

Ўсім прывітанне. Ніжэй прадстаўлена расшыфроўка .
– сістэма маніторынгу розных сістэм і сэрвісаў, з дапамогай якой сістэмныя адміністратары могуць збіраць інфармацыю аб бягучых параметрах сістэм і наладжваць абвесткі для атрымання апавяшчэнняў аб адхіленнях у працы сістэм.
У дакладзе будзе параўнанне и - Праектаў для доўгатэрміновага захоўвання метрык Prometheus.



Спачатку раскажу пра Prometheus. Гэта сістэма маніторынгу, якая збірае метрыкі з зададзеных target'аў і захоўвае іх у лакальнае сховішча. Prometheus умее запісваць метрыкі ў выдаленае сховішча, умее генераваць alert'ы і recording rules.

Абмежаванні Prometheus:
- Ён не мае global query view. Гэта калі ў вас ёсць некалькі незалежных экзэмпляраў prometheus. Яны збіраюць метрыкі. І вы хочаце зрабіць запыт-над усіх гэтых метрык, сабраных з розных асобнікаў prometheus. Prometheus гэта не дазваляе.
- У prometheus прадукцыйнасць абмежавана толькі адным серверам. Prometheus аўтаматычна не можа маштабавацца на некалькі сервераў. Вы толькі можаце ўручную падзяліць вашыя target'ы паміж некалькімі Prometheus'амі.
- Аб'ём метрык у Prometheus абмежаваны толькі адным серверам па тым жа чынніку, па якой ён аўтаматычна не можа аўтаматычна маштабавацца на некалькі сервераў.
- У Prometheus не вось так проста арганізаваць захаванасць дадзеных.

Рашэнні гэтых праблем/задач?
Рашэнні такія:
Усе гэтыя рашэнні для выдаленага захоўвання дадзеных, сабраных Prometheus. Яны вырашаюць праблему remote storage з папярэдняга слайда па-рознаму. У дадзенай прэзентацыі я раскажу толькі пра першыя два рашэнні: и .
Упершыню інфармацыя пра з'явілася па . Там апісана архітэктура і як ён працуе.

Thanos бярэ дадзеныя, якая захаваў Prometheus на лакальны дыск, і капіююць іх у S3, у альбо ў іншы object storage.

Такім чынам, Thanos забяспечвае global query view. Вы можаце запытваць дадзеныя, захаваныя ў object storage з некалькіх асобнікаў Prometheus.

Thanos падтрымлівае PromQL і .

Thanos выкарыстоўвае код Prometheus для захоўвання даных.

Thanos распрацоўвае тыя ж распрацоўшчыкі, што і Prometheus.
Пра . Вось , дзе мы ўпершыню распавялі пра .
VictoriaMetrics атрымлівае дадзеныя з некалькіх prometheus па пратаколу, які падтрымліваецца Prometheus.
VictoriaMetrics забяспечвае global query view, бо некалькі асобнікаў Prometheus могуць запісваць дадзеныя ў адну VictoriaMetrics. Адпаведна, вы можаце зрабіць запыты па гэтых усіх дадзеных.

VictoriaMetrics таксама падтрымлівае, як і Thanos – PromQL і Prometheus querying API.

У адрозненне ад Thanos, зыходны код VictoriaMetrics напісаны з нуля і аптымізаваны па хуткасці і спажываным рэсурсам.

VictoriaMetrics у адрозненне ад Thanos, маштабуецца як вертыкальна так і гарызантальна. Ёсць , якая маштабуецца вертыкальна. Вы можаце пачаць з аднаго працэсара і 1 ГБ памяці і паступова расці да сотні працэсараў і 1ТБ памяці. VictoriaMetrics умее выкарыстоўваць усе гэтыя рэсурсы. Яе прадукцыйнасць вырасце прыкладна ў 100 разоў у параўнанні з 1-ядзернай сістэмай.

Гісторыя Thanos пачалася ў лістападзе 2017 г., калі з'явіўся першы публічны коміт. Да гэтага Thanos распрацоўваўся ўнутры кампаніі .

У чэрвені 2019 года быў знакавы рэліз 0.5.0, у якім пратакол. Яго прыбралі з Thanos, таму што ён сябе паказаў не з лепшага боку. Часта кластар Thanos няправільна працаваў, няправільна падключаліся да яго ноды з-за gossip пратаколу. Таму вырашылі яго адтуль прыбраць. Я лічу, што гэта правільнае рашэньне.

