

大家好。以下是文字記錄 .
– 用於監控各種系統和服務的系統,借助該系統,系統管理員可以收集有關當前系統參數的信息,並設定警報以接收有關係統運行偏差的通知。
該報告將包含比較 и — Prometheus 指標的長期儲存項目。



首先,我來向大家介紹普羅米修斯。它是一個監控系統,從指定目標收集指標並將其保存到本地儲存。 Prometheus 可以將指標記錄到遠端存儲,並可以產生警報和記錄規則。

Prometheus 的局限性:
- 它沒有全域查詢視圖。這是當您有多個獨立的 Prometheus 實例時。他們收集指標。您想要查詢從不同的 Prometheus 實例收集的所有這些指標。普羅米修斯不允許這麼做。
- Prometheus 的效能受限於僅一台伺服器。 Prometheus 無法自動跨多台伺服器擴充。您只能手動將目標分割到多個 Prometheuse 之間。
- Prometheus 中的指標量僅限於一台伺服器,原因與其無法自動跨多台伺服器擴充的原因相同。
- Prometheus 並不是一個容易組織資料安全的地方。

這些問題/任務的解決方案?
解決方案如下:
所有這些解決方案都是為了遠端儲存 Prometheus 收集的資料。他們以不同的方式解決了上一張投影片中的遠端儲存問題。在本次演講中,我將只討論前兩種解決方案: и .
首次提供有關 出現在 。該建築結構已在那裡描述。 以及它是如何工作的。

Thanos 將 Prometheus 儲存在本機磁碟上的資料複製到 S3, 或儲存至另一個物件儲存。

因此Thanos提供了一個全域查詢視圖。您可以從多個 Prometheus 實例查詢儲存在物件儲存中的資料。

Thanos 支援 PromQL 和 .

Thanos 使用 Prometheus 程式碼來儲存資料。

Thanos 與 Prometheus 是由同一個開發人員開發的。
Про 。 這裡 ,我們第一次談到 .
VictoriaMetrics 從多個 Prometheus 接收數據 Prometheus 支援的協定。
VictoriaMetrics 提供全域查詢視圖,因為多個 Prometheus 實例可以將資料寫入單一 VictoriaMetrics。因此,您可以對所有這些資料進行查詢。

VictoriaMetrics 也支援像 Thanos、PromQL 和 Prometheus 這樣的查詢 API。

與 Thanos 不同,VictoriaMetrics 的原始程式碼是從頭開始編寫的,並針對速度和資源消耗進行了最佳化。

VictoriaMetrics 與 Thanos 不同,它可以垂直和水平擴展。吃 ,垂直縮放。您可以從一個處理器和 1GB 記憶體開始,逐漸成長到數百個處理器和 1TB 記憶體。 VictoriaMetrics 可以使用所有這些資源。與單核心系統相比,其性能將提高約100倍。

Thanos 的歷史始於 2017 年 XNUMX 月,當時發布了第一個公開提交。到目前為止,Thanos 都是內部開發的 .

2019 年 0.5.0 月,具有里程碑意義的 XNUMX 版本發布, 協定.他因為沒有展現出自己最好的一面而被薩諾斯除名。 Thanos 叢集經常無法正常運作,由於八卦協議,節點無法正確連接到它。這就是他們決定將其從那裡移除的原因。我認為這是正確的決定。

同年 2019 月,他們發送了申請號 в .

