


SRE (Site Reliability Engineering) is 'n benadering om die beskikbaarheid van webprojekte te verseker. Dit word beskou as 'n raamwerk vir DevOps en praat oor hoe om sukses te behaal in die toepassing van DevOps-praktyke. Vertaling in hierdie artikel boeke van Google. Ek het hierdie vertaling self voorberei en op my eie ervaring staatgemaak om moniteringsprosesse te verstaan. In die telegramkanaal и Ek het ook 'n vertaling van Hoofstuk 6 van dieselfde boek oor diensvlakdoelwitte gepubliseer.
Vertaling deur kat. Lekker lees!
Dit is onmoontlik om 'n diens te bestuur as daar geen begrip is van watter aanwysers werklik saak maak en hoe om dit te meet en te evalueer nie. Vir hierdie doel definieer en verskaf ons 'n sekere vlak van diens aan ons gebruikers, ongeag of hulle een van ons interne API's of 'n publieke produk gebruik.
Ons gebruik ons intuïsie, ervaring en begrip van gebruikers se begeerte om diensvlakaanwysers (SLI's), diensvlakdoelwitte (SLO's) en diensvlakooreenkomste (SLA's) te verstaan. Hierdie dimensies beskryf die belangrikste maatstawwe wat ons wil monitor en waarop ons sal reageer as ons nie die verwagte gehalte van diens kan lewer nie. Uiteindelik help die keuse van die regte maatstawwe om die regte aksies te lei as iets verkeerd loop, en gee ook die SRE-span vertroue in die gesondheid van die diens.
Hierdie hoofstuk beskryf die benadering wat ons gebruik om die probleme van metrieke modellering, metriese seleksie en metrieke analise te bestry. Die meeste van die verduidelikings sal sonder voorbeelde wees, so ons sal die Shakespeare-diens wat in die implementeringsvoorbeeld beskryf word (soek na Shakespeare se werke) gebruik om die hoofpunte te illustreer.
Diensvlakterminologie
Baie lesers is waarskynlik vertroud met die konsep van SLA, maar die terme SLI en SLO verdien noukeurige definisie, want in die algemeen is die term SLA oorlaai en het 'n aantal betekenisse afhangende van die konteks. Vir duidelikheid wil ons hierdie waardes skei.
Aanwysers
Die SLI is 'n diensvlak-aanwyser - 'n noukeurig gedefinieerde kwantitatiewe maatstaf van een aspek van die vlak van diens wat gelewer word.
Vir die meeste dienste word die sleutel-SLI beskou as versoekvertraging - hoe lank dit neem om 'n antwoord op 'n versoek terug te gee. Ander algemene SLI's sluit in foutkoers, dikwels uitgedruk as 'n fraksie van alle versoeke wat ontvang word, en stelseldeurset, gewoonlik gemeet in versoeke per sekonde. Metings word dikwels saamgevoeg: rou data word eers ingesamel en dan omgeskakel in 'n tempo van verandering, gemiddelde of persentiel.
Ideaal gesproke meet SLI die diensvlak van belang direk, maar soms is slegs 'n verwante maatstaf beskikbaar vir meting omdat die oorspronklike een moeilik is om te verkry of te interpreteer. Byvoorbeeld, kliënt-kant latency is dikwels 'n meer gepaste maatstaf, maar daar is tye wanneer latency slegs op die bediener gemeet kan word.
Nog 'n tipe SLI wat vir SRE's belangrik is, is beskikbaarheid, of die gedeelte van die tyd waartydens 'n diens gebruik kan word. Dikwels gedefinieer as die koers van suksesvolle versoeke, soms genoem opbrengs. (Leeftyd - die waarskynlikheid dat data vir 'n lang tydperk behou sal word - is ook belangrik vir databergingstelsels.) Alhoewel 100% beskikbaarheid nie moontlik is nie, is beskikbaarheid naby aan 100% dikwels haalbaar beskikbaarheidswaardes uitgedruk as; die aantal "nege" » persentasie van beskikbaarheid. Byvoorbeeld, 99% en 99,999% beskikbaarheid kan gemerk word as "2 nege" en "5 nege". Google Compute Engine se huidige verklaarde beskikbaarheidsdoelwit is "drie en 'n half nege" of 99,95%.
