


SRE (Site Reliability Engineering) je přístup k zajištění dostupnosti webových projektů. Je považován za rámec pro DevOps a hovoří o tom, jak dosáhnout úspěchu při uplatňování postupů DevOps. Překlad v tomto článku knihy od Googlu. Tento překlad jsem připravil sám a opíral jsem se o vlastní zkušenosti s pochopením monitorovacích procesů. V telegramovém kanálu и Publikoval jsem také překlad 6. kapitoly téže knihy o cílech na úrovni služeb.
Překlad kat. Příjemné čtení!
Je nemožné řídit službu, pokud nerozumíte tomu, na kterých ukazatelích skutečně záleží a jak je měřit a vyhodnocovat. Za tímto účelem definujeme a poskytujeme určitou úroveň služeb našim uživatelům, bez ohledu na to, zda používají jedno z našich interních rozhraní API nebo veřejný produkt.
Využíváme svou intuici, zkušenosti a porozumění přání uživatelů porozumět indikátorům úrovně služeb (SLI), cílům úrovně služeb (SLO) a dohodám o úrovni služeb (SLA). Tyto dimenze popisují hlavní metriky, které chceme sledovat a na které budeme reagovat, pokud nebudeme moci poskytnout očekávanou kvalitu služby. Nakonec výběr správných metrik pomáhá vést správné akce, pokud se něco pokazí, a také dává týmu SRE důvěru ve zdraví služby.
Tato kapitola popisuje přístup, který používáme k boji s problémy metrického modelování, výběru metrik a metrické analýzy. Většina výkladu bude bez příkladů, takže pro ilustraci hlavních bodů použijeme službu Shakespeare popsanou v jejím příkladu implementace (hledání Shakespearových děl).
Terminologie úrovně služeb
Mnoho čtenářů pravděpodobně zná koncept SLA, ale termíny SLI a SLO si zaslouží pečlivou definici, protože obecně je termín SLA přetížený a má řadu významů v závislosti na kontextu. Pro přehlednost chceme tyto hodnoty oddělit.
Ukazatele
SLI je indikátor úrovně služeb – pečlivě definované kvantitativní měřítko jednoho aspektu úrovně poskytovaných služeb.
U většiny služeb je klíč SLI považován za latenci požadavku – jak dlouho trvá vrácení odpovědi na požadavek. Mezi další běžné SLI patří chybovost, často vyjádřená jako zlomek všech přijatých požadavků, a propustnost systému, obvykle měřená v požadavcích za sekundu. Měření jsou často agregovaná: nejprve se shromáždí nezpracovaná data a poté se převedou na míru změny, střední hodnotu nebo percentil.
V ideálním případě SLI přímo měří požadovanou úroveň služeb, ale někdy je pro měření k dispozici pouze související metrika, protože původní je obtížné získat nebo interpretovat. Například latence na straně klienta je často vhodnější metrikou, ale jsou chvíle, kdy lze latenci měřit pouze na serveru.
Dalším typem SLI, který je pro SRE důležitý, je dostupnost, neboli časová část, během které lze službu používat. Často se definuje jako míra úspěšných požadavků, někdy nazývaná výnos. (Pro systémy pro ukládání dat je důležitá také životnost – pravděpodobnost, že data budou uchovávána po delší dobu.) Přestože není možná 100% dostupnost, často je dosažitelná dostupnost blízko 100 %; hodnoty dostupnosti jsou vyjádřeny jako počet "devítek" » procento dostupnosti. Například dostupnost 99 % a 99,999 % může být označena jako „2 devítky“ a „5 devítek“. Aktuální cíl dostupnosti Google Compute Engine je „tři a půl devítky“ neboli 99,95 %.
Cíle
SLO je cíl úrovně služeb: cílová hodnota nebo rozsah hodnot pro úroveň služeb, která je měřena pomocí SLI. Normální hodnota pro SLO je „SLI ≤ Target“ nebo „Lower Limit ≤ SLI ≤ Upper Limit“. Můžeme se například rozhodnout, že výsledky vyhledávání Shakespeara vrátíme „rychle“ nastavením SLO na průměrnou latenci vyhledávacího dotazu menší než 100 milisekund.
