

در این مقاله، من در مورد چگونگی تبدیل پروژه ای که روی آن کار می کنم از یک مونولیت بزرگ به مجموعه ای از میکروسرویس ها صحبت خواهم کرد.
این پروژه تاریخچه خود را خیلی وقت پیش، در آغاز سال 2000 آغاز کرد. اولین نسخه ها در ویژوال بیسیک 6 نوشته شدند. با گذشت زمان، مشخص شد که پشتیبانی از توسعه در این زبان در آینده دشوار خواهد بود، زیرا IDE و زبان خود ضعیف توسعه یافته است. در پایان دهه 2000، تصمیم گرفته شد که به سی شارپ امیدوارکنندهتر روی بیاوریم. نسخه جدید به موازات اصلاح نسخه قبلی نوشته شد، به تدریج کدهای بیشتری در دات نت نوشته شد. Backend در سی شارپ در ابتدا بر روی معماری سرویس متمرکز بود، اما در طول توسعه، از کتابخانه های مشترک با منطق استفاده شد و خدمات در یک فرآیند واحد راه اندازی شدند. نتیجه برنامه ای بود که ما آن را "یکپارچه خدمات" نامیدیم.
یکی از معدود مزایای این ترکیب، امکان تماس سرویس ها از طریق یک API خارجی بود. پیش نیازهای روشنی برای انتقال به یک سرویس صحیح تر و در آینده معماری میکروسرویس وجود داشت.
ما کار خود را روی تجزیه حدود سال 2015 شروع کردیم. ما هنوز به یک وضعیت ایده آل نرسیده ایم - هنوز بخش هایی از یک پروژه بزرگ وجود دارد که به سختی می توان آنها را یکپارچه نامید، اما آنها نیز شبیه به میکروسرویس ها نیستند. با این وجود، پیشرفت قابل توجهی است.
من در مورد آن در مقاله صحبت خواهم کرد.
مقدار
معماری و مشکلات راه حل موجود
در ابتدا، معماری به این صورت بود: UI یک برنامه جداگانه است، بخش یکپارچه در ویژوال بیسیک 6 نوشته شده است، برنامه دات نت مجموعه ای از خدمات مرتبط است که با یک پایگاه داده نسبتاً بزرگ کار می کند.
معایب راه حل قبلی
تنها نقطه شکست
ما یک نقطه شکست داشتیم: برنامه دات نت در یک فرآیند واحد اجرا شد. اگر هر یک از ماژول ها خراب می شد، کل برنامه از کار می افتاد و باید راه اندازی مجدد می شد. از آنجایی که ما تعداد زیادی از فرآیندها را برای کاربران مختلف خودکار می کنیم، به دلیل نقص در یکی از آنها، همه نمی توانند برای مدتی کار کنند. و در صورت بروز خطای نرم افزاری، پشتیبان گیری نیز کمکی نکرد.
صف بهبود
این اشکال بیشتر سازمانی است. برنامه ما مشتریان زیادی دارد و همه آنها می خواهند در اسرع وقت آن را بهبود بخشند. قبلاً انجام این کار به صورت موازی غیرممکن بود و همه مشتریان در صف ایستاده بودند. این روند برای کسب و کارها منفی بود زیرا آنها باید ثابت می کردند که وظیفه آنها ارزشمند است. و تیم توسعه زمانی را صرف سازماندهی این صف کرد. این کار زمان و تلاش زیادی را صرف کرد و محصول در نهایت نتوانست آنطور که می خواستند تغییر کند.
استفاده نابهینه از منابع
هنگام میزبانی خدمات در یک فرآیند، ما همیشه پیکربندی را از سروری به سرور دیگر به طور کامل کپی میکنیم. ما میخواستیم پربارترین سرویسها را جداگانه قرار دهیم تا منابع را هدر ندهیم و کنترل انعطافپذیرتری بر طرح استقرار خود بدست آوریم.
اجرای فناوری های مدرن دشوار است
مشکلی که برای همه توسعه دهندگان آشنا است: تمایل به معرفی فناوری های مدرن در پروژه وجود دارد، اما فرصتی وجود ندارد. با یک راه حل یکپارچه بزرگ، هر به روز رسانی کتابخانه فعلی، نه به ذکر انتقال به یک جدید، به یک کار نسبتاً غیر ضروری تبدیل می شود. مدت زمان زیادی طول می کشد تا به رهبر تیم ثابت شود که این کار پاداش های بیشتری نسبت به اعصاب تلف شده به همراه خواهد داشت.
مشکل در صدور تغییرات
این جدی ترین مشکل بود - ما هر دو ماه یک بار نسخه هایی را منتشر می کردیم.
با وجود آزمایش و تلاش توسعه دهندگان، هر نسخه به یک فاجعه واقعی برای بانک تبدیل شد. کسب و کار متوجه شد که در ابتدای هفته برخی از عملکردهای آن کار نمی کنند. و توسعه دهندگان فهمیدند که یک هفته حوادث جدی در انتظار آنها است.
همه میل به تغییر شرایط داشتند.
انتظارات از میکروسرویس ها
صدور قطعات در صورت آماده شدن تحویل اجزا در زمان آماده شدن با تجزیه محلول و جداسازی فرآیندهای مختلف.
تیم های محصول کوچک این مهم است زیرا مدیریت یک تیم بزرگ که روی یکپارچه قدیمی کار می کرد دشوار بود. چنین تیمی مجبور بود طبق یک روند سخت کار کند، اما آنها خلاقیت و استقلال بیشتری می خواستند. فقط تیم های کوچک می توانستند این کار را بپردازند.
جداسازی خدمات در فرآیندهای جداگانه. در حالت ایدهآل، من میخواهم آن را در کانتینرها ایزوله کنم، اما تعداد زیادی از سرویسهای نوشته شده در چارچوب .NET فقط تحت آن اجرا میشوند. Windowsسرویسهای مبتنی بر .NET Core اکنون در حال ظهور هستند، اما هنوز تعداد کمی از آنها وجود دارد.
