


Artiklen beskriver, hvordan man implementerer WMS-system, stod vi over for behovet for at løse et ikke-standardiseret klyngeproblem, og hvilke algoritmer vi brugte til at løse det. Vi vil fortælle dig, hvordan vi anvendte en systematisk, videnskabelig tilgang til at løse problemet, hvilke vanskeligheder vi stødte på, og hvilke erfaringer vi lærte.
Denne publikation indleder en række artikler, hvori vi deler vores succesfulde erfaring med implementering af optimeringsalgoritmer i lagerprocesser. Formålet med serien af artikler er at gøre publikum bekendt med de typer af optimeringsproblemer af lagerdrift, der opstår i næsten alle mellemstore og store varehuse, samt at fortælle om vores erfaring med at løse sådanne problemer og de faldgruber, man støder på undervejs. . Artiklerne vil være nyttige for dem, der arbejder i lagerlogistikbranchen, implementere WMS-systemer, samt programmører, der er interesserede i anvendelser af matematik i erhvervslivet og optimering af processer i en virksomhed.
Flaskehals i processer
I 2018 afsluttede vi et projekt, der skulle implementeres WMS-systemer på lageret i virksomheden “Trading House “LD” i Chelyabinsk. Vi implementerede produktet "1C-Logistics: Warehouse Management 3" til 20 arbejdspladser: operatører WMS, lagerholdere, gaffeltruckchauffører. Det gennemsnitlige lager er omkring 4 tusinde m2, antallet af celler er 5000 og antallet af SKU'er er 4500. Lageret opbevarer kugleventiler af vores egen produktion i forskellige størrelser fra 1 kg til 400 kg. Beholdningen på lageret opbevares i partier, da der er behov for at udvælge varer efter FIFO.
Ved design af lagerprocesautomatiseringsordninger stod vi over for det eksisterende problem med ikke-optimal lageropbevaring. Specifikationerne for opbevaring og stuvning af kraner er sådan, at en enhedslagercelle kun kan indeholde varer fra én batch. Produkter ankommer til lageret dagligt, og hver ankomst er en separat batch. I alt, som et resultat af 1 måneds lagerdrift, oprettes 30 separate batches, på trods af at hver skal opbevares i en separat celle. Produkter udvælges ofte ikke i hele paller, men i stykker, og som følge heraf ses følgende billede i stykvalgszonen i mange celler: I en celle med et volumen på mere end 1 m3 er der flere stykker kraner, som optager mindre end 5-10% af cellevolumenet.
 Fig 1. Foto af flere stykker varer i en celle
Fig 1. Foto af flere stykker varer i en celle
Det er tydeligt, at lagerkapaciteten ikke bliver udnyttet optimalt. For at forestille mig omfanget af katastrofen kan jeg give tal: I gennemsnit er der fra 1 til 3 celler af sådanne celler med et volumen på mere end 100 m300 med "minuskulære" balancer i forskellige perioder af lagerets drift. Da lageret er relativt lille, bliver denne faktor i de travle sæsoner på lageret en "flaskehals" og bremser lagerprocesserne kraftigt.
Idé til problemløsning
En idé opstod: partier af rester med de nærmeste datoer skulle reduceres til én enkelt batch, og sådanne rester med en samlet batch skulle placeres kompakt sammen i én celle eller i flere, hvis der ikke er plads nok i én til at rumme hele mængden af rester.
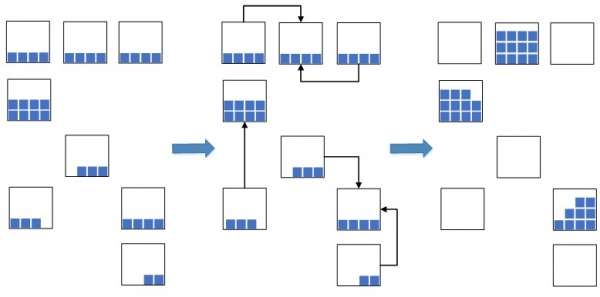
Fig.2. Skema til komprimering af rester i celler
Dette giver dig mulighed for betydeligt at reducere den besatte lagerplads, der vil blive brugt til nye varer, der placeres. I en situation, hvor lagerkapaciteten er overbelastet, er en sådan foranstaltning yderst nødvendig, ellers kan der simpelthen ikke være nok ledig plads til at rumme nye varer, hvilket vil føre til et stop i lagerplacering og genopfyldningsprocesser. Tidligere før implementering WMS-systemer udførte denne operation manuelt, hvilket var ineffektivt, da processen med at søge efter passende rester i cellerne var ret lang. Nu, med introduktionen af et WMS-system, besluttede vi at automatisere processen, fremskynde den og gøre den intelligent.