幾個月後,薩諾斯被接納進入 ,其中包括 Prometheus、Kubernetes 和其他流行項目。

VictoriaMetrics 的開發始於 2018 年 XNUMX 月。

2018 年 XNUMX 月,我第一次公開提到 VictoriaMetrics。

單節點版本於2018年XNUMX月發布。

5月份2019 單節點和叢集版本的來源。

2019 年 XNUMX 月,我們和 Thanos 一樣,向 CNCF 基金會提交了申請,申請編號為 。我們在薩諾斯申請前一天就申請了。

但不幸的是,我們仍然沒有被那裡錄取。需要社區的幫助。

讓我們來看看展示 Thanos 和 VictoriaMetrics 架構的最重要的幻燈片。
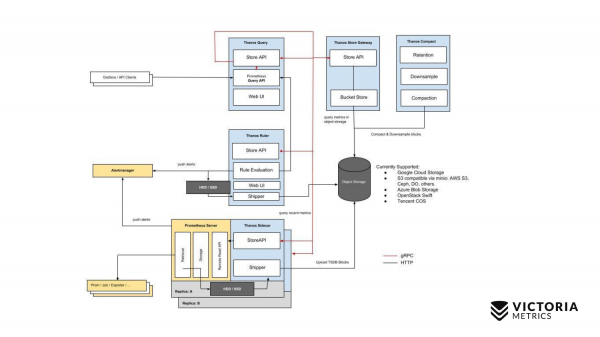
讓我們從薩諾斯開始。黃色組件是 Prometheus 組件。其餘一切都是 Thanos 元件。讓我們從最重要的組件開始。 Thanos Sidecar 是與每個 Prometheus 一起安裝的元件。它的作用是將 Prometheus 資料從本機儲存上傳到 S3 或其他物件儲存。
還有一個名為 Thanos Store Gateway 的元件,它可以在收到來自 Thanos Query 的請求時從物件儲存中讀取這些資料。 Thanos Query 實作了 PromQL 和 Prometheus API。也就是說,從外觀上看它就像普羅米修斯。接受 PromQL 查詢,將其發送到 Thanos Store Gateway,Thanos Store Gateway 從物件儲存中獲取所需的數據,並將其發送回來。
但由於 Thanos Sidecar 的實現特性,我們在物件儲存中儲存的數據沒有最近兩個小時的數據,無法將最近兩個小時的數據上傳到物件儲存 S3,因為 Prometheus 還沒有在本地儲存中創建這兩個小時的檔案。
他們是如何解決這個問題的? Thanos Query 除了向 Thanos Store Gateway 發送查詢之外,還會向位於 Prometheus 旁的每個 Thanos Sidecar 發送並行查詢。
而 Thanos Sidecar 則將請求進一步代理到 Prometheus,並檢索過去兩小時的資料。
除了這些組件之外,還有一個可選組件,如果沒有它,薩諾斯就會感覺不舒服。這是 Thanos Compact,它負責將物件儲存上的小檔案合併為由 Thanos Sidecars 上傳到那裡的大檔案。 Thanos Sidecar 在兩小時內將資料檔上傳到那裡。如果不將這些文件合併為更大的文件,其數量可能會顯著增加。這樣的檔案越多,Thanos Store Gateway 所需的記憶體就越大,透過網路傳輸資料和元資料所需的資源就越多。 Thanos Store Gateway 作業變得無效。因此,需要執行 Thanos Compact,將小文件合併為大文件,以減少此類文件的數量並減少 Thanos Store Gateway 的開銷。
還有 Thanos Ruler 這樣的元件。它執行 Prometheus 警報規則,並可以評估 Prometheus 記錄規則以將資料寫回物件儲存。但不建議使用這個組件,因為他 .
這是薩諾斯的一個簡單方案。
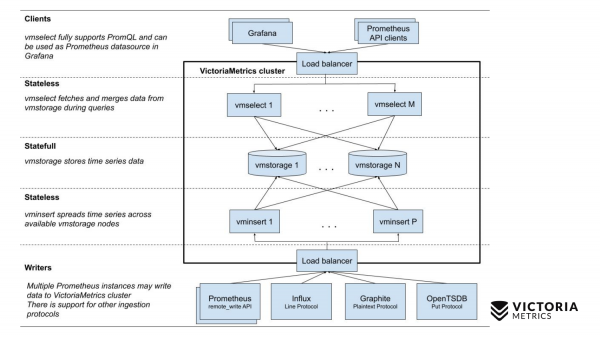
現在讓我們將它與 VictoriaMetrics 方案進行比較。
VictoriaMetrics 有兩個版本:單節點版本和叢集版本。單節點在一台電腦上運作。單節點沒有這些元件,只有一個二進位。這個二進位檔案在幻燈片上看起來就像這個正方形。方塊內的所有內容都是單節點版本的二進位檔案的內容。你不需要知道這件事。只需運行二進位文件,一切就可以正常工作。
叢集版本更加複雜。其中有三個不同的元件:vmselect、vminsert 和 vmstorage。從它們的名字就可以看出它們各自的角色。插入組件接受不同格式的資料:來自 Prometheus 遠端寫入 API、Influx 線路協定、Graphite 協定以及來自 OpenTSDB 協定。插入元件接受它們、解析它們並將它們分發到已經儲存資料的現有儲存元件中。反過來,Select 元件接受 PromQL 查詢。他實施 以及 Prometheus 查詢 API,它可以作為 Grafana 或其他 Prometheus API 用戶端中 Prometheus 的替代品。 Select 接受一個 promql 查詢,解析它,從儲存節點讀取執行此查詢所需的數據,處理該數據並傳回回應。

