

Cando se trata de monitorizar a seguridade dunha rede interna corporativa ou departamental, moita xente asóciaa coa detección de fugas de datos e a implementación de solucións DLP. Se intentas aclarar a pregunta e preguntar como detectas ataques na rede interna, a resposta normalmente mencionará os sistemas de detección de intrusións (IDS). O que era a única opción hai 10 ou 20 anos está a converterse agora nun anacronismo. Unha opción máis eficaz e, nalgúns casos, a única, para monitorizar unha rede interna é usar protocolos de fluxo. Estes protocolos foron deseñados orixinalmente para solucionar problemas de rede, pero evolucionaron co tempo ata converterse nunha ferramenta de seguridade verdadeiramente valiosa. Este artigo analizará os diferentes protocolos de fluxo dispoñibles, cales son os mellores para detectar ataques de rede, os mellores lugares para implementar a monitorización de fluxo, que ter en conta ao despregar un sistema deste tipo e mesmo como implementalo en equipos domésticos.
Non me detenderei na pregunta: "Por que é necesaria a vixilancia da seguridade da infraestrutura interna?". A resposta parece clara. Pero se queres estar seguro de que é esencial hoxe en día, Un vídeo curto que explica 17 xeitos de penetrar nunha rede corporativa protexida por un cortafuegos. Entón, supoñamos que entendemos que a monitorización interna é necesaria e o único que queda é descubrir como configurala.
Destacaría tres fontes de datos clave para a monitorización da infraestrutura a nivel de rede:
- tráfico "bruto", que capturamos e subministramos a certos sistemas de análise,
- eventos dos dispositivos de rede polos que pasa o tráfico,
- información de tráfico obtida mediante un dos protocolos de fluxo.

A captura de tráfico bruto é a opción máis popular entre os profesionais da seguridade porque foi historicamente a primeira en aparecer. Os sistemas convencionais de detección de intrusións en rede (o primeiro sistema comercial de detección de intrusións foi NetRanger de Wheel Group, adquirido por Cisco en 1998) capturaban paquetes (e sesións posteriores) para buscar sinaturas específicas ("regras de decisión" na terminoloxía FSTEC) que sinalan ataques. Por suposto, o tráfico bruto pódese analizar non só con IDS, senón tamén con outras ferramentas (por exemplo, Wireshark, tcpdum ou a funcionalidade NBAR2 en Cisco IOS), pero normalmente carecen da base de coñecementos que distingue unha solución de seguridade da información dunha ferramenta informática normal.
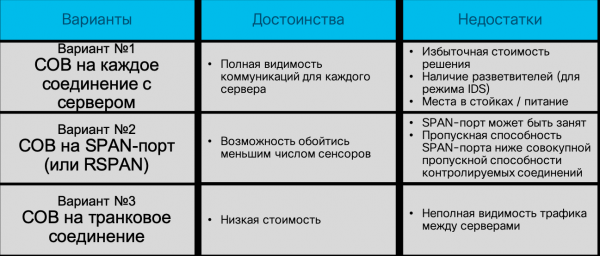
Entón, os sistemas de detección de intrusións. Este é o método máis antigo e popular para detectar ataques de rede, que fai un bo traballo no perímetro (xa sexa corporativo, de centro de datos, de segmento, etc.), pero que non é suficiente nas redes modernas conmutadas e definidas por software. Cunha rede construída con conmutadores convencionais, a infraestrutura de sensores de detección de intrusións faise demasiado grande: terías que instalar un sensor por cada conexión ao nodo que queiras monitorizar para detectar ataques. Calquera fabricante estaría encantado de venderche centos ou miles de sensores, pero dubido que o teu orzamento poida xestionar tal gasto. Podo dicir que mesmo en Cisco (somos os desenvolvedores de NGIPS), non poderiamos facer isto, aínda que parece que o prezo non debería ser un problema: é a nosa propia solución. Ademais, xorde a pregunta: como se conecta o sensor neste escenario? En liña? Que ocorre se o propio sensor falla? Deberías requirir un módulo de derivación no sensor? Usar derivacións? Todo isto aumenta o custo da solución e faina inasequible para unha empresa de calquera tamaño.
