

"Hadoop-da böyük həcmli məlumatların paylanmış işlənməsi üsulları" seriyasından "Hadoop. ZooKeeper" mühazirəsinin stenoqramını oxumağı təklif edirəm.
ZooKeeper nədir, onun Hadoop ekosistemindəki yeri. Paylanmış hesablamalar haqqında yalanlar. Standart paylanmış sistemin diaqramı. Paylanmış sistemləri koordinasiya etməkdə çətinlik. Tipik koordinasiya problemləri. ZooKeeper dizaynının arxasında duran prinsiplər. ZooKeeper məlumat modeli. znode bayraqları. Sessiyalar. Müştəri API. Primitivlər (konfiqurasiya, qrupa üzvlük, sadə kilidlər, lider seçimi, sürü effekti olmadan kilidləmə). ZooKeeper arxitekturası. ZooKeeper DB. ZAB. Sorğu idarəçisi.


Bu gün ZooKeeper haqqında danışacağıq. Bu şey çox faydalıdır. Hər hansı bir Apache Hadoop məhsulu kimi onun da loqosu var. Bir insanı təsvir edir.
Bundan əvvəl biz əsasən məlumatların orada necə emal oluna biləcəyi, onu necə saxlamaq, yəni ondan hansısa şəkildə istifadə etmək və onunla necə işləmək barədə danışdıq. Və bu gün mən paylanmış proqramların qurulması haqqında bir az danışmaq istərdim. ZooKeeper isə bu məsələni sadələşdirməyə imkan verən şeylərdən biridir. Bu, paylanmış sistemlərdə, paylanmış tətbiqlərdə proseslərin qarşılıqlı əlaqəsinin bir növ koordinasiyası üçün nəzərdə tutulmuş bir növ xidmətdir.
Bu cür tətbiqlərə ehtiyac hər gün daha da artmaqdadır, kursumuzun əsas məqsədi budur. Bir tərəfdən, MapReduce və bu hazır çərçivə sizə bu mürəkkəbliyi düzəltməyə və proqramçıya qarşılıqlı əlaqə və proseslərin koordinasiyası kimi primitivləri yazmaqdan azad etməyə imkan verir. Ancaq digər tərəfdən, heç kim zəmanət vermir ki, onsuz da bunu etmək lazım olmayacaq. MapReduce və ya digər hazır çərçivələr həmişə bundan istifadə etməklə həyata keçirilə bilməyən bəzi halları tamamilə əvəz etmir. MapReduce özü və bir sıra digər Apache layihələri də daxil olmaqla, onlar da paylanmış proqramlardır. Və yazmağı asanlaşdırmaq üçün ZooKeeper yazdılar.
Hadoop ilə əlaqəli bütün proqramlar kimi, Yahoo! O, həm də rəsmi Apache tətbiqidir. HBase kimi aktiv şəkildə inkişaf etməmişdir. JIRA HBase-ə gedirsinizsə, onda hər gün bir dəstə səhv hesabatı, nəyisə optimallaşdırmaq üçün bir dəstə təklif var, yəni layihədə həyat daim davam edir. ZooKeeper isə bir tərəfdən nisbətən sadə məhsuldur, digər tərəfdən isə bu onun etibarlılığını təmin edir. İstifadəsi olduqca asandır, buna görə də Hadoop ekosistemindəki tətbiqlərdə standart halına gəldi. Buna görə də onun necə işlədiyini və necə istifadə olunacağını başa düşmək üçün nəzərdən keçirməyin faydalı olacağını düşündüm.
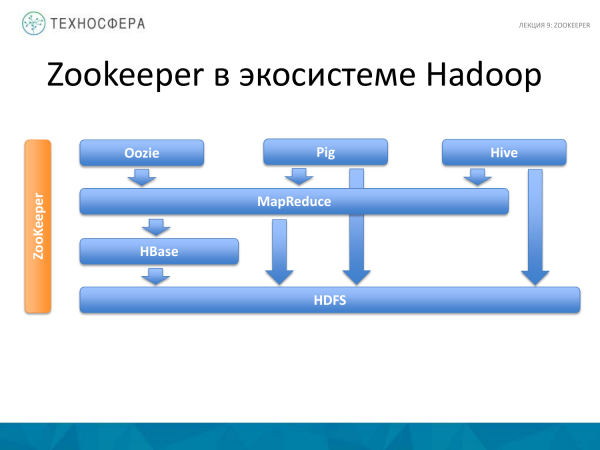
Bu, oxuduğumuz bəzi mühazirədən bir şəkildir. İndiyə qədər nəzərdən keçirdiyimiz hər şeyə ortoqonal olduğunu söyləyə bilərik. Və burada göstərilən hər şey, bu və ya digər dərəcədə, ZooKeeper ilə işləyir, yəni bütün bu məhsullardan istifadə edən bir xidmətdir. Nə HDFS, nə də MapReduce xüsusi olaraq onlar üçün işləyəcək öz oxşar xidmətlərini yazmır. Müvafiq olaraq, ZooKeeper istifadə olunur. Və bu, inkişafı və səhvlərlə əlaqəli bəzi şeyləri asanlaşdırır.