讓我們來比較一下安裝 Thanos 和 VictoriaMetrics 的複雜度。

讓我們從薩諾斯開始。在開始使用 Thanos 之前,您需要在物件儲存(例如 S3 或 GCS)中建立儲存桶,以便 Thanos Sidecar 可以向其中寫入資料。

然後,您需要為每個 Prometheus 安裝 Thanos Sidecar。在執行此操作之前,您必須記住停用 Prometheus 中的資料壓縮。資料壓縮定期壓縮 Prometheus 本機儲存中的數據,以減少資源消耗。
當你將 Thanos Sidecar 安裝到你的 Prometheus 時,你必須停用此資料壓縮,因為啟用資料壓縮後 Thanos Sidecar 無法正常運作。這意味著您的 Prometheus 開始以兩小時的區塊儲存數據,並停止將這些區塊合併為更大的區塊。因此,如果您進行的查詢超過了過去兩個小時的持續時間,那麼它們的執行效率將不如啟用資料壓縮時那麼高。

因此,Thanos 建議將資料在本地儲存中的保留時間縮短至 6-8 小時,以減少大量小塊的開銷。
安裝 Thanos Sidecar 後,必須為每個物件儲存桶安裝兩個組件。這些是 Thanos Compactor 和 Thanos Store Gateway。

之後,您需要安裝 Thanos Query 並對其進行配置,以便它可以連接到您擁有的所有 Thanos Store Gateway,並且還能夠連接到所有 Thanos Sidecar。
這裡可能存在一個小問題。

您需要從 Thanos Query 到這些元件建立安全可靠的連線。如果您的 Prometheuses 位於不同的資料中心或不同的 VPC 中,則禁止從外部連接它們。但是要使 Thanos Query 正常工作,您需要以某種方式在那裡建立連接,並且您必須想出一種方法。
如果您有許多這樣的資料中心,那麼整個系統的可靠性就會降低。因為 Thanos Query 必須不斷維持與位於不同資料中心的所有 Thanos Sidecar 的連線。對於每個傳入的請求,它都會將請求轉發給所有 Thanos Sidecar。如果連線中斷,您要么會收到一組不完整的數據,要么會收到「叢集已關閉」的回應。

在 VictoriaMetrics,事情變得簡單一些。對於單節點版本,只需運行一個二進位檔案即可,一切正常。

在叢集版本中,可以運行上述三種類型的元件,數量不限,或使用 自動啟動 Kubernetes 中的元件。我們也計劃製作一個 Kubernetes 操作員。 Helm chart 沒有涵蓋某些情況,讓你搬起石頭砸自己的腳。例如,它允許你減少儲存節點的數量,這將導致資料遺失。

一旦您啟動並運行單一二進位或叢集版本,您只需將 Prometheus 新增到您的配置中。 這樣它就可以開始將資料並行寫入本地儲存和遠端儲存。如您所見,與 Thanos 配置相比,此配置應該更加可靠。我們不需要維護從 VictoriaMetrics 到所有 Prometheuses 的連接,因為 Prometheuses 本身會連接到 VictoriaMetrics 並傳輸資料。

