

大家好。 以下是文字记录 .
– 各种系统和服务的监控系统,系统管理员可以借助该系统收集有关系统当前参数的信息,并设置警报以接收有关系统运行偏差的通知。
该报告将包括比较 и — 长期存储 Prometheus 指标的项目。



首先,我向您介绍一下普罗米修斯。 这是一个监控系统,从指定目标收集指标并将其保存到本地存储。 Prometheus 可以将指标记录到远程存储,并可以生成警报和记录规则。

普罗米修斯的限制:
- 它没有全局查询视图。 这是当你有多个独立的 prometheus 实例时。 他们收集指标。 您想要查询从不同 Prometheus 实例收集的所有这些指标。 普罗米修斯不允许这样做。
- 对于普罗米修斯,性能仅限于一台服务器。 Prometheus 不会自动跨多个服务器进行扩展。 您只能在多个 Prometheus 之间手动拆分目标。
- Prometheus 中的指标范围仅限于一台服务器,其原因与它无法自动扩展到多台服务器相同。
- 在 Prometheus 中组织数据安全并不是那么容易。

这些问题/挑战的解决方案?
解决方案是:
所有这些解决方案都是为了远程存储Prometheus收集的数据。 他们以不同的方式解决了上一张幻灯片中的远程存储问题。 在本次演示中,我将仅讨论前两个解决方案: и .
第一次了解有关 出现于 。 那里描述了该架构 以及它是如何运作的。

Thanos 将 Prometheus 保存到本地磁盘的数据复制到 S3,以 或另一个对象存储。

因此,Thanos 提供了一个全局查询视图。 您可以从多个 Prometheus 实例查询存储在对象存储中的数据。

Thanos 支持 PromQL 和 .

Thanos 使用 Prometheus 代码来存储数据。

Thanos 与 Prometheus 是由同一开发者开发的。
Про 。 这里 ,我们首先讨论的地方 .
VictoriaMetrics接收来自多个prometheus的数据 普罗米修斯支持的协议。
VictoriaMetrics 提供了一种全局查询视图,因为多个 Prometheus 实例可以将数据写入一个 VictoriaMetrics。 因此,您可以对所有这些数据进行查询。

VictoriaMetrics 还支持 Thanos、PromQL 和 Prometheus 等查询 API。

与 Thanos 不同,VictoriaMetrics 源代码是从头开始编写的,并针对速度和资源消耗进行了优化。

VictoriaMetrics 与 Thanos 不同,它可以垂直和水平缩放。 吃 ,垂直缩放。 您可以从一个处理器和 1 GB 内存开始,逐渐增长到数百个处理器和 1 TB 内存。 VictoriaMetrics 可以使用所有这些资源。 与100核系统相比,其性能将提升约1倍。

Thanos 的历史始于 2017 年 XNUMX 月,当时出现了第一个公开提交。 在此之前,Thanos是内部开发的 .

2019 年 0.5.0 月发布了具有里程碑意义的版本 XNUMX,其中 协议。 他因为表现不佳而被灭霸除名。 Thanos 集群经常无法正常工作,由于八卦协议,节点无法正确连接到它。 因此,我们决定将他从那里删除。 我认为这是正确的决定。

同年 2019 年 XNUMX 月,他们发送了申请号 в .