Bütün bunlar haradan gəlir? Görünür ki, biz müxtəlif kompüterlərdə paralel olaraq iki proqramı işə saldıq, onları simli və ya mesh ilə birləşdirdik və hər şey işləyir. Amma problem ondadır ki, Şəbəkə etibarsızdır və əgər siz trafikə baxsanız və ya orada baş verənlərə, müştərilərin Şəbəkədə necə qarşılıqlı əlaqəsinə baxsanız, tez-tez bəzi paketlərin itirildiyini və ya yenidən göndərildiyini görə bilərsiniz. Müəyyən bir sessiya qurmağa və mesajların çatdırılmasına zəmanət verməyə imkan verən TCP protokollarının icad edilməsi boş yerə deyil. Ancaq hər halda, hətta TCP həmişə sizi xilas edə bilməz. Hər şeyin vaxtı var. Şəbəkə sadəcə olaraq bir müddət kəsilə bilər. Sadəcə yanıb-sönə bilər. Və bütün bunlar ona gətirib çıxarır ki, siz Şəbəkənin etibarlı olmasına etibar edə bilməzsiniz. Şəbəkənin olmadığı, yaddaşda daha etibarlı məlumat mübadiləsi avtobusunun olduğu bir kompüterdə və ya bir superkompüterdə işləyən paralel proqramların yazılmasından əsas fərq budur. Və bu əsas fərqdir.
Digər şeylər arasında, Şəbəkədən istifadə edərkən həmişə müəyyən bir gecikmə var. Diskdə də var, lakin Şəbəkədə daha çox şey var. Gecikmə kiçik və ya kifayət qədər əhəmiyyətli ola bilən bəzi gecikmə vaxtıdır.
Şəbəkə topologiyası dəyişir. Topologiya nədir - bu, şəbəkə avadanlıqlarımızın yerləşdirilməsidir. Məlumat mərkəzləri var, orada dayanan rəflər var, şamlar var. Bütün bunlar yenidən birləşdirilə, köçürülə bilər və s. Bütün bunları da nəzərə almaq lazımdır. IP adları dəyişir, trafikimizin keçdiyi marşrut dəyişir. Bunu da nəzərə almaq lazımdır.
Şəbəkə avadanlıq baxımından da dəyişə bilər. Təcrübədən deyə bilərəm ki, şəbəkə mühəndislərimiz həqiqətən şamlarda vaxtaşırı nəyisə yeniləməyi sevirlər. Birdən yeni proqram təminatı çıxdı və onlar bəzi Hadoop klasterləri ilə o qədər də maraqlanmadılar. Onların öz işləri var. Onlar üçün əsas odur ki, Şəbəkə işləyir. Müvafiq olaraq, onlar orada nəyisə yenidən yükləmək, aparatlarında yanıb-sönmə etmək istəyirlər və aparat da vaxtaşırı dəyişir. Bütün bunları bir növ nəzərə almaq lazımdır. Bütün bunlar paylanmış tətbiqimizə təsir edir.
Adətən böyük həcmli məlumatlarla işləməyə başlayan insanlar nədənsə internetin sərhədsiz olduğuna inanırlar. Orada bir neçə terabaytlıq bir fayl varsa, onu serverinizə və ya kompüterinizə aparıb istifadə edərək aça bilərsiniz pişik və baxın. Başqa bir səhv var cəldlik loglara baxın. Bunu heç vaxt etməyin, çünki bu pisdir. Çünki Vim hər şeyi bufer etməyə, hər şeyi yaddaşa yükləməyə çalışır, xüsusən də biz bu jurnaldan keçib nəsə axtarmağa başlayanda. Bunlar unudulmuş, lakin nəzərə alınmağa dəyər olan şeylərdir.

