

In hierdie artikel sal ek praat oor hoe die projek waaraan ek werk, van 'n groot monoliet in 'n stel mikrodienste ontwikkel het.
Die projek het sy geskiedenis redelik lank gelede begin, vroeg in 2000. Die eerste weergawes is in Visual Basic 6 geskryf. Met verloop van tyd het dit duidelik geword dat ontwikkeling in hierdie taal moeilik in die toekoms ondersteun sou word, aangesien die IDE en die taal self ontwikkel swak. In die laat 2000's is besluit om na die meer belowende C# oor te skakel. Die nuwe weergawe is geskryf in parallel met die hersiening van die ou een, geleidelik meer en meer kode was in .NET. Die backend in C# was oorspronklik gefokus op die diensargitektuur, maar algemene biblioteke met logika is tydens ontwikkeling gebruik, en dienste is in 'n enkele proses bekendgestel. Die resultaat was 'n toepassing wat ons die "diensmonoliet" genoem het.
Een van die min voordele van so 'n bondel was die vermoë vir dienste om mekaar deur 'n eksterne API te bel. Daar was duidelike voorvereistes vir die oorgang na 'n meer korrekte diens, en in die toekoms, mikrodiensargitektuur.
Ons het rondom 2015 met ons ontbindingswerk begin. Ons het nog nie die ideale toestand bereik nie – daar is dele van ’n groot projek wat kwalik monoliete genoem kan word, maar dit lyk ook nie soos mikrodienste nie. Vooruitgang is egter beduidend.
Ek sal in die artikel daaroor praat.
inhoud
Argitektuur en probleme van die bestaande oplossing
Aanvanklik het die argitektuur soos volg gelyk: UI - 'n aparte toepassing, die monolitiese deel is in Visual Basic 6 geskryf, die .NET-toepassing was 'n stel verwante dienste wat met 'n redelik groot databasis werk.
Nadele van die vorige oplossing
Enkele punt van mislukking
Ons het 'n enkele punt van mislukking gehad: die .NET-toepassing het in een proses gehardloop. As enige van die modules misluk het, het die hele toepassing misluk en moes dit weer begin word. Aangesien ons 'n groot aantal prosesse vir verskillende gebruikers outomatiseer, as gevolg van 'n mislukking in een van hulle, kon almal vir 'n geruime tyd nie werk nie. En met 'n sagtewarefout het oortolligheid ook nie gehelp nie.
Verbeterings tou
Hierdie tekortkoming is meer organisatories. Daar is baie kliënte in ons aansoek, en hulle wil almal dit so gou as moontlik finaliseer. Voorheen was dit onmoontlik om dit parallel te doen, en alle kliënte het in die ry gestaan. Hierdie proses het 'n negatiewe vir die besigheid veroorsaak, want hulle moes bewys dat hul taak van waarde was. En die ontwikkelingspan het tyd spandeer om hierdie tou te organiseer. Dit het baie tyd en moeite gekos, en gevolglik kon die produk nie so vinnig verander as wat ons dit sou wou hê nie.
Suboptimale gebruik van hulpbronne
Wanneer ons dienste in 'n enkele proses aanbied, het ons die konfigurasie altyd heeltemal van bediener na bediener gekopieer. Ons wou die mees gelaaide dienste afsonderlik skei om nie hulpbronne te mors nie, en om meer buigsame beheer oor ons ontplooiingskema te kry.
Moeilik om moderne tegnologie te implementeer
'N Probleem wat aan alle ontwikkelaars bekend is: daar is 'n begeerte om moderne tegnologieë in die projek in te voer, maar daar is geen manier nie. Met 'n groot monolitiese oplossing, verander enige opdatering van die huidige biblioteek, om nie eens te praat van die oorgang na 'n nuwe een nie, in 'n taamlik nie-triviale taak. Dit neem lank om aan die spanleier te bewys dat dit meer bonusse sal meebring as vermorste senuwees.
Moeilik om veranderinge uit te reik
Dit was die ernstigste probleem - ons het elke twee maande vrystellings uitgereik.
Elke vrystelling het 'n ware ramp vir die bank geword, ondanks die toetsing en pogings van die ontwikkelaars. Die besigheid het verstaan dat sommige van die funksionaliteit aan die begin van die week nie daarvoor sou werk nie. En die ontwikkelaars het verstaan dat 'n week van ernstige voorvalle op hulle wag.
Almal het 'n begeerte gehad om die situasie te verander.
Verwagtinge van mikrodienste
Uitreiking van komponente wanneer gereed. Uitreiking van komponente soos hulle gereed is deur die oplossing te ontbind en verskillende prosesse te skei.
Klein produkspanne. Dit is belangrik omdat die groot span wat aan die ou monoliet gewerk het, moeilik was om te bestuur. So ’n span was gedwing om volgens ’n streng proses te werk, maar hulle wou meer kreatiwiteit en onafhanklikheid hê. Slegs klein spanne kon dit bekostig.
Isolasie van dienste in afsonderlike prosesse. Ideaal gesproke wil ek dit in houers isoleer, maar 'n groot aantal dienste wat in die .NET Framework geskryf is, loop slegs onder WindowsDienste gebaseer op .NET Core verskyn nou, maar daar is steeds min van hulle.
Ontplooiing buigsaamheid. Ek wil graag dienste kombineer soos ons dit nodig het, en nie soos die kode afdwing nie.
Gebruik van nuwe tegnologieë. Dit is van belang vir enige programmeerder.