Processen med at løse et sådant problem er opdelt i 2 faser:
- i det første trin finder vi grupper af batches tæt på dato for komprimering;
- i anden fase beregner vi for hver gruppe af partier den mest kompakte placering af de resterende varer i cellerne.
I den aktuelle artikel vil vi fokusere på den første fase af algoritmen og lade dækningen af den anden fase blive til den næste artikel.
Søg efter en matematisk model af problemet
Før vi satte os ned for at skrive kode og genopfinde vores hjul, besluttede vi at gribe dette problem videnskabeligt an, nemlig: formulere det matematisk, reducere det til et velkendt diskret optimeringsproblem og bruge effektive eksisterende algoritmer til at løse det, eller tage disse eksisterende algoritmer som grundlag og modificere dem til detaljerne i det praktiske problem, der skal løses.
Da det klart følger af problemformuleringens forretningsmæssige formulering, at vi har med mængder at gøre, vil vi formulere en sådan problemstilling ud fra mængdelære.
Lad  – sættet af alle partier af resten af et bestemt produkt på et lager. Lade
– sættet af alle partier af resten af et bestemt produkt på et lager. Lade  – givet konstant af dage. Lade
– givet konstant af dage. Lade  – en delmængde af batches, hvor forskellen i datoer for alle par af batches i delmængden ikke overstiger en konstant
– en delmængde af batches, hvor forskellen i datoer for alle par af batches i delmængden ikke overstiger en konstant  . Vi skal finde det mindste antal usammenhængende delmængder
. Vi skal finde det mindste antal usammenhængende delmængder  , sådan at alle delmængder
, sådan at alle delmængder  tilsammen ville give mange
tilsammen ville give mange  .
.
Vi skal med andre ord finde grupper eller klynger af lignende parter, hvor lighedskriteriet er bestemt af konstanten  . Denne opgave minder os om det velkendte klyngeproblem. Det er vigtigt at sige, at problemet under overvejelse adskiller sig fra klyngeproblemet ved, at vores problem har en strengt defineret betingelse for kriteriet om lighed mellem klyngeelementer, bestemt af den konstante
. Denne opgave minder os om det velkendte klyngeproblem. Det er vigtigt at sige, at problemet under overvejelse adskiller sig fra klyngeproblemet ved, at vores problem har en strengt defineret betingelse for kriteriet om lighed mellem klyngeelementer, bestemt af den konstante  , men i klyngeproblemet er der ingen sådan betingelse. Redegørelsen af klyngeproblemet og oplysninger om dette problem kan findes
, men i klyngeproblemet er der ingen sådan betingelse. Redegørelsen af klyngeproblemet og oplysninger om dette problem kan findes
Så det lykkedes os at formulere problemet og finde et klassisk problem med en lignende formulering. Nu er det nødvendigt at overveje velkendte algoritmer til at løse det, for ikke at genopfinde hjulet, men for at tage den bedste praksis og anvende dem. For at løse klyngeproblemet overvejede vi de mest populære algoritmer, nemlig:  -midler,
-midler,  -midler, algoritme til at identificere forbundne komponenter, minimum spændingstræ-algoritme. En beskrivelse og analyse af sådanne algoritmer kan findes
-midler, algoritme til at identificere forbundne komponenter, minimum spændingstræ-algoritme. En beskrivelse og analyse af sådanne algoritmer kan findes
For at løse vores problem, klynge algoritmer  - betyder og
- betyder og  -midler er slet ikke anvendelige, da antallet af klynger aldrig kendes på forhånd
-midler er slet ikke anvendelige, da antallet af klynger aldrig kendes på forhånd  og sådanne algoritmer tager ikke højde for den konstante dages begrænsning. Sådanne algoritmer blev oprindeligt kasseret fra overvejelse.
og sådanne algoritmer tager ikke højde for den konstante dages begrænsning. Sådanne algoritmer blev oprindeligt kasseret fra overvejelse.
