

Neste artigo, preséntovos os meus pensamentos sobre a historia e as perspectivas do desenvolvemento de Internet, as redes centralizadas e descentralizadas e, como resultado, a posible arquitectura da rede descentralizada de próxima xeración.
Hai algo mal en internet
Coñecín Internet por primeira vez no ano 2000. Por suposto, isto está lonxe do comezo: a Rede xa existía antes, pero ese tempo pódese chamar o primeiro momento de esplendor de Internet. A World Wide Web é a enxeñosa invención de Tim Berners-Lee, web1.0 na súa clásica forma canónica. Moitos sitios e páxinas enlazan entre si con hipervínculos. A primeira vista, a arquitectura é sinxela, como todas as cousas enxeñosas: descentralizado e gratuíto. Quero: viaxo a sitios doutras persoas seguindo hipervínculos; Quero - creo o meu propio sitio web no que publico o que me interesa - por exemplo, os meus artigos, fotografías, programas, hipervínculos a sitios que me interesan. E outros publican ligazóns para min.
Parecería unha imaxe idílica? Pero xa sabes como rematou todo.
Hai demasiadas páxinas, e buscar información converteuse nunha tarefa moi pouco trivial. Os hipervínculos prescritos polos autores simplemente non podían estruturar esta enorme cantidade de información. Primeiro houbo directorios cubertos manualmente, e despois motores de busca xigantes que comezaron a usar enxeñosos algoritmos de clasificación heurística. Creáronse e abandonáronse sitios web, duplicouse e distorsionouse a información. Internet foi rapidamente comercializando e afastándose máis da rede académica ideal. A linguaxe de marcas converteuse rapidamente nunha linguaxe de formato. Apareceu publicidade, banners molestos desagradables e unha tecnoloxía para promover e enganar os buscadores: o SEO. A rede axiña estaba atascada con lixo de información. Os hipervínculos deixaron de ser unha ferramenta de comunicación lóxica e convertéronse nunha ferramenta de promoción. Os sitios web pecháronse en si mesmos, pasaron de "páxinas" abertas a "aplicacións" seladas e convertéronse en só medios para xerar ingresos.
Mesmo entón tiven un certo pensamento de que "algo anda mal aquí". Unha morea de sitios diferentes, que van desde páxinas de inicio primitivas cunha aparencia de ollos saltones ata "megaportais" sobrecargados con banners intermitentes. Aínda que os sitios estean sobre o mesmo tema, non están relacionados en absoluto, cada un ten o seu propio deseño, a súa propia estrutura, banners molestos, busca mal funcionamento, problemas coa descarga (si, quería ter información fóra de liña). Mesmo entón, Internet comezaba a converterse nunha especie de televisión, onde todo tipo de guirnaldas estaban cravadas en contido útil.
A descentralización converteuse nun pesadelo.
Que queres?
É paradoxal, pero aínda así, sen saber aínda de web 2.0 ou p2p, eu, como usuario, non necesitaba descentralización! Recordando os meus pensamentos sen nubes daqueles tempos, chego á conclusión de que necesitaba... base de datos única! Tal consulta para a cal devolvería todos os resultados, e non os que son máis axeitados para o algoritmo de clasificación. Un no que todos estes resultados serían deseñados uniformemente e estilizados polo meu propio deseño uniforme, e non polos deseños propios de numerosos Vasya Pupkins. Un que podería gardarse fóra de liña e que non teña medo de que mañá o sitio desapareza e a información se perda para sempre. Unha na que puidese introducir a miña información, como comentarios e etiquetas. Un no que puiden buscar, ordenar e filtrar cos meus propios algoritmos persoais.
Web 2.0 e redes sociais
Mentres tanto, o concepto da Web 2.0 entrou na area. Formulada en 2005 por Tim O'Reilly como "unha técnica para deseñar sistemas que, tendo en conta as interaccións da rede, melloran canto máis persoas os usan" -e que implica a implicación activa dos usuarios na creación e edición colectiva de contidos Web. Sen esaxeración, o cumio e o triunfo deste concepto foron as Redes Sociais. Plataformas xigantes que conectan millóns de usuarios e almacenan centos de petabytes de datos.
