

Dans cet article, nous parlerons des dépendances fonctionnelles dans les bases de données : ce qu'elles sont, où elles sont utilisées et quels algorithmes existent pour les trouver.
Nous considérerons les dépendances fonctionnelles dans le contexte des bases de données relationnelles. En gros, dans de telles bases de données, les informations sont stockées sous forme de tableaux. Ensuite, nous utilisons des concepts approximatifs qui ne sont pas interchangeables en théorie relationnelle stricte : nous appellerons la table elle-même une relation, les colonnes - des attributs (leur ensemble - un schéma de relation), et l'ensemble des valeurs de ligne sur un sous-ensemble d'attributs. - un tuple.
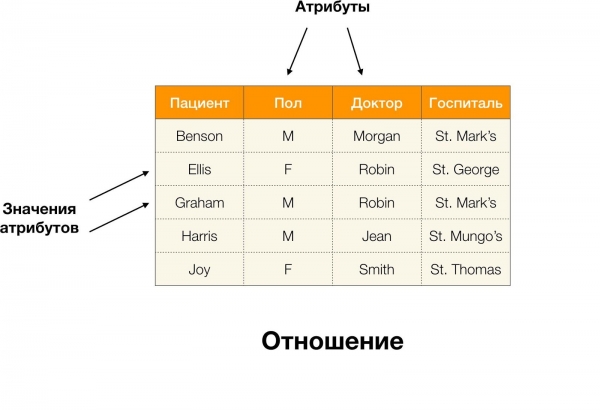
Par exemple, dans le tableau ci-dessus, (Benson, M, orgue M) est un tuple d'attributs (Patient, Paul, Docteur).
Plus formellement, cela s'écrit ainsi :  [Patient, sexe, médecin🇧🇷 (Benson, M, orgue M).
[Patient, sexe, médecin🇧🇷 (Benson, M, orgue M).
Nous pouvons maintenant introduire la notion de dépendance fonctionnelle (FD) :
Définition 1. La relation R satisfait la loi fédérale X → Y (où X, Y ⊆ R) si et seulement si pour tout tuple  ,
,  ∈ R est vrai : si
∈ R est vrai : si  [X] =
[X] =  [X], alors
[X], alors  [Y] =
[Y] =  [Y]. Dans ce cas, nous disons que X (l’ensemble déterminant ou définissant d’attributs) détermine fonctionnellement Y (l’ensemble dépendant).
[Y]. Dans ce cas, nous disons que X (l’ensemble déterminant ou définissant d’attributs) détermine fonctionnellement Y (l’ensemble dépendant).
Autrement dit, la présence d'une loi fédérale X → Oui signifie que si nous avons deux tuples R et ils correspondent dans les attributs X, alors ils coïncideront dans les attributs Y.
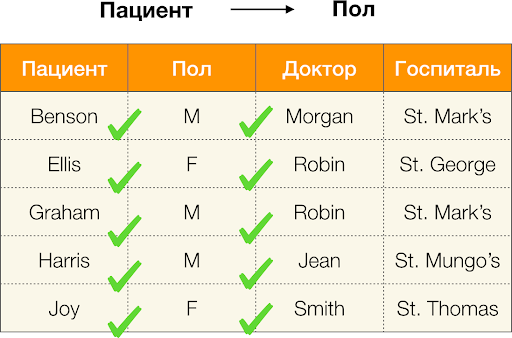
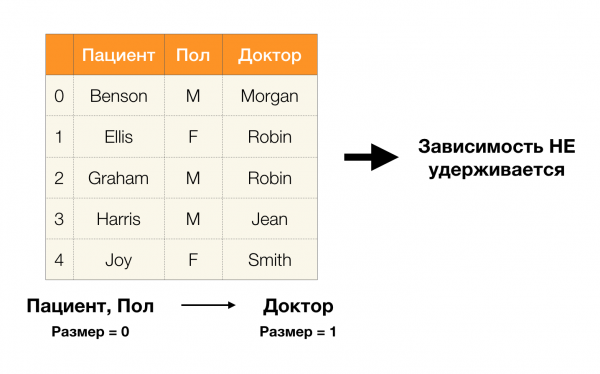
Et maintenant, dans l'ordre. Regardons les attributs Le patient и Genre pour lequel on veut savoir s'il existe ou non des dépendances entre eux. Pour un tel ensemble d'attributs, les dépendances suivantes peuvent exister :
- Patient → Sexe
- Sexe → Patient
Comme défini ci-dessus, pour que la première dépendance soit conservée, chaque valeur de colonne unique Le patient une seule valeur de colonne doit correspondre Genre. Et pour le tableau exemple, c’est effectivement le cas. Cependant, cela ne fonctionne pas dans le sens inverse, c'est-à-dire que la deuxième dépendance n'est pas satisfaite et que l'attribut Genre n'est pas un déterminant pour Patient. De même, si l’on prend la dépendance Médecin → Patient, vous pouvez voir qu'il est violé, puisque la valeur rouge-gorge cet attribut a plusieurs significations différentes - Ellis et Graham.
