

Wenn Sie zu Beginn des Stücks sagen, dass an der Wand ein Code in C++ hängt, muss er am Ende unbedingt Ihnen in das Bein schießen.
Bjarne Stroustrup
Vom 31. Oktober bis 1. November fand in St. Petersburg die Konferenz C++ Russia Piter statt – eine der größten Programmierkonferenzen in Russland, organisiert von JUG Ru Group. Unter den eingeladenen Referenten sind Mitglieder des C++-Standardisierungskomitees, Redner von CppCon, Autoren von Büchern aus dem O’Reilly-Verlag sowie Maintainer von Projekten wie LLVM, libc++ und Boost. Die Konferenz richtet sich an erfahrene C++-Entwickler, die ihre Expertise vertiefen und Erfahrungen im persönlichen Austausch teilen möchten. Studenten, Doktoranden und Hochschuldozenten erhalten sehr attraktive Rabatte.
Die Moskauer Ausgabe der Konferenz wird bereits im April nächsten Jahres stattfinden, aber bis dahin werden unsere Studenten berichten, was Interessantes sie bei der vergangenen Veranstaltung gelernt haben.

Foto aus
Über uns
An diesem Beitrag arbeiteten zwei Studenten der National Research University Higher School of Economics — St. Petersburg:
- Lisa Wasilenko ist eine Studentin im 4. Bachelorsemester, die das Fachgebiet "Programmiersprachen" im Rahmen des Studiengangs "Angewandte Mathematik und Informatik" studiert. Nachdem sie in ihrem ersten Universitätssemester mit der Programmiersprache C++ in Berührung kam, sammelte sie schließlich praktische Erfahrungen durch Praktika in der Branche. Ihre Begeisterung für Programmiersprachen allgemein und für funktionale Programmierung im Besonderen hat ihren Vortrag auf der Konferenz beeinflusst.
- Danila Smirnov ist Erstsemestler im Masterstudiengang "Programmierung und Datenanalyse". Schon in der Schule löste er Aufgaben in C++ für Wettbewerbe, und anschließend trat die Sprache immer wieder während seines Studiums auf, sodass sie zu seiner Hauptprogrammiersprache wurde. Er hat sich entschieden, an der Konferenz teilzunehmen, um sein Wissen aufzufrischen und neue Möglichkeiten kennenzulernen.
In den Mitteilungen teilt die Fakultätsleitung häufig Informationen über bildungsrelevante Ereignisse, die mit unserem Fachbereich in Verbindung stehen. Im September entdeckten wir die Informationen über C++ Russia und beschlossen, uns als Teilnehmer anzumelden. Dies ist unser erster Versuch, an einer solchen Konferenz teilzunehmen.
Konferenzstruktur
Vorträge
Innerhalb von zwei Tagen haben Experten 30 Vorträge gelesen, die viele spannende Themen beleuchten: kreative Anwendungen von Spracheigenschaften zur Lösung praktischer Probleme, bevorstehende Sprachupdates im Zusammenhang mit dem neuen Standard, Kompromisse im C++-Design und Sicherheitsmaßnahmen im Umgang mit deren Folgen, Beispiele interessanter Projektarchitekturen sowie einige technische Details zur Infrastruktur der Sprache. Gleichzeitig fanden drei Präsentationen statt, meist zwei auf Russisch und eine auf Englisch.
Diskussionszonen
Nach den Vorträgen wurden alle unbeantworteten Fragen und unvollendeten Diskussionen in speziell eingerichtete Kommunikationszonen mit den Referenten verlegt, die mit Whiteboards ausgestattet waren. Eine gute Möglichkeit, die Pause zwischen den Vorträgen mit angenehmen Gesprächen zu verbringen.
Lightning Talks und informelle Diskussionen
Wenn Sie einen kurzen Vortrag halten möchten, können Sie sich auf dem Whiteboard für den abendlichen Lightning Talk eintragen und fünf Minuten Zeit bekommen, um über ein beliebiges Thema im Kontext der Konferenz zu sprechen. Zum Beispiel eine schnelle Einführung in Sanitizers für C++ (was für einige neu war) oder eine Geschichte über einen Bug bei der Sinuswellen-Generierung, den man nur hören, aber nicht sehen kann.
