

Zunächst einmal ist es wichtig, ein neues Datenset zu verstehen. Um dies zu erreichen, sollte man unter anderem die Wertebereiche der Variablen, deren Typen sowie die Anzahl fehlender Werte ermitteln.
Die Bibliothek pandas bietet eine Vielzahl nützlicher Werkzeuge für die Durchführung von Exploratory Data Analysis (EDA). Bevor man jedoch zu diesen fortschrittlicheren Funktionen greift, beginnt man gewöhnlich mit allgemeineren Funktionen wie df.describe(). Es ist jedoch wichtig zu beachten, dass die Möglichkeiten dieser Funktionen begrenzt sind und die ersten Schritte bei der Arbeit mit Datensets in der Regel sehr ähnlich sind.
Der Autor des Materials, das wir heute veröffentlichen, ist kein Fan von sich wiederholenden Aufgaben. Auf der Suche nach Mitteln, um Exploratory Data Analysis schnell und effizient durchzuführen, hat er die Bibliothek gefunden. . Die Ergebnisse dieser Arbeit werden nicht in Form einzelner Kennzahlen, sondern in einem ausführlichen HTML-Bericht dargestellt, der die meisten Informationen über die analysierten Daten enthält, die man wissen sollte, bevor man mit intensiveren Arbeiten an ihnen beginnt.
Hier werden die Besonderheiten der Verwendung der Bibliothek pandas-profiling am Beispiel des Titanic-Datensatzes erläutert.
Explorative Datenanalyse mit pandas
Ich habe beschlossen, mit pandas-profiling am Titanic-Datensatz zu experimentieren, da er Daten verschiedener Typen enthält und auch fehlende Werte aufweist. Ich glaube, dass die pandas-profiling-Bibliothek besonders interessant ist, wenn die Daten noch nicht bereinigt sind und eine weitere Bearbeitung erforderlich ist, die von ihren Eigenschaften abhängt. Um diese Bearbeitung erfolgreich durchzuführen, ist es wichtig zu wissen, wo man beginnen sollte und worauf man achten muss. Hier kommen die Möglichkeiten von pandas-profiling ins Spiel.
Zunächst importieren wir die Daten und verwenden pandas, um Kennzahlen der deskriptiven Statistik zu erhalten:
# импорт необходимых пакетов
import pandas as pd
import pandas_profiling
import numpy as np
# импорт данных
df = pd.read_csv('/Users/lukas/Downloads/titanic/train.csv')
# вычисление показателей описательной статистики
df.describe()Nach der Ausführung dieses Codeabschnitts erhalten wir das, was im nächsten Bild gezeigt wird.
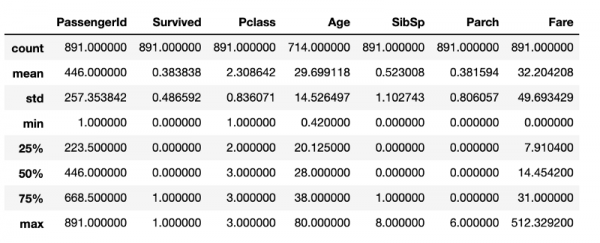
Beschreibende Statistiken, generiert mit den Standardwerkzeugen von pandas
Obwohl hier viele nützliche Informationen enthalten sind, fehlt es an allem, was interessant über die untersuchten Daten sein könnte. Zum Beispiel könnte man annehmen, dass der DataFrame, der die Struktur hat, DataFrame, 891 Zeilen umfasst. Um dies zu überprüfen, benötigst du eine weitere Zeile Code, um die Größe des DataFrames zu bestimmen. Obwohl diese Berechnungen nicht besonders ressourcenintensiv sind, wird die ständige Wiederholung sicherlich zu einem Zeitverlust führen, den man besser mit der Datenbereinigung verbringen sollte.
Explorative Datenanalyse mit pandas-profiling
Machen wir nun dasselbe unter Verwendung von pandas-profiling:
pandas_profiling.ProfileReport(df)Die Ausführung der obigen Codezeile ermöglicht es, einen Bericht mit Kennzahlen zur explorativen Datenanalyse zu erstellen. Der oben gezeigte Code führt zu einer Ausgabe der gefundenen Informationen über die Daten, aber es ist auch möglich, einen HTML-Bericht zu erstellen, den man beispielsweise jemandem zeigen kann.
