


A pesar de que ahora hay muchos datos en casi todas partes, las bases de datos analíticas siguen siendo bastante exóticas. Son poco conocidos y aún peor capaces de usarlos de manera efectiva. Muchos continúan "comiendo cactus" con MySQL o PostgreSQL, que están diseñados para otros escenarios, sufren con NoSQL o pagan de más por soluciones comerciales. ClickHouse cambia las reglas del juego y reduce significativamente el umbral para ingresar al mundo de los DBMS analíticos.
Informe de BackEnd Conf 2018 y se publica con el permiso del orador.


¿Quién soy y por qué hablo de ClickHouse? Soy director de desarrollo en LifeStreet, que usa ClickHouse. Además, soy el fundador de Altinity. Es un socio de Yandex que promueve ClickHouse y ayuda a Yandex a hacer que ClickHouse sea más exitoso. También listo para compartir conocimientos sobre ClickHouse.

Y no soy el hermano de Petya Zaitsev. A menudo me preguntan sobre esto. No, no somos hermanos.

“Todo el mundo sabe” que ClickHouse:
- Muy rapido,
- Muy cómoda
- Utilizado en Yandex.
Se sabe un poco menos en qué empresas y cómo se utiliza.

Le diré por qué, dónde y cómo se usa ClickHouse, excepto Yandex.
Le diré cómo se resuelven tareas específicas con la ayuda de ClickHouse en diferentes empresas, qué herramientas de ClickHouse puede usar para sus tareas y cómo se usaron en diferentes empresas.
Recogí tres ejemplos que muestran ClickHouse desde diferentes ángulos. Creo que será interesante.

La primera pregunta es: “¿Por qué necesitamos ClickHouse?”. Parece ser una pregunta bastante obvia, pero hay más de una respuesta.

- La primera respuesta es para el rendimiento. ClickHouse es muy rápido. Analytics en ClickHouse también es muy rápido. A menudo se puede usar cuando algo más es muy lento o muy malo.
- La segunda respuesta es el costo. Y en primer lugar, el coste del escalado. Por ejemplo, Vertica es una base de datos absolutamente genial. Funciona muy bien si no tienes muchos terabytes de datos. Pero cuando se trata de cientos de terabytes o petabytes, el costo de una licencia y soporte es una cantidad bastante significativa. Y es caro Y ClickHouse es gratis.
- La tercera respuesta es el costo operativo. Este es un enfoque ligeramente diferente. RedShift es un gran análogo. En RedShift, puede tomar una decisión muy rápidamente. Funcionará bien, pero al mismo tiempo, cada hora, cada día y cada mes, le pagarás bastante caro a Amazon, porque es un servicio significativamente caro. Google BigQuery también. Si alguien lo usó, entonces sabe que allí puede ejecutar varias solicitudes y obtener una factura de cientos de dólares de repente.
ClickHouse no tiene estos problemas.

¿Dónde se usa ClickHouse ahora? Además de Yandex, ClickHouse se utiliza en muchos negocios y empresas diferentes.
- En primer lugar, se trata de análisis de aplicaciones web, es decir, este es un caso de uso que proviene de Yandex.
- Muchas empresas de tecnología publicitaria utilizan ClickHouse.
- Numerosas empresas que necesitan analizar registros de transacciones de diferentes fuentes.
- Varias empresas usan ClickHouse para monitorear los registros de seguridad. Los suben a ClickHouse, hacen informes y obtienen los resultados que necesitan.
- Las empresas están empezando a utilizarlo en el análisis financiero, es decir, poco a poco las grandes empresas también se están acercando a ClickHouse.
- llamarada de nube Si alguien sigue a ClickHouse, probablemente haya escuchado el nombre de esta empresa. Este es uno de los contribuyentes esenciales de la comunidad. Y tienen una instalación ClickHouse muy seria. Por ejemplo, crearon Kafka Engine para ClickHouse.
- Las empresas de telecomunicaciones comenzaron a utilizar. Varias empresas utilizan ClickHouse como prueba de concepto o ya en producción.
- Una empresa utiliza ClickHouse para monitorear los procesos de producción. Prueban microcircuitos, cancelan un montón de parámetros, hay alrededor de 2 características. Y luego analizan si el juego es bueno o malo.
- Análisis de cadena de bloques. Existe una empresa rusa como Bloxy.info. Este es un análisis de la red ethereum. También hicieron esto en ClickHouse.

Y el tamaño no importa. Muchas empresas usan un solo servidor pequeño y eso les soluciona sus problemas. Y aún más empresas usan grandes clústeres de muchos... servidores o docenas de servidores.
Y si miras los registros, entonces:
- Yandex: más de 500 servidores, almacenan 25 mil millones de registros al día allí.
- LifeStreet: 60 servidores, aproximadamente 75 mil millones de registros por día. Hay menos servidores, más registros que en Yandex.
- CloudFlare: 36 servidores, guardan 200 mil millones de registros al día. Tienen aún menos servidores y almacenan aún más datos.
- Bloomberg: 102 servidorAproximadamente un billón de entradas al día. Récord de entradas.
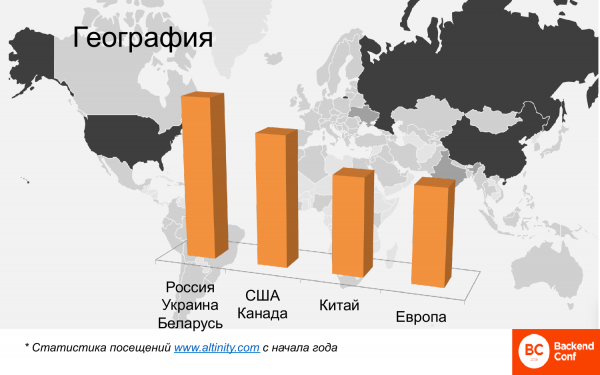
Geográficamente, esto también es mucho. Este mapa aquí muestra un mapa de calor de dónde se está utilizando ClickHouse en el mundo. Rusia, China, Estados Unidos se destacan claramente aquí. Hay pocos países europeos. Y hay 4 grupos.
Este es un análisis comparativo, no hay necesidad de buscar cifras absolutas. Este es un análisis de los visitantes que leen materiales en inglés en el sitio web de Altinity, porque allí no hay de habla rusa. Y Rusia, Ucrania, Bielorrusia, es decir, la parte de la comunidad de habla rusa, estos son los usuarios más numerosos. Luego viene Estados Unidos y Canadá. China se está poniendo al día. Casi no había China allí hace seis meses, ahora China ya ha superado a Europa y sigue creciendo. La vieja Europa tampoco se queda atrás, y el líder en el uso de ClickHouse es, curiosamente, Francia.