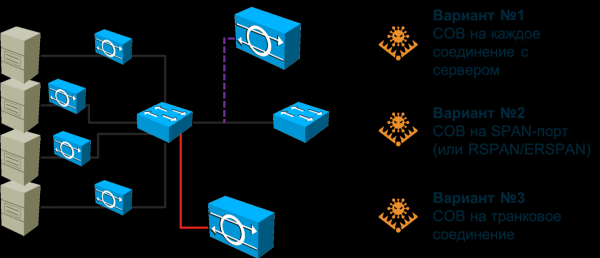
Podes tentar conectar un sensor a un porto SPAN/RSPAN/ERSPAN e reenviar o tráfico desde os portos de conmutación requiridos a el. Esta opción alivia parcialmente o problema descrito no parágrafo anterior, pero introduce outro: o porto SPAN non pode xestionar todo o tráfico que se lle envía; non ten ancho de banda suficiente. Terás que sacrificar algo. Ou deixa algúns nodos sen monitorizar (neste caso terás que priorizalos primeiro) ou reenvía só certos tipos de tráfico dun nodo, non todos. En calquera caso, poderiamos pasar por alto algúns ataques. Ademais, o porto SPAN pode estar ocupado por outras necesidades. En última instancia, teremos que revisar a topoloxía de rede existente e posiblemente facer axustes para maximizar a cobertura da rede co número de sensores que tes (e coordinar isto con TI).
Que ocorre se a súa rede usa rutas asimétricas? Que ocorre se implementou ou planea implementar SDN? Que ocorre se precisa monitorizar máquinas virtualizadas ou contedores cuxo tráfico nunca chega a un conmutador físico? Aos provedores de IDS tradicionais non lles gustan estas preguntas porque non saben como respondelas. Poden intentar convencerlle de que todas estas tecnoloxías de moda son só publicidade e que non as necesita. Poden dicirlle que comece pouco a pouco. Ou poden dicirlle que instale un potente trillador de rede no centro da rede e que enrute todo o tráfico cara a el mediante balanceadores de carga. Sexa cal sexa a opción que se lle ofreza, debe comprender claramente o axeitada que é para vostede. Só entón debería decidir unha estratexia para monitorizar a seguridade da información da súa infraestrutura de rede. Voltando á captura de paquetes, quero dicir que este método segue sendo moi popular e importante, pero o seu propósito principal é monitorizar os límites: os límites entre a súa organización e Internet, os límites entre o centro de datos e o resto da rede, os límites entre o ICS e o segmento corporativo. Nestes lugares, os IDS/IPS clásicos aínda teñen dereito a existir e a xestionar ben as tarefas que se lles asignan.
Pasemos á segunda opción. A análise de eventos procedentes de dispositivos de rede tamén se pode empregar para a detección de ataques, pero non como mecanismo principal, xa que só pode detectar unha pequena clase de intrusións. Ademais, é algo reactivo: primeiro debe producirse un ataque e despois ser detectado por un dispositivo de rede, o que sinalará un problema de seguridade dun xeito ou doutro. Existen varios métodos deste tipo. Estes inclúen syslog, RMON ou SNMP. Os dous últimos protocolos para a monitorización de redes no contexto da seguridade da información úsanse só se necesitamos detectar un ataque DoS no propio equipo de rede, xa que RMON e SNMP poden, por exemplo, rastrexar a carga na CPU dun dispositivo ou nas súas interfaces. Este é un dos métodos "máis baratos" (todo o mundo ten syslog ou SNMP), pero tamén o menos eficaz de todos os métodos para monitorizar a seguridade da información da infraestrutura interna: moitos ataques simplemente están ocultos dela. Por suposto, non se debe descoidar, e a análise do rexistro do sistema axuda a identificar rapidamente os cambios na configuración do dispositivo e o seu compromiso, pero non é moi axeitada para detectar ataques en toda a rede.
A terceira opción é analizar a información do tráfico que pasa por un dispositivo que admite un de varios protocolos de fluxo. Neste caso, independentemente do protocolo, a infraestrutura de fluxo consta necesariamente de tres compoñentes:
- Xeración ou exportación de fluxo. Esta función adoita asignarse a un enrutador, conmutador ou outro dispositivo de rede que procesa o tráfico de rede e extrae parámetros clave, que logo se transmiten a un módulo de recollida. Por exemplo, Cisco admite o protocolo Netflow non só en enrutadores e conmutadores, incluídos os virtuais e industriais, senón tamén en controladores sen fíos, cortafuegos e mesmo servidores.
- Recollida de fluxos. Dado que unha rede moderna normalmente ten máis dun dispositivo de rede, xorde a tarefa de recoller e consolidar fluxos. Isto realízase mediante os chamados colectores, que procesan os fluxos recibidos e logo os transmiten para a súa análise.
- Análise de fluxos. O analizador realiza a tarefa principal de intelixencia e, aplicando varios algoritmos aos fluxos, extrae conclusións. Por exemplo, nunha función de TI, un analizador deste tipo pode identificar os colos de botella da rede ou analizar os perfís de carga de tráfico para unha maior optimización da rede. E na seguridade da información, un analizador deste tipo pode detectar fugas de datos, propagación de software malicioso ou ataques de denegación de servizo.