Bir prosessorla bir kompüterdə işləyən bir proqramı yazmaq daha asandır.
Sistemimiz böyüdükdə, biz hamısını paralelləşdirmək və təkcə kompüterdə deyil, həm də klasterdə paralelləşdirmək istəyirik. Sual yaranır: bu məsələni necə əlaqələndirmək olar? Tətbiqlərimiz hətta bir-biri ilə qarşılıqlı əlaqədə olmaya bilər, lakin biz bir neçə serverdə paralel olaraq bir neçə prosesi icra etdik. Və hər şeyin onlar üçün yaxşı getdiyini necə izləmək olar? Məsələn, internet üzərindən nəsə göndərirlər. Onlar öz vəziyyətləri haqqında haradasa, məsələn, hansısa verilənlər bazasında və ya jurnalda yazmalıdırlar, sonra bu jurnalı birləşdirib, sonra haradasa təhlil etməlidirlər. Üstəlik, nəzərə almalıyıq ki, proses işləyir və işləyirdi, birdən onda hansısa səhv yarandı və ya qəzaya uğradı, onda biz bu barədə nə qədər tez xəbər tutacağıq?
Aydındır ki, bütün bunları tez bir zamanda izləmək olar. Bu da yaxşıdır, lakin monitorinq bəzi şeylərə ən yüksək səviyyədə nəzarət etməyə imkan verən məhdud bir şeydir.
Proseslərimizin bir-biri ilə qarşılıqlı əlaqəyə girməsini, məsələn, bir-birimizə bəzi məlumatlar göndərməsini istədikdə, sual da yaranır - bu necə baş verəcək? Bir növ yarış vəziyyəti olacaqmı, bir-birinin üstünə yazacaqlarmı, məlumatlar düzgün gələcəkmi, yolda bir şey itiriləcəkmi? Biz bir növ protokol hazırlamalıyıq və s.
Bütün bu proseslərin koordinasiyası xırda bir şey deyil. Və bu, tərtibatçını daha da aşağı səviyyəyə enməyə və sistemləri ya sıfırdan, ya da tamamilə sıfırdan yazmağa məcbur edir, lakin bu o qədər də sadə deyil.
Bir kriptoqrafik alqoritmlə qarşılaşsanız və ya hətta onu həyata keçirsəniz, onu dərhal atın, çünki çox güman ki, bu sizin üçün işləməyəcək. O, çox güman ki, təmin etməyi unutduğunuz bir sıra səhvlərdən ibarət olacaq. Heç vaxt ciddi bir şey üçün istifadə etməyin, çünki çox güman ki, qeyri-sabit olacaq. Çünki mövcud olan bütün alqoritmlər çox uzun müddətdir ki, zaman tərəfindən sınaqdan keçirilib. Bu, cəmiyyət tərəfindən qıcıqlanır. Bu ayrı bir mövzudur. Və burada da eynidir. Bir növ proses sinxronizasiyasını özünüz həyata keçirməmək mümkündürsə, o zaman bunu etməmək daha yaxşıdır, çünki bu, olduqca mürəkkəbdir və sizi daim səhvlər axtaran sarsıntılı yola aparır.
Bu gün biz ZooKeeper haqqında danışırıq. Bir tərəfdən, bu, bir çərçivədir, digər tərəfdən, tərtibatçının həyatını asanlaşdıran və məntiqin həyata keçirilməsini və proseslərimizin koordinasiyasını mümkün qədər asanlaşdıran bir xidmətdir.
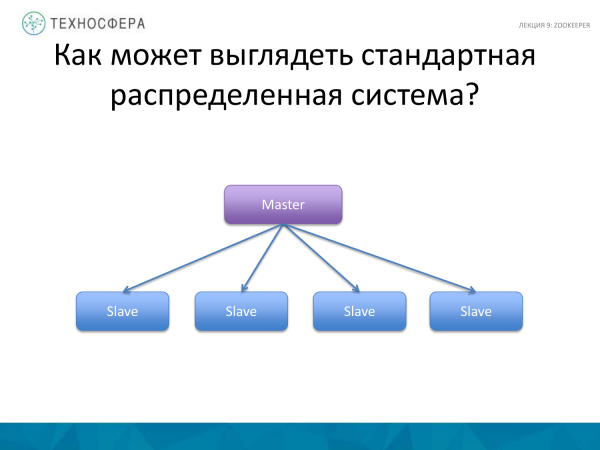
Standart paylanmış sistemin necə görünə biləcəyini xatırlayaq. Bu barədə danışdıq - HDFS, HBase. İşçiləri və qul proseslərini idarə edən Master prosesi var. O, tapşırıqların əlaqələndirilməsi və paylanması, işçilərin yenidən işə salınması, yenilərinin işə salınması və yükün paylanması üçün məsuliyyət daşıyır.
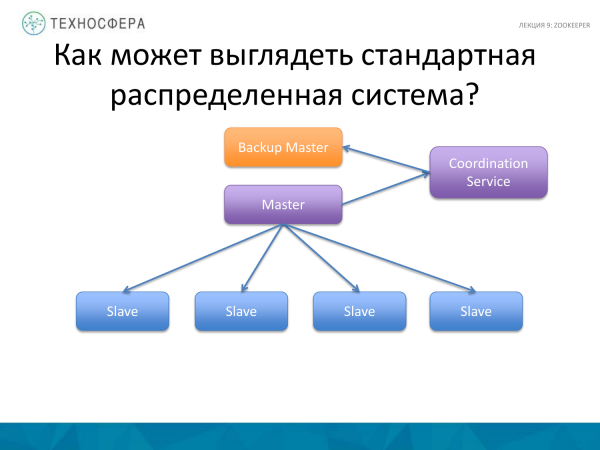
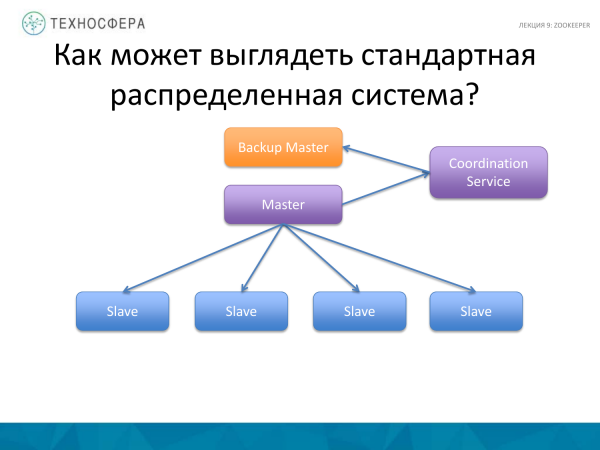
Daha inkişaf etmiş bir şey Koordinasiya Xidmətidir, yəni koordinasiya tapşırığının özünü ayrıca bir prosesə köçürün, üstəgəl bir növ ehtiyat nüsxəsini və ya stanby Master-ı paralel olaraq işə salın, çünki Master uğursuz ola bilər. Və əgər Ustad yıxılsa, o zaman sistemimiz işləməyəcək. Yedəkləməni həyata keçiririk. Bəziləri Master-ın ehtiyat nüsxə üçün təkrarlanmasının lazım olduğunu bildirir. Bu da Koordinasiya Xidmətinə həvalə edilə bilər. Lakin bu diaqramda Master özü işçilərin koordinasiyasına cavabdehdir, burada xidmət məlumatların təkrarlanması fəaliyyətlərini əlaqələndirir;
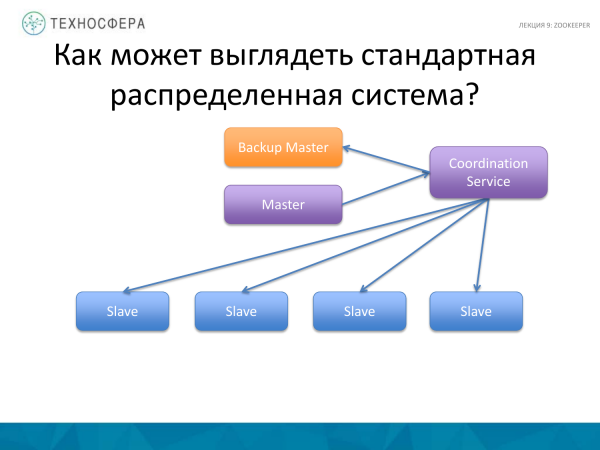
Daha təkmil seçim, adətən edildiyi kimi, bütün koordinasiyanın xidmətimiz tərəfindən idarə olunmasıdır. Hər şeyin işlədiyinə əmin olmaq üçün məsuliyyət daşıyır. Əgər bir şey işləmirsə, biz bu barədə məlumat əldə edirik və bu vəziyyətdən çıxmağa çalışırıq. İstənilən halda, biz qullarla bir növ qarşılıqlı əlaqədə olan və hansısa xidmət vasitəsilə məlumat, məlumat, mesaj və s. göndərə bilən Usta ilə qalmışıq.
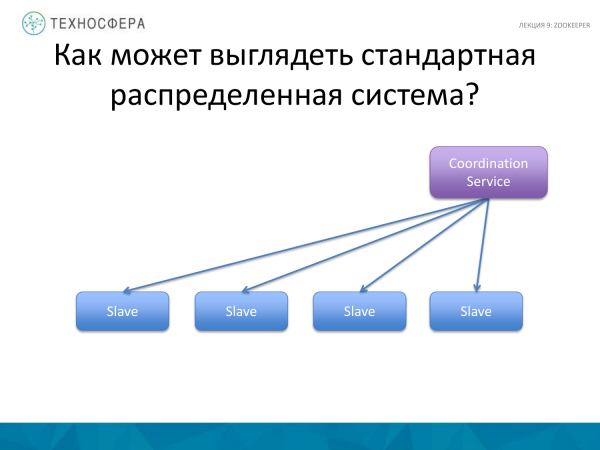
Daha təkmil bir sxem var, bizdə Ustad olmadıqda, bütün qovşaqlar davranışlarında fərqli olan master qullardır. Lakin onlar hələ də bir-biri ilə qarşılıqlı əlaqədə olmalıdırlar, buna görə də bu hərəkətləri əlaqələndirmək üçün hələ də bir az xidmət qalır. Yəqin ki, bu prinsiplə işləyən Kassandra bu sxemə uyğun gəlir.
Bu sxemlərdən hansının daha yaxşı işlədiyini söyləmək çətindir. Hər birinin öz müsbət və mənfi cəhətləri var.
Və Ustadla bəzi şeylərdən qorxmağa ehtiyac yoxdur, çünki təcrübədən göründüyü kimi, o, daim xidmət etməyə o qədər də həssas deyil. Burada əsas odur ki, bu xidməti ayrıca güclü qovşaqda yerləşdirmək üçün düzgün həll yolu seçməkdir ki, kifayət qədər resursa malik olsun, mümkünsə istifadəçilərin oraya girişi olmasın ki, təsadüfən bu prosesi öldürməsinlər. Ancaq eyni zamanda, belə bir sxemdə işçiləri Master prosesindən idarə etmək daha asandır, yəni bu sxem həyata keçirmək baxımından daha sadədir.
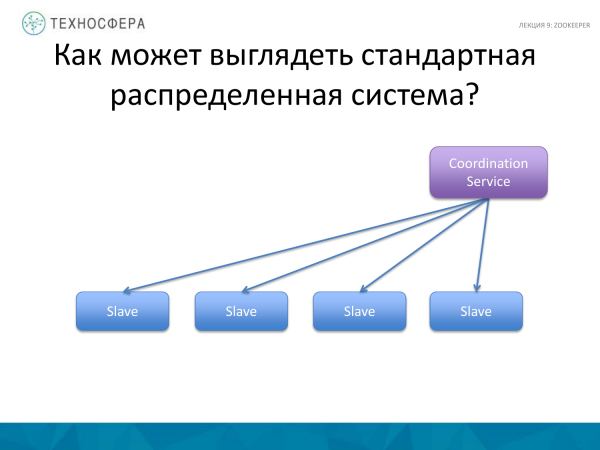
Və bu sxem (yuxarıda) yəqin ki, daha mürəkkəbdir, lakin daha etibarlıdır.