انعطاف پذیری استقرار ما میخواهیم خدمات را آنطور که نیاز داریم ترکیب کنیم، نه آنطور که کد آن را مجبور میکند.
استفاده از فناوری های جدید. این برای هر برنامه نویسی جالب است.
مشکلات انتقال
البته، اگر شکستن یکپارچه به میکروسرویس ها آسان بود، نیازی به صحبت در مورد آن در کنفرانس ها و نوشتن مقاله نبود. مشکلات زیادی در این روند وجود دارد؛ من مهمترین آنها را که مانع ما شد را شرح می دهم.
اولین مشکل معمولی برای اکثر یکپارچه ها: انسجام منطق تجاری. وقتی یک monolith می نویسیم، می خواهیم از کلاس های خود دوباره استفاده کنیم تا کدهای غیر ضروری ننویسیم. و هنگام انتقال به میکروسرویس ها، این یک مشکل می شود: همه کدها کاملاً به هم متصل شده اند و جدا کردن سرویس ها دشوار است.
در زمان شروع کار، این مخزن دارای بیش از 500 پروژه و بیش از 700 هزار خط کد بود. این یک تصمیم کاملا بزرگ است و مشکل دوم. گرفتن آن و تقسیم آن به میکروسرویس ها امکان پذیر نبود.
مشکل سوم - نبود زیرساخت های لازم در واقع ما به صورت دستی کد منبع را روی سرورها کپی می کردیم.
چگونه از یکپارچه به میکروسرویس ها حرکت کنیم
ارائه ریز خدمات
اولاً، ما بلافاصله برای خود تعیین کردیم که جداسازی میکروسرویس ها یک فرآیند تکراری است. همیشه از ما خواسته شده بود که مشکلات تجاری را به صورت موازی توسعه دهیم. اینکه چگونه این را از نظر فنی پیاده سازی کنیم، مشکل ماست. بنابراین، ما برای یک فرآیند تکراری آماده شدیم. اگر یک برنامه بزرگ دارید و در ابتدا آماده بازنویسی نیست، به هیچ وجه کار نمی کند.
از چه روش هایی برای جداسازی میکروسرویس ها استفاده می کنیم؟
اولین راه - ماژول های موجود را به عنوان سرویس جابجا کنید. در این راستا، ما خوش شانس بودیم: قبلاً خدمات ثبت شده ای وجود داشت که با استفاده از پروتکل WCF کار می کردند. آنها به مجامع جداگانه جدا شدند. ما آنها را به طور جداگانه پورت کردیم و به هر بیلد یک لانچر کوچک اضافه کردیم. این با استفاده از کتابخانه فوق العاده Topshelf نوشته شده است که به شما امکان می دهد برنامه را هم به عنوان سرویس و هم به عنوان کنسول اجرا کنید. این برای اشکال زدایی راحت است زیرا هیچ پروژه اضافی در راه حل مورد نیاز نیست.
سرویس ها بر اساس منطق تجاری به هم متصل شدند، زیرا از مجموعه های مشترک استفاده می کردند و با یک پایگاه داده مشترک کار می کردند. به سختی می توان آنها را میکروسرویس در شکل خالص خود نامید. با این حال، ما میتوانیم این خدمات را به صورت جداگانه و در فرآیندهای مختلف ارائه دهیم. این به تنهایی امکان کاهش تأثیر آنها بر یکدیگر را فراهم کرد و مشکل را با توسعه موازی و یک نقطه شکست کاهش داد.
اسمبلی با هاست فقط یک خط کد در کلاس Program است. ما کار با Topshelf را در یک کلاس کمکی مخفی کردیم.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
راه دوم برای تخصیص ریزسرویس ها این است: آنها را برای حل مشکلات جدید ایجاد کنید. اگر در همان زمان یکپارچه رشد نکند، این در حال حاضر عالی است، به این معنی که ما در جهت درست حرکت می کنیم. برای حل مشکلات جدید سعی کردیم سرویس های جداگانه ایجاد کنیم. اگر چنین فرصتی وجود داشت، ما خدمات "متعارف" بیشتری ایجاد کردیم که به طور کامل مدل داده خود را مدیریت می کند، یک پایگاه داده جداگانه.
ما، مانند بسیاری از افراد، با خدمات احراز هویت و مجوز شروع کردیم. آنها برای این کار عالی هستند. آنها مستقل هستند، به عنوان یک قاعده، آنها یک مدل داده جداگانه دارند. آنها خودشان با یکپارچه تعامل ندارند، فقط برای حل برخی مشکلات به آنها روی می آورد. با استفاده از این سرویسها، میتوانید انتقال به معماری جدید را آغاز کنید، زیرساختها را روی آنها اشکال زدایی کنید، برخی از رویکردهای مربوط به کتابخانههای شبکه و غیره را امتحان کنید. ما هیچ تیمی در سازمان خود نداریم که نتواند یک سرویس احراز هویت ایجاد کند.
راه سوم برای تخصیص ریز سرویس هاموردی که ما استفاده می کنیم کمی مختص ماست. این حذف منطق تجاری از لایه UI است. برنامه اصلی رابط کاربری ما دسکتاپ است؛ این برنامه، مانند backend، با C# نوشته شده است. توسعهدهندگان بهطور دورهای اشتباه میکردند و بخشهایی از منطق را به رابط کاربری منتقل میکردند که باید در backend وجود داشت و دوباره مورد استفاده قرار میگرفت.
اگر به یک مثال واقعی از کد قسمت UI نگاه کنید، می بینید که بیشتر این راه حل حاوی منطق تجاری واقعی است که در سایر فرآیندها مفید است، نه فقط برای ساخت فرم UI.
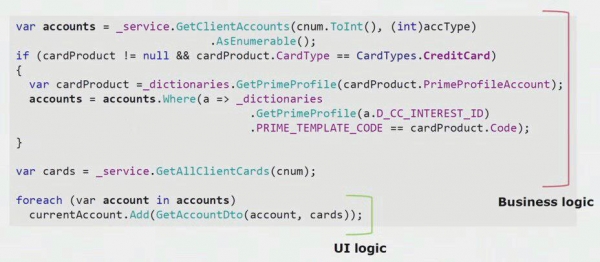
منطق UI واقعی فقط در دو خط آخر وجود دارد. ما آن را به سرور منتقل کردیم تا بتوان از آن دوباره استفاده کرد و در نتیجه رابط کاربری را کاهش داد و به معماری صحیح دست یافت.