讓我們來看看Thanos和VictoriaMetrics的支援情況。

Thanos 需要監控 Sidecar,以確保它們不會停止將資料載入到物件儲存中。他們可能會因為下載錯誤而停止此資料下載,例如,您與物件儲存的網路連線暫時中斷,或者物件儲存暫時無法使用。 Thanos Sidecar 此時會注意到這一點,報告錯誤,並可能崩潰然後停止工作。如果您不監控它,您將停止將資料傳輸到物件儲存。如果保留時間(建議 6-8 小時)過去,您將遺失尚未放入物件儲存的資料。

Thanos 壓實機可能會因以下原因停止運作 。壓縮器從物件儲存中獲取資料並將其合併為更大的資料塊。由於壓縮器與 Sidecar 不同步,因此可能會發生以下情況:Sidecar 尚未成功寫入區塊,而壓縮器認為該區塊已完全寫入。壓縮器開始讀取它。它讀取不完整的區塊並停止工作。看詳情 .

由於 Compactor 和 Sidecar 之間的競爭,Store Gateway 可能會傳回不一致的資料。這裡也發生了同樣的事情,因為 Store Gateway 沒有與 Compactors 和 Sidecar 同步。因此,當 Store Gateway 看不到部分資料或看到不必要的資料時,可能會出現競爭條件。

如果某些 Sidecar 或 Store Gateway 暫時無法使用,Thanos 中的 Query 元件會預設回傳部分結果。您將收到部分數據,甚至不知道您沒有收到全部數據。這是它預設的工作方式。在類似情況下,VictoriaMetrics 將標記資料作為部分傳回。

與 Thanos 不同,VictoriaMetrics 很少遺失資料。即使 Prometheus 到 VictoriaMetrics 的連線中斷,也沒有問題,因為 Prometheus 會繼續將傳入的新資料寫入 Write Ahead Log,其大小為 2 小時。如果您在兩小時內恢復與 VictoriaMetrics 的連接,您的資料將不會遺失。普羅米修斯 .

與 Thanos 僅在兩小時後將資料寫入物件存儲不同,Prometheus 會透過遠端寫入協定自動將資料複製到遠端存儲,例如 VictoriaMetrics。您不必擔心丟失 Prometheus 中的本機儲存。如果他突然丟失了本地存儲,那麼在最壞的情況下,您將丟失沒有時間寫入遠端存儲的最後幾秒的數據。

與 Thanos 不同,Kubernetes 會自動管理叢集。與 VictoriaMetrics 叢集元件不同,很難將所有 Thanos 元件放置在一個 Kubernetes 叢集中。

VictoriaMetrics 的新版本更新非常簡單。只需停止 VictoriaMetrics,更新二進位並啟動。當透過 SIGINT 訊號停止時,所有 VictoriaMetrics 二進位檔案都會執行正常關閉。它們正確地保存必要的數據,正確關閉傳入連接,以免丟失任何東西。因此升級時您不會丟失任何東西。

VictoriaMetrics 讓擴展您的叢集變得非常容易。只需添加必要的組件並繼續工作。

關於 Thanos 和 VictoriaMetrics 中的陷阱。

薩諾斯有以下幾個陷阱。 Prometheus 應該儲存過去兩個小時的資料。如果它們丟失,您將完全失去它們,因為它們尚未寫入像 S3 這樣的物件儲存。

如果儲存了許多小文件,則儲存網關元件和壓縮器元件可能需要大量記憶體來處理大型物件儲存。檔案的數量和大小越大,儲存網關和壓縮器儲存元資訊所需的 RAM 就越多。薩諾斯對於 .

據稱,Thanos 可以無限擴展到您擁有的 Prometheus 的數量。事實上,事實並非如此。由於所有請求都要經過Query組件,而Query組件必須同時查詢所有Store Gateway組件和所有Sidecar組件,從那裡提取數據,然後進行預處理。很明顯,請求速率受到最慢的薄弱環節的限制,要么是最慢的 Store Gateway,要么是最慢的 Sidecar。
這些組件可能負載不均勻。例如,您有 Prometheus,它每秒收集數百萬個指標。還有 Prometheus,它每秒收集數千個指標。 Prometheus 每秒收集數百萬個指標,為其運行的伺服器帶來更大的負載。因此,Sidecar 在那裡的運行速度較慢。總體來說,那裡的一切都進展緩慢。並且查詢組件將非常緩慢地從那裡提取資料。因此,整個集群的性能將受到這個緩慢的 Sidecar 的限制。