Ein weiteres Format ist die Podiumsdiskussion „Mit dem Komitee für Seelen“. Auf der Bühne sitzen einige Mitglieder des Standardisierungsausschusses, auf dem Projektor wird ein Kamin gezeigt (offiziell zur Schaffung einer gemütlichen Atmosphäre, aber der Grund „weil ALLES IN FLAMMEN STEHT“ scheint amüsanter zu sein), die Fragen beziehen sich auf den Standard und die allgemeine Vision von C++, ohne lebhafte technische Diskussionen oder Streitigkeiten. Es zeigte sich, dass auch im Ausschuss lebendige Menschen sitzen, die in bestimmten Dingen nicht ganz sicher sein oder etwas nicht wissen können.
Für die Liebhaber von technischen Debatten gab es eine dritte Veranstaltung - die BOF-Session "Go gegen C++". Ein Go-Enthusiast und ein C++-Liebhaber bereiten vor Beginn der Session gemeinsam 100500 Folien zu Themen vor (wie etwa Probleme mit Paketen in C++ oder das Fehlen von Generics in Go), und anschließend diskutieren sie lebhaft miteinander und mit dem Publikum, das versucht, beide Perspektiven zu verstehen. Wenn die Diskussion vom Thema abweicht, greift der Moderator ein und versöhnt die Parteien. Dieses Format zieht sich hin: mehrere Stunden nach Beginn wurden erst die Hälfte der Folien bearbeitet. Das Ende musste stark beschleunigt werden.
Partnerstände
In den Hallen waren die Partner der Konferenz vertreten - an den Ständen informierten sie über aktuelle Projekte, boten Praktika und Jobangebote an, veranstalteten Quizze und kleine Wettbewerbe und verlosten angenehme Preise. Einige Unternehmen boten sogar an, die ersten Phasen von Vorstellungsgesprächen zu durchlaufen, was für diejenigen nützlich sein könnte, die nicht nur kommen, um Vorträge zu hören.
Technische Details der Vorträge
Wir haben an beiden Tagen die Vorträge verfolgt. Oft war es schwierig, sich für einen Vortrag aus den gleichzeitig stattfindenden zu entscheiden – wir haben beschlossen, uns aufzuteilen und in den Pausen das Wissen auszutauschen. Und selbst so scheint es, als wäre viel ungenutzt geblieben. Hier möchten wir über den Inhalt einiger Vorträge berichten, die uns am interessantesten erschienen.
Ausnahmen in C++ durch die Linse von Compiler-Optimierungen, Roman Russejew
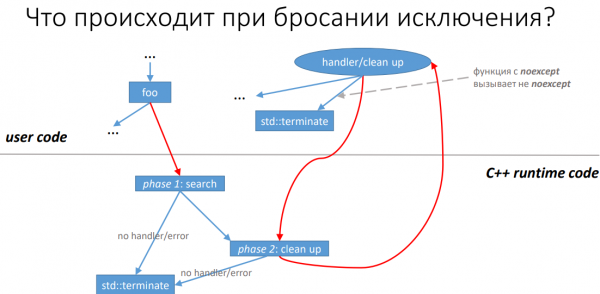
Folien aus
Wie der Titel schon sagt, behandelte Roman den Umgang mit Ausnahmen anhand von LLVM. Selbst für diejenigen, die Clang in ihrer Arbeit nicht verwenden, kann der Vortrag dennoch einen gewissen Einblick geben, wie Code potenziell optimiert werden kann. Das liegt daran, dass Compiler-Entwickler und die entsprechenden Standardbibliotheken miteinander kommunizieren und viele erfolgreiche Lösungen übereinstimmen können.
Für die Verarbeitung von Ausnahmen sind zahlreiche Schritte erforderlich: Entweder wird der Handlings-Code (falls vorhanden) aufgerufen oder Ressourcen auf der aktuellen Ebene freigegeben, während der Stack höher gemacht wird. All dies führt dazu, dass der Compiler zusätzliche Anweisungen für potenziell auslösende Aufrufe hinzufügt. Daher wird, selbst wenn keine Ausnahme tatsächlich ausgelöst wird, die Anwendung unnötige Aktionen ausführen. Um die Kosten etwas zu senken, gibt es in LLVM mehrere Heuristiken zur Identifizierung von Situationen, in denen kein Ausnahmebehandlungs-Code hinzugefügt werden muss oder bei denen die Anzahl der "überflüssigen" Anweisungen verringert werden kann.
