

A partir del año pasado, nuestra empresa empezó a organizar hackatones. El primer concurso de este tipo tuvo mucho éxito, escribimos sobre ello en . El segundo hackathon tuvo lugar en febrero de 2019 y no fue menos exitoso. Sobre los objetivos de la celebración de este último no hace mucho organizador.
A los participantes se les asignó una tarea bastante interesante con total libertad para elegir una pila de tecnología para su implementación. Era necesario implementar una plataforma de toma de decisiones para una implementación conveniente de funciones de puntuación de clientes que pudiera funcionar con un flujo rápido de aplicaciones, soportar cargas pesadas y que el sistema en sí fuera fácilmente escalable.
La tarea no es trivial y se puede resolver de muchas maneras, como nos convencimos durante la demostración de las presentaciones finales de los proyectos de los participantes. En el hackathon participaron 6 equipos de 5 personas, todos los participantes tenían buenos proyectos, pero nuestra plataforma resultó ser la más competitiva. Tenemos un proyecto muy interesante, del que me gustaría hablar en este artículo.
Nuestra solución es una plataforma basada en arquitectura Serverless dentro de Kubernetes, lo que reduce el tiempo necesario para llevar nuevas funciones a producción. Permite a los analistas escribir código en un entorno que les resulte conveniente e implementarlo en producción sin la participación de ingenieros y desarrolladores.
que es puntuar
Tinkoff.ru, como muchas empresas modernas, tiene puntuación de clientes. Scoring es un sistema de evaluación de clientes basado en métodos estadísticos de análisis de datos.
Por ejemplo, un cliente nos solicita que le concedamos un préstamo o que abramos una cuenta de empresario individual con nosotros. Si planeamos otorgarle un préstamo, entonces debemos evaluar su solvencia, y si la cuenta es de un empresario individual, entonces debemos estar seguros de que el cliente no realizará transacciones fraudulentas.
La base para tomar este tipo de decisiones son modelos matemáticos que analizan tanto los datos de la propia aplicación como los de nuestro almacenamiento. Además de la puntuación, también se pueden utilizar métodos estadísticos similares para generar recomendaciones individuales de nuevos productos para nuestros clientes.
El método de tal evaluación puede aceptar una variedad de datos de entrada. Y en algún momento podremos agregar un nuevo parámetro a la entrada que, según los resultados del análisis de datos históricos, aumentará la tasa de conversión del uso del servicio.
Disponemos de una gran cantidad de datos sobre las relaciones con los clientes y el volumen de esta información crece constantemente. Para que la puntuación funcione, el procesamiento de datos también requiere reglas (o modelos matemáticos) que le permitan decidir rápidamente a quién aprobar una solicitud, a quién rechazar y a quién ofrecer un par de productos más, evaluando su interés potencial.
Para la tarea que nos ocupa ya utilizamos un sistema de toma de decisiones especializado. , que, basándose en las reglas establecidas por analistas, tecnólogos y desarrolladores, decide si aprobar o rechazar un producto bancario en particular al cliente.
Existen en el mercado multitud de soluciones ya preparadas, tanto modelos de puntuación como sistemas propios de toma de decisiones. Utilizamos uno de estos sistemas en nuestra empresa. Pero el negocio crece, se diversifica, aumenta tanto el número de clientes como el número de productos ofrecidos y, al mismo tiempo, surgen ideas sobre cómo mejorar el proceso de toma de decisiones existente. Seguramente las personas que trabajan con el sistema existente tienen muchas ideas sobre cómo hacerlo más simple, mejor y más conveniente, pero a veces las ideas externas son útiles. El New Hackathon se organizó con el objetivo de recopilar ideas sólidas.
Tarea
El hackathon se celebró el 23 de febrero. A los participantes se les propuso una tarea de combate: desarrollar un sistema de toma de decisiones que debía cumplir una serie de condiciones.
Nos dijeron cómo funciona el sistema existente y qué dificultades surgen durante su funcionamiento, así como qué objetivos comerciales debe perseguir la plataforma desarrollada. El sistema debe tener un tiempo de comercialización rápido para desarrollar reglas, de modo que el código de trabajo de los analistas entre en producción lo más rápido posible. Y para el flujo entrante de solicitudes, el tiempo de toma de decisiones debería tender a ser mínimo. Además, el sistema que se está desarrollando debe tener capacidades de venta cruzada para brindarle al cliente la oportunidad de comprar otros productos de la empresa si son aprobados por nosotros y tienen un interés potencial por parte del cliente.
