữu ích. Một giải pháp là hạn chế dữ liệu đầu vào - 20 phần cuối cùng có thể được tính đến.
Một cách tiếp cận tương tự được sử dụng khi ước tính khả năng xảy ra một số hành động nhất định bằng cách giả định rằng sở thích trong quá khứ của người chơi sẽ giống nhau trong tương lai. Nếu một người chơi tấn công chúng tôi năm lần bằng quả cầu lửa, hai lần bằng tia chớp và một lần bằng cận chiến, rõ ràng là anh ta thích quả cầu lửa hơn. Hãy ngoại suy và xem xác suất sử dụng các loại vũ khí khác nhau: cầu lửa=62,5%, sét=25% và cận chiến=12,5%. AI trong trò chơi của chúng ta cần chuẩn bị để tự bảo vệ mình khỏi lửa.
Một phương pháp thú vị khác là sử dụng Naive Bayes Classifier để nghiên cứu lượng lớn dữ liệu đầu vào và phân loại tình huống để AI phản ứng theo cách mong muốn. Bộ phân loại Bayesian được biết đến nhiều nhất nhờ công dụng của chúng trong các bộ lọc thư rác qua email. Ở đó, họ kiểm tra các từ, so sánh chúng với vị trí những từ đó đã xuất hiện trước đó (trong thư rác hoặc không) và đưa ra kết luận về các email đến. Chúng ta có thể làm điều tương tự ngay cả với ít đầu vào hơn. Dựa trên tất cả thông tin hữu ích mà AI nhìn thấy (chẳng hạn như đơn vị quân địch nào được tạo ra, phép thuật nào chúng sử dụng hoặc công nghệ nào chúng đã nghiên cứu) và kết quả cuối cùng (chiến tranh hay hòa bình, vội vàng hay phòng thủ, v.v.) - chúng tôi sẽ chọn hành vi AI mong muốn.
Tất cả các phương pháp đào tạo này là đủ, nhưng nên sử dụng chúng dựa trên dữ liệu thử nghiệm. AI sẽ học cách thích ứng với các chiến lược khác nhau mà người chơi của bạn đã sử dụng. AI thích ứng với người chơi sau khi phát hành có thể trở nên quá dễ đoán hoặc quá khó để đánh bại.
Thích ứng dựa trên giá trị
Dựa vào nội dung của thế giới trò chơi và các quy tắc, chúng ta có thể thay đổi tập hợp các giá trị ảnh hưởng đến việc ra quyết định thay vì chỉ sử dụng dữ liệu đầu vào. Chúng tôi làm điều này:
- Hãy để AI thu thập dữ liệu về tình hình thế giới và các sự kiện quan trọng trong trò chơi (như trên).
- Hãy thay đổi một vài giá trị quan trọng dựa trên dữ liệu này.
- Chúng tôi thực hiện các quyết định của mình dựa trên việc xử lý hoặc đánh giá các giá trị này.
Ví dụ: một đặc vụ có một số phòng để lựa chọn trên bản đồ bắn súng góc nhìn thứ nhất. Mỗi phòng đều có giá trị riêng, quyết định mức độ mong muốn được ghé thăm. AI chọn ngẫu nhiên phòng nào sẽ đi dựa trên giá trị. Sau đó, đặc vụ sẽ nhớ anh ta đã bị giết ở căn phòng nào và giảm giá trị của nó (xác suất anh ta sẽ quay lại đó). Tương tự cho tình huống ngược lại - nếu tác nhân tiêu diệt được nhiều đối thủ thì giá trị của phòng sẽ tăng lên.
mô hình Markov
Điều gì sẽ xảy ra nếu chúng ta sử dụng dữ liệu thu thập được để đưa ra dự đoán? Nếu chúng tôi nhớ từng phòng mà chúng tôi gặp người chơi trong một khoảng thời gian nhất định, chúng tôi sẽ dự đoán người chơi có thể vào phòng nào. Bằng cách theo dõi và ghi lại chuyển động của người chơi trong các phòng (giá trị), chúng tôi có thể dự đoán chúng.