Výběr správného SLO je složitý proces. Za prvé, nemůžete vždy vybrat konkrétní hodnotu. U externích příchozích požadavků HTTP na vaši službu je metrika Query Per Second (QPS) primárně určena přáním vašich uživatelů navštívit vaši službu a nemůžete pro to nastavit SLO.
Na druhou stranu můžete říci, že chcete, aby průměrná latence pro každý požadavek byla menší než 100 milisekund. Stanovení takového cíle vás může donutit napsat svůj frontend s nízkou latencí nebo koupit zařízení, které takovou latenci poskytuje. (100 milisekund je samozřejmě libovolné číslo, ale je lepší mít ještě nižší latence. Existují důkazy, které naznačují, že vysoké rychlosti jsou lepší než pomalé rychlosti a že latence při zpracování uživatelských požadavků nad určité hodnoty ve skutečnosti nutí lidi držet se stranou z vaší služby.)
Opět je to nejednoznačnější, než by se mohlo na první pohled zdát: neměli byste z výpočtu úplně vyloučit QPS. Faktem je, že QPS a latence spolu úzce souvisejí: vyšší QPS často vede k vyšším latencím a služby obvykle zaznamenají prudký pokles výkonu, když dosáhnou určitého prahu zatížení.
Výběr a publikování SLO stanoví očekávání uživatelů ohledně toho, jak bude služba fungovat. Tato strategie může snížit nepodložené stížnosti na vlastníka služby, jako je pomalý výkon. Bez explicitního SLO si uživatelé často vytvářejí svá vlastní očekávání o požadovaném výkonu, což nemusí mít nic společného s názory lidí, kteří navrhují a spravují službu. Tato situace může vést k nafouknutým očekáváním od služby, kdy se uživatelé mylně domnívají, že služba bude dostupnější, než ve skutečnosti je, a způsobit nedůvěru, když se uživatelé domnívají, že systém je méně spolehlivý, než ve skutečnosti je.
Dohody
Smlouva o úrovni služeb je explicitní nebo implicitní smlouva s vašimi uživateli, která zahrnuje důsledky splnění (nebo nesplnění) SLO, které obsahují. Důsledky jsou nejsnáze rozpoznatelné, když jsou finanční – sleva nebo pokuta – ale mohou mít i jiné formy. Snadný způsob, jak mluvit o rozdílu mezi SLO a SLA, je zeptat se „co se stane, když SLO nejsou splněny?“ Pokud neexistují žádné jasné důsledky, téměř jistě se díváte na SLO.
SRE se obvykle nepodílí na vytváření SLA, protože SLA jsou úzce svázány s obchodními a produktovými rozhodnutími. SRE se však podílí na pomoci zmírňovat důsledky neúspěšných SLO. Mohou také pomoci určit SLI: Je zřejmé, že v dohodě musí existovat objektivní způsob měření SLO, jinak dojde k nesouhlasu.
Vyhledávání Google je příkladem důležité služby, která nemá veřejnou smlouvu SLA: chceme, aby všichni používali vyhledávání co nejefektivněji, ale nepodepsali jsme smlouvu se světem. Stále však existují důsledky, pokud je vyhledávání nedostupné – nedostupnost má za následek pokles naší reputace a také snížení příjmů z reklamy. Mnoho dalších služeb Google, jako je Google for Work, má s uživateli explicitní smlouvy o úrovni služeb. Bez ohledu na to, zda má konkrétní služba SLA, je důležité definovat SLI a SLO a používat je ke správě služby.
Tolik teorie - nyní k zážitku.
Indikátory v praxi
Vzhledem k tomu, že jsme dospěli k závěru, že je důležité vybrat vhodné metriky pro měření úrovně služeb, jak nyní víte, které metriky jsou pro službu nebo systém důležité?
Co vás a vaše uživatele zajímá?
