

Repasemos los aspectos básicos del inicio de sesión en Docker y Kubernetes, y luego veamos dos herramientas que se pueden usar de manera segura en producción: Grafana Loki y la pila EFK (Elasticsearch + Fluent Bit + Kibana).
El material del artículo es un apretón de . Si hay un deseo, y más aún si hay una necesidad de producción, puede realizar una capacitación completa: inscríbase en un curso sobre .

registro acoplable
En el nivel de Kubernetes, las aplicaciones se ejecutan en pods, pero en un nivel inferior, aún se ejecutan normalmente en Docker. Por lo tanto, debe configurar el registro de tal manera que recopile registros de contenedores. Docker lanza los contenedores, lo que significa que debe averiguar cómo se organiza el registro en el nivel de Docker.
Espero que todos los lectores sepan: los registros de la aplicación deben escribirse en stdout/stderr, y no dentro del contenedor. Docker Daemon agrega los registros y funciona exactamente con los registros que se envían a stdout/stderr. Además, escribir registros dentro del contenedor está plagado de problemas: el contenedor se expande a partir del registro creciente (ya que lo más probable es que no haya Logrotate en el contenedor), y Docker Daemon no está al tanto de este registro.
Docker tiene varios controladores de registro o complementos para recopilar registros de contenedores. El Docker Community Edition (CE) gratuito tiene menos controladores de registro que el Docker Enterprise Edition (EE) comercial.

Nunca he usado Docker EE en la práctica: en Southbridge tratamos de ceñirnos a las soluciones de código abierto y los clientes no necesitan la mayoría de las características adicionales de Docker EE.
Controladores de registro en Docker CE:
local - escribir registros en archivos internos de Docker Daemon;
json-archivo - creando json-log en la carpeta de cada contenedor;
diario - enviar registros a journald.
La configuración de registro de Docker se encuentra en el archivo daemon.json.
El campo "log-driver" especifica el complemento, y el campo "log-opts" especifica su configuración. En el ejemplo anterior, se especifica el complemento "json-file", el límite de tamaño del registro es "max-size": "10m"; límite en el número de archivos (configuración de rotación) — “max-file”: “3”; así como los valores que se adjuntarán a los registros.

Algunas configuraciones del controlador de registro se pueden establecer a través de la utilidad de línea de comandos. Esto es útil si se necesita ejecutar un contenedor separado con un controlador de registro diferente.
Así es como se ve el esquema de registro en Docker:
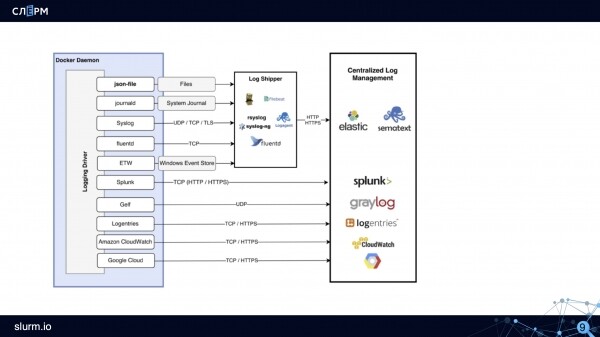
Cómo funciona el esquema: un controlador de registro como json-file crea archivos. Los recopiladores de registros (Rsyslog, Fluentd, Logagent y otros) recopilan estos archivos y los transfieren al almacenamiento en Elastic, Sematext u otros almacenamientos.
Características de iniciar sesión en Kubernetes
Simplificado, el esquema de registro en Kubernetes se ve así: hay un pod, un contenedor se está ejecutando en él, el contenedor envía registros a stdout/stderr. Docker luego crea un archivo y escribe registros, que luego puede rotar.
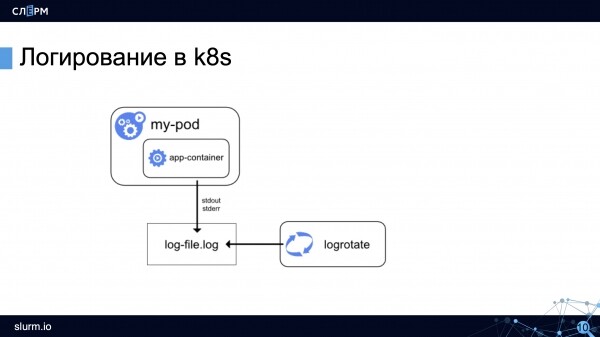
Considere las características de iniciar sesión en Kubernetes.