Non penses que esta arquitectura de tres niveis é demasiado complexa: todas as demais opcións (coa posible excepción dos sistemas de monitorización de rede que usan SNMP e RMON) tamén funcionan segundo ela. Temos un xerador de datos para a análise, que é un dispositivo de rede ou un sensor independente. Temos un sistema de recollida de alarmas e temos un sistema de xestión para toda a infraestrutura de monitorización. Os dous últimos compoñentes pódense combinar nun só nodo, pero en redes máis grandes, normalmente distribúense en polo menos dous dispositivos para garantir a escalabilidade e a fiabilidade.
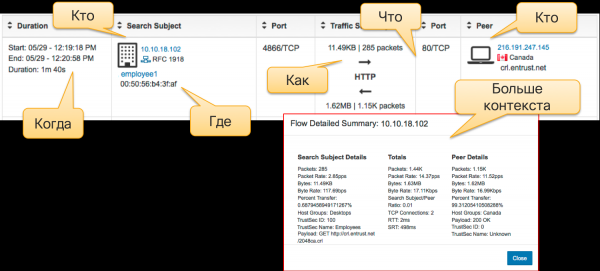
A diferenza da análise de paquetes, que se basea en examinar a cabeceira e o corpo de cada paquete e as sesións que o compoñen, a análise de fluxo baséase na recollida de metadatos sobre o tráfico de rede. Cando, canto, de onde, para onde, como... estas son as preguntas ás que se responde analizando a telemetría de rede utilizando varios protocolos de fluxo. Inicialmente, usábanse para analizar estatísticas e identificar problemas informáticos na rede, pero máis tarde, a medida que os mecanismos analíticos evolucionaron, fixéronse aplicables á mesma telemetría con fins de seguridade. Convén reiterar que a análise de fluxo non substitúe nin substituye a captura de paquetes. Cada un destes métodos ten a súa propia área de aplicación. Pero no contexto deste artigo, a análise de fluxo é máis axeitada para monitorizar a infraestrutura interna. Hai dispositivos de rede (xa sexan que operen nun paradigma definido por software ou segundo regras estáticas) que non poden ser ignorados por un ataque. Un ataque pode ignorar un sensor IDS clásico, pero non un dispositivo de rede que admita un protocolo de fluxo. Esta é a vantaxe deste método.
Por outra banda, se precisas probas para as forzas da orde ou para o teu propio equipo de resposta a incidentes, non podes prescindir da captura de paquetes: a telemetría de rede non é unha copia do tráfico que se poida usar para a recollida de probas; é necesaria para unha detección e toma de decisións rápidas no campo da seguridade da información. Por outra banda, mediante a análise de telemetría, non tes que "rexistrar" todo o tráfico de rede (Cisco encárgase disto cos centros de datos, por certo :-), senón só o que está implicado no ataque. As ferramentas de análise de telemetría complementan os mecanismos tradicionais de captura de paquetes neste sentido, permitindo a captura e o almacenamento selectivos. En caso contrario, terás que manter unha infraestrutura de almacenamento masiva.
Imaxinemos unha rede que funciona a 250 Mbps. Se quixeses almacenar todo este volume, necesitarías 31 MB de almacenamento para un segundo de tráfico, 1,8 GB para un minuto, 108 GB para unha hora e 2,6 TB para un día. Para almacenar os datos dun día dunha rede cun rendemento de 10 Gbps, necesitarías 108 TB de almacenamento. Algúns reguladores esixen almacenar datos de seguridade durante anos... A gravación baixo demanda, que a análise de fluxo che axuda a implementar, pode reducir estes valores en ordes de magnitude. Por certo, a proporción de datos de telemetría de rede gravados e captura completa de datos é de aproximadamente 1 a 500. Usando os mesmos valores anteriores, almacenar unha transcrición completa de todo o tráfico diario requiriría 5 GB e 216 GB, respectivamente (ata podería almacenarse nunha unidade flash normal).