Nemusíte používat každou metriku jako SLI, kterou můžete sledovat v monitorovacím systému; Pochopení toho, co uživatelé od systému chtějí, vám pomůže vybrat několik metrik. Výběrem příliš mnoha indikátorů je obtížné zaměřit se na důležité indikátory, zatímco výběr malého počtu může ponechat velké části vašeho systému bez dozoru. K vyhodnocení a pochopení stavu systému obvykle používáme několik klíčových indikátorů.
Služby lze obecně rozdělit do několika částí z hlediska SLI, které jsou pro ně relevantní:
- Vlastní front-end systémy, jako jsou vyhledávací rozhraní pro službu Shakespeare z našeho příkladu. Musí být dostupné, bez zpoždění a musí mít dostatečnou šířku pásma. V souladu s tím lze položit otázky: můžeme odpovědět na žádost? Jak dlouho trvalo odpovědět na žádost? Kolik žádostí lze zpracovat?
- Skladovací systémy. Oceňují nízkou latenci odezvy, dostupnost a odolnost. Související otázky: Jak dlouho trvá čtení nebo zápis dat? Můžeme k údajům na požádání přistupovat? Jsou data dostupná, když je potřebujeme? Podrobnou diskusi o těchto problémech naleznete v kapitole 26 Integrita dat: Co čtete, to píšete.
- Systémy velkých dat, jako jsou kanály pro zpracování dat, spoléhají na propustnost a latenci zpracování dotazů. Související otázky: Kolik údajů se zpracovává? Jak dlouho trvá, než data putují od přijetí požadavku po vydání odpovědi? (Některé části systému mohou mít také zpoždění v určitých fázích.)
Sbírka indikátorů
Mnoho indikátorů úrovně služeb se přirozeně shromažďuje na straně serveru pomocí monitorovacího systému, jako je Borgmon (viz níže). ) nebo Prometheus, nebo jednoduše periodicky analyzovat protokoly a identifikovat odpovědi HTTP se stavem 500. Některé systémy by však měly být vybaveny sběrem metrik na straně klienta, protože nedostatek monitorování na straně klienta může vést k přehlédnutí řady problémů, které ovlivňují uživatelů, ale neovlivní metriky na straně serveru. Například zaměření na latenci odezvy backendu naší vyhledávací testovací aplikace Shakespeare může mít za následek latenci na straně uživatele kvůli problémům s JavaScriptem: v tomto případě je lepší metrikou měřit, jak dlouho prohlížeči trvá zpracování stránky.
Agregace
Pro jednoduchost a snadné použití často agregujeme nezpracovaná měření. To musí být provedeno opatrně.
Některé metriky se zdají jednoduché, například požadavky za sekundu, ale i toto zdánlivě přímočaré měření implicitně agreguje data v průběhu času. Je měření přijímáno konkrétně jednou za sekundu nebo je měření zprůměrováno počtem požadavků za minutu? Druhá možnost může skrýt mnohem vyšší okamžitý počet požadavků, které trvají jen několik sekund. Představte si systém, který obsluhuje 200 požadavků za sekundu se sudými čísly a po zbytek času 0. Konstanta v podobě průměrné hodnoty 100 požadavků za sekundu a dvojnásobná okamžitá zátěž nejsou totéž. Podobně se může zdát atraktivní průměrování latence dotazů, ale skrývá důležitý detail: je možné, že většina dotazů bude rychlá, ale bude mnoho dotazů, které budou pomalé.
Na většinu ukazatelů je lépe pohlížet jako na rozdělení spíše než jako průměry. Například pro latenci SLI budou některé požadavky zpracovány rychle, zatímco některé budou vždy trvat déle, někdy mnohem déle. Prostý průměr může tyto dlouhé prodlevy skrýt. Obrázek ukazuje příklad: ačkoli typický požadavek trvá vyřízení přibližně 50 ms, 5 % požadavků je 20krát pomalejších! Sledování a upozorňování pouze na základě průměrné latence nevykazuje změny v chování během dne, i když ve skutečnosti dochází k znatelným změnám v době zpracování některých požadavků (nejvyšší řádek).
