


Yalnız ilk dəfə ağrıyır!
Hamıya salam! Hörmətli dostlar, bu məqalədə mən anbar əsasında TensorRT və RetinaNet istifadə təcrübəmi bölüşmək istəyirəm. (bu, rəsmi repo çəngəlidir , bu, optimallaşdırılmış modellərdən ən qısa müddətdə istehsalda istifadə etməyə başlamağa imkan verəcək). İcma kanallarında mesajlar arasında sürüşdürün TensorRT-dən istifadə ilə bağlı suallar alıram və onlar əsasən özlərini təkrarlayırlar, ona görə də yazmaq qərarına gəldim mümkün qədər tam TensorRT, RetinaNet, Unet və Docker əsasında sürətli nəticə çıxarmaq üçün bələdçi.
Tapşırıqın təsviri
Tapşırığı bu şəkildə formalaşdırmağı təklif edirəm: verilənlər dəstini etiketləməli, RetinaNet/Unet şəbəkəsini Pytorch 1.3+ üzərində öyrətməli, əldə edilən çəkiləri ONNX-ə çevirməli, sonra onları TensorRT mühərrikinə çevirməli və bütün prosesi Docker-də, tercihen Ubuntu 18 və ARM (Jetson)* arxitekturasında çox arzuolunandır, beləliklə mühitin əl ilə yerləşdirilməsini minimuma endirir. Son nəticə yalnız RetinaNet/Unet-i ixrac etmək və təlim etmək üçün deyil, həm də bütün lazımi avadanlıqlarla birlikdə təsnifat və seqmentasiya sistemlərinin tam inkişafı və təlimi üçün hazır bir konteyner olacaq.
Mərhələ 1. Ətraf mühitin hazırlanması
Qeyd etmək vacibdir ki, bu yaxınlarda mən masaüstü kompüterimdə, eləcə də DevBox-da hər hansı kitabxanaların istifadəsini və yerləşdirilməsindən tamamilə imtina etmişəm. Yaratmalı və quraşdırmalı olduğum yeganə şeylər Python virtual mühiti və deb paketindən Cuda 10.2 (və ya sadəcə NVIDIA sürücüsüdür).
Tutaq ki, təzə quraşdırmısınız Ubuntu 18. Gəlin cuda 10.2 (deb) versiyasını quraşdıraq. Quraşdırma prosesi haqqında ətraflı məlumat verməyəcəyəm, rəsmi sənədlər kifayətdir.
İndi docker quraşdıraq, docker quraşdırma təlimatını asanlıqla tapmaq olar, burada bir nümunə var Versiya 19+ artıq mövcuddur – gəlin onu quraşdıraq. Docker-dən sudo olmadan istifadə etmək imkanını aktivləşdirməyi unutmayın; daha rahat olar. Hər şey qurulduqdan sonra aşağıdakıları edin:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
Və hətta rəsmi depoya baxmaq lazım deyil. .
İndi biz git clone edirik .
Getmək üçün bir az daha. Docker-dən Nvidia şəkli ilə istifadə etməyə başlamaq üçün NGC Cloud-da qeydiyyatdan keçməli və daxil olmalıyıq. Bura daxil olun. , qeydiyyatdan keçin və NGC Cloud-a daxil olduqdan sonra ekranın yuxarı sol küncündə SETUP üzərinə klikləyin və ya bu linki izləyin "Açar yarat" düyməsini basın. Mən onu yadda saxlamağı məsləhət görürəm, əks halda növbəti dəfə ziyarət etdiyiniz zaman onu bərpa etməli olacaqsınız və buna görə də yeni avtomobilə yerləşdirərkən bu prosesi təkrarlamalı olacaqsınız.
edək:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Sadəcə istifadəçi adını kopyalayın. Baxın, ətraf mühitin yerləşdirildiyini düşünün!
Addım 2: Docker Konteynerinin qurulması
İşimizin ikinci mərhələsində biz Docker-i quracağıq və onun daxili hissələri ilə tanış olacağıq.
Retina-examples layihəsinə nisbətən kök qovluğa keçək və işə başlayaq
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Biz Docker-i ona cari istifadəçini ötürməklə qururuq—bu, cari istifadəçinin hüquqları ilə quraşdırılmış VOLUME-a nəsə yazmaq fikrindəsinizsə, bu çox faydalıdır, əks halda köklənməli olacaqsınız və əziyyət çəkəcəksiniz.
Docker qurarkən, gəlin Docker faylını nəzərdən keçirək:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Mətndən də göründüyü kimi, bütün sevimli kitabxanalarımızı götürürük, retinanet-i tərtib edirik və işləmək rahatlığı üçün bəzi əsas alətləri əlavə edirik. Ubuntu və OpenSSH serverini konfiqurasiya edin. Birinci sətir, NGC Cloud girişini yaratdığımız və Pytorch1.3, TensorRT6.xxx və detektorumuz üçün CPP mənbə kodunu tərtib etməyə imkan verən bir sıra digər kitabxanaları ehtiva edən NVIDIA görüntüsünü miras alır.