Der erste Teil des Berichts enthält den Abschnitt Überblick, der grundlegende Informationen zu den Daten liefert (Anzahl der Beobachtungen, Anzahl der Variablen usw.). Zudem gibt es eine Liste von Warnungen, die den Analysten auf besondere Punkte hinweist. Diese Warnungen können Hinweise darauf geben, worauf bei der Datenbereinigung besonders geachtet werden sollte.
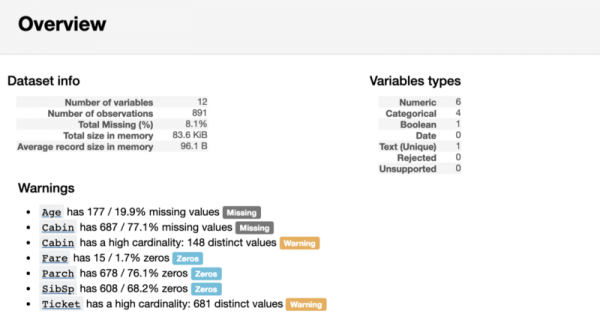
Überblicksbericht
Explorative Analyse der Variablen
Nach dem Abschnitt Überblick im Bericht findet man nützliche Informationen zu jeder Variablen. Dazu gehören unter anderem kleine Diagramme, die die Verteilung jeder Variablen darstellen.

Informationen zur numerischen Variable Alter
Wie aus dem vorherigen Beispiel ersichtlich, bietet pandas-profiling uns einige nützliche Indikatoren, wie z. B. den Prozentsatz und die Anzahl der fehlenden Werte sowie Kennzahlen der beschreibenden Statistik, die wir bereits gesehen haben. Da Alter eine numerische Variable ist, ermöglicht die Visualisierung ihrer Verteilung in Form eines Histogramms den Schluss, dass es sich um eine rechtsschiefe Verteilung handelt.
Bei der Analyse einer kategorialen Variablen weichen die ermittelten Werte etwas von denen ab, die für eine numerische Variable gefunden wurden.

Informationen zur kategorialen Variablen Geschlecht
Statt den Durchschnitt, das Minimum und Maximum zu bestimmen, hat die Bibliothek pandas-profiling die Anzahl der Klassen ermittelt. Da Geschlecht eine binäre Variable ist, werden ihre Werte durch zwei Klassen dargestellt.
Wenn Sie, wie ich, gerne den Code erforschen, könnte Sie interessieren, wie genau die Bibliothek pandas-profiling diese Kennzahlen berechnet. Es ist nicht sehr schwierig, dies herauszufinden, da der Code der Bibliothek offen ist und auf GitHub zur Verfügung steht. Da ich kein großer Fan von "Black Boxes" in meinen Projekten bin, habe ich mir den Quellcode der Bibliothek angesehen. Beispielsweise sieht der Mechanismus zur Verarbeitung von numerischen Variablen, dargestellt durch die Funktion :
def describe_numeric_1d(series, **kwargs):
"""Berechnet Zusammenfassungsstatistiken einer numerischen (`TYPE_NUM`) Variablen (einer Serie).
Erstellt auch Histogramme (mini und voll) ihrer Verteilung.
Parameter
----------
series : Serie
Die zu beschreibende Variable.
Rückgabe
-------
Serie
Die Beschreibung der Variablen als Serie mit dem Index als Statistik-Schlüssel.
"""
# Formatiert eine Zahl als Prozentsatz. Zum Beispiel wird 0,25 zu 25%.
_percentile_format = "{:.0%}"
stats = dict()
stats['type'] = base.TYPE_NUM
stats['mean'] = series.mean()
stats['std'] = series.std()
stats['variance'] = series.var()
stats['min'] = series.min()
stats['max'] = series.max()
stats['range'] = stats['max'] - stats['min']
# Um mehrfache Berechnungen zu vermeiden
_series_no_na = series.dropna()
for percentile in np.array([0.05, 0.25, 0.5, 0.75, 0.95]):
# Das dropna() ist eine Umgehung für https://github.com/pydata/pandas/issues/13098
stats[_percentile_format.format(percentile)] = _series_no_na.quantile(percentile)
stats['iqr'] = stats['75%'] - stats['25%']
stats['kurtosis'] = series.kurt()
stats['skewness'] = series.skew()
stats['sum'] = series.sum()
stats['mad'] = series.mad()
stats['cv'] = stats['std'] / stats['mean'] if stats['mean'] else np.NaN
stats['n_zeros'] = (len(series) - np.count_nonzero(series))
stats['p_zeros'] = stats['n_zeros'] * 1.0 / len(series)
# Histogramme
stats['histogram'] = histogram(series, **kwargs)
stats['mini_histogram'] = mini_histogram(series, **kwargs)
return pd.Series(stats, name=series.name) Obwohl dieser Codeabschnitt ziemlich groß und komplex erscheinen mag, ist es in Wirklichkeit ganz einfach, ihn zu verstehen. Es geht darum, dass im Quellcode der Bibliothek eine Funktion vorhanden ist, die die Typen der Variablen bestimmt. Wenn die Bibliothek auf eine numerische Variable trifft, findet die oben genannte Funktion die Werte, die wir betrachtet haben. In dieser Funktion werden die Standardoperationen von pandas für den Umgang mit Objekten vom Typ Seriesverwendet, wie zum Beispiel series.mean(). Die Berechnungsergebnisse werden in einem Wörterbuch statsgespeichert. Die Histogramme werden mithilfe einer angepassten Version der Funktion matplotlib.pyplot.histgebildet. Die Anpassung zielt darauf ab, dass die Funktion mit verschiedenen Datensatztypen arbeiten kann.
