


Zovem se Yuri i šef sam tima za sistemsku administraciju u Citymobilu. Danas ću podijeliti svoje iskustvo rada s tehnologijom tankog pružanja resursa za datotečne sisteme. Linux Objasnit ću kako se to može primijeniti u CI/CD procesima kompanije. Ispitat ćemo situaciju u kojoj su nam, za automatsko testiranje koda prilikom isporuke u produkciju, potrebne kopije MySQL baze podataka za čitanje i pisanje što je moguće sličnije produkcijskoj verziji.
Uvod: zašto davati loš savjet?
Logično pitanje, jer postoje dobro uspostavljeni mehanizmi za migraciju šema baze podataka u testna okruženja. Zašto se glavni DBMS bez dijeljenja uopće dovodi u takve količine? I nisu svi podaci potrebni za testiranje. Pokušaću da objasnim.
Prije otprilike godinu dana, u pozadini aktivnog rasta našeg taxi agregatora (u 2018. porastao je za oko 15 puta u smislu izvršenih putovanja), povećali su se obim podataka, opterećenje servera i učestalost pokretanja. Nalazimo se u sledećoj situaciji:
- Glavna MySQL baza podataka je porasla na oko 1000 tabela ukupne veličine 2,5 TB i nastavlja da raste.
- Nije bilo načina da se baza brzo razbije i uništi. Ovo nije bilo dozvoljeno starim pristupom „pišem u bazu podataka šta želim i kako želim“, gomila JOIN-ova i internih tabela.
- Nije postojao mehanizam za migracije šeme baze podataka u testna okruženja.
- Nije bilo automatskog testiranja koda prilikom pokretanja.
Poslednji problem koji sam želeo da rešim što je pre moguće. Postman testovi su već bili napisani za testiranje glavnog PHP monolita, ali je nedostajala ažurirana baza podataka. Istovremeno, nismo mogli da kreiramo repliku noću, da je napravimo master i damo je na komade tokom dana: veoma veliki broj uvođenja i promena, uključujući podatke i šemu baze podataka, bi učinio štand nefunkcionalnim do sredine dana. I bilo bi neefikasno ograničiti uvođenje samo na radni dan.
Ipak, zadatak je završen: dobili smo prvi radni štand za dvije sedmice. Tokom protekle godine pretrpeo je mnoge promene i nastavlja da se koristi.
Zatim ću detaljno opisati sve korake i faze razvoja našeg rješenja. Vidjet ćete da ova metoda zaslužuje pravo na postojanje.
Šta je "tanka rezervacija"?
Ovo je hardverska ili softverska tehnologija (drugo ime su rijetki volumeni), koja vam omogućava da dodijelite više potrebnog resursa nego što je dostupno. Istovremeno, dodijeljeni volumen mora zadovoljiti kriterije dovoljno (koliko je potrebno) i taman na vrijeme (za potrebno vrijeme). Općenito, tanko obezbjeđivanje se koristi u različitim sistemima skladištenja kako bi se obezbijedio prostor na disku u potrebnim količinama iznad onoga što je stvarno dostupno. Tehnologiju podržavaju različiti sistemi datoteka, kao što su LVM2, ZFS, BTRFS. Široko se koristi u virtualizacijskim hipervizorima. Tanka rezervna kopija nam je omogućila da brzo kreiramo onoliko kopija ove particije iz snimaka glavne particije podataka koliko nam je potrebno (direktorijum podataka MySQL DBMS).
Prvi štand, Thin LVM tehnologija
Ovo poglavlje bi se moglo nazvati i „Kako napraviti najbrže moguće snimke velikih količina podataka koristeći , smanjujući stabilnost MySQL sistema datoteka i DBMS-a na opscene nivoe.