Está claro que es imposible escribir un proyecto listo para su lanzamiento de la noche a la mañana que seguramente entrará en producción, y es bastante difícil cubrir todo el sistema, por lo que nos pidieron que implementáramos al menos una parte. Se establecieron una serie de requisitos que debe cumplir el prototipo. Se pudo intentar tanto cubrir todos los requisitos en su totalidad como trabajar en detalle en secciones individuales de la plataforma en desarrollo.
En cuanto a la tecnología, todos los participantes tuvieron total libertad de elección. Fue posible utilizar cualquier concepto y tecnología: transmisión de datos, aprendizaje automático, abastecimiento de eventos, big data y otros.
Nuestra solución
Después de una pequeña lluvia de ideas, decidimos que una solución FaaS sería ideal para completar la tarea.
Para esta solución, era necesario encontrar un marco Serverless adecuado para implementar las reglas del sistema de toma de decisiones que se estaba desarrollando. Dado que Tinkoff utiliza activamente Kubernetes para la gestión de infraestructura, analizamos varias soluciones listas para usar basadas en él; les contaré más sobre esto más adelante.
Para encontrar la solución más eficaz, analizamos el producto que se estaba desarrollando a través de los ojos de sus usuarios. Los principales usuarios de nuestro sistema son analistas involucrados en el desarrollo de reglas. Las reglas deben desplegarse en el servidor, o como en nuestro caso, desplegarse en la nube, para la posterior toma de decisiones. Desde la perspectiva de un analista, el flujo de trabajo se ve así:
- El analista escribe un script, una regla o un modelo de ML basado en datos del almacén. Como parte del hackathon, decidimos utilizar Mongodb, pero la elección del sistema de almacenamiento de datos no es importante aquí.
- Después de probar las reglas desarrolladas sobre datos históricos, el analista carga su código en el panel de administración.
- Para garantizar el control de versiones, todo el código irá a los repositorios de Git.
- A través del panel de administración será posible implementar el código en la nube como un módulo funcional independiente sin servidor.
Los datos iniciales de los clientes deben pasar por un servicio de enriquecimiento especializado diseñado para enriquecer la solicitud inicial con datos del almacén. Era importante implementar este servicio de tal manera que funcionara con un único repositorio (del cual el analista toma datos al desarrollar reglas) para mantener una estructura de datos unificada.
Incluso antes del hackathon, decidimos qué marco Serverless usaríamos. Hoy en día existen bastantes tecnologías en el mercado que implementan este enfoque. Las soluciones más populares dentro de la arquitectura Kubernetes son Fission, Open FaaS y Kubeless. Incluso hay .
Después de sopesar todos los pros y los contras, elegimos . Este marco sin servidor es bastante fácil de administrar y cumple con los requisitos de la tarea.
Para trabajar con Fission, es necesario comprender dos conceptos básicos: función y entorno. Una función es un fragmento de código escrito en uno de los lenguajes para los que existe un entorno Fission. Incluye Python, JS, Go, JVM y muchos otros lenguajes y tecnologías populares.
Fission también es capaz de realizar funciones divididas en varios archivos, empaquetados previamente en un archivo. El funcionamiento de Fission en un clúster de Kubernetes está garantizado por pods especializados, que son gestionados por el propio marco. Para interactuar con los pods del clúster, a cada función se le debe asignar su propia ruta, a la que puede pasar parámetros GET o el cuerpo de la solicitud en el caso de una solicitud POST.
Como resultado, planeamos obtener una solución que permitiera a los analistas implementar scripts de reglas desarrollados sin la participación de ingenieros y desarrolladores. El enfoque descrito también elimina la necesidad de que los desarrolladores reescriban el código del analista en otro idioma. Por ejemplo, para el sistema de toma de decisiones actual que utilizamos, tenemos que escribir reglas en tecnologías y lenguajes altamente especializados, cuyo alcance es extremadamente limitado, y también existe una fuerte dependencia del servidor de aplicaciones, ya que todos los borradores de reglas bancarias se implementan en un único entorno. Como resultado, para implementar nuevas reglas es necesario liberar todo el sistema.