几个月后,灭霸被录取了 ,其中包括 Prometheus、Kubernetes 等热门项目。

2018年XNUMX月,VictoriaMetrics的开发开始。

2018年XNUMX月,我第一次公开提到VictoriaMetrics。

2018年XNUMX月,发布了单节点版本。

5月份2019 单节点和集群版本的来源。

2019 年 XNUMX 月,就像 Thanos 一样,我们向 CNCF 基金会提交了申请,编号为 。 我们在灭霸申请前一天申请了。

但不幸的是,我们仍然没有被那里接受。 需要社区帮助。

让我们看一下展示 Thanos 和 VictoriaMetrics 架构的最重要的幻灯片。
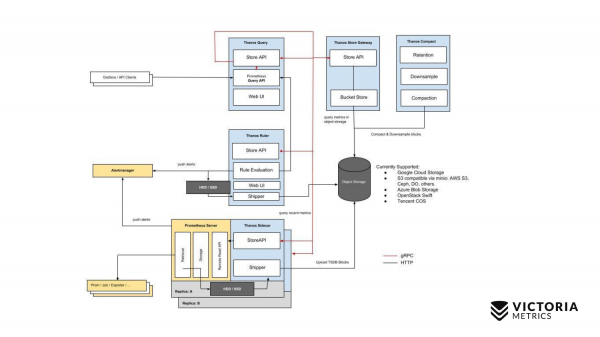
让我们从灭霸开始吧。 黄色组件是 Prometheus 组件。 其他一切都是 Thanos 组件。 让我们从最重要的组件开始。 Thanos Sidecar 是安装在每个 Prometheus 旁边的组件。 它将 Prometheus 数据从本地存储加载到 S3 或其他对象存储中。
还有一个名为 Thanos Store Gateway 的组件,它可以根据来自 Thanos Query 的传入请求从对象存储中读取此数据。 Thanos Query 实现了 PromQL 和 Prometheus API。 也就是说,从外面看它就像普罗米修斯。 接收 PromQL 查询,将其发送到 Thanos Store Gateway,Thanos Store Gateway 从对象存储检索必要的数据,然后将其发回。
但是,由于 Thanos Sidecar 实现的一个功能,我们将没有过去两小时的数据存储在对象存储中,它无法将过去两小时上传到对象存储 S3,因为 Prometheus 尚未在本地存储中创建这两小时的文件。
您决定如何解决这个问题? Thanos Query 除了向 Thanos Store Gateway 发出请求外,还向位于 Prometheus 旁边的每个 Thanos Sidecar 发送并行请求。
而 Thanos Sidecar 则将进一步的请求代理给 Prometheus,并检索过去两个小时的数据。
除了这些组件之外,还有一个可选组件,没有它,Thanos 将无法正常运行。 这是 Thanos Compact,它负责将对象存储上的小文件合并为由 Thanos Sidecars 上传到此处的较大文件。 Thanos Sidecar 在两个小时内将数据文件上传到那里。 这些文件如果不合并成更大的文件,那么它们的数量可能会显着增长。 此类文件越多,Thanos Store Gateway 需要的内存就越多,通过网络传输数据和元数据所需的资源也就越多。 Thanos Store Gateway 失效。 因此,有必要运行 Thanos Compact,它将小文件合并为大文件,从而减少此类文件并减少 Thanos Store Gateway 的开销。
还有灭霸统治者这样的组件。 它执行 Prometheus 警报规则,并可以评估 Prometheus 记录规则,以便将数据写回对象存储。 但不建议使用这个组件,因为... 他 .
这就是灭霸的简单方案。
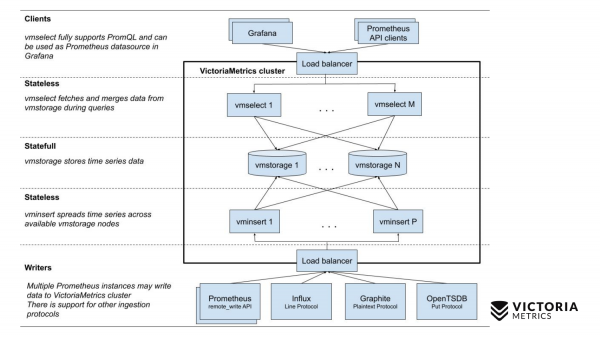
现在让我们将其与 VictoriaMetrics 方案进行比较。
VictoriaMetrics有2个版本:单节点和集群版本。 单节点在一台计算机上运行。 单节点没有这些组件,只有一个二进制文件。 幻灯片上的这个二进制看起来像这个正方形。 方块内的所有内容都是单节点版本的二进制文件的内容。 你不需要了解他。 您只需运行二进制文件,一切就对我们有用了。
集群版本更复杂。 其内部包含三个不同的组件:vmselect、vminsert 和 vmstorage。 从他们的名字就应该清楚他们每个人是做什么的。 Insert 组件接受不同格式的数据:来自 Prometheus 远程写入 API、Influx 线路协议、Graphite 协议和 OpenTSDB 协议。 插入组件接受它们,解析它们并将它们分发到已存储数据的现有存储组件之间。 Select 组件反过来接受 PromQL 查询。 他实现 以及 Prometheus 查询 API,它可以用作 Grafana 或其他 Prometheus API 客户端中 Prometheus 的替代品。 Select 接受 promql 请求,解析它,从存储节点读取执行该请求所需的数据,处理该数据并返回响应。