Oorgangskwessies
Natuurlik, as dit maklik was om 'n monoliet in mikrodienste te verdeel, sou dit nie nodig wees om by konferensies daaroor te praat en artikels te skryf nie. Daar is baie slaggate in hierdie proses, ek sal die belangrikstes beskryf wat ons verhinder het.
Eerste probleem tipies vir die meeste monoliete: besigheidslogika-konnektiwiteit. Wanneer ons 'n monoliet skryf, wil ons ons klasse hergebruik om nie ekstra kode te skryf nie. En wanneer na mikrodienste oorgeskakel word, word dit 'n probleem: al die kode is nogal styf gekoppel, en dit is moeilik om dienste te skei.
Ten tyde van die aanvang van die werk het die bewaarplek meer as 500 projekte en meer as 700 duisend reëls kode gehad. Dit is 'n groot genoeg oplossing. tweede probleem. Dit was nie moontlik om dit bloot in mikrodienste te neem en te verdeel nie.
Derde probleem — Gebrek aan nodige infrastruktuur. Trouens, ons was besig met die handmatige kopiëring van die bronkode na die bedieners.
Hoe om van monoliet na mikrodienste te beweeg
Toewysing van mikrodienste
Eerstens het ons dadelik vir onsself vasgestel dat die skeiding van mikrodienste 'n iteratiewe proses is. Daar is nog altyd van ons verwag om besigheidstake parallel te ontwikkel. Hoe ons dit tegnies gaan implementeer, is reeds ons probleem. Daarom het ons voorberei vir 'n iteratiewe proses. Dit sal nie anders werk as jy 'n groot toepassing het nie, en dit is nie aanvanklik gereed om oorgeskryf te word nie.
Watter metodes gebruik ons om mikrodienste te isoleer?
Die eerste manier - om bestaande modules as dienste uit te neem. In hierdie verband was ons gelukkig: daar was reeds geformaliseerde dienste wat volgens die WCF-protokol gewerk het. Hulle is in afsonderlike gemeentes verdeel. Ons het hulle afsonderlik oorgedra en 'n klein lanseerder by elke bou gevoeg. Dit is geskryf met behulp van die wonderlike Topshelf-biblioteek, waarmee u die toepassing sowel as 'n diens as 'n konsole kan laat loop. Dit is nuttig vir ontfouting omdat geen bykomende projekte in die oplossing vereis word nie.
Die dienste is deur besigheidslogika verbind, aangesien hulle algemene samestellings gebruik het en met 'n gemeenskaplike databasis gewerk het. Dit was moeilik om hulle mikrodienste in hul suiwerste vorm te noem. Ons kan egter hierdie dienste afsonderlik in verskillende prosesse uitreik. Dit het dit reeds moontlik gemaak om hul invloed op mekaar te verminder, wat die probleem met parallelle ontwikkeling en 'n enkele punt van mislukking verminder het.
Die gasheersamestelling is net een reël kode in die Programklas. Ons het die werk met Topshelf in 'n hulpklas weggesteek.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Die tweede manier om mikrodienste te isoleer: skep hulle om nuwe probleme op te los. As die monoliet terselfdertyd nie groei nie, is dit reeds uitstekend, wat beteken dat ons in die regte rigting beweeg. Om nuwe probleme op te los, het ons probeer om aparte dienste te skep. As daar so 'n geleentheid was, dan het ons meer "kanonieke" dienste geskep wat hul datamodel, 'n aparte databasis, heeltemal bestuur.
Ons, soos baie ander, het begin met verifikasie- en magtigingsdienste. Hulle is perfek hiervoor. Hulle is onafhanklik, as 'n reël het hulle 'n aparte datamodel. Hulle het self nie interaksie met die monoliet nie, net dit verwys na hulle om 'n paar probleme op te los. Op hierdie dienste kan u die oorgang na 'n nuwe argitektuur begin, die infrastruktuur daarop ontfout, 'n paar benaderings probeer wat met netwerkbiblioteke verband hou, ens. Daar is geen spanne in ons organisasie wat nie 'n stawingdiens kon maak nie.
Die derde manier om mikrodienste te isoleer, wat ons gebruik, is 'n bietjie spesifiek vir ons. Dit is die verwydering van besigheidslogika van die UI-laag. Ons hoof UI-toepassing is lessenaar, dit is, soos die backend, in C# geskryf. Die ontwikkelaars het van tyd tot tyd foute gemaak en dele van die logika op die UI uitgehaal wat in die agterkant moes bestaan en hergebruik het.
As jy na 'n werklike voorbeeld van die kode van die UI-deel kyk, kan jy sien dat die meeste van hierdie oplossing werklike besigheidslogika bevat, wat nuttig is in ander prosesse, nie net vir die bou van 'n UI-vorm nie.
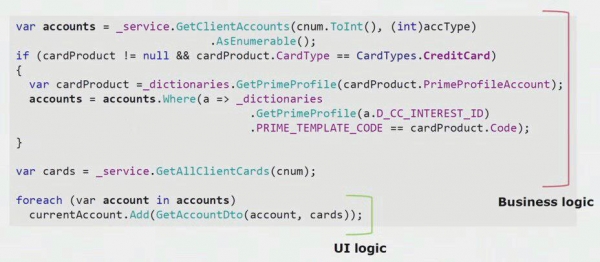
Die regte UI-logika daar is net die laaste paar reëls. Ons het dit na die bediener oorgedra sodat dit hergebruik kon word, en sodoende die UI verminder en die korrekte argitektuur verkry.
