

Hej alle! Mit navn er Nikolaj Golov. Tidligere arbejdede jeg hos Avito og administrerede dataplatformen i seks år, hvilket betød, at jeg var involveret i alle databaser: analytiske (Vertica, ClickHouse), streaming og OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). I denne periode har jeg beskæftiget mig med et stort antal databaser - de mest forskelligartede og usædvanlige, og med ikke-standardiserede tilfælde af deres anvendelse.
Jeg arbejder i øjeblikket hos ManyChat. Det er i bund og grund en startup – ny, ambitiøs og i hastig vækst. Og da jeg først kom til virksomheden, opstod det klassiske spørgsmål: "Hvad skal en ung startup tage med sig fra DBMS- og databasemarkedet nu?"
I denne artikel, baseret på min rapport på , Jeg vil besvare dette spørgsmål. En videoversion af rapporten er tilgængelig på .
Almindeligt kendte databaser fra 2020
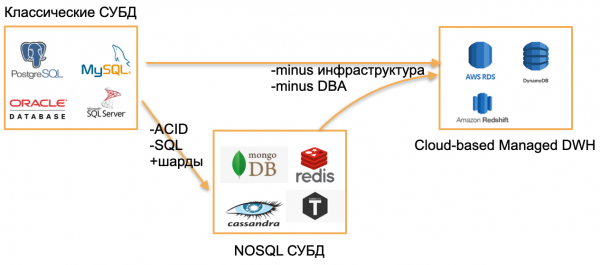
Det er 2020, jeg kiggede mig omkring og så tre typer BD.
Den første type er klassiske OLTP-databaserPostgreSQL, SQL Server, Oracle, MySQL. De blev skrevet for længe siden, men er stadig relevante, fordi de er velkendte i udviklingsmiljøet.
Den anden type er baser fra "nullerne". De forsøgte at bevæge sig væk fra klassiske mønstre ved at opgive SQL, traditionelle strukturer og ACID, ved at tilføje indbygget sharding og andre attraktive funktioner. For eksempel Cassandra, MongoDB, Redis eller Tarantool. Alle disse løsninger ønskede at tilbyde markedet noget fundamentalt nyt og fandt deres niche, fordi de viste sig at være yderst praktiske til bestemte opgaver. Jeg vil betegne disse databaser med paraplybetegnelsen NOSQL.
2000'erne er forbi, vi har vænnet os til NOSQL-databaser, og verden har, set fra mit synspunkt, taget det næste skridt - til administrerede databaser. Disse databaser har den samme kerne som klassiske OLTP-databaser eller nye NoSQL-databaser. Men de behøver ikke DBA og DevOps, og de kører på administreret hardware i skyerne. For udvikleren er det “bare en base”, der fungerer et sted, og ingen er interesserede i, hvordan den er installeret på serveren, hvem der har konfigureret serveren, og hvem der opdaterer den.
Eksempler på sådanne baser:
- AWS RDS er en administreret wrapper til PostgreSQL/MySQL.
- DynamoDB er en AWS-analog til en dokumentbaseret database, der minder om Redis og MongoDB.
- Amazon Redshift er en administreret analysedatabase.
Disse er grundlæggende gamle databaser, men oprettet i et administreret miljø uden behov for at arbejde med hardware.
Note. Eksemplerne er taget fra AWS-miljøet, men deres analoger findes også i Microsoft Azure, Google Cloud eller Yandex.Cloud.
Hvad er nyt ved dette? I 2020, intet af dette.
Serverløst koncept
Det, der virkelig er nyt på markedet i 2020, er serverløse løsninger.
Jeg vil forsøge at forklare, hvad dette betyder ved hjælp af eksemplet med en almindelig tjeneste eller backend-applikation.
For at implementere en almindelig backend-applikation køber eller lejer vi en server, kopierer koden til den, publicerer endpointen eksternt og betaler regelmæssigt for husleje, elektricitet og datacentertjenester. Dette er en standardordning.
Er der nogen anden måde? Med serverløse tjenester er det muligt.
