


Πονάει μόνο την πρώτη φορά!
Γεια σε όλους! Αγαπητοί φίλοι, σε αυτό το άρθρο θέλω να μοιραστώ την εμπειρία μου από τη χρήση του TensorRT, RetinaNet με βάση το αποθετήριο (αυτό είναι ένα διακλάδωμα του επίσημου αποθετηρίου από , το οποίο θα σας επιτρέψει να ξεκινήσετε να χρησιμοποιείτε βελτιστοποιημένα μοντέλα στην παραγωγή στον συντομότερο δυνατό χρόνο). Κύλιση σε μηνύματα σε κανάλια κοινότητας , Συναντώ ερωτήσεις σχετικά με τη χρήση του TensorRT και ως επί το πλείστον οι ερωτήσεις επαναλαμβάνονται, οπότε αποφάσισα να γράψω όσο το δυνατόν πιο ολοκληρωμένο Ένας οδηγός για τη χρήση γρήγορης συμπερασματολογίας βασισμένος σε TensorRT, RetinaNet, Unet και docker.
Περιγραφή της εργασίας
Προτείνω να διατυπωθεί η εργασία ως εξής: πρέπει να επισημάνουμε το σύνολο δεδομένων, να εκπαιδεύσουμε το δίκτυο RetinaNet/Unet στο Pytorch 1.3+, να μετατρέψουμε τα βάρη που λάβαμε σε ONNX, στη συνέχεια να τα μετατρέψουμε στη μηχανή TensorRT και να εκτελέσουμε ολόκληρη την εργασία στο Docker, κατά προτίμηση σε Ubuntu 18 και ιδιαίτερα επιθυμητό στην αρχιτεκτονική ARM (Jetson)*, ελαχιστοποιώντας έτσι τη χειροκίνητη ανάπτυξη του περιβάλλοντος. Το τελικό αποτέλεσμα θα είναι ένα κοντέινερ έτοιμο όχι μόνο για εξαγωγή και εκπαίδευση του RetinaNet/Unet, αλλά και για πλήρη ανάπτυξη και εκπαίδευση συστημάτων ταξινόμησης και τμηματοποίησης, με όλο το απαραίτητο υλικό.
Βήμα 1. Προετοιμασία του περιβάλλοντος
Είναι σημαντικό να σημειωθεί εδώ ότι πρόσφατα έχω εγκαταλείψει εντελώς τη χρήση και την ανάπτυξη οποιωνδήποτε βιβλιοθηκών στον επιτραπέζιο υπολογιστή, καθώς και στο devbox. Το μόνο που χρειάζεται να δημιουργηθεί και να εγκατασταθεί είναι το εικονικό περιβάλλον python και το cuda 10.2 (μπορείτε να περιορίσετε τον εαυτό σας σε έναν οδηγό nvidia) από το deb.
Ας υποθέσουμε ότι έχετε εγκαταστήσει πρόσφατα Ubuntu 18. Ας εγκαταστήσουμε το cuda 10.2 (deb). Δεν θα επεκταθώ σε λεπτομέρειες σχετικά με τη διαδικασία εγκατάστασης, η επίσημη τεκμηρίωση είναι αρκετά επαρκής.
Τώρα ας εγκαταστήσουμε το docker, ο οδηγός εγκατάστασης του docker μπορεί εύκολα να βρεθεί, εδώ είναι ένα παράδειγμα , η έκδοση 19+ είναι ήδη διαθέσιμη — ας την εγκαταστήσουμε. Και μην ξεχάσετε να κάνετε δυνατή τη χρήση του docker χωρίς sudo, θα είναι πιο βολικό. Αφού όλα πάνε καλά, κάντε το ως εξής:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
Και δεν χρειάζεται καν να ψάξετε στο επίσημο αποθετήριο .
Τώρα κάνουμε git clone .
Απομένει μόνο λίγο, για να αρχίσουμε να χρησιμοποιούμε το docker με μια εικόνα nvidia, πρέπει να εγγραφούμε στο NGC Cloud και να συνδεθούμε. Πηγαίνετε εδώ. , εγγραφείτε και αφού μπούμε στο NGC Cloud, κάντε κλικ στο SETUP στην επάνω αριστερή γωνία της οθόνης ή ακολουθήστε αυτόν τον σύνδεσμο Κάντε κλικ στην επιλογή "δημιουργία κλειδιού". Συνιστώ να το αποθηκεύσετε, διαφορετικά την επόμενη φορά που θα το επισκεφθείτε θα πρέπει να το δημιουργήσετε ξανά και, κατά συνέπεια, κατά την ανάπτυξή του σε ένα νέο αυτοκίνητο, επαναλάβετε αυτήν τη λειτουργία.