¿Por qué cuento todo esto? Mostrar que ClickHouse se está convirtiendo en una solución estándar para el análisis de big data y que ya se usa en muchos lugares. Si lo usas, estás en la tendencia correcta. Si aún no lo está usando, entonces no puede tener miedo de quedarse solo y nadie lo ayudará, porque muchos ya lo están haciendo.

Estos son ejemplos de uso real de ClickHouse en varias empresas.
- El primer ejemplo es una red publicitaria: migración de Vertica a ClickHouse. Y conozco algunas empresas que han hecho la transición de Vertica o están en proceso de transición.
- El segundo ejemplo es el almacenamiento transaccional en ClickHouse. Este es un ejemplo basado en antipatrones. Todo lo que no se debe hacer en ClickHouse por consejo de los desarrolladores se hace aquí. Y se hace con tanta eficacia que funciona. Y funciona mucho mejor que la típica solución transaccional.
- El tercer ejemplo es la computación distribuida en ClickHouse. Hubo una pregunta sobre cómo se puede integrar ClickHouse en el ecosistema de Hadoop. Mostraré un ejemplo de cómo una empresa hizo algo similar a un contenedor de reducción de mapa en ClickHouse, realizando un seguimiento de la localización de datos, etc., para calcular una tarea nada trivial.

- LifeStreet es una empresa de Ad Tech que tiene toda la tecnología que viene con una red publicitaria.
- Se dedica a la optimización de anuncios, licitaciones programáticas.
- Muchos datos: alrededor de 10 mil millones de eventos por día. Al mismo tiempo, los eventos allí se pueden dividir en varios subeventos.
- Hay muchos clientes de estos datos, y estos no son solo personas, mucho más: son varios algoritmos que participan en las ofertas programáticas.

La empresa ha recorrido un camino largo y espinoso. Y hablé de ello en HighLoad. Primero, LifeStreet pasó de MySQL (con una breve parada en Oracle) a Vertica. Y puedes encontrar una historia al respecto.
Y todo estuvo muy bien, pero rápidamente quedó claro que los datos están creciendo y que Vertica es costosa. Por ello, se buscaron diversas alternativas. Algunos de ellos se enumeran aquí. Y, de hecho, hicimos pruebas de concepto o, a veces, pruebas de rendimiento de casi todas las bases de datos que estaban disponibles en el mercado desde el año 13 hasta el 16 y eran aproximadamente adecuadas en términos de funcionalidad. Y también hablé de algunos de ellos en HighLoad.

La tarea era migrar desde Vertica en primer lugar, porque los datos crecían. Y crecieron exponencialmente a lo largo de los años. Luego se fueron en el estante, pero no obstante. Y al predecir este crecimiento, los requisitos comerciales para la cantidad de datos sobre los que se necesitaba realizar algún tipo de análisis, estaba claro que pronto se hablaría de petabytes. Y pagar petabytes ya es muy caro, así que buscábamos una alternativa a dónde ir.
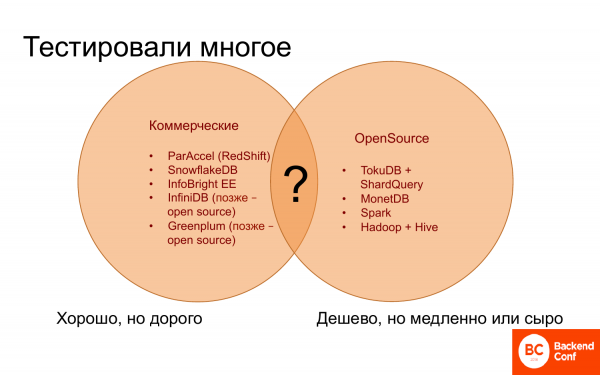
¿Dónde ir? Y durante mucho tiempo no estaba nada claro a dónde ir, porque por un lado hay bases de datos comerciales, parecen funcionar bien. Algunos funcionan casi tan bien como Vertica, otros peor. Pero todos son caros, no se pudo encontrar nada más barato y mejor.
Por otro lado, existen soluciones de código abierto, que no son muy numerosas, es decir, para analítica, se pueden contar con los dedos. Y son gratis o baratos, pero lentos. Y a menudo carecen de la funcionalidad necesaria y útil.
Y no había nada que combinar lo bueno que hay en las bases de datos comerciales y todo lo gratuito que hay en el código abierto.

No había nada hasta que, inesperadamente, Yandex sacó ClickHouse, como un mago de un sombrero, como un conejo. Y fue una decisión inesperada, todavía hacen la pregunta: "¿Por qué?", Pero sin embargo.
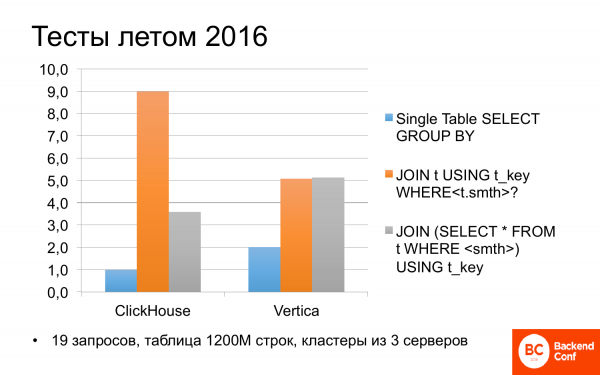
Y de inmediato, en el verano de 2016, comenzamos a ver qué es ClickHouse. Y resultó que a veces puede ser más rápido que Vertica. Probamos diferentes escenarios en diferentes solicitudes. Y si la consulta usaba solo una tabla, es decir, sin uniones (join), entonces ClickHouse era el doble de rápido que Vertica.
No fui demasiado perezoso y miré las pruebas de Yandex el otro día. Es lo mismo allí: ClickHouse es el doble de rápido que Vertica, por lo que a menudo hablan de eso.
Pero si hay uniones en las consultas, entonces todo resulta no muy ambiguo. Y ClickHouse puede ser el doble de lento que Vertica. Y si corrige ligeramente la solicitud y la vuelve a escribir, entonces son aproximadamente iguales. Nada mal. Y gratis.