У тым жа чэрвені 2019 года яны даслалі заяўку нумар в .

І праз пару месяцаў Thanos прынялі ў , У якую ўваходзіць Prometheus, Kubernetes і іншыя папулярнае праекты.

У студзені 2018 года пачалася распрацоўка VictoriaMetrics.

У верасні 2018 года я ўпершыню публічна згадаў пра VictoriaMetrics.

У снежні 2018 гады апублікавалі Single-node версію.

У траўні 2019 зыходнікі як Single-node, так і кластарнай версіі.

У чэрвені 2019 года, таксама як Thanos, мы падалі заяўку ў CNCF foundation пад нумарам . Мы падалі заяўку на адзін дзень раней, чым падаў заяўку Thanos.

Але, на жаль, нас да гэтага часу не прынялі туды. Патрэбна дапамога кам'юніці.

Разгледзім самыя галоўныя слайды, якія паказваюць архітэктуру Thanos і VictoriaMetrics.
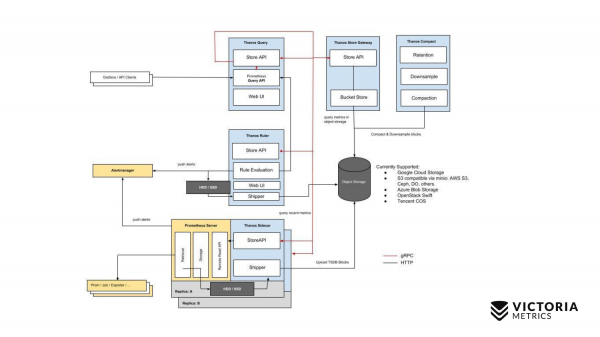
Пачнём з Thanos. Жоўтыя кампаненты - гэта кампаненты Prometheus. Усё астатняе - гэта кампаненты Thanos. Пачнём з самага галоўнага кампанента. Thanos Sidecar - гэта кампанент, які ўсталёўваецца побач з кожным Prometheus. Ён займаецца тым, што загружае дадзеныя Prometheus з лакальнага storage у S3 або ў іншы Object Storage.
Ёсць яшчэ такі кампанент, як Thanos Store Gateway, які ўмее счытваць гэтыя дадзеныя c Object Storage пры ўваходных запытах ад Thanos Query. Thanos Query рэалізуе PromQL і Prometheus API. Гэта значыць звонку ён выглядае як Prometheus. Прымае запыты PromQL, адпраўляе іх у Thanos Store Gateway, Thanos Store Gateway дастае патрэбныя дадзеныя з Object Storage, адпраўляе іх назад.
Але ў нас у Object Storage захоўваюцца дадзеныя без апошніх дзвюх гадзін з-за асаблівасці рэалізацыі Thanos Sidecar, які не можа запампаваць апошнія дзве гадзіны ў Object Storage S3, бо для гэтых дзвюх гадзін Prometheus яшчэ не стварыў файлы ў лакальным сховішчы.
Як жа гэта вырашылі абысці? Thanos Query акрамя, запытаў у Thanos Store Gateway, адпраўляе паралельна запыты яшчэ ў кожны Thanos Sidecar, які знаходзяцца побач з Prometheus.
А Thanos Sidecar, у сваю чаргу, праксіруе запыты далей у Prometheus, і дастае дадзеныя за апошнія дзве гадзіны.
Акрамя гэтых кампанент, ёсць яшчэ апцыянальны кампанент, без якога Thanos будзе дрэнна сябе адчуваць. Гэта Thanos Compact, які займаецца зліццём дробных файлаў на Object Storage у буйнейшыя файлы, якія былі загружаныя сюды Thanos Sidecar'амі. Thanos Sidecar загружае туды файлы з дадзенымі за дзве гадзіны. Гэтыя файлы, калі іх не зліваць у буйнейшыя файлы, тая іх колькасць можа выгадаваць вельмі істотна. Чым больш такіх файлаў, тым больш трэба памяці для Thanos Store Gateway, тым больш трэба рэсурсаў для перадачы дадзеных па сетцы, метададзеных. Праца Thanos Store Gateway становіцца неэфектыўнай. Таму трэба абавязкова запускаць Thanos Compact, які злівае дробныя файлы ў буйнейшыя, каб такіх файлаў было менш і каб паменшыць overhead на Thanos Store Gateway.
Ёсць яшчэ такі кампанент як Thanos Ruler. Ён выконвае Prometheus alerting rules і можа вылічваць Prometheus recording rules, для таго каб запісваць дадзеныя зноў у Object Storage. Але гэты кампанент не рэкамендуецца выкарыстоўваць, т.я. ён .
Вось такая схема простая ў Thanos.
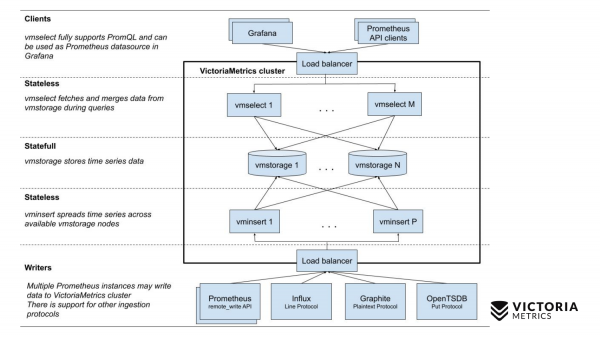
Цяпер параўнаем са схемай VictoriaMetrics.
У VictoriaMetrics ёсць 2 версіі: Single-node і кластарная версія. Single-node працуе на адным кампутары. У Single-node няма гэтых кампанентаў, проста адзін бінарнік. Гэты бінарнік на слайдзе выглядае вось гэтым квадратам. Усё, што знаходзіцца ўнутры квадрата - гэта змесціва бінарнага файла для Single-node версіі. Вам неабавязкова пра яго ведаць. Проста запускаеце бінарнік - і ўсё ў нас працуе.
Кластарная версія складаней. Унутры яе знаходзіцца тры розных кампанента: vmselect, vminsert і vmstorage. З іх назову павінна быць зразумела, чым кожны з іх займаецца. Insert кампанент прымае дадзеныя ў розных фарматах: з Prometheus remote write API, Influx line пратаколу, Graphite пратаколу і з OpenTSDB пратаколу. Insert кампанент прымае іх, парсіт і размяркоўвае паміж наяўнымі storage кампанентамі, дзе дадзеныя ўжо захоўваецца. Select кампанент, у сваю чаргу, прымае PromQL запыты. Ён рэалізуе , А таксама Prometheus querying API, і ён можа быць выкарыстаны, як замена Prometheus ў Grafana ці іншых Prometheus API кліентах. Select прымае promql запыт, парсіць яго, счытвае неабходныя дадзеныя для выканання гэтага запыту з storage нод, працэсіць гэтыя дадзеныя і вяртае адказ.

