

پیشنهاد میکنم متن گزارش نیکولای ساموخوالوف «رویکرد صنعتی برای تنظیم PostgreSQL: آزمایشهای روی پایگاههای داده» را بخوانید.
Shared_buffers = 25% - زیاد است یا کم؟ یا درست است؟ چگونه می دانید که این توصیه - نسبتاً قدیمی - در مورد خاص شما مناسب است؟
زمان آن رسیده است که به موضوع انتخاب پارامترهای postgresql.conf "مانند یک بزرگسال" نزدیک شویم. نه با کمک "تیونرهای خودکار" کور یا توصیه های قدیمی از مقالات و وبلاگ ها، بلکه بر اساس:
- آزمایشهای کاملاً تأیید شده بر روی پایگاههای داده، که به طور خودکار، در مقادیر زیاد و در شرایطی که تا حد امکان نزدیک به آزمایشهای «مبارزه» انجام میشود،
- درک عمیق از ویژگی های DBMS و OS.
با استفاده از نانسی CLI ()، به یک مثال خاص - shared_buffers بدنام - در موقعیتهای مختلف، در پروژههای مختلف نگاه میکنیم و سعی میکنیم بفهمیم که چگونه تنظیمات بهینه را برای زیرساخت، پایگاه داده و بار خود انتخاب کنیم.

ما در مورد آزمایشات با پایگاه داده صحبت خواهیم کرد. این داستانی است که کمی بیش از شش ماه طول می کشد.

کمی درباره من. تجربه با Postgres برای بیش از 14 سال. تعدادی از شرکت های شبکه های اجتماعی تاسیس کرده اند. Postgres در همه جا استفاده می شد و استفاده می شود.
همچنین گروه RuPostgres در Meetup، مقام دوم در جهان. کم کم داریم به 2 نفر نزدیک می شویم. RuPostgres.org.
و در رایانههای شخصی کنفرانسهای مختلف، از جمله Highload، من از همان ابتدا مسئول پایگاههای اطلاعاتی، به ویژه Postgres هستم.

و در چند سال گذشته، من تمرین مشاوره Postgres خود را در 11 منطقه زمانی از اینجا دوباره شروع کردم.

و وقتی چند سال پیش این کار را انجام دادم، احتمالاً از سال 2010، در کار دستی فعال با Postgres وقفه داشتم. من تعجب کردم که روال کاری یک DBA چقدر تغییر نکرده است، و هنوز چقدر کار دستی باید استفاده شود. و بلافاصله فکر کردم که اینجا مشکلی وجود دارد، من باید بیشتر از همه چیز را خودکار کنم.
و از آنجایی که همه چیز از راه دور بود، اکثر مشتریان در ابرها بودند. و بسیاری از موارد قبلاً خودکار شده اند، بدیهی است. بیشتر در این مورد بعدا. یعنی همه اینها به این ایده منجر شد که باید تعدادی ابزار وجود داشته باشد، به عنوان مثال، نوعی پلتفرم که تقریباً تمام اقدامات DBA را خودکار می کند تا بتوان تعداد زیادی پایگاه داده را مدیریت کرد.

این گزارش شامل موارد زیر نخواهد بود:
- "گلوله های نقره ای" و عباراتی مانند - 8 گیگابایت یا 25٪ shared_buffers تنظیم کنید و خوب خواهید بود. چیز زیادی در مورد shared_buffers وجود نخواهد داشت.
- هاردکور "درون".

و چه خواهد شد؟
- اصول بهینه سازی وجود خواهد داشت که ما آنها را اعمال و توسعه می دهیم. انواع ایدههایی که در این مسیر به وجود میآیند و ابزارهای مختلفی وجود خواهند داشت که بیشتر آنها را در منبع باز ایجاد میکنیم، یعنی اساس را در منبع باز ایجاد میکنیم. علاوه بر این، ما بلیط داریم، تمام ارتباطات عملا منبع باز است. شما می توانید ببینید که ما در حال حاضر چه کاری انجام می دهیم، در نسخه بعدی چه خواهد بود و غیره.
- همچنین تجربه ای در استفاده از این اصول، این ابزارها در تعدادی از شرکت ها وجود خواهد داشت: از استارتاپ های کوچک گرفته تا شرکت های بزرگ.

این همه چگونه در حال توسعه است؟

اولاً، وظیفه اصلی یک DBA، علاوه بر اطمینان از ایجاد نمونه ها، استقرار پشتیبان گیری و غیره، یافتن گلوگاه ها و بهینه سازی عملکرد است.
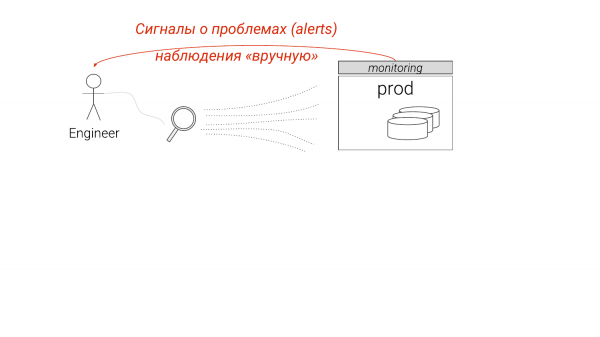
حالا اینجوری راه اندازی شده ما به نظارت نگاه می کنیم، چیزی می بینیم، اما برخی جزئیات را از دست می دهیم. ما شروع به حفاری با دقت بیشتری می کنیم، معمولاً با دستانمان، و می فهمیم که با آن چه کاری انجام دهیم.
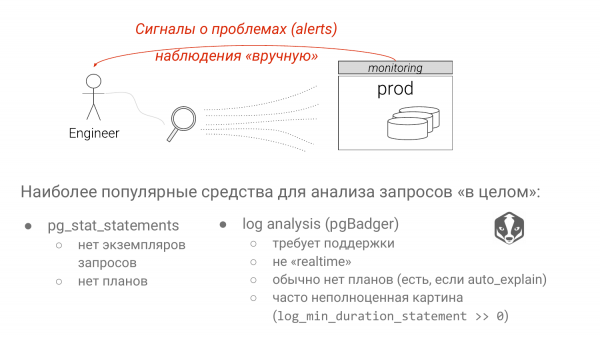
و دو رویکرد وجود دارد. Pg_stat_statements راه حل پیش فرض برای شناسایی پرس و جوهای کند است. و تجزیه و تحلیل سیاهههای مربوط به Postgres با استفاده از pgBadger.
هر رویکرد دارای اشکالات جدی است. در رویکرد اول، ما تمام پارامترها را حذف کرده ایم. و اگر گروه های جدول SELECT * FROM را ببینیم که ستون برابر با "?" یا "$" از Postgres 10. ما نمی دانیم که آیا این یک اسکن شاخص است یا یک اسکن متوالی. خیلی به پارامتر بستگی دارد. اگر مقداری را که به ندرت با آن مواجه می شوید جایگزین کنید، این یک اسکن شاخص خواهد بود. اگر مقداری را جایگزین کنید که 90٪ از جدول را در آنجا اشغال می کند، اسکن seq واضح خواهد بود، زیرا Postgres آمار را می داند. و این یک اشکال بزرگ برای pg_stat_statements است، اگرچه برخی کارها در حال انجام است.
بزرگترین نقطه ضعف تجزیه و تحلیل گزارش این است که شما نمی توانید "log_min_duration_statement = 0" را به عنوان یک قانون پرداخت کنید. و ما در این مورد نیز صحبت خواهیم کرد. بر این اساس، شما کل تصویر را نمی بینید. و برخی از پرس و جوها، که بسیار سریع هستند، ممکن است مقدار زیادی از منابع را مصرف کنند، اما شما آن را نخواهید دید زیرا زیر آستانه شما است.
چگونه DBA ها مشکلاتی را که پیدا می کنند حل می کنند؟
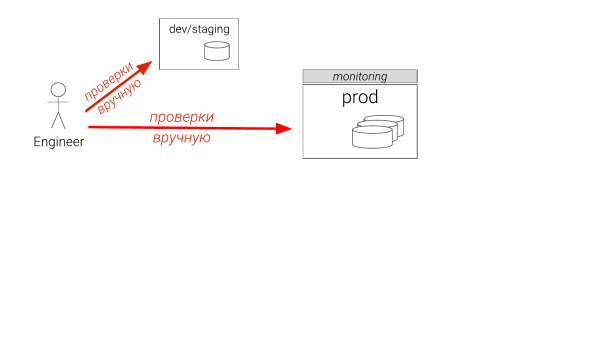
به عنوان مثال، ما یک مشکل پیدا کردیم. معمولا چه کاری انجام می شود؟ اگر توسعهدهنده هستید، در برخی از نمونهها کاری انجام میدهید که اندازه آن یکسان نیست. اگر شما یک DBA هستید، پس مرحله بندی دارید. و فقط یکی می تواند وجود داشته باشد. و شش ماه عقب بود. و شما فکر می کنید که به سمت تولید خواهید رفت. و حتی DBA های با تجربه و سپس تولید را بر روی یک ماکت بررسی می کنند. و این اتفاق می افتد که یک شاخص موقت ایجاد می کنند، مطمئن می شوند که کمک می کند، آن را رها می کنند و به توسعه دهندگان می دهند تا بتوانند آن را در فایل های مهاجرت قرار دهند. این همان مزخرفاتی است که اکنون در حال رخ دادن است. و این یک مشکل است.
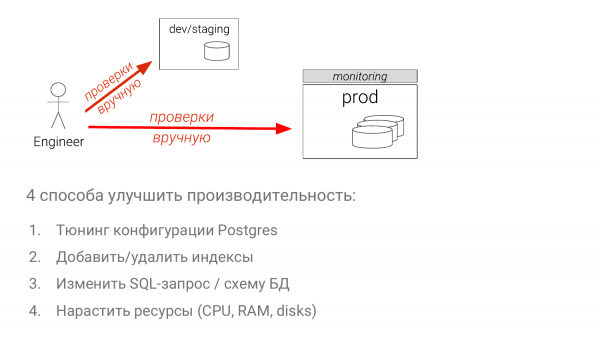
- تنظیمات را تنظیم کنید
- بهینه سازی مجموعه شاخص ها
- خود پرس و جوی SQL را تغییر دهید (این سخت ترین راه است).
- ظرفیت اضافه کنید (در بیشتر موارد ساده ترین راه).