Y después de recibir los resultados de la prueba y mirarlos desde diferentes ángulos, LifeStreet fue a ClickHouse.

Este es el año 16, les recuerdo. Era como un chiste sobre ratones que lloraban y se pinchaban, pero seguían comiéndose los nopales. Y esto se describió en detalle, hay un video sobre esto, etc.

Por lo tanto, no hablaré de eso en detalle, solo hablaré de los resultados y algunas cosas interesantes de las que no hablé entonces.
Los resultados son:
- Migración exitosa y más de un año el sistema ya está funcionando en producción.
- La productividad y la flexibilidad han aumentado. De los 10 75 millones de registros que podíamos permitirnos almacenar por día y luego por un período breve, LifeStreet ahora almacena 3 XNUMX millones de registros por día y puede hacerlo durante XNUMX meses o más. Si cuenta en el pico, entonces esto es hasta un millón de eventos por segundo. Más de un millón de consultas SQL al día llegan a este sistema, en su mayoría de diferentes robots.
- A pesar de que se usaron más servidores para ClickHouse que para Vertica, también ahorraron en hardware, porque en Vertica se usaron discos SAS bastante caros. ClickHouse utilizó SATA. ¿Y por qué? Porque en Vertica la inserción es síncrona. Y la sincronización requiere que los discos no se ralenticen demasiado, y también que la red no se ralentice demasiado, es decir, una operación bastante costosa. Y en ClickHouse, la inserción es asíncrona. Además, siempre puede escribir todo localmente, no hay costos adicionales por esto, por lo que los datos se pueden insertar en ClickHouse mucho más rápido que en Vertika, incluso en unidades más lentas. Y leer es casi lo mismo. Leyendo en SATA, si están en RAID, entonces todo esto es lo suficientemente rápido.
- No limitado por licencia, es decir, 3 petabytes de datos en 60 servidores (20 servidores es una réplica) y 6 billones de registros en hechos y agregaciones. Nada como esto podría permitirse en Vertica.

Paso ahora a las cosas prácticas en este ejemplo.
- El primero es un esquema eficiente. Mucho depende del esquema.
- El segundo es la generación eficiente de SQL.
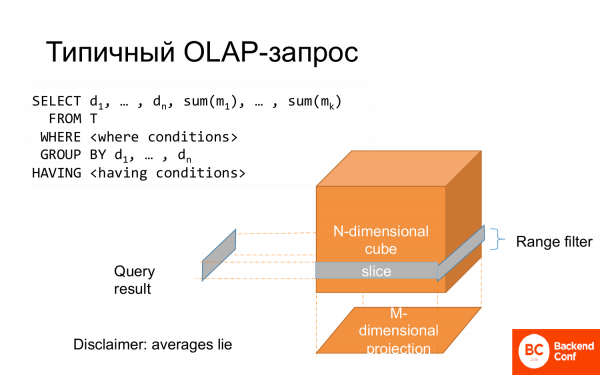
Una consulta OLAP típica es una selección. Algunas de las columnas van a agrupar por, algunas de las columnas van a funciones agregadas. Hay dónde, que se puede representar como una rebanada de cubo. Todo el grupo se puede considerar como una proyección. Y es por eso que se llama análisis de datos multivariados.

Y a menudo esto se modela en forma de esquema estelar, cuando hay un hecho central y características de este hecho a lo largo de los lados, a lo largo de los rayos.

Y en cuanto al diseño físico, cómo encaja en la mesa, suelen hacer una representación normalizada. Puede desnormalizar, pero es costoso en el disco y no es muy eficiente en las consultas. Por lo tanto, suelen hacer una representación normalizada, es decir, una tabla de hechos y muchas, muchas tablas de dimensiones.
Pero no funciona bien en ClickHouse. Hay dos razones:
- La primera es porque ClickHouse no tiene muy buenos joins, es decir, hay joins, pero son malos. Mientras mal.
- La segunda es que las tablas no están actualizadas. Por lo general, en estas placas, que están alrededor del circuito estelar, es necesario cambiar algo. Por ejemplo, nombre del cliente, nombre de la empresa, etc. Y no funciona.
Y hay una salida a esto en ClickHouse. incluso dos:
- El primero es el uso de diccionarios. External Dictionaries es lo que ayuda al 99% a resolver el problema con el esquema en estrella, con actualizaciones, etc.
- El segundo es el uso de matrices. Las matrices también ayudan a eliminar las uniones y los problemas de normalización.

- No es necesario unirse.
- Actualizable. Desde marzo de 2018 ha aparecido una oportunidad no documentada (no la encontrarás en la documentación) para actualizar parcialmente los diccionarios, es decir, aquellas entradas que han cambiado. Prácticamente, es como una mesa.
- Siempre en memoria, por lo que las uniones con un diccionario funcionan más rápido que si fuera una tabla que está en disco y aún no es un hecho que esté en caché, lo más probable es que no.

- Tampoco necesitas uniones.
- Esta es una representación compacta de 1 a muchos.
- Y en mi opinión, las matrices están hechas para geeks. Estas son funciones lambda y así sucesivamente.
Esto no es para palabras rojas. Esta es una funcionalidad muy poderosa que te permite hacer muchas cosas de una manera muy simple y elegante.