Que conseguimos nas redes sociais?
- unificación de interfaces; Resultou que os usuarios non necesitan todas as oportunidades para crear unha variedade de deseños atractivos; todas as páxinas de todos os usuarios teñen o mesmo deseño e isto convén a todos e mesmo é cómodo; Só o contido é diferente.
- unificación de funcionalidades; toda a variedade de guións resultou innecesaria. "Feed", amigos, álbums... durante a existencia das redes sociais, a súa funcionalidade estabilizouse máis ou menos e é improbable que cambie: despois de todo, a funcionalidade está determinada polo tipo de actividades das persoas e a xente practicamente non cambia. .
- base de datos única; resultou moito máis cómodo traballar con tal base de datos que con moitos sitios dispares; a busca fíxose moito máis fácil. En lugar de escanear continuamente unha variedade de páxinas pouco relacionadas, almacenalo todo na caché, clasificando mediante algoritmos heurísticos complexos: unha consulta unificada relativamente sinxela a unha única base de datos cunha estrutura coñecida.
- interface de comentarios: gústame e reposta; na web normal, o mesmo Google non puido recibir comentarios dos usuarios despois de seguir unha ligazón nos resultados da busca. Nas redes sociais esta conexión resultou sinxela e natural.
Que perdemos? Perdemos a descentralización, que significa liberdade. Crese que os nosos datos agora non nos pertencen. Se antes podíamos colocar unha páxina de inicio mesmo no noso propio ordenador, agora dámoslle todos os nosos datos a xigantes de Internet.
Ademais, a medida que Internet se desenvolveu, gobernos e corporacións interesáronse por ela, o que provocou problemas de censura política e restricións de dereitos de autor. As nosas páxinas nas redes sociais poden ser prohibidas e eliminadas se o contido non cumpre con ningunha das regras da rede social; por un posto descoidado - levar a responsabilidade administrativa e mesmo penal.
E agora volvemos a pensar: non deberíamos devolver a descentralización? Pero nunha forma diferente, carente das deficiencias do primeiro intento?
Redes peer-to-peer
As primeiras redes p2p apareceron moito antes da web 2.0 e desenvolvéronse paralelamente ao desenvolvemento da web. A principal aplicación clásica de p2p é compartir ficheiros; desenvolvéronse as primeiras redes para o intercambio de música. As primeiras redes (como Napster) estaban esencialmente centralizadas e, polo tanto, foron pechadas rapidamente polos posuidores dos dereitos de autor. Os seguidores seguiron o camiño da descentralización. En 2000, apareceron os protocolos ED2K (o primeiro cliente eDokney) e Gnutella, en 2001: o protocolo FastTrack (cliente KaZaA). Pouco a pouco, o grao de descentralización aumentou, as tecnoloxías melloraron. Os sistemas de "cola de descarga" foron substituídos por torrents e apareceu o concepto de táboas hash distribuídas DHT. A medida que os estados apertan os parafusos, o anonimato dos participantes fíxose máis demandado. A rede Freenet desenvolveuse desde 2000, I2003P desde 2 e o proxecto RetroShare lanzouse en 2006. Podemos mencionar numerosas redes p2p, tanto existentes como xa desaparecidas, e actualmente en funcionamento: WASTE, MUTE, TurtleF2F, RShare, PerfectDark, ARES, Gnutella2, GNUNet, IPFS, ZeroNet, Tribbler e moitas outras. Moitos deles. Son diferentes. Moi diferentes, tanto no propósito como no deseño... Probablemente moitos de vostedes nin sequera estean familiarizados con todos estes nomes. E isto non é todo.