Doelwitte
'n SLO is 'n diensvlakdoelwit: 'n teikenwaarde of reeks waardes vir 'n diensvlak wat deur die SLI gemeet word. 'n Normale waarde vir SLO is “SLI ≤ Target” of “Lawer Limit ≤ SLI ≤ Upper Limit”. Byvoorbeeld, ons kan besluit dat ons Shakespeare-soekresultate "vinnig" sal gee deur die SLO op 'n gemiddelde soektogvertraging van minder as 100 millisekondes te stel.
Die keuse van die regte SLO is 'n komplekse proses. Eerstens kan jy nie altyd 'n spesifieke waarde kies nie. Vir eksterne inkomende HTTP-versoeke na jou diens, word die Query Per Second (QPS) metriek hoofsaaklik bepaal deur jou gebruikers se begeerte om jou diens te besoek, en jy kan nie 'n SLO hiervoor stel nie.
Aan die ander kant kan jy sê dat jy wil hê dat die gemiddelde latensie vir elke versoek minder as 100 millisekondes moet wees. Om so 'n doelwit te stel, kan jou dwing om jou frontend met lae latency te skryf of toerusting te koop wat sulke latency verskaf. (100 millisekondes is natuurlik 'n arbitrêre getal, maar dit is beter om selfs laer latensiegetalle te hê. Daar is bewyse wat daarop dui dat vinnige spoed beter is as stadige spoed, en dat vertraging in die verwerking van gebruikersversoeke bo sekere waardes mense eintlik dwing om weg te bly van jou diens.)
Weereens, dit is meer dubbelsinnig as wat dit met die eerste oogopslag mag lyk: jy moet QPS nie heeltemal van die berekening uitsluit nie. Die feit is dat QPS en latency sterk met mekaar verband hou: hoër QPS lei dikwels tot hoër latensies, en dienste ervaar gewoonlik 'n skerp afname in werkverrigting wanneer hulle 'n sekere lasdrempel bereik.
Die keuse en publisering van 'n SLO stel gebruikersverwagtings oor hoe die diens sal werk. Hierdie strategie kan ongegronde klagtes teen die dienseienaar verminder, soos stadige werkverrigting. Sonder 'n eksplisiete SLO skep gebruikers dikwels hul eie verwagtinge oor gewenste prestasie, wat dalk niks te doen het met die menings van die mense wat die diens ontwerp en bestuur nie. Hierdie situasie kan lei tot opgeblase verwagtinge van die diens, wanneer gebruikers verkeerdelik glo dat die diens meer toeganklik sal wees as wat dit werklik is, en wantroue veroorsaak wanneer gebruikers glo dat die stelsel minder betroubaar is as wat dit werklik is.
Ooreenkomste
'n Diensvlakooreenkoms is 'n eksplisiete of implisiete kontrak met jou gebruikers wat die gevolge insluit om die SLO's wat hulle bevat te ontmoet (of nie te ontmoet nie). Gevolge word die maklikste herken wanneer dit finansieel is - 'n afslag of 'n boete - maar dit kan ander vorme aanneem. 'n Maklike manier om oor die verskil tussen SLO's en SLA's te praat, is om te vra "wat gebeur as die SLO's nie nagekom word nie?" As daar geen duidelike gevolge is nie, kyk jy byna seker na 'n SLO.
Die SRE is gewoonlik nie betrokke by die skep van SLA's nie, want SLA's is nou gekoppel aan besigheids- en produkbesluite. Die SRE is egter betrokke om te help om die gevolge van mislukte SLO's te versag. Hulle kan ook help om die SLI te bepaal: Uiteraard moet daar 'n objektiewe manier wees om die SLO in die ooreenkoms te meet of daar sal onenigheid wees.