For at løse vores problem er algoritmen til at identificere forbundne komponenter og minimum spanning tree-algoritmen mere egnede, men som det viste sig, kan de ikke anvendes "head-on" på det problem, der skal løses, og opnå en god løsning. For at forklare dette, lad os overveje logikken i driften af sådanne algoritmer i forhold til vores problem.
Overvej grafen  , hvor hjørnerne er sættet af partier
, hvor hjørnerne er sættet af partier  , og kanten mellem hjørnerne
, og kanten mellem hjørnerne  и
и  har en vægt svarende til forskellen på dage mellem batch
har en vægt svarende til forskellen på dage mellem batch  и
и  . I algoritmen til at identificere tilsluttede komponenter er inputparameteren angivet
. I algoritmen til at identificere tilsluttede komponenter er inputparameteren angivet  Hvor
Hvor  , og i grafen
, og i grafen  alle kanter, hvor vægten er større, fjernes
alle kanter, hvor vægten er større, fjernes  . Kun de nærmeste par af objekter forbliver forbundet. Pointen med algoritmen er at vælge en sådan værdi
. Kun de nærmeste par af objekter forbliver forbundet. Pointen med algoritmen er at vælge en sådan værdi  , hvor grafen "falder fra hinanden" i flere forbundne komponenter, hvor parterne, der tilhører disse komponenter, vil opfylde vores lighedskriterium, bestemt af konstanten
, hvor grafen "falder fra hinanden" i flere forbundne komponenter, hvor parterne, der tilhører disse komponenter, vil opfylde vores lighedskriterium, bestemt af konstanten  . De resulterende komponenter er klynger.
. De resulterende komponenter er klynger.
Minimumspændingstræ-algoritmen bygger først på en graf  minimum spanning tree, og derefter sekventielt fjerner kanter med den højeste vægt, indtil grafen "falder fra hinanden" i flere forbundne komponenter, hvor parterne, der tilhører disse komponenter, også vil opfylde vores lighedskriterium. De resulterende komponenter vil være klynger.
minimum spanning tree, og derefter sekventielt fjerner kanter med den højeste vægt, indtil grafen "falder fra hinanden" i flere forbundne komponenter, hvor parterne, der tilhører disse komponenter, også vil opfylde vores lighedskriterium. De resulterende komponenter vil være klynger.
Når man bruger sådanne algoritmer til at løse det pågældende problem, kan der opstå en situation som i figur 3.
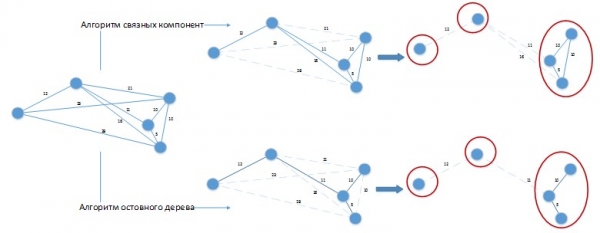
Fig. 3. Anvendelse af klyngealgoritmer til det problem, der skal løses
Lad os sige, at vores konstant for forskellen mellem batchdage er 20 dage. Kurve  blev afbildet i rumlig form for at lette visuel opfattelse. Begge algoritmer producerede en 3-klynge løsning, som nemt kan forbedres ved at kombinere batchene placeret i separate klynger med hinanden! Det er indlysende, at sådanne algoritmer skal modificeres for at passe til det specifikke problem, der løses, og deres anvendelse i sin rene form til løsningen af vores problem vil give dårlige resultater.
blev afbildet i rumlig form for at lette visuel opfattelse. Begge algoritmer producerede en 3-klynge løsning, som nemt kan forbedres ved at kombinere batchene placeret i separate klynger med hinanden! Det er indlysende, at sådanne algoritmer skal modificeres for at passe til det specifikke problem, der løses, og deres anvendelse i sin rene form til løsningen af vores problem vil give dårlige resultater.

Så før vi begyndte at skrive kode til grafalgoritmer modificeret til vores opgave og genopfinde vores egen cykel (i hvis silhuetter vi allerede kunne skelne konturerne af firkantede hjul), besluttede vi igen at nærme os et sådant problem videnskabeligt, nemlig: prøv at reducere det til en anden diskret problemoptimering i håb om, at eksisterende algoritmer til at løse det kan anvendes uden ændringer.