Ας το κάνουμε:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Απλώς αντιγράφουμε το Όνομα Χρήστη. Λοιπόν, σκεφτείτε το περιβάλλον που αναπτύχθηκε!
Βήμα 2: Κατασκευή ενός κοντέινερ Docker
Στο δεύτερο στάδιο της εργασίας μας, θα κατασκευάσουμε το docker και θα εξοικειωθούμε με τα εσωτερικά του στοιχεία.
Ας πάμε στον ριζικό φάκελο που σχετίζεται με το έργο retina-examples και ας εκτελέσουμε
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Χτίζουμε το docker περνώντας τον τρέχοντα χρήστη σε αυτό - αυτό είναι πολύ χρήσιμο αν πρόκειται να γράψετε κάτι στον προσαρτημένο ΤΟΜΟ με τα δικαιώματα του τρέχοντος χρήστη, διαφορετικά θα είναι root και pain.
Ενώ το docker κατασκευάζει, ας εξετάσουμε το αρχείο Docker:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Όπως μπορείτε να δείτε από το κείμενο, παίρνουμε όλες τις αγαπημένες μας βιβλιοθήκες, μεταγλωττίζουμε το retinanet και προσθέτουμε μερικά βασικά εργαλεία για ευκολία στην εργασία. Ubuntu και να διαμορφώσουμε τον διακομιστή OpenSSH. Η πρώτη γραμμή κληρονομεί την εικόνα NVIDIA για την οποία δημιουργήσαμε τα στοιχεία σύνδεσης NGC Cloud και η οποία περιέχει τα Pytorch1.3, TensorRT6.xxx και μια σειρά από άλλες βιβλιοθήκες που μας επιτρέπουν να μεταγλωττίσουμε τον πηγαίο κώδικα CPP για τον ανιχνευτή μας.
Βήμα 3: Εκκίνηση και εντοπισμός σφαλμάτων στο κοντέινερ Docker
Ας προχωρήσουμε στην κύρια περίπτωση χρήσης του container και του περιβάλλοντος ανάπτυξης. Αρχικά θα ξεκινήσουμε το nvidia docker. Ας εκτελέσουμε:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestΤο κοντέινερ είναι πλέον προσβάσιμο μέσω ssh @localhost. Μετά την επιτυχή εκκίνηση, ανοίξτε το έργο στο PyCharm. Στη συνέχεια, ανοίξτε
Settings->Project Interpreter->Add->Ssh Interpreter Βήμα 1
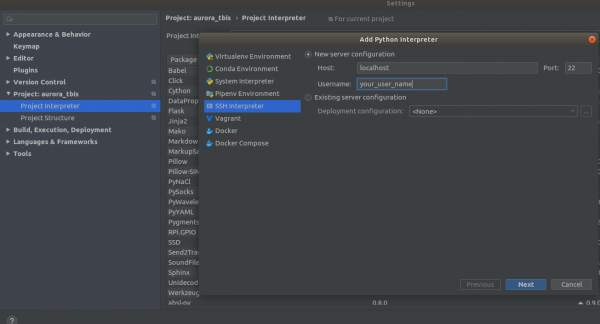
Βήμα 2
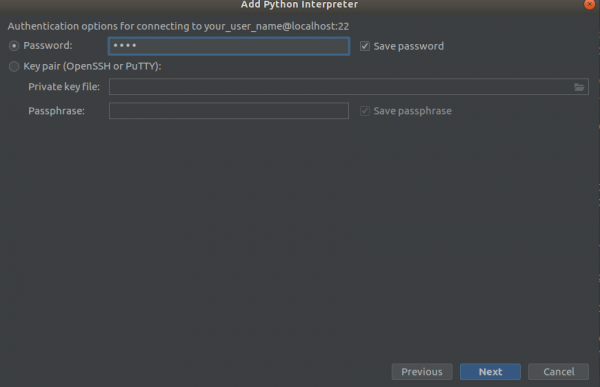
Βήμα 3
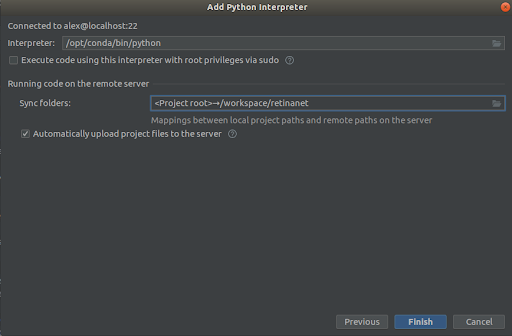
Επιλέγουμε τα πάντα όπως στα στιγμιότυπα οθόνης,
Interpreter -> /opt/conda/bin/python- θα είναι ln σε Python3.6 και
Sync folder -> /workspace/retinanetΚάντε κλικ στο κουμπί "Τέλος", περιμένετε για την δημιουργία ευρετηρίου και αυτό είναι όλο, το περιβάλλον είναι έτοιμο για χρήση!
