

VictoriaMetrics、TimescaleDB 和 InfluxDB 的比較 在一個包含 40 億個資料點且屬於 XNUMXK 個獨特時間序列的資料集上。
幾年前是Zabbix時代。每個裸機伺服器只有幾個指標——CPU 使用率、RAM 使用率、磁碟使用率和網路使用率。這樣,來自數千台伺服器的指標就可以融入 40 個獨特的時間序列,而 Zabbix 可以使用 MySQL 作為時間序列資料的後端:)
目前一個 使用預設配置,普通主機上可提供超過 500 個指標。有許多 適用於各種資料庫、網路伺服器、硬體系統等。它們都提供了許多有用的指標。全部 開始為自己設定各種指標。 Kubernetes 有自己的叢集和 pod,可以揭露大量指標。這會導致伺服器在每個主機上暴露數千個唯一指標。因此,獨特的 40K 時間序列不再具有高功率。它正在成為主流,並且應該可以透過單一伺服器上的任何現代 TSDB 輕鬆處理。
此時大量獨特的時間序列是什麼?大概是 400K 或 4M?還是40米?讓我們將現代 TSDB 與這些圖表進行比較。
安裝基準
– 是 TSDB 的絕佳基準測試工具。它允許透過傳遞所需時間序列數量除以 10 來產生任意數量的指標 - 標誌 (以前的 -scale-var)。 10 是每個主機、伺服器上產生的測量(指標)的數量。使用 TSBS 為基準產生了以下資料集:
- 400K 個唯一時間序列,資料點間隔 60 秒,資料跨越整整 3 天,總資料點約 1.7 億個。
- 4M 獨特時間序列,600 秒間隔,資料跨越整整 3 天,總資料點約 1.7 億個。
- 40M 獨特時間序列,1 小時間隔,資料跨越整整 3 天,總資料點約 2.8B。
客戶端和伺服器在專用實例上運行。 在谷歌雲中。這些樣本具有以下配置:
- vCPU:16
- 內存:60 GB
- 儲存:標準1TB硬碟。它可提供 120MBps 的讀取/寫入吞吐量、每秒 750 次讀取操作和每秒 1,5K 次寫入操作。
TSDB 是從官方 docker 映像中提取出來的,並在 docker 中運行,配置如下:
VictoriaMetrics:
docker run -it --rm -v /mnt/disks/storage/vmetrics-data:/victoria-metrics-data -p 8080:8080 valyala/victoria-metrics為了支援高容量,需要使用 InfluxDB 值(-e)。有關詳細信息,請參閱 ):
docker run -it --rm -p 8086:8086 -e INFLUXDB_DATA_MAX_VALUES_PER_TAG=4000000 -e INFLUXDB_DATA_CACHE_MAX_MEMORY_SIZE=100g -e INFLUXDB_DATA_MAX_SERIES_PER_DATABASE=0 -v /mnt/disks/storage/influx-data:/var/lib/influxdb influxdbTimescaleDB(配置採用自 文件):
MEM=`free -m | grep "Mem" | awk ‘{print $7}’`
let "SHARED=$MEM/4"
let "CACHE=2*$MEM/3"
let "WORK=($MEM-$SHARED)/30"
let "MAINT=$MEM/16"
let "WAL=$MEM/16"
docker run -it — rm -p 5432:5432