Параўнальны складанасць усталёўкі Thanos і VictoriaMetrics.

Пачнём з Thanos. Перад тым, як пачаць працаваць з Thanos, трэба стварыць bucket у Object Storage, такі як S3 ці GCS, каб Thanos Sidecar мог туды запісваць дадзеныя.

Затым для кожнага Prometheus неабходна ўсталяваць Thanos Sidecar. Перад гэтым трэба не забыцца адключыць data compaction у Prometheus. Data compaction перыядычна сціскае дадзеныя ў лакальным сховішчы Prometheus для таго, каб паменшыць спажыванне рэсурсаў.
Калі вы ўсталёўваеце Thanos Sidecar да вашых Prometheus'ам, вы павінны адключыць гэты data compaction, таму што Thanos Sidecar не ўмее звычайна працаваць пры ўключаным data compaction. Гэта азначае, што ваш Prometheus пачынае захоўваць дадзеныя блокамі па дзве гадзіны і перастае зліваць гэтыя блокі ў буйнейшыя. Адпаведна, калі вы робіце запыты, якія перавышаюць працягласць за апошнія дзве гадзіны, то яны будуць не настолькі эфектыўна працаваць у параўнанні з тым, як маглі б працаваць, калі быў бы ўключаны data compaction.

Таму Thanos рэкамендуе памяншаць час захоўвання дадзеных (data retention) у лакальным storage да 6-8 гадзін, каб знізіць гэты overhead вялікай колькасці дробных блокаў.
Пасля таго як вы ўсталявалі Thanos Sidecar, вы павінны для кожнага Object Storage Bucket усталяваць два кампаненты. Гэта Thanos Compactor і Thanos Store Gateway.