Vierde, belangrikste manier om mikrodienste te isoleer, wat jou toelaat om die monoliet te verminder, is die verwydering van bestaande dienste met verwerking. Wanneer ons bestaande modules uithaal soos hulle is, hou ontwikkelaars nie altyd van die resultaat nie, en die besigheidsproses kan verouderd raak sedert die skepping van die funksionaliteit. Deur herfaktorering kan ons 'n nuwe besigheidsproses ondersteun omdat besigheidsvereistes voortdurend verander. Ons kan die bronkode verbeter, bekende defekte verwyder, 'n beter datamodel skep. Daar is baie voordele om te behaal.
Ontkoppeling van dienste met herwerk gaan hand aan hand met die konsep van begrensde konteks. Dit is 'n konsep van domein-georiënteerde ontwerp. Dit beteken 'n gedeelte van die domeinmodel waarin al die terme van 'n enkele taal uniek gedefinieer word. Beskou die konteks van versekering en rekeninge as 'n voorbeeld. Ons het 'n monolitiese toepassing, en dit is nodig om met die rekening in versekering te werk. Ons verwag dat die ontwikkelaar die bestaande rekeningklas in 'n ander samestelling sal vind, 'n verwysing daarna uit die versekeringsklas sal maak, en ons sal werkskode kry. Die DRY-beginsel sal nagekom word, die taak sal vinniger gedoen word deur bestaande kode te gebruik.
Gevolglik blyk dit dat die kontekste van rekeninge en versekerings verband hou. Soos nuwe vereistes kom, sal hierdie verhouding inmeng met ontwikkeling, wat kompleksiteit by 'n reeds komplekse besigheidslogika voeg. Om hierdie probleem op te los, moet jy die grense tussen kontekste in die kode vind en hul oortredings verwyder. Byvoorbeeld, in die konteks van versekering, is dit heel moontlik dat die 20-syfernommer van die Sentrale Bankrekening en die datum van opening van die rekening voldoende sal wees.
Om hierdie begrensde kontekste van mekaar te skei en die proses te begin om mikrodienste uit 'n monolitiese oplossing te onttrek, het ons 'n benadering gebruik soos die skep van eksterne API's binne die toepassing. As ons geweet het dat een of ander module 'n mikrodiens moet word, op een of ander manier binne die proses moet verander, dan het ons dadelik oproepe gemaak na die logika wat tot 'n ander beperkte konteks behoort deur eksterne oproepe. Byvoorbeeld, deur REST of WCF.
Ons het beslis self besluit dat ons nie kode sal vermy wat verspreide transaksies sal vereis nie. In ons geval was dit redelik maklik om hierdie reël te volg. Tot dusver het ons nog nie sulke situasies teëgekom wanneer hard verspreide transaksies regtig nodig is nie - die finale konsekwentheid tussen die modules is heeltemal genoeg.
Kom ons kyk na 'n spesifieke voorbeeld. Ons het die konsep van 'n orkestreerder - 'n pyplyn wat die essensie van die "toepassing" verwerk. Hy skep om die beurt 'n kliënt, 'n rekening en 'n bankkaart. As die kliënt en die rekening suksesvol geskep word, maar die kaartskepping misluk, gaan die toepassing nie na die "suksesvolle" status nie en bly dit in die "kaart nie geskep nie" status. In die toekoms sal die agtergrondaktiwiteit dit optel en voltooi. Die stelsel is al 'n geruime tyd in 'n toestand van inkonsekwentheid, maar ons is oor die algemeen tevrede hiermee.
In die geval dat 'n situasie nietemin ontstaan wanneer dit nodig sal wees om 'n deel van die data konsekwent te stoor, sal ons heel waarskynlik vir die vergroting van die diens gaan om dit in een proses te verwerk.
Oorweeg 'n voorbeeld van die toekenning van 'n mikrodiens. Hoe kan dit relatief veilig wees om dit na produksie te bring? In hierdie voorbeeld het ons 'n aparte deel van die stelsel - 'n betaalstaatdiensmodule, een van die kodeafdelings waarvan ons mikrodiens wil maak.
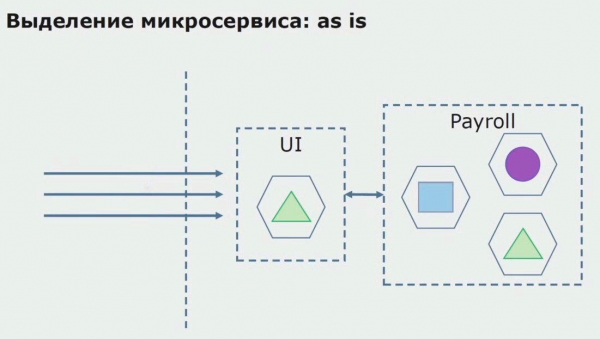
Eerstens skep ons 'n mikrodiens deur die kode te herskryf. Ons verbeter 'n paar punte wat ons nie gepas het nie. Ons implementeer nuwe besigheidsvereistes van die kliënt. Ons voeg by die bondel tussen die UI en die API Gateway-agterkant, wat oproepaanstuur sal verskaf.