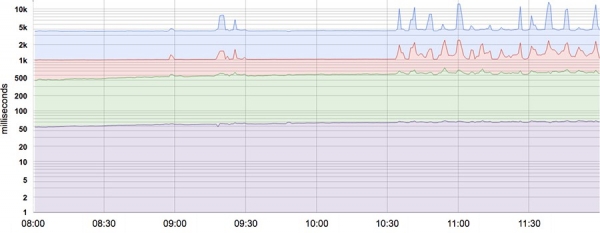
Systémová latence 50, 85, 95 a 99 percentilů. Osa Y je v logaritmickém formátu.
Použití percentilů pro ukazatele vám umožňuje vidět tvar rozdělení a jeho charakteristiky: vysoká úroveň percentilu, jako je 99 nebo 99,9, ukazuje nejhorší hodnotu, zatímco percentil 50 (známý také jako medián) ukazuje nejčastější stav metrika. Čím větší je rozptyl doby odezvy, tím více dlouhotrvající požadavky ovlivňují uživatelský dojem. Efekt je zesílen při vysoké zátěži a v přítomnosti front. Výzkum uživatelských zkušeností ukázal, že lidé obecně preferují pomalejší systém s velkým rozptylem doby odezvy, takže některé týmy SRE se zaměřují pouze na vysoké percentilové skóre na základě toho, že pokud je chování metriky na percentilu 99,9 dobré, většina uživatelů nebude mít problémy. .
Poznámka ke statistickým chybám
Obecně raději pracujeme s percentily než s průměrem (aritmetickým průměrem) souboru hodnot. To nám umožňuje uvažovat více rozptýlené hodnoty, které mají často výrazně odlišné (a zajímavější) charakteristiky než průměr. Kvůli umělé povaze výpočetních systémů jsou metrické hodnoty často zkreslené, takže žádný požadavek nemůže obdržet odpověď za méně než 0 ms a časový limit 1000 ms znamená, že nemohou existovat úspěšné odpovědi s hodnotami vyššími než časový limit. V důsledku toho nemůžeme přijmout, že průměr a medián mohou být stejné nebo blízko sebe!
Bez předchozího testování a pokud neplatí určité standardní předpoklady a aproximace, dáváme pozor, abychom nedošli k závěru, že naše data jsou normálně distribuována. Pokud distribuce není podle očekávání, proces automatizace, který problém řeší (například když vidí odlehlé hodnoty, restartuje server s vysokými latencemi zpracování požadavků), to možná dělá příliš často nebo nedostatečně často (obě nejsou velmi dobře).
Standardizovat ukazatele
Doporučujeme standardizovat obecné charakteristiky pro SLI, abyste o nich nemuseli pokaždé spekulovat. Jakákoli funkce, která splňuje standardní vzory, může být vyloučena ze specifikace jednotlivého SLI, například:
- Intervaly agregace: „průměr přes 1 minutu“
- Oblasti agregace: „Všechny úkoly v clusteru“
- Jak často se měření provádějí: „Každých 10 sekund“
- Jaké požadavky jsou zahrnuty: "HTTP GET z úloh monitorování černé skříňky"
- Jak jsou data získávána: "Díky našemu monitoringu měřenému na serveru"
- Latence přístupu k datům: "Čas do posledního bajtu"
Chcete-li ušetřit úsilí, vytvořte sadu opakovaně použitelných šablon SLI pro každou společnou metriku; také usnadňují každému pochopit, co znamená určité SLI.
Cíle v praxi
Začněte tím, že se zamyslíte (nebo zjistíte!), co vaše uživatele zajímá, ne co můžete měřit. Často je obtížné nebo nemožné měřit to, co vaše uživatele zajímá, takže se nakonec přiblížíte jejich potřebám. Pokud však začnete s tím, co se dá snadno měřit, skončíte u méně užitečných SLO. V důsledku toho jsme někdy zjistili, že prvotní identifikace požadovaných cílů a následná práce s konkrétními ukazateli funguje lépe než výběr ukazatelů a následné dosažení cílů.