چهارمین و مهمترین راه برای جداسازی میکروسرویس ها، که امکان کاهش یکپارچگی را فراهم می کند، حذف خدمات موجود با پردازش است. وقتی ماژولهای موجود را همانطور که هست خارج میکنیم، نتیجه همیشه مورد پسند توسعهدهندگان نیست و ممکن است فرآیند کسبوکار از زمان ایجاد عملکرد منسوخ شده باشد. با refactoring، میتوانیم از یک فرآیند کسبوکار جدید پشتیبانی کنیم، زیرا الزامات تجاری دائماً در حال تغییر هستند. ما می توانیم کد منبع را بهبود بخشیم، نقص های شناخته شده را حذف کنیم و مدل داده بهتری ایجاد کنیم. مزایای زیادی به همراه دارد.
جداسازی خدمات از پردازش به طور جدایی ناپذیری با مفهوم بافت محدود مرتبط است. این مفهومی از Domain Driven Design است. این به معنای بخشی از مدل دامنه است که در آن تمام اصطلاحات یک زبان به طور منحصر به فرد تعریف شده است. بیایید به عنوان مثال به زمینه بیمه و قبوض نگاه کنیم. ما یک برنامه یکپارچه داریم و باید با حساب در بیمه کار کنیم. ما انتظار داریم که توسعهدهنده یک کلاس حساب موجود را در مجموعهای دیگر پیدا کند، آن را از کلاس بیمه ارجاع دهد، و ما کد کاری خواهیم داشت. اصل DRY رعایت می شود، کار با استفاده از کد موجود سریعتر انجام می شود.
در نتیجه معلوم می شود که زمینه های حساب و بیمه به هم مرتبط است. با ظهور الزامات جدید، این جفت با توسعه تداخل خواهد داشت و پیچیدگی منطق تجاری از قبل پیچیده را افزایش می دهد. برای حل این مشکل، باید مرزهای بین زمینه ها را در کد پیدا کنید و تخلفات آنها را حذف کنید. به عنوان مثال در زمینه بیمه این امکان وجود دارد که شماره حساب 20 رقمی بانک مرکزی و تاریخ افتتاح حساب کافی باشد.
برای جدا کردن این زمینههای محدود از یکدیگر و شروع فرآیند جداسازی میکروسرویسها از یک راهحل یکپارچه، از رویکردی مانند ایجاد APIهای خارجی در برنامه استفاده کردیم. اگر میدانستیم که برخی از ماژولها باید به یک میکروسرویس تبدیل شود، به نحوی که در فرآیند اصلاح شود، بلافاصله از طریق تماسهای خارجی با منطقی که به زمینه محدود دیگری تعلق دارد تماس میگرفتیم. به عنوان مثال، از طریق REST یا WCF.
ما قاطعانه تصمیم گرفتیم که از کدهایی که به تراکنش های توزیع شده نیاز دارند اجتناب نکنیم. در مورد ما، پیروی از این قانون بسیار آسان است. ما هنوز با موقعیتهایی مواجه نشدهایم که واقعاً به تراکنشهای توزیع شده دقیق نیاز باشد - سازگاری نهایی بین ماژولها کاملاً کافی است.
بیایید به یک مثال خاص نگاه کنیم. ما مفهوم ارکستراتور را داریم - خط لوله ای که موجودیت "برنامه" را پردازش می کند. او به نوبه خود یک مشتری، یک حساب و یک کارت بانکی ایجاد می کند. اگر مشتری و حساب با موفقیت ایجاد شوند، اما ایجاد کارت ناموفق باشد، برنامه به وضعیت "موفقیت" منتقل نمی شود و در وضعیت "کارت ایجاد نشده" باقی می ماند. در آینده، فعالیت پسزمینه آن را انتخاب کرده و به پایان میرساند. مدتی است که سیستم دچار ناهماهنگی شده است، اما ما به طور کلی از این امر راضی هستیم.
اگر شرایطی پیش بیاید که لازم باشد به طور مداوم بخشی از داده ها ذخیره شود، به احتمال زیاد به دنبال یکپارچه سازی سرویس خواهیم بود تا آن را در یک فرآیند پردازش کنیم.
بیایید نمونه ای از تخصیص یک میکروسرویس را بررسی کنیم. چگونه می توانید آن را با خیال راحت به تولید برسانید؟ در این مثال، ما یک بخش جداگانه از سیستم داریم - یک ماژول خدمات حقوق و دستمزد، که یکی از بخش های کد آن را می خواهیم میکروسرویس بسازیم.
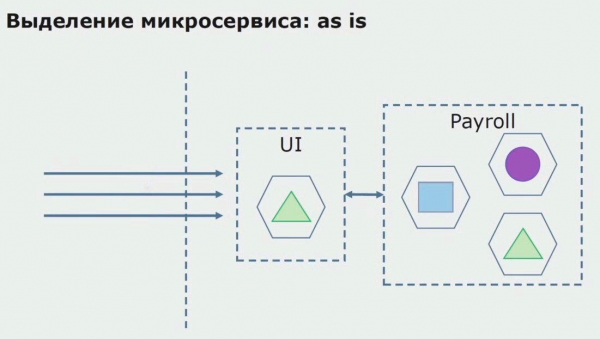
اول از همه با بازنویسی کد یک میکروسرویس ایجاد می کنیم. ما در حال بهبود برخی از جنبه هایی هستیم که از آنها راضی نبودیم. ما الزامات کسب و کار جدید مشتری را پیاده سازی می کنیم. ما یک API Gateway را به اتصال بین UI و backend اضافه می کنیم که انتقال تماس را فراهم می کند.