Hvad er tricket ved denne tilgang: der er ingen server, ikke engang en virtuel instans til udlejning i skyen. For at implementere tjenesten kopierer vi koden (funktionerne) ind i repository'et og publicerer endpoint'et eksternt. Så betaler vi simpelthen for hvert kald til denne funktion og ignorerer fuldstændigt den hardware, hvor den udføres.
Jeg vil forsøge at illustrere denne fremgangsmåde med billeder.
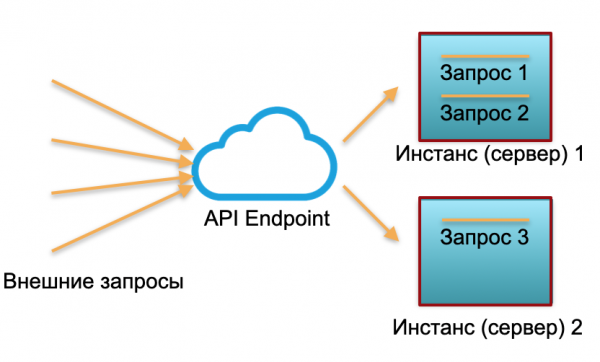
Klassisk implementering. Vi har en tjeneste med en bestemt belastning. Vi opretter to instanser: fysiske servere eller instanser i AWS. Eksterne anmodninger sendes til disse instanser og behandles der.
Som det fremgår af billedet, udnyttes serverne ikke ligeligt. Den ene er 100% udnyttet, der er to anmodninger, og den anden er kun 50% udnyttet - delvist inaktiv. Hvis der ikke kommer tre anmodninger ind, men 30, vil hele systemet ikke klare belastningen og begynde at blive langsommere.
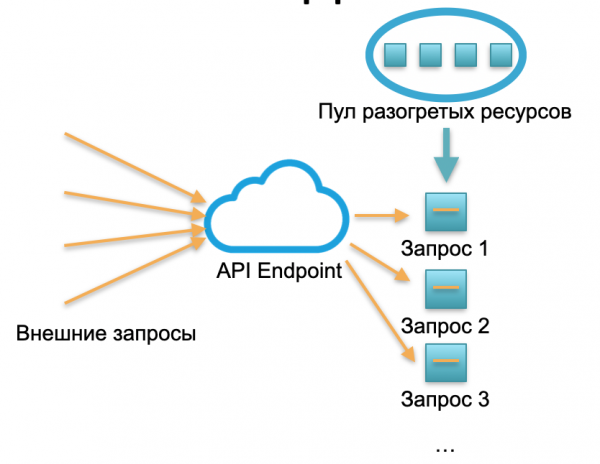
Serverløs implementering. I et serverløst miljø har en sådan tjeneste ingen instanser eller servere. Der er en pulje af opvarmede ressourcer - små forberedte Docker-containere med implementeret funktionskode. Systemet modtager eksterne anmodninger, og for hver af dem opretter det serverløse framework en lille container med kode: den behandler denne specifikke anmodning og afslutter containeren.
Én anmodning - én hævet container, 1000 anmodninger - 1000 containere. Og implementering på hardwareservere er allerede cloududbyderens arbejde. Det er fuldstændig skjult af det serverløse framework. I dette koncept betaler vi for hvert opkald. For eksempel, hvis der kom ét opkald på en dag, betalte vi for ét opkald; Hvis en million kom på et minut, betalte vi for en million. Eller om et sekund, sker det også.
Konceptet med at udgive en serverløs funktion er egnet til en tilstandsløs tjeneste. Og hvis du har brug for en (state) statefull-tjeneste, så tilføj en database til tjenesten. I dette tilfælde, når det kommer til at arbejde med state, skriver hver statefull-funktion blot til og læser fra databasen. Desuden fra en database over en af de tre typer beskrevet i begyndelsen af artiklen.
Hvad er den fælles begrænsning ved alle disse baser? Dette er omkostningerne ved en permanent anvendt cloud- eller hardwareserver (eller flere servere). Det er ligegyldigt, om vi bruger en klassisk eller administreret database, om der er Devops og en administrator eller ej, vi betaler stadig døgnet rundt for hardware, elektricitet og datacenterleje. Hvis vi har en klassisk base, betaler vi for master og slave. Hvis det er en meget belastet sharded database, betaler vi for 24, 7 eller 10 servere, og vi betaler konstant.