預設情況下,如果某些 Sidecar 或 Store Gateway 不可用,Thanos 會提供部分資料。例如,如果您的 Sidecar 分散在世界各地的不同資料中心,則連線失敗和元件不可用的可能性會大大增加。因此,在大多數情況下,您會在不知情的情況下收到部分資料。
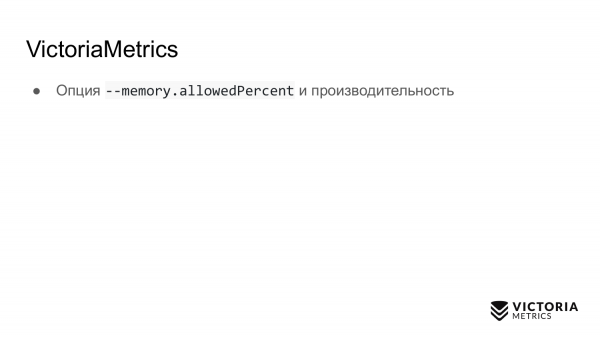
VictoriaMetrics 也有其缺陷。第一個陷阱是限制用於 VictoriaMetrics 快取的 RAM 數量的選項。預設情況下,它等於運行 VictoriaMetrics 的機器上 RAM 的 60%,或 Kubernetes 中 VictoriaMetrics pod RAM 的 60%。
如果您錯誤地變更此值,則可能會破壞 VictoriaMetrics 的效能。例如,如果您將值設定得太低,資料可能不再適合 VictoriaMetrics 快取。因此,它將不得不做額外的工作並加載處理器和磁碟。如果將此選項設定得太大,則首先會增加 VictoriaMetrics 因記憶體不足錯誤而崩潰的可能性,其次會導致作業系統為檔案快取剩餘的 RAM 非常少。 VictoriaMetrics 依靠檔案快取來提高效能。如果不夠的話,磁碟的負載可能會大幅增加。因此,建議是:除非絕對必要,否則不要更改參數。
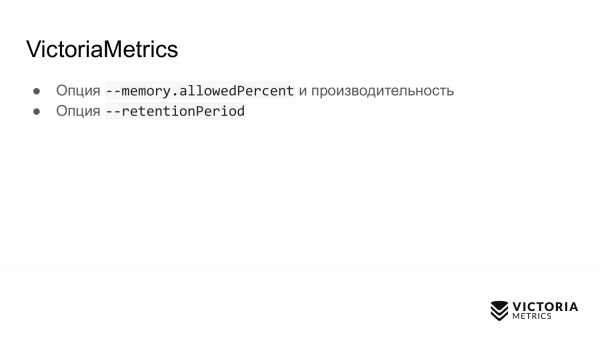
第二種選擇。這是保留期限,預設為 1 個月。這是 VictoriaMetrics 儲存資料的時間。在此期間之後,VictoriaMetrics 將刪除資料。
許多人在運行 VictoriaMetrics 時沒有使用此參數,並記錄一個月的數據。然後他們問:為什麼上個月的數據消失了?因為預設的retentionPeriod是1個月。因此,您需要了解並設定正確的retentionPeriod。

讓我們來看看這些獨特的功能。

Thanos 有一個稱為下採樣的功能:5 分鐘和每小時的間隔,通常 。如果你用谷歌搜尋並查看他們在 github 上的問題,你會發現有很多與這種下採樣相關的問題,它有時不能正常工作,或者不能按照用戶期望的方式工作。

Thanos 為 Prometheus HA 對提供了重複資料刪除功能。當兩個 Prometheus 從相同的目標收集相同的指標並且 Thanos 將它們放入物件儲存中。與 VictoriaMetrics 不同,Thanos 能夠正確地對這些資料進行重複資料刪除。

Thanos 有一個警報元件,該元件位於 Thanos 示意圖中。但他的 .