Пасля гэтага трэба ўсталяваць Thanos Query і наладзіць яго, каб ён умеў падлучацца да ўсіх Thanos Store Gateway, якія ў вас ёсць, а таксама ўмеў падлучацца да ўсіх Thanos Sidecar.
Тут можа быць невялікая проблемка.

Вам трэба наладзіць надзейнае і абароненае падлучэнне ад Thanos Query да гэтых кампанентаў. І калі ў вас Prometheus'ы знаходзяцца ў розных дата-цэнтрах, альбо ў розных VPC, то да іх забароненыя падлучэнні звонку. Але для працы Thanos Query вам трэба неяк наладзіць падлучэнне туды, і вы павінны прыдумаць спосаб.
Калі ў вас такіх дата-цэнтраў шмат, тое, адпаведна, змяншаецца надзейнасць усёй сістэмы. Бо Thanos Query павінен увесь час трымаць падлучэнні да ўсіх Thanos Sidecar, размешчаных у розных дата-цэнтрах. Пры кожным уваходным запыце ён будзе накіроўваць запыты на ўсе Thanos Sidecar. Калі злучэнне перарвецца, тыя вы атрымаеце альбо не поўны набор дадзеных, альбо атрымаеце адказ "кластар не працуе".

У VictoriaMetrics усё крыху прасцей. Для Single-node версіі дастаткова проста запусціць адзін бінарнік і ўсё працуе.

У кластарнай на версіі дастаткова запусціць усе вышэйзгаданыя тры тыпу кампанентаў у любой неабходнай вам колькасці, альбо выкарыстоўваць для аўтаматызацыі запуску кампанентаў у Kubernetes. Мы яшчэ плануем зрабіць аператара Kubernetes. Helm chart не пакрывае некаторыя кейсы, і дазваляе вам стрэліць нагу. Напрыклад, ён дазваляе паменшыць колькасць storage node, што прывядзе да страты даных.

Пасля таго, як вы запусцілі адзін бінарнік або кластарную версію, вам дастаткова дадаць у канфіг Prometheus , Каб ён пачаў запісваць дадзеных паралельна ў лакальны storage і ў remote storage. Як вы заўважылі, такая канфігурацыя павінна працаваць нашмат надзейней у параўнанні з канфігурацыяй Thanos. Нам не трэба трымаць падлучэнне ад VictoriaMetrics да ўсіх Prometheus'ам, таму што Prometheus'ы самі падключаюцца да VictoriaMetrics і перадаюць дадзеныя.

Разгледзім суправаджэнне Thanos і VictoriaMetrics.

У Thanos трэба сачыць за Sidecar, каб яны не спынялі загрузку дадзеных у Object Storage. Яны могуць спыніць гэтую загрузку дадзеных з прычыны памылак загрузкі, напрыклад у вас часова перарвалася сеткавае злучэнне з Object Storage, альбо Object Storage часова стаў недаступны. Thanos Sidecar у гэты момант заўважыць гэта, паведаміць пра памылку, можа зваліцца і пасля гэтага перастаць працаваць. Калі вы не будзеце яго маніторыць, то ў вас перастануць перадавацца дадзеныя ў Object Storage. Калі пройдзе час retention (6-8 гадзін рэкамендаванае), тыя вы будзеце губляць дадзеныя, якія не патрапілі ў Object Storage.

Thanos сompactor-ы могуць перастаць працаваць з-за . Сompactor-ы бяруць дадзеныя з Object Storage і зліваюць іх у буйнейшыя кавалкі дадзеных. Бо сompactor-ы не сінхранізаваныя з Sidecar'амі, тое можа адбыцца вось што: Sidecar не паспеў яшчэ дапісаць блок, Compactor вырашае, што гэты блок цалкам запісаны. Compactor пачынае яго счытваць. Ён счытвае блок не ў поўным выглядзе і перастае працаваць. Глядзіце падрабязнасці .

Store Gateway можа аддаваць некансістэнтныя дадзеныя з-за race'аў паміж Compactor'ам і Sidecar'амі. Тут такая ж штука, таму што Store Gateway ніяк не сінхранізаваны з Compactor'амі і Sidecar'амі. Адпаведна, могуць узнікаць стан гонак, калі Store Gateway не бачыць частку дадзеных, або бачыць лішнія дадзеныя.