Pošto smo već koristili LVM za izgradnju glavnih OS particija, odlučili smo da počnemo s njim. Za početak nam je bila potrebna posebna fizička mašina - replika naše glavne MySQL baze podataka, na kojoj bismo mogli kreirati snimak replike na zahtjev i podići ga pored zasebne MySQL instance. Za vrijeme trajanja testiranja, dozvolili smo primjenu operacija modifikacije na ovu instancu, a po završetku testova, bezbedno smo je izbrisali. Konfiguracija servera je bila ovakva:
- 2 x Intel Silver 4114 (10x2,2GHz HT)
- 8 x 32 GB DDR4
- 8 x 1920 GB Intel SSD u Adaptec RAID-10
Možete napisati poseban članak na temu izbora između RAID kontrolera i softverskog RAID MD. Samo da kažem da su na naš izbor uticala dva faktora:
- U trenutku postavljanja zadatka, sve DBMS smo instalirali na RAID kontrolere, tako da možemo reći da se to istorijski dešavalo.
- Razlika u performansama na testovima sintetičkog sistema datoteka i testova sa različitim operacijama u MySQL bila je minimalna.
Podijelili smo rezultujući RAID-10: napravili smo jednu grupu volumena (VG) za cijeli volumen (sa dodatnim troškovima od približno 6,7 GB) i kreirali logičku particiju (Logical Volume, LV) za sistem od 50 GB. U normalnoj situaciji, ostatak mjesta definiramo ispod odjeljka c MySQL. Ali trebala nam je tanka rezervacija, pa smo prvo kreirali takozvani bazen, unutar kojeg smo kreirali particiju od 3,5 TB pod /var/lib/mysql (na osnovu procijenjenih volumena baze podataka):
lvcreate -l 100%FREE -T vga/thin
lvcreate -V 3.5T -T vga/thin -n mysqlFormatirali smo particiju u ext4, montirali je, snimili repliku i dobili originalno postolje. Zatim smo napravili vezu u obliku API-ja koji treba da kreira snimke, podigne instancu MySQL baze podataka na datom portu i izbriše kreiranu instancu. Budući da ovo koristi samo sistemske pozive, odabrali smo uobičajeni bash kao skriptni jezik i implementirali rješenje otvorenog koda kao HTTP → bash API veza , napisano u Go.
Jednog dana ćemo objaviti naše bash skripte u otvorenom kodu, ali za sada ću jednostavno opisati osnovni algoritam:
Kreiranje glavnog snimka snapmaina:
- Zaustavljamo glavnu repliku.
- Stavili smo zaključavanje na operacije sa snapshot snapmain-om.
- Kreirajte novi snimak glavnog snimka.
- Pokrenite MySQL i uklonite zaključavanje.
Kreirajte bazu podataka na proizvoljnom portu iz snapmain-a:
- Stavljamo zaključavanje na određenu instancu baze podataka (port).
- Provjerite blokira li se stvaranje glavnog snimka. Ako jeste, onda čekamo i provjeravamo svakih 5 sekundi.
- Provjerite postoji li stari LV dio instance.
3.1 Ako postoji, zaustavite MySQL instancu sa kill -9 i obrišite LV particiju. - Kreirajte novu instancu iz snapmain-a.
- Pripremite i montirajte direktorije za ovu instancu.
- Uklanjamo znakove slave (fajlova) i pokrećemo MySQL instancu.
- Od toga pravimo majstora.
- Uklonite blokiranje.
Brisanje baze podataka na proizvoljnom portu:
- Stavljamo zaključavanje na određenu instancu baze podataka (port).
- Ubijte MySQL instancu sa kill -9.
- Demontirajte direktorije.
- Izbrišite LV dio i otpustite bravu.
Primjer naredbi za kloniranje particija nove instance baze podataka:
lvcreate -n stage_3307 -s vga/snapmain
lvchange -ay -K vga/stage_3307
mount -o noatime,nodiratime,data=writeback /dev/mapper/vga-stage_3307 /mnt/stage_3307Sada ću vam reći o glavnom problemu na koji smo naišli prilikom korištenja tankih rezervacija. Naišli smo na performanse SSD diskova. To se dogodilo zbog posebnosti Thin LVM-a: on u osnovi radi na nivou uređaja s niskorazinskim dijelovima sa zadanom veličinom od 4 MB. Kako je izgledalo:
- Napravite snimak sa glavne /var/lib/mysql particije.
- Počinjemo replikaciju da bismo sustigli master.