Guardar registros entre implementaciones. Este es un requisito previo para la configuración de registro correcta. Si no guarda registros entre implementaciones, cuando se publique una nueva versión de la aplicación, los registros de la anterior se sobrescribirán, y la recarga del contenedor también estará plagada de pérdidas de registros. Kubernetes tiene la clave --previous, que le permite ver los registros de la aplicación antes del último reinicio del Pod, pero no más profundo.
Registros agregados de todas las instancias. Si los microservicios están alojados en las nubes, el proveedor de la nube es responsable del control del sistema. Si los microservicios están en su propio hardware, además de los registros de los contenedores, también debe recopilar registros del sistema.
Anteriormente, no existían herramientas convenientes para recopilar registros tanto del sistema como de los microservicios. Normalmente, una herramienta recopilaba los registros del sistema (por ejemplo, Rsyslog) y otra recopilaba los registros de Docker (por ejemplo, journal-bit con el controlador de registro de Docker configurado en journald). Intentamos usar journal-bit para recopilar registros tanto de los contenedores (especificando en el controlador de registro de Docker que los registros se escribieran en journald) como del sistema (en CentOS Windows 7 ya incluye systemd y journald. La solución funciona, pero no es la ideal. Si hay muchos registros, journal-bit empieza a ralentizarse y se pierden mensajes.
Los experimentos continuaron y se encontró otra solución. CentOS Los 7 registros principales del sistema (mensajes, auditoría, seguridad) se duplican en el registro var como archivos. Docker también se puede configurar para guardar los registros en archivos JSON. En consecuencia, estos archivos son CentOS Android 7 y Docker se pueden compilar juntos.
Con el tiempo, la solución ELK Stack se hizo popular. Es una combinación de varias herramientas: Elasticsearch, Logstash y Kibana.
Elasticsearch almacena registros de contenedores, Logstash recopila registros de instancias, Kibana le permite procesar los registros recibidos y crear gráficos basados en ellos. ELK Stack se ha utilizado activamente durante algún tiempo, pero, en mi opinión, su tiempo está pasando. Te diré por qué más tarde.
Agregar metadatos. Los pods, las aplicaciones y los contenedores se pueden ejecutar en cualquier lugar. Además, una aplicación puede tener varias instancias. Los registros están escritos en el mismo formato, y necesitamos entender qué tipo de réplica es, qué Pod lo escribe, en qué espacio de nombres se encuentra. Es por eso que los registros necesitan agregar metadatos.
Analizar registros. Es gracioso, pero el costo de mantener un sistema de registro y monitoreo puede exceder el costo de la aplicación principal. Cuando tienes decenas y cientos de miles de troncos volando por segundo, esto parece natural, pero aún necesitas conocer la línea. Una forma de encontrar este borde es analizar los registros.
Como regla general, no necesita recopilar y almacenar todos los registros, debe enviar solo una parte para su almacenamiento, por ejemplo, registros con el estado "advertencia" o "error". Si estamos hablando de nginx o registros del controlador de entrada, entonces solo se pueden enviar para almacenamiento aquellos cuyo estado es diferente de 200. Pero este no es un consejo universal: si de alguna manera crea análisis basados en registros de Nginx, entonces obviamente vale la pena recopilarlos.
No se recomienda filtrar registros sin pensar, porque los datos filtrados pueden no ser suficientes para el análisis normal. Por otro lado, quizás el análisis deba llevarse a cabo no a nivel de registro, sino a nivel de recopilación de métricas. Entonces no tiene que almacenar cientos de miles de líneas con el código 200. Un enfoque es obtener información sobre el tráfico y los errores de las métricas de los controladores de ingreso.
En general, aquí debe pensar detenidamente: qué desea almacenar y por cuánto tiempo, porque de lo contrario surgirá una situación en la que el sistema de registro requerirá más recursos que el proyecto principal.
Todavía no existe una solución estándar para el registro. A diferencia del monitoreo, donde existe una solución de Prometheus más común, no existe un estándar en el registro.