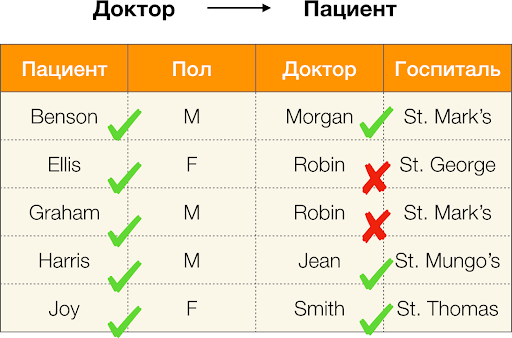
Ainsi, les dépendances fonctionnelles permettent de déterminer les relations existantes entre des ensembles d'attributs de table. A partir de là, nous examinerons les connexions les plus intéressantes, ou plutôt celles X → Ouique sont ils:
- non trivial, c'est-à-dire que le côté droit de la dépendance n'est pas un sous-ensemble du côté gauche (Y ̸⊆ X);
- minime, c'est-à-dire qu'il n'y a pas une telle dépendance Z → OuiQue Z ⊂X.
Les dépendances considérées jusqu'à présent étaient strictes, c'est-à-dire qu'elles ne prévoyaient aucune violation sur la table, mais en plus d'elles, il y a aussi celles qui permettent une certaine incohérence entre les valeurs des tuples. De telles dépendances sont placées dans une classe distincte, appelée approximation, et peuvent être violées pour un certain nombre de tuples. Ce montant est régulé par l'indicateur d'erreur maximale emax. Par exemple, le taux d'erreur  = 0.01 peut signifier que la dépendance peut être violée de 1 % des tuples disponibles sur l'ensemble d'attributs considéré. Autrement dit, pour 1000 10 enregistrements, un maximum de XNUMX tuples peuvent enfreindre la loi fédérale. Nous considérerons une métrique légèrement différente, basée sur des valeurs deux à deux différentes des tuples comparés. Pour la dépendance X → Oui sur l'attitude r on le considère ainsi :
= 0.01 peut signifier que la dépendance peut être violée de 1 % des tuples disponibles sur l'ensemble d'attributs considéré. Autrement dit, pour 1000 10 enregistrements, un maximum de XNUMX tuples peuvent enfreindre la loi fédérale. Nous considérerons une métrique légèrement différente, basée sur des valeurs deux à deux différentes des tuples comparés. Pour la dépendance X → Oui sur l'attitude r on le considère ainsi :

Calculons l'erreur pour Médecin → Patient de l'exemple ci-dessus. Nous avons deux tuples dont les valeurs diffèrent sur l'attribut Le patient, mais coïncident sur Médecin:  [Médecin, Patient] = (Robin, Ellis) Et
[Médecin, Patient] = (Robin, Ellis) Et  [Médecin, Patient] = (Robin, Graham). Suite à la définition d'une erreur, il faut prendre en compte toutes les paires en conflit, ce qui signifie qu'il y en aura deux : (
[Médecin, Patient] = (Robin, Graham). Suite à la définition d'une erreur, il faut prendre en compte toutes les paires en conflit, ce qui signifie qu'il y en aura deux : ( ,
,  ) et son inversion (
) et son inversion ( ,
,  ). Remplaçons-le dans la formule et obtenons :
). Remplaçons-le dans la formule et obtenons :

Essayons maintenant de répondre à la question : « À quoi ça sert ? En fait, les lois fédérales sont différentes. Le premier type concerne les dépendances déterminées par l'administrateur au stade de la conception de la base de données. Ils sont généralement peu nombreux, stricts et leur application principale est la normalisation des données et la conception de schémas relationnels.
Le deuxième type concerne les dépendances, qui représentent des données « cachées » et des relations jusque-là inconnues entre les attributs. Autrement dit, de telles dépendances n'ont pas été prises en compte au moment de la conception et elles sont trouvées pour l'ensemble de données existant, de sorte que plus tard, sur la base des nombreuses lois fédérales identifiées, des conclusions puissent être tirées sur les informations stockées. Ce sont précisément ces dépendances avec lesquelles nous travaillons. Ils sont traités par tout un domaine de data mining avec diverses techniques de recherche et algorithmes construits sur cette base. Voyons comment les dépendances fonctionnelles trouvées (exactes ou approximatives) dans n'importe quelle donnée peuvent être utiles.

Aujourd’hui, l’une des principales applications des dépendances est le nettoyage des données. Il s’agit de développer des processus permettant d’identifier les « données sales » puis de les corriger. Les exemples frappants de « données sales » sont les doublons, les erreurs de données ou les fautes de frappe, les valeurs manquantes, les données obsolètes, les espaces supplémentaires, etc.