- Svaka promjena u tabelama replika prisiljava stare, nepromijenjene komade podataka da se pohranjuju u particiju snimka.
- Svaka promjena podignute test instance uzrokuje da se stari, neizmijenjeni komadi podataka pohranjuju u odjeljak kloniranih snimaka za tu instancu.
- Dobivamo opterećenje I/O operacija na 100% po uređaju, usporavajući sve operacije i postepeno zaostajanje za replikom.
- Do kraja radnog dana dobijamo štand koji kasni nekoliko sati.
Kako smo se pozabavili ovim da bismo dobili razumniji rezultat (izdvajamo):
RAID kontroler:
- Podrazumevano onemogućene sve vrste keširanja.
- Podesite povratni zapis (kada podaci uđu u bafer, upisivanje je završeno prije nego što se izvrši stvarno spremanje na disk).
Sistem podataka:
- Na tački montiranja /var/lib/mysql smo napisali noatime,nodiratitime,data=writeback
- Isključeno ext4 dnevnik sa tune2fs.
MySQL:
- Propisano innodb_flush_method = O_DSYNC (povećala brzinu pisanja, čime je smanjena pouzdanost).
- Onemogućeno evidentiranje, ne trebaju nam logovi.
- Propisano innodb_buffer_pool_size = 4G (što je manja veličina InnoDB bazena, brži će MySQL umrijeti kada se zaustavi, i brže ćemo napraviti snimak).
Ovo nije potpuna lista, posebno za MySQL. Međutim, ostale promjene su male i često nisu uvijek primjenjive i ne baš. Na primjer, u pokušaju da istovarimo diskove, čak smo se i zanijeli innodb_parallel_doublewrite_path u /dev/shm, što nam je u nekim slučajevima, prilikom pokretanja pogrešno prekinute instance, uštedilo i do 5 sekundi.
Zašto zaustavljamo MySQL prije snimanja? Na kraju krajeva, možemo ga ukloniti iz radne replike. Tako je, osim što će se nova instanca baze podataka na ovom snimku po defaultu smatrati oštećenom i zahtijevat će potpuno skeniranje pri pokretanju. Zaustavljanje replike je definitivno brže, iako je to najduža operacija u cijelom procesu.
Kao rezultat toga, dobili smo prihvatljivije tajminge i štand spreman za rad. Iako, kao što možete vidjeti iz najupečatljivijeg prikaza zaostatka replikacije glavne replike, situacija je još uvijek daleko od idealne:
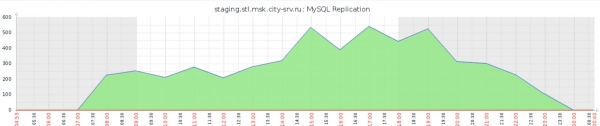
Među ostalim nedostacima, vrijedi napomenuti praktičnu nemogućnost praćenja Thin LVM bazena: pored standardnih sistemskih iostat funkcija, nemoguće je razumjeti, na primjer, koji element skupa sada proizvodi najveće opterećenje na datoteci sistem.
Zasebno, vrijedi napomenuti jedan veliki nedostatak povezan s gore opisanom optimizacijom: dobili smo YOLO stalak. Otprilike svakih jedan ili dva mjeseca, ext4 nije mogao izdržati takvu zloupotrebu samog sebe i nepovratno se pokvario, što je zahtijevalo ponovno formatiranje i ponovno postavljanje replike. Pobijedivši u brzini, beznadežno smo uništili stabilnost.
Koje metrike treba pratiti tokom rada Thin LVM:
- podaci tankog bazena %
- tanki bazen metapodataka %
Ako naš štand preživi nedostatak prostora za podatke (dovoljno je očistiti diskove), onda će nedostatak prostora za metapodatke dovesti do potpunog kolapsa bazena i potrebe da se ponovo kreira od nule.
Sistem datoteka unutar bazena postaje vrlo fragmentiran tokom vremena. Preporučujem pokretanje cron komande jednom dnevno fstrim -v /var/lib/mysql.
Međuzbroji:
- Tehnologija je lako primjenjiva, kao i sam LVM, i ne zahtijeva posebne inženjerske vještine.