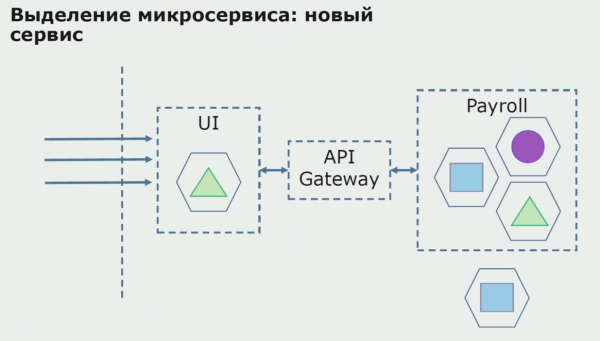
در مرحله بعد، ما این پیکربندی را به کار میگیریم، اما در حالت آزمایشی. اکثر کاربران ما هنوز با فرآیندهای تجاری قدیمی کار می کنند. برای کاربران جدید، ما در حال توسعه نسخه جدیدی از برنامه یکپارچه هستیم که دیگر حاوی این فرآیند نیست. در اصل، ما ترکیبی از یکپارچه و میکروسرویس داریم که به عنوان پایلوت کار می کند.
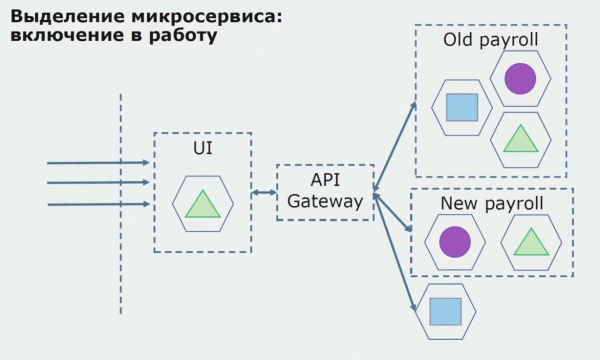
با یک پایلوت موفق، میدانیم که پیکربندی جدید واقعاً قابل اجرا است، میتوانیم یکپارچه قدیمی را از معادله حذف کنیم و پیکربندی جدید را به جای راهحل قدیمی رها کنیم.
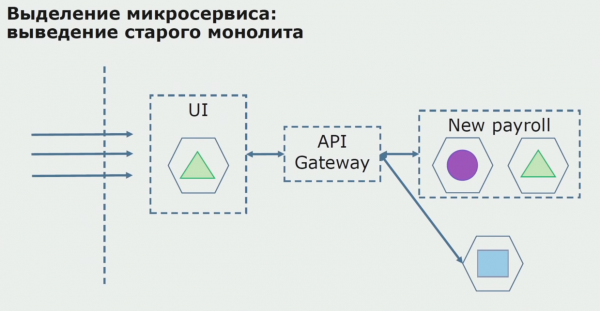
در مجموع، ما تقریباً از تمام روشهای موجود برای تقسیم کد منبع یک مونولیت استفاده میکنیم. همه آنها به ما این امکان را می دهند که اندازه بخش هایی از برنامه را کاهش دهیم و آنها را به کتابخانه های جدید ترجمه کنیم و کد منبع بهتری ایجاد کنیم.
کار با پایگاه داده
پایگاه داده را می توان بدتر از کد منبع تقسیم کرد، زیرا نه تنها شامل طرحواره فعلی، بلکه داده های تاریخی انباشته شده است.
پایگاه داده ما، مانند بسیاری دیگر، یک اشکال مهم دیگر داشت - اندازه عظیم آن. این پایگاه داده بر اساس منطق تجاری پیچیده یکپارچه طراحی شده است، و روابط بین جداول زمینه های مختلف محدود شده انباشته شده است.
در مورد ما، برای رفع تمام مشکلات (پایگاه داده بزرگ، اتصالات زیاد، گاهی اوقات مرزهای نامشخص بین جداول)، مشکلی پیش آمد که در بسیاری از پروژه های بزرگ رخ می دهد: استفاده از الگوی پایگاه داده مشترک. دادهها از جداول از طریق مشاهده، از طریق تکرار گرفته شده و به سیستمهای دیگری که در آنجا به این تکرار نیاز بود ارسال شد. در نتیجه، ما نمیتوانستیم جداول را به یک طرحواره جداگانه منتقل کنیم، زیرا آنها به طور فعال استفاده میشدند.
همین تقسیم بندی به زمینه های محدود در کد به ما در جداسازی کمک می کند. معمولاً ایده خوبی از نحوه تجزیه داده ها در سطح پایگاه داده به ما می دهد. ما درک می کنیم که کدام جداول به یک بافت محدود و کدام به زمینه دیگر تعلق دارند.
ما از دو روش جهانی پارتیشن بندی پایگاه داده استفاده کردیم: پارتیشن بندی جداول موجود و پارتیشن بندی با پردازش.
جدا کردن جداول موجود روش خوبی برای استفاده در صورتی است که ساختار داده خوب باشد، الزامات تجاری را برآورده کند و همه از آن راضی باشند. در این حالت می توانیم جداول موجود را در یک طرح مجزا جدا کنیم.
زمانی که مدل کسب و کار به شدت تغییر کرده است و جداول دیگر ما را راضی نمی کند، یک بخش با پردازش مورد نیاز است.
جدا کردن جداول موجود باید مشخص کنیم چه چیزی را از هم جدا خواهیم کرد. بدون این دانش، هیچ چیز کار نخواهد کرد، و در اینجا جداسازی زمینه های محدود در کد به ما کمک می کند. به عنوان یک قاعده، اگر بتوانید مرزهای زمینه ها را در کد منبع درک کنید، مشخص می شود که کدام جداول باید در لیست دپارتمان گنجانده شود.
بیایید تصور کنیم که راه حلی داریم که در آن دو ماژول یکپارچه با یک پایگاه داده تعامل دارند. ما باید مطمئن شویم که فقط یک ماژول با بخش جداول جدا شده تعامل داشته باشد و دیگری از طریق API شروع به تعامل با آن کند. برای شروع، کافی است که فقط ضبط از طریق API انجام شود. این شرط لازم برای صحبت در مورد استقلال میکروسرویس ها است. خواندن اتصالات می تواند تا زمانی که مشکل بزرگی وجود نداشته باشد باقی بماند.