Exemple d'erreur de données :
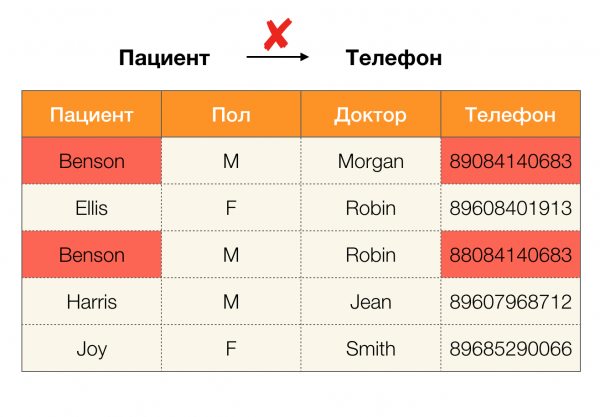
Exemple de doublons dans les données :
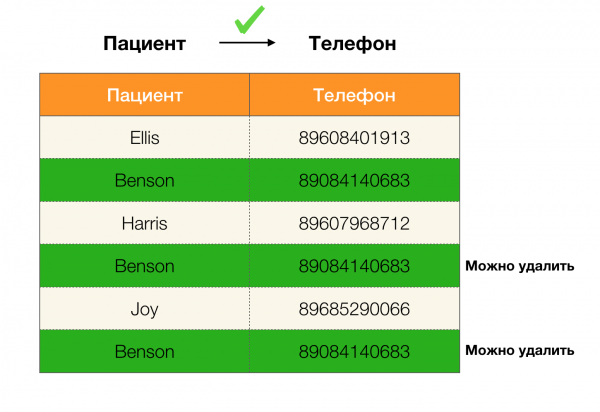
Par exemple, nous avons un tableau et un ensemble de lois fédérales qui doivent être exécutées. Dans ce cas, le nettoyage des données implique la modification des données afin que les lois fédérales deviennent correctes. Dans ce cas, le nombre de modifications doit être minime (cette procédure possède ses propres algorithmes, sur lesquels nous ne nous concentrerons pas dans cet article). Vous trouverez ci-dessous un exemple d'une telle transformation de données. À gauche se trouve la relation originale dans laquelle, évidemment, les FL nécessaires ne sont pas remplies (un exemple de violation de l'un des FL est surligné en rouge). À droite se trouve la relation mise à jour, les cellules vertes affichant les valeurs modifiées. Après cette procédure, les dépendances nécessaires ont commencé à être maintenues.
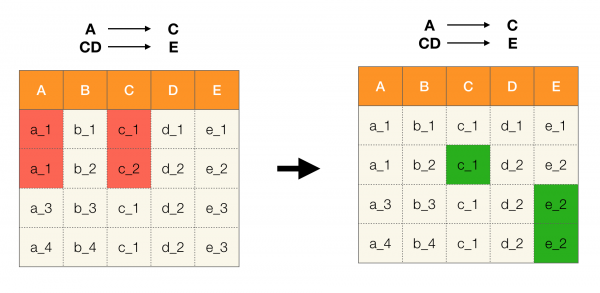
Une autre application populaire est la conception de bases de données. Ici, il convient de rappeler les formes normales et la normalisation. La normalisation est le processus de mise en conformité d'une relation avec un certain ensemble d'exigences, dont chacune est définie à sa manière par la forme normale. Nous ne décrirons pas les exigences des différentes formes normales (cela se fait dans n'importe quel livre sur un cours de base de données pour débutants), mais notons seulement que chacune d'elles utilise le concept de dépendances fonctionnelles à sa manière. Après tout, les FL sont intrinsèquement des contraintes d'intégrité qui sont prises en compte lors de la conception d'une base de données (dans le contexte de cette tâche, les FL sont parfois appelées superkeys).
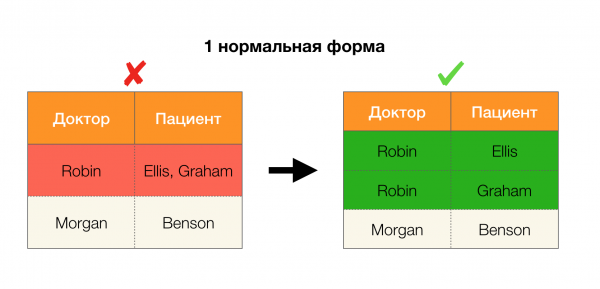
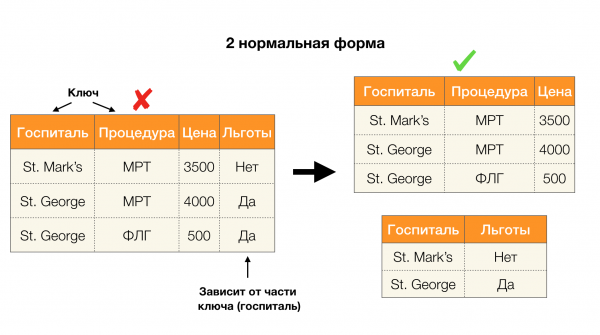
Considérons leur application pour les quatre formes normales dans l'image ci-dessous. Rappelons que la forme normale de Boyce-Codd est plus stricte que la troisième forme, mais moins stricte que la quatrième. Nous ne considérons pas cette dernière pour l'instant, car sa formulation nécessite une compréhension des dépendances multivaluées, qui ne nous intéressent pas dans cet article.