Hãy lấy ba phòng: đỏ, xanh lá cây và xanh lam. Và cả những quan sát mà chúng tôi ghi lại được khi theo dõi phiên thi đấu:
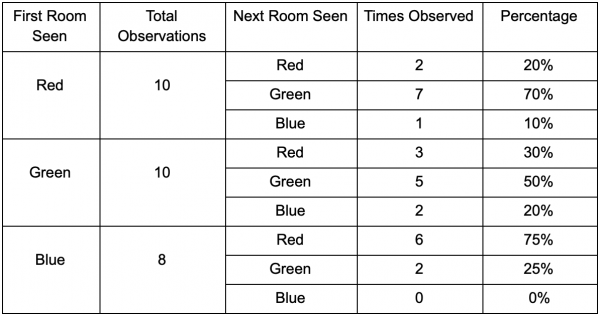
Số lượng quan sát trong mỗi phòng gần như bằng nhau - chúng tôi vẫn chưa biết tìm nơi nào tốt để phục kích. Việc thu thập số liệu thống kê cũng phức tạp do sự hồi sinh của người chơi xuất hiện đồng đều trên khắp bản đồ. Nhưng dữ liệu về phòng tiếp theo họ vào sau khi xuất hiện trên bản đồ đã rất hữu ích.
Có thể thấy phòng xanh phù hợp với người chơi - hầu hết mọi người đều di chuyển từ phòng đỏ đến phòng đó, 50% trong số họ vẫn ở đó thêm. Ngược lại, căn phòng màu xanh không được ưa chuộng, hầu như không có ai đến và nếu có thì họ cũng không ở lại lâu.
Nhưng dữ liệu cho chúng ta biết điều gì đó quan trọng hơn - khi người chơi ở trong phòng màu xanh lam, phòng tiếp theo mà chúng ta nhìn thấy anh ta sẽ có màu đỏ chứ không phải màu xanh lá cây. Mặc dù phòng xanh phổ biến hơn phòng đỏ nhưng tình hình sẽ thay đổi nếu người chơi ở trong phòng xanh. Trạng thái tiếp theo (tức là phòng mà người chơi sẽ đến) phụ thuộc vào trạng thái trước đó (tức là phòng mà người chơi hiện đang ở). Bởi vì chúng tôi khám phá sự phụ thuộc nên chúng tôi sẽ đưa ra dự đoán chính xác hơn so với việc chúng tôi chỉ đếm các quan sát một cách độc lập.
Dự đoán trạng thái trong tương lai dựa trên dữ liệu từ trạng thái trong quá khứ được gọi là mô hình Markov và các ví dụ như vậy (có phòng) được gọi là chuỗi Markov. Vì các mẫu thể hiện xác suất thay đổi giữa các trạng thái liên tiếp nên chúng được hiển thị trực quan dưới dạng FSM với xác suất xung quanh mỗi lần chuyển đổi. Trước đây, chúng tôi đã sử dụng FSM để thể hiện trạng thái hành vi của một tác nhân, nhưng khái niệm này mở rộng đến bất kỳ trạng thái nào, cho dù nó có liên quan đến tác nhân hay không. Trong trường hợp này, các tiểu bang đại diện cho phòng mà đại lý chiếm giữ:
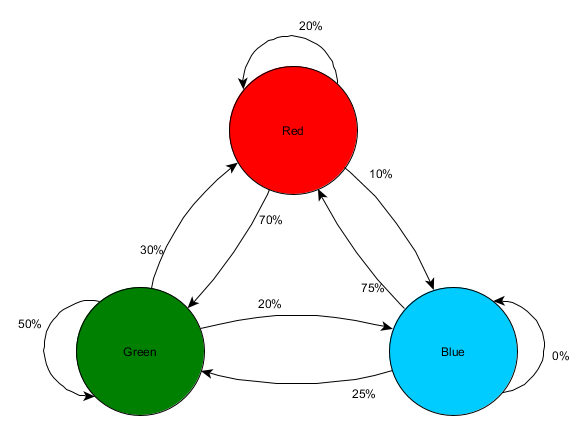
Đây là một cách đơn giản để thể hiện khả năng tương đối của các thay đổi trạng thái, mang lại cho AI một số khả năng dự đoán trạng thái tiếp theo. Bạn có thể dự đoán trước một số bước.