Non obstante, as redes p2p teñen moitas desvantaxes. Ademais das deficiencias técnicas inherentes a cada protocolo específico e implementación do cliente, podemos, por exemplo, observar unha desvantaxe bastante xeral: a complexidade da busca (é dicir, todo o que atopou a Web 1.0, pero nunha versión aínda máis complexa). Non hai Google aquí coa súa busca omnipresente e instantánea. E se para redes de intercambio de ficheiros aínda podes usar unha busca por nome de ficheiro ou metainformación, entón atopar algo, por exemplo, en redes de superposición de cebola ou i2p é moi difícil, se non imposible.
En xeral, se trazamos analoxías coa Internet clásica, a maioría das redes descentralizadas están atrapadas nalgún lugar a nivel FTP. Imaxina unha Internet na que non haxa máis que FTP: nin sitios modernos, nin web2.0, nin Youtube... Este é aproximadamente o estado das redes descentralizadas. E a pesar dos intentos individuais de cambiar algo, hai poucos cambios ata agora.
Contido
Pasemos a outra peza importante deste puzzle: o contido. O contido é o principal problema de calquera recurso de Internet, e especialmente un descentralizado. De onde conseguilo? Por suposto, podes confiar nun puñado de entusiastas (como ocorre coas redes p2p existentes), pero entón o desenvolvemento da rede será bastante longo e haberá pouco contido alí.
Traballar con Internet normal significa buscar e estudar contido. Ás veces, gardando (se o contido é interesante e útil, moitos, sobre todo os que chegaron a Internet nos días de acceso telefónico, incluído eu, gárdano con prudencia sen conexión para non perderse; porque Internet é unha cousa). fóra do noso control, hoxe o sitio está aí mañá non hai , hoxe hai un vídeo en YouTube, mañá borrarase, etc.
E para os torrents (que percibimos máis como un medio de entrega que como unha rede p2p), o aforro é xeralmente implícito. E este, por certo, é un dos problemas dos torrents: un ficheiro descargado unha vez é difícil de mover a onde sexa máis cómodo de usar (por regra xeral, cómpre rexenerar manualmente a distribución) e absolutamente non se pode renomear ( podes vinculalo duro, pero moi pouca xente sabe disto).
En xeral, moitas persoas gardan contido dun xeito ou doutro. Cal é o seu destino futuro? Normalmente, os ficheiros gardados acaban nalgún lugar do disco, nun cartafol como Descargas, no montón xeral e atópanse alí xunto con outros miles de ficheiros. Isto é malo - e malo para o propio usuario. Se Internet ten motores de busca, entón a computadora local do usuario non ten nada semellante. É bo se o usuario está ordenado e está afeito a ordenar os ficheiros descargados "entrantes". Pero non todos son así...
De feito, agora son moitos os que non gardan nada, pero confían enteiramente na rede. Pero nas redes p2p, asúmese que o contido se almacena localmente no dispositivo do usuario e distribúese a outros participantes. É posible atopar unha solución que permita que ambas categorías de usuarios se impliquen nunha rede descentralizada sen cambiar os seus hábitos e, ademais, facilitándolles a vida?
A idea é ben sinxela: e se facemos un medio de gardar contido da Internet normal, cómodo e transparente para o usuario, e gardar intelixentemente - con metainformación semántica, e non nun montón común, senón nunha estrutura específica con a posibilidade de estruturar máis, e ao mesmo tempo distribuír o contido gardado nunha rede descentralizada?
Comecemos por gardar
Non teremos en conta o uso utilitario de Internet para ver as previsións meteorolóxicas ou os horarios de avións. Interésanos máis os obxectos autosuficientes e máis ou menos inmutables: artigos (desde chíos/publicacións de redes sociais ata artigos grandes, como aquí en Habré), libros, imaxes, programas, gravacións de audio e vídeo. De onde vén principalmente a información? Normalmente isto
- redes sociais (varias noticias, pequenas notas - "tweets", imaxes, audio e vídeo)
- artigos sobre recursos temáticos (como Habr); Non hai moitos bos recursos, normalmente estes recursos tamén se constrúen no principio das redes sociais
- sitios de noticias
Como regra xeral, hai funcións estándar: "gústame", "republicar", "compartir en redes sociais", etc.