让我们比较一下安装 Thanos 和 VictoriaMetrics 的复杂性。

让我们从灭霸开始吧。 在开始使用 Thanos 之前,您需要在对象存储(例如 S3 或 GCS)中创建一个存储桶,以便 Thanos Sidecar 可以向其中写入数据。

然后,对于每个 Prometheus,您需要安装 Thanos Sidecar。 在此之前,您需要记住在 Prometheus 中禁用数据压缩。 数据压缩会定期压缩 Prometheus 本地存储中的数据,以减少资源消耗。
当您在 Prometheus 上安装 Thanos Sidecar 时,必须禁用此数据压缩,因为启用数据压缩后 Thanos Sidecar 无法正常工作。 这意味着您的 Prometheus 开始将数据保存在两小时的块中,并停止将这些块合并为更大的块。 因此,如果您进行的查询超过了过去两个小时的持续时间,那么它们将无法像启用数据压缩时那样有效地工作。

因此,Thanos建议将数据在本地存储的保留时间减少到6-8小时,以减少大量小块的开销。
安装 Thanos Sidecar 后,必须为每个对象存储桶安装两个组件。 它们是 Thanos Compactor 和 Thanos Store Gateway。

之后,您需要安装 Thanos Query 并配置它,以便它可以连接到您拥有的所有 Thanos Store Gateway,并且还可以连接到所有 Thanos Sidecar。
这里可能有一个小问题。

您需要配置从 Thanos Query 到这些组件的可靠且安全的连接。 如果您的 Prometheus 位于不同的数据中心或不同的 VPC 中,则禁止从外部连接到它们。 但为了让 Thanos Query 工作,你需要以某种方式配置那里的连接,并且你必须找到一种方法。
如果你有很多这样的数据中心,那么相应地,整个系统的可靠性就会降低。 由于 Thanos Query 必须不断维护与位于不同数据中心的所有 Thanos Sidecar 的连接。 对于每个传入请求,它都会将请求路由到所有 Thanos Sidecar。 如果连接中断,您将收到不完整的数据集,或者收到“集群已关闭”响应。

在 VictoriaMetrics 中,一切都变得更加简单。 对于单节点版本,您只需要运行一个二进制文件即可一切正常。

在集群版本中,运行以上三类组件任意数量就足够了,或者使用 自动启动 Kubernetes 中的组件。 我们还计划做一个 Kubernetes Operator。 Helm 图表不涵盖某些情况,会让您搬起石头砸自己的脚。 例如,它允许你减少存储节点的数量,这会导致数据丢失。

启动一个二进制版本或集群版本后,只需将 Prometheus 添加到配置中 以便它开始并行地将数据写入本地存储和远程存储。 正如您所看到的,与 Thanos 配置相比,此配置的性能应该可靠得多。 我们不需要维护VictoriaMetrics到所有Prometheus的连接,因为Prometheus本身连接到VictoriaMetrics并传输数据。

让我们考虑一下 Thanos 和 VictoriaMetrics 的支持。

Thanos 需要监控 Sidecar 以确保它们不会停止将数据加载到对象存储中。 他们可能会因下载错误而停止此数据下载,例如您与对象存储的网络连接暂时中断,或者对象存储暂时不可用。 Thanos Sidecar 此时会注意到这一点,报告错误,可能会崩溃然后停止工作。 如果您不监视它,那么您将停止将数据传输到对象存储。 如果保留时间过去(建议 6-8 小时),那么您将丢失未最终存入对象存储的数据。