Nếu một người chơi ở trong phòng xanh, có 50% khả năng anh ta sẽ ở lại đó vào lần tiếp theo được quan sát. Nhưng khả năng anh ấy vẫn ở đó sau đó là bao nhiêu? Không chỉ có khả năng người chơi vẫn ở trong phòng xanh sau hai lần quan sát mà còn có khả năng anh ta đã rời đi và quay trở lại. Đây là bảng mới có tính đến dữ liệu mới:
Nó cho thấy khả năng nhìn thấy người chơi ở phòng xanh sau hai lần quan sát sẽ bằng 51% - 21% là người đó sẽ đến từ phòng đỏ, 5% trong số đó là người chơi sẽ đến phòng xanh giữa họ, và 25% người chơi sẽ không rời khỏi phòng xanh.
Bảng chỉ đơn giản là một công cụ trực quan - quy trình chỉ yêu cầu nhân các xác suất ở mỗi bước. Điều này có nghĩa là bạn có thể nhìn xa về tương lai với một lưu ý: chúng tôi cho rằng cơ hội vào phòng phụ thuộc hoàn toàn vào phòng hiện tại. Đây được gọi là Tài sản Markov - trạng thái tương lai chỉ phụ thuộc vào hiện tại. Nhưng điều này không chính xác XNUMX%. Người chơi có thể thay đổi quyết định tùy thuộc vào các yếu tố khác: mức độ sức khỏe hoặc số lượng đạn dược. Vì chúng tôi không ghi lại những giá trị này nên dự báo của chúng tôi sẽ kém chính xác hơn.
N-gam
Còn ví dụ về một game đối kháng và dự đoán các chiêu thức combo của người chơi thì sao? Giống nhau! Nhưng thay vì một trạng thái hoặc sự kiện, chúng ta sẽ xem xét toàn bộ trình tự tạo nên một đòn kết hợp.
Một cách để thực hiện việc này là lưu trữ từng đầu vào (chẳng hạn như Kick, Punch hoặc Block) vào bộ đệm và ghi toàn bộ bộ đệm dưới dạng một sự kiện. Vì vậy, người chơi liên tục nhấn Kick, Kick, Punch để sử dụng đòn tấn công SuperDeathFist, hệ thống AI lưu trữ tất cả thông tin đầu vào vào bộ đệm và ghi nhớ ba thông tin cuối cùng được sử dụng trong mỗi bước.
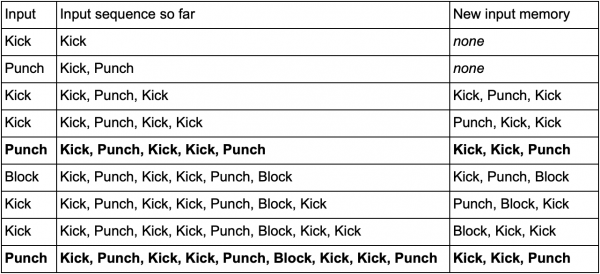
(Các dòng in đậm là khi người chơi tung ra đòn tấn công SuperDeathFist.)
AI sẽ thấy tất cả các tùy chọn khi người chơi chọn Kick, tiếp theo là một Kick khác và sau đó thông báo rằng đầu vào tiếp theo luôn là Punch. Điều này sẽ cho phép đặc vụ dự đoán bước di chuyển kết hợp của SuperDeathFist và chặn nó nếu có thể.
Những chuỗi sự kiện này được gọi là N-gram, trong đó N là số phần tử được lưu trữ. Trong ví dụ trước đó là 3 gram (lạ quái), có nghĩa là: hai mục đầu tiên được sử dụng để dự đoán mục thứ ba. Theo đó, trong 5 gam, bốn mục đầu tiên dự đoán mục thứ năm, v.v.
Người thiết kế cần chọn kích thước của N-gram một cách cẩn thận. N nhỏ hơn yêu cầu ít bộ nhớ hơn nhưng cũng lưu trữ ít lịch sử hơn. Ví dụ: 2 gram (bigram) sẽ ghi Kick, Kick hoặc Kick, Punch, nhưng sẽ không lưu được Kick, Kick, Punch nên AI sẽ không phản hồi với combo SuperDeathFist.