Google Search is 'n voorbeeld van 'n belangrike diens wat nie 'n publieke SLA het nie: ons wil hê almal moet Search so doeltreffend moontlik gebruik, maar ons het nie 'n kontrak met die wêreld onderteken nie. Daar is egter steeds gevolge as soektog nie beskikbaar is nie - onbeskikbaarheid lei tot 'n daling in ons reputasie sowel as verminderde advertensie-inkomste. Baie ander Google-dienste, soos Google for Work, het eksplisiete diensvlakooreenkomste met gebruikers. Ongeag of 'n spesifieke diens 'n SLA het, is dit belangrik om die SLI en SLO te definieer en dit te gebruik om die diens te bestuur.
Soveel teorie – nou om te ervaar.
Aanwysers in die praktyk
Gegewe dat ons tot die gevolgtrekking gekom het dat dit belangrik is om toepaslike maatstawwe te kies om diensvlak te meet, hoe weet jy nou watter maatstawwe saak maak vir ’n diens of stelsel?
Waaroor gee jy en jou gebruikers om?
Jy hoef nie elke metrieke as 'n SLI te gebruik wat jy in 'n moniteringstelsel kan opspoor nie; Om te verstaan wat gebruikers van 'n stelsel wil hê, sal jou help om verskeie maatstawwe te kies. Die keuse van te veel aanwysers maak dit moeilik om op belangrike aanwysers te fokus, terwyl die keuse van 'n klein aantal groot stukke van jou stelsel onbewaak kan laat. Ons gebruik gewoonlik verskeie sleutelaanwysers om die gesondheid van 'n stelsel te evalueer en te verstaan.
Dienste kan oor die algemeen in verskeie dele opgedeel word in terme van SLI wat vir hulle relevant is:
- Pasgemaakte voorkantstelsels, soos die soekkoppelvlakke vir die Shakespeare-diens uit ons voorbeeld. Hulle moet beskikbaar wees, geen vertragings hê nie en voldoende bandwydte hê. Gevolglik kan vrae gevra word: kan ons op die versoek reageer? Hoe lank het dit geneem om op die versoek te reageer? Hoeveel versoeke kan verwerk word?
- Bergingstelsels. Hulle waardeer lae reaksievertraging, beskikbaarheid en duursaamheid. Verwante vrae: Hoe lank neem dit om data te lees of te skryf? Kan ons op versoek toegang tot die data kry? Is die data beskikbaar wanneer ons dit nodig het? Sien Hoofstuk 26 Data-integriteit: Wat jy lees is wat jy skryf vir 'n gedetailleerde bespreking van hierdie kwessies.
- Grootdatastelsels soos dataverwerkingspyplyne maak staat op deurset en navraagverwerkingslatens. Verwante vrae: Hoeveel data word verwerk? Hoe lank neem dit vir data om te reis vanaf die ontvangs van 'n versoek tot die uitreiking van 'n antwoord? (Sommige dele van die stelsel kan ook in sekere stadiums vertragings hê.)
Versameling van aanwysers
Baie diensvlakaanwysers word natuurlik op die bedienerkant ingesamel, met behulp van 'n moniteringstelsel soos Borgmon (sien hieronder). ) of Prometheus, of bloot die logboeke periodiek te ontleed, HTTP-reaksies met status 500 te identifiseer. Sommige stelsels moet egter toegerus wees met kliënt-kant-metriekversameling, aangesien die gebrek aan kliënt-kant monitering kan lei tot die mis van 'n aantal probleme wat 'n invloed het gebruikers, maar beïnvloed nie bediener-kant-metrieke nie. Byvoorbeeld, om te fokus op die vertraging van die backend-reaksie van ons Shakespeare-soektogtoetstoepassing, kan latensie aan die gebruikerkant veroorsaak as gevolg van JavaScript-kwessies: in hierdie geval is dit 'n beter maatstaf om te meet hoe lank dit die blaaier neem om die bladsy te verwerk.