Korrelationskennzahlen und ein Beispiel für die untersuchten Daten
Nach der Analyse der Variablen gibt pandas-profiling im Abschnitt Korrelations die Pearson- und Spearman-Korrelationsmatrizen aus.
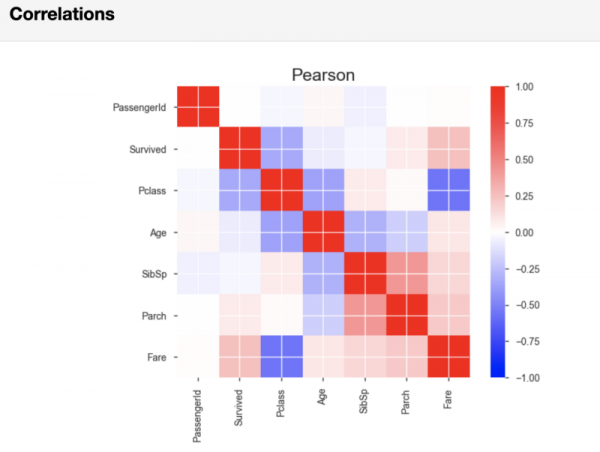
Pearson-Korrelationsmatrix
Falls erforderlich, können Sie in der Zeile des Codes, die den Bericht generiert, die Schwellenwerte angeben, die bei der Berechnung der Korrelation verwendet werden. Damit können Sie festlegen, welche Stärke der Korrelation für Ihre Analyse als bedeutend erachtet wird.
Und schließlich wird im pandas-profiling-Bericht im Abschnitt Beispiel ein Ausschnitt von Daten angezeigt, der zu Beginn des Datensatzes entnommen wurde. Dieser Ansatz kann zu unangenehmen Überraschungen führen, da die ersten Beobachtungen eine Auswahl darstellen können, die nicht die Merkmale des gesamten Datensatzes widerspiegelt.
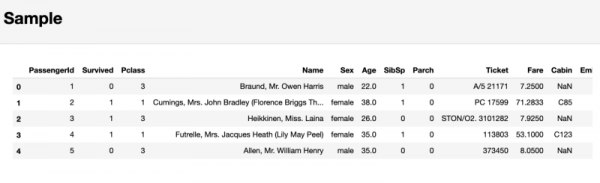
Abschnitt mit einer Probe der untersuchten Daten
Daher empfehle ich, diesen letzten Abschnitt nicht zu beachten. Stattdessen ist es besser, den Befehl df.sample(5), der zufällig 5 Beobachtungen aus dem Datensatz auswählt, zu verwenden.
Ergebnisse
Zusammenfassend lässt sich sagen, dass die Bibliothek pandas-profiling Analysten einige nützliche Funktionen bietet, die in Situationen hilfreich sind, in denen man schnell einen allgemeinen Überblick über Daten erhalten oder jemandem einen Bericht über die explorative Datenanalyse übermitteln möchte. Dabei erfolgt die tatsächliche Arbeit mit den Daten, die deren Besonderheiten berücksichtigt, wie auch ohne die Verwendung von pandas-profiling manuell.
Wenn Sie sehen möchten, wie die gesamte explorative Datenanalyse in einem Jupyter-Notebook aussieht – schauen Sie sich mein Projekt an, das mit nbviewer erstellt wurde. Und im GitHub-Repository finden Sie den entsprechenden Code.
Sehr geehrte Leser! Wie beginnen Sie mit der Analyse neuer Datensätze?
Quelle: habr.com