با این چیزها خیلی اتفاق می افتد. تعداد زیادی دستگیره در Postgres وجود دارد. چیزهای زیادی برای دانستن وجود دارد. ایندکس های زیادی در Postgres وجود دارد که از سازمان دهندگان این کنفرانس نیز تشکر می کنم. و همه اینها باید شناخته شوند، و این همان چیزی است که باعث می شود افراد غیرDBA احساس کنند DBA ها در حال تمرین جادوی سیاه هستند. یعنی شما باید 10 سال مطالعه کنید تا به طور معمول همه اینها را بفهمید.
و من یک مبارز علیه این جادوی سیاه هستم. من می خواهم همه چیز را انجام دهم تا فناوری وجود داشته باشد و هیچ شهودی در همه اینها وجود نداشته باشد.
نمونه های زندگی واقعی

من این را حداقل در دو پروژه از جمله پروژه خودم مشاهده کردم. یک پست وبلاگ دیگر به ما می گوید که مقدار 1 برای default_statistict_target خوب است. خوب، بیایید آن را در تولید امتحان کنیم.

و اینجا هستیم، با استفاده از ابزار خود دو سال بعد، با کمک آزمایشهایی روی پایگاههای دادهای که امروز در مورد آن صحبت میکنیم، میتوانیم آنچه را که بوده و چه شده است مقایسه کنیم.
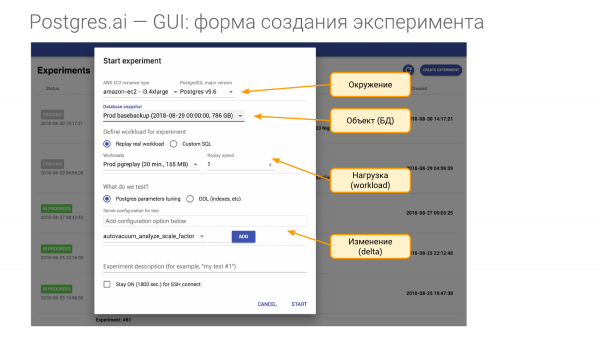
و برای این ما نیاز به ایجاد یک آزمایش داریم. از چهار قسمت تشکیل شده است.
- اولین مورد محیط زیست است. به یک قطعه سخت افزار نیاز داریم. و وقتی به فلان شرکت می آیم و قرارداد می بندم، می گویم همان سخت افزاری را که در تولید است به من بدهند. برای هر یک از استادان شما، من حداقل به یک قطعه سخت افزار مانند این نیاز دارم. یا این یک ماشین مجازی نمونه در آمازون یا گوگل است، یا من دقیقاً به همان سخت افزار نیاز دارم. یعنی می خواهم محیط را از نو بسازم. و در مفهوم محیط، نسخه اصلی Postgres را شامل میشویم.
- بخش دوم موضوع تحقیق ما است. این یک پایگاه داده است. می توان آن را به روش های مختلفی ایجاد کرد. من به شما نشان خواهم داد که چگونه.
- قسمت سوم بار است. این سخت ترین لحظه است.
- و بخش چهارم این است که چه چیزی را بررسی می کنیم، یعنی چه چیزی را با چه چیزی مقایسه خواهیم کرد. فرض کنید میتوانیم یک یا چند پارامتر را در پیکربندی تغییر دهیم، یا میتوانیم یک شاخص ایجاد کنیم و غیره.
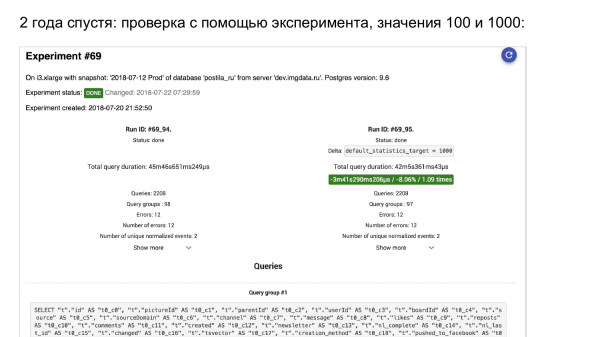
ما در حال راه اندازی یک آزمایش هستیم. اینجا pg_stat_statements است. در سمت چپ چیزی است که اتفاق افتاده است. در سمت راست - چه اتفاقی افتاد.
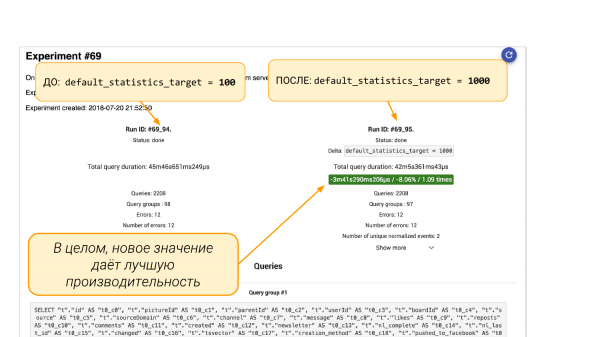
در سمت چپ default_statistics_target = 100، در سمت راست = 1 می بینیم که این به ما کمک کرد. به طور کلی، همه چیز 000٪ بهتر شد.
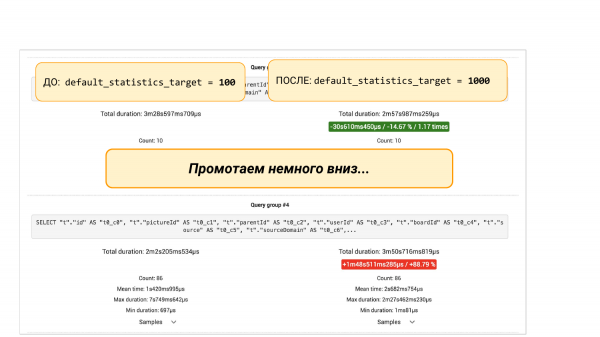
اما اگر به پایین اسکرول کنیم، گروههایی از درخواستها از pgBadger یا pg_stat_statements وجود خواهد داشت. دو گزینه وجود دارد. خواهیم دید که برخی از درخواست ها 88 درصد کاهش یافته است. و در اینجا رویکرد مهندسی مطرح می شود. میتوانیم داخل را بیشتر حفاری کنیم زیرا تعجب میکنیم که چرا غرق شد. باید بفهمید که با آمار چه اتفاقی افتاده است. چرا سطل های بیشتر در آمار منجر به نتایج بدتر می شود.
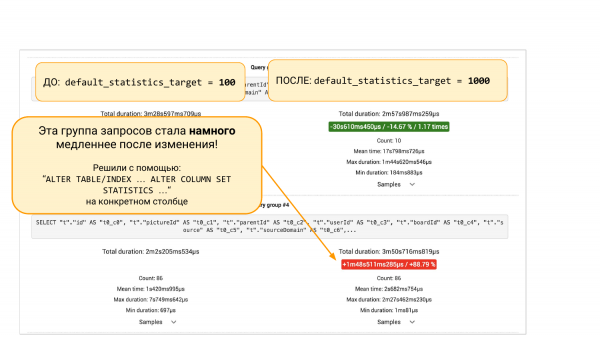
یا نمی توانیم حفاری کنیم، اما “ALTER TABLE ... ALTER COLUMN” را انجام دهیم و 100 سطل را به آمار این ستون برگردانیم. و سپس با آزمایش دیگری می توانیم مطمئن شویم که این پچ کمک کرده است. همه. این یک رویکرد مهندسی است که به ما کمک میکند تصویر بزرگ را ببینیم و بر اساس دادهها تصمیم بگیریم نه بر اساس شهود.