At have permanent reserverede servere i sin omkostningsstruktur blev tidligere opfattet som et nødvendigt onde. Konventionelle databaser har også andre vanskeligheder, såsom forbindelsesbegrænsninger, skaleringsbegrænsninger og geodistribueret konsensus - disse kan løses på en eller anden måde i visse databaser, men ikke alle på én gang og ikke ideelt set.
Serverløs database - Teori
Spørgsmål til 2020: Kan en database også gøres serverløs? Alle har hørt om serverløs backend ... lad os prøve at gøre databasen serverløs også?
Det lyder mærkeligt, fordi databasen er en statefull-tjeneste, hvilket ikke er særlig velegnet til en serverløs infrastruktur. Samtidig er databasens tilstand meget stor: gigabyte, terabyte og i analytiske databaser endda petabyte. Det er ikke så nemt at køre det i lette Docker-containere.
På den anden side er næsten alle moderne databaser en enorm mængde logik og komponenter: transaktioner, integritetsmatchning, procedurer, relationelle afhængigheder og en masse logik. En hel del databaselogik kræver en lille tilstand. Gigabyte og terabyte bruges kun direkte af en lille del af databaselogikken, der er relateret til den faktiske udførelse af forespørgsler.
Ideen er derfor: hvis en del af logikken tillader statsløs udførelse, hvorfor så ikke opdele basen i Stateful og Stateless dele.
Serverløs til OLAP-løsninger
Lad os se på, hvordan det kan se ud at opdele en database i Stateful og Stateless dele ved hjælp af praktiske eksempler.
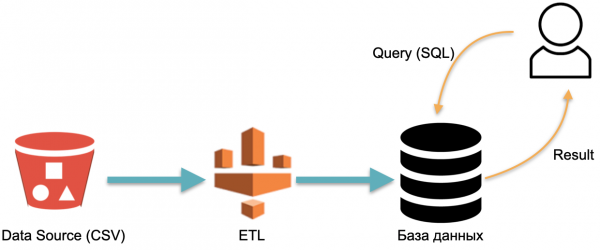
For eksempel har vi en analytisk database: eksterne data (rød cylinder til venstre), en ETL-proces, der indlæser dataene i databasen, og en analytiker, der sender SQL-forespørgsler til databasen. Dette er en klassisk datawarehouse-driftsordning.
I denne ordning udføres ETL betinget én gang. Så skal du konstant betale for de servere, som databasen med de ETL-fyldte data kører på, så der er noget at sende forespørgsler til.
Lad os se på en alternativ tilgang implementeret i AWS Athena Serverless-databasen. Der er ingen permanent dedikeret hardware, hvor downloadede data gemmes. I stedet:
- Brugeren sender en SQL-forespørgsel til Athena. Athena-optimeringsværktøjet analyserer SQL-forespørgslen og søger i metadatalagret efter de specifikke data, der er nødvendige for at udføre forespørgslen.
- Baseret på de indsamlede data downloader Optimizeren de nødvendige data fra eksterne kilder til midlertidig lagring (midlertidig database).
- En SQL-forespørgsel fra brugeren udføres i et midlertidigt lager, og resultatet returneres til brugeren.
- Midlertidig lagring ryddes, og ressourcer frigives.
I denne arkitektur betaler vi kun for processen med at udføre anmodningen. Ingen anmodninger - ingen udgifter.
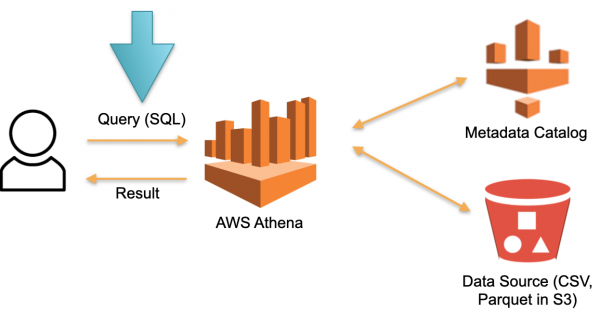
Dette er en fungerende tilgang og er implementeret ikke kun i Athena Serverless, men også i Redshift Spectrum (på AWS).