Mặt khác, số lượng lớn hơn đòi hỏi nhiều bộ nhớ hơn và AI sẽ khó huấn luyện hơn vì sẽ có nhiều lựa chọn khả thi hơn. Nếu bạn có ba đầu vào có thể là Kick, Punch hoặc Block và chúng tôi sử dụng loại 10 gam, thì đó sẽ có khoảng 60 nghìn tùy chọn khác nhau.
Mô hình bigram là một chuỗi Markov đơn giản - mỗi cặp trạng thái trong quá khứ/trạng thái hiện tại là một bigram và bạn có thể dự đoán trạng thái thứ hai dựa trên trạng thái đầu tiên. N-gram 3 gam và lớn hơn cũng có thể được coi là chuỗi Markov, trong đó tất cả các phần tử (ngoại trừ phần tử cuối cùng trong N-gram) cùng nhau tạo thành trạng thái đầu tiên và phần tử cuối cùng là phần tử thứ hai. Ví dụ về trò chơi đối kháng cho thấy cơ hội chuyển từ trạng thái Đá và Đá sang trạng thái Đá và Đấm. Bằng cách xử lý nhiều mục nhập lịch sử đầu vào dưới dạng một đơn vị, về cơ bản, chúng tôi đang chuyển đổi chuỗi đầu vào thành một phần của toàn bộ trạng thái. Điều này mang lại cho chúng ta thuộc tính Markov, cho phép chúng ta sử dụng chuỗi Markov để dự đoán đầu vào tiếp theo và đoán xem động tác kết hợp nào sẽ diễn ra tiếp theo.
Kết luận
Chúng tôi đã nói về những công cụ và cách tiếp cận phổ biến nhất trong việc phát triển trí tuệ nhân tạo. Chúng tôi cũng xem xét các tình huống mà chúng cần được sử dụng và chúng đặc biệt hữu ích ở đâu.
Điều này là đủ để hiểu những điều cơ bản về AI trong trò chơi. Nhưng tất nhiên đây không phải là tất cả các phương pháp. Ít phổ biến hơn nhưng không kém phần hiệu quả bao gồm:
- các thuật toán tối ưu hóa bao gồm leo đồi, giảm độ dốc và thuật toán di truyền
- thuật toán lập kế hoạch/tìm kiếm đối nghịch (cắt tỉa minimax và alpha-beta)
- phương pháp phân loại (perceptron, mạng lưới thần kinh và máy vectơ hỗ trợ)
- hệ thống nhận thức và trí nhớ của các tác nhân xử lý
- các phương pháp tiếp cận kiến trúc đối với AI (hệ thống lai, kiến trúc tập hợp con và các cách khác để xếp chồng các hệ thống AI)
- công cụ hoạt hình (lập kế hoạch và phối hợp chuyển động)
- các yếu tố hiệu suất (mức độ chi tiết, bất kỳ lúc nào và thuật toán cắt thời gian)
Tài nguyên Internet về chủ đề:
1. GameDev.net có và .
2. chứa nhiều bài thuyết trình và bài viết về nhiều chủ đề liên quan đến phát triển AI trong trò chơi.
3. bao gồm các chủ đề từ Hội nghị thượng đỉnh AI của GDC, nhiều chủ đề trong số đó được cung cấp miễn phí.
4. Các tài liệu hữu ích cũng có thể được tìm thấy trên trang web .
5. Tommy Thompson, nhà nghiên cứu AI và nhà phát triển trò chơi, tạo video trên YouTube với lời giải thích và nghiên cứu về AI trong trò chơi thương mại.
Sách về chủ đề:
1. Bộ sách Game AI Pro là tập hợp các bài viết ngắn giải thích cách triển khai các tính năng cụ thể hoặc cách giải quyết các vấn đề cụ thể.
2. Dòng AI Game Programming Wisdom là tiền thân của dòng Game AI Pro. Nó chứa các phương pháp cũ hơn, nhưng hầu hết tất cả đều có liên quan ngay cả ngày nay.
3. là một trong những văn bản cơ bản dành cho tất cả những ai muốn tìm hiểu lĩnh vực chung về trí tuệ nhân tạo. Đây không phải là cuốn sách về phát triển trò chơi - nó dạy những điều cơ bản về AI.
Nguồn: www.habr.com