Thanos 压实机可能会因以下原因停止工作 。 压缩器从对象存储中获取数据并将其合并为更大的数据块。 由于 Compactor 与 Sidecar 不同步,因此可能会发生以下情况:Sidecar 尚未来得及完成该块,Compactor 判定该块已完全写入。 压缩机开始读取它。 它不会完整读取该块并停止工作。 查看具体信息 .

由于 Compactor 和 Sidecar 之间的竞争,Store Gateway 可能会返回不一致的数据。 这里也发生同样的事情,因为 Store Gateway 不以任何方式与 Compactors 和 Sidecar 同步。 因此,当应用商店网关看不到部分数据或看到不必要的数据时,可能会出现竞争条件。

如果某些 Sidecar 或 Store Gateway 目前不可用,Thanos 中的查询组件默认返回部分结果。 您将收到部分数据,您甚至不知道您没有收到全部数据。 这是默认情况下的工作方式。 在类似的情况下,VictoriaMetrics 将标记数据返回为部分数据。

与 Thanos 不同,VictoriaMetrics 很少丢失数据。 即使 Prometheus 到 VictoriaMetrics 的连接中断,这也不是问题,因为 Prometheus 会继续在 Write Ahead Log 中记录传入的新数据,该日志的大小为 2 小时。 如果您在两小时内恢复与 VictoriaMetrics 的连接,您的数据将不会丢失。 普罗米修斯 .

与 Thanos 在两小时后才将数据写入对象存储不同,Prometheus 会使用远程写入协议自动将数据复制到远程存储,例如 VictoriaMetrics。 您不必担心丢失 Prometheus 中的本地存储。 如果他突然丢失了本地存储,那么最坏的情况就是你会丢失最后几秒没有来得及记录在远程存储中的数据。

与 Thanos 不同,Kubernetes 自动管理集群。 与 VictoriaMetrics 集群组件不同,将所有 Thanos 组件放入一个 Kubernetes 集群是很困难的。

VictoriaMetrics 对新版本进行了非常简单的更新。 只需停止 VictoriaMetrics,更新二进制文件并启动它即可。 当通过 SIGINT 信号停止时,所有 VictoriaMetrics 二进制文件都会执行正常关闭。 它们正确保存必要的数据,正确关闭传入连接,以免丢失任何内容。 所以升级时你不会丢失任何东西。

VictoriaMetrics 使扩展集群变得非常容易。 只需添加必要的组件并继续工作即可。

关于 Thanos 和 VictoriaMetrics 的陷阱。

灭霸有以下陷阱。 Prometheus 必须存储最近两个小时的数据。 如果它们丢失,您将完全丢失它们,因为它们尚未像 S3 那样写入对象存储。

如果存储有许多小文件,则存储网关组件和压缩器组件可能需要大量内存才能与大型对象存储配合使用。 文件的数量和大小越大,存储元信息所需的 Store Gateway 和压缩器 RAM 就越多。 灭霸有很多问题,因为 .

据称,Thanos 可以根据您拥有的 Prometheus 数量无限扩展。 这实际上是不正确的。 由于所有请求都经过查询组件,该组件必须同时轮询所有 Store Gateway 组件和所有 Sidecar 组件,从那里提取数据,然后对其进行预处理。 显然,请求速度受到最慢的薄弱环节、最慢的 Store Gateway 或最慢的 Sidecar 的限制。
这些组件的负载可能不均匀。 例如,您有 Prometheus,它每秒收集数百万个指标。 还有 Prometheus,它每秒收集数千个指标。 Prometheus 每秒收集数百万个指标,这给它运行的服务器带来了更高的负载。 因此,Sidecar 在那里运行速度较慢。 一般来说,一切都进展缓慢。 查询组件将从那里提取数据的速度非常慢。 因此,整个集群的性能将受到这个缓慢的 Sidecar 的限制。