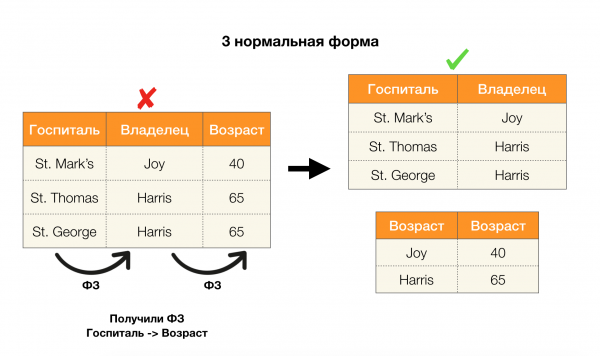
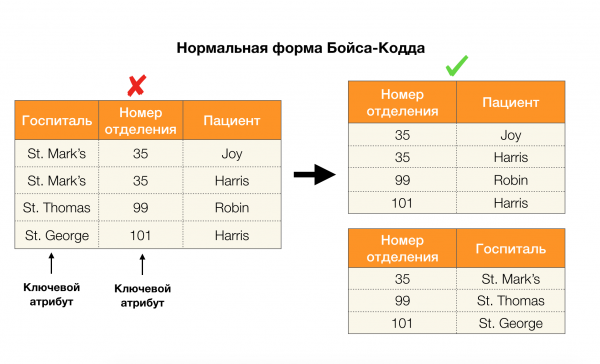
Un autre domaine dans lequel les dépendances ont trouvé leur application est la réduction de la dimensionnalité de l'espace des fonctionnalités dans des tâches telles que la création d'un classificateur Bayes naïf, l'identification des fonctionnalités significatives et le reparamétrage d'un modèle de régression. Dans les articles originaux, cette tâche est appelée la détermination de la redondance et de la pertinence des fonctionnalités [5, 6], et elle est résolue grâce à l'utilisation active des concepts de bases de données. Avec l'avènement de tels travaux, nous pouvons dire qu'il existe aujourd'hui une demande pour des solutions qui nous permettent de combiner la base de données, l'analyse et la mise en œuvre des problèmes d'optimisation ci-dessus en un seul outil [7, 8, 9].
Il existe de nombreux algorithmes (à la fois modernes et moins modernes) pour rechercher des lois fédérales dans un ensemble de données. Ces algorithmes peuvent être divisés en trois groupes :
- Algorithmes utilisant le parcours de réseaux algébriques (Algorithmes de parcours de treillis)
- Algorithmes basés sur la recherche de valeurs convenues (algorithmes de différence et d'accord)
- Algorithmes basés sur des comparaisons par paires (Algorithmes d'induction de dépendances)
Une brève description de chaque type d’algorithme est présentée dans le tableau ci-dessous :
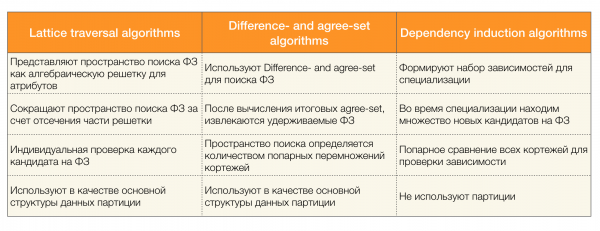
Vous pouvez en savoir plus sur cette classification [4]. Vous trouverez ci-dessous des exemples d'algorithmes pour chaque type :
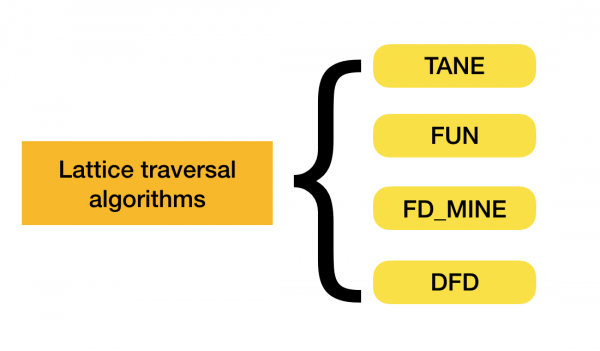
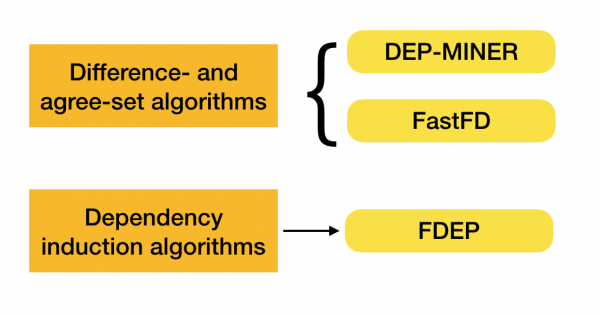
Actuellement, de nouveaux algorithmes apparaissent qui combinent plusieurs approches pour trouver des dépendances fonctionnelles. Des exemples de tels algorithmes sont Pyro [2] et HyFD [3]. Une analyse de leurs travaux est attendue dans les articles suivants de cette série. Dans cet article, nous examinerons uniquement les concepts de base et le lemme nécessaires pour comprendre les techniques de détection des dépendances.
Commençons par un simple - les ensembles de différences et d'accords, utilisés dans le deuxième type d'algorithmes. Difference-set est un ensemble de tuples qui n'ont pas les mêmes valeurs, tandis que l'accord-set, au contraire, est constitué de tuples qui ont les mêmes valeurs. Il convient de noter que dans ce cas, nous considérons uniquement le côté gauche de la dépendance.
Un autre concept important rencontré ci-dessus est le réseau algébrique. Étant donné que de nombreux algorithmes modernes fonctionnent sur ce concept, nous devons avoir une idée de ce dont il s’agit.
Afin d'introduire la notion de treillis, il est nécessaire de définir un ensemble partiellement ordonné (ou ensemble partiellement ordonné, en abrégé poset).