Endnu en søgning efter et lignende klassisk problem har været vellykket! Det lykkedes os at finde et diskret optimeringsproblem, hvis formulering falder 1 i 1 sammen med formuleringen af vores problem. Denne opgave viste sig at være sæt dækningsproblem. Lad os præsentere problemformuleringen i forhold til vores detaljer.
Der er et begrænset sæt  og familie
og familie  af alle dets usammenhængende delmængder af parter, således at forskellen i datoer for alle par af parter i hver delmængde
af alle dets usammenhængende delmængder af parter, således at forskellen i datoer for alle par af parter i hver delmængde  fra familien
fra familien  ikke overstiger konstanter
ikke overstiger konstanter  . En dækning kaldes en familie
. En dækning kaldes en familie  af den mindste magt, hvis elementer hører til
af den mindste magt, hvis elementer hører til  , sådan at foreningen af sæt
, sådan at foreningen af sæt  fra familien
fra familien  bør give sæt af alle parter
bør give sæt af alle parter  .
.
En detaljeret analyse af dette problem kan findes и Andre muligheder for den praktiske anvendelse af dækningsproblemet og dets modifikationer kan findes
Algoritme til at løse problemet
Vi har besluttet os for den matematiske model for det problem, der skal løses. Lad os nu se på algoritmen til at løse det. Undersæt  fra familien
fra familien  kan nemt findes ved følgende procedure.
kan nemt findes ved følgende procedure.
- Arranger batches fra et sæt
 i faldende rækkefølge efter deres datoer.
i faldende rækkefølge efter deres datoer. - Find minimum og maksimum batchdatoer.
- For hver dag fra minimumsdatoen til maksimum, find alle batches, hvis datoer afviger fra ikke mere end (altså værdien Det er bedre at tage det lige tal).
 i faldende rækkefølge efter deres datoer.
i faldende rækkefølge efter deres datoer. fra minimumsdatoen til maksimum, find alle batches, hvis datoer afviger fra
fra minimumsdatoen til maksimum, find alle batches, hvis datoer afviger fra  ikke mere end
ikke mere end  (altså værdien
(altså værdien  Det er bedre at tage det lige tal).
Det er bedre at tage det lige tal). Logikken i proceduren til at danne en familie af sæt  при
при  dage er vist i figur 4.
dage er vist i figur 4.

Fig.4. Dannelse af undergrupper af partier
Denne procedure er ikke nødvendig for alle  gå gennem alle andre batches og kontroller forskellen i deres datoer eller fra den aktuelle værdi
gå gennem alle andre batches og kontroller forskellen i deres datoer eller fra den aktuelle værdi  flyt til venstre eller højre, indtil du finder en batch, hvis dato er forskellig fra
flyt til venstre eller højre, indtil du finder en batch, hvis dato er forskellig fra  med mere end halvdelen af værdien af konstanten. Alle efterfølgende elementer, når de flyttes både til højre og venstre, vil ikke være interessante for os, da forskellen i dage kun vil stige for dem, da elementerne i arrayet oprindeligt blev bestilt. Denne tilgang vil betydeligt spare tid, når antallet af fester og spredningen af deres datoer er væsentligt stort.
med mere end halvdelen af værdien af konstanten. Alle efterfølgende elementer, når de flyttes både til højre og venstre, vil ikke være interessante for os, da forskellen i dage kun vil stige for dem, da elementerne i arrayet oprindeligt blev bestilt. Denne tilgang vil betydeligt spare tid, når antallet af fester og spredningen af deres datoer er væsentligt stort.
Sættets dækningsproblem er  -svært, hvilket betyder, at der ikke er nogen hurtig (med driftstid svarende til et polynomium af inputdataene) og nøjagtig algoritme til at løse det. Derfor blev der valgt en hurtig grådig algoritme for at løse det sæt dækkende problem, som selvfølgelig ikke er nøjagtig, men har følgende fordele:
-svært, hvilket betyder, at der ikke er nogen hurtig (med driftstid svarende til et polynomium af inputdataene) og nøjagtig algoritme til at løse det. Derfor blev der valgt en hurtig grådig algoritme for at løse det sæt dækkende problem, som selvfølgelig ikke er nøjagtig, men har følgende fordele:
- For små problemer (og det er netop vores tilfælde) beregner den løsninger, der er ret tæt på det optimale. Efterhånden som problemets størrelse øges, forringes kvaliteten af løsningen, men stadig ret langsomt;
- Meget let at implementere;
- Hurtig, da dens køretidsestimat er .