Ejemplos típicos que ayudan a resolver arreglos. Estos ejemplos son lo suficientemente simples y claros:
- Buscar Por Etiquetas. Si tiene hashtags allí y desea encontrar algunas publicaciones por hashtag.
- Búsqueda por pares clave-valor. También hay algunos atributos con un valor.
- Almacenar listas de claves que necesita traducir a otra cosa.
Todas estas tareas se pueden resolver sin arreglos. Las etiquetas se pueden poner en alguna línea y seleccionar con una expresión regular o en una tabla separada, pero luego hay que hacer uniones.

Y en ClickHouse, no necesita hacer nada, basta con describir la matriz de cadenas para los hashtags o crear una estructura anidada para los sistemas clave-valor.
La estructura anidada puede no ser el mejor nombre. Se trata de dos matrices que tienen una parte común en el nombre y algunas características relacionadas.
Y es muy fácil buscar por etiqueta. tener una función has, que comprueba que la matriz contiene un elemento. Todos, encontraron todas las entradas relacionadas con nuestra conferencia.
Buscar por subid es un poco más complicado. Primero debemos encontrar el índice de la clave y luego tomar el elemento con este índice y verificar que este valor es lo que necesitamos. Sin embargo, es muy simple y compacto.
La expresión regular que le gustaría escribir si la mantuviera toda en una sola línea, sería, en primer lugar, torpe. Y, en segundo lugar, funcionó mucho más que dos matrices.

Otro ejemplo. Tiene una matriz donde almacena la identificación. Y puedes traducirlos a nombres. Función arrayMap. Esta es una función lambda típica. Pasas expresiones lambda allí. Y saca el valor del nombre para cada ID del diccionario.
La búsqueda se puede hacer de la misma manera. Se pasa una función de predicado que comprueba qué elementos coinciden.

Estas cosas simplifican enormemente el circuito y resuelven un montón de problemas.
Pero el siguiente problema al que nos enfrentamos, y que me gustaría mencionar, son las consultas eficientes.
- ClickHouse no tiene un planificador de consultas. Absolutamente no.
- Sin embargo, las consultas complejas aún deben planificarse. ¿En qué casos?
- Si hay múltiples uniones en la consulta, las envuelve en subselecciones. Y el orden en que se ejecutan importa.
- Y el segundo, si la solicitud se distribuye. Porque en una consulta distribuida, solo la subselección más interna se ejecuta distribuida, y todo lo demás se pasa a un servidor al que se conectó y se ejecutó allí. Por lo tanto, si tiene consultas distribuidas con muchas uniones (join), entonces debe elegir el orden.
E incluso en casos más simples, a veces también es necesario hacer el trabajo del planificador y reescribir un poco las consultas.

Aquí hay un ejemplo. En el lado izquierdo hay una consulta que muestra los 5 países principales. Y tarda 2,5 segundos, en mi opinión. Y en el lado derecho, la misma consulta, pero ligeramente reescrita. En lugar de agrupar por cadena, comenzamos a agrupar por clave (int). Y es más rápido. Y luego conectamos un diccionario al resultado. En lugar de 2,5 segundos, la solicitud tarda 1,5 segundos. Esto es bueno.

Un ejemplo similar con filtros de reescritura. Aquí hay una solicitud para Rusia. Funciona durante 5 segundos. Si lo reescribimos de tal manera que comparamos nuevamente no una cadena, sino números con algún conjunto de esas claves que se relacionan con Rusia, entonces será mucho más rápido.

Hay muchos trucos de este tipo. Y le permiten acelerar significativamente las consultas que cree que ya se ejecutan rápido o, por el contrario, se ejecutan lentamente. Se pueden hacer aún más rápido.

- Máximo trabajo en modo distribuido.
- Ordenando por tipos mínimos, como hice por ints.
- Si hay uniones (join), diccionarios, entonces es mejor hacerlo como último recurso, cuando ya tenga datos al menos parcialmente agrupados, entonces la operación de unión o llamada de diccionario se llamará menos veces y será más rápido. .
- Reemplazo de filtros.
Hay otras técnicas, y no sólo las que he demostrado. Y todos ellos a veces pueden acelerar significativamente la ejecución de consultas.

Pasemos al siguiente ejemplo. Empresa X de EE.UU. ¿Qué está haciendo?
Había una tarea:
- Vinculación offline de transacciones publicitarias.
- Modelado de diferentes modelos de encuadernación.

¿Cuál es el escenario?
Un visitante normal llega al sitio, por ejemplo, 20 veces al mes con diferentes anuncios, o simplemente a veces viene sin ningún anuncio, porque recuerda este sitio. Mira algunos productos, los mete en la canasta, los saca de la canasta. Y, al final, algo compra.
Preguntas razonables: "¿Quién debe pagar la publicidad, si es necesario?" y “¿Qué publicidad lo influenció, si es que hubo alguna?”. Es decir, ¿por qué compró y cómo hacer que gente como esta persona también compre?
Para resolver este problema, debe conectar los eventos que ocurren en el sitio web de la manera correcta, es decir, de alguna manera construir una conexión entre ellos. Luego se envían para su análisis a DWH. Y en base a este análisis, construya modelos de quién y qué anuncios mostrar.

Una transacción publicitaria es un conjunto de eventos de usuario relacionados que comienzan mostrando un anuncio, luego sucede algo, luego tal vez una compra y luego puede haber compras dentro de una compra. Por ejemplo, si se trata de una aplicación móvil o un juego móvil, generalmente la instalación de la aplicación se realiza de forma gratuita, y si se hace algo allí, es posible que se requiera dinero para esto. Y cuanto más gasta una persona en la aplicación, más valiosa es. Pero para esto necesitas conectar todo.