ΣΗΜΑΝΤΙΚΟ !!! Αμέσως μετά την ευρετηρίαση, εξαγάγετε τα μεταγλωττισμένα αρχεία για το Retinanet από το Docker. Στο μενού περιβάλλοντος στη ρίζα του έργου, επιλέξτε το στοιχείο
Deployment->DownloadΘα εμφανιστούν ένα αρχείο και δύο φάκελοι: build, retinanet.egg-info και _С.so
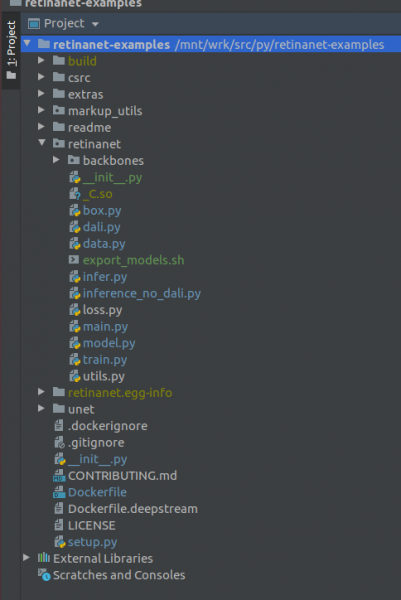
Αν το έργο σας μοιάζει με αυτό, τότε το περιβάλλον βλέπει όλα τα απαραίτητα αρχεία και είμαστε έτοιμοι να εκπαιδεύσουμε το RetinaNet.
Βήμα 4. Επισημάνετε τα δεδομένα και εκπαιδεύστε τον ανιχνευτή
Για τη σήμανση χρησιμοποιώ κυρίως — ένα ωραίο και βολικό εργαλείο, πρόσφατα διορθώθηκαν πολλά σφάλματα και άρχισε να συμπεριφέρεται πολύ καλύτερα.
Ας υποθέσουμε ότι έχετε επισημάνει το σύνολο δεδομένων και το έχετε κατεβάσει, αλλά δεν θα μπορείτε να το βάλετε αμέσως στο RetinaNet μας, καθώς έχει τη δική του μορφή και για αυτό πρέπει να το μετατρέψουμε σε COCO. Το εργαλείο μετατροπής βρίσκεται στη διεύθυνση:
markup_utils/supervisly_to_coco.pyΛάβετε υπόψη ότι η κατηγορία στο σενάριο είναι ένα παράδειγμα και πρέπει να εισαγάγετε τη δική σας (δεν χρειάζεται να προστεθεί η κατηγορία φόντου)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Οι συγγραφείς του αρχικού αποθετηρίου για κάποιο λόγο αποφάσισαν ότι δεν θα εκπαιδεύσετε τίποτα άλλο εκτός από το COCO/VOC για ανίχνευση, οπότε έπρεπε να επεξεργαστώ λίγο το αρχείο πηγής.
retinanet/dataset.pyΠροσθέτοντας εδώ τις αγαπημένες σας επαυξήσεις και να αποκόψετε κατηγορίες με σκληρό κώδικα από το COCO. Είναι επίσης δυνατό να περικόψετε μεγάλες περιοχές ανίχνευσης εάν ψάχνετε για μικρά αντικείμενα σε μεγάλες εικόνες, έχετε ένα μικρό σύνολο δεδομένων =), και τίποτα δεν λειτουργεί, αλλά θα το συζητήσουμε αυτό κάποια άλλη φορά.
