


إنه يؤلم فقط في المرة الأولى!
أهلاً بكم! أصدقائي الأعزاء، في هذه المقالة أريد أن أشارككم تجربتي في استخدام TensorRT وRetinaNet استنادًا إلى المستودع (هذا هو فرع من المستودع الرسمي من (الذي سيسمح لك بالبدء في استخدام النماذج المحسنة في الإنتاج في أقصر وقت ممكن). التمرير عبر الرسائل في قنوات المجتمع ، أواجه أسئلة حول استخدام TensorRT، وغالبًا ما تكون الأسئلة متكررة، لذا قررت الكتابة كاملة قدر الإمكان دليل لاستخدام الاستدلال السريع استنادًا إلى TensorRT وRetinaNet وUnet وdocker.
وصف المهمة
أقترح صياغة المهمة على النحو التالي: نحتاج إلى تصنيف مجموعة البيانات، وتدريب شبكة RetinaNet/Unet على Pytorch 1.3+، وتحويل الأوزان المُستخرجة إلى ONNX، ثم تحويلها إلى محرك TensorRT، وتشغيل كل ذلك في Docker، ويفضل أن يكون ذلك على Ubuntu يُعدّ هذا النظام مثاليًا لبنية ARM (Jetson)*، مما يقلل من الحاجة إلى النشر اليدوي للبيئة. ستكون النتيجة النهائية حاوية جاهزة ليس فقط لتصدير وتدريب RetinaNet/Unet، بل أيضًا لتطوير وتدريب أنظمة التصنيف والتجزئة بشكل كامل، مع توفير جميع الأجهزة اللازمة.
الخطوة 1. إعداد البيئة
من المهم أن نلاحظ هنا أنني مؤخرًا ابتعدت تمامًا عن استخدام ونشر أي مكتبات على جهاز سطح المكتب، وكذلك على devbox. الشيء الوحيد الذي عليك إنشاؤه وتثبيته هو بيئة Python الافتراضية وCuda 10.2 (يمكنك تقييد نفسك ببرنامج تشغيل NVIDIA واحد) من Deb.
لنفترض أن لديك جهازًا مثبتًا حديثًا Ubuntu 18. لنقم بتثبيت CUDA 10.2 (deb). لن أتطرق إلى تفاصيل عملية التثبيت، فالوثائق الرسمية كافية تمامًا.
الآن دعنا نقوم بتثبيت Docker، يمكن العثور على دليل تثبيت Docker بسهولة، فيما يلي مثال الإصدار 19+ متاح بالفعل - فلنقم بتثبيته. ولا تنسَ أن تجعل من الممكن استخدام Docker بدون sudo، فسيكون ذلك أكثر ملاءمة. بعد أن نجح كل شيء، نفعل ذلك على النحو التالي:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
ولا تحتاج حتى إلى البحث في المستودع الرسمي .
الآن نقوم باستنساخ git .
لم يتبق سوى القليل لبدء استخدام Docker مع صورة nvidia، سنحتاج إلى التسجيل في NGC Cloud وتسجيل الدخول. لننتقل إلى هنا ، قم بالتسجيل وبعد أن ندخل إلى NGC Cloud، انقر فوق SETUP في الزاوية العلوية اليسرى من الشاشة أو اتبع هذا الرابط . انقر فوق "إنشاء مفتاح". أنصحك بحفظه وإلا في زيارتك القادمة سيكون عليك إنشاءه مرة أخرى، وبناءً عليه عند نشره على سيارة جديدة، كرر هذه العملية.
دعنا نفعل:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
نحن ببساطة نقوم بنسخ اسم المستخدم. حسنًا، فكر في البيئة الموسعة!
الخطوة 2: بناء حاوية Docker
في المرحلة الثانية من عملنا، سنقوم ببناء Docker والتعرف على مكوناته الداخلية.
دعنا ننتقل إلى المجلد الجذر المتعلق بمشروع retina-examples ونقوم بتشغيله
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
نقوم ببناء Docker عن طريق تمرير المستخدم الحالي إليه - وهذا مفيد جدًا إذا كنت ستكتب شيئًا إلى VOLUME المثبت بحقوق المستخدم الحالي، وإلا فسيكون ذلك جذرًا وألمًا.
أثناء بناء Docker، دعنا نفحص ملف Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
كما ترون من النص، فقد جمعنا جميع مكتباتنا المفضلة، وقمنا بتجميع مكتبة retinanet، وأضفنا بعض الأدوات الأساسية لتسهيل العمل معها. Ubuntu ثم قم بتهيئة خادم OpenSSH. يرث السطر الأول صورة NVIDIA التي أنشأنا عليها تسجيل دخول NGC Cloud، والتي تحتوي على Pytorch 1.3 وTensorRT 6.xxx ومجموعة من المكتبات الأخرى التي تسمح لنا بتجميع كود CPP المصدري لكاشفنا.