- Pogodan je za malu bazu podataka i nije previše opterećen. Što je baza podataka manja, to se manje komada kreće kroz sistem datoteka unutar spremišta i manje je opterećenje diskova.
- Za naš problem počeli smo tražiti druga rješenja, o kojima će biti riječi u sljedećem odjeljku.
Drugi štand, ZFS tehnologija
Davno sam radio sa ZFS datotečnim sistemom, ali tada je ZFS pouzdano radio na svojoj izvornoj Solaris OS porodici. Postojao je port za FreeBSD sa prilično dobrim nivoom implementacije. Postojao je i nedovršeni port za... Linux, koji je malo ljudi koristilo. Zbog svoje B-stabla strukture pohrane podataka (usput, MySQL-ov InnoDB ima istu strukturu pohrane), ZFS se loše pokazao na instalacijama s vrlo velikim brojem datoteka. Ovo, zajedno s potrebom da se prije upotrebe nauči osnove, dovelo je do dugoročne upotrebe ovog datotečnog sistema. Pojavili su se Ext4 i xfs i postali standard. Ali s obzirom na to da je ZFS više nego pogodan za naše potrebe, i Linux-verzija, sudeći po recenzijama, izrasla je u potpuno razuman proizvod (iako nije u potpunosti podržana, zbog čega je instaliranje sistema na ZFS od nule moguće samo uz pomoć raznih voodoo tehnika), odlučili smo da je isprobamo.
Iz očiglednih razloga, stalak je izabran sa sličnom konfiguracijom (osim RAID kontrolera). Instalirano osam SSD diskova od 1920 GB. Nije bilo želje da napišem sopstvenu mrežnu sliku za upload servera na goli ZFS, pa smo odgrizli svih diskova od 50 GB i napravili MD RAID-10 na njima za sistem. Preostalih 1950 GB na svakom disku je kombinovano u ZFS analog RAID-10:
zpool create zpool mirror /dev/sda2 /dev/sdb2 mirror /dev/sdc2 /dev/sdd2 mirror /dev/sde2 /dev/sdf2 mirror /dev/sdg2 /dev/sdh2Napravljene particije za MySQL:
zfs create zpool/mysql
zfs set compression=gzip zpool/mysql
zfs set recordsize=128k zpool/mysql
zfs set atime=off zpool/mysql
zfs create zpool/mysql/data
zfs set recordsize=16k zpool/mysql/data
zfs set primarycache=metadata zpool/mysql/data
zfs set mountpoint=/var/lib/mysql zpool/mysql/dataImajte na umu da smo omogućili izvornu gzip kompresiju podataka. Imamo dosta procesorskih resursa na serveru i oni nisu u potpunosti iskorišćeni. Kao rezultat toga, 3 TB naše baze podataka se pretvorilo u 1,6 TB, a pošto je slaba karika, kao iu prethodnom slučaju, maksimalne performanse diska, manje podataka, to bolje, mi od samog početka dobijamo odličan bonus od ZFS-a! Tokom špica pri punom opterećenju, potrebno je do 4 jezgra da bi gzip radio, ali nemamo ništa protiv.
Dalja implementacija je išla brže. Postavke MySQL replike su prebačene sa LVM postolja kao nacrt. Morao sam provesti neko vrijeme prepravljajući skripte za ZFS komande, ali generalno, algoritmi su ostali isti. Primjer snimka:
zfs set snapdir=visible zpool/mysql/data
zfs create zpool/stage_3307
zfs clone zpool/mysql/data@snapmain zpool/stage_3307/data
zfs set mountpoint=/mnt/stage_3307 zpool/stage_3307/dataIz dodatnog podešavanja: ZFS particije sa metapodacima i l2arc i zil logovima su preuzete u memoriju. Za naš zadatak, kako se kasnije ispostavilo, ovo je bilo suvišno, ali za sada smo ovu optimizaciju ostavili, nije je teško povremeno promijeniti. Od negativnih efekata - nakon ponovnog pokretanja servera, morate ponovo kreirati odgovarajuća memorijska područja. Podaci se ne gube. Clipping zpool status:
logs
/dev/shm/zil_slog.img ONLINE 0 0 0
cache
/dev/shm/l2arc.img ONLINE 0 0 0U ovoj konfiguraciji smo počeli da testiramo bench i dobili smo odlične rezultate: sa dve istovremeno pokrenute instance baze podataka (i aktivnom glavnom replikom) na snimcima, dobili smo 50-60% iskorišćenosti diska.