Hay muchos modelos de encuadernación.
Los más populares son:
- Última interacción, donde la interacción es un clic o una impresión.
- Primera interacción, es decir, lo primero que trajo a una persona al sitio.
- Combinación lineal - todos por igual.
- Atenuación.
- Etc.
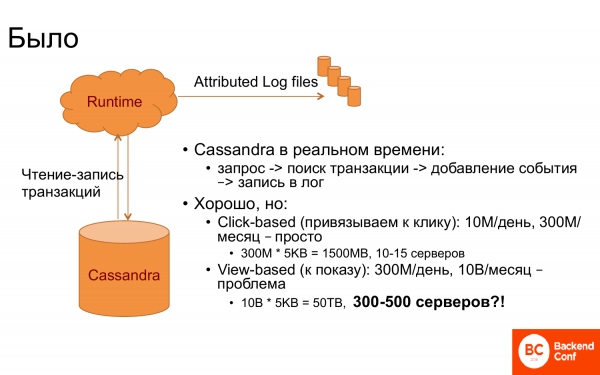
¿Y cómo funcionó todo en primer lugar? Estaban Runtime y Cassandra. Cassandra se utilizó como almacenamiento de transacciones, es decir, todas las transacciones relacionadas se almacenaron en él. Y cuando aparece algún evento en Runtime, por ejemplo, mostrando alguna página u otra cosa, entonces se hizo una solicitud a Cassandra: ¿existe esa persona o no? Luego se obtuvieron las transacciones que se relacionan con el mismo. Y se hizo la conexión.
Y si tiene suerte de que la solicitud tenga una identificación de transacción, entonces es fácil. Pero normalmente no hay suerte. Por lo tanto, era necesario encontrar la última transacción o la transacción con el último clic, etc.
Y todo funcionó muy bien siempre que la vinculación fuera hasta el último clic. Porque hay, digamos, 10 millones de clics por día, 300 millones por mes, si establecemos una ventana de un mes. Y dado que en Cassandra tiene que estar todo en la memoria para ejecutarse rápido, porque el tiempo de ejecución debe responder rápidamente, se necesitaron entre 10 y 15 servidores.
Y cuando querían vincular una transacción a la pantalla, inmediatamente resultó que no era tan divertido. ¿Y por qué? Se puede ver que es necesario almacenar 30 veces más eventos. Y, en consecuencia, necesita 30 veces más servidores. Y resulta que se trata de una especie de figura astronómica. Mantener hasta 500 servidores para hacer la vinculación, a pesar de que hay muchos menos servidores en Runtime, entonces esta es una cifra incorrecta. Y empezaron a pensar qué hacer.

Y fuimos a ClickHouse. ¿Y cómo hacerlo en ClickHouse? A primera vista, parece que se trata de un conjunto de antipatrones.
- La transacción crece, le conectamos más y más eventos, es decir, es mutable, y ClickHouse no funciona muy bien con objetos mutables.
- Cuando un visitante viene a nosotros, debemos extraer sus transacciones por clave, por su identificación de visita. Esta también es una consulta puntual, no lo hacen en ClickHouse. Por lo general, ClickHouse tiene escaneos grandes, pero aquí necesitamos obtener algunos registros. También un antipatrón.
- Además, la transacción estaba en json, pero no querían reescribirla, por lo que querían almacenar json de forma no estructurada y, si era necesario, sacar algo de él. Y esto también es un antipatrón.
Es decir, un conjunto de antipatrones.
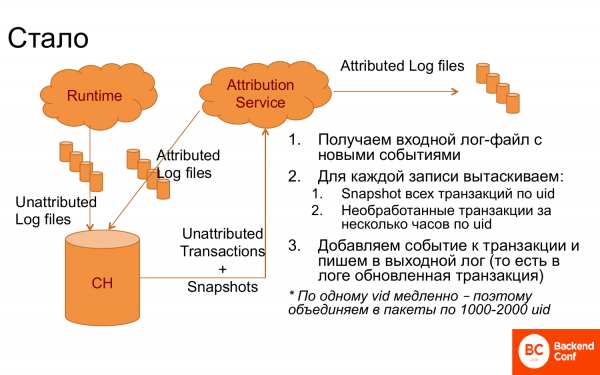
Pero, sin embargo, resultó ser un sistema que funcionó muy bien.
¿Lo que fue hecho? Apareció ClickHouse, en el que se arrojaron registros, divididos en registros. Apareció un servicio atribuido que recibió registros de ClickHouse. Después de eso, para cada entrada, por identificación de visita, recibí transacciones que podrían no haber sido procesadas aún y más instantáneas, es decir, transacciones ya conectadas, es decir, el resultado de un trabajo anterior. Ya hice lógica con ellos, elegí la transacción correcta, conecté nuevos eventos. Registrado de nuevo. El registro volvió a ClickHouse, es decir, es un sistema constantemente cíclico. Y además, fui a DWH a analizarlo allí.
Fue en esta forma que no funcionó muy bien. Y para facilitarle las cosas a ClickHouse, cuando había una solicitud por identificación de visita, agrupaban estas solicitudes en bloques de 1 a 000 identificaciones de visita y extraían todas las transacciones de 2 a 000 personas. Y entonces todo funcionó.
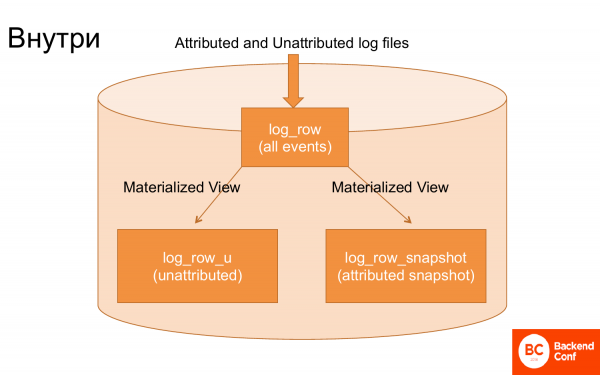
Si miras dentro de ClickHouse, entonces solo hay 3 mesas principales que sirven para todo esto.
La primera tabla en la que se cargan los registros y los registros se cargan casi sin procesamiento.
Segunda mesa. A través de la vista materializada, los eventos que aún no han sido atribuidos, es decir, los que no están relacionados, fueron eliminados de estos registros. Y a través de la vista materializada, las transacciones se extrajeron de estos registros para crear una instantánea. Es decir, una vista materializada especial creó una instantánea, es decir, el último estado acumulado de la transacción.
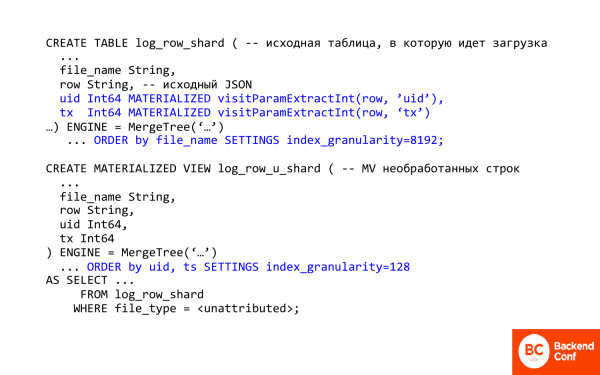
Aquí está el texto escrito en SQL. Me gustaría comentar algunas cosas importantes en él.
Lo primero importante es la capacidad de extraer columnas y campos de json en ClickHouse. Es decir, ClickHouse tiene algunos métodos para trabajar con json. Son muy, muy primitivos.
visitParamExtractInt le permite extraer atributos de json, es decir, el primer golpe funciona. Y de esta manera puede extraer la identificación de la transacción o la identificación de la visita. Esta vez.
En segundo lugar, aquí se utiliza un campo materializado engañoso. ¿Qué significa? Esto significa que no puede insertarlo en la tabla, es decir, no se inserta, se calcula y almacena al insertarlo. Al pegar, ClickHouse hace el trabajo por usted. Y lo que necesita más adelante ya está extraído de json.
En este caso, la vista materializada es para filas sin procesar. Y solo se usa la primera tabla con registros prácticamente sin procesar. ¿Y qué hace? En primer lugar, cambia la clasificación, es decir, la clasificación ahora se realiza por identificación de visita, porque necesitamos extraer rápidamente su transacción para una persona específica.
La segunda cosa importante es index_granularity. Si ha visto MergeTree, generalmente es 8 por defecto index_granularity. ¿Lo que es? Este es el parámetro de dispersión del índice. En ClickHouse, el índice es escaso, nunca indexa todas las entradas. Hace esto cada 192. Y esto es bueno cuando se requiere calcular una gran cantidad de datos, pero malo cuando se necesita poca, porque hay una gran sobrecarga. Y si reducimos la granularidad del índice, entonces reducimos la sobrecarga. No se puede reducir a uno, porque puede que no haya suficiente memoria. El índice siempre se almacena en la memoria.

