


Forord
Der findes et så simpelt og meget nyttigt værktøj i verden - , og det skete sådan, at den havde været en del af vores produktionsproces i meget lang tid (selvom vi ikke var i stand til at fastslå dens version, var den bestemt ikke den nyeste tilgængelige). Vi bruger det til dets tilsigtede formål - at bygge binære patches. Hvis man ser på, hvad der er i arkivet, bliver det lidt trist: faktisk blev det forladt for længe siden, og meget af det er meget forældet (min tidligere kollega lavede engang adskillige redigeringer der, men det er længe siden). Generelt besluttede jeg at genoplive denne ting: Jeg forkede, smed det ud, jeg ikke planlægger at bruge, og flyttede projektet til , indlejrede "hotte" mikrofunktioner, fjernede store arrays fra stakken (og arrays med variabel længde, som ærligt talt "pumpede" mig), kørte profileren igen - og fandt ud af, at omkring 40% af tiden bruges på ...
Så hvad er der galt med fwrite?
I denne kode kaldes fwrite (i mit specifikke testcase: opbygning af en programrettelse mellem tætliggende 300 MB-filer, inputdata udelukkende i hukommelsen) millioner af gange med en lille buffer. Det er indlysende, at det her vil aftage, og derfor vil jeg gerne på en eller anden måde påvirke denne skændsel. Der er endnu ikke noget ønske om at implementere forskellige typer datakilder eller asynkron input/output; Jeg vil gerne finde en enklere løsning. Det første, der faldt mig ind, var at øge bufferstørrelsen.
setvbuf(file, nullptr, _IOFBF, 64* 1024)men jeg oplevede ingen væsentlig forbedring i resultatet (nu tegnede fwrite sig for omkring 37% af tiden) – så problemet ligger ikke i hyppig skrivning af data til disk. Hvis man kigger "under motorhjelmen" på fwrite, kan man se, at låsning/oplåsning af FILE-strukturen sker i noget i retning af dette (pseudokode, al analyse blev udført under Visual Studio 2017):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream)
{
size_t retval = 0;
_lock_str(stream); /* lock stream */
__try
{
retval = _fwrite_nolock(buffer, size, count, stream);
}
__finally
{
_unlock_str(stream); /* unlock stream */
}
return retval;
}
Ifølge profileren tegner _fwrite_nolock sig kun for 6% af tiden, resten er overhead. I mit specifikke tilfælde er trådsikkerhed klart overflødig, så jeg vil ofre den ved at erstatte fwrite-kaldet med — der er ingen grund til at være smart med argumenter. I alt reducerede denne simple manipulation omkostningerne ved at registrere resultatet flere gange, hvilket i den originale version tegnede sig for næsten halvdelen af den brugte tid. Forresten, der er en lignende funktion i POSIX-verdenen - . Generelt set gælder det samme for fread. Ved at bruge et par #define'er kan du således få en fuldstændig tværplatformsløsning uden unødvendige låse, i tilfælde af at de ikke er nødvendige (og dette sker ret ofte).
fwrite, _fwrite_nolock, setvbuf
Lad os bevæge os væk fra det oprindelige projekt og fokusere på at teste et specifikt tilfælde: at skrive en stor fil (512 MB) i ekstremt små bidder – én byte hver. Testsystem: AMD Ryzen 7 1700, 16 GB RAM, 7200 rpm harddisk, 64 MB cache. Windows 10 1809, den binære fil blev bygget som 32-bit, optimeringer er aktiveret, og biblioteket er statisk linket.
Prøve til eksperimentet:
#include <chrono>
#include <cstdio>
#include <inttypes.h>
#include <memory>
#ifdef _MSC_VER
#define fwrite_unlocked _fwrite_nolock
#endif
using namespace std::chrono;
int main()
{
std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose);
if (!file)
return 1;
constexpr size_t TEST_BUFFER_SIZE = 256 * 1024;
if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0)
return 2;
auto start = steady_clock::now();
const uint8_t b = 77;
constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024;
for (size_t i = 0; i < TEST_FILE_SIZE; ++i)
fwrite_unlocked(&b, 1, sizeof(b), file.get());
auto end = steady_clock::now();
auto interval = duration_cast<microseconds>(end - start);
printf("Time: %lldn", interval.count());
return 0;
}
Variablerne vil være TEST_BUFFER_SIZE, og i et par tilfælde vil vi erstatte fwrite_unlocked med fwrite. Lad os starte med fwrite-tilfældet uden eksplicit at indstille bufferstørrelsen (kommenter setvbuf og den tilhørende kode ud): tid 27048906 µs, skrivehastighed 18.93 MB/s. Lad os nu indstille bufferstørrelsen til 64 KB: tid - 25037111 µs, hastighed - 20.44 Mbps. Lad os nu teste _fwrite_nolocks funktion uden at kalde setvbuf: 7262221 µs, hastighed - 70.5 Mb/s!
Lad os derefter eksperimentere med bufferstørrelsen (setvbuf):
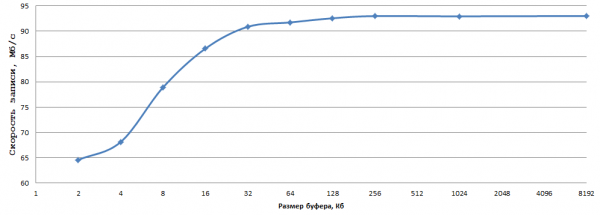
Dataene blev opnået ved at gennemsnittet af 5 eksperimenter; Jeg var for doven til at beregne fejlene. Efter min mening er 93 MB/s, når man skriver 1 byte til en almindelig harddisk, et rigtig godt resultat. Alt du skal gøre er at vælge den optimale bufferstørrelse (i mit tilfælde er 256 KB lige præcis passende) og erstatte fwrite med _fwrite_nolock/fwrite_unlocked (hvis du ikke har brug for trådsikkerhed, selvfølgelig).
Det er det samme med fread under lignende forhold. Da jeg ikke har en hardwaremaskine med Linux ved hånden (computere med én bundkort tæller ikke), besluttede jeg at udføre et begrænset eksperiment på en virtuel maskine (Hyper-V, OpenSUSE 15, GCC 8.3.1) — mønsteret er stort set det samme: bare fwrite 20 Mb/s, fwrite + 256 KB buffer gav 23 Mb/s, fwrite_unlocked med den samme buffer — 35 Mb/s (64-bit binær, kompileret med g++ -o2 -s -static-libgcc -static-libstdc++ fwrite_test.cpp -o fwrite_test).
efterskrift
Formålet med at skrive denne artikel var at beskrive en simpel og effektiv teknik i mange tilfælde (jeg har aldrig stødt på _fwrite_nolock/fwrite_unlocked-funktionerne før, de er ikke særlig populære - og forgæves). Jeg påstår ikke, at materialet er nyt, men jeg håber, at artiklen vil være nyttig for fællesskabet.
Kilde: www.habr.com