Query кампанент у Thanos па змаўчанні аддае частковы вынік, калі некаторыя Sidecar-ы або Store Gateway не даступныя ў дадзены момант. Вы атрымаеце частку даных, і нават не будзе ведаць, што атрымалі не ўсе дадзеныя. Гэта ён працуе так па змаўчанні. У падобнай сітуацыі VictoriaMetrics вяртае пазначаныя дадзеныя як частковыя.

У адрозненне ад Thanos, VictoriaMetrics рэдка страчвае дадзеныя. Нават калі перарвалася падлучэнне ад Prometheus да VictoriaMetrics, то не праблема, бо Prometheus працягваецца запісваць якія паступаюць новыя дадзеныя ў Write Ahead Log, памер якога роўны 2 гадзінам. Калі вы на працягу двух гадзін адновіце падлучэнне да VictoriaMetrics, то дадзеныя не згубяцца. Prometheus .

У адрозненне ад Thanos, які запісвае дадзеныя ў object storage толькі праз дзве гадзіны, Prometheus аўтаматычна рэплікуе дадзеныя па remote write пратаколу ў remote storage, такі як VictoriaMetrics. Вам не страшная страта local storage у Prometheus. Калі ён раптам страціў local storage, тыя вы горшым выпадку страціце апошнія секунды дадзеных, якія не паспелі запісацца ў remote storage.

Kubernetes аўтаматычна кіруе кластарам у адрозненне ад Thanos. Усе кампаненты Thanos складана змясціць у адзін Kubernetes кластар, у адрозненне ад кластарных кампанент VictoriaMetrics.

У VictoriaMetrics вельмі простае абнаўленне на новую версію. Проста спыняеце VictoriaMetrics, абнаўляеце бінарнікі і запускаеце. Пры прыпынку праз SIGINT сігнал усе бінарнікі VictoriaMetrics робяць gracefull shutdown. Яны правільна захоўваюць патрэбныя дадзеныя, правільна зачыняюць уваходныя злучэнні, каб нічога не страціць. Таму вы нічога не страціце пры абнаўленні.

У VictoriaMetrics вельмі проста пашыраць кластар. Проста дадаеце неабходныя кампаненты і працягваеце працаваць.

Пра падводныя камяні ў Thanos і VictoriaMetrics.

У Thanos наступныя падводныя камяні. Prometheus павінен захоўваць дадзеныя за апошнія дзве гадзіны. Калі яны згубяцца, вы іх цалкам страціце, бо яны яшчэ не паспелі запісацца ў Object Storage, такі як S3.

Store Gateway кампанент і сompactor кампанент можа патрабаваць шмат памяці для працы з вялікім Object Storage, калі тамака захоўваецца шмат дробных файлаў. Чым большая колькасць і аб'ём файлаў, тым больш патрабуецца аператыўнай памяці Store Gateway і сompactor для захоўвання метаінфармацыі. У Thanos шмат issues з нагоды таго, што .

Thanos рэкламуецца, што ён можа скейліцца бясконца на колькасць вашых Prometheus. Насамрэч гэта няпраўда. Бо ўсе запыты ідуць праз Query кампанент, які павінен раўналежна апытаць усе Store Gateway кампаненты і ўсе Sidecar кампаненты, выцягнуць адтуль дадзеныя і потым іх препроцессить. Відавочна што хуткасць запытаў абмежавана самым павольным слабым звяном, самым павольным Store Gateway або самым павольным Sidecar.
Гэтыя кампаненты могуць быць нераўнамерна нагружаны. Напрыклад, у вас ёсць Prometheus, які збірае мільёны метрык у секунду. І ёсць Prometheus, у якім збіраецца тысячы метрык за секунду. Prometheus, у якім збіраюцца мільёны метрык у секунду, нашмат мацней загружае сервер, на якім ён працуе. Адпаведна Sidecar там працуе павольней. І ўвогуле ўсё там павольна працуе. І Query кампанент будзе вельмі павольна адтуль дадзеныя выцягваць. Адпаведна прадукцыйнасць вашага ўсяго кластара будзе абмежавана гэтым павольным Sidecar.