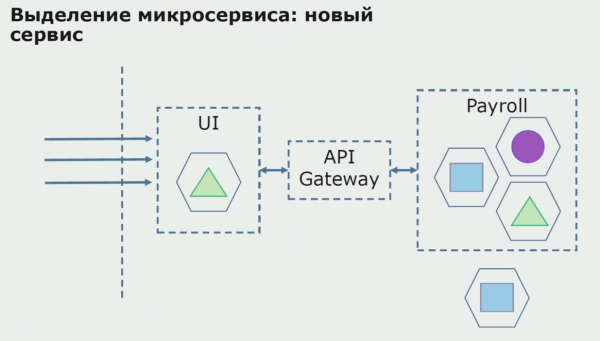
Vervolgens stel ons hierdie konfigurasie in werking, maar in 'n loodstoestand. Die meeste van ons gebruikers werk steeds met ou besigheidsprosesse. Vir nuwe gebruikers ontwikkel ons 'n nuwe weergawe van die monolitiese toepassing wat hierdie proses nie meer bevat nie. Trouens, ons het 'n klomp monoliete en mikrodiens wat in die vorm van 'n vlieënier werk.
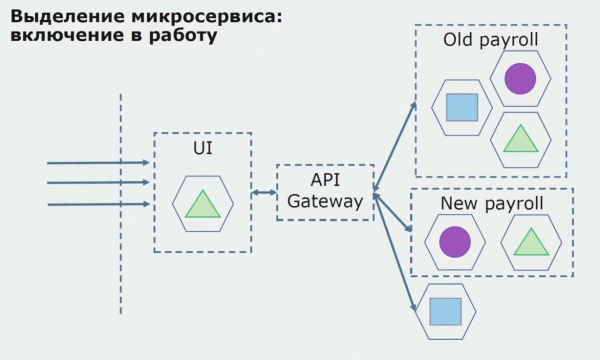
Met 'n suksesvolle vlieënier verstaan ons dat die nuwe konfigurasie regtig werk, ons kan die ou monoliet uit die vergelyking verwyder en die nuwe konfigurasie in die plek van die ou oplossing laat.
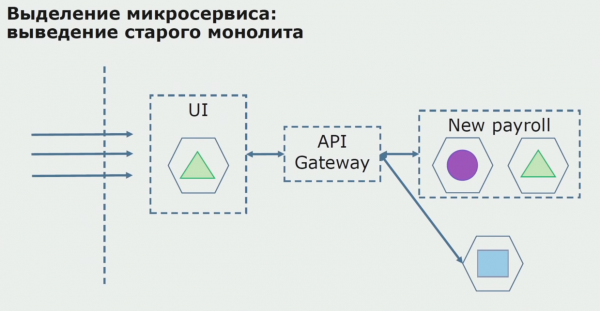
In totaal gebruik ons byna alle bestaande metodes om die bronkode van 'n monoliet te skei. Almal van hulle stel ons in staat om die grootte van dele van die toepassing te verminder en dit na nuwe biblioteke te vertaal, wat 'n beter bronkode maak.
Werk met die databasis
Die databasis leen hom tot skeiding erger as die bronkode, aangesien dit nie net die huidige skema bevat nie, maar ook die opgehoopte historiese data.
Ons databasis, soos baie ander, het nog 'n belangrike nadeel gehad - sy groot grootte. Hierdie databasis is ontwerp volgens die ingewikkelde besigheidslogika van 'n monoliet, en verwantskappe het opgehoop tussen tabelle van verskeie beperkte kontekste.
In ons geval was daar bo en behalwe al die probleme ('n groot databasis, baie verhoudings, soms onverstaanbare grense tussen tabelle), 'n probleem wat in baie groot projekte voorkom: die gebruik van die gedeelde databasispatroon. Data is uit tabelle geneem deur aansigte, deur replikasie en na ander stelsels gestuur waar hierdie replikasie nodig is. As gevolg hiervan kon ons nie die tabelle na 'n aparte skema skuif nie, omdat hulle aktief gebruik is.
In die verdeling help die einste verdeling in beperkte kontekste in die kode ons. Dit gee ons gewoonlik 'n goeie idee van hoe ons data op databasisvlak opbreek. Ons verstaan watter tabelle aan een begrensde konteks behoort en watter aan 'n ander.
Ons het twee globale maniere toegepas om die databasis te verdeel: verdeel bestaande tabelle en verdeel met verwerking.
Om bestaande tabelle te skei is 'n goeie praktyk om te gebruik as die datastruktuur goed is, aan die besigheidsvereistes voldoen en almal tevrede daarmee is. In hierdie geval kan ons bestaande tabelle in 'n aparte skema toewys.
’n Tak met verwerking is nodig wanneer die sakemodel baie verander het, en die tabelle ons glad nie meer tevrede stel nie.
Skeiding van bestaande tabelle. Ons moet bepaal wat ons sal skei. Sonder hierdie kennis sal niks werk nie, en skeiding van beperkte kontekste in die kode sal ons hier help. As 'n reël, as jy die grense van die kontekste in die bronkode kan verstaan, word dit duidelik watter tabelle ingesluit moet word in die lys vir skeiding.
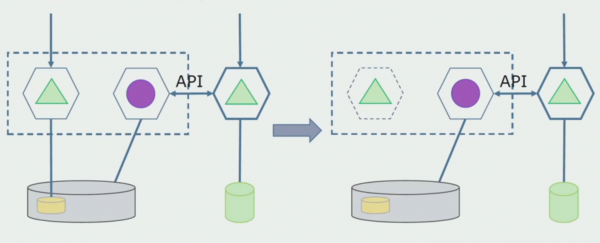
Stel jou voor dat ons 'n oplossing het waar twee monolietmodules met dieselfde databasis interaksie het. Ons moet seker maak dat slegs een module in wisselwerking is met die afdeling van geskeide tabelle, en die ander een begin met dit in wisselwerking deur die API. Om mee te begin, is dit genoeg dat slegs opname deur die API uitgevoer word. Dit is 'n noodsaaklike voorwaarde sodat ons kan praat oor die onafhanklikheid van mikrodienste. Leesskakels kan bly solank daar geen groot probleem is nie.