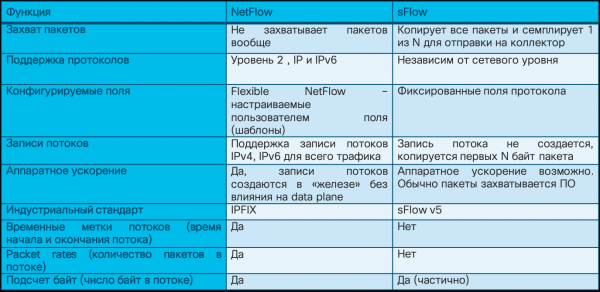
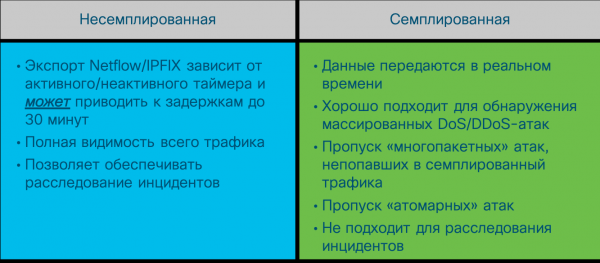
Aínda que as ferramentas de análise de datos de rede brutos empregan métodos de captura similares en todos os provedores, a análise de fluxo é unha cuestión diferente. Existen varias variantes do protocolo de fluxo e é importante comprender as diferenzas neste sentido, especialmente no contexto da seguridade. A máis popular é o protocolo Netflow, desenvolvido por Cisco. Existen varias versións deste protocolo, que difiren nas súas capacidades e na cantidade de información de tráfico rexistrada. A versión actual é a versión 9 (Netflow v9), que serviu como base para o estándar da industria Netflow v10, tamén coñecido como IPFIX. Hoxe en día, a maioría dos provedores de redes admiten Netflow ou IPFIX nos seus equipos. Non obstante, tamén existen outras variantes do protocolo de fluxo (sFlow, jFlow, cFlow, rFlow, NetStream, etc.), das cales sFlow é a máis popular. A miúdo é compatible cos fabricantes de equipos de rede domésticos debido á súa facilidade de implementación. Cales son as principais diferenzas entre Netflow, que se converteu no estándar de facto, e sFlow? Destacaría algunhas clave. En primeiro lugar, Netflow ten campos configurables polo usuario, a diferenza dos campos fixos de sFlow. En segundo lugar, e no noso caso o máis importante, sFlow recompila a chamada telemetría mostreada, a diferenza da telemetría non mostreada de Netflow e IPFIX. Cal é a diferenza entre elas?
Imaxina que decidiches ler o libro "" polos meus compañeiros Gary McIntyre, Joseph Muniz e Nadem Alfardan (podes descargar unha parte do libro na ligazón). Tes tres opcións para acadar este obxectivo: ler o libro enteiro, botarlle unha ollada, parar en cada páxina 10 ou 20 ou tentar atopar un resumo dos conceptos clave nun blog ou servizo como SmartReading. Polo tanto, a telemetría non mostreada consiste en ler cada "páxina" do tráfico de rede, é dicir, analizar os metadatos de cada paquete. A telemetría mostreada estuda selectivamente o tráfico coa esperanza de que as mostras seleccionadas produzan o que necesitas. Dependendo da velocidade da ligazón, a telemetría mostreada proporcionará cada paquete número 64, 200, 500, 1000, 2000 ou incluso 10000 para a súa análise.

No contexto da monitorización da seguridade da información, isto significa que a telemetría mostreada é axeitada para detectar ataques DDoS, análises e propagación de software malicioso, pero pode pasar por alto ataques atómicos ou multipaquete que non se inclúen na mostra enviada para a análise. A telemetría non mostreada non ten estes inconvenientes e permite unha gama moito máis ampla de ataques detectables. Aquí tes unha breve lista de eventos que se poden detectar mediante ferramentas de análise de telemetría de rede.
Por suposto, un analizador Netflow de código aberto non che permitirá facer isto, xa que o seu propósito principal é recompilar telemetría e realizar análises informáticas básicas. Para detectar ameazas á seguridade da información mediante análises baseadas en fluxos, o analizador debe estar equipado con varios motores e algoritmos que logo usarán campos Netflow estándar ou personalizados para identificar problemas de ciberseguridade, enriquecer os datos estándar con datos externos de diversas fontes de intelixencia de ameazas, etc.
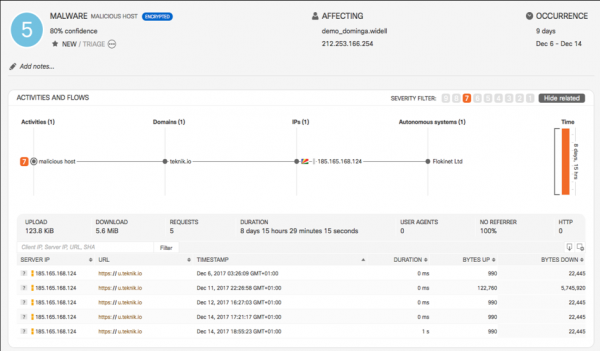
Polo tanto, se tes a opción de elixir, escolle Netflow ou IPFIX. Pero mesmo se o teu equipo só admite sFlow, como é o caso dos fabricantes nacionais, aínda podes beneficiarte del en termos de seguridade.
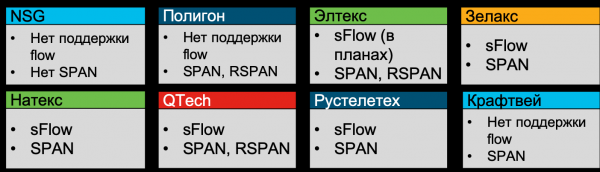
No verán de 2019, analicei as capacidades dos fabricantes rusos de hardware de rede e todos eles, coa excepción de NSG, Polygon e Kraftway, declararon soporte para sFlow (polo menos Zelax, Natex, Eltex, QTech e Rusteletech).