Der Referent betrachtet etwa ein Dutzend solcher Situationen und demonstriert sowohl die Fälle, in denen sie die Ausführung des Programms beschleunigen, als auch die, in denen diese Methoden nicht anwendbar sind.
Somit führt Roman Russejev die Zuhörer zu der Erkenntnis, dass Code, der mit Ausnahmen arbeitet, keineswegs immer mit null Overhead ausgeführt werden kann, und gibt folgende Ratschläge:
- bei der Entwicklung von Bibliotheken sollte grundsätzlich auf Ausnahmen verzichtet werden;
- Wenn Ausnahmen dennoch notwendig sind, sollten überall, wo es möglich ist, die Modifikatoren noexcept (und const) hinzugefügt werden, damit der Compiler so viel wie möglich optimieren kann.
Insgesamt bestätigte der Redner die Meinung, dass Ausnahmen am besten möglichst sparsam eingesetzt oder idealerweise ganz vermieden werden sollten.
Die Folien des Vortrags sind unter dem folgenden Link verfügbar:
Generatoren, Koroutinen und andere aufregende Aspekte, Adi Shavit

Folien aus
Einer der vielen Vorträge dieser Konferenz, der sich mit den Neuerungen in C++20 befasste, blieb nicht nur durch seine ansprechend gestaltete Präsentation im Gedächtnis, sondern auch durch die klare Benennung der vorhandenen Probleme bei der Logik der Sammlungshandhabung (for-Schleife, Callback-Funktionen).
Adi Shavit hebt hervor, dass die derzeit verfügbaren Methoden die gesamte Sammlung durchlaufen, jedoch keinen Zugriff auf einen internen Zwischenzustand bieten (oder nur im Fall von Callbacks, aber mit zahlreichen unangenehmen Nebenwirkungen, wie dem sogenannten Callback Hell). Es scheinen zwar Iteratoren erhältlich zu sein, aber auch diese bringen Schwierigkeiten mit sich: Es gibt keinen einheitlichen Einstiegspunkt und keine einheitliche Ausgangsstelle (begin → end im Vergleich zu rbegin → rend usw.), und es bleibt unklar, wie oft wir überhaupt iterieren werden. Ab C++20 werden diese Probleme gelöst!
Die erste Möglichkeit: Ranges. Durch eine Schicht über den Iteratoren erhalten wir eine einheitliche Schnittstelle für den Start und das Ende der Iteration sowie die Möglichkeit zur Komposition. All dies ermöglicht es, vollwertige Datenverarbeitungs-Pipelines einfach zu erstellen. Doch nicht alles ist so einfach: Ein Teil der Logik für die Berechnungen befindet sich innerhalb der Implementierung eines bestimmten Iterators, was den Code schwerer verständlich und debugbar machen kann.

Folien aus
Für diese Situation wurden in C++20 Koroutinen hinzugefügt (Funktionen, deren Verhalten den Generatoren in Python ähnelt): Die Ausführung kann verzögert werden, indem ein aktueller Wert zurückgegeben wird, während der Zwischenzustand beibehalten wird. Somit erreichen wir nicht nur die Verarbeitung von Daten, sobald sie verfügbar sind, sondern inkapsulieren auch die gesamte Logik innerhalb einer bestimmten Koroutine.
Aber es gibt einen Kritikpunkt: Derzeit werden sie nur teilweise von den verfügbaren Compilern unterstützt und sind auch nicht so sorgfältig implementiert, wie man es sich wünschen würde. Zum Beispiel sollte man in Koroutinen keine Referenzen und temporären Objekte verwenden. Außerdem gibt es bestimmte Einschränkungen dafür, was als Koroutine dienen kann, und constexpr-Funktionen, Konstruktoren/Dekonstruktoren sowie die main gehören nicht dazu.
Somit lösen Koroutinen einen erheblichen Teil der Probleme mit der Einfachheit der Datenverarbeitung, aber ihre aktuellen Implementierungen erfordern Verbesserungen.