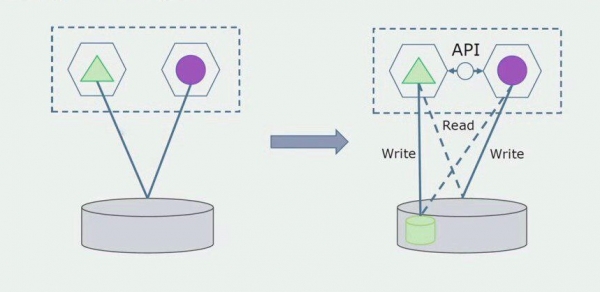
As die volgende stap kan ons reeds die afdeling kode wat met afneembare tabelle werk, met of sonder verwerking, in 'n aparte mikrodiens skei en in 'n aparte proses, 'n houer, hardloop. Dit sal 'n aparte diens wees met 'n verbinding met die monoliet-databasis en daardie tabelle wat nie direk daarmee verband hou nie. Die monoliet is steeds in wisselwerking met die afneembare deel vir lees.
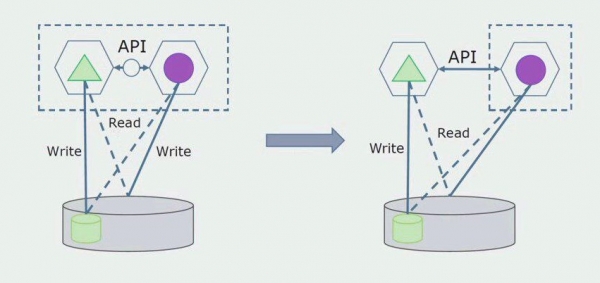
Later sal ons hierdie verbinding verwyder, dit wil sê, ons sal ook die lees van monolitiese toepassingsdata van losstaande tabelle na die API oordra.
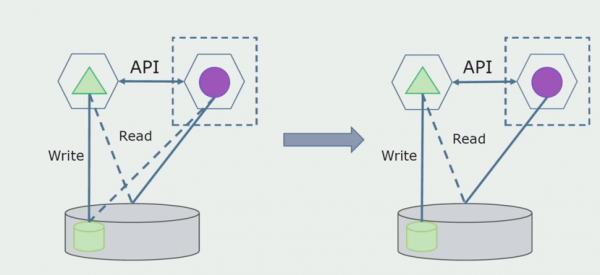
Vervolgens kies ons tabelle uit die algemene databasis waarmee slegs die nuwe mikrodiens werk. Ons kan die tabelle na 'n aparte skema of selfs na 'n aparte fisiese databasis skuif. Daar bly 'n verband vir lees tussen die mikrodiens en die monoliet-databasis, maar daar is niks om oor bekommerd te wees nie, in hierdie opset kan dit vir 'n lang tyd lewe.
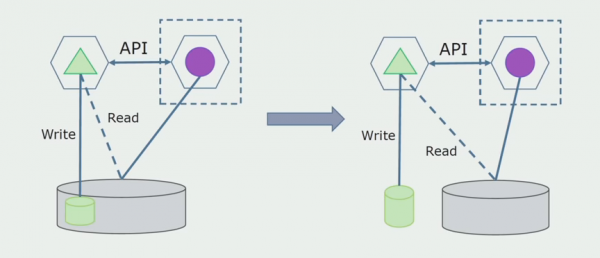
Die laaste stap is om alle verbindings heeltemal te verwyder. In hierdie geval sal ons dalk data van die hoofdatabasis moet migreer. Soms wil ons sommige data of gidse wat vanaf eksterne stelsels in verskeie databasisse gerepliseer is, hergebruik. Ons het dit van tyd tot tyd.
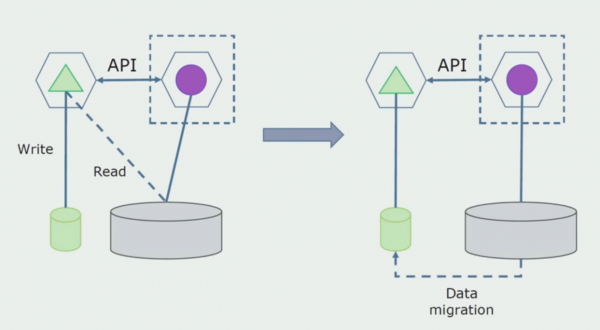
Verwerkingsafdeling. Hierdie metode is baie soortgelyk aan die eerste een, net dit gaan omgekeerd. Ons het onmiddellik 'n nuwe databasis en 'n nuwe mikrodiens wat deur die API met die monoliet in wisselwerking tree. Maar dit laat 'n stel databasistabelle wat ons in die toekoms wil uitvee. Ons sal dit nie meer nodig hê nie, ons het dit in die nuwe model vervang.
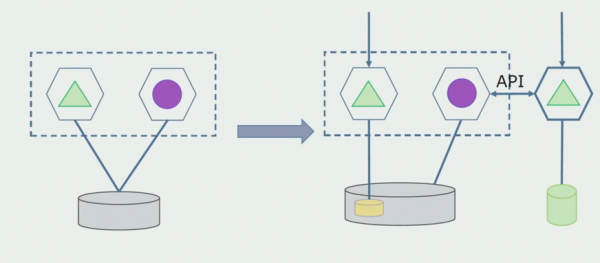
Vir hierdie skema om te werk, sal ons heel waarskynlik 'n oorgangstydperk nodig hê.