Imaxinemos algúns complemento do navegador, que gardará especialmente todo o que nos gustou, volvemos publicar, gardar nos "favoritos" (ou facer clic nun botón de complemento especial que aparece no menú do navegador - no caso de que o sitio non teña unha función de "gústame/repost/marcador"). A idea principal é que simplemente che guste, como xa fixeches un millón de veces antes, e o sistema garda o artigo, a imaxe ou o vídeo nun almacenamento especial sen conexión e este artigo ou imaxe estará dispoñible para ti para ver sen conexión a través do interface de cliente descentralizada, e na rede máis descentralizada! Na miña opinión, é moi cómodo. Non hai accións innecesarias e resolvemos moitos problemas á vez:
- Conservando contido valioso que se pode perder ou eliminar
- recheo rápido da rede descentralizada
- agregación de contidos de diferentes fontes (podes rexistrarte en decenas de recursos de Internet e todos os Gústame/republicacións pasarán a unha única base de datos local)
- estruturando contidos que che interesen segundo o teu as regras
Obviamente, o complemento do navegador debe configurarse para a estrutura de cada sitio (isto é bastante realista: xa hai complementos para gardar contido de Youtube, Twitter, VK, etc.). Non hai tantos sitios para os que teña sentido facer complementos persoais. Por regra xeral, trátase de redes sociais comúns (apenas hai máis dunha ducia delas) e dunha serie de sitios temáticos de alta calidade como Habr (tamén hai algúns destes). Co código e especificacións de fonte aberta, desenvolver un novo complemento baseado nun modelo non debería levar moito tempo. Para outros sitios, pode usar un botón de gardar universal, que gardaría a páxina enteira en mhtml, quizais despois de limpar a páxina de publicidade.
Agora sobre a estruturación
Por gardar "intelixente" refírome, polo menos, a gardar con metainformación: a fonte do contido (URL), un conxunto de "gústame", etiquetas, comentarios, os seus identificadores, etc. Despois de todo, durante o gardado normal, esta información pérdese... A fonte pódese entender non só como un URL directo, senón tamén como un compoñente semántico: por exemplo, un grupo nunha rede social ou un usuario que fixo unha republicación. O complemento pode ser o suficientemente intelixente como para usar esta información para a estruturación e etiquetado automáticos. Ademais, debe entenderse que o propio usuario sempre pode engadir algunha metainformación ao contido gardado, para o que deberían proporcionarse as ferramentas de interface máis convenientes (teño bastantes ideas sobre como facelo).
Así, resólvese o problema de estruturar e organizar os ficheiros locais do usuario. Este é un beneficio listo que se pode usar mesmo sen ningún p2p. Só unha especie de base de datos fóra de liña que sabe que, onde e en que contexto gardamos e que nos permite realizar pequenos estudos. Por exemplo, busca usuarios dunha rede social externa aos que máis lles gustaron as mesmas publicacións ca ti. Cantas redes sociais permiten isto de forma explícita?
Xa se debe mencionar aquí que un complemento do navegador certamente non é suficiente. O segundo compoñente máis importante do sistema é o servizo de rede descentralizada, que se executa en segundo plano e serve tanto á propia rede p2p (solicitudes da rede e solicitudes do cliente) como ao gardado de novos contidos mediante o complemento. O servizo, traballando xunto co complemento, colocará o contido no lugar correcto, calculará os hash (e posiblemente determinará que ese contido xa se gardou previamente) e engadirá a metainformación necesaria á base de datos local.
O interesante é que o sistema sería útil xa nesta forma, sen ningún p2p. Moitas persoas usan clippers web que engaden contido interesante da web a Evernote, por exemplo. A arquitectura proposta é unha versión estendida de tal clipper.
E finalmente, intercambio p2p
A mellor parte é que se pode intercambiar información e metainformación (tanto capturadas da web como das propias). O concepto de rede social transfírese perfectamente á arquitectura p2p. Podemos dicir que a rede social e o p2p parecen estar feitos un para o outro. Calquera rede descentralizada debería construírse idealmente como unha rede social, só entón funcionará de forma eficaz. "Amigos", "Grupos" - estes son os mesmos compañeiros cos que debería haber conexións estables, e estes son tomados dunha fonte natural - os intereses comúns dos usuarios.