Définition 2. Un ensemble S est dit partiellement ordonné par la relation binaire ⩽ si pour tout a, b, c ∈ S les propriétés suivantes sont satisfaites :
- La réflexivité, c'est-à-dire a ⩽ a
- Antisymétrie, c'est-à-dire si a ⩽ b et b ⩽ a, alors a = b
- Transitivité, c'est-à-dire que pour a ⩽ b et b ⩽ c, il s'ensuit que a ⩽ c
Une telle relation est appelée relation d'ordre partiel (vrac), et l'ensemble lui-même est appelé un ensemble partiellement ordonné. Notation formelle : ⟨S, ⩽⟩.
Comme exemple le plus simple d'un ensemble partiellement ordonné, nous pouvons prendre l'ensemble de tous les nombres naturels N avec la relation d'ordre habituelle ⩽. Il est facile de vérifier que tous les axiomes nécessaires sont satisfaits.
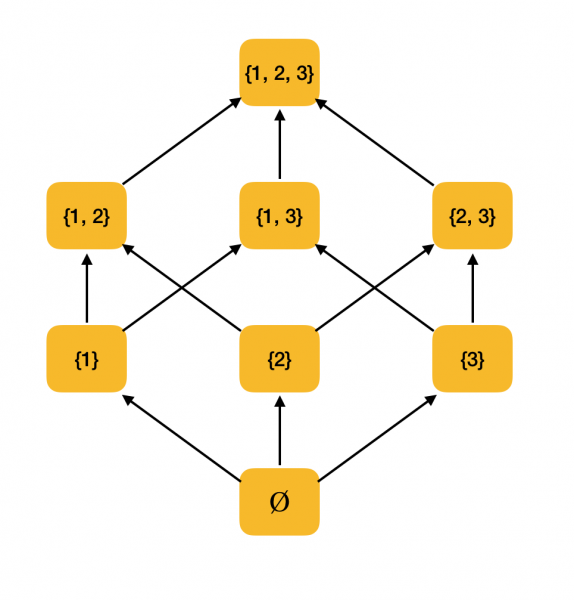
Un exemple plus significatif. Considérons l'ensemble de tous les sous-ensembles {1, 2, 3}, ordonnés par la relation d'inclusion ⊆. En effet, cette relation satisfait toutes les conditions d'ordre partiel, donc ⟨P ({1, 2, 3}), ⊆⟩ est un ensemble partiellement ordonné. La figure ci-dessous montre la structure de cet ensemble : si un élément peut être atteint par des flèches vers un autre élément, alors ils sont dans une relation d'ordre.
Nous aurons besoin de deux définitions plus simples du domaine des mathématiques : supremum et infimum.
Définition 3. Soit ⟨S, ⩽⟩ un ensemble partiellement ordonné, A ⊆ S. La borne supérieure de A est un élément u ∈ S tel que ∀x ∈ S : x ⩽ u. Soit U l'ensemble de toutes les bornes supérieures de S. S'il y a un plus petit élément dans U, alors il est appelé le supremum et est noté sup A.
Le concept de limite inférieure exacte est introduit de la même manière.
Définition 4. Soit ⟨S, ⩽⟩ un ensemble partiellement ordonné, A ⊆ S. L'infimum de A est un élément l ∈ S tel que ∀x ∈ S : l ⩽ x. Soit L l'ensemble de toutes les limites inférieures de S. S'il y a un plus grand élément dans L, alors il est appelé un infimum et est noté inf A.
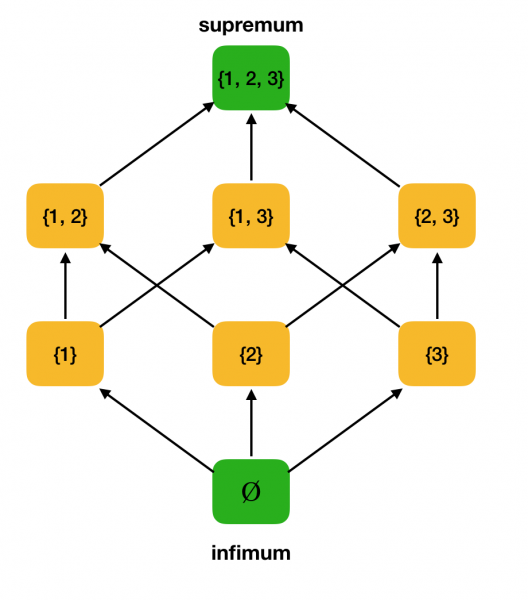
Considérons à titre d'exemple l'ensemble partiellement ordonné ci-dessus ⟨P ({1, 2, 3}), ⊆⟩ et trouvez-y le supremum et l'infimum :
Nous pouvons maintenant formuler la définition d’un réseau algébrique.
Définition 5. Soit ⟨P,⩽⟩ un ensemble partiellement ordonné tel que chaque sous-ensemble de deux éléments ait une limite supérieure et inférieure. Alors P est appelé réseau algébrique. Dans ce cas, sup{x, y} s'écrit x ∨ y, et inf {x, y} comme x ∧ y.