Materialien:
- Folien von C++ Russia —
C++ Tricks von Yandex.Taxi, Anton Poluchin
In meiner beruflichen Tätigkeit kommt es manchmal vor, dass ich rein unterstützende Aufgaben umsetzen muss: eine Wrapper zwischen einer internen Schnittstelle und der API einer Bibliothek, Protokollierung oder Parsing. In der Regel besteht dabei keine Notwendigkeit für zusätzliche Optimierungen. Aber was, wenn diese Komponenten in einigen der beliebtesten Dienste im russischen Internet verwendet werden? In einem solchen Fall müssen Terabytes von Logs pro Stunde verarbeitet werden! Da zählt jede Millisekunde, und man muss auf verschiedene Tricks zurückgreifen – über diese sprach Anton Poluchin.
Ein besonders interessantes Beispiel war die Implementierung des Patterns Pointer-to-Implementation (Pimpl).
#include <third_party/json.hpp> //PROBLEMS!
struct Value {
Value() = default;
Value(Value&& other) = default;
Value& operator=(Value&& other) = default;
~Value() = default;
std::size_t Size() const { return data_.size(); }
private:
third_party::Json data_;
};In diesem Beispiel möchte ich zunächst die Header-Dateien externer Bibliotheken loswerden – das verkürzt die Kompilierungszeit und schützt vor möglichen Namenskonflikten und anderen ähnlichen Fehlern.
Gut, wir haben #include in die .cpp-Datei verschoben: Es wird ein Forward-Declaration der umschlossenen API sowie std::unique_ptr benötigt. Nun haben wir dynamische Zuweisungen und andere unangenehme Dinge wie verstreute Daten im Heap und reduzierte Garantien. Mit all dem kann std::aligned_storage helfen.
struct Value {
// ...
private:
using JsonNative = third_party::Json;
const JsonNative* Ptr() const noexcept;
JsonNative* Ptr() noexcept;
constexpr std::size_t kImplSize = 32;
constexpr std::size_t kImplAlign = 8;
std::aligned_storage_t data_;
};Das einzige Problem: Für jede Wrapper müssen wir Größe und Ausrichtung definieren – machen wir unser pimpl zu einer Template-Klasse mit den Parametern , verwenden wir willkürliche Werte und fügen im Destruktor eine Überprüfung hinzu, ob alles korrekt ist:
~FastPimpl() noexcept {
validate();
Ptr()->~T();
}
template
static void validate() noexcept {
static_assert(
Size == ActualSize,
"Größe und sizeof(T) stimmen nicht überein"
);
static_assert(
Alignment == ActualAlignment,
"Ausrichtung und alignof(T) stimmen nicht überein"
);
}Da T bereits beim Verarbeiten des Destruktors definiert ist, wird dieser Code korrekt behandelt und gibt beim Kompilieren die erforderlichen Werte für Größe und Ausrichtung als Fehlermeldungen aus, die angegeben werden müssen. Damit vermeiden wir durch einen zusätzlichen Kompilierungsdurchlauf die dynamische Zuordnung von umschlossenen Klassen, verstecken die API in einer .cpp-Datei mit Implementierung und erhalten eine für den Prozessor besser cachebare Struktur.
Logging und Parsing erscheinen weniger beeindruckend, daher werden sie in dieser Übersicht nicht erwähnt.
Die Folien des Vortrags sind unter dem folgenden Link verfügbar:
Moderne Techniken, um Ihren Code DRY zu halten, Björn Fahller
In diesem Vortrag zeigt Björn Fahller verschiedene Ansätze, um den stilistischen Fehler der wiederholten Bedingungsprüfungen zu vermeiden:
assert(a == IDLE || a == CONNECTED || a == DISCONNECTED);Klingt vertraut? Mit einigen leistungsstarken C++-Techniken aus den neuesten Standards lässt sich dieselbe Funktionalität elegant umsetzen, ohne jegliche Leistungseinbußen. Vergleichen Sie:
assert(a == any_of(IDLE, CONNECTED, DISCONNECTED));Um eine variable Anzahl von Prüfungen zu verarbeiten, bietet sich die Verwendung von variadischen Templates und Fold-Expressions an. Angenommen, wir möchten die Gleichheit mehrerer Variablen mit einem Element des Enums state_type überprüfen. Zunächst könnte man eine Hilfsfunktion is_any_of schreiben:
enum state_type { IDLE, CONNECTED, DISCONNECTED };
template