A seguinte pregunta á que te enfrontarás é onde implementar o soporte de fluxo para fins de seguridade. De feito, esa non é a pregunta correcta. Os equipos modernos case sempre admiten protocolos de fluxo. Polo tanto, reformularía a pregunta: onde é máis eficaz recompilar telemetría desde unha perspectiva de seguridade? A resposta é bastante obvia: no nivel de acceso, onde verás o 100 % de todo o tráfico, onde terás información detallada do host (MAC, VLAN, ID de interface) e onde incluso podes monitorizar o tráfico P2P entre hosts, o cal é fundamental para detectar análises e propagar software malicioso. No nivel central, pode que simplemente perdas algo de tráfico, mentres que no nivel perimetral, verás quizais unha cuarta parte de todo o tráfico da túa rede. Pero se por algún motivo tes dispositivos alleos na túa rede que permiten aos atacantes "entrar e saír" sen atravesar o perímetro, analizar a telemetría deles non dará ningún resultado. Polo tanto, para unha cobertura máxima, recoméndase activar a recompilación de telemetría no nivel de acceso. Cómpre sinalar que mesmo cando se fala de virtualización ou contedores, os conmutadores virtuais modernos tamén adoitan admitir fluxo, o que tamén permite o control do tráfico alí.
Pero xa que mencionei o tema, preciso responder á pregunta: que pasa se o equipo, xa sexa físico ou virtual, non admite protocolos de fluxo? Ou está prohibido activalo (por exemplo, en entornos industriais para garantir a fiabilidade)? Ou activalo supón unha carga elevada da CPU (o que pode ocorrer en equipos máis antigos)? Para resolver este problema, existen sensores de fluxo virtual especializados, que son esencialmente divisores sinxelos que pasan o tráfico e o transmiten como un fluxo ao módulo de recollida. Non obstante, neste caso, atopámonos coa mesma serie de problemas mencionados anteriormente en relación coas ferramentas de captura de paquetes. Isto significa que debemos comprender non só as vantaxes da tecnoloxía de análise de fluxo, senón tamén as súas limitacións.
Outro punto importante a lembrar ao falar de ferramentas de análise de fluxo. Aínda que usamos a métrica EPS (evento por segundo) para as ferramentas convencionais de xeración de eventos de seguridade, esta métrica non é aplicable á análise de telemetría; é substituída por FPS (fluxo por segundo). Do mesmo xeito que co EPS, non se pode calcular con antelación, pero é posible estimar o número aproximado de fluxos xerados por un dispositivo determinado dependendo da súa tarefa. Podes atopar táboas en liña con valores aproximados para diferentes tipos de dispositivos e condicións corporativas, o que che permitirá estimar que licenzas necesitas para as ferramentas de análise e cal será a súa arquitectura. O certo é que, do mesmo xeito que un sensor IDS está limitado polo ancho de banda que pode manexar, un colector de fluxo tamén ten as súas propias limitacións que deben ser comprendidas. Polo tanto, en redes grandes e distribuídas xeograficamente, adoita haber varios colectores. Cando describín... , xa dei o número dos nosos recolectores (hai 21). E isto é para unha rede espallada por cinco continentes e que conta con arredor de medio millón de dispositivos activos).
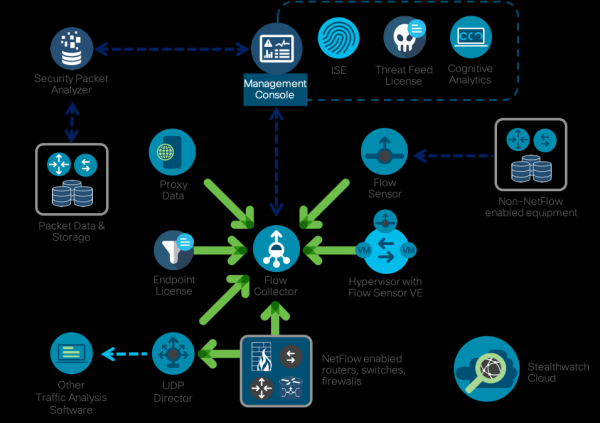
Usamos a nosa propia solución como sistema de monitorización de Netflow. , que se centra especificamente en solucións de seguridade. Ten varios motores integrados para detectar actividades anómalas, sospeitosas e directamente maliciosas, o que lle permite detectar unha ampla gama de ameazas, desde a criptominería ata as filtracións de datos, desde a distribución de software malicioso ata a fraude. Como a maioría dos analizadores de fluxo, Stealthwatch está construído sobre unha arquitectura de tres niveis (xerador, colector, analizador), pero ten unha serie de características interesantes que son importantes para o contexto deste artigo. En primeiro lugar, intégrase con solucións de captura de paquetes (como Cisco Security Packet Analyzer), o que permite rexistrar sesións de rede seleccionadas para unha investigación e análise máis exhaustivas. En segundo lugar, para abordar as necesidades de seguridade, desenvolvemos un protocolo especializado, nvzFlow, que permite "transmitir" a actividade das aplicacións en puntos finais (servidores, estacións de traballo, etc.) en telemetría e transmitila a un colector para unha análise máis profunda. Aínda que Stealthwatch funciona de forma nativa con calquera protocolo de fluxo (sFlow, rFlow, Netflow, IPFIX, cFlow, jFlow, NetStream) a nivel de rede, a compatibilidade con nvzFlow permite a correlación de datos a nivel de nodo, o que aumenta a eficiencia de todo o sistema e detecta máis ataques que os analizadores de fluxo de rede estándar.
