


只是第一次會痛!
大家好!親愛的朋友們,在這篇文章中我想分享一下我基於儲存庫使用TensorRT、RetinaNet的經驗 (這是官方蘿蔔的叉子 ,這將使您能夠盡快開始在生產中使用最佳化的模型)。滾動瀏覽社區頻道中的消息 ,我遇到了有關使用 TensorRT 的問題,而且這些問題大多是重複的,所以我決定寫 盡可能完整 使用基於 TensorRT、RetinaNet、Unet 和 docker 的快速推理的指南。
任務描述
我建議這樣描述這項任務:我們需要標註資料集,在 PyTorch 1.3+ 上訓練 RetinaNet/Unet 網絡,將得到的權重轉換為 ONNX 格式,然後將其轉換為 TensorRT 引擎格式,並在 Docker 中運行整個過程,最好是在… Ubuntu 18,並且非常適合 ARM (Jetson)* 架構,從而最大限度地減少環境的手動部署。最終成果將是一個容器,不僅可用於匯出和訓練 RetinaNet/Unet,還可用於開發和訓練功能齊全的分類和分割系統,並包含所有必要的硬體。
第一階段.準備環境
這裡要注意的是,最近我已經完全放棄了在桌上型電腦以及 devbox 上至少使用和部署一些函式庫。您唯一需要建立和安裝的是 deb 中的 python 虛擬環境和 cuda 10.2(您可以限制自己使用一個 nvidia 驅動程式)。
假設您剛剛安裝了一個新系統。 Ubuntu 18. 我們來安裝 CUDA 10.2(deb 套件)。安裝過程我就不贅述了,官方文件已經夠詳細。
現在我們來安裝docker,docker安裝指南可以很容易找到,這裡是一個例子 ,版本 19+ 已經可用 - 安裝它。好吧,別忘了讓 docker 不用 sudo 就可以使用,這樣會更方便。一切順利後,我們這樣做:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
你甚至不必查看官方儲存庫 .
現在讓我們進行 git 克隆 .
還剩下一點點,為了開始使用 docker 和 nvidia 映像,我們需要註冊 NGC Cloud 並登入。我們去這裡吧 ,註冊並進入NGC Cloud後,點擊螢幕左上角的SETUP或點擊此鏈接 。按一下“產生金鑰”。我建議保存它,否則下次訪問它時,您將不得不再次生成它,並相應地將其部署在新車上並重複此操作。
讓我們做:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
用戶名只需複製即可。好吧,考慮一下部署的環境!
第 2 階段:建置 docker 容器
在工作的第二階段,我們將建立 docker 並熟悉其內部結構。
讓我們轉到與 retina-examples 專案相關的根資料夾並執行
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
我們透過將目前使用者傳遞到其中來建置 docker - 如果您使用目前使用者的權限向已安裝的磁碟區寫入內容,這非常有用,否則它將是 root 和痛苦。
在建置 docker 時,讓我們檢查一下 Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
正如您從文本中看到的,我們使用了所有我們最喜歡的庫,編譯了 RetinaNet,並添加了一些基本工具以方便使用。 Ubuntu 並配置 OpenSSH 伺服器。第一行繼承了我們用於建立 NGC 雲端登入的 NVIDIA 映像,該映像包含 PyTorch 1.3、TensorRT 6.xxx 以及其他一些程式庫,這些程式庫允許我們編譯探測器的 C++ 原始程式碼。
第 3 階段:啟動和調試 Docker 容器
讓我們繼續使用容器和開發環境的主要案例;首先,讓我們啟動 nvidia docker。讓我們做:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest現在可以透過 ssh 存取容器@本機。啟動成功後,在PyCharm中開啟專案。接下來我們打開
Settings->Project Interpreter->Add->Ssh Interpreter 步驟1
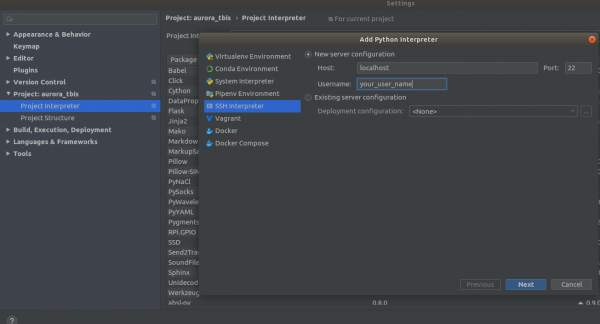
步驟2
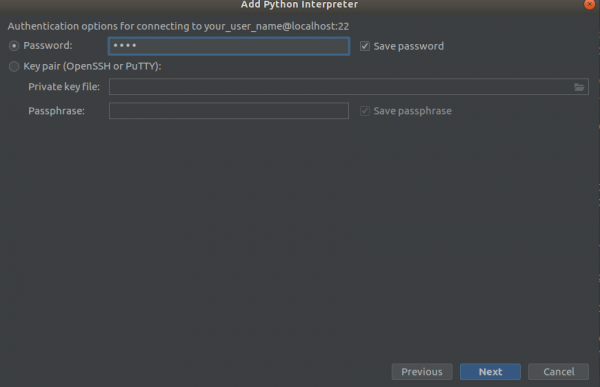
步驟3
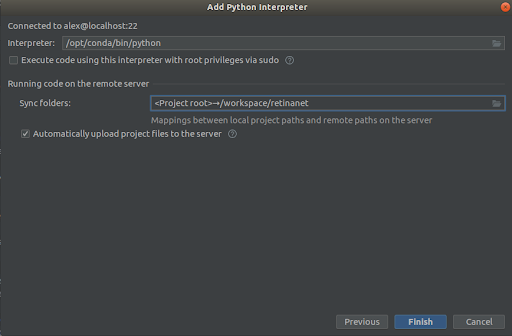
我們選擇螢幕截圖中的所有內容,
Interpreter -> /opt/conda/bin/python- 這將是Python3.6中的ln並且
Sync folder -> /workspace/retinanet我們按完成,等待索引,就這樣,環境就可以使用了!