Athena-eksemplet viser, at den serverløse database fungerer på rigtige forespørgsler med tiere og hundreder af terabyte data. Hundredvis af terabyte ville kræve hundredvis af servere, men vi behøver ikke at betale for dem - vi betaler for anmodninger. Hastigheden på hver forespørgsel er (meget) lav sammenlignet med specialiserede analytiske databaser som Vertica, men vi betaler ikke for nedetidsperioder.
En sådan database er velegnet til sjældne ad hoc-analytiske forespørgsler. For eksempel når vi spontant beslutter at teste en hypotese på en gigantisk mængde data. I disse tilfælde er Athena ideel. For regelmæssige anmodninger er sådan et system dyrt. I dette tilfælde skal du cache dataene i en specialiseret løsning.
Serverløs til OLTP-løsninger
Det forrige eksempel omhandlede OLAP-opgaver (analytiske opgaver). Lad os nu se på OLTP-opgaver.
Lad os forestille os en skalerbar PostgreSQL eller MySQL. Lad os opsætte en almindelig administreret instans af PostgreSQL eller MySQL med minimale ressourcer. Når instansen modtager mere belastning, forbinder vi yderligere replikaer, som vi fordeler en del af læsebelastningen til. Hvis der ikke er nogen anmodninger eller indlæsning, deaktiverer vi replikaer. Den første instans er masteren, og resten er replikaer.
Denne idé er implementeret i et framework kaldet Aurora Serverless AWS. Princippet er enkelt: anmodninger fra eksterne applikationer modtages af proxy-flåden. Når den ser stigningen i belastning, allokerer den computerressourcer fra forvarmede minimumsinstanser - forbindelsen oprettes så hurtigt som muligt. Deaktivering af instanser sker på samme måde.
Inden for Aurora findes konceptet Aurora Capacity Unit, ACU. Dette er (betinget) en instans (server). Hver specifik ACU kan enten være en master eller en slave. Hver kapacitetsenhed har sin egen RAM, processor og minimumsdisk. Derfor er én en master, resten er skrivebeskyttede replikaer.
Antallet af disse kørende Aurora-kapacitetsenheder er en konfigurerbar parameter. Minimumsantallet kan være én eller nul (i hvilket tilfælde databasen ikke fungerer, hvis der ikke er nogen anmodninger).
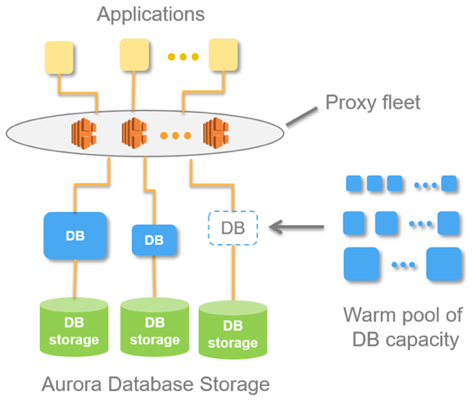
Når databasen modtager anmodninger, øger proxy-flåden Aurora CapacityUnits, hvilket øger systemets produktive ressourcer. Muligheden for at øge og mindske ressourcer gør det muligt for systemet at "jonglere" med ressourcer: automatisk trække individuelle ACU'er tilbage (erstatte dem med nye) og udrulle alle aktuelle opdateringer til de tilbagetrukne ressourcer.
Aurora Serverless-databasen kan skalere læseindlæsningen. Men dokumentationen siger ikke dette direkte. Det kan føles som om, de kan løfte en multimaster. Der er ingen magi.
