


你好,哈布尔。
最近我 关于我们作为一个团队最常使用 Kafka 生产者和消费者的哪些参数来更接近保证交付。 在本文中,我想告诉您我们如何组织重新处理由于外部系统暂时不可用而从 Kafka 收到的事件。
现代应用程序在非常复杂的环境中运行。 业务逻辑封装在现代技术堆栈中,在由 Kubernetes 或 OpenShift 等编排器管理的 Docker 映像中运行,并通过一系列物理和虚拟路由器与其他应用程序或企业解决方案进行通信。 在这样的环境中,某些东西总是可能会出现故障,因此,如果外部系统之一不可用,则重新处理事件是我们业务流程的重要组成部分。
卡夫卡之前是怎样的
在项目的早期,我们使用 IBM MQ 进行异步消息传递。 如果服务运行期间发生任何错误,则可以将接收到的消息放入死信队列(DLQ)中以供进一步手动解析。 DLQ 在传入队列旁边创建,消息在 IBM MQ 内部传输。
如果错误是暂时的并且我们可以确定它(例如,HTTP 调用上的 ResourceAccessException 或 MongoDb 请求上的 MongoTimeoutException),则重试策略将生效。 无论应用程序的分支逻辑如何,原始消息要么被移动到系统队列以延迟发送,要么被移动到很久以前创建的单独应用程序以重新发送消息。 这包括消息标头中的重发编号,该编号与延迟间隔或应用程序级策略的结束相关。 如果我们已经到达策略的末尾但外部系统仍然不可用,那么消息将被放置在DLQ中以供手动解析。
搜索解决方案
,你可以找到以下内容 。 简而言之,建议为每个延迟间隔创建一个主题,并在侧面实现 Consumer 应用程序,该应用程序将以所需的延迟读取消息。
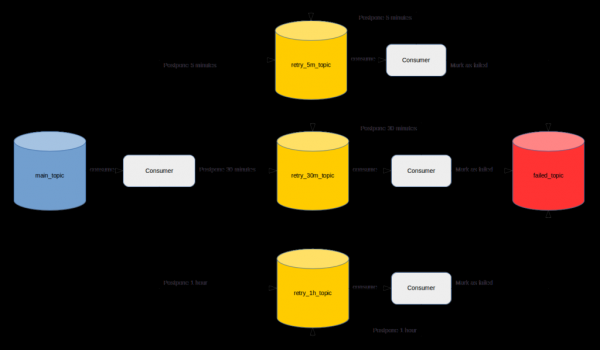
尽管有大量正面评价,但在我看来,它并不完全成功。 首先,因为开发人员除了实现业务需求之外,还必须花费大量时间来实现所描述的机制。
此外,如果在 Kafka 集群上启用了访问控制,您将必须花费一些时间创建主题并提供对它们的必要访问权限。 除此之外,您还需要为每个重试主题选择正确的retention.ms参数,以便消息有时间重新发送并且不会从中消失。 对于每个现有的或新的服务,必须重复实施和访问请求。
现在让我们看看 spring 和 spring-kafka 为我们提供了哪些机制来进行消息重新处理。 Spring-kafka 对 spring-retry 有传递依赖,它提供了管理不同 BackOffPolicies 的抽象。 这是一个相当灵活的工具,但其显着缺点是将消息存储在应用程序内存中以供重新发送。 这意味着由于更新或操作错误而重新启动应用程序将导致所有待重新处理的消息丢失。 由于这一点对于我们的系统至关重要,因此我们没有进一步考虑。
spring-kafka本身提供了ContainerAwareErrorHandler的几种实现,例如 ,使用它您可以稍后处理消息,而无需在发生错误时移动偏移量。 从 spring-kafka 2.3 版本开始,可以设置 BackOffPolicy。
这种方法允许重新处理的消息在应用程序重新启动后继续存在,但仍然没有 DLQ 机制。 我们在 2019 年初选择了这个选项,乐观地认为不需要 DLQ(我们很幸运,在使用这样的再处理系统运行应用程序几个月后实际上不需要它)。 临时错误导致 SeekToCurrentErrorHandler 触发。 剩余的错误被打印在日志中,导致偏移,并继续处理下一条消息。
最终决定
基于SeekToCurrentErrorHandler的实现促使我们开发自己的消息重发机制。
首先,我们想利用现有的经验,并根据应用逻辑进行扩展。 对于线性逻辑应用程序,最好在重试策略指定的短时间内停止读取新消息。 对于其他应用程序,我希望有一个可以强制执行重试策略的单点。 此外,该单点必须具有适用于两种方法的 DLQ 功能。
重试策略本身必须存储在应用程序中,应用程序负责在发生临时错误时检索下一个间隔。
停止线性逻辑应用程序的使用者
使用 spring-kafka 时,停止 Consumer 的代码可能如下所示:
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// to DLQ
}在示例中,retryAt 是重新启动 MessageListenerContainer(如果它仍在运行)的时间。 重新启动将发生在TaskScheduler中启动的单独线程中,该线程的实现也是由spring提供的。
我们通过以下方式找到 retryAt 值:
- 查找重新调用计数器的值。
- 根据计数器的值,查找当前重试策略中的延迟间隔。 该策略在应用程序本身中声明;我们选择 JSON 格式来存储它。
- JSON 数组中的间隔包含需要重复处理的秒数。 将此秒数添加到当前时间以形成 retryAt 的值。
- 如果没有找到间隔,那么retryAt的值为null,消息将被发送到DLQ进行手动解析。
使用这种方法,剩下的就是保存当前正在处理的每条消息的重复调用次数,例如在应用程序内存中。 将重试计数保留在内存中对于这种方法并不重要,因为线性逻辑应用程序无法处理整个处理。 与 spring-retry 不同的是,重新启动应用程序不会导致所有消息丢失而需要重新处理,而只是简单地重新启动策略。
这种方法有助于减轻外部系统的负载,外部系统可能由于负载过重而无法使用。 也就是说,除了重新处理之外,我们还实现了模式的实现 .