Claramente, no que respecta aos sistemas de análise de fluxo de rede desde unha perspectiva de seguridade, o mercado non se limita a unha única solución de Cisco. Podes usar solucións comerciais, gratuítas ou de shareware. Sería estraño que citase as solucións da competencia como exemplos nun blog de Cisco, polo que direi unhas palabras sobre como se pode analizar a telemetría de rede usando dúas ferramentas populares, de nomes similares pero distintas: SiLK e ELK.
SiLK (System for Internet-Level Knowledge) é un conxunto de ferramentas de análise de tráfico desenvolvido polo CERT/CC estadounidense. No contexto do artigo de hoxe, é compatible con Netflow (versións 5 e 9, as máis populares), IPFIX e sFlow. Mediante varias utilidades (rwfilter, rwcount, rwflowpack, etc.), pode realizar diversas operacións na telemetría da rede para detectar signos de actividade non autorizada. Non obstante, cómpre ter en conta un par de puntos importantes. SiLK é unha ferramenta de liña de comandos e, para realizar unha análise operativa, sempre se introduce un comando como este (detección de paquetes ICMP de máis de 200 bytes):
rwfilter --flowtypes=all/all --proto=1 --bytes-per-packet=200- --pass=stdout | rwrwcut --fields=sIP,dIP,iType,iCode --num-recs=15
Non é moi cómodo. Podes usar a interface gráfica de iSiLK, pero non che facilitará moito a vida, xa que só serve como unha solución de visualización en lugar de substituír o analista. E ese é o segundo punto. A diferenza das solucións comerciais, que xa teñen unha base analítica sólida, algoritmos de detección de anomalías, fluxos de traballo correspondentes, etc., con SiLK tes que facer todo isto ti mesmo, o que require competencias lixeiramente diferentes ás de usar unha ferramenta lista para usar. Isto non é nin bo nin malo: é unha característica de case calquera ferramenta gratuíta, que asume que sabes o que estás facendo e só che axudará a facelo (as ferramentas comerciais dependen menos das competencias dos seus usuarios, aínda que tamén asumen que os analistas entenden polo menos os conceptos básicos das investigacións e monitorización de redes). Pero volvamos a SiLK. O fluxo de traballo dun analista con el é así:
- Formulación dunha hipótese. Debemos entender o que buscaremos na telemetría de rede e coñecer os atributos únicos polos que identificaremos certas anomalías ou ameazas.
- Construíndo un modelo. Despois de formular unha hipótese, programámola usando o mesmo Python, unha shell ou outras ferramentas non incluídas en SiLK.
- Probas. Agora é o momento de verificar a corrección da nosa hipótese, que se confirma ou refuta usando as utilidades SiLK que comezan por 'rw', 'set' e 'bag'.
- Análise de datos do mundo real. No uso industrial, SiLK axúdanos a identificar problemas específicos e o analista debe responder a preguntas como: "Atopamos o que esperabamos?", "Coincide isto coa nosa hipótese?", "Como podemos reducir os falsos positivos?", "Como podemos mellorar o recoñecemento?", etc.
- Mellora. Na fase final, refinamos o que fixemos ata o de agora: crear modelos, mellorar e optimizar o código, reformular e refinar a hipótese, etc.
Este ciclo tamén se aplicará a Cisco Stealthwatch, pero este último automatiza estes cinco pasos tanto como sexa posible, reducindo os erros dos analistas e aumentando a velocidade de detección de incidentes. Por exemplo, en SiLK, pódense enriquecer as estatísticas da rede con datos externos sobre IP maliciosas mediante scripts personalizados, mentres que en Cisco Stealthwatch, esta función integrada mostra inmediatamente unha alerta se o tráfico da rede atopa interaccións con enderezos IP da lista negra.