Γενικά, ο βρόχος τρένου είναι επίσης αδύναμος, αρχικά δεν αποθήκευε σημεία ελέγχου, χρησιμοποιούσε κάποιο απαίσιο χρονοπρογραμματιστή κ.λπ. Αλλά τώρα πρέπει μόνο να επιλέξετε το βασικό δίκτυο και να εκτελέσετε
/opt/conda/bin/python retinanet/main.pyμε παραμέτρους:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
Στην κονσόλα θα δείτε:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Για να μελετήσετε το πλήρες σύνολο των παραμέτρων, βλ.
retinanet/main.pyΓενικά, είναι τυπικά για την ανίχνευση και έχουν μια περιγραφή. Εκτελέστε την εκπαίδευση και περιμένετε τα αποτελέσματα. Ένα παράδειγμα συμπερασμού μπορεί να βρεθεί στο:
retinanet/infer_example.pyή εκτελέστε την εντολή:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
Το αποθετήριο έχει ήδη ενσωματωμένες λειτουργίες Focal Loss και αρκετές backbone, και είναι επίσης εύκολο να προσθέσετε τις δικές σας.
retinanet/backbones/*.pyΣτον πίνακα, οι συγγραφείς παρέχουν ορισμένα χαρακτηριστικά:
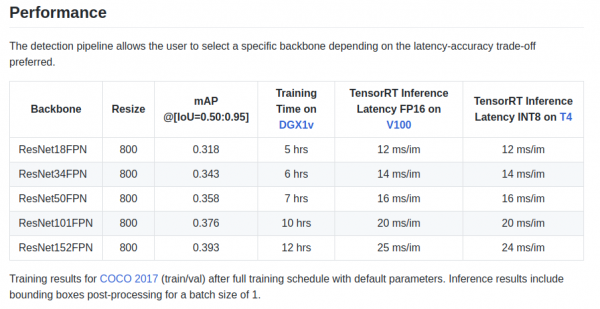
Υπάρχει επίσης ένα backbone ResNeXt50_32x4dFPN και ένα ResNeXt101_32x8dFPN που προέρχονται από το torchvision.
Ελπίζω να έχουμε τακτοποιήσει κάπως την ανίχνευση, αλλά σίγουρα αξίζει να διαβάσετε την επίσημη τεκμηρίωση για να κατανοήστε τις λειτουργίες εξαγωγής και καταγραφής.
Βήμα 5. Εξαγωγή και εξαγωγή συμπερασμάτων μοντέλων Unet με κωδικοποιητή Resnet
Όπως ίσως έχετε παρατηρήσει, το Dockerfile εγκατέστησε βιβλιοθήκες για τμηματοποίηση, και συγκεκριμένα την υπέροχη βιβλιοθήκη Στο πακέτο unet μπορείτε να βρείτε παραδείγματα συμπερασμάτων και εξαγωγής σημείων ελέγχου pytorch στη μηχανή TensorRT.
Το κύριο πρόβλημα κατά την εξαγωγή μοντέλων τύπου Unet από το ONNX στο TensoRT είναι η ανάγκη να οριστεί ένα σταθερό μέγεθος Upsample ή να χρησιμοποιηθεί το ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Με αυτήν τη μετατροπή, μπορείτε να το κάνετε αυτό αυτόματα κατά την εξαγωγή σε ONNX, αλλά στην έκδοση 7 του TensorRT αυτό το πρόβλημα λύθηκε και μας απομένει μόνο λίγος χρόνος για να περιμένουμε.
Συμπέρασμα
Όταν άρχισα να χρησιμοποιώ το docker, είχα αμφιβολίες για την απόδοσή του στις εργασίες μου. Μία από τις μονάδες μου έχει αυτή τη στιγμή αρκετή κίνηση δικτύου που παράγεται από αρκετές κάμερες.
Διάφορες δοκιμές στο Διαδίκτυο έχουν δείξει μια σχετικά μεγάλη επιβάρυνση για την αλληλεπίδραση δικτύου και την εγγραφή σε VOLUME, καθώς και το άγνωστο και τρομακτικό GIL, και από τη στιγμή που γυρίζετε ένα καρέ, η λειτουργία του οδηγού και η μετάδοση καρέ μέσω του δικτύου είναι μια ατομική λειτουργία στη λειτουργία σκληρός πραγματικός χρόνος, οι καθυστερήσεις δικτύου είναι πολύ κρίσιμες για μένα.
Αλλά όλα πήγαν καλά =)
Υ.Γ. Το μόνο που μένει είναι να προσθέσετε την αγαπημένη σας διαδρομή τρένου για τμηματοποίηση και παραγωγή!
Ευχαριστίες
Ευχαριστίες στην κοινότητα , χωρίς αυτό είναι αδύνατο να αναπτυχθείς! Σας ευχαριστώ πολύ , ο οποίος με ενέπνευσε να ξεκινήσω τη σχολή DL, για τις πολύτιμες συμβουλές του και τον εξαιρετικό επαγγελματισμό του!
Χρησιμοποιήστε βελτιστοποιημένα μοντέλα στην παραγωγή!
 Aurora, ΕΠΕ
Aurora, ΕΠΕ
Πηγή: www.habr.com