Əsas problem qismən uğursuzluqlardır. Məsələn, biz Şəbəkə üzərindən mesaj göndərdiyimiz zaman hansısa qəza baş verir və mesajı göndərən öz mesajının alınıb-almadığını və qəbul edən tərəfdə nə baş verdiyini bilməyəcək, mesajın düzgün işlənib-işlənmədiyini bilməyəcək. , yəni heç bir təsdiq almayacaq.
Buna uyğun olaraq, biz bu vəziyyəti emal etməliyik. Ən sadə şey isə bu mesajı yenidən göndərmək və cavab alana qədər gözləməkdir. Bu zaman qəbuledicinin vəziyyətinin dəyişib-dəyişmədiyi nəzərə alınmır. Biz mesaj göndərə və eyni məlumatları iki dəfə əlavə edə bilərik.
ZooKeeper bu cür imtinalarla mübarizə yollarını təklif edir ki, bu da həyatımızı asanlaşdırır.

Bir az əvvəl qeyd edildiyi kimi, bu, çox yivli proqramların yazılmasına bənzəyir, lakin əsas fərq ondan ibarətdir ki, müxtəlif maşınlarda qurduğumuz paylanmış proqramlarda ünsiyyət qurmağın yeganə yolu Şəbəkədir. Əslində, bu, paylaşılan heç bir arxitekturadır. Bir maşında işləyən hər bir proses və ya xidmətin heç kimlə paylaşmadığı öz yaddaşı, öz diski, öz prosessoru var.
Əgər bir kompüterdə çox yivli proqram yazsaq, o zaman məlumat mübadiləsi üçün ortaq yaddaşdan istifadə edə bilərik. Orada kontekst keçidimiz var, proseslər dəyişə bilər. Bu, performansa təsir göstərir. Bir tərəfdən, klasterdə proqramda belə bir şey yoxdur, lakin Şəbəkə ilə bağlı problemlər var.

Müvafiq olaraq, paylanmış sistemlərin yazılması zamanı yaranan əsas problemlər konfiqurasiyadır. Bir növ ərizə yazırıq. Əgər bu sadədirsə, onda biz kodda hər cür rəqəmi sərt kodlaşdırırıq, lakin bu, əlverişsizdir, çünki yarım saniyəlik fasilə əvəzinə bir saniyəlik fasilə istəməyimizə qərar versək, onda tətbiqi yenidən tərtib etməliyik və hər şeyi yenidən yuvarlayın. Bir maşında olduqda, onu sadəcə yenidən işə sala bildiyiniz zaman bir şeydir, lakin bir çox maşınımız olduqda, hər şeyi daim kopyalamalıyıq. Tətbiqi konfiqurasiya edilə bilən hala gətirməyə çalışmalıyıq.
Burada söhbət sistem prosesləri üçün statik konfiqurasiyadan gedir. Bu, tamamilə deyil, bəlkə də əməliyyat sistemi nöqteyi-nəzərindən, bu, bizim proseslərimiz üçün statik bir konfiqurasiya ola bilər, yəni bu, sadəcə götürülə və yenilənə bilməyən konfiqurasiyadır.
Dinamik konfiqurasiya da var. Tez dəyişmək istədiyimiz parametrlər bunlardır ki, orada seçilsinlər.
Burada problem nədir? Konfiqurasiyanı yenilədik, yaydıq, bəs nə olacaq? Problem onda ola bilər ki, bir tərəfdən konfiqurasiyanı yaydıq, amma yeni şeyi unutduq, konfiqurasiya orada qaldı. İkincisi, biz yaydığımız müddətdə konfiqurasiya bəzi yerlərdə yeniləndi, bəzilərində isə yox. Bir maşında işləyən tətbiqimizin bəzi prosesləri yeni konfiqurasiya ilə, haradasa köhnəsi ilə yenidən başladıldı. Bu, paylanmış tətbiqimizin konfiqurasiya baxımından uyğunsuzluğu ilə nəticələnə bilər. Bu problem ümumidir. Dinamik konfiqurasiya üçün bu, daha aktualdır, çünki onun tez dəyişdirilə biləcəyini nəzərdə tutur.
Digər problem qrupa üzvlüklə bağlıdır. Həmişə bir neçə işçi dəstəmiz var, biz həmişə onlardan hansının sağ, hansının öldüyünü bilmək istəyirik. Usta varsa, o zaman başa düşməlidir ki, hansı işçilərin hesablamalar aparması və ya verilənlərlə işləməsi üçün müştərilərə yönləndirilə bilər, hansının isə yox. Daim yaranan problem odur ki, bizim klasterimizdə kimin işlədiyini bilməliyik.
Başqa bir tipik problem, kimin rəhbərlik etdiyini bilmək istədiyimiz zaman lider seçkiləridir. Bir nümunə, yazma əməliyyatlarını qəbul edən və sonra onları digər proseslər arasında təkrarlayan bəzi prosesimiz olduqda replikasiyadır. O, lider olacaq, hamı ona tabe olacaq, onun ardınca gedəcək. Elə bir proses seçmək lazımdır ki, hamı üçün birmənalı olsun, iki liderin seçildiyi üzə çıxmasın.
Qarşılıqlı eksklüziv giriş də var. Burada problem daha mürəkkəbdir. Muteks kimi bir şey var, çox yivli proqramlar yazdıqda və bəzi resursa, məsələn, yaddaş hüceyrəsinə girişin məhdudlaşdırılmasını və yalnız bir iplə həyata keçirilməsini istədikdə. Burada resurs daha mücərrəd bir şey ola bilər. Şəbəkəmizin müxtəlif qovşaqlarından olan müxtəlif proqramlar yalnız verilmiş resursa eksklüziv giriş əldə etməlidir və hər kəs onu dəyişdirə və ya orada nəsə yaza bilməməlidir. Bunlar sözdə qıfıllardır.
ZooKeeper bütün bu problemləri bu və ya digər dərəcədə həll etməyə imkan verir. Və bunun sizə necə imkan verdiyini misallarla göstərəcəyəm.

Heç bir bloklama primitivləri yoxdur. Biz bir şeydən istifadə etməyə başladığımız zaman bu primitiv heç bir hadisənin baş verməsini gözləməyəcək. Çox güman ki, bu şey asinxron işləyəcək və bununla da proseslərin nəyisə gözləyərkən asılmamasına imkan verəcəkdir. Bu çox faydalı bir şeydir.
Bütün müştəri sorğuları ümumi növbə qaydasında işlənir.
Müştərilər dəyişdirilmiş məlumatları müştəri özləri görməzdən əvvəl bəzi dövlətlərdəki dəyişikliklər, məlumatlarda dəyişikliklər haqqında bildiriş almaq imkanı var.