چند نمونه از مناطق دیگر. سال هاست که تست های CI در تست وجود دارد. و هیچ پروژه ای در ذهن درست خود بدون آزمایش های خودکار زندگی نمی کند.
در صنایع دیگر: در هوانوردی، در صنعت خودروسازی، وقتی آیرودینامیک را آزمایش می کنیم، فرصت انجام آزمایش نیز داریم. ما چیزی را از یک نقاشی مستقیماً به فضا پرتاب نمی کنیم، یا فوراً مقداری ماشین را به پیست نخواهیم برد. مثلاً یک تونل باد وجود دارد.
ما می توانیم از مشاهدات سایر صنایع نتیجه گیری کنیم.

اولا، ما یک محیط خاص داریم. به تولید نزدیک است، اما نزدیک نیست. ویژگی اصلی آن این است که باید ارزان، قابل تکرار و تا حد امکان خودکار باشد. و همچنین باید ابزار خاصی برای انجام تجزیه و تحلیل دقیق وجود داشته باشد.
به احتمال زیاد، زمانی که هواپیما را پرتاب می کنیم و پرواز می کنیم، نسبت به تونل باد فرصت کمتری برای مطالعه هر میلی متر از سطح بال داریم. ما ابزارهای تشخیصی بیشتری داریم. ما می توانیم وسایل سنگین بیشتری را حمل کنیم که نمی توانیم در هواپیما در هوا قرار دهیم. Postgres هم همینطور. ممکن است، در برخی موارد، ثبت کامل پرس و جو را در طول آزمایش ها فعال کنیم. و ما نمی خواهیم این کار را در تولید انجام دهیم. حتی ممکن است برنامه ریزی کنیم که این را با استفاده از auto_explain فعال کنیم.
و همانطور که گفتم، سطح بالای اتوماسیون به این معنی است که دکمه را فشار می دهیم و تکرار می کنیم. این طوری باید باشد که آزمایش زیاد باشد تا در جریان باشد.
نانسی CLI - پایه و اساس "آزمایشگاه پایگاه داده"

و بنابراین ما این کار را انجام دادیم. یعنی تقریباً یک سال پیش در ژوئن درباره این ایده ها صحبت کردم. و ما قبلاً به اصطلاح Nancy CLI را در منبع باز داریم. این پایه و اساس ساخت یک آزمایشگاه پایگاه داده است.
- در متن باز، در Gitlab است. می توانید آن را بگویید، می توانید آن را امتحان کنید. من یک لینک در اسلایدها قرار دادم. می توانید روی آن کلیک کنید و آنجا خواهد بود از همه لحاظ
البته هنوز چیزهای زیادی در دست توسعه است. ایده های زیادی در آنجا وجود دارد. اما این چیزی است که ما تقریبا هر روز از آن استفاده می کنیم. و وقتی ایده ای داریم - چرا وقتی 40،000،000 خط را حذف می کنیم، همه چیز به IO ختم می شود، آنگاه می توانیم آزمایشی انجام دهیم و جزئیات بیشتری را بررسی کنیم تا بفهمیم چه اتفاقی دارد می افتد و سپس سعی کنیم آن را در پرواز درست کنیم. یعنی ما داریم آزمایش می کنیم. مثلاً چیزی را تغییر می دهیم و می بینیم که در نهایت چه می شود. و ما این کار را در تولید انجام نمی دهیم. این اصل ایده است.
این کجا می تواند کار کند؟ این می تواند به صورت محلی کار کند، یعنی می توانید آن را در هر جایی انجام دهید، حتی می توانید آن را روی مک بوک اجرا کنید. ما به یک داکر نیاز داریم، بیا بریم. همین. شما می توانید آن را در برخی موارد بر روی یک قطعه سخت افزاری یا در یک ماشین مجازی، در هر مکانی اجرا کنید.
و همچنین این فرصت برای اجرا از راه دور در آمازون در EC2 Instance، در نقاط وجود دارد. و این یک فرصت بسیار عالی است. به عنوان مثال، دیروز ما بیش از 500 آزمایش را بر روی نمونه i3 انجام دادیم که از جوانترین آزمایش شروع شد و با i3-16-xlarge پایان یافت. و 500 آزمایش برای ما 64 دلار هزینه داشت. هر کدام 15 دقیقه طول کشید. یعنی با توجه به اینکه از اسپک ها در آنجا استفاده می شود، بسیار ارزان است - 70٪ تخفیف، صورتحساب آمازون در هر ثانیه. شما می توانید کارهای زیادی انجام دهید. شما می توانید تحقیق واقعی انجام دهید.
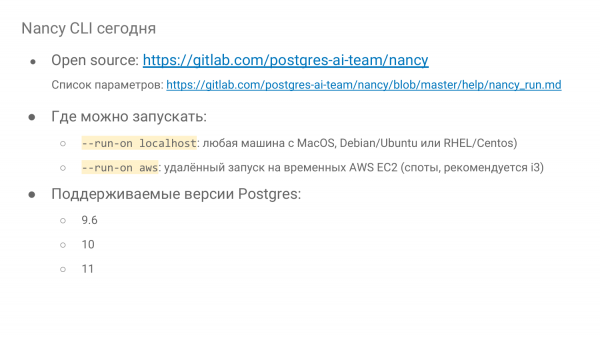
و سه نسخه اصلی Postgres پشتیبانی می شوند. به پایان رساندن برخی از نسخه های قدیمی و نسخه دوازدهم جدید چندان دشوار نیست.