Aggregasie
Vir eenvoud en gemak van gebruik, versamel ons dikwels rou mates. Dit moet versigtig gedoen word.
Sommige statistieke lyk eenvoudig, soos versoeke per sekonde, maar selfs hierdie oënskynlik eenvoudige meting versamel implisiet data oor tyd. Word die meting spesifiek een keer per sekonde ontvang of is die meting gemiddeld oor die aantal versoeke per minuut? Laasgenoemde opsie kan 'n baie hoër onmiddellike aantal versoeke versteek wat net 'n paar sekondes duur. Oorweeg 'n stelsel wat 200 versoeke per sekonde bedien met ewe getalle en 0 die res van die tyd. 'n Konstante in die vorm van 'n gemiddelde waarde van 100 versoeke per sekonde en twee keer die oombliklike lading is nie dieselfde ding nie. Net so kan die gemiddelde navraagvertragings aantreklik lyk, maar dit verberg 'n belangrike detail: dit is moontlik dat die meeste navrae vinnig sal wees, maar daar sal baie navrae wees wat stadig is.
Die meeste aanwysers word beter beskou as verdelings eerder as gemiddeldes. Byvoorbeeld, vir SLI latency, sal sommige versoeke vinnig verwerk word, terwyl sommige altyd langer sal neem, soms baie langer. 'n Eenvoudige gemiddelde kan hierdie lang vertragings verberg. Die figuur toon 'n voorbeeld: alhoewel 'n tipiese versoek ongeveer 50 ms neem om te bedien, is 5% van versoeke 20 keer stadiger! Monitering en waarskuwing wat slegs op gemiddelde latensie gebaseer is, wys nie veranderinge in gedrag deur die loop van die dag nie, terwyl daar in werklikheid merkbare veranderinge in die verwerkingstyd van sommige versoeke is (boonste lyn).
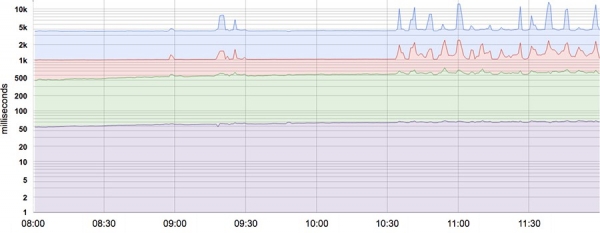
50, 85, 95 en 99 persentiel stelsel latency. Die Y-as is in logaritmiese formaat.
Deur persentiele vir aanwysers te gebruik, laat jou toe om die vorm van die verspreiding en sy kenmerke te sien: 'n hoë persentielvlak, soos 99 of 99,9, toon die swakste waarde, terwyl die 50 persentiel (ook bekend as die mediaan) die mees algemene toestand van die metrieke. Hoe groter die reaksietydverspreiding, hoe meer langdurige versoeke beïnvloed die gebruikerservaring. Die effek word versterk onder hoë las en in die teenwoordigheid van toue. Gebruikerservaring-navorsing het getoon dat mense oor die algemeen 'n stadiger stelsel met 'n hoë reaksietyd-afwyking verkies, so sommige SRE-spanne fokus slegs op hoë persentieltellings, op die basis dat as 'n maatstaf se gedrag by die 99,9 persentiel goed is, die meeste gebruikers nie probleme sal ervaar nie. .