重要的! 建立索引後,立即從 docker 中提取 Retinanet 的編譯檔。在項目根目錄的上下文選單中,選擇該項目
Deployment->Download將出現一個檔案和兩個資料夾:build、retinanet.egg-info 和 _С.so
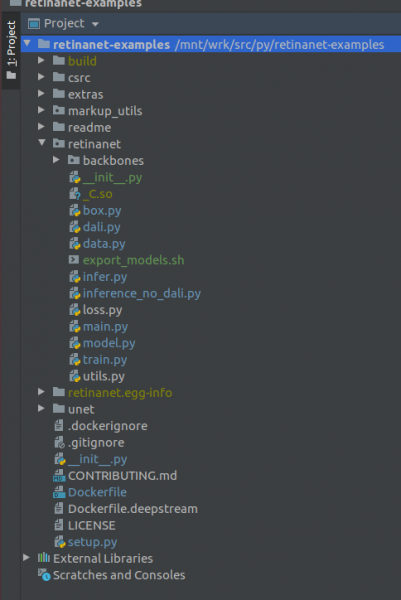
如果您的專案如下所示,那麼環境會看到所有必要的文件,我們就準備好訓練 RetinaNet 了。
第 4 階段:標記資料並訓練偵測器
對於標記我主要使用 - 一個令人愉快且方便的工具,最近修復了一些錯誤,而且它的行為明顯變得更好。
假設您已經標記了資料集並下載了它,但您無法立即將其放入我們的 RetinaNet 中,因為它採用自己的格式,為此我們需要將其轉換為 COCO。轉換工具位於:
markup_utils/supervisly_to_coco.py請注意,腳本中的類別是一個範例,您需要插入自己的類別(無需新增背景類別)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] 由於某種原因,原始儲存庫的作者決定不會訓練除 COCO/VOC 之外的任何內容進行檢測,因此他們必須對原始檔案進行一些編輯
retinanet/dataset.py透過在此處添加您最喜歡的增強功能 並從 COCO 中刪除硬連接的類別。也可以裁剪大的偵測區域,如果您正在大圖片中尋找小物體,您有一個小資料集 =),但沒有任何作用,但下次會更多。
一般來說,火車循環也很弱,最初它沒有保存檢查點,它使用了某種糟糕的調度程序等。但現在你要做的就是選擇主幹並執行
/opt/conda/bin/python retinanet/main.py帶參數:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
在控制台中您將看到:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148若要探索整套參數,請查看
retinanet/main.py一般來說,它們是檢測的標準,並且有描述。開始訓練並等待結果。推理的例子可見於:
retinanet/infer_example.py或運行命令:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
該存儲庫已經內建了 Focal Loss 和幾個主幹,並且也可以輕鬆嵌入您自己的
retinanet/backbones/*.py在表中,作者給了一些特徵:
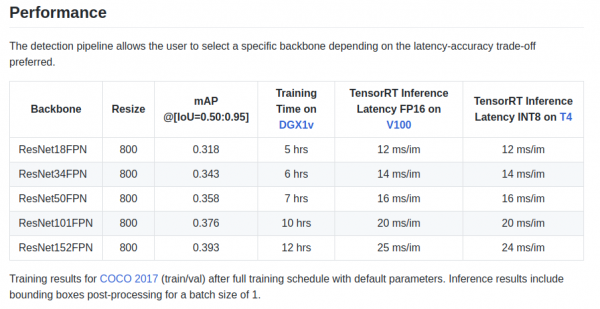
還有一個主幹 ResNeXt50_32x4dFPN 和 ResNeXt101_32x8dFPN,取自 torchvision。
我希望您已經對檢測有了一些了解,但是您一定應該閱讀官方文檔,以便 了解匯出和記錄模式.
階段 5. 使用 Resnet 編碼器匯出並推理 Unet 模型
正如您可能注意到的,用於分段的庫安裝在 Dockerfile 中,特別是精彩的庫 。在unitet套件中,您可以找到推理範例以及將pytorch檢查點匯出到TensorRT引擎的範例。
將類似 Unet 的模型從 ONNX 匯出到 TensoRT 時的主要問題是需要設定固定的 Upsample 大小或使用 ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
使用此轉換,您可以在匯出至 ONNX 時自動執行此操作,但在 TensorRT 版本 7 中,此問題已解決,我們必須等待一段時間。
結論
當我開始使用 docker 時,我對其任務的表現產生了懷疑。我的一台設備目前有相當多的網路流量,由多個攝影機產生。
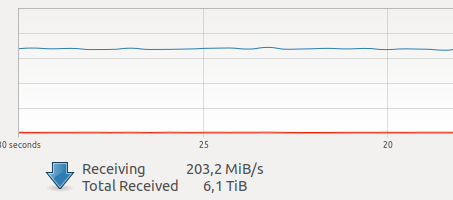
網路上的各種測試都說網路互動和VOLUME錄製的開銷比較大,加上未知的可怕的GIL,而且由於捕獲幀,操作驅動程式並透過網路傳輸幀是該模式下的原子操作 硬實時,網路延遲對我來說非常關鍵。
但一切都還好 =)
PS 剩下的就是添加您最喜歡的火車循環以進行分割和製作!
謝謝
感謝社區 ,沒有它就不可能發展!多謝 ,他鼓勵我進行深度學習,因為他提供了寶貴的建議和極端的專業!
在生產中使用最佳化的模型!
 奧羅萊有限公司
奧羅萊有限公司
來源: www.habr.com