ZooKeeper iki rejimdə işləyə bilər. Birincisi, tək bir qovşaqda müstəqildir. Bu, sınaq üçün əlverişlidir. Həmçinin, istənilən sayda qovşaqda klaster rejimində işləyə bilər. serverlərƏgər 100 maşınlıq klasterimiz varsa, onun mütləq 100 maşında işləməsi vacib deyil. ZooKeeper-in işlədə biləcəyi bir neçə maşın ayırmaq kifayətdir. Və o, yüksək mövcudluq prinsipinə riayət edir. ZooKeeper hər bir işləyən instansiyada məlumatların tam surətini saxlayır. Bunu necə etdiyini daha sonra izah edəcəyəm. Məlumatları parçalamır və ya bölməyə qoymur. Bir tərəfdən bu, bir dezavantajdır, çünki çox şey saxlaya bilmirik, digər tərəfdən isə lazımsızdır. Bunun üçün nəzərdə tutulmayıb; verilənlər bazası deyil.
Məlumatlar müştəri tərəfində yaddaşda saxlanıla bilər. Bu standart bir prinsipdir ki, biz xidmətə mane olmayaq və onu eyni sorğularla yükləməyək. Ağıllı bir müştəri adətən bunu bilir və yaddaşda saxlayır.
Məsələn, burada nəsə dəyişib. Bir növ tətbiq var. Məsələn, yazma əməliyyatlarına cavabdeh olan yeni rəhbər seçildi. Və biz məlumatları təkrarlamaq istəyirik. Bir həll onu bir döngəyə qoymaqdır. Və biz daim xidmətimizdən şübhələnirik - nəsə dəyişibmi? İkinci seçim daha optimaldır. Bu, müştərilərə nəyinsə dəyişdiyini bildirməyə imkan verən bir saat mexanizmidir. Bu, resurslar baxımından daha ucuz və müştərilər üçün daha əlverişli üsuldur.

Müştəri ZooKeeper-dən istifadə edən istifadəçidir.
Server ZooKeeper prosesinin özüdür.
Znode ZooKeeper-də əsas şeydir. Bütün znodlar ZooKeeper tərəfindən yaddaşda saxlanılır və iyerarxik diaqram şəklində, ağac şəklində təşkil edilir.
İki növ əməliyyat var. Birincisi, bəzi əməliyyatlar ağacımızın vəziyyətini dəyişdirdiyi zaman yeniləmə/yazmadır. Ağac ümumidir.
Mümkündür ki, müştəri bir sorğunu tamamlamır və əlaqəsi kəsilir, lakin ZooKeeper ilə qarşılıqlı əlaqədə olduğu bir sessiya qura bilər.

ZooKeeper-in məlumat modeli fayl sisteminə bənzəyir. Standart bir kök var və sonra biz kökdən gedən qovluqlardan keçdik. Və sonra birinci səviyyənin kataloqu, ikinci səviyyə. Bu, bütün znodes.
Hər bir znode bəzi məlumatları saxlaya bilər, adətən çox böyük deyil, məsələn, 10 kilobayt. Və hər bir znode müəyyən sayda uşaq sahibi ola bilər.

Znodlar bir neçə növdə olur. Onlar yaradıla bilər. Və bir znode yaratarkən, onun aid edilməli olduğu növü müəyyənləşdiririk.
İki növ var. Birincisi efemer bayraqdır. Znode seans daxilində yaşayır. Məsələn, müştəri bir sessiya qurdu. Və nə qədər ki, bu sessiya yaşayır, o, mövcud olacaq. Bu, lazımsız bir şey istehsal etməmək üçün lazımdır. Bu, seans daxilində verilənlərin primitivlərini saxlamağımızın vacib olduğu məqamlar üçün də uyğundur.
İkinci növ ardıcıl bayraqdır. Znode yolunda sayğacı artırır. Məsələn, 1_5 tətbiqi ilə bir kataloqumuz var idi. Və biz ilk node yaratdıqda, o, p_1, ikinci - p_2 aldı. Və biz hər dəfə bu metodu çağırdıqda, yolun yalnız bir hissəsini göstərərək tam yolu keçirik və bu rəqəm avtomatik olaraq artırılır, çünki biz node tipini - ardıcıl göstəririk.
Adi zond. O, həmişə yaşayacaq və ona söylədiyimiz adı alacaq.

Başqa bir faydalı şey saat bayrağıdır. Onu quraşdırsaq, müştəri müəyyən bir node üçün bəzi hadisələrə abunə ola bilər. Bunun necə edildiyini bir nümunə ilə sizə daha sonra göstərəcəyəm. ZooKeeper özü müştəriyə node haqqında məlumatların dəyişdiyini bildirir. Bununla belə, bildirişlər bəzi yeni məlumatların gəldiyinə zəmanət vermir. Sadəcə olaraq deyirlər ki, nəsə dəyişib, ona görə də siz yenə də məlumatları sonradan ayrı-ayrı zənglərlə müqayisə etməlisiniz.
Artıq dediyim kimi, məlumatların sırası kilobaytlarla müəyyən edilir. Orada böyük mətn məlumatlarını saxlamağa ehtiyac yoxdur, çünki o, verilənlər bazası deyil, fəaliyyət koordinasiya serveridir.

İcazə verin, sizə sessiyalar haqqında bir az məlumat verim. Əgər bir neçə serverimiz varsa, bir serverdən digərinə şəffaf şəkildə keçə bilərik. server, sessiya ID-sindən istifadə etməklə. Bu olduqca rahatdır.
Hər sessiyanın bir növ fasiləsi var. Sessiya müştərinin həmin sessiya zamanı serverə nəsə göndərib-göndərməməsi ilə müəyyən edilir. Taym-aut ərzində heç nə ötürməsə, sessiya yıxılır və ya müştəri özü onu bağlaya bilər.

Onun o qədər də çox funksiyası yoxdur, lakin bu API ilə müxtəlif işlər görə bilərsiniz. Yaratmağı gördüyümüz çağırış znode yaradır və üç parametr alır. Bu, znoda gedən yoldur və o, kökdən tam şəkildə göstərilməlidir. Həm də bu, oraya köçürmək istədiyimiz bəzi məlumatlardır. Və bayrağın növü. Və yaradıldıqdan sonra znode yolunu qaytarır.
İkincisi, onu silə bilərsiniz. Burada hiylə odur ki, ikinci parametr, znode gedən yola əlavə olaraq, versiyanı təyin edə bilər. Müvafiq olaraq, köçürdüyümüz versiyası əslində mövcud olana bərabər olarsa, həmin znode silinəcək.
Bu versiyanı yoxlamaq istəmiriksə, sadəcə olaraq "-1" arqumentini keçirək.