默认情况下,如果某些 Sidecar 和 Store Gateway 不可用,Thanos 会提供部分数据。 例如,如果您的 Sidecar 分散在世界各地的不同数据中心,那么连接失败和组件不可用的可能性就会大大增加。 因此,在大多数情况下,您会在不知情的情况下收到部分数据。
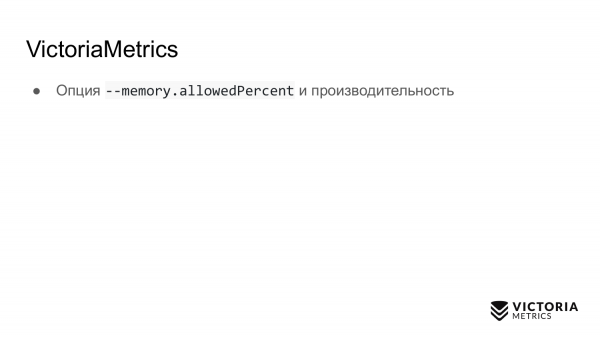
VictoriaMetrics也有陷阱。 第一个陷阱是限制用于 VictoriaMetrics 缓存的 RAM 量的选项。 默认情况下,它等于运行 VictoriaMetrics 的机器上 RAM 的 60% 或 Kubernetes 中 VictoriaMetrics pod 的 RAM 的 60%。
如果错误地更改此值,可能会破坏 VictoriaMetrics 的性能。 例如,如果您将该值设置得太低,数据可能不再适合 VictoriaMetrics 缓存。 因此,她将不得不做额外的工作并加载处理器和磁盘。 如果您将此选项设置得太大,首先,它会增加 VictoriaMetrics 因内存不足错误而崩溃的可能性,其次,它会导致操作系统内存中剩余的 RAM 非常少。文件缓存。 VictoriaMetrics 依靠文件缓存来提高性能。 如果不够,磁盘上的负载会大大增加。 因此,建议:除非绝对必要,否则不要更改该参数。
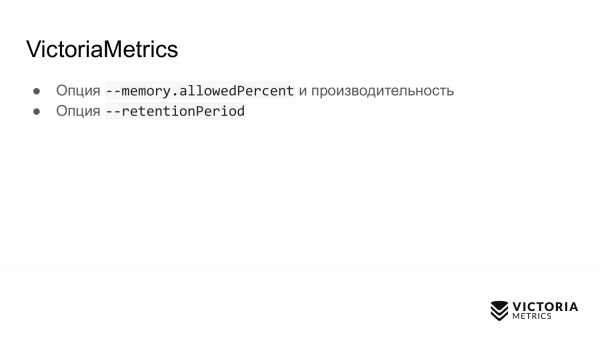
第二个选择。 这是保留期 - 默认设置为 1 个月的期限。 这是VictoriaMetrics 存储数据的时间长度。 在此期限之后,VictoriaMetrics 会删除数据。
许多人在没有此参数的情况下运行VictoriaMetrics并记录一个月的数据。 然后他们问:为什么上个月的数据消失了? 因为默认的retentionPeriod是1个月。 因此,您需要了解并设置正确的retentionPeriod。

让我们来看看独特的功能。

Thanos 有一个称为下采样的功能:5 分钟和每小时的间隔,这通常 。 如果你用谷歌搜索并在 github 上查看他们的问题,就会发现有很多与此下采样相关的问题,它有时无法正常工作,或者无法按照用户的预期工作。

Thanos 为 Prometheus HA 对提供重复数据删除功能。 当两个 Prometheus 从相同的目标收集相同的指标并且 Thanos 将它们存储在对象存储中时。 与 VictoriaMetrics 不同,Thanos 可以正确删除这些数据的重复数据。

Thanos 在 Thanos 原理图中有一个警报组件。 但他 .