En esta lección, veremos dos herramientas: una es popular y la segunda está ganando popularidad. Además de ellos, hay otros, pero en este artículo no los tocaremos.
Teniendo en cuenta todas las funciones discutidas anteriormente, el inicio de sesión en Kubernetes ahora se puede representar de la siguiente manera:
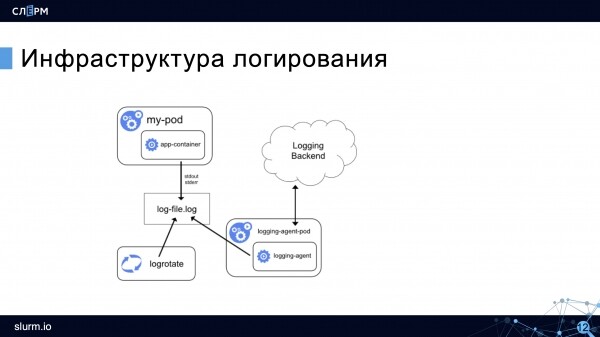
El registro del contenedor permanece, rotación, pero aparece un agente recopilador, que recoge los registros y los envía para su almacenamiento (en el diagrama, en el backend de registro). El agente se ejecuta en cada nodo y normalmente se ejecuta en Kubernetes.
Ahora considere las herramientas para el registro.
Grafana loki
apareció recientemente, pero ya se ha vuelto bastante famoso. Sus ventajas: fácil de instalar, consume pocos recursos, no requiere instalación de Elasticsearch, ya que almacena datos en TSDB (base de datos de series temporales). En el último artículo, escribí que Prometheus almacena datos en dicha base de datos, y esta es una de las muchas similitudes entre los dos productos. Los desarrolladores incluso afirman que Loki es "Prometeo para el mundo de la tala".
Una pequeña digresión sobre TSDB para aquellos que no han leído : TSDB hace un gran trabajo al almacenar grandes cantidades de datos, series temporales, pero no está diseñado para el almacenamiento a largo plazo. Si por alguna razón necesita almacenar registros durante más de dos semanas, es mejor configurar su transferencia a otra base de datos.
Otra ventaja de Loki es que Grafana se utiliza para la visualización de datos. Es muy conveniente: en Grafana miramos los datos de monitoreo y en el mismo lugar, al conectar Loki, miramos los registros. Los registros se pueden utilizar para crear gráficos.
La arquitectura de Loki se parece a esto:
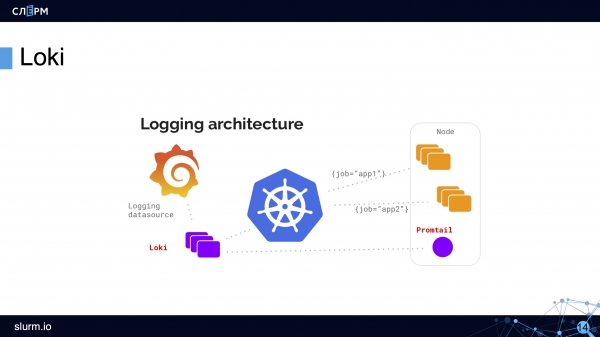
Con DaemonSet, se implementa un agente en todos los servidores del clúster: Promtail o Fluent Bit. El agente recopila registros. Loki los recoge y los almacena en su TSDB. Los metadatos se agregan inmediatamente a los registros, lo cual es conveniente: puede filtrar por pods, espacios de nombres, nombres de contenedores e incluso etiquetas.
Loki se ejecuta en la interfaz familiar de Grafana. Loki incluso tiene su propio lenguaje de consulta llamado LogQL, que es similar en nombre y sintaxis a PromQL en Prometheus. La interfaz de Loki tiene indicaciones con consultas, por lo que no es necesario saberlas de memoria.
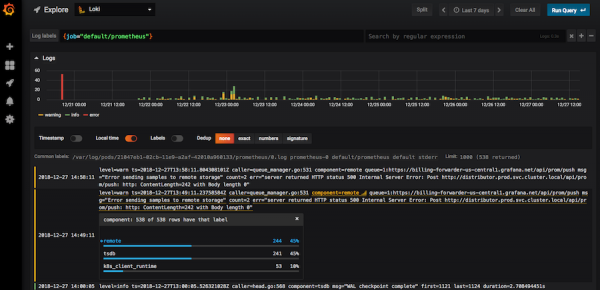
Loki en la interfaz de Grafana
Usando filtros, Loki puede encontrar códigos ("400", "404" y cualquier otro); ver registros de todo el nodo; filtrar todos los registros que contengan la palabra "error". Si hace clic en el registro, se abrirá una tarjeta con toda la información sobre el evento.