الخطوة 3: تشغيل حاوية Docker واستكشاف أخطائها وإصلاحها
دعنا ننتقل إلى حالة الاستخدام الرئيسية للحاوية وبيئة التطوير، أولاً سنقوم بتشغيل nvidia docker. دعونا نفعل ذلك:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestالحاوية متاحة الآن عبر ssh @localhost. بعد الإطلاق الناجح، افتح المشروع في PyCharm. بعد ذلك نفتح
Settings->Project Interpreter->Add->Ssh Interpreter الخطوة 1
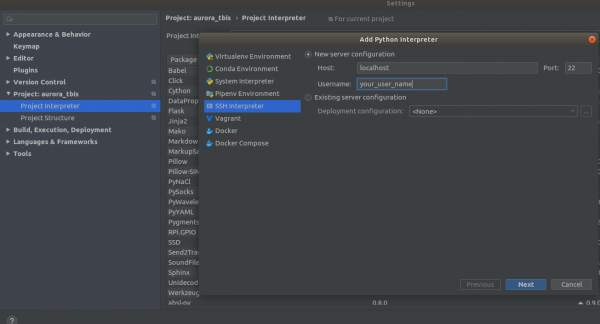
الخطوة 2
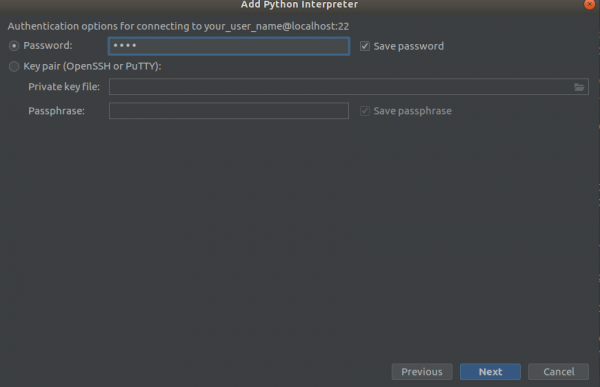
الخطوة 3
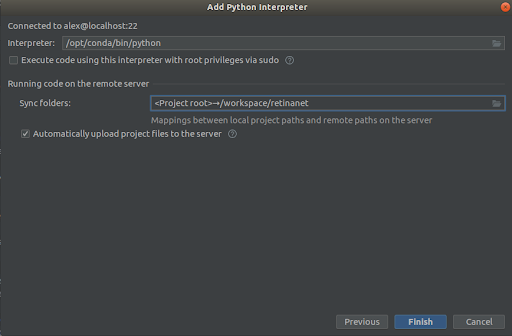
نختار كل شيء كما في لقطات الشاشة،
Interpreter -> /opt/conda/bin/python- سيتم تشغيله على Python3.6 و
Sync folder -> /workspace/retinanetانقر فوق "إنهاء"، وانتظر الفهرسة، وهذا كل شيء، البيئة جاهزة للاستخدام!
هام !!! بعد الفهرسة مباشرة، قم بسحب الملفات المترجمة لـ Retinanet من docker. في قائمة السياق الموجودة في جذر المشروع، حدد العنصر
Deployment->Downloadسيظهر ملف واحد ومجلدان: build وretinanet.egg-info و_С.so
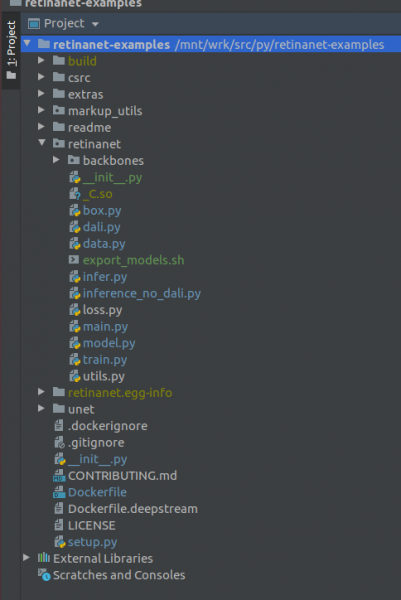
إذا كان مشروعك يبدو بهذا الشكل، فسترى البيئة جميع الملفات الضرورية ونحن مستعدون لتدريب RetinaNet.
الخطوة 4. قم بتسمية البيانات وتدريب الكاشف
للتمييز أستخدم بشكل أساسي - أداة لطيفة ومريحة، وقد تم إصلاح مجموعة من الأخطاء مؤخرًا وبدأت تتصرف بشكل أفضل كثيرًا.
لنفترض أنك قمت بوضع علامة على مجموعة البيانات وتنزيلها، ولكنك لن تتمكن من وضعها على الفور في RetinaNet، نظرًا لأنها بتنسيقها الخاص ولهذا نحتاج إلى تحويلها إلى COCO. توجد أداة التحويل في:
markup_utils/supervisly_to_coco.pyيرجى ملاحظة أن الفئة الموجودة في البرنامج النصي هي مثال ويجب عليك إدراج مثال خاص بك (لا يلزم إضافة فئة الخلفية)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] قرر مؤلفو المستودع الأصلي لسبب ما أنك لن تدرب أي شيء آخر غير COCO/VOC للكشف، لذا كان عليّ تعديل ملف المصدر قليلاً
retinanet/dataset.pyأضف هنا الإضافات المفضلة لديك وقطع الفئات الثابتة من COCO. هناك أيضًا إمكانية اقتصاص مناطق اكتشاف كبيرة إذا كنت تبحث عن كائنات صغيرة في صور كبيرة، لديك مجموعة بيانات صغيرة =)، ولا شيء يعمل، ولكن المزيد حول هذا في وقت آخر.