En nuestra solución propuesta, no es necesario publicar reglas; el código se puede implementar fácilmente con solo hacer clic en un botón. Además, la gestión de infraestructura en Kubernetes le permite no pensar en la carga y el escalamiento; estos problemas se resuelven de inmediato. Y el uso de un único almacén de datos elimina la necesidad de comparar datos en tiempo real con datos históricos, lo que simplifica el trabajo del analista.
Que conseguimos
Desde que llegamos al hackathon con una solución ya preparada (en nuestras fantasías), todo lo que teníamos que hacer era convertir todos nuestros pensamientos en líneas de código.
La clave del éxito en cualquier hackathon es la preparación y un plan bien redactado. Por tanto, lo primero que hicimos fue decidir en qué módulos estaría compuesta la arquitectura de nuestro sistema y qué tecnologías utilizaríamos.
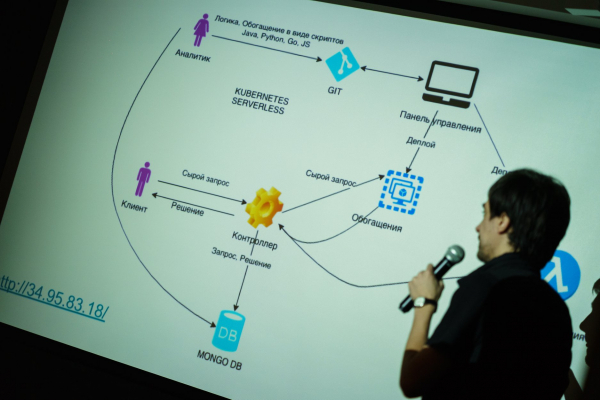
La arquitectura de nuestro proyecto fue la siguiente:
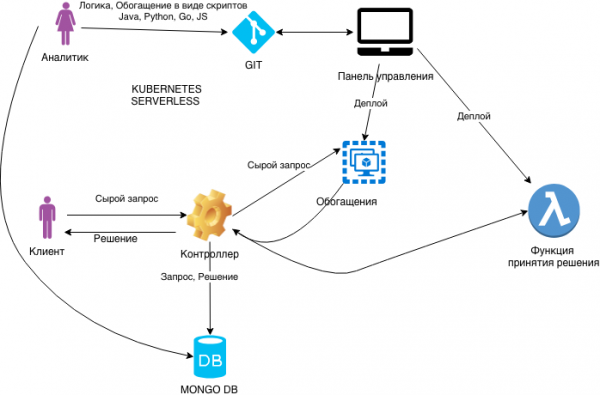
Este diagrama muestra dos puntos de entrada, el analista (el usuario principal de nuestro sistema) y el cliente.
El proceso de trabajo está estructurado así. El analista desarrolla una función de regla y una función de enriquecimiento de datos para su modelo, almacena su código en un repositorio Git e implementa su modelo en la nube a través de la aplicación de administrador. Consideremos cómo se llamará la función implementada y tomaremos decisiones sobre las solicitudes entrantes de los clientes:
- El cliente rellena un formulario en el sitio web y envía su solicitud al responsable del tratamiento. Una solicitud sobre la cual es necesario tomar una decisión llega a la entrada del sistema y se registra en la base de datos en su forma original.
- A continuación, la solicitud sin procesar se envía para su enriquecimiento, si es necesario. Puede complementar la solicitud inicial con datos tanto de servicios externos como del almacenamiento. La consulta enriquecida resultante también se almacena en la base de datos.
- Se inicia la función de analista, que toma una consulta enriquecida como entrada y produce una solución, que también se escribe en el almacenamiento.
Decidimos utilizar MongoDB como almacenamiento en nuestro sistema debido al almacenamiento de datos orientado a documentos en forma de documentos JSON, ya que los servicios de enriquecimiento, incluida la solicitud original, agregaron todos los datos a través de controladores REST.
Entonces teníamos XNUMX horas para implementar la plataforma. Distribuimos los roles con bastante éxito, cada miembro del equipo tenía su propia área de responsabilidad en nuestro proyecto:
- Paneles de administración frontales para el trabajo del analista, a través de los cuales podía descargar reglas del sistema de control de versiones de scripts escritos, seleccionar opciones para enriquecer los datos de entrada y editar scripts de reglas en línea.
- Administrador de backend, incluida API REST para el front e integración con VCS.
- Configuración de infraestructura en Google Cloud y desarrollo de un servicio para enriquecer los datos de origen.