Hay suficientes herramientas en Loki que te permiten sacar los registros necesarios, aunque para ser honesto, técnicamente podría haber más. Ahora Loki se está desarrollando activamente y ganando popularidad.
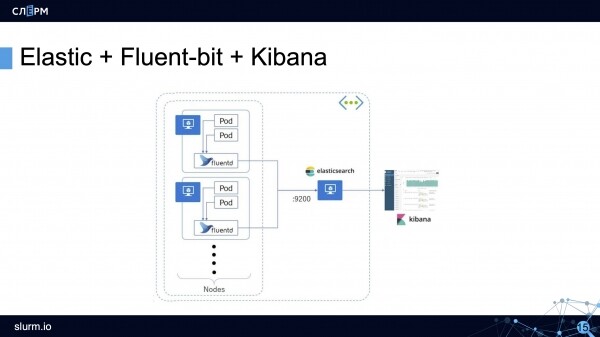
Elástico + Fluent Bit + Kibana (pila EFK)
La pila EFK es una herramienta de registro más clásica pero igualmente popular.
Al comienzo del artículo, se mencionó ELK (Elasticsearch + Logstash + Kibana), pero esta pila está desactualizada debido a que Logstash no es muy productivo y, al mismo tiempo, consume muchos recursos. En su lugar, comenzaron a usar el Fluentd más liviano y productivo, y después de un tiempo vino al rescate. - un agente-recolector aún más ligero e incluso más productivo.
Según los desarrolladores, Fluent Bit tiene un rendimiento más de 100 veces mejor que Fluentd: "Donde Fluentd consume 20 MB de RAM, Fluent Bit consumirá 150 KB", una cita directa de la documentación. Mirando esto, Fluent Bit se ha vuelto más utilizado.
Fluent Bit tiene menos funciones que Fluentd, pero cubre las necesidades principales, por lo que usamos principalmente Fluent Bit.
Cómo funciona la pila EFK: el agente recopila registros de todos los pods (generalmente un DaemonSet que se ejecuta en todos los servidores del clúster) y los envía al almacenamiento (Elasticsearch, PostgreSQL o Kafka). Kibana se conecta al repositorio y recupera toda la información necesaria desde allí.
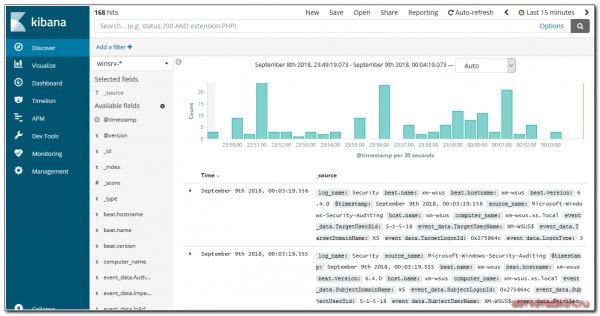
presenta información en una interfaz web fácil de usar. Hay gráficos, filtros y más.
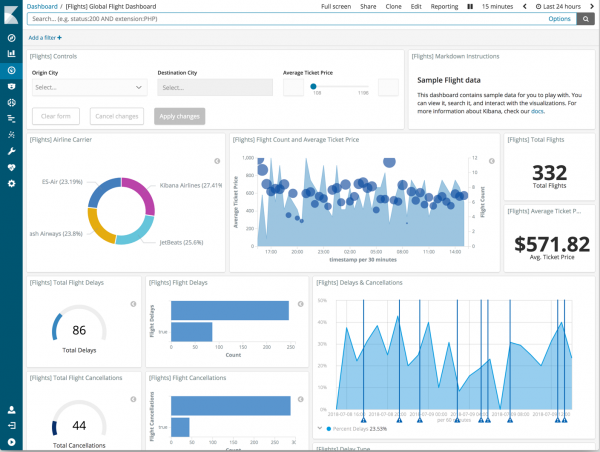
Los registros se pueden usar para crear tableros completos.