Addım 3: Docker Konteynerinin işə salınması və sazlanması
Konteyner və inkişaf mühitinin əsas istifadə vəziyyətinə keçək. Əvvəlcə Nvidia Docker proqramını işə salaq. Qaçış:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestKonteynerə indi ssh vasitəsilə daxil olmaq mümkündür. @localhost. Uğurlu işə salındıqdan sonra layihəni PyCharm-da açın. Sonra, açın
Settings->Project Interpreter->Add->Ssh Interpreter 1 addım
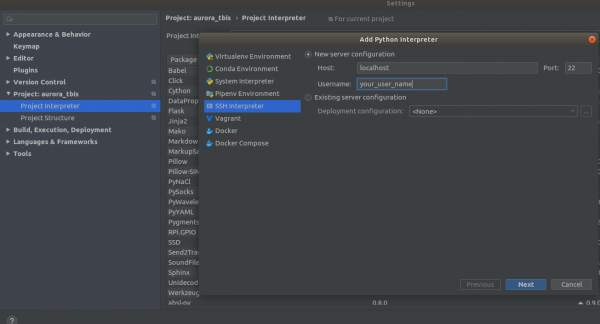
2 addım
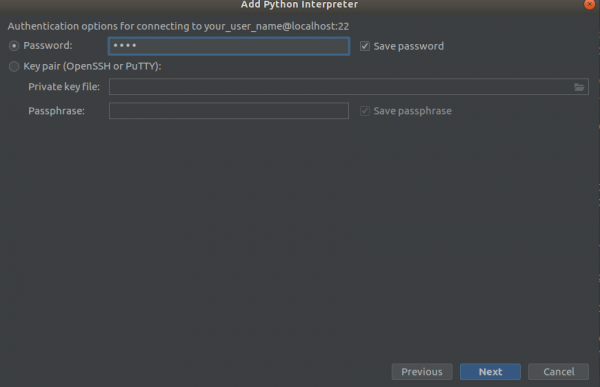
3 addım
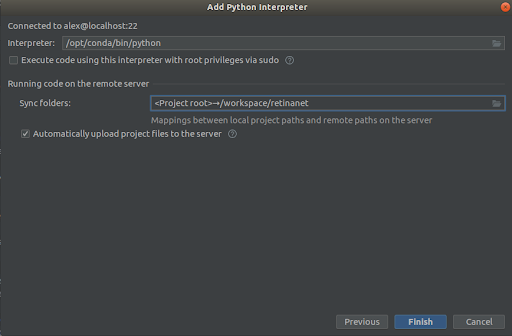
Ekran görüntülərində olduğu kimi hər şeyi seçirik,
Interpreter -> /opt/conda/bin/python— Python3.6-da ln olacaq və
Sync folder -> /workspace/retinanetBitir düyməsini basın, indeksləşdirməni gözləyin və budur, mühit istifadəyə hazırdır!
Vacib !!! İndeksləmədən dərhal sonra Retinanet üçün tərtib edilmiş faylları Docker-dən çəkin. Layihənin kökündəki kontekst menyusundan [Retinanet] seçin.
Deployment->DownloadBir fayl və iki qovluq görünəcək: build, retinanet.egg-info və _С.so
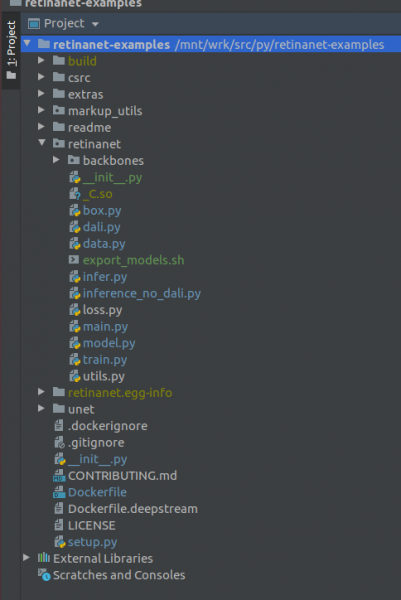
Əgər layihəniz belə görünürsə, o zaman mühit bütün lazımi faylları görür və biz RetinaNet-i öyrətməyə hazırıq.
Addım 4. Məlumatları etiketləyin və detektoru məşq edin
İşarələmə üçün mən əsasən istifadə edirəm — gözəl və rahat alət; Bu yaxınlarda bir sıra səhvlər düzəldildi və o, özünü əhəmiyyətli dərəcədə yaxşılaşdırmağa başladı.