بشكل عام، حلقة القطار ضعيفة أيضًا، في البداية لم تحفظ نقاط التفتيش، واستخدمت بعض جداول العمل الرهيبة، وما إلى ذلك. ولكن الآن كل ما عليك فعله هو تحديد العمود الفقري وتنفيذه
/opt/conda/bin/python retinanet/main.pyمع المعلمات:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
في وحدة التحكم سوف ترى:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148لدراسة المجموعة الكاملة من المعلمات، انظر
retinanet/main.pyبشكل عام، فهي معايير للكشف، ولها وصف. ابدأ التدريب وانتظر النتائج. يمكن رؤية مثال للاستدلال في:
retinanet/infer_example.pyأو قم بتشغيل الأمر:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
يحتوي المستودع بالفعل على Focal Loss والعديد من الهياكل الأساسية المضمنة، ومن السهل أيضًا إضافة Focal Loss الخاص بك
retinanet/backbones/*.pyوفي الجدول، يقدم المؤلفون بعض الخصائص:
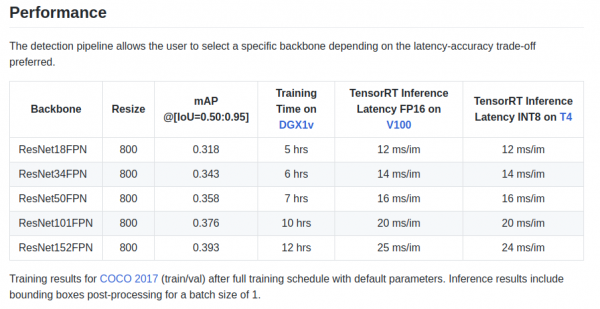
هناك أيضًا العمود الفقري ResNeXt50_32x4dFPN وResNeXt101_32x8dFPN المأخوذ من torchvision.
آمل أن نكون قد تمكنا من حل مشكلة الكشف قليلاً، ولكن الأمر يستحق بالتأكيد قراءة الوثائق الرسمية فهم أوضاع التصدير والتسجيل.
الخطوة 5. تصدير واستنتاج نماذج Unet باستخدام مُرمِّز Resnet
كما لاحظت، قام Dockerfile بتثبيت المكتبات الخاصة بالتجزئة، وخاصة المكتبة الرائعة . في حزمة unet يمكنك العثور على أمثلة لاستنتاج وتصدير نقاط تفتيش pytorch إلى محرك TensorRT.
المشكلة الرئيسية عند تصدير نماذج تشبه Unet من ONNX إلى TensoRT هي الحاجة إلى تعيين حجم Upsample ثابت أو استخدام ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
باستخدام هذا التحويل، يمكنك القيام بذلك تلقائيًا عند التصدير إلى ONNX، ولكن في الإصدار 7 من TensorRT تم حل هذه المشكلة، ولم يتبق لدينا سوى القليل من الوقت للانتظار.
اختتام
عندما بدأت في استخدام Docker، كانت لدي شكوك حول أدائه لمهامي. تحتوي إحدى وحداتي حاليًا على قدر كبير من حركة مرور الشبكة التي يتم إنشاؤها بواسطة العديد من الكاميرات.
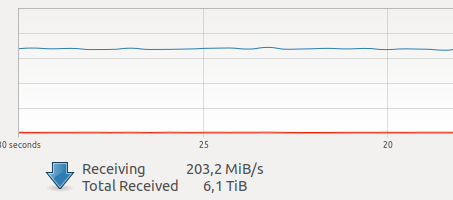
أشارت اختبارات مختلفة على الإنترنت إلى وجود تكلفة إضافية كبيرة نسبيًا للتفاعل مع الشبكة والتسجيل على VOLUME، بالإضافة إلى GIL غير المعروف والمخيف، ونظرًا لأن تصوير إطار، فإن تشغيل السائق ونقل الإطار عبر الشبكة عبارة عن عملية ذرية في الوضع الوقت الحقيقي الصعب، تأخيرات الشبكة مهمة جدًا بالنسبة لي.
ولكن كل شيء أصبح على ما يرام =)
ملاحظة: كل ما تبقى هو إضافة حلقة القطار المفضلة لديك للتجزئة والإنتاج!
الشكر والتقدير
شكرا للمجتمع ، فبدونها لا يمكن التطور! شكرًا جزيلاً ، الذي ألهمني لاتخاذ قرار بشأن DL، لنصيحته الثمينة واحترافيته غير العادية!
استخدم النماذج المُحسّنة في الإنتاج!
 أورورا، ذ.م.م
أورورا، ذ.م.م
المصدر: www.habr.com