在我们的例子中,错误阈值仅为 1,为了最大限度地减少由于临时网络中断而导致的系统停机时间,我们使用了非常细粒度的重试策略,延迟间隔很小。 这可能并不适合所有的群体应用,因此必须根据系统的特性来选择误差阈值和间隔值之间的关系。
一个单独的应用程序,用于处理来自具有非确定性逻辑的应用程序的消息
以下是向此类应用程序(重试器)发送消息的代码示例,当到达 RETRY_AT 时间时,该应用程序将重新发送到 DESTINATION 主题:
public <K, V> void retry(ConsumerRecord<K, V> record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List<Header> arrayOfHeaders =
new ArrayList<>(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "backout"::getBytes);
}
ProducerRecord<K, V> messageToSend =
new ProducerRecord<>(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
}该示例显示大量信息是在标头中传输的。 RETRY_AT 的值的查找方式与通过 Consumer stop 重试机制相同。 除了 DESTINATION 和 RETRY_AT 之外,我们还传递:
- GROUP_ID,我们通过它对消息进行分组以进行手动分析和简化搜索。
- ORIGINAL_PARTITION 尝试保留相同的 Consumer 进行重新处理。 该参数可以为空,在这种情况下,将使用原始消息的 record.key() 键获取新分区。
- 更新了 COUNTER 值以遵循重试策略。
- SEND_TO 是一个常量,指示消息是在到达 RETRY_AT 时发送以进行重新处理还是放置在 DLQ 中。
- REASON - 消息处理中断的原因。
Retryer 在 PostgreSQL 中存储用于重新发送和手动解析的消息。 计时器启动一个任务,查找带有 RETRY_AT 的消息,并使用键 record.key() 将它们发送回 DESTINATION 主题的 ORIGINAL_PARTITION 分区。
发送后,消息将从 PostgreSQL 中删除。 消息的手动解析发生在一个简单的 UI 中,该 UI 通过 REST API 与 Retryer 交互。 其主要功能是从 DLQ 重新发送或删除消息、查看错误信息以及搜索消息(例如按错误名称)。
由于我们的集群启用了访问控制,因此需要另外请求访问 Retryer 正在侦听的主题,并允许 Retryer 写入 DESTINATION 主题。 这很不方便,但是与间隔主题方法不同,我们有一个成熟的 DLQ 和 UI 来管理它。
在某些情况下,传入的主题会被多个不同的消费者组读取,这些消费者组的应用程序实现不同的逻辑。 通过其中一个应用程序的重试器重新处理消息将导致在另一个应用程序上产生重复消息。 为了防止这种情况,我们创建一个单独的主题进行重新处理。 传入的主题和重试的主题可以由同一个 Consumer 读取,没有任何限制。
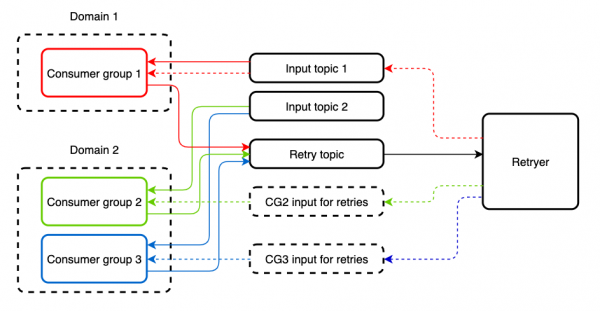
默认情况下,此方法不提供断路器功能,但是可以使用以下命令将其添加到应用程序中: 或新的 ,将调用外部服务的地方包装到适当的抽象中。 此外,还可以选择策略 模式,这也很有用。 例如,在 spring-cloud-netflix 中,这可能是线程池或信号量。
结论
因此,我们有一个单独的应用程序,允许我们在任何外部系统暂时不可用时重复消息处理。
该应用程序的主要优点之一是它可以被运行在同一 Kafka 集群上的外部系统使用,而无需对其进行重大修改! 这样的应用程序只需要访问重试主题,填写一些 Kafka 标头并向重试器发送消息。 无需增加任何额外的基础设施。 为了减少从应用程序到 Retryer 并返回的消息数量,我们识别了具有线性逻辑的应用程序,并通过 Consumer stop 重新处理它们。
来源: habr.com