Denne base er velegnet til at undgå at bruge enorme mængder penge på systemer med uforudsigelig adgang. For eksempel, når vi opretter MVP'er eller marketingwebsteder, forventer vi normalt ikke en stabil belastning. Hvis der derfor ikke er adgang, betaler vi ikke for instanser. Når der opstår uventet belastning, for eksempel efter en konference eller reklamekampagne, besøger store mængder mennesker stedet, og belastningen stiger kraftigt, overtager Aurora Serverless automatisk denne belastning og forbinder hurtigt de manglende ressourcer (ACU). Så går konferencen over, alle glemmer prototypen, serverne (ACU) går ud, og omkostningerne falder til nul - praktisk nok.
Denne løsning er ikke egnet til stabil høj belastning, fordi den ikke kan skalere skrivebelastningen. Alle disse forbindelser og afbrydelser af ressourcer sker på det såkaldte "skaleringspunkt" - et tidspunkt, hvor databasen ikke holdes af en transaktion, og midlertidige tabeller ikke holdes. For eksempel kan skalapunktet muligvis ikke forekomme i løbet af ugen, og basen fungerer på de samme ressourcer og kan simpelthen ikke udvide sig eller trække sig sammen.
Der er ingen magi - det er bare almindelig PostgreSQL. Men processen med at tilføje og frakoble maskiner er delvist automatiseret.
Serverløs design
Aurora Serverless er en gammel base, der er omskrevet til skyen for at drage fordel af nogle af fordelene ved Serverless. Nu vil jeg fortælle jer om grundlaget, som oprindeligt blev skrevet til clouds, for den serverløse tilgang — Serverless-by-design. Det blev oprindeligt udviklet uden antagelsen om, at det ville køre på fysiske servere.
Denne base kaldes Snefnug. Den har tre nøgleblokke.
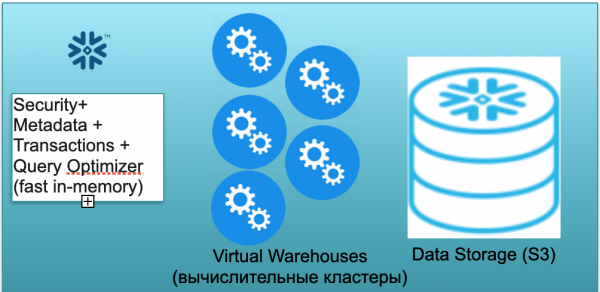
Den første er metadatablokken. Dette er en hurtig in-memory-tjeneste, der løser problemer med sikkerhed, metadata, transaktioner og forespørgselsoptimering (i illustrationen til venstre).
Den anden blok er et sæt virtuelle computerklynger til beregninger (i illustrationen - et sæt blå cirkler).
Den tredje blok er et datalagringssystem baseret på S3. S3 er AWS's one-size-fits-all objektlagring, lidt ligesom en one-size-fits-all Dropbox til virksomheder.
Lad os se, hvordan Snowflake fungerer, forudsat at det er en koldstart. Det vil sige, der er en database, data er indlæst i den, men der er ingen fungerende forespørgsler. Hvis der derfor ikke er nogen anmodninger til databasen, har vi en hurtig in-memory metadata-tjeneste (første blok) oppe og kørende. Og vi har S3-lagring, hvor tabeldataene er gemt, opdelt i såkaldte mikropartitioner. For enkelhedens skyld: Hvis tabellen indeholder transaktioner, er mikropartitioner transaktionsdagene. Hver dag er en separat mikropartition, en separat fil. Og når databasen fungerer i denne tilstand, betaler du kun for den plads, som dataene optager. Desuden er prisen pr. sæde meget lav (især i betragtning af den betydelige kompression). Metadatatjenesten fungerer også konstant, men det kræver ikke mange ressourcer at optimere forespørgsler, og tjenesten kan betragtes som betinget gratis.
Lad os nu forestille os, at en bruger kommer til vores database og sender en SQL-forespørgsel. SQL-forespørgslen sendes straks til metadatatjenesten til behandling. Når denne tjeneste modtager en anmodning, analyserer den derfor anmodningen, tilgængelige data og brugertilladelser, og hvis alt er i orden, udarbejder den en plan for behandling af anmodningen.