ما می توانیم یک شی را به سه روش تعریف کنیم. این:
- فایل Dump/sql.
- راه اصلی کلون کردن دایرکتوری PGDATA است. به عنوان یک قاعده، از سرور پشتیبان گرفته می شود. اگر نسخه پشتیبان باینری معمولی دارید، می توانید از آنجا کلون بسازید. اگر فضای ابری دارید، یک دفتر ابری مانند آمازون و گوگل این کار را برای شما انجام خواهد داد. این مهمترین راه برای شبیه سازی تولید واقعی است. اینگونه آشکار می شویم.
- و آخرین روش زمانی برای تحقیق مناسب است که می خواهید بفهمید چیزی در Postgres چگونه کار می کند. این pgbench است. می توانید با استفاده از pgbench تولید کنید. این فقط یک گزینه "db-pgbench" است. شما به او بگویید چه ترازو. و همانطور که گفته شد همه چیز در ابر تولید می شود.

و بارگیری کنید:
- ما می توانیم بار را در یک رشته SQL اجرا کنیم. این ابتدایی ترین راه است.
- و ما می توانیم بار را شبیه سازی کنیم. و ما می توانیم اول از همه به روش زیر از آن تقلید کنیم. ما باید تمام سیاههها را جمع آوری کنیم. و دردناک است. من به شما نشان خواهم داد که چرا. و با استفاده از pgreplay بازی می کنیم که در نانسی ساخته شده است.
- یا گزینه دیگری. به اصطلاح بار کرافت که با تلاش و کوشش انجام می دهیم. با تجزیه و تحلیل بار فعلی خود بر روی سیستم رزمی، گروه های برتر درخواست ها را بیرون می آوریم. و با استفاده از pgbench می توانیم این بار را در آزمایشگاه شبیه سازی کنیم.

- یا باید نوعی SQL را انجام دهیم، یعنی نوعی مهاجرت را بررسی کنیم، یک شاخص در آنجا ایجاد کنیم، ANALAZE را در آنجا اجرا کنیم. و ما به آنچه قبل از خلاء و بعد از خلاء رخ داده است نگاه می کنیم. به طور کلی، هر SQL.
- یا یک یا چند پارامتر را در پیکربندی تغییر می دهیم. میتوانیم به ما بگوییم که مثلاً 100 مقدار در آمازون را برای پایگاه داده ترابایتی خود بررسی کنیم. و در عرض چند ساعت به نتیجه خواهید رسید. به عنوان یک قاعده، چند ساعت طول می کشد تا یک پایگاه داده ترابایتی را مستقر کنید. اما یک وصله در حال توسعه وجود دارد، ما یک سری ممکن داریم، یعنی می توانید به طور مداوم از همان pgdata در همان سرور استفاده کنید و بررسی کنید. Postgres مجدداً راه اندازی می شود و حافظه پنهان بازنشانی می شود. و شما می توانید بار را برانید.

- دایرکتوری با دسته ای از فایل های مختلف می رسد که از عکس های فوری pg شروع می شودآمار*** و جالب ترین چیز pg_stat_statements، pg_stat_kcacke است. این دو افزونه هستند که درخواست ها را تجزیه و تحلیل می کنند. و pg_stat_bgwriter نه تنها شامل آمار pgwriter میشود، بلکه در مورد چک پوینت و نحوه جابجایی بافرهای کثیف توسط backendها نیز وجود دارد. و دیدن همه اینها جالب است. به عنوان مثال، هنگامی که ما shared_buffers را راه اندازی می کنیم، بسیار جالب است که ببینیم همه چقدر جایگزین کرده اند.
- سیاهههای مربوط به پست گرس نیز در حال رسیدن هستند. دو گزارش - یک گزارش آماده سازی و یک گزارش پخش بار.
- یک ویژگی نسبتا جدید FlameGraphs است.
- همچنین، اگر از گزینههای pgreplay یا pgbench برای پخش بار استفاده کردهاید، خروجی آنها بومی خواهد بود. و شما تاخیر و TPS را خواهید دید. می توان فهمید که آنها چگونه آن را دیدند.
- اطلاعات سیستم.
- بررسی های اولیه CPU و IO. این بیشتر برای مثال EC2 در آمازون است، زمانی که میخواهید 100 نمونه یکسان را در یک رشته راهاندازی کنید و 100 اجرای مختلف را در آنجا اجرا کنید، سپس 10 آزمایش خواهید داشت. و باید مطمئن شوید که با یک نمونه معیوب روبرو نشوید که قبلاً توسط کسی مورد ظلم قرار گرفته باشد. دیگران در این بخش از سخت افزار فعال هستند و شما منبع کمی باقی مانده است. بهتر است چنین نتایجی را کنار بگذارید. و با کمک sysbench از Alexey Kopytov، چندین بررسی کوتاه انجام می دهیم که می آیند و می توانند با دیگران مقایسه شوند، یعنی شما متوجه خواهید شد که CPU چگونه رفتار می کند و چگونه IO رفتار می کند.

مشکلات فنی بر اساس مثال شرکت های مختلف چیست؟

فرض کنید می خواهیم بار واقعی را با استفاده از لاگ ها تکرار کنیم. اگر بر روی منبع باز pgreplay نوشته شده باشد، ایده خوبی است. ما از آن استفاده می کنیم. اما برای اینکه آن به خوبی کار کند، باید ثبت کامل پرس و جو را با پارامترها و زمان بندی فعال کنید.
برخی از عوارض با مدت و زمان وجود دارد. ما کل این آشپزخانه را خالی می کنیم. سوال اصلی این است که آیا می توانید آن را بپردازید یا نه؟

مشکل این است که ممکن است در دسترس نباشد. اول از همه، باید بفهمید که چه جریانی در گزارش نوشته می شود. اگر pg_stat_statements دارید، می توانید از این پرس و جو (لینک در اسلایدها موجود خواهد بود) استفاده کنید تا بفهمید تقریباً چند بایت در هر ثانیه نوشته می شود.
ما به طول درخواست نگاه می کنیم. ما از این واقعیت غفلت می کنیم که هیچ پارامتری وجود ندارد، اما طول درخواست را می دانیم و می دانیم که چند بار در ثانیه اجرا شده است. به این ترتیب ما می توانیم تقریباً چند بایت در ثانیه را تخمین بزنیم. ممکن است دوبرابر اشتباه کنیم، اما قطعاً ترتیب را اینگونه خواهیم فهمید.
می بینیم که 802 بار در ثانیه این درخواست اجرا می شود. و می بینیم که bytes_per sec – 300 kB/s به اضافه یا منهای نوشته می شود. و به عنوان یک قاعده، ما می توانیم چنین جریانی را تحمل کنیم.