- Un módulo para integrar la aplicación de administración con el marco Serverless para la posterior implementación de reglas.
- Scripts de reglas para probar el rendimiento de todo el sistema y agregación de análisis sobre aplicaciones entrantes (decisiones tomadas) para la demostración final.
Vamos a empezar desde el principio.
Nuestra interfaz se escribió en Angular 7 utilizando el kit de interfaz de usuario bancario. La versión final del panel de administración tenía este aspecto:
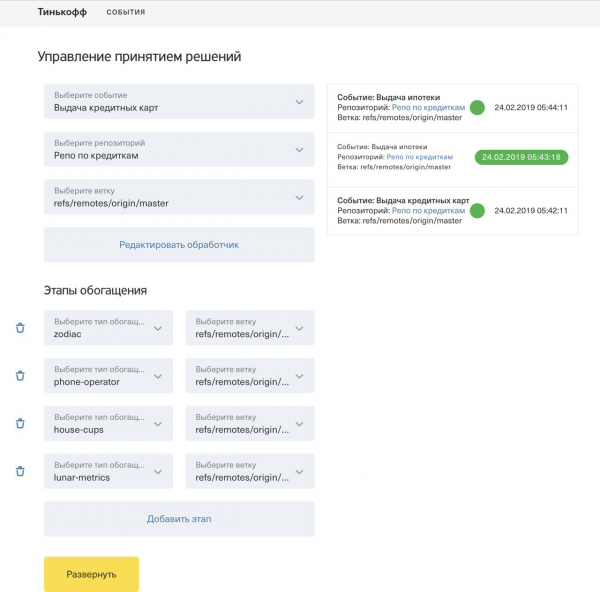
Como había poco tiempo, intentamos implementar solo la funcionalidad clave. Para implementar una función en el clúster de Kubernetes, era necesario seleccionar un evento (un servicio para el cual es necesario implementar una regla en la nube) y el código de la función que implementa la lógica de toma de decisiones. Para cada implementación de una regla para el servicio seleccionado, escribimos un registro de este evento. En el panel de administración puedes ver registros de todos los eventos.
Todo el código de función se almacenó en un repositorio Git remoto, que también debía configurarse en el panel de administración. Para versionar el código, todas las funciones se almacenaron en diferentes ramas del repositorio. El panel de administración también brinda la posibilidad de realizar ajustes en los scripts escritos, de modo que antes de implementar una función en producción, no solo pueda verificar el código escrito, sino también realizar los cambios necesarios.
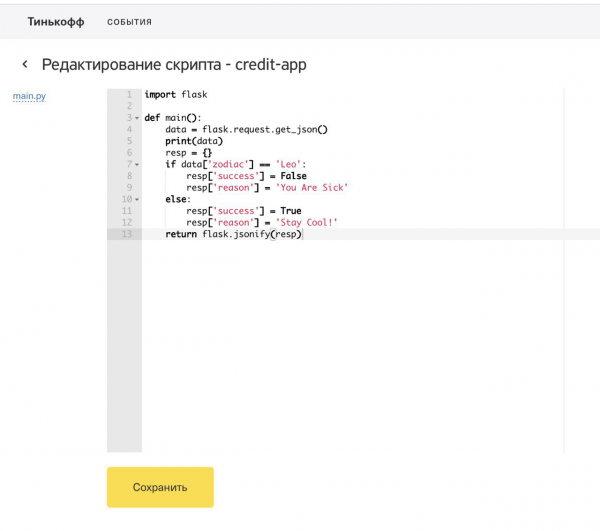
Además de las funciones de reglas, también implementamos la capacidad de enriquecer gradualmente los datos de origen mediante funciones de enriquecimiento, cuyo código también eran scripts en los que era posible ir al almacén de datos, llamar a servicios de terceros y realizar cálculos preliminares. . Para demostrar nuestra solución, calculamos el signo zodiacal del cliente que dejó la solicitud y determinamos su operador de telefonía móvil utilizando un servicio REST de terceros.