Os principios de gardar e distribuír contido nunha rede descentralizada son completamente idénticos aos principios de gardar (capturar) contido da Internet normal. Se usas algún contido da rede (e polo tanto o gardou), calquera pode usar os teus recursos (disco e canle) necesarios para recibir este contido en particular.
Gústame — a ferramenta máis sinxela de gardar e compartir. Se me gustou, non importa na Internet externa ou dentro da rede descentralizada, significa que me gusta o contido e, se é así, estou preparado para mantelo localmente e distribuílo a outros participantes na rede descentralizada.
- O contido non se "perderá"; agora está gardado localmente, podo volver a el máis tarde, en calquera momento, sen preocuparme de que alguén o elimine ou o bloquee
- Podo (inmediatamente ou máis tarde) categorizalo, etiquetalo, comentalo, asocialo con outro contido e, en xeral, facer algo significativo con el; chamémoslle "xeración de metainformación".
- Podo compartir esta metainformación con outros membros da rede
- Podo sincronizar a miña metainformación coa metainformación doutros membros
Probablemente, renunciar ás aversións tamén parece lóxico: se non me gusta o contido, entón é bastante lóxico que non queira perder o meu espazo no disco para almacenar e a miña canle de Internet para distribuír este contido. Polo tanto, as aversións non encaixan de xeito moi orgánico na descentralización (aínda que ás veces si ).
Ás veces cómpre conservar o que "non che gusta". Hai unha palabra como "debe" :)
«Marcadores” (ou “Favoritos”): non expreso afinidade polo contido, pero gárdoo na miña base de datos de marcadores local. A palabra "favoritos" non é moi adecuada no seu significado (para iso hai "gústame" e a súa posterior categorización), pero os "marcadores" son bastante axeitados. Tamén se distribúe o contido en "marcadores": se o "necesita" (é dicir, o "utiliza" dun xeito ou doutro), entón é lóxico que outra persoa poida "necesitalo". Por que non empregar os teus recursos para facelo?
A función "друзья". Estes son os compañeiros, persoas con intereses similares e, polo tanto, os que teñen máis probabilidades de ter contido interesante. Nunha rede descentralizada, isto significa principalmente subscribirse a fontes de noticias dos amigos e acceder aos seus catálogos (álbums) de contido que gardaron.
Similar á función "grupos“- algún tipo de feeds colectivos, ou foros, ou algo así, aos que tamén podes subscribirte- e iso significa, aceptar todos os materiais do grupo e distribuílos. Quizais os "grupos", como os grandes foros, deberían ser xerárquicos; isto permitirá unha mellor estruturación do contido do grupo, así como limitar o fluxo de información e non aceptar/distribuír o que non é moi interesante para vostede.
Todo o resto
Hai que ter en conta que unha arquitectura descentralizada sempre é máis complexa que unha centralizada. Nos recursos centralizados hai un estrito ditado do código do servidor. Nos descentralizados, hai que negociar entre moitos participantes iguais. Por suposto, isto non se pode facer sen a criptografía, as cadeas de bloques e outros logros desenvolvidos principalmente en criptomoedas.
Supoño que pode ser necesaria algún tipo de clasificación criptográfica de confianza mutua formada polos participantes da rede entre si. A arquitectura debería permitir combater eficazmente as botnets que, existentes nunha determinada nube, poden, por exemplo, aumentar mutuamente as súas propias valoracións. Quero moito que as corporacións e as granxas de botnets, con toda a súa superioridade tecnolóxica, non se apoden do control dunha rede tan descentralizada; de xeito que o seu principal recurso son persoas vivas capaces de producir e estruturar contidos interesantes e útiles para outras persoas vivas.