Па змаўчанні Thanos аддае частковае дадзеныя, калі некаторыя Sidecar'ы і альбо Store Gateway недаступныя. Напрыклад, калі ў вас Sidecar'ы раскіданыя па ўсім свеце ў розных дата-цэнтрах, то верагоднасць разрыву злучэння і недаступнасці кампанентаў моцна ўзрастае. Адпаведна, у большасці выпадкаў вы будзеце атрымліваць частковыя дадзеныя, нават не ведаючы аб гэтым.
У VictoriaMetrics таксама ёсць падводныя камяні. Першы падводны камень – гэта опцыя, якая абмяжоўвае аб'ём аператыўнай памяці, якая выкарыстоўваецца пад кэш VictoriaMetrics. Па змаўчанні яна роўная 60% аператыўнай памяці на машыне, дзе VictoriaMetrics запушчана або 60% АЗП пода VictoriaMetrics у Kubernetes.
Калі няправільна памяняць гэтае значэнне, то можна загубіць прадукцыйнасць VictoriaMetrics. Напрыклад, калі ўсталяваць занізкае значэнне, то дадзеныя могуць перастаць змяшчацца ў кэш VictoriaMetrics. З-за гэтага ёй давядзецца рабіць лішнюю працу і нагружаць працэсар з дыскам. Калі вы зробіце гэтую опцыю занадта вялікі, тое гэта падвышае, па-першае, верагоднасць таго, што VictoriaMetrics будзе вылятаць з памылкай out of memory, і, па-другое, гэта будзе прыводзіць да таго, што ў аперацыйнай сістэме будзе заставацца вельмі мала аператыўнай памяці для файлавага кэша. А VictoriaMetrics належыць на файлавы кэш для прадукцыйнасці. Калі яго недастаткова, тое можа моцна павялічыцца нагрузка на дыск. Таму парада: не мяняць параметр без крайняй неабходнасці.
Другая опцыя. Гэта retentionPeriod - перыяд, які па змаўчанні выстаўлены ў 1 месяц. Гэты час, на працягу якога VictoriaMetrics захоўвае дадзеныя. Па заканчэнні гэтага тэрміна VictoriaMetrics дадзеныя выдаляе.
Многія запускаюць VictoriaMetrics без гэтага параметра, запісваюць дадзеныя на працягу месяца. А потым пытаюцца: чаму дадзеныя зніклі за папярэдні месяц? Таму што retentionPeriod па змаўчанні роўны 1 месяцу. Таму трэба ведаць і ўсталёўваць правільны retentionPeriod.

Пройдземся па ўнікальных магчымасцях.

У Thanos ёсць такая фіча, як downsampling: 5-хвілінныя і вартавыя інтэрвалы, якія часта . Калі трошкі і паглядзець іх issue на github, там вельмі шмат issues, звязаных з гэтым downsampling, што ён часам няправільна працуе, альбо працуе не так, як чакаюць карыстальнікі.

У Thanos ёсць дэдуплікацыя дадзеных для Prometheus HA pairs. Калі два Prometheus'а збіраюць адны і тыя ж метрыкі з адных і тых жа target'у і Thanos іх складае ў Object Storage. Thanos умее правільна дэдуплікаваць гэтыя дадзеныя, у адрозненне ад VictoriaMetrics.

У Thanos ёсць alert кампанент, які быў на схеме Thanos. Але яго .

У Thanos перавага, што код у Thanos і ў Prometheus – агульны. Thanos і Prometheus распрацаваны аднымі і тымі ж распрацоўшчыкамі. Пры паляпшэннях у Thanos або Prometheus выйграе іншы бок.

У VictoriaMetrics галоўная фіча гэта – MetricsQL. Гэта пашырэнні VictoriaMetrics для PromQL, пра якія я расказваў на папярэднім big monitoring metup.

VictoriaMetrics падтрымлівае заліванне дадзеных па мностве розных пратаколаў. VictoriaMetrics не толькі можа прымаць дадзеныя ад Prometheus, але і па пратаколах Influx, OpenTSDB і Graphite.

Дадзеныя VictoriaMetrics займаюць звычайныя нашмат менш месцы ў параўнанні з Thanos і Prometheus.
Калі запісваць рэальныя дадзеныя, то карыстачы кажуць аб 2-5 кратным памяншэнне памеру дадзеных на дыску ў параўнанні з Prometheus і Thanos.