Vervolgens is daar twee moontlike benaderings.
Eerste: ons dupliseer alle data in die nuwe en ou databasisse. In hierdie geval het ons data-oortolligheid, daar kan probleme met sinchronisasie wees. Maar dan kan ons twee verskillende kliënte neem. Een sal met die nuwe weergawe werk, die ander met die ou een.
Tweede: skeiding van data volgens een of ander besigheidskenmerk. Ons het byvoorbeeld 5 produkte in die stelsel gehad, wat in die ou databasis gestoor word. Die sesde een, binne die raamwerk van die nuwe besigheidstaak, plaas ons in 'n nuwe databasis. Maar ons het 'n API Gateway nodig wat hierdie data sinchroniseer en die kliënt wys waar en wat om te neem.
Albei benaderings werk, kies afhangende van die situasie.
Nadat ons seker gemaak het dat alles werk, kan die deel van die monoliet wat met die ou databasisstrukture werk, gedeaktiveer word.
Die laaste stap is om die ou datastrukture te verwyder.
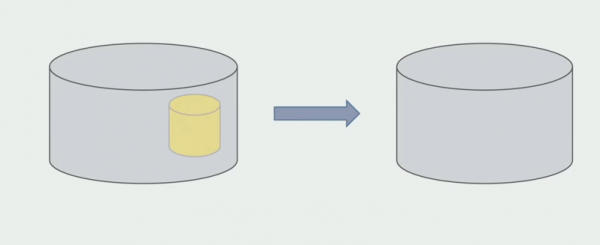
Samevattend kan ons sê dat ons probleme met die databasis het: dit is moeilik om daarmee te werk in vergelyking met die bronkode, dit is moeiliker om te skei, maar dit kan en moet gedoen word. Ons het 'n paar maniere gevind wat jou toelaat om dit redelik veilig te doen, maar dit is makliker om 'n fout met die data te maak as met die bronkode.
Werk met bronkode
Dit is hoe die bronkodediagram gelyk het toe ons die monolitiese projek begin ontleed het.
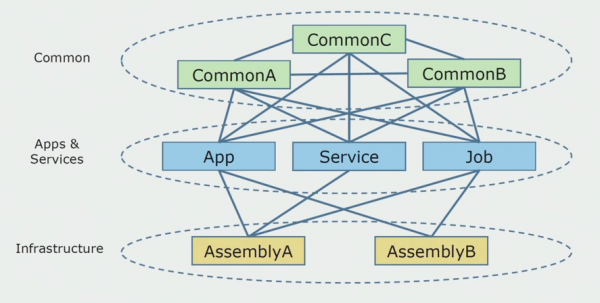
Dit kan voorwaardelik in drie lae verdeel word. Dit is 'n laag lopende modules, plugins, dienste en individuele aktiwiteite. Trouens, dit was toegangspunte binne 'n monolitiese oplossing. Almal van hulle is styf vasgemaak met die Common-laag. Dit het besigheidslogika gehad wat tussen dienste en baie verhoudings gedeel is. Elke diens en inprop het tot 10 of meer algemene samestellings gebruik, afhangend van hul grootte en die gewete van die ontwikkelaars.
Ons was gelukkig, ons het infrastruktuurbiblioteke gehad wat afsonderlik gebruik kon word.
Soms het 'n situasie ontstaan wanneer sommige Algemene voorwerpe nie eintlik aan hierdie laag behoort het nie, maar infrastruktuurbiblioteke was. Dit is opgelos deur te hernoem.
Begrensde kontekste was die grootste bekommernis. Dit het gebeur dat 3-4 kontekste in een gemeenskaplike vergadering gemeng is en mekaar binne dieselfde besigheidsfunksies gebruik het. Dit was nodig om te verstaan waar dit verdeel kan word en langs watter grense, en wat om volgende te doen met die kartering van hierdie skeiding na bronkode samestellings.
Ons het verskeie reëls vir die kodeverdelingsproses geformuleer.
Die eerste: Ons wou nie meer besigheidslogika tussen dienste, aktiwiteite en inproppe deel nie. Ons wou besigheidslogika onafhanklik maak binne mikrodienste. Aan die ander kant word mikrodienste, ideaal gesproke, beskou as dienste wat heeltemal onafhanklik bestaan. Ek dink hierdie benadering is ietwat verkwistend en moeilik om te bereik, want byvoorbeeld C#-dienste sal in elk geval deur die standaardbiblioteek verbind word. Ons stelsel is in C# geskryf, ander tegnologieë is nog nie gebruik nie. Daarom het ons besluit dat ons dit kan bekostig om algemene tegniese geboue te gebruik. Die belangrikste ding is dat hulle geen fragmente van besigheidslogika bevat nie. As jy 'n mooi omhulsel het om die ORM wat jy gebruik, is dit baie duur om dit van diens tot diens te kopieer.
Ons span is 'n aanhanger van domein-georiënteerde ontwerp, so uie-argitektuur was 'n goeie pas vir ons. Die basis in ons dienste was nie die datatoegangslaag nie, maar 'n samestelling met domeinlogika, wat slegs besigheidslogika bevat en sonder skakels na die infrastruktuur is. Terselfdertyd kan ons die domeinsamestelling onafhanklik verfyn om probleme wat met raamwerke verband hou, op te los.