--shm-size=${SHARED}MB
-v /mnt/disks/storage/timescaledb-data:/var/lib/postgresql/data
timescale/timescaledb:latest-pg10 postgres
-cmax_wal_size=${WAL}MB
-clog_line_prefix="%m [%p]: [%x] %u@%d"
-clogging_collector=off
-csynchronous_commit=off
-cshared_buffers=${SHARED}MB
-ceffective_cache_size=${CACHE}MB
-cwork_mem=${WORK}MB
-cmaintenance_work_mem=${MAINT}MB
-cmax_files_per_process=100資料載入器以 16 個並行執行緒運行。
本文僅包含插入基準的結果。樣本基準測試的結果將在單獨的文章中發布。
400K 個唯一時間序列
讓我們從簡單的元素開始—400K。基準測試結果:
- VictoriaMetrics:每秒 2,6 萬個資料點; RAM 使用量:3 GB;磁碟上的最終資料大小:965 MB
- InfluxDB:每秒 1.2M 個資料點; RAM 使用量:8.5 GB;磁碟上的最終資料大小:1.6 GB
- 時間尺度:每秒 849K 個資料點; RAM 使用量:2,5 GB;磁碟上的最終資料大小:50 GB
從上面的結果可以看出,VictoriaMetrics在插入效能和壓縮率上勝出。時間軸在 RAM 使用方面勝出,但它佔用了大量的磁碟空間——每個資料點 29 位元組。
以下是基準測試期間每個 TSDB 的 CPU 使用率圖表:
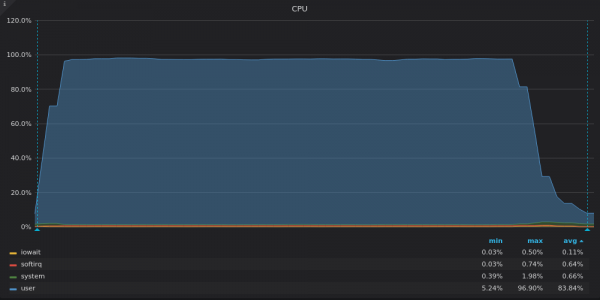
上面的截圖:VictoriaMetrics – 唯一指標 400K 的插入測試期間的 CPU 負載。
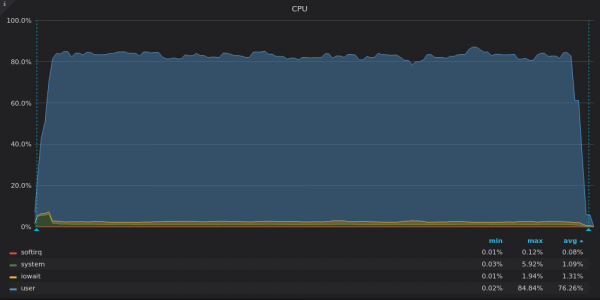
上面的截圖:InfluxDB-400K 個唯一指標插入測試期間的 CPU 負載。
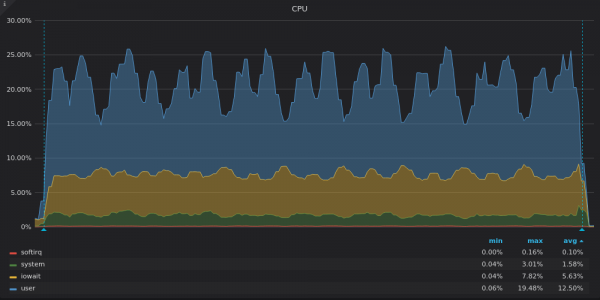
上面的截圖:TimescaleDB-對唯一指標400K進行插入測試期間的CPU負載。
VictoriaMetrics 利用了所有可用的 vCPU,而 InfluxDB 的 2 個 vCPU 中約 16 個利用不足。
Timescale 僅使用 3 個 vCPU 中的 4-16 個。 TimescaleDB 時間尺度圖上的高 iowait 和系統共用顯示輸入/輸出 (I/O) 子系統存在瓶頸。我們來看看磁碟頻寬使用量圖表:
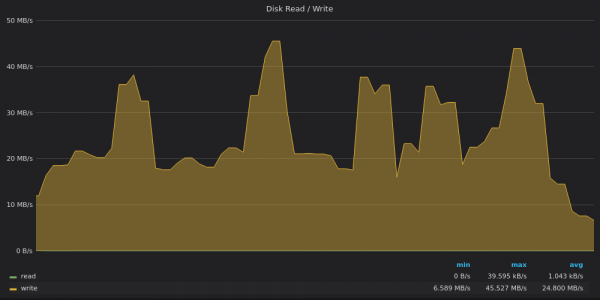
上面的截圖:VictoriaMetrics - 400K 唯一計數的插入測試的磁碟頻寬利用率。
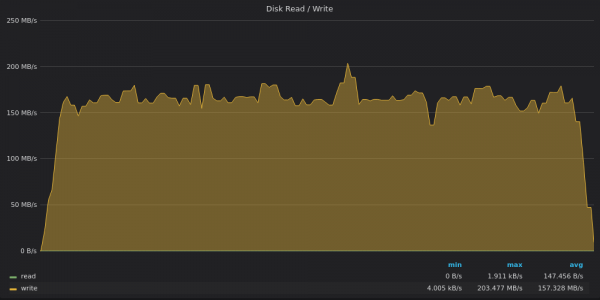
上面的截圖:InfluxDB-400K唯一值的插入測試的磁碟吞吐量使用情況。
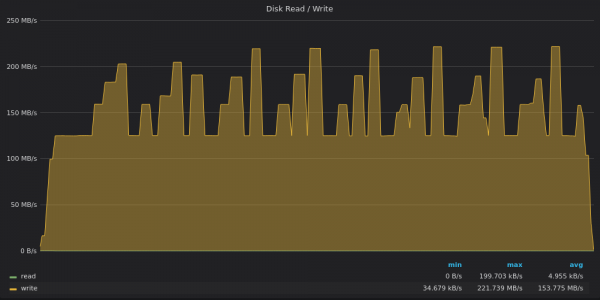
上面的截圖:TimescaleDB-400K唯一值的插入測試的磁碟頻寬使用量。
VictoriaMetrics 以 20 Mbps 的速度記錄數據,峰值高達 45 Mbps。峰值對應於樹中的大型部分合併 .