Tamén quero que esa rede faga avanzar á civilización. Teño un montón de ideas sobre este tema, que, porén, non encaixan no ámbito deste artigo. Só direi que en certo modo científico, técnico, médico, etc. o contido debe ter prioridade sobre o entretemento, e iso requirirá algún tipo de moderación. A moderación dunha rede descentralizada en si é unha tarefa non trivial, pero pódese resolver (non obstante, a palabra "moderación" aquí é completamente incorrecta e non reflicte a esencia do proceso en absoluto, nin externa nin internamente... e Nin sequera podía pensar como se podería chamar este proceso).
Probablemente non sexa necesario mencionar a necesidade de garantir o anonimato, tanto por medios integrados (como en i2p ou Retroshare) como pasando todo o tráfico a través de TOR ou VPN.
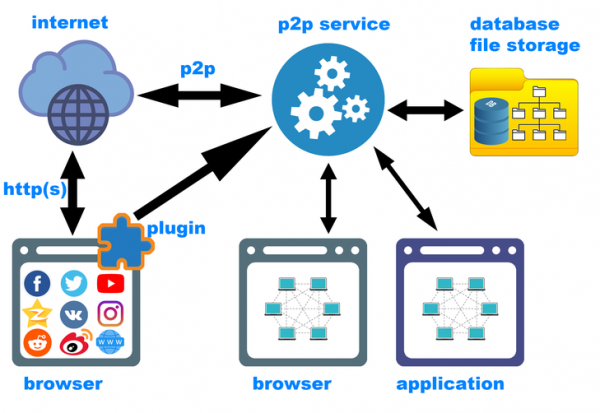
E, finalmente, a arquitectura do software (mostrada esquematicamente na imaxe que acompaña o artigo). Como xa se mencionou, o primeiro compoñente do sistema é un complemento do navegador que captura contido con metadatos. O segundo compoñente máis importante é un servizo p2p que se executa en segundo plano ("backend"). Obviamente, o funcionamento da rede non debería depender de se o navegador está a executarse ou non. O terceiro compoñente é o software cliente: o frontend. Pode ser un servizo web local (neste caso, o usuario pode interactuar coa rede descentralizada sen saír do seu navegador favorito) ou unha aplicación GUI separada para un sistema operativo específico (Windows, Linux, MacOS, Android, iOS, etc.). Gústame a idea de que todas as variantes do frontend coexistan simultaneamente. Isto tamén requirirá unha arquitectura de backend máis rigorosa.
Hai moitos máis aspectos que non están incluídos neste artigo. Conectarse á distribución de almacenamentos de ficheiros existentes (é dicir, cando xa tes un par de terabytes de datos bombeados, e deixas que o cliente os escanee, obteña hash, comparalos co que hai dentro da Rede e únete á distribución, e ao mesmo tempo). tempo obtén metainformación sobre os seus propios ficheiros: nomes normais, descricións, clasificacións, comentarios, etc.), conexión de fontes externas de metainformación (como a base de datos Libgen), uso opcional do espazo en disco para almacenar contido cifrado doutras persoas (como en Freenet). ), arquitectura de integración con redes descentralizadas existentes (este é un bosque completamente escuro), a idea do hash multimedia (o uso de hash perceptivos especiais para o contido multimedia: imaxes, audio e vídeo, que lle permitirá comparar ficheiros multimedia de o mesmo significado, diferente en tamaño, resolución, etc.) e moito máis.
Breve resumo do artigo
1. Nas redes descentralizadas non hai Google coa súa busca e clasificación, senón que hai unha Comunidade de persoas reais. Unha rede social cos seus mecanismos de retroalimentación (gústame, repostos...) e gráfica social (amigos, comunidades...) é un modelo de capa de aplicación ideal para unha rede descentralizada.
2. A idea principal que traio con este artigo é o gardado automático de contido interesante da Internet normal cando estableces un Gústame/repost; isto pode ser útil sen p2p, só manter un arquivo persoal de información interesante
3. Este contido tamén pode encher automaticamente a rede descentralizada
4. O principio de gardar automaticamente contido interesante tamén funciona con me gusta/republicacións na rede máis descentralizada
Fonte: www.habr.com