 .
.Den grådige algoritme udvælger sæt baseret på følgende regel: På hvert trin vælges et sæt, der dækker det maksimale antal elementer, der endnu ikke er dækket. En detaljeret beskrivelse af algoritmen og dens pseudokode kan findes
En sammenligning af nøjagtigheden af en sådan grådig algoritme på testdata af problemet, der løses, med andre kendte algoritmer, såsom den sandsynlige grådige algoritme, myrekolonialgoritmen osv., er ikke blevet foretaget. Resultaterne af at sammenligne sådanne algoritmer på genererede tilfældige data kan findes
Implementering og implementering af algoritmen
Denne algoritme blev implementeret i sproget 1С og indgik i en ekstern behandling kaldet "Residue Compression", som var forbundet med WMS-system. Vi implementerede ikke algoritmen i sproget C++ og brug det fra en ekstern Native-komponent, hvilket ville være mere korrekt, da kodens hastighed er lavere C + + gange og i nogle eksempler endda titusinder gange hurtigere end hastigheden af lignende kode på 1С. På tungen 1С Algoritmen blev implementeret for at spare udviklingstid og nem fejlfinding i kundens produktionsbase. Resultatet af algoritmen er vist i figur 5.
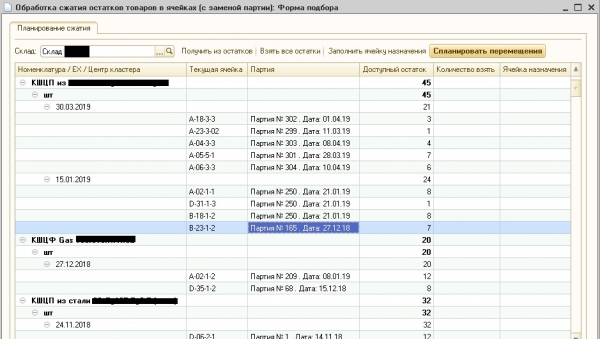
Fig.5. Behandling for at "komprimere" rester
Figur 5 viser, at i det angivne lager er de aktuelle saldi af varer i lagerceller opdelt i klynger, inden for hvilke datoerne for varepartierne afviger fra hinanden med højst 30 dage. Da kunden producerer og opbevarer metalkugleventiler på lageret, hvis holdbarhed er beregnet i år, kan en sådan datoforskel negligeres. Bemærk, at en sådan forarbejdning i øjeblikket bruges systematisk i produktion og operatører WMS bekræfte den gode kvalitet af festklynger.
Konklusioner og fortsættelse
Den vigtigste erfaring, vi fik fra at løse et sådant praktisk problem, er bekræftelse af effektiviteten af at bruge paradigmet: matematik. problemformulering  berømt måtte. model
berømt måtte. model  berømte algoritme
berømte algoritme  algoritme, der tager højde for problemets detaljer. Diskret optimering har eksisteret i mere end 300 år, og i løbet af denne tid har folk formået at overveje en masse problemer og akkumulere en masse erfaring med at løse dem. Først og fremmest er det mere tilrådeligt at vende sig til denne oplevelse, og først derefter begynde at genopfinde dit hjul.
algoritme, der tager højde for problemets detaljer. Diskret optimering har eksisteret i mere end 300 år, og i løbet af denne tid har folk formået at overveje en masse problemer og akkumulere en masse erfaring med at løse dem. Først og fremmest er det mere tilrådeligt at vende sig til denne oplevelse, og først derefter begynde at genopfinde dit hjul.
I den næste artikel vil vi fortsætte historien om optimeringsalgoritmer og se på det mest interessante og meget mere komplekse: en algoritme til optimal "komprimering" af cellerester, som bruger data modtaget fra batch-klyngealgoritmen som input.
Forberedte artiklen
Roman Shangin, programmør for projektafdelingen,
Første BIT-selskab, Chelyabinsk
Kilde: www.habr.com