InfluxDB 以 160 MB/s 的速度寫入數據,而 1 TB 磁碟 寫入吞吐量為120 MB/s。
TimescaleDB 的寫入吞吐量限制為 120 Mbps,但有時它會突破該限制並達到 220 Mbps 的峰值。這些峰值與上圖中 CPU 使用率不足的下降相對應。
讓我們來看看 I/O 使用圖:
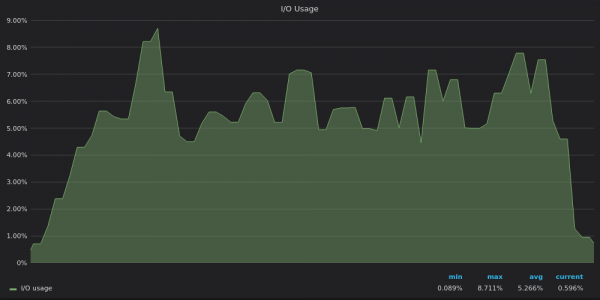
上面的截圖:VictoriaMetrics - 插入測試期間 400K 個唯一指標的 I/O 使用情況。
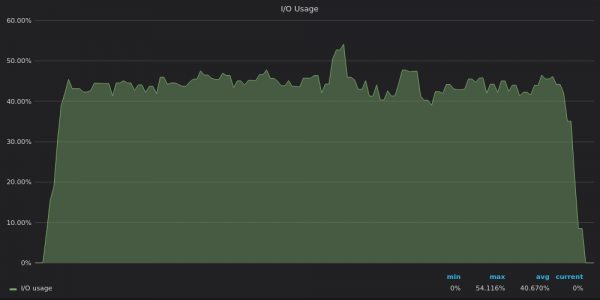
上面的截圖:InfluxDB-插入 400K 個唯一指標的測試 IO 使用情況。
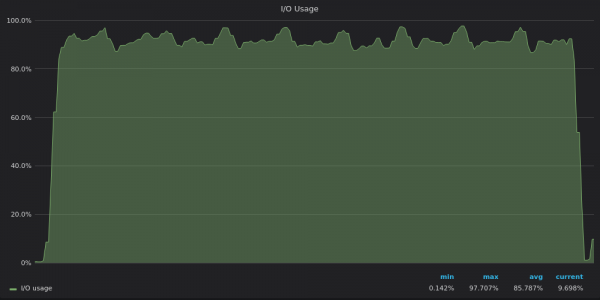
上面的截圖:TimescaleDB - 插入測試期間 400K 個唯一指標的 I/O 使用情況。
現在很明顯,TimescaleDB 已達到其 I/O 限制,因此它無法使用剩餘的 12 個 vCPU。
4M 獨特時間序列
4M 時間序列看起來有點困難。但我們的競爭對手成功通過了這次考驗。基準測試結果:
- VictoriaMetrics:每秒 2,2 萬個資料點; RAM 使用量:6 GB;磁碟上的最終資料大小:3 GB。
- InfluxDB:每秒 330K 個資料點; RAM 使用量:20,5 GB;磁碟上的最終資料大小:18,4 GB。
- TimescaleDB:每秒 480K 個資料點; RAM 使用量:2,5 GB;磁碟上的最終資料大小:52 GB。
InfluxDB 效能從 1,2K 時間序列的 400M 個資料點/秒下降到 330M 時間序列的 4K 個資料點/秒。與其他競爭對手相比,這是一個顯著的性能損失。讓我們來看看 CPU 使用率圖表來了解這種損失的根本原因:
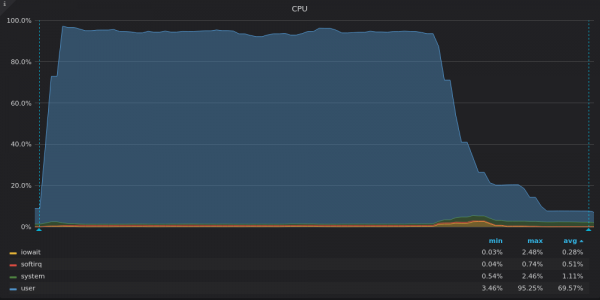
上面的截圖:VictoriaMetrics - 4M 唯一時間序列插入測試期間的 CPU 使用率。
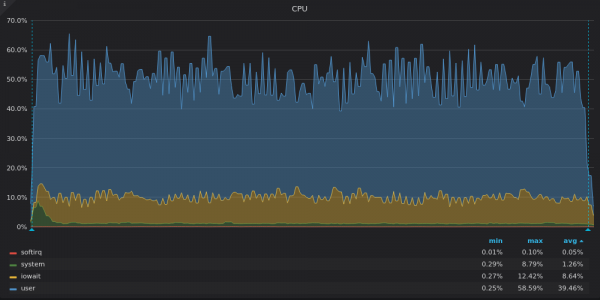