Definujte cíle
Pro maximální jasnost by mělo být definováno, jak se SLO měří a za jakých podmínek jsou platné. Mohli bychom například říci následující (druhý řádek je stejný jako první, ale používá výchozí hodnoty SLI):
- 99 % (v průměru za 1 minutu) volání Get RPC se dokončí za méně než 100 ms (měřeno na všech backendových serverech).
- 99 % volání Get RPC se dokončí za méně než 100 ms.
Pokud je tvar křivek výkonu důležitý, můžete zadat více SLO:
- 90 % volání Get RPC bylo dokončeno za méně než 1 ms.
- 99 % volání Get RPC bylo dokončeno za méně než 10 ms.
- 99.9% Získejte dokončení RPC volání za méně než 100 ms.
Pokud vaši uživatelé generují heterogenní pracovní zátěže: hromadné zpracování (pro které je důležitá propustnost) a interaktivní zpracování (pro které je důležitá latence), může být užitečné definovat samostatné cíle pro každou třídu zátěže:
- 95 % požadavků zákazníků vyžaduje propustnost. Nastavte počet provedených RPC volání <1 s.
- 99 % klientů záleží na latenci. Nastavte počet RPC hovorů s provozem <1 KB a běžícím <10 ms.
Je nereálné a nežádoucí trvat na tom, že SLO budou splněny 100 % času: to může snížit tempo zavádění nových funkcí a nasazení a vyžadovat drahá řešení. Místo toho je lepší povolit chybový rozpočet – procento povoleného výpadku systému – a sledovat tuto hodnotu denně nebo týdně. Vrcholový management může chtít měsíční nebo čtvrtletní hodnocení. (Chybový rozpočet je jednoduše SLO pro srovnání s jiným SLO.)
Procento porušení SLO lze porovnat s rozpočtem na chyby (viz kapitola 3 a oddíl ), přičemž hodnota rozdílu se použije jako vstup do procesu, který rozhoduje, kdy nasadit nová vydání.
Výběr cílových hodnot
Výběr plánovacích hodnot (SLO) není čistě technickou činností, protože produkty a obchodní zájmy se musí odrážet ve vybraných SLI, SLO (a případně SLA). Podobně může být nutné vyměňovat si informace týkající se otázek souvisejících s personálním obsazením, dobou uvedení na trh, dostupností vybavení a financováním. SRE by měla být součástí tohoto rozhovoru a pomoci pochopit rizika a životaschopnost různých možností. Přišli jsme s několika otázkami, které by mohly pomoci zajistit produktivnější diskusi:
Nevybírejte si cíl podle aktuálního výkonu.
Zatímco pochopení silných stránek a limitů systému je důležité, přizpůsobení metrik bez uvažování vám může zabránit v udržování systému: bude to vyžadovat hrdinské úsilí k dosažení cílů, kterých nelze dosáhnout bez výrazného přepracování.
Udržujte to jednoduché
Složité výpočty SLI mohou skrýt změny ve výkonu systému a ztížit nalezení příčiny problému.
Vyhněte se absolutním
I když je lákavé mít systém, který zvládne nekonečně rostoucí zátěž bez zvýšení latence, tento požadavek je nereálný. Systém, který se blíží takovým ideálům, bude pravděpodobně vyžadovat spoustu času na návrh a stavbu, bude drahý na provoz a bude příliš dobrý pro očekávání uživatelů, kteří by si vystačili s čímkoli méně.
Používejte co nejméně SLO
Vyberte dostatečný počet SLO, abyste zajistili dobré pokrytí systémových atributů. Chraňte SLO, které si vyberete: Pokud nikdy nemůžete vyhrát hádku o prioritách zadáním konkrétního SLO, pravděpodobně nestojí za to uvažovat o tomto SLO. Ne všechny systémové atributy jsou však přístupné SLO: je obtížné vypočítat úroveň uživatelského potěšení pomocí SLO.