Op hierdie stadium het ons die eerste ernstige probleem ontmoet. Die diens moes na een domeinsamestelling verwys, ons wou die logika onafhanklik maak, en die DRY-beginsel het ons hier ingemeng. Die ontwikkelaars wou klasse van naburige gemeentes hergebruik om duplisering te vermy, en gevolglik het die domeine weer met mekaar begin kommunikeer. Ons het die resultate ontleed en besluit dat die probleem miskien ook op die gebied van die bronkode-bewaartoestel lê. Ons het 'n groot bewaarplek gehad wat al die bronkodes bevat het. Oplossing vir die hele projek was baie moeilik om op 'n plaaslike masjien te bou. Daarom is aparte klein oplossings vir dele van die projek geskep, en niemand het verbied om een of ander gemeenskaplike of domeinsamestelling daarby te voeg en dit te hergebruik nie. Die enigste hulpmiddel wat ons nie toegelaat het om dit te doen nie, was die hersieningskode. Maar soms het hy ook gemors.
Toe het ons begin beweeg na 'n model met aparte bewaarplekke. Besigheidslogika het opgehou om van diens tot diens te vloei, domeine het inderdaad onafhanklik geword. Begrensde kontekste word meer eksplisiet ondersteun. Hoe hergebruik ons infrastruktuurbiblioteke? Ons het hulle in 'n aparte bewaarplek geskei, en dan in Nuget-pakkette gesit, wat ons in Artifactory gesit het. Met enige verandering vind die samestelling en publikasie outomaties plaas.
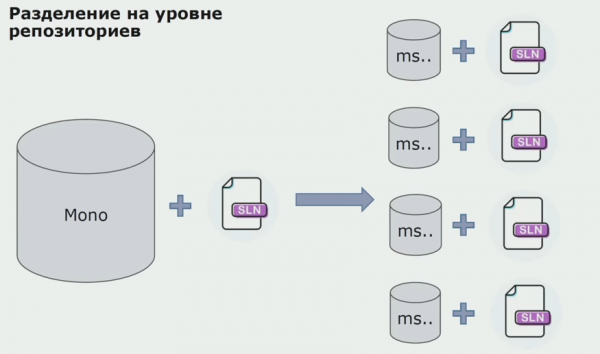
Ons dienste het op dieselfde manier na interne infrastruktuurpakkette begin verwys as na eksterne. Ons laai eksterne biblioteke van Nuget af. Om met Artifactory te werk, waar ons hierdie pakkette geplaas het, het ons twee pakketbestuurders gebruik. In klein bewaarplekke het ons ook Nuget gebruik. In bewaarplekke met veelvuldige dienste het ons 'n Paket gebruik wat meer weergawekonsekwentheid tussen modules bied.
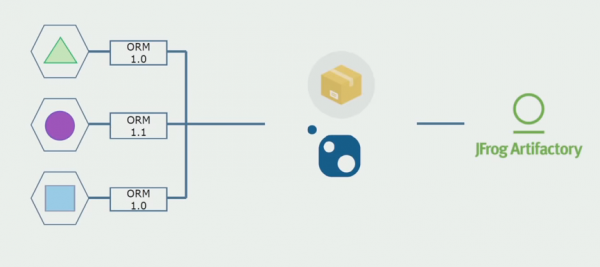
Deur dus aan die bronkode te werk, die argitektuur effens te verander en die bewaarplekke te skei, maak ons ons dienste meer onafhanklik.
Infrastruktuurkwessies
Die meeste van die nadele van die migreer na mikrodienste het te make met infrastruktuur. Jy sal outomatiese ontplooiing nodig hê, jy sal nuwe biblioteke nodig hê om die infrastruktuur te bestuur.
Handmatige installasie in omgewings
Aanvanklik het ons die oplossing op omgewings met die hand geïnstalleer. Om hierdie proses te outomatiseer, het ons 'n CI/CD-pyplyn geskep. Ons het die deurlopende afleweringsproses gekies, want deurlopende ontplooiing is steeds vir ons onaanvaarbaar uit die oogpunt van besigheidsprosesse. Daarom word die stuur in werking deur 'n knoppie uitgevoer, en vir toetsing - outomaties.
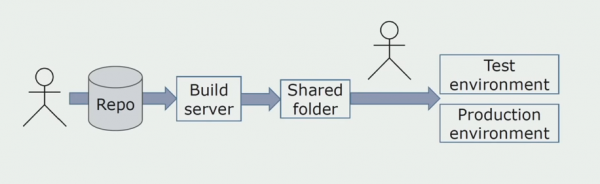
Ons gebruik Atlassian, Bitbucket vir bronberging en Bamboo vir bouwerk. Ons hou daarvan om bouskrifte in Cake te skryf, want dit is dieselfde C#. Klaargemaakte pakkette kom na Artifactory, en Ansible kom outomaties na die toetsbedieners, waarna dit onmiddellik getoets kan word.
Afsonderlike aantekening
Op 'n tyd was een van die idees van die monoliet om gedeelde logboek te verskaf. Ons moes ook uitvind wat om te doen met individuele logs wat op die skywe is. Logs word na tekslêers geskryf. Ons het besluit om die standaard ELK-stapel te gebruik. Ons het nie direk deur verskaffers aan ELK geskryf nie, maar het besluit dat ons die tekslogboeke sou finaliseer en die spoor-ID daarin sou skryf as 'n identifiseerder, en die diensnaam bygevoeg het sodat hierdie logboeke dan ontleed kon word.