Vérifions que notre exemple de travail ⟨P ({1, 2, 3}), ⊆⟩ est un treillis. En effet, pour tout a, b ∈ P ({1, 2, 3}), a∨b = a∪b, et a∧b = a∩b. Par exemple, considérons les ensembles {1, 2} et {1, 3} et trouvez leur infimum et supremum. Si nous les croisons, nous obtiendrons l'ensemble {1}, qui sera l'infimum. Nous obtenons le suprême en les combinant - {1, 2, 3}.
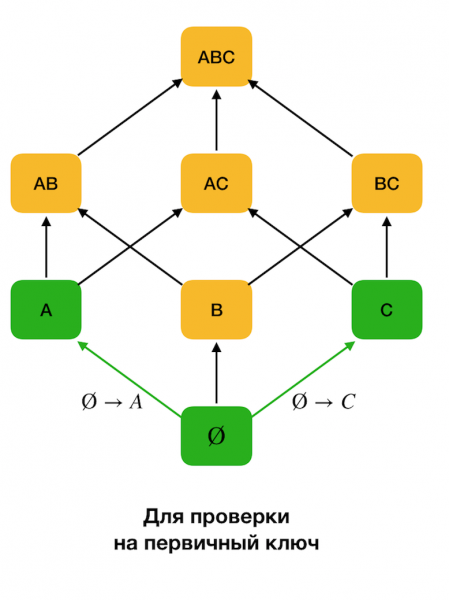
Dans les algorithmes d'identification de problèmes physiques, l'espace de recherche est souvent représenté sous la forme d'un réseau, où des ensembles d'un élément (lire le premier niveau du réseau de recherche, où le côté gauche des dépendances est constitué d'un attribut) représentent chaque attribut. de la relation originelle.
Tout d’abord, nous considérons des dépendances de la forme ∅ → Attribut unique. Cette étape vous permet de déterminer quels attributs sont des clés primaires (pour de tels attributs, il n'y a pas de déterminants, et donc le côté gauche est vide). De plus, ces algorithmes se déplacent vers le haut le long du réseau. Il convient de noter que la totalité du réseau ne peut pas être parcourue, c'est-à-dire que si la taille maximale souhaitée du côté gauche est transmise à l'entrée, l'algorithme n'ira pas plus loin qu'un niveau ayant cette taille.
La figure ci-dessous montre comment un réseau algébrique peut être utilisé dans le problème de recherche d'une FZ. Ici chaque bord (X, XY) représente une dépendance X → Oui. Par exemple, nous avons passé le premier niveau et savons que l'addiction est entretenue A→B (nous l'afficherons sous la forme d'une connexion verte entre les sommets A и B). Cela signifie que plus loin, lorsque nous progressons le long du réseau, nous ne pouvons pas vérifier la dépendance A, C → B, car il ne sera plus minime. De même, nous ne le vérifierions pas si la dépendance était maintenue C → B.
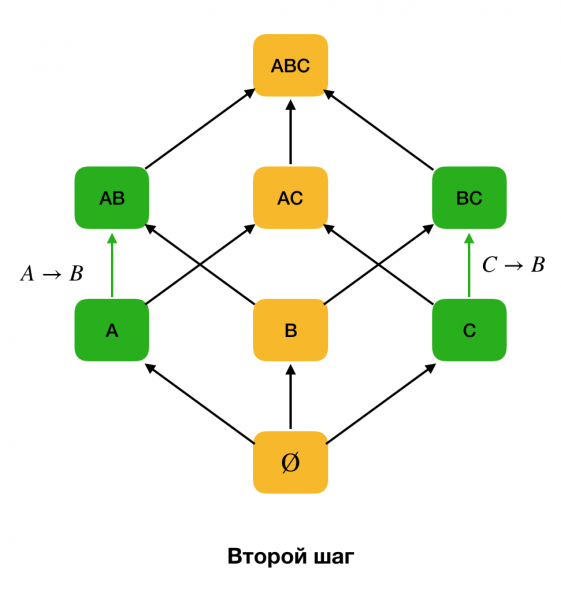
De plus, en règle générale, tous les algorithmes modernes de recherche de lois fédérales utilisent une structure de données telle qu'une partition (dans la source originale - partition supprimée [1]). La définition formelle d'une partition est la suivante :
Définition 6. Soit X ⊆ R un ensemble d'attributs pour la relation r. Un cluster est un ensemble d'indices de tuples dans r qui ont la même valeur pour X, c'est-à-dire c(t) = {i|ti[X] = t[X]}. Une partition est un ensemble de clusters, hors clusters de longueur unitaire :

En termes simples, une partition pour un attribut X est un ensemble de listes, où chaque liste contient des numéros de ligne avec les mêmes valeurs pour X. Dans la littérature moderne, la structure représentant les partitions est appelée index de liste de positions (PLI). Les clusters de longueur unitaire sont exclus à des fins de compression PLI, car ce sont des clusters qui contiennent uniquement un numéro d'enregistrement avec une valeur unique qui sera toujours facile à identifier.