Üçüncüsü, bir znode varlığını yoxlayır. Düyün mövcuddursa doğru, əks halda yalan qaytarır.
Və sonra bu nodu izləməyə imkan verən bayraq saatı görünür.
Siz bu bayrağı hətta mövcud olmayan qovşaqda təyin edə və görünəndə bildiriş ala bilərsiniz. Bu da faydalı ola bilər.
Daha bir neçə problem var əldə edin. Aydındır ki, znode vasitəsilə məlumatları qəbul edə bilərik. Bayraq saatından da istifadə edə bilərsiniz. Bu vəziyyətdə, node olmadığı təqdirdə quraşdırılmayacaq. Buna görə də, onun mövcud olduğunu başa düşmək və sonra məlumat almaq lazımdır.

da var SetData. Burada versiyanı keçirik. Və bunu ötürsək, müəyyən bir versiyanın znode-dakı məlumatlar yenilənəcək.
Bu çeki istisna etmək üçün "-1" də təyin edə bilərsiniz.
Başqa bir faydalı üsuldur Uşaqları əldə edin. Ona aid olan bütün znodların siyahısını da əldə edə bilərik. Biz bayraq saatını təyin etməklə buna nəzarət edə bilərik.
Və üsul senkronize bütün dəyişikliklərin bir anda göndərilməsinə imkan verir və bununla da onların saxlanmasını və bütün məlumatların tamamilə dəyişdirilməsini təmin edir.
Əgər biz adi proqramlaşdırma ilə analogiyalar aparsaq, o zaman diskə nə isə yazan yazmaq kimi metodlardan istifadə etdikdə və o sizə cavab qaytardıqdan sonra məlumatı diskə yazdığınıza zəmanət yoxdur. Və hətta əməliyyat sistemi hər şeyin yazıldığına əmin olduqda belə, diskin özündə prosesin bufer qatlarından keçdiyi mexanizmlər var və yalnız bundan sonra məlumatlar diskə yerləşdirilir.

Əsasən asinxron zənglərdən istifadə olunur. Bu, müştəriyə müxtəlif sorğularla paralel işləməyə imkan verir. Sinxron yanaşmadan istifadə edə bilərsiniz, lakin daha az məhsuldardır.
Haqqında danışdığımız iki əməliyyat məlumatı dəyişdirən yeniləmə/yazma əməliyyatıdır. Bunlar yaratmaq, setData, sinxronizasiya, silməkdir. Və oxumaq mövcuddur, getData, getChildren.
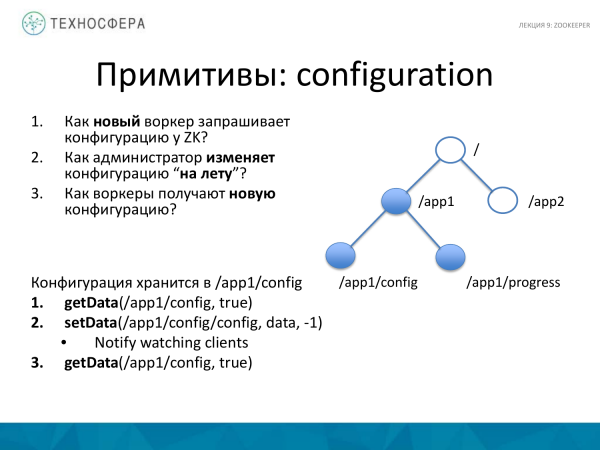
İndi paylanmış sistemdə işləmək üçün primitivləri necə yarada biləcəyiniz barədə bir neçə nümunə. Məsələn, bir şeyin konfiqurasiyası ilə əlaqədar. Yeni işçi peyda oldu. Maşını əlavə etdik və prosesə başladıq. Və aşağıdakı üç sual var. Konfiqurasiya üçün ZooKeeper-i necə sorğulayır? Və əgər konfiqurasiyanı dəyişmək istəyiriksə, onu necə dəyişdirə bilərik? Biz onu dəyişdirdikdən sonra bizdə olan işçilər bunu necə əldə edəcəklər?
ZooKeeper bunu nisbətən asanlaşdırır. Məsələn, bizim znode ağacımız var. Tətbiqimiz üçün burada bir node var, biz konfiqurasiyadan məlumatları ehtiva edən əlavə bir qovşaq yaradırıq. Bunlar ayrı-ayrı parametrlər ola bilər, olmaya da bilər. Ölçü kiçik olduğundan, konfiqurasiya ölçüsü də adətən kiçik olur, ona görə də onu burada saxlamaq olduqca mümkündür.
Siz metoddan istifadə edirsiniz əldə edin qovşaqdan işçi üçün konfiqurasiyanı əldə etmək. Doğru olaraq təyin edin. Əgər nədənsə bu node mövcud deyilsə, o, görünəndə və ya dəyişdikdə bizə bu barədə məlumat veriləcək. Bir şeyin dəyişdiyini bilmək istəyiriksə, o zaman onu doğru qoyuruq. Və bu qovşaqdakı məlumatlar dəyişərsə, biz bu barədə biləcəyik.
SetData. Biz məlumatları təyin etdik, "-1" təyin etdik, yəni versiyanı yoxlamırıq, hər zaman bir konfiqurasiyamız olduğunu güman edirik, çoxlu konfiqurasiyaları saxlamağa ehtiyac yoxdur. Çox şey saxlamaq lazımdırsa, başqa səviyyə əlavə etməli olacaqsınız. Burada yalnız birinin olduğuna inanırıq, ona görə də yalnız ən sonuncunu yeniləyirik, ona görə də versiyanı yoxlamırıq. Bu anda, əvvəllər abunə olan bütün müştərilər bu qovşaqda nəyinsə dəyişdiyi barədə bildiriş alırlar. Və onu aldıqdan sonra onlar da məlumatları yenidən tələb etməlidirlər. Bildiriş ondan ibarətdir ki, onlar məlumatın özünü qəbul etmir, yalnız dəyişikliklər barədə bildiriş alırlar. Bundan sonra onlar yeni məlumatlar tələb etməlidirlər.
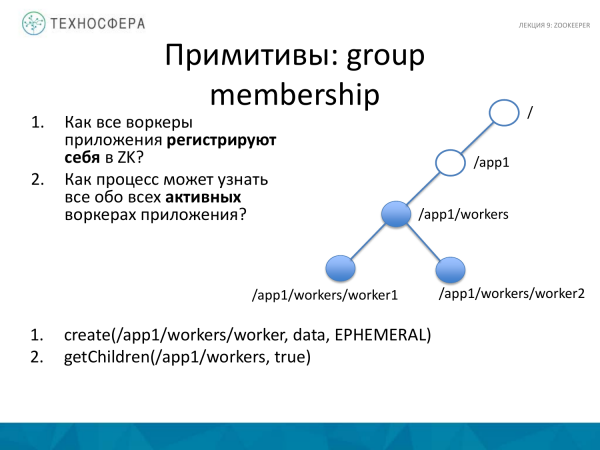
Primitivdən istifadə üçün ikinci seçimdir qrupa üzvlük. Paylanmış tətbiqimiz var, bir dəstə işçi var və onların hamısının yerində olduğunu başa düşmək istəyirik. Buna görə də ərizəmizdə işlədikləri üçün özlərini qeydiyyatdan keçirməlidirlər. Biz həmçinin, ya Master prosesindən, ya da başqa bir yerdən, hazırda mövcud olan bütün fəal işçilər haqqında öyrənmək istəyirik.
Bunu necə edirik? Tətbiq üçün işçi qovşağı yaradırıq və yaratma metodundan istifadə edərək oraya alt səviyyə əlavə edirik. Slaydda xəta var. Burada sizə lazımdır ardıcıl dəqiqləşdirin, sonra bütün işçilər bir-bir yaradılacaq. Və bu qovşağın uşaqları haqqında bütün məlumatları tələb edən proqram mövcud olan bütün aktiv işçiləri qəbul edir.
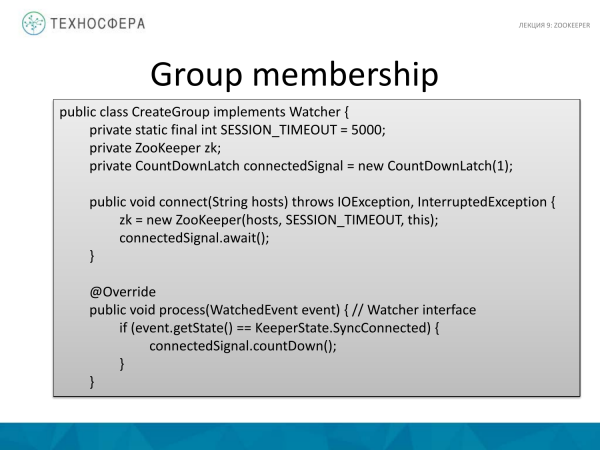