Thanos 的优点是 Thanos 和 Prometheus 共享相同的代码。 Thanos 和 Prometheus 是由同一开发商开发的。 通过灭霸或普罗米修斯的改进,对方获胜。

VictoriaMetrics 的主要功能是 MetricsQL。 这些是 PromQL 的 VictoriaMetrics 扩展,我在之前的大型监控聚会中谈到过。

VictoriaMetrics 支持使用许多不同协议加载数据。 VictoriaMetrics不仅可以接受来自Prometheus的数据,还可以通过Influx、OpenTSDB和Graphite协议接受数据。

与 Thanos 和 Prometheus 相比,VictoriaMetrics 数据占用的空间要少得多。
如果记录真实数据,用户表示与 Prometheus 和 Thanos 相比,磁盘上的数据大小减少了 2-5 倍。

VictoriaMetrics 的另一个优点是它针对速度进行了优化。

我们来看看基础设施的成本。

Thanos 的优点之一是它将数据存储在对象存储中,相对便宜。
在对象存储中存储数据时,您必须为数据写入和读取操作付费(每百万次操作 10 美元)。 当您将数据写入对象存储时,您需要支付将数据上传到互联网的托管费用;如果您的集群不在AWS中,那么它是免费的。 读取数据时,每 10TB 需要支付 230 至 1 美元的费用。 如果您经常从 Thanos 集群查询历史数据,这可能会很重要。

对于 Thanos 集群,您需要为需要大量内存的 Compact、Store Gateway、查询组件以及用于处理大量数据的 CPU 的服务器付费。

VictoriaMetrics 有以下费用。 如果您将数据存储在 GCE HDD 驱动器上,则 40TB 的价格为 1 美元。 对于VictoriaMetrics来说,普通HDD驱动器就足够了;不需要价格五倍的SSD。 VictoriaMetrics 针对 HDD 进行了优化。

VictoriaMetrics 需要组件服务器:无论是单节点组件还是集群组件,与 Thanos 组件不同,它们需要的 CPU 和 RAM 少得多,因此也更便宜。

实施示例。

Thanos 在 Gitlab 中有一个实现示例。 Gitlab 完全运行在 Thanos 上。 但那里并不是一切都那么顺利。 如果你看着他们 ,那么你可以看到他们不断地有一些 :没有足够的内存用于存储网关或查询组件。 他们必须不断增加内存量。
因此,解决这些问题的成本就会增加。
第二个实施方案可能更成功,是 Improbable 公司,该公司开始开发 Thanos。 他们发布了灭霸源代码。 Improbable是一家开发游戏引擎的公司。

VictoriaMetrics 有公开的实施示例:
- wix.com 网站建设者
- 阿迪达斯正在实施 VictoriaMetrics,甚至在上届 PromCon 2019 上进行了演示
- TrafficStars - 广告网络
- Seznam.cz 是流行的捷克搜索引擎。
然后还有一些我现在无法说出名字的无名公司。 他们不同意。
- 一位主要的游戏开发商。 比我大是不可能的。
- 主要图形软件开发商。
- 俄罗斯大型银行。
- 已成功测试 VictoriaMetrics 的欧洲风力涡轮机制造商。 该制造商正在实施 VictoriaMetrics,以每个传感器每秒 50 个样本的速率监控从风力涡轮机收集的数据。 每个风力涡轮机都有数百个传感器。 他们有数百台风力涡轮机。
- 俄罗斯航空公司想要实施 VictoriaMetrics,但仍然无法实施。 我们正与他们签订合同。
 结论。
结论。
VictoriaMetrics 和 Thanos 解决了类似的问题,但方式不同:
- 全局查询视图
- 水平缩放
- 任意保留

谢谢。
我们在我们的店等你 .

只有注册用户才能参与调查。 拜托
您使用什么作为 Prometheus 的长期存储?
35,3%Thanos6
0,0%皮质0
0,0%M3DB0
41,2%维多利亚指标7
23,5%其他4
17 位用户投票。 16 名用户弃权。
来源: habr.com