Nota oor statistiese foute
Ons verkies gewoonlik om met persentiele te werk eerder as die gemiddelde (rekenkundige gemiddelde) van 'n stel waardes. Dit stel ons in staat om meer verspreide waardes te oorweeg, wat dikwels aansienlik verskillende (en meer interessante) eienskappe as die gemiddelde het. As gevolg van die kunsmatige aard van rekenaarstelsels, is metrieke waardes dikwels skeef, sodanig dat geen versoek 'n antwoord in minder as 0 ms kan ontvang nie, en 'n time-out van 1000 ms beteken dat daar nie suksesvolle antwoorde met waardes groter as die tydsduur. Gevolglik kan ons nie aanvaar dat die gemiddelde en mediaan dieselfde of naby aan mekaar kan wees nie!
Sonder voorafgaande toetsing, en tensy sekere standaard aannames en benaderings geld, is ons versigtig om nie tot die gevolgtrekking te kom dat ons data normaal versprei is nie. As die verspreiding nie soos verwag is nie, kan die outomatiseringsproses wat die probleem regstel (byvoorbeeld, wanneer dit uitskieters sien, dit die bediener herbegin met hoë versoekverwerkingsvertragings) dit dalk te dikwels of nie gereeld genoeg doen nie (albei nie baie goed).
Standaardiseer aanwysers
Ons beveel aan om die algemene kenmerke vir SLI te standaardiseer sodat jy nie elke keer daaroor hoef te spekuleer nie. Enige kenmerk wat aan standaardpatrone voldoen, kan uitgesluit word van die spesifikasie van 'n individuele SLI, byvoorbeeld:
- Aggregasie-intervalle: "gemiddeld oor 1 minuut"
- Samevoegingsgebiede: "Alle take in die groepering"
- Hoe gereeld metings geneem word: "Elke 10 sekondes"
- Watter versoeke is ingesluit: "HTTP GET from black box monitoring jobs"
- Hoe die data verkry word: "Danksy ons monitering gemeet op die bediener"
- Datatoegang latency: "Tyd tot laaste greep"
Om moeite te bespaar, skep 'n stel herbruikbare SLI-sjablone vir elke algemene maatstaf; hulle maak dit ook makliker vir almal om te verstaan wat 'n sekere SLI beteken.
Doelwitte in die praktyk
Begin deur te dink oor (of uit te vind!) waaroor jou gebruikers omgee, nie wat jy kan meet nie. Dit is dikwels moeilik of onmoontlik om te meet waarvoor jou gebruikers omgee, so jy kom uiteindelik nader aan hul behoeftes. As jy egter net begin met wat maklik is om te meet, sal jy met minder nuttige SLO's eindig. Gevolglik het ons soms gevind dat om aanvanklik gewenste doelwitte te identifiseer en dan met spesifieke aanwysers te werk, beter werk as om aanwysers te kies en dan die doelwitte te bereik.
Definieer jou doelwitte
Vir maksimum duidelikheid, moet dit gedefinieer word hoe SLO's gemeet word en die voorwaardes waaronder hulle geldig is. Ons kan byvoorbeeld die volgende sê (die tweede reël is dieselfde as die eerste, maar gebruik die SLI-standaarde):
- 99% (gemiddeld oor 1 minuut) van Get RPC-oproepe sal binne minder as 100 ms voltooi (gemeet oor alle backend-bedieners).
- 99% van Get RPC-oproepe sal in minder as 100 ms voltooi word.
As die vorm van die prestasiekrommes belangrik is, kan jy verskeie SLO's spesifiseer:
- 90% van Kry RPC-oproepe wat in minder as 1 ms voltooi is.
- 99% van Kry RPC-oproepe wat in minder as 10 ms voltooi is.
- 99.9% Kry RPC-oproepe in minder as 100 ms voltooi.
As jou gebruikers heterogene werkladings genereer: grootmaatverwerking (waarvoor deurvloei belangrik is) en interaktiewe verwerking (waarvoor latensie belangrik is), kan dit die moeite werd wees om afsonderlike doelwitte vir elke vragklas te definieer:
- 95% van kliënteversoeke vereis deurset. Stel die telling van RPC-oproepe wat uitgevoer is <1 s.