Snapshot también utiliza otras características interesantes de ClickHouse.
Primero, es AggregatingMergeTree. Y AggregatingMergeTree almacena argMax, es decir, este es el estado de la transacción correspondiente a la última marca de tiempo. Las transacciones se generan todo el tiempo para un visitante determinado. Y en el último estado de esta transacción, agregamos un evento y tenemos un nuevo estado. Golpeó a ClickHouse nuevamente. Y a través de argMax en esta vista materializada, siempre podemos obtener el estado actual.

- El enlace está "desacoplado" del tiempo de ejecución.
- Se almacenan y procesan hasta 3 mil millones de transacciones por mes. Este es un orden de magnitud más de lo que era en Cassandra, es decir, en un sistema transaccional típico.
- Cluster de 2x5 servidores ClickHouse. 5 servidores y cada servidor tiene una réplica. Esto es incluso menos de lo que era en Cassandra para realizar la atribución basada en clics, y aquí tenemos la atribución basada en impresiones. Es decir, en lugar de aumentar 30 veces la cantidad de servidores, lograron reducirlos.

Y el último ejemplo es la compañía financiera Y, que analizó las correlaciones de los cambios en los precios de las acciones.
Y la tarea era:
- Hay aproximadamente 5 acciones.
- Se conocen cotizaciones cada 100 milisegundos.
- Los datos se han acumulado durante 10 años. Aparentemente, para algunas empresas más, para otras menos.
- Hay aproximadamente 100 mil millones de filas en total.
Y era necesario calcular la correlación de cambios.
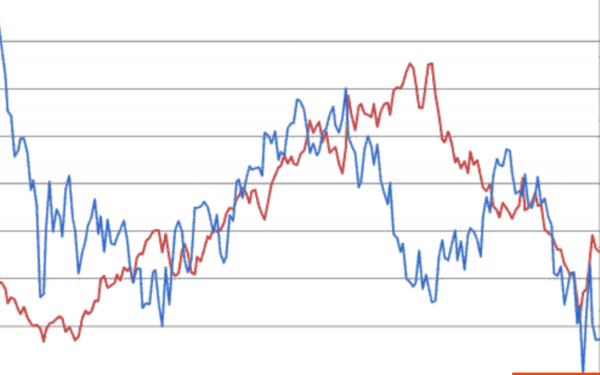
Aquí hay dos acciones y sus cotizaciones. Si uno sube y el otro sube, entonces esta es una correlación positiva, es decir, uno sube y el otro sube. Si uno sube, como al final del gráfico, y el otro baja, entonces se trata de una correlación negativa, es decir, cuando uno sube, el otro baja.
Al analizar estos cambios mutuos, se pueden hacer predicciones en el mercado financiero.

Pero la tarea es difícil. ¿Qué se está haciendo para esto? Tenemos 100 mil millones de registros que tienen: tiempo, stock y precio. Necesitamos calcular primero 100 mil millones de veces la diferencia de ejecución del algoritmo de precios. RunningDifference es una función en ClickHouse que calcula secuencialmente la diferencia entre dos cadenas.
Y después de eso, debe calcular la correlación, y la correlación debe calcularse para cada par. Por 5 acciones, los pares son 000 millones. Y esto es mucho, es decir, 12,5 veces es necesario calcular tal función de correlación.
Y si alguien se olvidó, entonces ͞x y ͞y es un jaque mate. expectativa de muestreo. Es decir, es necesario no solo calcular las raíces y las sumas, sino también una suma más dentro de estas sumas. Es necesario realizar un montón de cálculos 12,5 millones de veces, e incluso agruparlos por horas. También tenemos muchas horas. Y tienes que hacerlo en 60 segundos. Es una broma.