Subindo na pirámide "de pago" do software de análise de fluxo, o SiLK, completamente gratuíto, é seguido polo ELK, relativamente gratuíto, que consta de tres compoñentes clave: Elasticsearch (indexación, busca e análise de datos), Logstash (entrada/saída de datos) e Kibana (visualización). A diferenza de SiLK, onde tes que codificar todo ti mesmo, ELK ten moitas bibliotecas e módulos predefinidos (algúns de pago, outros gratuítos) que automatizan a análise de telemetría de rede. Por exemplo, o filtro GeoIP en Logstash permíteche asociar os enderezos IP monitorizados coa súa localización xeográfica (Stealthwatch ten esta función integrada).
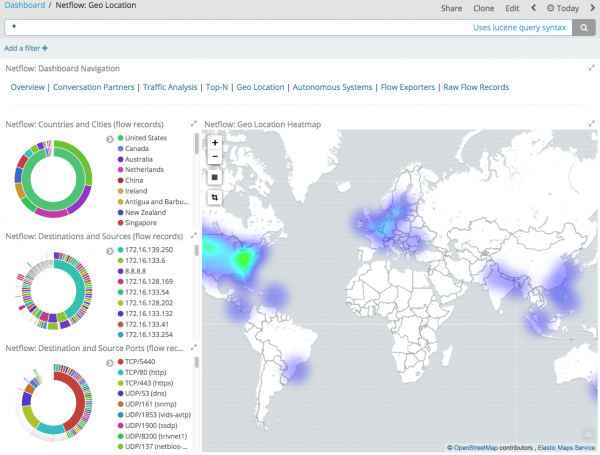
ELK tamén ten unha comunidade bastante grande que contribúe con compoñentes que faltan a esta solución de monitorización. Por exemplo, para traballar con Netflow, IPFIX e sFlow, podes usar o módulo , se non estás satisfeito co módulo Netflow de Logstash, que só é compatible con Netflow.
Aínda que ELK ofrece unha maior eficiencia na recollida e busca de fluxos, actualmente carece de análises integradas ricas para detectar anomalías e ameazas na telemetría de rede. Isto significa que, seguindo o ciclo de vida descrito anteriormente, terás que describir manualmente os patróns de violación e logo usalos no sistema de produción (non hai modelos integrados).
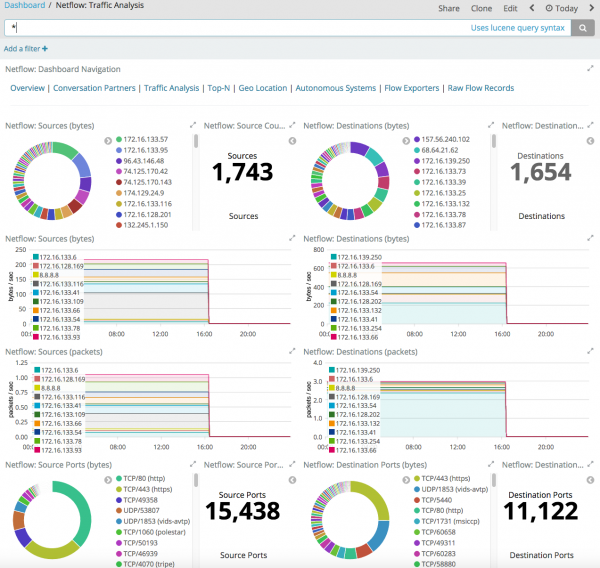
Por suposto, existen extensións máis sofisticadas para ELK que xa inclúen algúns modelos para detectar anomalías na telemetría de rede, pero tales extensións custan diñeiro e a pregunta entón é se paga a pena o esforzo: escribir un modelo similar vostede mesmo, mercar a súa implementación para a súa ferramenta de monitorización ou mercar unha solución de análise de tráfico de rede xa preparada.
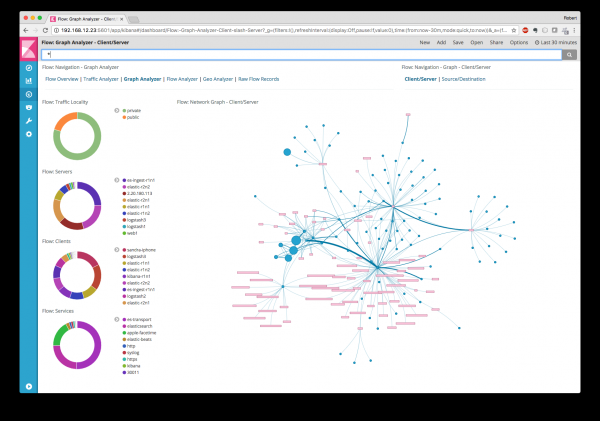
Non quero entrar nun debate sobre se é mellor gastar cartos e mercar unha solución xa feita para monitorizar anomalías e ameazas na telemetría de rede (por exemplo, Cisco Stealthwatch) ou descubrilo vostede mesmo e axustar as mesmas ferramentas SiLK, ELK, nfdump ou OSU Flow Tools para cada nova ameaza (estou a falar das dúas últimas). (A última vez)? Cada quen escolle o que quere e cada quen ten as súas propias razóns para escoller calquera das opcións. Simplemente quería demostrar que a telemetría de rede é unha ferramenta crucial para garantir a seguridade da rede da túa infraestrutura interna e que non se debe descoidar, para non acabar uníndose á lista de empresas cuxos nomes se mencionan nos medios xunto cos epítetos "pirateadas", "que non cumpren cos requisitos de seguridade da información" e "sen preocupación pola seguridade dos seus propios datos e os dos seus clientes".