Thanos 的優勢在於 Thanos 和 Prometheus 共享相同的程式碼。 Thanos 和 Prometheus 是由同一個開發人員開發的。當薩諾斯或普羅米修斯其中一方升級時,另一方就會獲勝。

VictoriaMetrics 的主要功能是 MetricsQL。這些是 PromQL 的 VictoriaMetrics 擴展,我在之前的大型監控聚會上討論過它。

VictoriaMetrics 支援透過多種不同的協定上傳資料。 VictoriaMetrics 不僅可以接受來自 Prometheus 的數據,還可以接受 Influx、OpenTSDB 和 Graphite 協定的數據。

VictoriaMetrics 資料通常比 Thanos 和 Prometheus 佔用的空間少得多。
在記錄真實資料時,使用者報告與 Prometheus 和 Thanos 相比,磁碟上的資料大小減少了 2-5 倍。

VictoriaMetrics 的另一個優點是它已經針對速度進行了最佳化。

讓我們來看看基礎設施的成本。

Thanos 的優點之一是將資料儲存在物件儲存中,相對便宜。
在物件儲存中儲存資料時,您必須為資料寫入和讀取操作付費(每百萬次操作 10 美元)。當您將資料寫入物件儲存時,您需要支付將資料上傳到網路的託管費用,除非您的叢集在 AWS 中 - 那裡是免費的。當您讀取資料時,您需要支付每 10TB 230 美元到 1 美元。如果您經常從 Thanos 叢集查詢歷史數據,這可能非常重要。

對於 Thanos 集群,您需要為 Compact、Store Gateway、Query 元件的伺服器付費,這些元件需要大量記憶體、CPU 來處理大量資料。

VictoriaMetrics 有以下費用。如果將資料儲存在 GCE HDD 磁碟上,則每 40TB 的費用為 1 美元。對於 VictoriaMetrics 來說,普通的 HDD 磁碟就足夠了,不需要 SSD,後者的成本要高出五倍。 VictoriaMetrics 針對 HDD 進行了最佳化。

VictoriaMetrics 需要元件伺服器:單一節點或叢集元件,與 Thanos 元件不同,它們需要的 CPU 和 RAM 要少得多,因此更便宜。

實施範例。

Thanos 的實作範例是 Gitlab。 Gitlab 完全在 Thanos 上運作。但那裡的情況並非如此順利。如果你看著它們 ,然後你可以看到他們不斷有某種 :儲存網關或查詢元件記憶體不足。他們必須不斷增加內存容量。
這增加了解決這些問題的成本。
第二個實現者可能更成功的是 Improbable 公司,該公司已開始開發 Thanos。他們已經發布了 Thanos 原始碼。 Improbable 是一家開發遊戲引擎的公司。

VictoriaMetrics 公開的實作範例有:
- wix.com 網站建置者
- 阿迪達斯正在推出 VictoriaMetrics,甚至在最新的 PromCon 2019 上發表了演講
- TrafficStars — 廣告網絡
- Seznam.cz 是一個受歡迎的捷克搜尋引擎。
然後出現了一些不知名的公司,我現在不能說出它們的名字。他們沒有表示同意。
- 大型遊戲開發商。比他們的不可能更大。
- 圖形軟體的主要開發人員。
- 一家大型俄羅斯銀行。
- 成功測試 VictoriaMetrics 的歐洲風力渦輪機製造商。該製造商正在部署 VictoriaMetrics 來監測從風力渦輪機收集的數據,每個感測器的速率為每秒 50 個樣本。每個風力渦輪機包含數百個感測器。他們有數百颱風力渦輪機。
- 俄羅斯航空公司想要實施 VictoriaMetrics,但無法實施。我們正與他們處於協議階段。
 結論。
結論。
VictoriaMetrics 和 Thanos 解決了類似的問題,但方式不同:
- 全域查詢視圖
- 水平擴展
- 任意扣留

謝謝。
我們期待您的光臨 .

只有註冊用戶才能參與調查。 , 請。
您使用什麼作為 Prometheus 的長期儲存?
滅霸6
Cortex0
M3DB0
VictoriaMetrics7
其他4
17 位用戶投票。 16 名用戶棄權。
來源: www.habr.com