Tjenesten initierer derefter lanceringen af computerklyngen. En computerklynge er en klynge af servere, der udfører beregninger. Det vil sige, at det er en klynge, der kan indeholde 1 server, 2 servere, 4, 8, 16, 32 - så mange, som du ønsker. Du indsender en anmodning, og klyngen starter straks baseret på den. Det tager virkelig kun få sekunder.
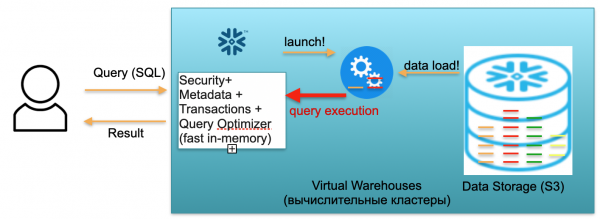
Derefter, efter at klyngen er startet, begynder de mikropartitioner, der er nødvendige for at behandle din specifikke anmodning, at blive kopieret fra S3 til klyngen. Det vil sige, lad os forestille os, at du har brug for to partitioner fra én tabel og en fra den anden for at udføre en SQL-forespørgsel. I dette tilfælde kopieres kun de tre nødvendige partitioner til klyngen, og ikke alle tabellerne som helhed. Det er netop derfor, og netop fordi alt er placeret i ét datacenter og forbundet via meget hurtige kanaler, at hele downloadprocessen sker meget hurtigt: på sekunder, meget sjældent på minutter, medmindre vi taler om nogle uhyrlige anmodninger. Derfor kopieres mikropartitionerne til beregningsklyngen, og når det er færdigt, udføres SQL-forespørgslen på den pågældende beregningsklynge. Resultatet af denne forespørgsel kan være én række, flere rækker eller en tabel - de sendes ud til brugeren, så han kan downloade, vise i sit BI-værktøj eller bruge dem på en anden måde.
Hver SQL-forespørgsel kan ikke kun læse aggregater fra tidligere indlæste data, men også indlæse/danne nye data i databasen. Det vil sige, at det kunne være en forespørgsel, der for eksempel indsætter nye poster i en anden tabel, hvilket resulterer i, at der vises en ny partition på computerklyngen, som igen automatisk gemmes i et enkelt S3-lager.
Scenariet beskrevet ovenfor, fra brugerens ankomst til klyngens opståen, indlæsning af data, udførelse af forespørgsler, modtagelse af resultater, betales med den sats, der gælder pr. minut for brugen af den opbyggede virtuelle databehandlingsklynge, det virtuelle lager. Priserne varierer afhængigt af AWS-zonen og klyngestørrelsen, men i gennemsnit er det et par dollars i timen. En klynge på fire biler er dobbelt så dyr som en klynge på to biler, og en klynge på otte biler er dobbelt så dyr. Der er mulighed for at vælge mellem 16 og 32 maskiner, afhængigt af anmodningernes kompleksitet. Men du betaler kun for de minutter, hvor klyngen rent faktisk kører, for når der ikke er nogen anmodninger, slipper du bare for det, og efter 5-10 minutters ventetid (konfigurerbar parameter) slukker den sig selv, frigør ressourcer og bliver ledig.
Det er et fuldstændig realistisk scenarie, når du sender en anmodning, og klyngen dukker op, f.eks. om et minut, tæller i et minut mere, så tager det fem minutter at lukke ned, og du ender med at betale for syv minutters drift af denne klynge, og ikke for måneder og år.
Det første scenarie beskrev brugen af Snowflake i et enkeltbrugermiljø. Lad os nu forestille os, at der er mange brugere, hvilket er tættere på det virkelige scenarie.
Lad os sige, at vi har en masse analytikere og Tableau-rapporter, der konstant bombarderer vores database med en masse simple analytiske SQL-forespørgsler.
Derudover, lad os sige, at vi har opfindsomme dataforskere, der forsøger at gøre uhyrlige ting med data, opererer på snesevis af terabyte, analyserer milliarder og billioner af rækker af data.