上面的截圖:InfluxDB-4M 唯一時間序列插入測試期間的 CPU 使用率。
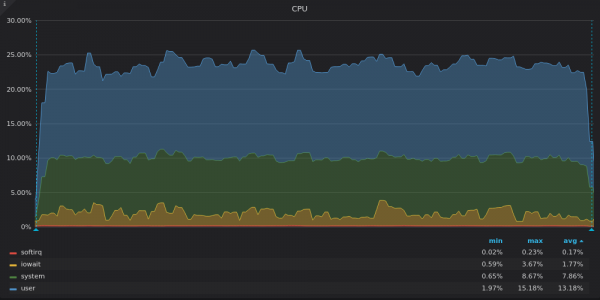
上面的截圖:TimescaleDB - 4M 唯一時間序列插入測試期間的 CPU 使用率。
VictoriaMetrics 幾乎使用了您所有的 CPU 能力。最後的 drop 對應於所有資料插入後剩餘的 LSM 合併。
InfluxDB 只使用 8 個 vCPU 中的 16 個,而 TimsecaleDB 使用了 4 個 vCPU 中的 16 個。他們的圖表有哪些共同點?高份額 iowait,這再次表明存在 I/O 瓶頸。
TimescaleDB 佔有率很高 system。我們認為高功率導致了許多系統呼叫或許多 .
讓我們來看看磁碟吞吐量圖表:
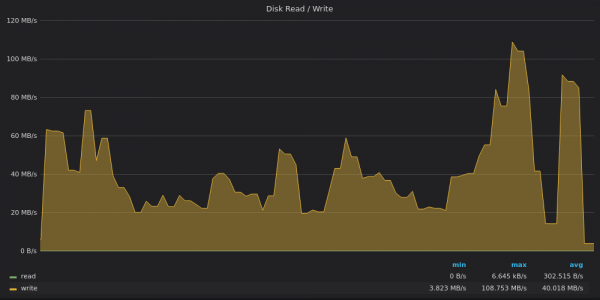
上面的截圖:VictoriaMetrics - 插入 4M 個唯一指標的磁碟頻寬使用量。
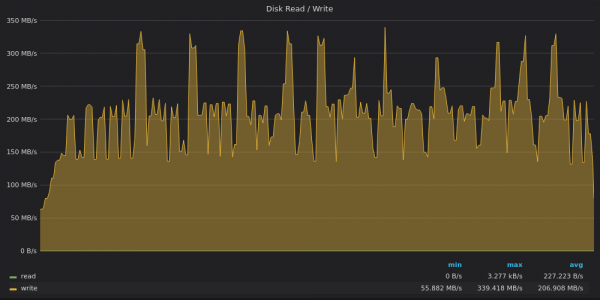
上面的截圖:InfluxDB-插入 4M 個唯一指標的磁碟頻寬使用量。
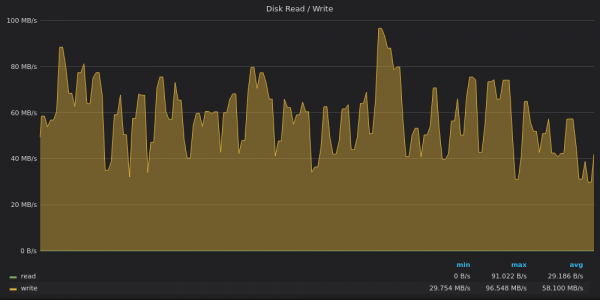
上面的截圖:TimescaleDB-插入 4M 個唯一指標的磁碟頻寬使用量。
VictoriaMetrics 的峰值為 120MB/s,而平均寫入速度為 40MB/s。在高峰期可能發生過幾次大規模的 LSM 合併。
InfluxDB 再次在寫入限制為 200 MB/s 的磁碟上實現了 340 MB/s 的平均寫入吞吐量,峰值高達 120 MB/s :)
TimescaleDB 不再受磁碟限制。似乎受到其他高比例物質的限制 системной CPU 負載。
我們來看看 IO 使用情況圖表:
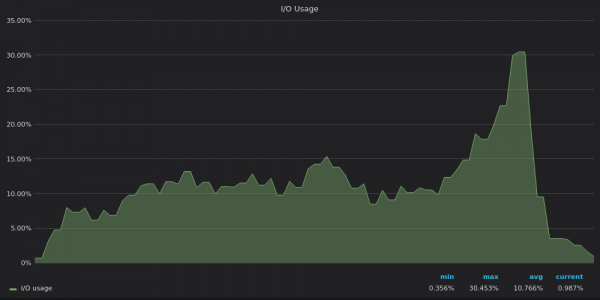
上面的截圖:VictoriaMetrics - 4M 唯一時間序列插入測試期間的 I/O 使用情況。
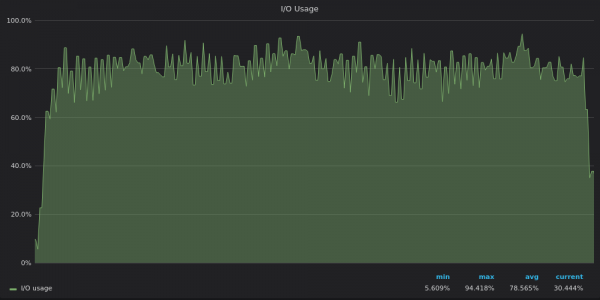