- 99% van kliënte gee om oor die vertraging. Stel die telling van RPC-oproepe met verkeer <1 KB en loop <10 ms.
Dit is onrealisties en onwenslik om aan te dring dat SLO's 100% van die tyd nagekom sal word: dit kan die pas van die bekendstelling van nuwe funksionaliteit en ontplooiing verminder en duur oplossings vereis. In plaas daarvan is dit beter om 'n foutbegroting toe te laat - die persentasie stelselstilstand wat toegelaat word - en hierdie waarde daagliks of weekliks te monitor. Senior bestuur wil dalk maandelikse of kwartaallikse evaluasies hê. (Die foutbegroting is bloot 'n SLO vir vergelyking met 'n ander SLO.)
Die persentasie SLO-oortredings kan vergelyk word met die foutbegroting (sien Hoofstuk 3 en afdeling ), met die verskilwaarde wat gebruik word as insette tot die proses wat besluit wanneer om nuwe vrystellings te ontplooi.
Kies teikenwaardes
Die keuse van beplanningswaardes (SLO's) is nie 'n suiwer tegniese aktiwiteit nie as gevolg van die produk- en besigheidsbelange wat in die geselekteerde SLI's, SLO's (en moontlik SLA's) weerspieël moet word. Net so kan inligting uitgeruil moet word oor kwessies wat verband hou met personeel, tyd tot mark, beskikbaarheid van toerusting en finansiering. SRE moet deel wees van hierdie gesprek en help om die risiko's en lewensvatbaarheid van verskillende opsies te verstaan. Ons het met 'n paar vrae vorendag gekom wat kan help om 'n meer produktiewe bespreking te verseker:
Moenie 'n doelwit op grond van huidige prestasie kies nie.
Alhoewel dit belangrik is om die sterkpunte en grense van 'n stelsel te verstaan, kan die aanpassing van maatstawwe sonder redenasie jou verhoed om die stelsel in stand te hou: dit sal heldhaftige pogings verg om doelwitte te bereik wat nie bereik kan word sonder beduidende herontwerp nie.
Hou dit eenvoudig
Komplekse SLI-berekeninge kan veranderinge in stelselwerkverrigting versteek en dit moeiliker maak om die oorsaak van die probleem te vind.
Vermy absolutes
Alhoewel dit aanloklik is om 'n stelsel te hê wat 'n onbepaalde groeiende vrag kan hanteer sonder om latensie te verhoog, is hierdie vereiste onrealisties. 'n Stelsel wat sulke ideale benader, sal waarskynlik baie tyd verg om te ontwerp en te bou, sal duur wees om te bedryf, en sal te goed wees vir die verwagtinge van gebruikers wat met enigiets minder sou doen.
Gebruik so min SLO's as moontlik
Kies 'n voldoende aantal SLO's om goeie dekking van stelselkenmerke te verseker. Beskerm die SLO's wat jy kies: As jy nooit 'n argument oor prioriteite kan wen deur 'n spesifieke SLO te spesifiseer nie, is dit waarskynlik nie die moeite werd om daardie SLO te oorweeg nie. Nie alle stelselkenmerke is egter vatbaar vir SLO's nie: dit is moeilik om die vlak van gebruikersgenot met SLO's te bereken.
Moenie perfeksie najaag nie
Jy kan altyd die definisies en doelwitte van SLO's mettertyd verfyn soos jy meer leer oor die stelsel se gedrag onder las. Dit is beter om te begin met 'n drywende doelwit wat jy mettertyd sal verfyn as om 'n te streng doelwit te kies wat verslap moet word wanneer jy vind dat dit onbereikbaar is.