For de to typer arbejdsbyrder beskrevet ovenfor giver Snowflake dig mulighed for at køre flere uafhængige computerklynger med varierende kapacitet. Desuden opererer disse databehandlingsklynger uafhængigt, men med fælles, konsistente data.
For et stort antal lette forespørgsler kan du oprette 2-3 små klynger, der hver er cirka 2 maskiner i størrelse. Denne adfærd kan blandt andet implementeres ved hjælp af automatiske indstillinger. Så du siger: "Snefnug, løft en lille klynge. Hvis belastningen på den stiger mere end en bestemt parameter, løft den anden, tredje på samme måde. Når belastningen begynder at falde, sluk for overskuddet." Så uanset hvor mange analytikere der kommer og begynder at kigge på rapporter, har alle nok ressourcer.
Samtidig, hvis analytikerne sover, og ingen kigger på rapporterne, kan klyngerne forsvinde helt, og du holder op med at betale for dem.
Samtidig kan du for tunge forespørgsler (fra dataloger) oprette en meget stor klynge på betingede 32 maskiner. Denne klynge vil også kun blive betalt for de minutter og timer, hvor din gigantiske forespørgsel kører der.
Den ovenfor beskrevne funktion giver dig mulighed for at opdele ikke kun 2, men også flere typer belastninger i klynger (ETL, overvågning, rapportmaterialisering osv.).
Lad os opsummere Snowflake. Grundlaget kombinerer en smuk idé og en fungerende implementering. Hos ManyChat bruger vi Snowflake til at analysere alle vores data. Vi har ikke tre klynger, som i eksemplet, men fra 5 til 9 i forskellige størrelser. Vi har betingede 16-maskiner, 2-maskiner, og der er også supersmå 1-maskiner til bestemte opgaver. De fordeler belastningen med succes og giver os mulighed for at spare meget.
Databasen skalerer læse- og skrivebelastningen. Dette er en kæmpe forskel og et kæmpe gennembrud sammenlignet med den samme Aurora, som kun håndterede læsebelastningen. Snowflake giver dig mulighed for at skalere din skrivearbejdsbyrde på tværs af disse beregningsklynger. Så, som jeg nævnte, har vi flere klynger i ManyChat, små og supersmå klynger bruges primært til ETL, til indlæsning af data. Og analytikere lever allerede på mellemstore klynger, som absolut ikke påvirkes af ETL-belastningen, så de arbejder meget hurtigt.
Derfor er databasen velegnet til OLAP-opgaver. Desværre er det endnu ikke relevant for OLTP-indlæsninger. For det første er dette en søjleformet base med alle de deraf følgende konsekvenser. For det andet er selve tilgangen, hvor man for hver anmodning opretter en computerklynge efter behov og oversvømmer den med data, desværre endnu ikke hurtig nok til OLTP-indlæsninger. Sekunders ventetid på OLAP-opgaver er normalt, men for OLTP-opgaver er det uacceptabelt. 100 ms ville være bedre, og endnu bedre - 10 ms.
Total
En serverløs database er mulig ved at opdele databasen i Stateless og Stateful dele. Du har måske bemærket, at i alle de givne eksempler lagrer Stateful-delen så at sige mikropartitioner i S3, og Stateless-delen er optimeringsværktøjet, der arbejder med metadata og håndterer sikkerhedsproblemer, der kan opstå som uafhængige, lette Stateless-tjenester.
SQL-forespørgsler kan også betragtes som lette tilstandstjenester, der kan dukke op i serverløs tilstand, ligesom Snowflakes computerklynger, kun downloade de data, de har brug for, udføre forespørgslen og "gå i darkness".
Serverløse databaser i produktionskvalitet er allerede tilgængelige til brug, og de fungerer. Disse serverløse databaser er allerede klar til at håndtere OLAP-opgaver. Desværre bruges de til OLTP-opgaver ... med nuancer, da der er begrænsninger. På den ene side er dette et minus. Men på den anden side er det en mulighed. Måske finder en af læserne en måde at gøre en OLTP-database fuldstændig serverløs, uden Aurora-begrænsninger.
Jeg håber, du fandt det interessant. Serverløs er fremtiden 🙂
Kilde: www.habr.com