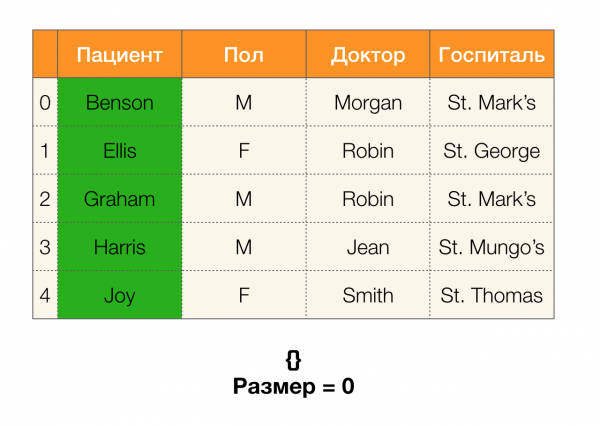
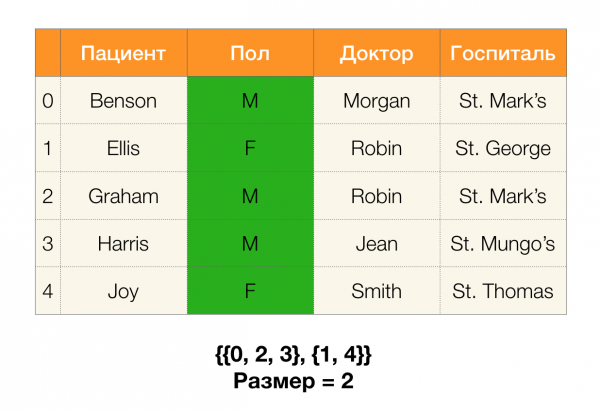
Regardons un exemple. Revenons à la même table avec les patients et construisons des partitions pour les colonnes Le patient и Genre (une nouvelle colonne est apparue à gauche, dans laquelle les numéros de lignes du tableau sont marqués) :
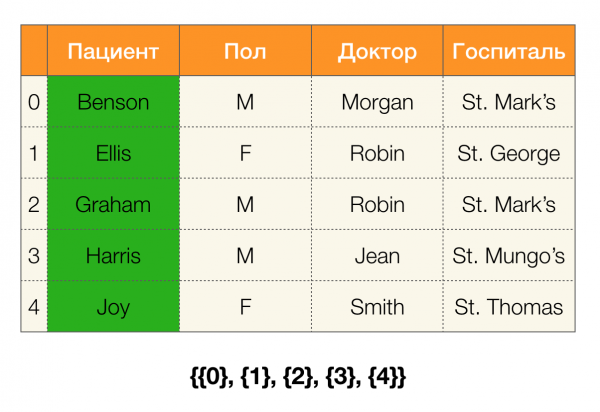
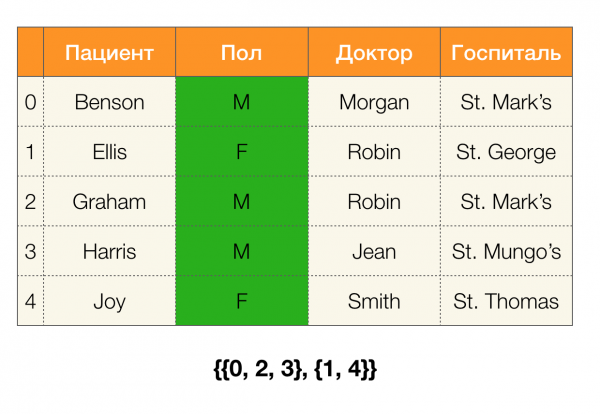
De plus, selon la définition, la partition de la colonne Le patient sera en fait vide, puisque les clusters uniques sont exclus de la partition.
Les partitions peuvent être obtenues par plusieurs attributs. Et il y a deux manières de procéder : en parcourant le tableau, construire une partition en utilisant tous les attributs nécessaires d'un coup, ou en la construisant en utilisant l'opération d'intersection de partitions en utilisant un sous-ensemble d'attributs. Les algorithmes de recherche de lois fédérales utilisent la deuxième option.
En termes simples, pour par exemple obtenir une partition par colonnes abc, vous pouvez prendre des partitions pour AC и B (ou tout autre ensemble de sous-ensembles disjoints) et les croiser les uns avec les autres. L'opération d'intersection de deux partitions sélectionne les clusters de plus grande longueur communs aux deux partitions.
Regardons un exemple:
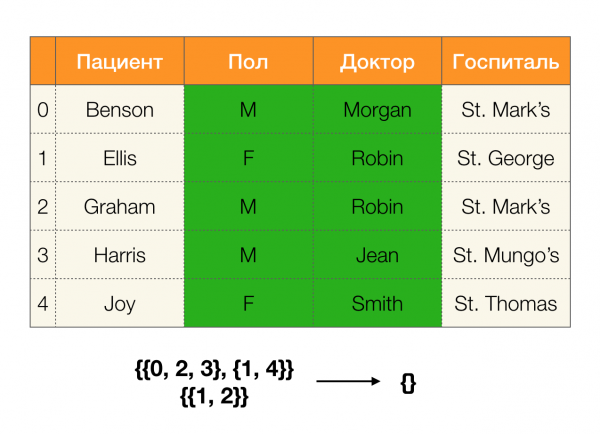

Dans le premier cas, nous avons reçu une partition vide. Si vous regardez attentivement le tableau, alors en effet, il n'y a pas de valeurs identiques pour les deux attributs. Si on modifie légèrement le tableau (cas de droite), on obtiendra déjà une intersection non vide. De plus, les lignes 1 et 2 contiennent en réalité les mêmes valeurs pour les attributs Genre и Médecin.