Era necesario tener tiempo al menos de alguna manera, porque todo esto funcionaba muy, muy lentamente antes de que llegara ClickHouse.

Intentaron calcularlo en Hadoop, en Spark, en Greenplum. Y todo esto era muy lento o caro. Es decir, era posible calcular de alguna manera, pero luego era costoso.
Y luego apareció ClickHouse y las cosas mejoraron mucho.
Les recuerdo que tenemos un problema con la localidad de los datos, porque las correlaciones no se pueden localizar. No podemos poner algunos de los datos en un servidor, algunos en otro y calcular, debemos tener todos los datos en todas partes.
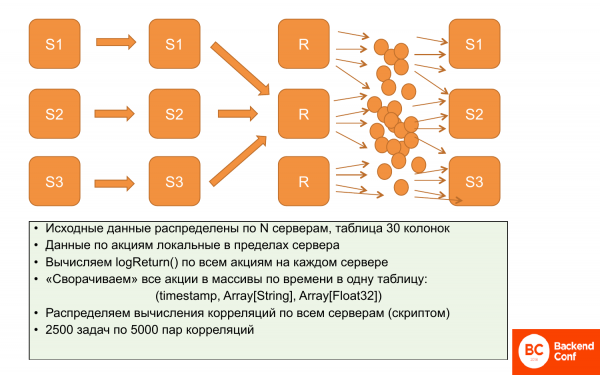
¿Que hicieron? Inicialmente, los datos están localizados. Cada servidor almacena datos sobre el precio de un determinado conjunto de acciones. Y no se superponen. Por lo tanto, es posible calcular logReturn en paralelo y de forma independiente, todo esto ocurre hasta ahora en paralelo y distribuido.
Entonces decidimos reducir estos datos, sin perder expresividad. Reduzca el uso de matrices, es decir, para cada período de tiempo, haga una matriz de acciones y una matriz de precios. Por lo tanto, ocupa mucho menos espacio de datos. Y son un poco más fáciles de trabajar. Estas son operaciones casi paralelas, es decir, leemos parcialmente en paralelo y luego escribimos en el servidor.
Después de eso, se puede replicar. La letra "r" significa que replicamos estos datos. Es decir, tenemos los mismos datos en los tres servidores: estos son los arreglos.
Y luego, con un script especial de este conjunto de 12,5 millones de correlaciones que deben calcularse, puede crear paquetes. Es decir, 2 tareas con 500 pares de correlaciones. Y esta tarea debe calcularse en un servidor ClickHouse específico. Tiene todos los datos, porque los datos son los mismos y puede calcularlos secuencialmente.
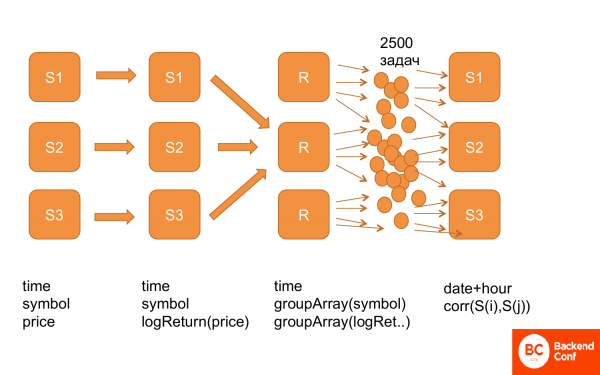
Una vez más, esto es lo que parece. Primero, tenemos todos los datos en esta estructura: tiempo, acciones, precio. Luego calculamos logReturn, es decir, datos de la misma estructura, pero en lugar del precio ya tenemos logReturn. Luego se rehicieron, es decir, obtuvimos el tiempo y groupArray para acciones y precios. Sreplicado. Y después de eso, generamos un montón de tareas y las alimentamos a ClickHouse para que las contara. Y funciona.

En la prueba de concepto, la tarea era una subtarea, es decir, se tomaron menos datos. Y solo tres servidores.
Estas dos primeras etapas: calcular Log_return y envolver en matrices tomó alrededor de una hora.
Y el cálculo de la correlación es de unas 50 horas. Pero 50 horas no son suficientes, porque solían trabajar durante semanas. Fue un gran éxito. Y si cuentas, entonces 70 veces por segundo todo se contó en este grupo.
Pero lo más importante es que este sistema prácticamente no tiene cuellos de botella, es decir, escala casi linealmente. Y lo comprobaron. Lo amplió con éxito.

- El esquema correcto es la mitad de la batalla. Y el esquema correcto es el uso de todas las tecnologías necesarias de ClickHouse.
- Summing/AggregatingMergeTrees son tecnologías que le permiten agregar o considerar una instantánea de estado como un caso especial. Y simplifica mucho muchas cosas.
- Las vistas materializadas le permiten omitir el límite de un índice. Tal vez no lo dije muy claramente, pero cuando cargamos los registros, los registros sin procesar estaban en la tabla con un índice y los registros de atributos estaban en la tabla, es decir, los mismos datos, solo filtrados, pero el índice estaba completamente otros. Parece ser la misma información, pero diferente clasificación. Y Materialized Views le permite, si lo necesita, eludir dicha limitación de ClickHouse.
- Reduzca la granularidad del índice para las consultas puntuales.
- Y distribuya los datos de manera inteligente, intente localizar los datos dentro del servidor tanto como sea posible. Y trate de asegurarse de que las solicitudes también utilicen la localización siempre que sea posible.
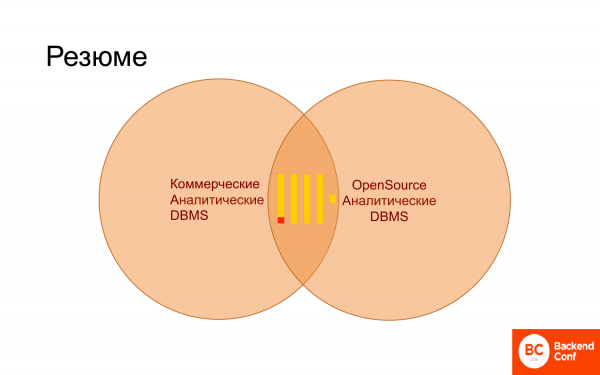
Y resumiendo este breve discurso, podemos decir que ClickHouse ahora ha ocupado firmemente el territorio tanto de las bases de datos comerciales como de las bases de datos de código abierto, es decir, específicamente para análisis. Encaja perfectamente en este paisaje. Y lo que es más, lentamente comienza a desplazar a otros, porque cuando tiene ClickHouse, no necesita InfiniDB. Es posible que Vertika no sea necesario pronto si tienen soporte SQL normal. ¡Disfrutar!