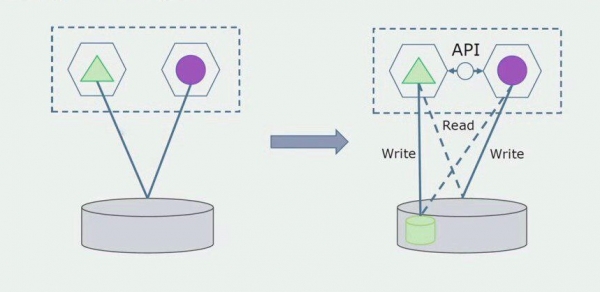
مرحله بعدی این است که میتوانیم بخشی از کد را که با جداول جدا شده کار میکند، با یا بدون پردازش، در یک میکروسرویس جداگانه جدا کرده و آن را در یک فرآیند جداگانه، یک ظرف، اجرا کنیم. این یک سرویس جداگانه با اتصال به پایگاه داده monolith و جداولی است که مستقیماً به آن مربوط نمی شود. یکپارچه هنوز برای خواندن با قسمت جداشدنی تعامل دارد.
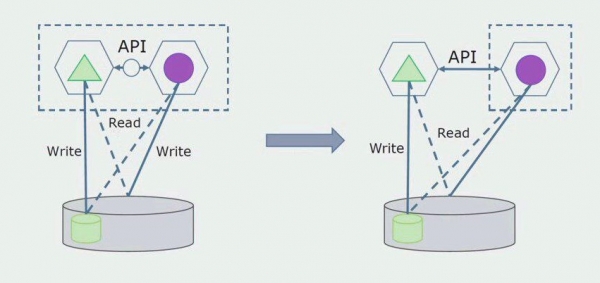
بعداً این اتصال را حذف خواهیم کرد، یعنی خواندن داده ها از یک برنامه یکپارچه از جداول جدا شده نیز به API منتقل می شود.
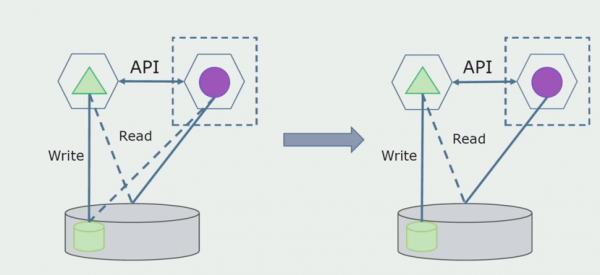
در مرحله بعد، از پایگاه داده عمومی جداولی را که فقط میکروسرویس جدید با آنها کار می کند، انتخاب می کنیم. میتوانیم جداول را به یک طرحواره جداگانه یا حتی به یک پایگاه داده فیزیکی جداگانه منتقل کنیم. هنوز یک ارتباط خواندن بین میکروسرویس و پایگاه داده مونولیت وجود دارد، اما جای نگرانی وجود ندارد، در این پیکربندی می تواند برای مدت طولانی زنده بماند.
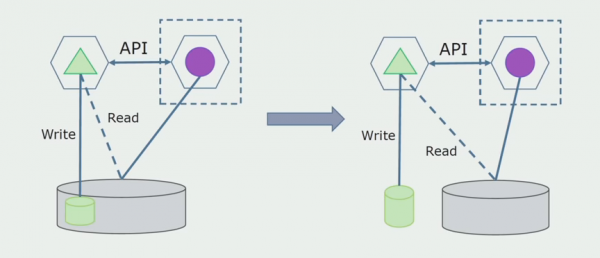
آخرین مرحله حذف کامل تمام اتصالات است. در این مورد، ممکن است نیاز به انتقال داده ها از پایگاه داده اصلی داشته باشیم. گاهی اوقات می خواهیم از برخی داده ها یا دایرکتوری های کپی شده از سیستم های خارجی در چندین پایگاه داده استفاده مجدد کنیم. این اتفاق به صورت دوره ای برای ما می افتد.
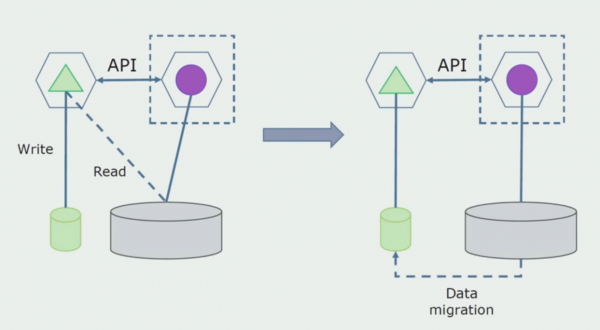
بخش پردازش این روش بسیار شبیه به روش اول است، فقط به ترتیب معکوس. ما بلافاصله یک پایگاه داده جدید و یک میکروسرویس جدید را اختصاص می دهیم که از طریق یک API با یکپارچه تعامل دارد. اما در عین حال، مجموعه ای از جداول پایگاه داده باقی می ماند که می خواهیم در آینده آن ها را حذف کنیم. ما دیگر به آن نیازی نداریم؛ ما آن را در مدل جدید جایگزین کردیم.
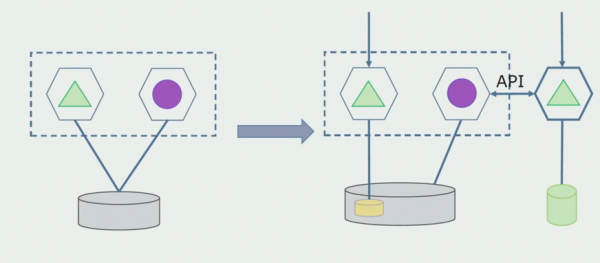
برای اینکه این طرح کار کند، احتمالاً به یک دوره انتقال نیاز خواهیم داشت.
سپس دو رویکرد ممکن وجود دارد.