Funciones de bits fluidos
Dado que Fluent Bit generalmente se escucha menos que Logstash, echemos un vistazo más de cerca. Fluent Bit se puede dividir lógicamente en 6 módulos, y se pueden adjuntar complementos a algunos de los módulos que amplían las capacidades de Fluent Bit.
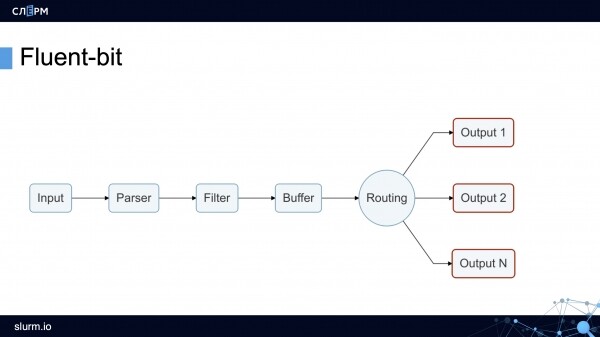
Módulo de entrada recopila registros de archivos, servicios systemd e incluso de tcp-socket (solo necesita especificar un punto final y Fluent Bit comenzará a ir allí). Estas funciones son suficientes para recopilar registros tanto del sistema como de los contenedores.
En producción, usamos complementos con mayor frecuencia (se puede configurar en una carpeta con registros) y (Se le puede decir de qué servicios recopilar registros).
Módulo analizador lleva los registros a una vista común. De forma predeterminada, los registros de Nginx son una cadena. Usando el complemento, esta cadena se puede convertir a JSON: configure los campos y sus valores. Es mucho más fácil trabajar con JSON que con un registro de cadena porque hay opciones de clasificación más flexibles.
Módulo de filtro. En este nivel, se eliminan los registros innecesarios. Por ejemplo, los registros se envían para almacenamiento solo con el valor "advertencia" o con ciertas etiquetas. Los registros seleccionados se almacenan en búfer.
Módulo de búfer. Fluent Bit tiene dos tipos de búfer: un búfer de memoria y un búfer de disco. Un búfer es un almacenamiento de registro temporal que se necesita en caso de errores o fallas. Todos quieren ahorrar en RAM, por lo que generalmente eligen un búfer de disco. Pero tenga en cuenta que antes de ir al disco, los registros aún se descargan en la memoria.
Módulo de enrutamiento/salida contiene reglas y direcciones para enviar registros. Como ya se mencionó, los registros se pueden enviar a Elasticsearch, PostgreSQL o, por ejemplo, Kafka.
Curiosamente, los registros se pueden enviar desde Fluent Bit a Fluentd. Dado que el primero es más liviano y menos funcional, puede recopilar registros a través de él y enviarlos a Fluentd, y ya allí, con la ayuda de complementos adicionales, pueden procesarse y enviarse a los almacenamientos.
Si planea usar Elasticsearch...
Finalmente, dos consejos para aquellos que planean usar Elasticsearch como repositorio de registros en producción.
- Configurar alertas con . Este programa aísla los mensajes importantes del flujo general de registros y genera alertas sobre ellos en el correo u otro canal. Cierto, no hace mucho .
- Rotar registros con la aplicación o llamadas a la API de Elasticsearch. El mismo Elastic, en principio, ahora está tomando medidas significativas para administrar la vida útil de los índices sin el uso de herramientas de terceros. En general, no tiene sentido mantener registros durante mucho tiempo: es poco probable que se necesite ningún registro después de dos semanas; si es realmente crítico, definitivamente se resolverá en dos semanas. En casos extremos, los registros antiguos se pueden archivar y enviar a algún lugar para su almacenamiento a largo plazo. Escuché acerca de registros especiales que la ley requiere que se mantengan hasta por 5 años. Personalmente, no me he encontrado con esto, pero no equipararía dicha información con los registros ordinarios, y tal vez incluso los almacenaría por separado.
To be continued ...
Autor: Marcel Ibraev, administrador certificado de Kubernetes, ingeniero en ejercicio en la empresa , ponente y desarrollador de cursos .
Fuente: habr.com