El backend de la plataforma fue escrito en Java e implementado como una aplicación Spring Boot. Inicialmente planeamos usar Postgres para almacenar datos administrativos, pero, como parte del hackathon, decidimos limitarnos a un simple H2 para ahorrar tiempo. En el backend, se implementó la integración con Bitbucket para versionar las funciones de enriquecimiento de consultas y los scripts de reglas. Para la integración con repositorios Git remotos, utilizamos , que es una especie de contenedor de comandos CLI, que le permite ejecutar cualquier instrucción de git utilizando una cómoda interfaz de software. Entonces teníamos dos repositorios separados para funciones y reglas de enriquecimiento, y todos los scripts estaban divididos en directorios. A través de la interfaz de usuario fue posible seleccionar la última confirmación de un script de una rama arbitraria del repositorio. Al realizar cambios en el código a través del panel de administración, se crearon confirmaciones del código modificado en repositorios remotos.
Para implementar nuestra idea, necesitábamos una infraestructura adecuada. Decidimos implementar nuestro clúster de Kubernetes en la nube. Nuestra elección fue Google Cloud Platform. El marco sin servidor Fission se instaló en un clúster de Kubernetes, que implementamos en Gcloud. Inicialmente, el servicio de enriquecimiento de datos de origen se implementó como una aplicación Java separada empaquetada en un Pod dentro del clúster k8s. Pero después de una demostración preliminar de nuestro proyecto en medio del hackathon, nos recomendaron flexibilizar el servicio de enriquecimiento para brindar la oportunidad de elegir cómo enriquecer los datos sin procesar de las aplicaciones entrantes. Y no tuvimos más remedio que hacer que el servicio de enriquecimiento también fuera Serverless.
Para trabajar con Fission, utilizamos la CLI de Fission, que debe instalarse encima de la CLI de Kubernetes. Implementar funciones en un clúster k8s es bastante simple; solo necesita asignar una ruta interna e ingresar a la función para permitir el tráfico entrante si se necesita acceso fuera del clúster. La implementación de una función normalmente no lleva más de 10 segundos.
Presentación final del proyecto y resumen.
Para demostrar cómo funciona nuestro sistema, hemos colocado un formulario simple en un servidor remoto donde puede enviar una solicitud para uno de los productos del banco. Para solicitarlo, debías ingresar tus iniciales, fecha de nacimiento y número de teléfono.
Los datos del formulario del cliente fueron al controlador, que simultáneamente envió solicitudes para todas las reglas disponibles, habiendo previamente enriquecido los datos de acuerdo con las condiciones especificadas y los guardó en un almacenamiento común. En total, implementamos tres funciones que toman decisiones sobre las aplicaciones entrantes y 4 servicios de enriquecimiento de datos. Después de enviar la solicitud, el cliente recibió nuestra decisión:
Además del rechazo o la aprobación, el cliente también recibió una lista de otros productos, solicitudes que enviamos en paralelo. Así demostramos la posibilidad de venta cruzada en nuestra plataforma.
Había un total de 3 productos bancarios ficticios disponibles:
- Crédito.
- Juguete
- Hipoteca.
Durante la demostración, implementamos funciones preparadas y scripts de enriquecimiento para cada servicio.
Cada regla requería su propio conjunto de datos de entrada. Entonces, para aprobar una hipoteca, calculamos el signo zodiacal del cliente y lo relacionamos con la lógica del calendario lunar. Para aprobar un juguete, verificamos que el cliente haya alcanzado la mayoría de edad, y para emitir un préstamo, enviamos una solicitud a un servicio abierto externo para determinar el operador celular y se tomó una decisión al respecto.
Intentamos hacer nuestra demostración interesante e interactiva, todos los presentes pudieron acceder a nuestro formulario y verificar la disponibilidad de nuestros servicios ficticios. Y al final de la presentación, mostramos análisis de las solicitudes recibidas, que mostraron cuántas personas utilizaron nuestro servicio, la cantidad de aprobaciones y rechazos.
Para recopilar análisis en línea, implementamos adicionalmente una herramienta de BI de código abierto. y lo atornillé a nuestra unidad de almacenamiento. Metabase permite construir pantallas con análisis sobre los datos que nos interesan, solo necesitamos registrar una conexión a la base de datos, seleccionar tablas (en nuestro caso, colecciones de datos, ya que usamos MongoDB) y especificar los campos que nos interesan. .
Como resultado, obtuvimos un buen prototipo de plataforma para la toma de decisiones y, durante la demostración, cada oyente pudo comprobar personalmente su funcionamiento. Una solución interesante, un prototipo terminado y una demostración exitosa nos permitieron ganar, a pesar de la fuerte competencia de otros equipos. Estoy seguro de que también se puede escribir un artículo interesante sobre el proyecto de cada equipo.
Fuente: habr.com