اول: همه داده ها را در پایگاه داده های جدید و قدیمی کپی می کنیم. در این مورد، ما افزونگی داده ها را داریم و ممکن است مشکلات همگام سازی ایجاد شود. اما میتوانیم دو مشتری متفاوت بگیریم. یکی با نسخه جدید کار می کند، دیگری با نسخه قدیمی.
دوم: داده ها را بر اساس برخی معیارهای تجاری تقسیم می کنیم. به عنوان مثال ما 5 محصول در سیستم داشتیم که در پایگاه داده قدیمی ذخیره شده بودند. ما ششمین مورد را در وظایف تجاری جدید در یک پایگاه داده جدید قرار می دهیم. اما ما به یک API Gateway نیاز داریم که این داده ها را همگام سازی کند و به کلاینت نشان دهد که از کجا و چه چیزی باید دریافت کند.
هر دو روش کار می کنند، بسته به موقعیت انتخاب کنید.
پس از اینکه مطمئن شدیم همه چیز کار می کند، بخشی از یکپارچه که با ساختارهای پایگاه داده قدیمی کار می کند را می توان غیرفعال کرد.
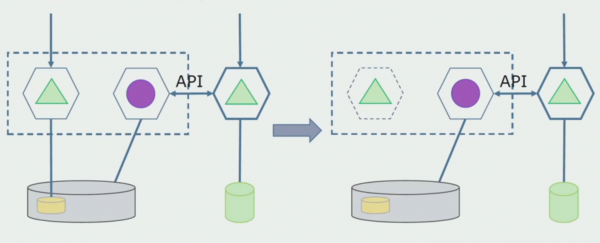
آخرین مرحله حذف ساختارهای داده قدیمی است.
به طور خلاصه، می توان گفت که ما با پایگاه داده مشکل داریم: کار با آن در مقایسه با کد منبع دشوار است، اشتراک گذاری آن دشوارتر است، اما می توان و باید انجام شود. ما راههایی پیدا کردهایم که به ما امکان میدهد این کار را کاملاً ایمن انجام دهیم، اما اشتباه کردن با دادهها آسانتر از کد منبع است.
کار با کد منبع
زمانی که ما شروع به تجزیه و تحلیل پروژه یکپارچه کردیم، نمودار کد منبع به این شکل بود.
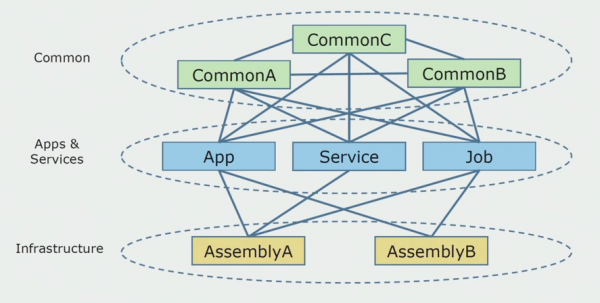
تقریباً می توان آن را به سه لایه تقسیم کرد. این لایه ای از ماژول ها، پلاگین ها، خدمات و فعالیت های فردی راه اندازی شده است. در واقع، اینها نقاط ورودی در یک راه حل یکپارچه بودند. همه آنها با یک لایه مشترک محکم بسته شدند. منطق تجاری بود که خدمات به اشتراک گذاشته می شد و ارتباطات زیادی داشت. هر سرویس و افزونه بسته به اندازه آنها و وجدان توسعه دهندگان از حداکثر 10 اسمبلی رایج یا بیشتر استفاده می کند.
ما خوش شانس بودیم که کتابخانههای زیرساختی داشتیم که میتوانستند جداگانه استفاده شوند.
گاهی اوقات موقعیتی پیش میآمد که برخی از اشیاء رایج در واقع به این لایه تعلق نداشتند، بلکه کتابخانههای زیرساختی بودند. این با تغییر نام حل شد.
بزرگترین نگرانی زمینه های محدود بود. این اتفاق افتاد که 3-4 زمینه در یک اسمبلی مشترک مخلوط شدند و از یکدیگر در همان عملکردهای تجاری استفاده کردند. لازم بود درک کنیم که این تقسیمبندی در کجا و در امتداد چه مرزهایی قابل تقسیم است، و با نگاشت این تقسیمبندی به مجموعههای کد منبع چه باید کرد.
ما چندین قانون برای فرآیند تقسیم کد تدوین کرده ایم.
اول: دیگر نمیخواستیم منطق تجاری را بین خدمات، فعالیتها و افزونهها به اشتراک بگذاریم. ما می خواستیم منطق کسب و کار را در میکروسرویس ها مستقل کنیم. از طرف دیگر، میکروسرویس ها به طور ایده آل به عنوان خدماتی در نظر گرفته می شوند که کاملاً مستقل وجود دارند. من معتقدم که این رویکرد تا حدودی بیهوده است و دستیابی به آن دشوار است، زیرا به عنوان مثال، خدمات در سی شارپ در هر صورت توسط یک کتابخانه استاندارد متصل خواهند شد. سیستم ما به زبان سی شارپ نوشته شده است؛ ما هنوز از فناوری های دیگری استفاده نکرده ایم. بنابراین تصمیم گرفتیم که بتوانیم از مجامع فنی مشترک استفاده کنیم. نکته اصلی این است که آنها حاوی هیچ قطعه ای از منطق تجاری نیستند. اگر روی ORM که استفاده میکنید یک بستهبندی راحت دارید، کپی کردن آن از سرویسی به سرویس دیگر بسیار گران است.
تیم ما از طرفداران طراحی دامنه محور است، بنابراین معماری پیاز برای ما مناسب بود. اساس خدمات ما لایه دسترسی به داده نیست، بلکه یک اسمبلی با منطق دامنه است که فقط شامل منطق تجاری است و هیچ ارتباطی با زیرساخت ندارد. در همان زمان، ما می توانیم به طور مستقل اسمبلی دامنه را برای حل مشکلات مربوط به فریمورک ها تغییر دهیم.