Bu, Java kodunda bunun necə edilə biləcəyinin dəhşətli bir tətbiqidir. Əsas üsulla sondan başlayaq. Bu bizim sinifdir, onun metodunu yaradaq. İlk arqument olaraq biz qoşulduğumuz hostdan istifadə edirik, yəni onu arqument kimi təyin edirik. İkinci arqument isə qrupun adıdır.
Əlaqə necə baş verir? Bu istifadə olunan API-nin sadə bir nümunəsidir. Burada hər şey nisbətən sadədir. Standart ZooKeeper sinfi var. Biz hostları ona ötürürük. Və vaxt aşımını, məsələn, 5 saniyəyə təyin edin. Bizim connectSignal adlı üzvümüz var. Əslində, ötürülən yol boyunca bir qrup yaradırıq. Biz orada məlumat yazmırıq, baxmayaraq ki, bir şey yazıla bilərdi. Və buradakı düyün davamlı tipdir. Əslində, bu, hər zaman mövcud olacaq adi müntəzəm düyündür. Burada sessiya yaradılır. Bu, müştərinin özünün həyata keçirilməsidir. Müştərimiz sessiyanın canlı olduğunu bildirən dövri mesajlar göndərəcək. Sessiyanı bitirəndə yaxın zəng edirik və bu da seans yıxılır. Bu, ZooKeeper'ın bu barədə məlumat əldə etməsi və sessiyanı dayandırması üçün bizim üçün bir şey olarsa.
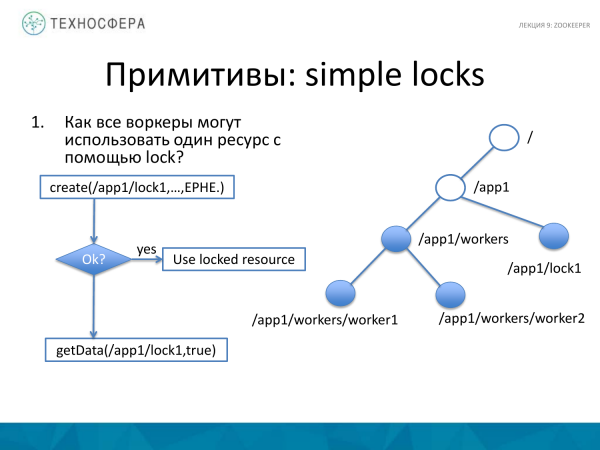
Resursu necə bağlamaq olar? Burada hər şey bir az daha mürəkkəbdir. Bir sıra işçilərimiz var, bağlamaq istədiyimiz bəzi resurs var. Bunun üçün ayrı bir node yaradırıq, məsələn, lock1 adlanır. Əgər biz onu yarada bilsəydik, deməli burada bir kilidimiz var. Əgər biz onu yarada bilməsək, o zaman işçi getData-nı buradan almağa çalışır və qovşaq artıq yaradıldığına görə, biz bura bir müşahidəçi qoyuruq və bu qovşağın vəziyyəti dəyişən kimi biz bu barədə məlumat alacağıq. Və biz onu yenidən yaratmağa vaxt tapmağa cəhd edə bilərik. Əgər biz bu qovşağı götürsək, bu kilidi götürsək, sonra kilidə ehtiyacımız qalmadıqdan sonra onu tərk edəcəyik, çünki düyün yalnız sessiya daxilində mövcuddur. Müvafiq olaraq, yox olacaq. Və başqa bir müştəri, başqa bir seans çərçivəsində, bu qovşağın kilidini götürə biləcək, daha doğrusu, nəyinsə dəyişdiyi barədə bildiriş alacaq və bunu vaxtında etməyə çalışa bilər.
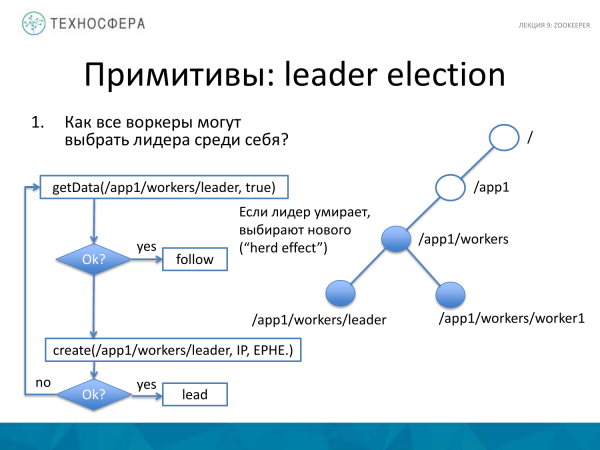
Əsas lideri necə seçə biləcəyinizin başqa bir nümunəsi. Bu bir az daha mürəkkəbdir, həm də nisbətən sadədir. Burda nə baş verir? Bütün işçiləri birləşdirən əsas qovşaq var. Lider haqqında məlumat əldə etməyə çalışırıq. Əgər bu uğurla baş veribsə, yəni bəzi məlumatlar əldə etdiksə, işçimiz bu liderin ardınca getməyə başlayır. O, artıq liderin olduğuna inanır.
Əgər lider nədənsə ölübsə, məsələn, yıxılıbsa, o zaman biz yeni lider yaratmağa çalışırıq. Əgər uğur qazansaq, o zaman işçimiz lider olur. Və əgər bu anda kimsə yeni lider yaratmağı bacarıbsa, biz onun kim olduğunu anlamağa və sonra onu izləməyə çalışırıq.
Burada sürü effekti deyilən şey yaranır, yəni sürü effekti, çünki lider öləndə vaxtında birinci olan lider olacaq.
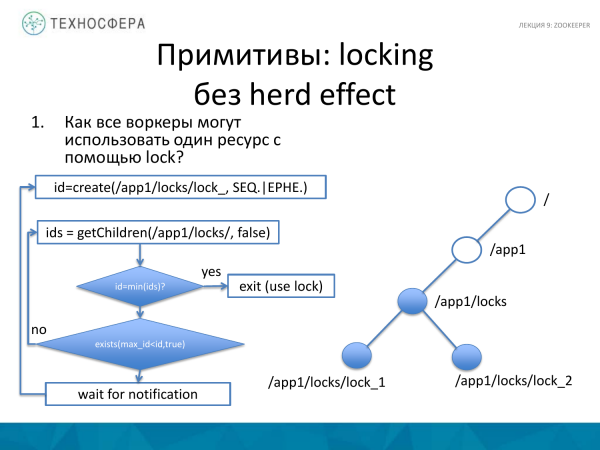
Resursu ələ keçirərkən, bir az fərqli yanaşmadan istifadə etməyə cəhd edə bilərsiniz, bu da aşağıdakı kimidir. Məsələn, biz kilid almaq istəyirik, lakin hert effekti olmadan. Bu ondan ibarət olacaq ki, tətbiqimiz artıq kilidli mövcud node üçün bütün node id-lərinin siyahısını tələb edir. Əgər bundan əvvəl kilid yaratdığımız qovşaq aldığımız dəstdən ən kiçikidirsə, bu, kilidi tutduğumuz deməkdir. Kilidi aldığımızı yoxlayırıq. Çek olaraq, yeni kilid yaratarkən aldığımız id-nin minimal olması şərti olacaq. Əgər biz bunu almışıqsa, daha da işləyirik.
Kilidimizdən kiçik olan müəyyən bir id varsa, biz bu hadisəyə bir izləyici qoyuruq və bir şey dəyişənə qədər bildiriş gözləyirik. Yəni bu kilidi aldıq. Və o, yıxılana qədər biz minimum id-yə çevrilməyəcəyik və minimum kilidi almayacağıq və beləliklə, daxil ola biləcəyik. Və əgər bu şərt yerinə yetirilmirsə, onda biz dərhal bura gedirik və bu kilidi yenidən almağa çalışırıq, çünki bu müddət ərzində nəsə dəyişmiş ola bilər.
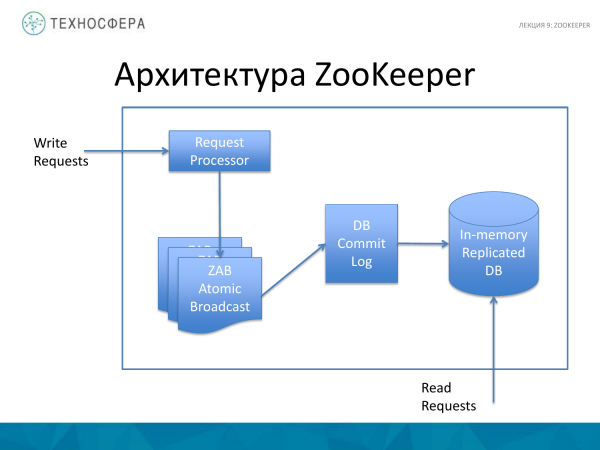
ZooKeeper nədən ibarətdir? 4 əsas şey var. Bu emal prosesləridir - Sorğu. Həm də ZooKeeper Atomic Broadcast. Bütün əməliyyatların qeyd olunduğu bir Commit Log var. Yaddaşda Replikasiya edilmiş DB-nin özü, yəni bütün ağacın saxlandığı verilənlər bazası.
Qeyd etmək lazımdır ki, bütün yazma əməliyyatları Sorğu Prosessorundan keçir. Və oxu əməliyyatları birbaşa yaddaşdaxili verilənlər bazasına keçir.