Nehonit se za dokonalostí
Definice a cíle SLO můžete vždy zpřesnit, když se dozvíte více o chování systému při zatížení. Je lepší začít s plovoucím cílem, který si časem upřesníte, než volit příliš přísný cíl, který se musí uvolnit, když zjistíte, že je nedosažitelný.
SLO mohou a měly by být klíčovým faktorem při upřednostňování práce pro SRE a vývojáře produktů, protože odrážejí zájem uživatelů. Dobrý SLO je užitečný nástroj pro vymáhání pro vývojový tým. Ale špatně navržený SLO může vést k plýtvání, pokud tým vynaloží hrdinské úsilí k dosažení příliš agresivního SLO, nebo špatnému produktu, pokud je SLO příliš nízké. SLO je mocná páka, používejte ji moudře.
Kontrolujte svá měření
SLI a SLO jsou klíčové prvky používané pro správu systémů:
- Monitorujte a měřte SLI systémy.
- Porovnejte SLI a SLO a rozhodněte se, zda je potřeba jednat.
- Pokud je nutná akce, zjistěte, co se musí stát, aby bylo dosaženo cíle.
- Dokončete tuto akci.
Pokud například krok 2 ukazuje, že časový limit požadavku vypršel a pokud se nic nepodnikne, během několika hodin přeruší SLO, krok 3 může zahrnovat testování hypotézy, že servery jsou vázány na CPU a přidání dalších serverů rozloží zátěž. Bez SLO byste nevěděli, zda (nebo kdy) jednat.
Nastavit SLO – poté se nastaví očekávání uživatele
Publikování SLO stanoví očekávání uživatelů ohledně chování systému. Uživatelé (a potenciální uživatelé) často chtějí vědět, co od služby očekávat, aby pochopili, zda je vhodná k použití. Například lidé, kteří chtějí používat web pro sdílení fotografií, se mohou chtít vyhnout používání služby, která slibuje dlouhou životnost a nízkou cenu výměnou za mírně nižší dostupnost, i když stejná služba může být ideální pro systém správy archivních záznamů.
Chcete-li svým uživatelům nastavit realistická očekávání, použijte jednu nebo obě z následujících taktik:
- Udržujte určitou míru bezpečnosti. Používejte přísnější interní SLO, než jaké je uživatelům inzerováno. To vám dá příležitost reagovat na problémy dříve, než se stanou navenek viditelnými. Vyrovnávací paměť SLO vám také umožňuje mít bezpečnostní rezervu při instalaci verzí, které ovlivňují výkon systému, a zajišťují snadnou údržbu systému, aniž byste museli uživatele frustrovat prostoji.
- Nepřekračujte očekávání uživatelů. Uživatelé jsou založeni na tom, co nabízíte, ne na tom, co říkáte. Pokud je skutečný výkon vaší služby mnohem lepší než uvedené SLO, uživatelé se budou spoléhat na aktuální výkon. Přílišné závislosti se můžete vyhnout záměrným vypnutím systému nebo omezením výkonu při nízké zátěži.
Pochopení toho, jak dobře systém naplňuje očekávání, pomáhá při rozhodování, zda investovat do zrychlení systému a učinit jej dostupnějším a odolnějším. Alternativně, pokud služba funguje příliš dobře, měli by zaměstnanci věnovat určitý čas jiným prioritám, jako je splacení technického dluhu, přidávání nových funkcí nebo zavádění nových produktů.
Dohody v praxi
Vytvoření smlouvy SLA vyžaduje, aby obchodní a právní týmy definovaly důsledky a sankce za její porušení. Úlohou SRE je pomoci jim porozumět pravděpodobným problémům při plnění SLO obsažených v SLA. Většina doporučení pro vytváření SLO platí i pro SLA. Je moudré být konzervativní v tom, co uživatelům slibujete, protože čím více jich máte, tím těžší je změnit nebo odstranit SLA, která se zdají být nepřiměřená nebo obtížně splnitelná.
Děkuji za přečtení překladu až do konce. Přihlaste se k odběru mého telegramového kanálu o monitorování и .
Zdroj: www.habr.com