در این مرحله با اولین مشکل جدی خود مواجه شدیم. این سرویس باید به یک اسمبلی دامنه ارجاع میداد، ما میخواستیم منطق را مستقل کنیم، و اصل DRY ما را در اینجا بسیار با مشکل مواجه کرد. توسعهدهندگان میخواستند از کلاسهای مجموعههای همسایه برای جلوگیری از تکراری استفاده مجدد کنند، و در نتیجه دامنهها دوباره به هم مرتبط شدند. ما نتایج را تجزیه و تحلیل کردیم و به این نتیجه رسیدیم که شاید مشکل در ناحیه دستگاه ذخیره سازی کد منبع نیز باشد. ما یک مخزن بزرگ داشتیم که حاوی تمام کد منبع بود. راهحل کل پروژه برای مونتاژ کردن روی یک ماشین محلی بسیار دشوار بود. بنابراین راهحلهای کوچک جداگانهای برای بخشهایی از پروژه ایجاد شد و هیچکس اضافه کردن اسمبلی مشترک یا دامنه به آنها و استفاده مجدد از آنها را منع نکرد. تنها ابزاری که به ما اجازه انجام این کار را نمی داد، بررسی کد بود. اما گاهی اوقات نیز شکست می خورد.
سپس ما شروع به حرکت به سمت مدلی با مخازن جداگانه کردیم. منطق کسب و کار دیگر از سرویسی به سرویس دیگر جریان نمی یابد، دامنه ها واقعا مستقل شده اند. زمینه های محدود با وضوح بیشتری پشتیبانی می شوند. چگونه از کتابخانه های زیرساختی استفاده مجدد کنیم؟ ما آنها را در یک مخزن جداگانه جدا کردیم، سپس آنها را در بسته های Nuget قرار دادیم که آنها را در Artifactory قرار دادیم. با هر تغییری، مونتاژ و انتشار به صورت خودکار انجام می شود.
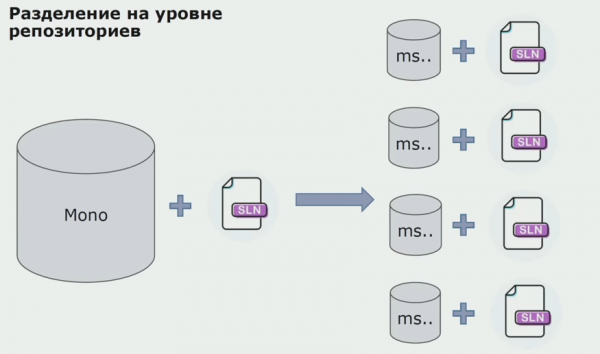
خدمات ما شروع به ارجاع به بستههای زیرساخت داخلی مانند بستههای خارجی کردند. ما کتابخانه های خارجی را از Nuget دانلود می کنیم. برای کار با Artifactory، جایی که این بسته ها را قرار دادیم، از دو مدیر بسته استفاده کردیم. در مخازن کوچک نیز از Nuget استفاده کردیم. در مخازن با چندین سرویس، از Paket استفاده کردیم که سازگاری نسخه بیشتری را بین ماژول ها فراهم می کند.
بنابراین، با کار بر روی کد منبع، کمی تغییر معماری و جداسازی مخازن، خدمات خود را مستقل تر می کنیم.
مشکلات زیرساختی
بسیاری از معایب حرکت به سمت میکروسرویس ها مربوط به زیرساخت ها است. شما به استقرار خودکار نیاز دارید، برای اجرای زیرساخت به کتابخانه های جدیدی نیاز دارید.
نصب دستی در محیط ها
در ابتدا راه حل برای محیط ها را به صورت دستی نصب کردیم. برای خودکارسازی این فرآیند، یک خط لوله CI/CD ایجاد کردیم. ما فرآیند تحویل مداوم را انتخاب کردیم زیرا استقرار مداوم از نظر فرآیندهای تجاری هنوز برای ما قابل قبول نیست. بنابراین، ارسال برای عملیات با استفاده از یک دکمه، و برای آزمایش - به طور خودکار انجام می شود.
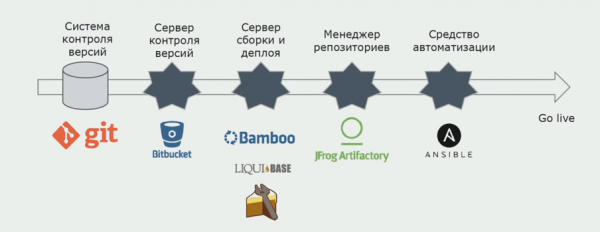
ما از Atlassian، Bitbucket برای ذخیره کد منبع و Bamboo برای ساختن استفاده می کنیم. ما دوست داریم اسکریپت های ساخت را در کیک بنویسیم زیرا همان سی شارپ است. بسته های آماده به Artifactory می آیند و Ansible به طور خودکار به سرورهای آزمایشی می رسد و پس از آن می توان بلافاصله آنها را آزمایش کرد.
قطع درختان جدا
در یک زمان، یکی از ایده های یکپارچه این بود که قطع درختان مشترک را فراهم کند. ما همچنین نیاز داشتیم که بفهمیم با لاگهای فردی که روی دیسکها هستند چه کار کنیم. گزارش های ما در فایل های متنی نوشته می شوند. ما تصمیم گرفتیم از یک پشته استاندارد ELK استفاده کنیم. ما مستقیماً از طریق ارائهدهندگان به ELK ننوشتیم، اما تصمیم گرفتیم که گزارشهای متن را اصلاح کنیم و شناسه ردیابی را در آنها به عنوان شناسه بنویسیم و نام سرویس را اضافه کنیم تا این گزارشها بعداً تجزیه شوند.
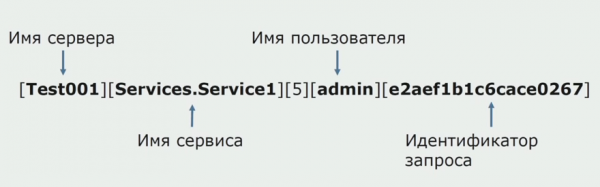
با Filebeat میتوانیم گزارشهای خود را از ... جمعآوری کنیم. سرورها، سپس آنها را تغییر شکل دهید، از Kibana برای ساخت کوئریها در رابط کاربری استفاده کنید و ببینید که چگونه فراخوانی بین سرویسها مسیریابی شده است. شناسههای ردیابی برای این کار بسیار مفید هستند.