bool is_any_of(state_type s, const Ts& ... ts) {
return ((s == ts) || ...);
}
Ein solches Zwischenergebnis ist enttäuschend. Der Code wird bisher nicht leserlicher:
assert(is_any_of(state, IDLE, DISCONNECTING, DISCONNECTED)); Ein wenig mehr Klarheit bringen non-type Template-Parameter. Damit übertragen wir die aufgezählten Elemente des enums in die Parameterliste des Templates:
template
bool is_any_of(state_type t) {
return ((t == states) | ...);
}
assert(is_any_of(state)); Mit der Verwendung von auto in nicht typisierten Template-Parametern (C++17) wird der Ansatz einfach auf Vergleiche mit nicht nur den Elementen von state_type, sondern auch mit primitiven Typen verallgemeinert, die als non-type Template-Parameter verwendet werden können:
template
bool is_any_of(const T& t) {
return ((t == alternatives) | ...);
}Durch solche sequenziellen Verbesserungen wird die gewünschte flüssige Syntax für Überprüfungen erreicht:
template
struct any_of : private std::tuple {
// Lassen wir es uns leicht machen und erben die Konstruktoren von tuple
using std::tuple::tuple;
template
bool operator ==(const T& t) const {
return std::apply(
[&t](const auto& ... ts) {
return ((ts == t) || ...);
},
static_cast<const std::tuple&>(*this));
}
};
template
any_of(Ts ...) -> any_of;
assert(any_of(IDLE, DISCONNECTING, DISCONNECTED) == state);
In diesem Beispiel dient der Deduktionsleitfaden als Hinweis für die gewünschten Vorlagenparameter, um dem Compiler die Typen der Konstruktorargumente zu vermitteln.
Es wird spannender. Björn lehrt, wie man den erzeugten Code für die Vergleichsoperatoren neben == abstrahiert und später auch für beliebige Operationen. Währenddessen werden Funktionen wie das Attribut no_unique_address (C++20) und Vorlagenparameter in Lambda-Funktionen (C++20) an Beispielen erläutert. (Ja, jetzt ist die Syntax von Lambdas noch einfacher zu merken – es sind vier aufeinanderfolgende Klammerpaare aller Arten.) Die endgültige Lösung mit Funktionen als Teil des Konstruktors freut mich persönlich sehr, ganz zu schweigen von der Darstellung von Tupeln in bester Tradition der Lambda-Kalküle.
Am Ende vergessen wir nicht, alles zu verfeinern:
- Denken wir daran, dass Lambdas – constexpr umsonst sind;
- Fügen wir Perfect Forwarding hinzu und betrachten wir die unansehnliche Syntax in Bezug auf Parameterpakete in Lambda-Schließungen;
- Geben wir dem Compiler mehr Möglichkeiten zur Optimierung mit conditional noexcept;
- Wir sorgen für eine klarere Fehlerausgabe in Templates dank expliziter Rückgabewerte von Lambdas. Dies zwingt den Compiler, mehr Überprüfungen vor dem tatsächlichen Aufruf der Template-Funktion – in der Typüberprüfungsphase – vorzunehmen.
Für Details wenden Sie sich bitte an die Materialien der Vorlesung:
- Präsentationsunterlagen:
Unsere Eindrücke
Unsere erste Teilnahme an C++ Russia bleibt in Erinnerung wegen ihrer Intensität. Es entsteht der Eindruck, dass C++ Russia eine herzliche Veranstaltung ist, bei der die Grenze zwischen Lernen und lebendigem Austausch kaum spürbar ist. Alles, vom Elan der Referenten bis hin zu Wettbewerben der Veranstaltungspartner, lädt zu lebhaften Diskussionen ein. Der inhaltliche Teil der Konferenz, bestehend aus Vorträgen, deckt ein breites Spektrum an Themen ab, einschließlich Neuerungen in C++, praktischen Beispielen großer Projekte und ideologischen architektonischen Überlegungen. Aber es wäre ungerecht, auch die soziale Komponente der Veranstaltung zu vernachlässigen, die dazu beiträgt, Sprachbarrieren nicht nur in Bezug auf C++ zu überwinden.
Wir danken den Organisatoren der Konferenz für die Möglichkeit, an solch einem Ereignis teilzunehmen!
Den Beitrag der Organisatoren über die Vergangenheit, Gegenwart und Zukunft von C++ Russia konnten Sie .
lesen. Vielen Dank für Ihr Interesse, und wir hoffen, unser Rückblick auf die Ereignisse war hilfreich!
Quelle: habr.com