-¡Gracias por el informe! ¡Muy interesante! ¿Hubo alguna comparación con Apache Phoenix?
No, no he oído a nadie comparar. Nosotros y Yandex intentamos realizar un seguimiento de todas las comparaciones de ClickHouse con diferentes bases de datos. Porque si de repente algo resulta ser más rápido que ClickHouse, entonces Lesha Milovidov no puede dormir por la noche y comienza a acelerarlo rápidamente. No he oído hablar de tal comparación.
(Aleksey Milovidov) Apache Phoenix es un motor SQL impulsado por Hbase. Hbase es principalmente para el escenario de trabajo de clave-valor. Allí, en cada línea, puede haber un número arbitrario de columnas con nombres arbitrarios. Esto se puede decir sobre sistemas como Hbase, Cassandra. Y son precisamente las consultas analíticas pesadas las que no funcionarán normalmente para ellos. O podría pensar que funcionan bien si no ha tenido ninguna experiencia con ClickHouse.
Gracias
Buenas tardes Ya estoy bastante interesado en este tema, porque tengo un subsistema analítico. Pero cuando miro a ClickHouse, tengo la sensación de que ClickHouse es muy adecuado para el análisis de eventos, mutable. Y si necesito analizar una gran cantidad de datos comerciales con un montón de tablas grandes, ClickHouse, según tengo entendido, no es muy adecuado para mí. Sobre todo si cambian. ¿Es esto correcto o hay ejemplos que pueden refutar esto?
Esto es correcto. Y esto es cierto para la mayoría de las bases de datos analíticas especializadas. Se adaptan al hecho de que hay una o más tablas grandes que son mutables y muchas pequeñas que cambian lentamente. Es decir, ClickHouse no es como Oracle, donde puedes poner todo y construir algunas consultas muy complejas. Para usar ClickHouse de manera efectiva, debe crear un esquema de manera que funcione bien en ClickHouse. Es decir, evita la normalización excesiva, usa diccionarios, intenta hacer menos enlaces largos. Y si el esquema se construye de esta manera, las tareas comerciales similares se pueden resolver en ClickHouse de manera mucho más eficiente que en una base de datos relacional tradicional.
¡Gracias por el informe! Tengo una pregunta sobre el último caso financiero. Tenían análisis. Era necesario comparar cómo suben y bajan. ¿Y entiendo que construyó el sistema específicamente para este análisis? Si mañana, por ejemplo, necesitan algún otro informe sobre estos datos, ¿necesitan reconstruir el esquema y cargar los datos? Es decir, ¿hacer algún tipo de preprocesamiento para obtener la solicitud?
Por supuesto, este es el uso de ClickHouse para una tarea muy específica. Podría resolverse más tradicionalmente dentro de Hadoop. Para Hadoop, esta es una tarea ideal. Pero en Hadoop es muy lento. Y mi objetivo es demostrar que ClickHouse puede resolver tareas que normalmente se resuelven por medios completamente diferentes, pero al mismo tiempo hacerlo de manera mucho más eficiente. Está diseñado para una tarea específica. Está claro que si hay un problema con algo similar, entonces se puede resolver de manera similar.
Está vacío. Dijiste que se procesaron 50 horas. ¿Es desde el principio, cuándo cargó los datos u obtuvo los resultados?
Si, si
Vale, muchas gracias.
Esto está en un clúster de 3 servidores.
¡Saludos! ¡Gracias por el informe! Todo es muy interesante. No preguntaré un poco sobre la funcionalidad, sino sobre el uso de ClickHouse en términos de estabilidad. Es decir, ¿tuviste alguna, tuviste que restaurar? ¿Cómo se comporta ClickHouse en este caso? ¿Y sucedió que también tenías una réplica? Por ejemplo, encontramos un problema con ClickHouse cuando todavía se sale de su límite y se cae.
Por supuesto, no hay sistemas ideales. Y ClickHouse también tiene sus propios problemas. Pero, ¿ha oído hablar de que Yandex.Metrica no funciona durante mucho tiempo? Probablemente no. Ha estado funcionando de manera confiable desde 2012-2013 en ClickHouse. Puedo decir lo mismo de mi experiencia. Nunca hemos tenido fracasos completos. Algunas cosas parciales podrían suceder, pero nunca fueron lo suficientemente críticas como para afectar seriamente el negocio. Nunca sucedió. ClickHouse es bastante fiable y no se cuelga al azar. No tienes que preocuparte por eso. No es algo crudo. Esto ha sido probado por muchas empresas.
¡Hola! Dijiste que necesitas pensar en el esquema de datos de inmediato. ¿Qué pasa si sucedió? Mis datos están vertiendo y vertiendo. Pasan seis meses y entiendo que es imposible vivir así, necesito volver a subir los datos y hacer algo con ellos.
Esto depende, por supuesto, de su sistema. Hay varias maneras de hacer esto prácticamente sin parar. Por ejemplo, puede crear una vista materializada en la que crear una estructura de datos diferente si se puede asignar de forma única. Es decir, si permite el mapeo usando ClickHouse, es decir, extraer algunas cosas, cambiar la clave principal, cambiar la partición, entonces puede hacer una Vista materializada. Sobrescriba sus datos antiguos allí, los nuevos se escribirán automáticamente. Y luego simplemente cambie a usar la Vista materializada, luego cambie el registro y elimine la tabla anterior. Este es generalmente un método continuo.
Gracias.
Fuente: habr.com