Riješili smo se našeg glavnog problema, koji se može vidjeti na grafu zaostatka replikacije (uporedite s prethodnim grafikonom u odjeljku Thin LVM):
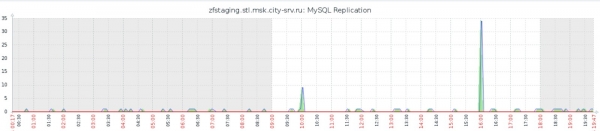
Osim toga, i zahvaljujući tome, uvelike smo ubrzali sve operacije: kompletno kreiranje snimka sa zaustavljanjem i pokretanjem replike traje do 40 sekundi, a implementacija nove MySQL instance iz snimka traje do 20 sekundi. Što više nego zadovoljava i nas i naše testove koda.
Međuzbroji:
- Rezultati su u potpunosti zadovoljili našu potrebu za kopijom proizvodne baze podataka za testiranje koda.
- Tehnologija zahtijeva unos: morate razumjeti šta je ZFS i kako raditi s njim.
- Nismo provjerili trenutno stanje ZFS-a sa velikim brojem (od 1 milion) malih fajlova. Ali pretpostavljamo da problem i dalje postoji, tako da ne bih preporučio ovaj sistem datoteka za bilo kakvo skladištenje datoteka.
Što je sljedeće?
U okviru štanda nema šta drugo raditi, odgovara nam rezultat. Možda ćemo u budućnosti dodati izuzetke tablicama koje nisu potrebne za testiranje u postavku replikacije štanda, što će dodatno smanjiti veličinu baze podataka. Nismo testirali BTRFS sistem i njegovu implementaciju tankog obezbjeđivanja. Međutim, takav zadatak više nije vrijedan, jer je glavni cilj postignut. Općenito, naravno, želim pobjeći od gornjeg pristupa - implementirati migracije radne baze podataka u testno okruženje, kreirati zasebno kolo testne baze podataka i početi dijeliti glavnu bazu podataka. Dosta toga već implementiramo, o čemu ćemo vam svakako govoriti u budućim člancima.
Ishodi
Prvobitni problem je riješen, iako na neobičan način. U prijelaznim zaključcima opisane su prednosti i nedostaci svake od primijenjenih tehnologija, pa odlučimo koja tehnologija se može koristiti i kada:
- Tanki LVM - na malim bazama podataka i kada ne želite ili nemate vremena da naučite ZFS.
- ZFS - ako imate iskustva s njim ili priliku da provedete vrijeme učeći u bilo kojoj situaciji.
Na višem nivou prezentacije, ovaj članak nije samo poređenje tehnologije dva sistema datoteka. Glavna ideja koju bih želio prenijeti i učvrstiti je da se ne treba bojati razmišljati izvan okvira u situacijama koje su kritične za posao i uzimati samo gotove recepte. Nekada smo u cijelom tehničkom odjelu mogli odmahnuti glavom i reći da je zadatak stvaranja tri terabajtne kopije baze podataka za manje od minute nemoguć, a ne trebaju nam rizične tehnologije, uradimo to kako treba. Bilo je moguće, ali izgubili bismo oko šest mjeseci do godinu dana i puno putovanja kupaca (putovanja su naš glavni pokazatelj poslovanja) bez testova i tokom implementacije. Izvan okvira nismo izgubili mnogo vremena za implementaciju, stekli iskustvo u novim i zaboravljenim starim tehnologijama i omogućili testiranje u trenutku kada nam je zaista bilo potrebno. Bez sumnje, to je imalo pozitivan uticaj na sve naše pokazatelje. Izbor je uvek na vama, a mi ćemo sa svoje strane nastaviti da pričamo o zanimljivim trenutnim i budućim dostignućima na našem blogu.
izvor: www.habr.com