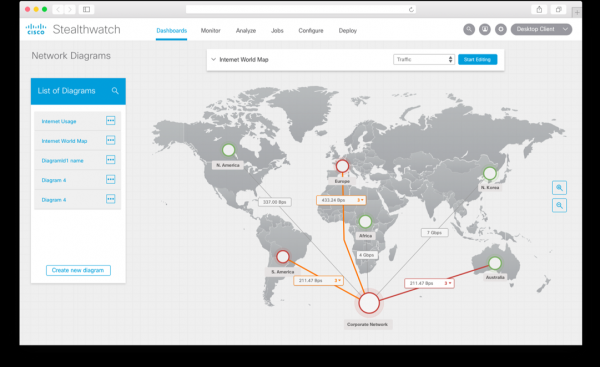
En resumo, gustaríame enumerar os consellos clave a seguir ao crear a monitorización da seguridade da información para a túa infraestrutura interna:
- Non te limites ao perímetro! Usa (e escolle) a túa infraestrutura de rede non só para mover o tráfico do punto A ao punto B, senón tamén para abordar problemas de ciberseguridade.
- Revise os mecanismos de monitorización da seguridade da información existentes nos seus equipos de rede e impleménteos.
- Para a monitorización interna, prioriza a análise de telemetría: permite detectar ata o 80-90 % de todos os incidentes de seguridade da información da rede, conseguindo o que a captura de paquetes de rede non pode e aforrando espazo de almacenamento para todos os eventos de seguridade da información.
- Para monitorizar fluxos, use Netflow v9 ou IPFIX: proporcionan máis información no contexto da seguridade e permiten monitorizar non só IPv4, senón tamén IPv6, MPLS, etc.
- Usa un protocolo de fluxo non mostreado: proporciona máis información para a detección de ameazas. Por exemplo, Netflow ou IPFIX.
- Comproba a carga do teu equipo de rede; pode que non sexa capaz de xestionar o protocolo de fluxo tan ben. Nese caso, considera o uso de sensores virtuais ou un dispositivo de xeración Netflow.
- Implementa o control principalmente a nivel de acceso: isto che dará a capacidade de ver o 100 % de todo o tráfico.
- Se non tes outra opción e estás a usar equipos de rede rusos, escolle un que admita protocolos de fluxo ou que teña portos SPAN/RSPAN.
- Combinar sistemas de detección/prevención de intrusións nas fronteiras e sistemas de análise de fluxo na rede interna (incluída a nube).
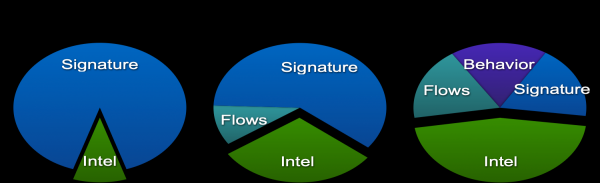
En canto ao último consello, gustaríame ilustrar algo que xa mencionei. Como se pode ver, mentres que o equipo de seguridade da información de Cisco construía anteriormente o seu sistema de monitorización da seguridade da información case na súa totalidade sobre sistemas de detección de intrusións e métodos baseados en sinaturas, agora estes só representan o 20 % dos incidentes. O outro 20 % corresponde a sistemas de análise de fluxo, o que indica que estas solucións non son unha moda, senón unha ferramenta real para os equipos de seguridade da información das empresas modernas. Ademais, tedes o máis importante para a súa implementación: a infraestrutura de rede, cuxos investimentos poden protexerse aínda máis engadindo funcións de monitorización da seguridade da información á rede.
Evitei deliberadamente falar das respostas a anomalías ou ameazas detectadas nos fluxos de rede, pero creo que está claro que a monitorización non debería rematar só coa detección de ameazas. Debería ir seguida dunha resposta, preferiblemente automatizada ou automatizada. Pero ese é tema para outro artigo.
Máis información:
P.D. Se che resulta máis doado entender de oído todo o que está escrito anteriormente, podes ver a presentación dunha hora de duración que serviu de base para este artigo.

Fonte: www.habr.com