SLO's kan en moet 'n sleutelaandrywer wees in die prioritisering van werk vir SRE's en produkontwikkelaars omdat dit 'n besorgdheid vir gebruikers weerspieël. 'n Goeie SLO is 'n nuttige toepassingsinstrument vir 'n ontwikkelingspan. Maar 'n swak ontwerpte SLO kan lei tot verkwistende werk as die span heldhaftige pogings aanwend om 'n te aggressiewe SLO te bereik, of 'n swak produk as die SLO te laag is. SLO is 'n kragtige hefboom, gebruik dit verstandig.
Beheer jou metings
SLI en SLO is sleutelelemente wat gebruik word om stelsels te bestuur:
- Monitor en meet SLI-stelsels.
- Vergelyk SLI met SLO en besluit of aksie nodig is.
- As aksie vereis word, bepaal wat moet gebeur om die doel te bereik.
- Voltooi hierdie aksie.
Byvoorbeeld, as stap 2 wys dat die versoek uittel en die SLO binne 'n paar uur sal breek as niks gedoen word nie, kan stap 3 behels dat die hipotese getoets word dat die bedieners SVE-gebonde is en dat die byvoeging van meer bedieners die las sal versprei. Sonder 'n SLO sou jy nie weet of (of wanneer) om op te tree nie.
Stel SLO - dan sal gebruikersverwagtinge gestel word
Die publikasie van 'n SLO stel gebruikersverwagtinge vir stelselgedrag. Gebruikers (en potensiële gebruikers) wil dikwels weet wat om van 'n diens te verwag om te verstaan of dit geskik is vir gebruik. Byvoorbeeld, mense wat 'n foto-deelwebwerf wil gebruik, wil dalk vermy om 'n diens te gebruik wat lang lewe en lae koste beloof in ruil vir effens minder beskikbaarheid, al is dieselfde diens dalk ideaal vir 'n argiefrekordbestuurstelsel.
Gebruik een of albei van die volgende taktieke om realistiese verwagtinge vir jou gebruikers te stel:
- Handhaaf 'n veiligheidsmarge. Gebruik 'n strenger interne SLO as wat aan gebruikers geadverteer word. Dit sal jou die geleentheid gee om op probleme te reageer voordat dit ekstern sigbaar word. Die SLO-buffer laat jou ook toe om 'n veiligheidsmarge te hê wanneer vrystellings geïnstalleer word wat stelselwerkverrigting beïnvloed en verseker dat die stelsel maklik is om in stand te hou sonder om gebruikers met stilstand te frustreer.
- Moenie gebruikersverwagtinge oorskry nie. Gebruikers is gebaseer op wat jy aanbied, nie wat jy sê nie. As die werklike prestasie van jou diens baie beter is as die genoemde SLO, sal gebruikers staatmaak op die huidige prestasie. U kan oorafhanklikheid vermy deur die stelsel doelbewus af te skakel of werkverrigting onder ligte vragte te beperk.
Om te verstaan hoe goed 'n stelsel aan verwagtinge voldoen, help om te besluit of om te belê om die stelsel te bespoedig en dit meer toeganklik en veerkragtig te maak. Alternatiewelik, as 'n diens te goed presteer, moet sekere personeeltyd aan ander prioriteite bestee word, soos om tegniese skuld af te betaal, nuwe kenmerke by te voeg of nuwe produkte bekend te stel.
Ooreenkomste in die praktyk
Die skep van 'n SLA vereis dat sake- en regspanne die gevolge en strawwe vir die oortreding daarvan moet definieer. Die SRE se rol is om hulle te help om die waarskynlike uitdagings te verstaan om die SLO's wat in die SLA vervat is, te ontmoet. Die meeste van die aanbevelings vir die skep van SLO's is ook van toepassing op SLA's. Dit is wys om konserwatief te wees in wat jy gebruikers belowe, want hoe meer jy het, hoe moeiliker is dit om SLA's te verander of te verwyder wat onredelik of moeilik lyk om na te kom.
Dankie dat jy die vertaling tot die einde gelees het. Teken in op my telegramkanaal oor monitering и .
Bron: will.com