Ensuite, nous aurons besoin d'un concept tel que la taille de la partition. Officiellement:

En termes simples, la taille de la partition correspond au nombre de clusters inclus dans la partition (rappelez-vous que les clusters uniques ne sont pas inclus dans la partition !) :
Nous pouvons maintenant définir l'un des lemmes clés, qui, pour des partitions données, nous permet de déterminer si une dépendance est maintenue ou non :
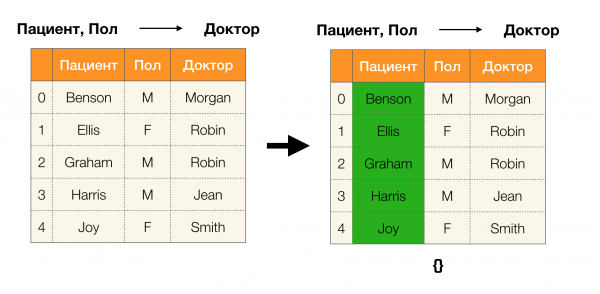
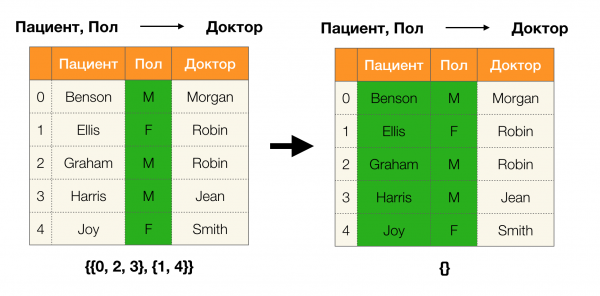
Lemme 1. La dépendance A, B → C est vraie si et seulement si

Selon le lemme, pour déterminer si une dépendance est vraie, quatre étapes doivent être effectuées :
- Calculer la partition pour le côté gauche de la dépendance
- Calculer la partition pour le côté droit de la dépendance
- Calculer le produit de la première et de la deuxième étape
- Comparez les tailles des partitions obtenues aux première et troisième étapes
Vous trouverez ci-dessous un exemple de vérification si la dépendance est vraie selon ce lemme :
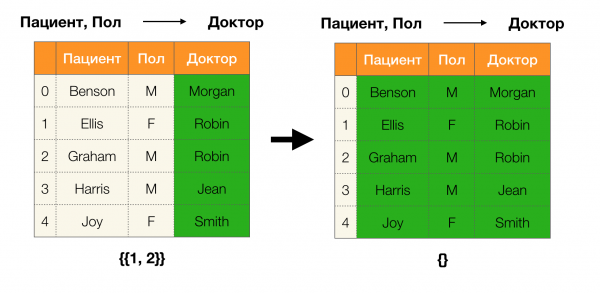
Dans cet article, nous avons examiné des concepts tels que la dépendance fonctionnelle, la dépendance fonctionnelle approximative, examiné où ils sont utilisés, ainsi que quels algorithmes existent pour rechercher des fonctions physiques. Nous avons également examiné en détail les concepts fondamentaux mais importants qui sont activement utilisés dans les algorithmes modernes de recherche de lois fédérales.
Les références:
- Huhtala Y. et coll. TANE : Un algorithme efficace pour découvrir des dépendances fonctionnelles et approximatives //Le journal informatique. – 1999. – T. 42. – Non. 2. – pp. 100-111.
- Kruse S., Naumann F. Découverte efficace des dépendances approximatives // Actes de la Dotation VLDB. – 2018. – T. 11. – Non. 7. – pp. 759-772.
- Papenbrock T., Naumann F. Une approche hybride de la découverte des dépendances fonctionnelles // Actes de la Conférence internationale 2016 sur la gestion des données. – ACM, 2016. – p. 821-833.
- Papenbrock T. et coll. Découverte des dépendances fonctionnelles : une évaluation expérimentale de sept algorithmes //Actes du VLDB Endowment. – 2015. – T. 8. – Non. 10. – pp. 1082-1093.
- Kumar A. et al. Rejoindre ou ne pas adhérer ? : Réfléchir à deux fois avant de sélectionner les fonctionnalités // Actes de la Conférence internationale 2016 sur la gestion des données. – ACM, 2016. – p. 19-34.
- Abo Khamis M. et coll. Apprentissage dans la base de données avec des tenseurs clairsemés // Actes du 37e Symposium ACM SIGMOD-SIGACT-SIGAI sur les principes des systèmes de bases de données. – ACM, 2018. – p. 325-340.
- Hellerstein JM et al. La bibliothèque d'analyse MADlib : ou MAD skills, le SQL //Actes du VLDB Endowment. – 2012. – T. 5. – Non. 12. – pp. 1700-1711.
- Qin C., Rusu F. approximations spéculatives pour l'optimisation de la descente de gradient distribuée terascale // Actes du quatrième atelier sur l'analyse des données dans le cloud. – ACM, 2015. – P. 1.
- Meng X. et coll. Mllib : Apprentissage automatique dans Apache Spark //The Journal of Machine Learning Research. – 2016. – T. 17. – Non. 1. – pp. 1235-1241.
Auteurs des articles : , chercheur à , и , chercheur à
Source: habr.com