Яшчэ адна перавага VictoriaMetrics яна аптымізаваная пад хуткасць.

Пройдзем па кошце інфраструктуры.

Адно з пераваг Thanos у тым, што ён захоўвае дадзеныя ў object storage, які параўнальна танны.
Пры захаванні дадзеных у object storage, вы павінны аплачваць аперацыі запіс і чытанні дадзеных ($10 за мільён аперацый). Калі вы запісваеце дадзеныя ў object storage, вы аплачваеце выдаткі вашага хостынгу на загрузку дадзеных у інтэрнэт, калі ваш кластар знаходзіцца не ў AWS - там бясплатна. Калі вы счытваеце дадзеныя, вы аплачваеце ад $10 да $230 за 1ТБ. Гэта можа быць істотна, калі вы часта запытваеце гістарычныя дадзеныя з Thanos кластара.

Для Thanos кластара трэба аплачваць сервера для Compact, Store Gateway, Query кампанентаў, якія патрабуе шмат памяці, ЦПУ для вялікіх аб'ёмаў даных.

У VictoriaMetrics выдаткі такія. Калі захоўваць дадзеныя на GCE HDD дысках, тое выходзіць $40 за 1ТБ. Для VictoriaMetrics дастаткова звычайных HDD дыскаў, не патрэбныя ніякія SSD, якія каштуюць раз у пяць даражэй. VictoriaMetrics аптымізавана пад HDD.

Для VictoriaMetrics патрэбныя серверы для кампанентаў: альбо Single-nod альбо для кластарных кампанентаў, якія ў адрозненне ад Thanos кампанентаў, патрабуе нашмат менш ЦПУ, АЗП – адпаведна будзе танней.

Прыклады ўкаранення.

У Thanos прыклад укаранення гэта Gitlab. Gitlab поўнасцю працуе на Thanos. Але тамака не ўсё так гладка. Калі паглядзець па іх , то можна ўбачыць што ў іх увесь час узнікаюць нейкія : бракуе памяці для Store Gateway або Query кампанентаў. Ім увесь час даводзіцца павялічваць аб'ём памяці.
З-за гэтага павялічваюцца выдаткі на вырашэнне гэтых праблем.
Другое ўкараненне, якое можа быць больш паспяховае – гэта кампанія Improbable, якія пачалі распрацоўку Thanos. Яны апублікавалі зыходнікі Thanos. Improbable кампанія, якая займаецца распрацоўкай гульнявых рухавічкоў.

У VictoriaMetrics публічныя прыклады ўкаранення гэта:
- wix.com канструктар сайтаў
- Adidas укараняе VictoriaMetrics і нават зрабіў даклад на апошнім PromCon 2019
- TrafficStars - ad network
- Seznam.cz - папулярны чэшскі пошукавік.
А далей пайшлі ноўнэйм кампаніі, якія я не магу назваць зараз. Яны не далі згоду.
- Адзін буйны распрацоўшчык гульняў. Буйней, чым ім Improbable.
- Буйны распрацоўшчык графічнага ПЗ.
- Буйны расейскі банк.
- Еўрапейскі вытворца ветраных турбін, які паспяхова пратэсціраваў VictoriaMetrics. Гэты вытворца ўкараняе VictoriaMetrics для маніторынгу дадзеных, атрыманых з ветраных турбін з хуткасцю 50 сэмплаў у секунду на кожны датчык. У кожнай ветранай турбіне па некалькіх сотняў датчыкаў. У іх некалькі сотняў ветраных турбін.
- Расейскія авіялініі, якія жадаюць укараніць VictoriaMetrics, але ўсё ніяк не могуць. Мы з імі на стадыі дамовы.
 Высновы.
Высновы.
VictoriaMetrics і Thanos вырашаюць падобныя задачы, але рознымі спосабамі:
- Global query view
- гарызантальнае маштабаванне
- адвольны retention

Дзякуй.
Чакаем вас на нашым .

Толькі зарэгістраваныя карыстачы могуць удзельнічаць у апытанні. , Калі ласка.
Што вы карыстаецеся ў якасці long term storage для Prometheus?
35,3%Танос6
0,0%Cortex0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%іншае4
Прагаласавалі 17 карыстальнікаў. Устрымаліся 16 карыстальнікаў.
Крыніца: habr.com