ولی! واقعیت این است که سیستم های گزارش گیری متفاوتی وجود دارد. و پیش فرض افراد معمولا "syslog" است.
و اگر syslog دارید، ممکن است تصویری مانند این داشته باشید. ما pgbench را می گیریم، ثبت پرس و جو را فعال می کنیم و ببینیم چه اتفاقی می افتد.
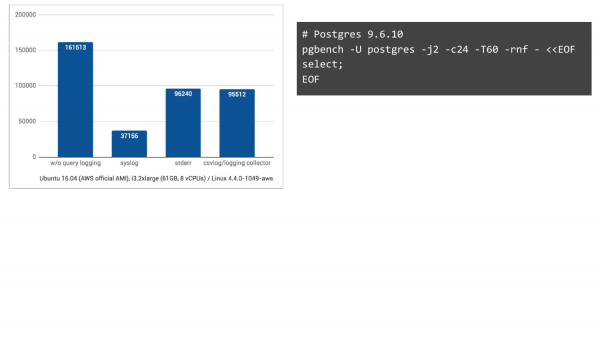
بدون ثبت وقایع، این ستون سمت چپ است. ما ۱۶۱۰۰۰ تراکنش در ثانیه داریم. با ثبت وقایع سیستمی، این در Ubuntu در ۱۶ آوریل، ما ۳۷۰۰۰ تراکنش در ثانیه در آمازون دریافت میکنیم. و اگر به دو روش ثبت دیگر روی بیاوریم، وضعیت خیلی بهتر میشود. بنابراین، انتظار افت داشتیم، اما نه آنقدر زیاد.
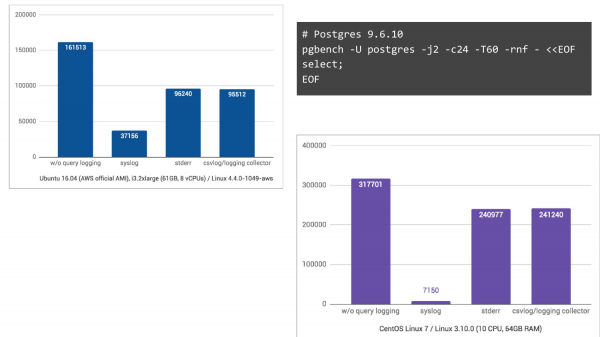
و در ادامه CentOS نسخه ۷ که از journald نیز استفاده میکند و لاگها را برای جستجوی آسان به فرمت دودویی تبدیل میکند و غیره، با افت ۴۴ برابری در تعداد تراکنشها (TPS)، یک کابوس تمامعیار است.
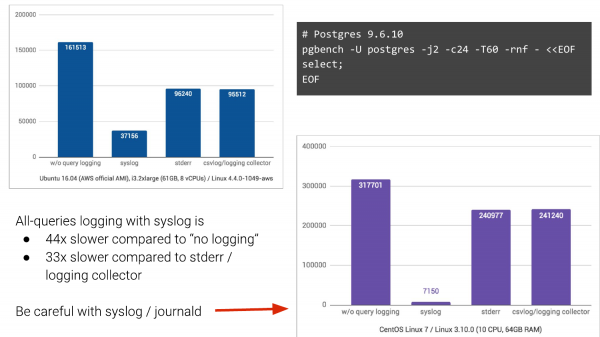
و این چیزی است که مردم با آن زندگی می کنند. و اغلب در شرکت ها، به ویژه شرکت های بزرگ، تغییر این امر بسیار دشوار است. اگر می توانید از syslog دور شوید، لطفاً از آن دور شوید.

- IOPS را ارزیابی کنید و جریان را بنویسید.
- سیستم گزارش خود را بررسی کنید.
- اگر بار پیش بینی شده بیش از حد بزرگ است، نمونه برداری را در نظر بگیرید.

ما pg_stat_statements داریم. همانطور که گفتم باید آنجا باشد. و می توانیم هر گروه از درخواست ها را به شکلی خاص در یک فایل گرفته و توصیف کنیم. و سپس می توانیم از یک ویژگی بسیار راحت در pgbench استفاده کنیم - این توانایی درج چندین فایل با استفاده از گزینه "-f" است.
خیلی از "-f" را می فهمد. و می توانید با کمک "@" در پایان بگویید که هر فایل چه سهمی باید داشته باشد. یعنی می توان گفت در 10 درصد موارد این کار را انجام دهید و در 20 درصد این کار را انجام دهید. و این ما را به آنچه در تولید می بینیم نزدیکتر می کند.

چگونه آنچه را که در تولید داریم درک خواهیم کرد؟ چه سهمی و چگونه؟ این کمی به کناری است. ما یک محصول دیگر داریم . همچنین یک پایگاه در متن باز. و ما اکنون به طور فعال در حال توسعه آن هستیم.
او به دلایل کمی متفاوت به دنیا آمد. به دلایلی که نظارت کافی نیست. یعنی شما بیایید، پایگاه را نگاه کنید، به مشکلاتی که وجود دارد نگاه کنید. و به عنوان یک قاعده، شما یک Health_check انجام می دهید. اگر شما یک DBA باتجربه هستید، پس Health_check را انجام دهید. ما به استفاده از ایندکس ها و غیره نگاه کردیم. اگر OKmeter دارید، عالی است. این نظارت عالی برای Postgres است. OKmeter.io - لطفاً آن را نصب کنید، همه چیز در آنجا بسیار خوب انجام می شود. پرداخت شده است.
اگر یکی ندارید، پس معمولاً چیز زیادی ندارید. در مانیتورینگ معمولا CPU، IO، و سپس با رزرو وجود دارد، و تمام. و ما بیشتر نیاز داریم. باید ببینیم که autovacuum چگونه کار می کند، چک پوینت چگونه کار می کند، در io باید checkpoint را از bgwriter و از backend ها و غیره جدا کنیم.
مشکل این است که وقتی به یک شرکت بزرگ کمک میکنید، آنها نمیتوانند به سرعت چیزی را اجرا کنند. آنها نمی توانند به سرعت اوکی متر را بخرند. شاید شش ماه دیگر بخرند. آنها نمی توانند برخی از بسته ها را به سرعت تحویل دهند.
و ما به این ایده رسیدیم که به ابزار خاصی نیاز داریم که نیازی به نصب نداشته باشد، یعنی اصلاً نیازی به نصب چیزی در تولید ندارید. آن را روی لپ تاپ خود یا روی یک سرور مشاهده کننده از جایی که آن را اجرا می کنید نصب کنید. و بسیاری از چیزها را تجزیه و تحلیل خواهد کرد: سیستم عامل، سیستم فایل، و خود Postgres، ایجاد برخی پرس و جوهای سبک که می توانند مستقیماً برای تولید اجرا شوند و هیچ چیز شکست نخواهد خورد.
اسمش را گذاشتیم چکاپ Postgres. از نظر پزشکی، این یک بررسی بهداشتی منظم است. اگر با مضمون خودرو باشد، مانند تعمیر و نگهداری است. شما بسته به برند خودروی خود را هر شش ماه یا یک سال یکبار تعمیر و نگهداری انجام می دهید. آیا برای پایگاه خود تعمیر و نگهداری انجام می دهید؟ یعنی آیا به طور مرتب تحقیق عمیق انجام می دهید؟ باید انجام شود. اگر نسخه پشتیبان تهیه می کنید، پس چکاپ انجام دهید، این اهمیت کمتری ندارد.
و ما چنین ابزاری داریم. تنها حدود سه ماه پیش شروع به ظهور فعال کرد. او هنوز جوان است، اما چیزهای زیادی وجود دارد.