Verilənlər bazası özü tam təkrarlanır. ZooKeeper-in bütün nümunələri məlumatların tam surətini saxlayır.
Qəzadan sonra verilənlər bazasını bərpa etmək üçün Commit log var. Standart təcrübə ondan ibarətdir ki, məlumat yaddaşa daxil olmamışdan əvvəl orada yazılır ki, əgər o, qəzaya uğrayarsa, bu jurnalı oxutmaq və sistemin vəziyyətini bərpa etmək mümkün olsun. Və verilənlər bazasının dövri snapshotları da istifadə olunur.

ZooKeeper Atomic Broadcast təkrarlanan məlumatları saxlamaq üçün istifadə edilən bir şeydir.
ZAB ZooKeeper qovşağının nöqteyi-nəzərindən daxili olaraq lider seçir. Digər qovşaqlar onun davamçılarına çevrilir və ondan bəzi hərəkətlər gözləyir. Yazıları qəbul edərlərsə, hamısını liderə yönləndirirlər. O, əvvəlcə bir yazma əməliyyatı həyata keçirir və sonra izləyicilərinə nəyin dəyişdiyi barədə mesaj göndərir. Bu, əslində, atomik şəkildə həyata keçirilməlidir, yəni hər şeyin qeyd və yayım əməliyyatı atomik şəkildə yerinə yetirilməlidir və bununla da məlumatların ardıcıllığına zəmanət verilir.
 O, yalnız yazı sorğularını emal edir. Onun əsas vəzifəsi əməliyyatı əməliyyat yeniləməsinə çevirməkdir. Bu, xüsusi olaraq yaradılmış sorğudur.
O, yalnız yazı sorğularını emal edir. Onun əsas vəzifəsi əməliyyatı əməliyyat yeniləməsinə çevirməkdir. Bu, xüsusi olaraq yaradılmış sorğudur.
Və burada qeyd etmək lazımdır ki, eyni əməliyyat üçün yeniləmələrin qeyri-mümkünlüyünə zəmanət verilir. Bu nədir? Bu şey, iki dəfə icra edilərsə, eyni vəziyyətə sahib olacaq, yəni sorğunun özü dəyişməyəcək. Və bunu etmək lazımdır ki, qəza baş verərsə, əməliyyatı yenidən başladın və bununla da hazırda düşmüş dəyişiklikləri geri qaytara biləsiniz. Bu halda, sistemin vəziyyəti eyni olacaq, yəni bir sıra eyni, məsələn, yeniləmə prosesləri sistemin müxtəlif son vəziyyətlərinə səbəb olmamalıdır.








Mənbə: www.habr.com