Tutaq ki, siz verilənlər bazasını qeyd edib onu endirmisiniz, lakin siz onu birbaşa RetinaNet-ə yükləyə bilməzsiniz, çünki o, mülkiyyət formatındadır. Bunun üçün onu COCO-ya çevirməliyik. Dönüşüm aləti burada yerləşir:
markup_utils/supervisly_to_coco.pyNəzərə alın ki, skriptdəki Kateqoriya nümunədir və siz öz kateqoriyanızı daxil etməlisiniz (fon kateqoriyasını əlavə etməyə ehtiyac yoxdur)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Orijinal deponun müəllifləri nədənsə aşkar etmək üçün COCO/VOC-dan başqa bir şey öyrətməyəcəyinizə qərar verdilər, ona görə də mənbə faylını bir az redaktə etməli oldum.
retinanet/dataset.pySevimli artırmalarınızı buraya əlavə edin Və COCO-dan sərt kodlu kateqoriyaları silin. Böyük təsvirlərdə kiçik obyektlər axtarırsınızsa, kiçik məlumat dəstinə sahibsinizsə və heç bir şey işləmirsə, ancaq başqa vaxt daha çox işləmirsinizsə, böyük aşkarlama sahələrini kəsmək də mümkündür.
Ümumiyyətlə, qatar döngəsi də zəifdir, ilkin olaraq yoxlama məntəqələrini saxlamadı, hansısa dəhşətli planlaşdırıcıdan istifadə etdi və s. Amma indi sizə lazım olan tək şey onurğa sütununu seçmək və yerinə yetirməkdir.
/opt/conda/bin/python retinanet/main.pyparametrləri ilə:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
Konsolda siz görəcəksiniz:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Parametrlərin tam spektrini araşdırmaq üçün nəzər yetirin
retinanet/main.pyÜmumiyyətlə, onlar aşkarlama üçün standartdır və onların təsviri var. Məşq edin və nəticələri gözləyin. Nəticə nümunəsini burada görə bilərsiniz:
retinanet/infer_example.pyvə ya əmri işlədin:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
Repozitoriyada artıq Focal Loss və quraşdırılmış bir neçə onurğa sütunu var və özünüzü əlavə etmək də asandır
retinanet/backbones/*.pyCədvəldə müəlliflər bəzi xüsusiyyətləri təqdim edirlər:
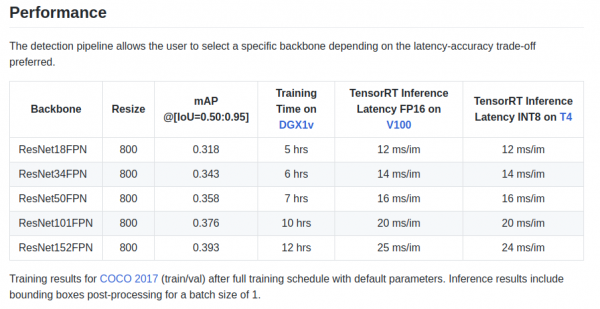
Torchvision-dan götürülmüş ResNeXt50_32x4dFPN və ResNeXt101_32x8dFPN onurğa sütunu da var.
Ümid edirəm ki, biz aşkarlamanı bir az anladıq, lakin siz mütləq rəsmi sənədləri oxumalısınız ixrac və giriş rejimlərini başa düşmək.
Addım 5. Resnet kodlayıcısı ilə Unet modellərinin ixracı və nəticə çıxarması
Diqqət etdiyiniz kimi, Dockerfile seqmentləşdirmə üçün kitabxanalar, xüsusən də gözəl lib. Unet paketində nəticə çıxarmaq və PyTorch yoxlama nöqtələrini TensorRT mühərrikinə ixrac etmək nümunələri var.
Unet-ə bənzər modelləri ONNX-dən TensoRT-ə ixrac edərkən əsas problem sabit Upsample ölçüsünü təyin etmək və ya ConvTranspose2D-dən istifadə etmək ehtiyacıdır:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
ONNX-ə ixrac edərkən bu çevrilmə avtomatik həyata keçirilə bilər, lakin bu problem TensorRT-nin 7-ci versiyasında artıq həll olunub və bizim yalnız qısa bir gözləməmiz qalıb.
Nəticə
Docker-dən istifadə etməyə başlayanda onun vəzifələrim üçün performansına şübhə edirdim. Mənim bölmələrimdən biri hazırda bir neçə kamera tərəfindən yaradılan kifayət qədər çox şəbəkə trafikinə malikdir.
İnternetdəki müxtəlif testlər şəbəkənin qarşılıqlı əlaqəsi və VOLUME-də qeyd üçün nisbətən böyük yükü, üstəlik naməlum və qorxulu GIL-i göstərdi və çərçivəni çəkdiyindən, sürücünün işləməsi və şəbəkə üzərindən kadr ötürülməsi rejimdə atom əməliyyatlarıdır. çətin real vaxt, şəbəkə gecikmələri mənim üçün çox vacibdir.
Amma hər şey yaxşı oldu =)
P.S. Qalan yalnız seqmentasiya və istehsal üçün sevimli qatar döngənizi əlavə etməkdir!
təşəkkürlər
Camaata təşəkkürlər , onsuz inkişaf etmək mümkün deyil! çox sağ olun. Məni DL ilə məşğul olmağa ruhlandıran, əvəzsiz məsləhətlərinə və qeyri-adi peşəkarlığına görə!
İstehsalda optimallaşdırılmış modellərdən istifadə edin!
 Aurorai, MMC
Aurorai, MMC
Mənbə: www.habr.com