جمع آوری "تاثیرگذارترین" گروه های پرس و جو - گزارش K003 در Postgres-checkup
و یک گروه از گزارشات K. سه گزارش تا کنون وجود دارد. و چنین گزارش K003 وجود دارد. بالای pg_stat_statements وجود دارد که بر اساس total_time مرتب شده است.
وقتی گروههای درخواست را بر اساس total_time مرتب میکنیم، در بالا گروهی را میبینیم که سیستم ما را بیشتر بارگذاری میکند، یعنی منابع بیشتری مصرف میکند. چرا گروه های پرس و جو را نام می برم؟ چون ما پارامترها را حذف کردیم. اینها دیگر درخواست نیستند، بلکه گروهی از درخواست ها هستند، یعنی انتزاع می شوند.
و اگر از بالا به پایین بهینه سازی کنیم، منابع خود را کم می کنیم و لحظه ای را که نیاز به ارتقا داریم به تاخیر می اندازیم. این یک راه بسیار خوب برای صرفه جویی در هزینه است.
شاید این روش خیلی خوبی برای مراقبت از کاربران نباشد، زیرا ممکن است موارد نادر، اما بسیار آزاردهنده ای را مشاهده نکنیم که شخصی 15 ثانیه منتظر بماند. در مجموع، آنها آنقدر نادر هستند که ما آنها را نمی بینیم، اما ما با منابع سروکار داریم.

در این جدول چه اتفاقی افتاده است؟ دو تا عکس گرفتیم Postgres_checkup یک دلتا برای هر معیار به شما می دهد: کل زمان، تماس ها، ردیف ها، shared_blks_read و غیره. همین، دلتا محاسبه شده است. مشکل بزرگ pg_stat_statements این است که به یاد نمی آورد چه زمانی ریست شده است. اگر pg_stat_database به خاطر بیاورد، pg_stat_statements به خاطر نمی آورد. می بینید که تعداد 1 وجود دارد، اما ما نمی دانیم از کجا حساب کرده ایم.
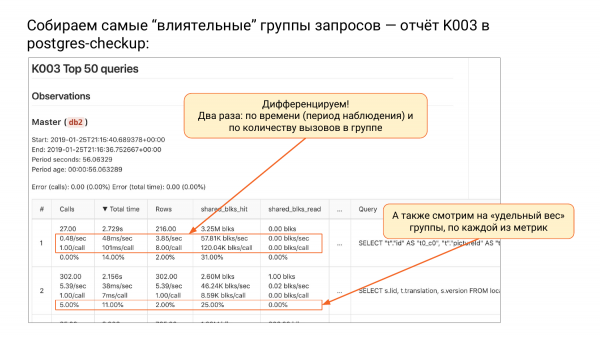
و در اینجا ما می دانیم، در اینجا ما دو عکس فوری داریم. می دانیم که دلتا در این مورد 56 ثانیه بود. یک فاصله بسیار کوتاه مرتب شده بر اساس total_time. و سپس می توانیم متمایز کنیم، یعنی تمام معیارها را بر اساس مدت زمان تقسیم می کنیم. اگر هر متریک را بر مدت زمان تقسیم کنیم، تعداد تماس در ثانیه خواهیم داشت.
بعد، total_time در ثانیه معیار مورد علاقه من است. بر حسب ثانیه، در هر ثانیه اندازه گیری می شود، یعنی چند ثانیه طول کشید تا سیستم ما این گروه از درخواست ها را در هر ثانیه اجرا کند. اگر در آنجا بیش از یک ثانیه در ثانیه دیدید، به این معنی است که باید بیش از یک هسته بدهید. این یک معیار بسیار خوب است. می توانید بفهمید که این دوست مثلا حداقل به سه هسته نیاز دارد.
این دانش ماست، من هرگز چنین چیزی را در هیچ کجا ندیده ام. لطفا توجه داشته باشید - این یک چیز بسیار ساده است - ثانیه در ثانیه. گاهی اوقات، وقتی CPU شما 100٪ است، نیم ساعت در ثانیه، یعنی نیم ساعت صرف این درخواست ها کرده اید.
در مرحله بعد ردیف در ثانیه را می بینیم. ما می دانیم که در هر ثانیه چند ردیف برگردانده شده است.
و سپس یک چیز جالب نیز وجود دارد. در هر ثانیه چند shared_buffer از خود shared_buffers می خوانیم. بازدیدها قبلاً وجود داشت، و ما ردیفها را از حافظه پنهان سیستم عامل یا از دیسک برداشتیم. گزینه اول سریع است و گزینه دوم بسته به شرایط ممکن است سریع باشد یا نباشد.
و راه دوم تمایز تقسیم تعداد درخواست های این گروه است. در ستون دوم شما همیشه یک پرس و جو تقسیم شده در هر پرس و جو خواهید داشت. و سپس جالب است - این درخواست چند میلی ثانیه بود. ما می دانیم که این پرس و جو به طور متوسط چگونه رفتار می کند. برای هر درخواست 101 میلی ثانیه لازم بود. این معیار سنتی است که باید درک کنیم.
هر پرس و جو به طور متوسط چند ردیف برگردانده است؟ ما شاهد بازگشت 8 این گروه هستیم. به طور متوسط چقدر از حافظه پنهان برداشته شده و خوانده شده است. می بینیم که همه چیز به خوبی ذخیره شده است. ضربه های محکم برای گروه اول.
و چهارمین زیر رشته در هر خط چند درصد از کل است. تماس داریم فرض کنید 1 و ما می توانیم درک کنیم که این گروه چه کمکی می کند. می بینیم که در این مورد، گروه اول کمتر از 000 درصد سهم دارند. یعنی آنقدر کند است که در تصویر کلی آن را نمی بینیم. و گروه دوم 000% در تماس هستند. یعنی 0,01 درصد از کل تماس ها گروه دوم هستند.
Total_time هم جالبه. ما 14 درصد از کل زمان کار خود را صرف اولین گروه از درخواست ها کردیم. و برای دوم - 11٪ و غیره.
من وارد جزئیات نمیشوم، اما نکات ظریفی وجود دارد. ما یک خطا را در بالا نمایش می دهیم، زیرا هنگام مقایسه، ممکن است عکس های فوری شناور شوند، یعنی ممکن است برخی از درخواست ها خارج شوند و دیگر در مورد دوم وجود نداشته باشند، در حالی که ممکن است برخی از درخواست های جدید ظاهر شوند. و در آنجا خطا را محاسبه می کنیم. اگر 0 را می بینید، خوب است. هیچ خطایی وجود ندارد. اگر میزان خطا تا 20 درصد باشد، اشکالی ندارد.

