

Jean-Baptiste Lallement, director de enxeñaría de Canonical, presentou o proxecto Myna, que está a desenvolver unha aplicación de recoñecemento de voz destinada a organizar a entrada de voz e recoñecer comandos en linguaxe natural en Ubuntu Escritorio. O proxecto distribúese baixo a licenza GPLv3, pero o repositorio actualmente só contén bosquexos que describen a arquitectura modular do proxecto e a súa integración con Ubuntu.
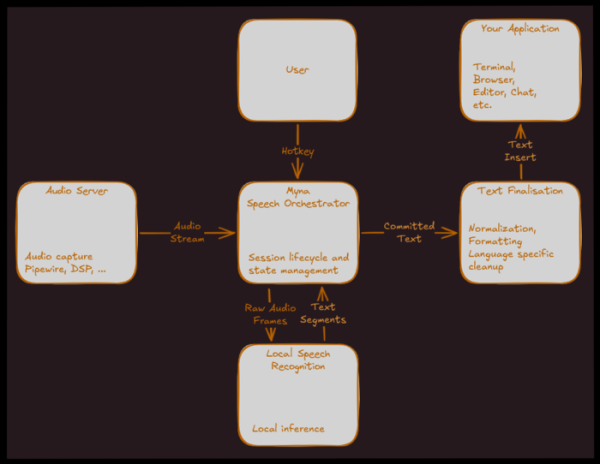
Para a súa publicación Ubuntu Está previsto que a aplicación sexa compatible coa entrada de voz o 26.10 de outubro. Unha sesión de usuario consiste en activar a aplicación mediante un atallo de teclado, ditar en voz alta e pegar o texto recoñecido na aplicación actual mediante unha entrada de teclado simulada mentres falas. Aparecerá un indicador especial no panel cando se active o micrófono.
Indícase que o entorno de probas base é GNOME baseado en Wayland, pero a aplicación está deseñada desde o principio para ser adaptable a varios entornos de escritorio.
Myna empregará un modelo de IA que se executa localmente para o recoñecemento de voz. Os requisitos para a aplicación inclúen: a capacidade de funcionar sen conexión; activar o micrófono só despois de activar explicitamente o modo de ditado cunha tecla de atallo; procesar o audio na memoria, que se borra despois de cada uso; e prohibir a transferencia de gravacións de audio a servizos externos.
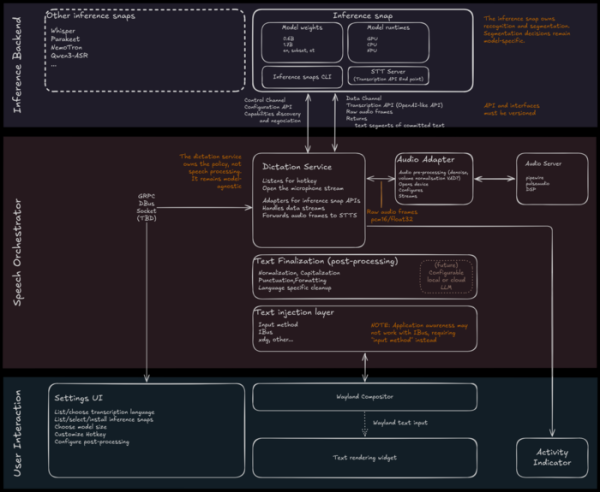
Os compoñentes para o recoñecemento de voz, a interacción co usuario, a xestión de ditados e a substitución de texto desenvólvense en forma de módulos.
O entorno de execución do modelo de IA estará empaquetado ao instante. Menciónanse Whisper, Parakeet, NemoTron e Qwen3-ASR como posibles modelos de recoñecemento.
O servizo de xestión de ditados monitoriza as pulsacións de teclas de atallo, activa o micrófono, accede ao modelo de IA no paquete snap a través dunha API, reenvía o fluxo de audio desde o servizo de audio a este e coordina os fluxos de datos.
O servizo de audio accede ao dispositivo de audio, xa sexa directamente ou a través dos servidores de audio PulseAudio ou PipeWire, suprime o ruído e ecualiza o volume. O texto xerado polo modelo pásase ao módulo de posprocesamento para a súa limpeza, normalización, formato e puntuación. O texto final insírese na aplicación mediante substitución de entrada, por exemplo, a través do protocolo de método de entrada Wayland ou IBus.
Unha vez estabilizada a funcionalidade inicial, non se pode descartar a implementación de capacidades como actuar como asistente de voz, executar comandos de voz, controlar o escritorio por voz e traducir texto ditado con recoñecemento automático de idiomas.
Fonte: opennet.ru