上面的截圖:InfluxDB-4M 唯一時間序列插入測試期間的 I/O 使用情況。
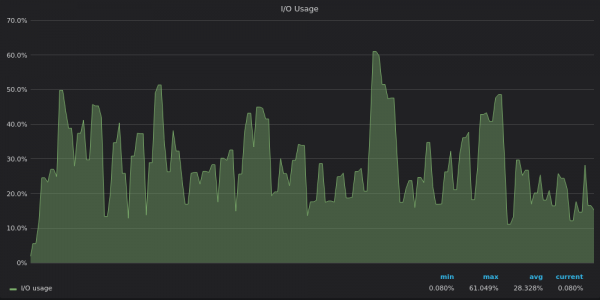
上面的截圖:TimescaleDB - 4M 唯一時間序列插入測試期間的 I/O 使用。
IO 使用情況圖表反映了磁碟頻寬使用量圖表 - InfluxDB 受到 IO 限制,而 VictoriaMetrics 和 TimescaleDB 有足夠的 IO 資源。
40M 獨特時間序列
40M 唯一時間序列對 InfluxDB 來說太大了 🙁
基準測試結果:
- VictoriaMetrics:每秒 1,7 萬個資料點; RAM 使用量:29 GB;磁碟空間使用量:17 GB。
- InfluxDB:未完成,因為它需要超過 60GB 的 RAM。
- TimescaleDB:每秒 330K 個資料點,RAM 使用量:2,5GB;磁碟空間使用量:84GB。
TimescaleDB 顯示 RAM 使用率異常低且穩定,為 2,5GB,與 4M 和 400K 唯一指標相同。
VictoriaMetrics 以每秒 100 萬個數據點的速度緩慢增長,直到處理完所有 40 萬個帶標籤的指標名稱。然後它實現了每秒 1,5-2,0 M 個數據點的穩定插入率,因此最終結果是每秒 1,7 M 個數據點。
40M 唯一時間序列的圖表與 4M 唯一時間序列的圖表類似,因此我們跳過它們。
發現
- 現代 TSDB 能夠在單一伺服器上處理數百萬個唯一時間序列的插入。在下一篇文章中,我們將測試 TSDB 對數百萬個唯一時間序列的選擇效果如何。
- 低 CPU 使用率通常表示存在 I/O 瓶頸。此外,它可能表示鎖定太粗糙,一次只能運行幾個執行緒。
- I/O 瓶頸確實存在,尤其是在非 SSD 儲存中,例如雲端供應商的虛擬化區塊裝置。
- VictoriaMetrics 針對速度慢、I/O 低的儲存提供了最佳最佳化。它提供最佳的速度和最佳的壓縮比。
下載 並在您的數據上嘗試。相應的靜態二進位檔案可在以下位置取得: .
閱讀有關 VictoriaMetrics 的更多信息 .
更新:已發布 具有可重複的結果。
更新#2:另請閱讀 .
更新 #3: !
電報聊天:
來源: www.habr.com