سپس به موضوع خود باز می گردیم. ما باید حجم کار را ایجاد کنیم. از بالا به پایین می گیریم و می رویم تا به 80 درصد یا 90 درصد برسیم. معمولا این 10-20 گروه است. و برای pgbench فایل میسازیم. ما در آنجا از تصادفی استفاده می کنیم. گاهی اوقات این، متاسفانه، کار نمی کند. و در Postgres 12 فرصت های بیشتری برای استفاده از این رویکرد وجود خواهد داشت.
و بعد از این طریق 80-90% در total_time به دست می آوریم. بعد از «@» چه چیزی را باید قرار دهم؟ ما به تماسها نگاه میکنیم، نگاه میکنیم که چقدر علاقه وجود دارد و میفهمیم که در اینجا این همه بهره مدیونیم. از این درصدها می توانیم بفهمیم که چگونه هر یک از فایل ها را متعادل کنیم. بعد از آن از pgbench استفاده می کنیم و سر کار می رویم.
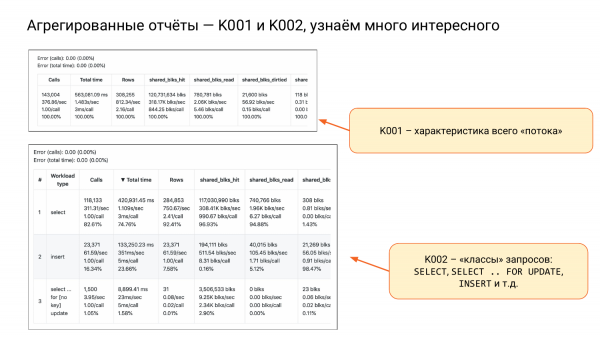
K001 و K002 هم داریم.
K001 یک رشته بزرگ با چهار رشته فرعی است. این ویژگی کل بار ماست. ستون دوم و زیر ردیف دوم را ببینید. می بینیم که حدود یک و نیم ثانیه در ثانیه است، یعنی اگر دو هسته باشد، خوب خواهد بود. حدود 75 درصد ظرفیت وجود خواهد داشت. و اینگونه عمل خواهد کرد. اگر 10 هسته داشته باشیم، به طور کلی آرام خواهیم بود. از این طریق می توانیم منابع را ارزیابی کنیم.
K002 همان چیزی است که من آن را کلاس های پرس و جو می نامم، یعنی SELECT، INSERT، UPDATE، DELETE. و جداگانه SELECT FOR UPDATE چون قفل است.
و در اینجا می توانیم نتیجه بگیریم که SELECT خوانندگان معمولی است - 82٪ از همه تماس ها، اما در همان زمان - 74٪ در total_time. یعنی زیاد نامیده می شوند اما منابع کمتری مصرف می کنند.
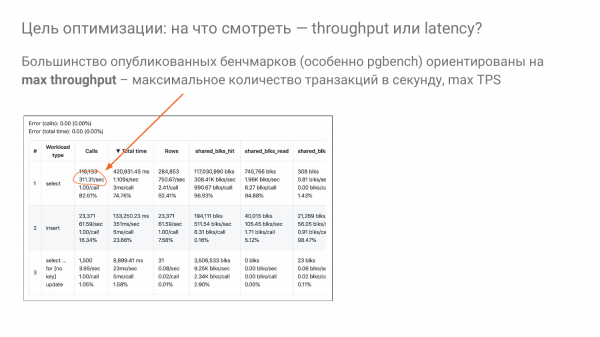
و به این سوال باز می گردیم: "چگونه می توانیم shared_buffers مناسب را انتخاب کنیم؟" مشاهده میکنم که بیشتر معیارها بر اساس این ایده هستند - بیایید ببینیم توان عملیاتی چقدر خواهد بود، یعنی توان عملیاتی چقدر خواهد بود. معمولاً با TPS یا QPS اندازه گیری می شود.
و ما سعی می کنیم با استفاده از پارامترهای تنظیم تا حد امکان تراکنش در هر ثانیه را از خودرو خارج کنیم. در اینجا دقیقاً 311 در ثانیه برای انتخاب است.

اما هیچ کس با سرعت کامل به سمت محل کار و بازگشت به خانه رانندگی نمی کند. این احمقانه است. در مورد دیتابیس ها هم همینطور. ما مجبور نیستیم با سرعت کامل رانندگی کنیم و هیچ کس هم این کار را نمی کند. هیچ کس در تولیدی که 100% CPU دارد زندگی نمی کند. اگرچه، شاید کسی زندگی کند، اما این خوب نیست.
ایده این است که ما معمولاً با 20 درصد ظرفیت، ترجیحاً بیش از 50 درصد رانندگی می کنیم. و ما بیشتر از همه سعی می کنیم زمان پاسخگویی را برای کاربران خود بهینه کنیم. یعنی باید دستگیره های خود را بچرخانیم تا حداقل تاخیر در سرعت 20 درصد مشروط وجود داشته باشد. این ایده ای است که ما نیز سعی می کنیم در آزمایشات خود از آن استفاده کنیم.
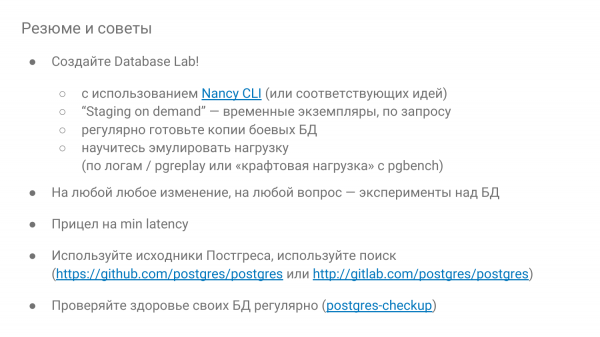
و در آخر توصیه هایی:
- حتماً Database Lab را انجام دهید.
- در صورت امکان، آن را در صورت تقاضا انجام دهید تا برای مدتی باز شود - بازی کنید و آن را دور بیندازید. اگر ابر دارید، پس ناگفته نماند، یعنی ایستادن زیادی داشته باشید.
- کنجکاو باشید و اگر چیزی اشتباه است، با آزمایشها بررسی کنید که چگونه رفتار میکند. از نانسی می توان برای آموزش نحوه عملکرد پایه استفاده کرد.
- و حداقل زمان پاسخگویی را هدف بگیرید.
- و از منابع Postgres نترسید. وقتی با منابع کار می کنید، باید انگلیسی بلد باشید. نظرات زیادی در آنجا وجود دارد، همه چیز در آنجا توضیح داده شده است.
- و سلامت پایگاه داده را به طور مرتب، حداقل هر سه ماه یک بار، به صورت دستی یا پس از بررسی چک کنید.