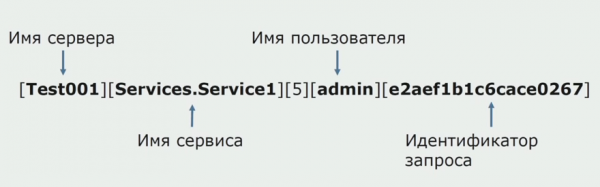
Met Filebeat kan ons ons logs insamel van bedieners, transformeer hulle dan, gebruik Kibana om navrae in die gebruikerskoppelvlak te bou, en kyk hoe die oproep tussen dienste gerig is. Spoor-ID's is baie nuttig hiervoor.
Toets en ontfouting verwante dienste
Aanvanklik het ons nie ten volle verstaan hoe ons die dienste wat ons ontwikkel kon ontfout nie. Alles was eenvoudig met die monoliet, ons het dit op die plaaslike masjien laat loop. Aanvanklik het hulle dieselfde met mikrodienste probeer doen, maar soms, om een mikrodiens volledig te begin, moet jy verskeie ander begin, en dit is ongerieflik. Ons het besef dat dit nodig is om na die model te beweeg wanneer ons net die diens of dienste wat ons wil ontfout op die plaaslike masjien laat. Die oorblywende dienste word gebruik vanaf bedieners wat ooreenstem met die konfigurasie met prod. Na ontfouting, tydens toetsing, vir elke taak, word slegs veranderde dienste aan die toetsbediener uitgereik. Die oplossing word dus getoets in die vorm waarin dit in die toekoms te koop sal wees.
Daar is bedieners waarop slegs produksieweergawes van dienste geïnstalleer is. Hierdie bedieners word benodig vir voorvalle, vir afleweringskontroles voor ontplooiing en vir interne opleiding.
Ons het 'n outomatiese toetsproses bygevoeg deur die gewilde Specflow-biblioteek te gebruik. Toetse word outomaties deur NUnit uitgevoer sodra dit vanaf Ansible ontplooi word. As taakdekking ten volle outomaties is, is dit nie nodig vir handmatige toetsing nie. Alhoewel soms addisionele handtoetsing steeds nodig is. Om te bepaal watter toetse om vir 'n spesifieke kwessie uit te voer, gebruik ons merkers in Jira.
Boonop het die behoefte aan vragtoetsing toegeneem, voorheen is dit slegs in seldsame gevalle uitgevoer. Ons gebruik JMeter om die toetse uit te voer, InfluxDB om dit te stoor, en Grafana om die proses te plot.
Wat het ons bereik?
Eerstens het ons ontslae geraak van die konsep van "vrystelling". Monsterlike vrystellings van twee maande het verdwyn toe hierdie kolos in 'n produksie-omgewing ontplooi is, wat besigheidsprosesse vir 'n rukkie verbreek het. Nou ontplooi ons dienste gemiddeld elke 1,5 dae, groepeer hulle, want hulle gaan na goedkeuring in werking.
Daar is geen noodlottige ongelukke in ons stelsel nie. As ons 'n mikrodiens met 'n fout vrystel, sal die funksionaliteit wat daarmee geassosieer word, gebreek word, en alle ander funksionaliteit sal nie geraak word nie. Dit verbeter die gebruikerservaring aansienlik.
Ons kan die ontplooiingskema beheer. Jy kan groepe dienste afsonderlik van die res van die oplossing skei, indien nodig.
Daarbenewens het ons die probleem aansienlik verminder met 'n groot ry van verbeterings. Ons het aparte produkspanne wat onafhanklik met sommige van die dienste werk. Dit is waar die Scrum-proses handig te pas kom. 'n Spesifieke span kan 'n aparte produkeienaar hê wat take daaraan toewys.
Opsomming
- Mikrodienste is goed geskik vir die ontbinding van komplekse stelsels. In die proses begin ons verstaan wat in ons sisteem is, wat die beperkte kontekste is, waar is hul grense. Dit laat jou toe om verbeterings behoorlik aan modules te versprei en kodeverduistering te voorkom.
- Mikrodienste bied organisatoriese voordele. Daar word dikwels net na hulle verwys as argitektuur, maar enige argitektuur is nodig om besigheidsbehoeftes op te los, en nie op sigself nie. Daarom kan ons sê dat mikrodienste goed geskik is om probleme in klein spanne op te los, aangesien Scrum tans baie gewild is.
- Skeiding is 'n iteratiewe proses. Jy kan nie 'n toepassing neem en dit net in mikrodienste verdeel nie. Dit is onwaarskynlik dat die resulterende produk werkbaar sal wees. Wanneer mikrodienste uitgelig word, is dit voordelig om die bestaande nalatenskap te herskryf, dit wil sê om dit te omskep in kode waarvan ons hou en beter voldoen aan die behoeftes van die besigheid in terme van funksionaliteit en spoed.
Klein waarskuwing: Die koste om na mikrodienste te migreer is redelik aansienlik. Dit het lank geneem om die probleem van infrastruktuur op te los. As u dus 'n klein toepassing het wat nie spesifieke skaal benodig nie, as daar nie 'n groot aantal kliënte is wat veg vir die aandag en tyd van u span nie, dan is mikrodienste miskien nie wat u vandag nodig het nie. Dis nogal duur. As jy die proses met mikrodienste begin, dan sal die koste aanvanklik meer wees as wanneer dieselfde projek met die ontwikkeling van 'n monoliet begin.
NS 'n Meer emosionele storie (en asof aan jou persoonlik) - deur .
Hier is die volledige weergawe van die verslag.
Bron: will.com