تست و رفع اشکال خدمات مرتبط
در ابتدا، ما به طور کامل متوجه نشدیم که چگونه سرویس های در حال توسعه را اشکال زدایی کنیم. همه چیز با یکپارچه ساده بود؛ ما آن را روی یک ماشین محلی اجرا کردیم. در ابتدا سعی کردند همین کار را با میکروسرویسها انجام دهند، اما گاهی اوقات برای راهاندازی کامل یک میکروسرویس باید چندین سرویس دیگر را راهاندازی کرد، و این ناخوشایند است. متوجه شدیم که باید به مدلی برویم که در آن فقط سرویس یا سرویسهایی را که میخواهیم اشکالزدایی کنیم، در ماشین محلی باقی میگذاریم. سرویسهای باقیمانده از سرورهایی استفاده میشوند که با پیکربندی مطابقت دارند. پس از رفع اشکال، در حین تست، برای هر کار، تنها سرویس های تغییر یافته برای سرور تست صادر می شود. بنابراین، محلول به شکلی که در آینده در تولید ظاهر می شود، آزمایش می شود.
سرورهایی وجود دارند که فقط نسخه های تولیدی خدمات را اجرا می کنند. این سرورها در صورت بروز حوادث، برای بررسی تحویل قبل از استقرار و برای آموزش داخلی مورد نیاز هستند.
ما یک فرآیند تست خودکار را با استفاده از کتابخانه محبوب Specflow اضافه کردهایم. تست ها به طور خودکار با استفاده از NUnit بلافاصله پس از استقرار از Ansible اجرا می شوند. اگر پوشش کار کاملاً خودکار باشد، دیگر نیازی به تست دستی نیست. اگرچه گاهی اوقات آزمایش دستی اضافی هنوز مورد نیاز است. ما از برچسبها در Jira استفاده میکنیم تا مشخص کنیم که کدام تست برای یک مشکل خاص اجرا شود.
علاوه بر این، نیاز به آزمایش بار افزایش یافته است؛ قبلاً فقط در موارد نادر انجام می شد. ما از JMeter برای اجرای تست ها، InfluxDB برای ذخیره آن ها و Grafana برای ساخت نمودارهای فرآیند استفاده می کنیم.
چه چیزی به دست آورده ایم؟
اولا، ما از مفهوم "رهاسازی" خلاص شدیم. زمانی که این غول پیکر در یک محیط تولید مستقر شد و به طور موقت فرآیندهای کسب و کار را مختل کرد، نسخه های هیولایی دو ماهه از بین رفت. اکنون ما خدمات را به طور متوسط هر 1,5 روز یکبار مستقر می کنیم و آنها را گروه بندی می کنیم زیرا پس از تأیید عملیاتی می شوند.
هیچ خرابی کشنده ای در سیستم ما وجود ندارد. اگر یک میکروسرویس را با یک باگ منتشر کنیم، عملکرد مرتبط با آن خراب می شود و همه عملکردهای دیگر تحت تأثیر قرار نمی گیرند. این به میزان زیادی تجربه کاربر را بهبود می بخشد.
ما می توانیم الگوی استقرار را کنترل کنیم. در صورت لزوم میتوانید گروههایی از خدمات را جدا از بقیه راهحلها انتخاب کنید.
علاوه بر این، با صف زیادی از بهبودها، مشکل را به میزان قابل توجهی کاهش داده ایم. ما اکنون تیم های محصول جداگانه ای داریم که با برخی از خدمات به طور مستقل کار می کنند. فرآیند اسکرام از قبل در اینجا مناسب است. یک تیم خاص ممکن است صاحب محصول جداگانه ای داشته باشد که وظایفی را به آن محول می کند.
خلاصه
- میکروسرویس ها برای تجزیه سیستم های پیچیده مناسب هستند. در این فرآیند، ما شروع می کنیم به درک آنچه در سیستم ما وجود دارد، چه زمینه های محدودی وجود دارد، مرزهای آنها کجاست. این به شما امکان می دهد پیشرفت ها را به درستی بین ماژول ها توزیع کنید و از سردرگمی کد جلوگیری کنید.
- میکروسرویس ها مزایای سازمانی را ارائه می دهند. اغلب از آنها فقط به عنوان معماری صحبت می شود، اما هر معماری برای حل نیازهای تجاری مورد نیاز است و نه به تنهایی. بنابراین، می توان گفت که میکروسرویس ها برای حل مشکلات در تیم های کوچک مناسب هستند، با توجه به اینکه اسکرام در حال حاضر بسیار محبوب است.
- جداسازی یک فرآیند تکراری است. شما نمی توانید برنامه ای را انتخاب کنید و به سادگی آن را به میکروسرویس ها تقسیم کنید. محصول حاصل بعید است که کاربردی باشد. هنگام اختصاص ریز سرویسها، بازنویسی میراث موجود مفید است، یعنی آن را به کدی تبدیل کنیم که دوست داریم و از نظر عملکرد و سرعت، نیازهای تجاری را بهتر برآورده میکند.
یک هشدار کوچک: هزینه های انتقال به میکروسرویس ها بسیار قابل توجه است. زمان زیادی طول کشید تا مشکل زیرساختی به تنهایی حل شود. بنابراین اگر برنامه کوچکی دارید که نیاز به مقیاسبندی خاصی ندارد، مگر اینکه تعداد زیادی مشتری برای جلب توجه و زمان تیم شما رقابت کنند، ممکن است میکروسرویسها آن چیزی نباشند که امروز به آن نیاز دارید. این کاملا گران است. اگر فرآیند را با میکروسرویس ها شروع کنید، در ابتدا هزینه ها بیشتر از زمانی است که همان پروژه را با توسعه یکپارچه شروع کنید.
PS یک داستان احساسی تر (و انگار برای شما شخصا) - با توجه به .
در اینجا نسخه کامل گزارش آمده است.
منبع: www.habr.com