پرسش
خیلی ممنون! یه چیز خیلی جالب
دو تکه.
بله دو تکه فقط من کاملا متوجه نشدم وقتی من و نانسی کار می کنیم، آیا می توانیم فقط یک پارامتر یا کل گروه را تغییر دهیم؟
ما یک پارامتر پیکربندی delta داریم. می توانید یکباره هر چقدر که بخواهید به آنجا بپیچید. اما باید درک کنید که وقتی چیزهای زیادی را تغییر می دهید، می توانید نتیجه گیری های اشتباهی بگیرید.
آره. چرا پرسیدم؟ زیرا زمانی که شما فقط یک پارامتر دارید، انجام آزمایش ها دشوار است. سفتش کن ببین چطور کار میکنه بیرونش کردم سپس مورد بعدی را شروع می کنید.
می توانید همزمان آن را سفت کنید، البته بستگی به شرایط دارد. اما بهتر است یک ایده را آزمایش کنید. دیروز یه ایده داشتیم شرایط خیلی نزدیکی داشتیم. دو کانفیگ بود و ما نمی توانستیم بفهمیم که چرا تفاوت زیادی وجود دارد. و این ایده به وجود آمد که شما باید از دوگانگی استفاده کنید تا به طور مداوم تفاوت را بفهمید و پیدا کنید. می توانید بلافاصله نیمی از پارامترها را یکسان کنید، سپس یک چهارم و غیره. همه چیز قابل انعطاف است.
و یک سوال دیگر وجود دارد. این پروژه جوان و در حال توسعه است. مستندات از قبل آماده است، آیا شرح مفصلی وجود دارد؟
من به طور خاص در آنجا پیوندی به توضیحات پارامترها ایجاد کردم. آنجاست. اما خیلی چیزها هنوز وجود ندارد. من به دنبال افراد همفکر هستم. و هنگام اجرا آنها را پیدا می کنم. این خیلی باحاله یک نفر در حال حاضر با من کار می کند، کسی کمک کرده و کاری در آنجا انجام داده است. و اگر به این موضوع علاقه دارید، در مورد آنچه که از دست رفته است، بازخورد بدهید.
زمانی که آزمایشگاه را بسازیم، شاید بازخوردی وجود داشته باشد. اجازه بدید ببینم. متشکرم!
سلام! با تشکر از گزارش! من دیدم که پشتیبانی آمازون وجود دارد. آیا برنامه ای برای حمایت از GSP وجود دارد؟
سؤال خوبی بود. ما شروع به انجام آن کردیم. و فعلاً آن را منجمد کردیم زیرا میخواهیم در پول خود صرفهجویی کنیم. یعنی با استفاده از run در لوکال هاست پشتیبانی وجود دارد. می توانید خودتان یک نمونه ایجاد کنید و به صورت محلی کار کنید. اتفاقا ما همین کار را می کنیم. من این کار را در Getlab انجام می دهم، آنجا در GSP. اما ما هنوز هدفی در انجام چنین ارکستراسیونی نمی بینیم، زیرا گوگل نقاط ارزان قیمتی ندارد. وجود دارد ؟؟؟ نمونه ها، اما محدودیت هایی دارند. اولا، آنها همیشه فقط 70٪ تخفیف دارند و شما نمی توانید با قیمت آنجا بازی کنید. در نقاط مختلف، ما قیمت را 5-10٪ افزایش می دهیم تا احتمال لگد شدن شما را کاهش دهیم. یعنی شما نقاط را ذخیره می کنید، اما می توان آنها را در هر زمان از شما گرفت. اگر کمی بالاتر از دیگران پیشنهاد دهید، بعداً کشته خواهید شد. گوگل مشخصات کاملا متفاوتی دارد. و محدودیت بسیار بد دیگری وجود دارد - آنها فقط 24 ساعت زندگی می کنند. و گاهی می خواهیم یک آزمایش را به مدت 5 روز اجرا کنیم. اما شما می توانید این کار را در نقاط مختلف انجام دهید.
سلام! با تشکر از گزارش! به چکاپ اشاره کردید. چگونه خطاهای stat_statements را محاسبه می کنید؟
سوال خیلی خوبیه من می توانم با جزئیات زیاد به شما نشان دهم و بگویم. به طور خلاصه، ما به نحوه شناور شدن مجموعه گروه های درخواست نگاه می کنیم: چه تعداد از آنها سقوط کرده اند و چه تعداد گروه جدید ظاهر شده اند. و سپس به دو معیار نگاه می کنیم: total_time و calls، بنابراین دو خطا وجود دارد. و ما به سهم گروه های شناور نگاه می کنیم. دو زیر گروه وجود دارد: آنهایی که رفتند و کسانی که وارد شدند. بیایید ببینیم سهم آنها در تصویر کلی چیست.
آیا نمی ترسید که در فاصله زمانی بین عکس های فوری، دو یا سه بار به آنجا بچرخد؟
یعنی دوباره ثبت نام کردند یا چی؟
به عنوان مثال، این درخواست قبلاً یک بار پیش دستی شده است، سپس آمد و مجدداً پیش دستی شد، سپس دوباره آمد و مجدداً پیش دستی شد. و شما چیزی را در اینجا محاسبه کردید، و آن همه کجاست؟
سوال خوبی است، ما باید نگاه کنیم.
من یک کار مشابه انجام دادم. ساده تر بود البته من به تنهایی این کار را کردم. اما مجبور شدم ریست کنم، stat_statements را بازنشانی کنم و در زمان عکس فوری بفهمم که کمتر از یک کسر مشخص وجود دارد، که هنوز به سقف تعداد stat_statements نمیتواند در آنجا انباشته شود. و درک من این است که به احتمال زیاد هیچ چیز جابجا نشده است.
بله بله.
اما نمیدانم چگونه میتوان آن را با اطمینان انجام داد.
متأسفانه، دقیقاً به خاطر ندارم که آیا از متن query در آنجا استفاده می کنیم یا queryid با pg_stat_statements و روی آن تمرکز می کنیم. اگر روی queryid تمرکز کنیم، در تئوری چیزهای قابل مقایسه را با هم مقایسه می کنیم.
نه، او می تواند چندین بار بین عکس های فوری بیرون بیاید و دوباره بیاید.
با همون آی دی؟
بله.
ما این را مطالعه خواهیم کرد سؤال خوبی بود. ما باید آن را مطالعه کنیم. اما در حال حاضر چیزی که می بینیم 0 نوشته شده است...
این البته یک مورد نادر است، اما وقتی فهمیدم stat_statemetns میتواند در آنجا جابجا شود، شوکه شدم.
در Pg_stat_statements چیزهای زیادی می تواند وجود داشته باشد. ما با این واقعیت مواجه شدیم که اگر track_utility = روشن داشته باشید، مجموعه های شما نیز ردیابی می شوند.
بله البته
و اگر java hibernate دارید که تصادفی است، جدول هش در آنجا قرار می گیرد. و به محض خاموش کردن یک برنامه بسیار بارگذاری شده، در نهایت با 50-100 گروه مواجه می شوید. و همه چیز در آنجا کم و بیش پایدار است. یکی از راههای مبارزه با آن، افزایش pg_stat_statements.max است.
بله، اما باید بدانید چقدر است. و به نوعی باید مراقب او باشیم. این همون چیزیه که من انجام می دم. یعنی pg_stat_statements.max دارم. و من می بینم که در زمان عکس فوری به 70٪ نرسیده بودم. خوب، پس ما چیزی را از دست نداده ایم. بازنشانی کنیم و دوباره پس انداز می کنیم. اگر اسنپ شات بعدی کمتر از 70 باشد، به احتمال زیاد دیگر چیزی را از دست نداده اید.
آره. پیش فرض اکنون 5 است و این برای بسیاری از افراد کافی است.
معمولا بله.
ویدئو:

PS از طرف خودم، اضافه می کنم که اگر Postgres حاوی داده های محرمانه است و نمی تواند در محیط آزمایش گنجانده شود، می توانید از آن استفاده کنید. . این طرح تقریباً به شرح زیر است:
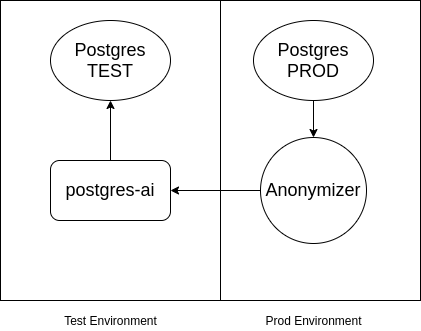
منبع: www.habr.com
