

O canario é un paxaro pequeno que canta constantemente. Estas aves son sensibles ao metano e ao monóxido de carbono. Mesmo a partir dunha pequena concentración de exceso de gases no aire, perden o coñecemento ou morren. Os buscadores de ouro e os mineiros levaron os paxaros á mina: mentres cantan os canarios, podes traballar, se estás calado: hai gas na mina e é hora de marchar. Os mineiros sacrificaron un paxariño para saír vivo das minas.

Unha práctica semellante atopouse nas TIC. Por exemplo, na tarefa estándar de implementar unha nova versión dun servizo ou aplicación en produción con probas anteriores. O ambiente de proba pode ser demasiado caro, as probas automatizadas non cobren todo o que queres e non probar e sacrificar a calidade é arriscado. Aquí é onde resulta útil o enfoque Canary Deployment, onde parte do tráfico de produción real se dirixe cara á nova versión. O enfoque axuda con seguridade comprobar a nova versión para a produción, sacrificar un pouco por unha gran causa. Dirán máis detalles sobre como funciona o enfoque, o que é útil e como implementalo Andrei Markelov (), sobre o exemplo de implantación na empresa Infobip.
Andrei Markelov - Lead Software Engineer en Infobip, desenvolve dende hai 11 anos aplicacións Java no ámbito das finanzas e as telecomunicacións. Desenvolve produtos de código aberto, participa activamente na comunidade Atlassian e escribe complementos para produtos Atlassian. Evanxelista de Prometeo, Docker e Redis.

Sobre Infobip
É unha plataforma global de telecomunicacións que permite aos bancos, venda polo miúdo, tendas en liña e empresas de transporte enviar mensaxes aos seus clientes a través de SMS, push, cartas e mensaxes de voz. Neste negocio, a estabilidade e a fiabilidade son importantes para que os clientes reciban as mensaxes a tempo.
Infraestrutura de TI de Infobip en cifras:
- 15 centros de datos en todo o mundo;
- 500 servizos únicos en funcionamento;
- 2500 instancias de servizos, o que é moito máis que comandos;
- 4,5 TB de tráfico mensual;
- 4,5 millóns de números de teléfono;
O negocio está crecendo, e con el o número de lanzamentos. Gastamos en 60 lanzamentos por díaporque os clientes queren máis funcións e potencia. Pero isto é difícil: hai moitos servizos, pero poucos comandos. Ten que escribir rapidamente código que debería funcionar en produción sen erros.
Lanzamentos
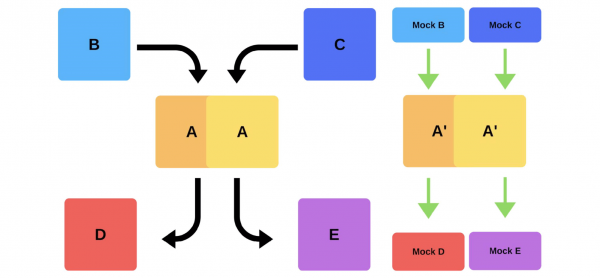
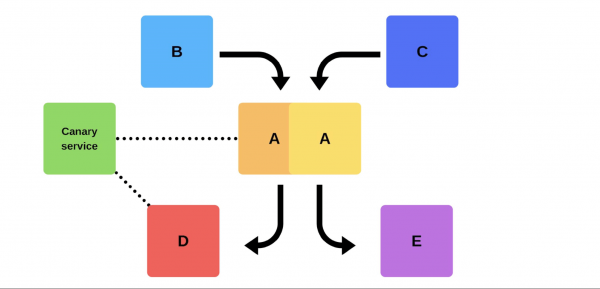
Unha versión típica é así. Por exemplo, hai servizos A, B, C, D e E, cada un deles desenvolvido por un equipo separado.
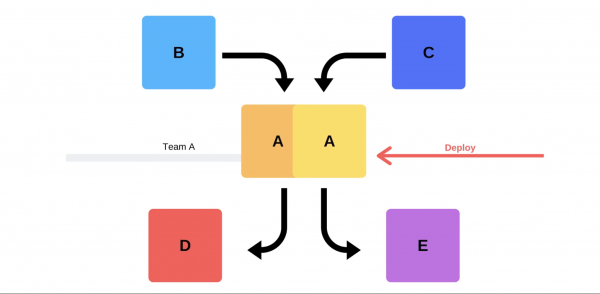
Nalgún momento, o equipo do servizo A decide despregar unha nova versión, pero os equipos dos servizos B, C, D e E non o saben. Hai dúas opcións sobre como actuará o equipo de servizo A.
Aguantará liberación incremental: primeiro substituír unha versión e despois a segunda.
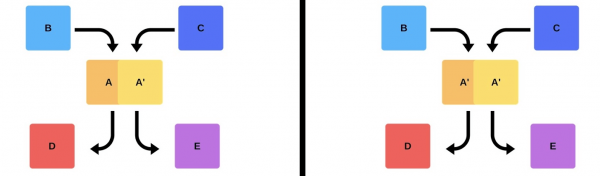
Pero hai unha segunda opción: o comando atopará capacidades e máquinas adicionais, despregue a nova versión e, a continuación, cambie o enrutador e a versión comezará a funcionar para a produción.

En calquera caso, case sempre hai problemas despois da implantación, aínda que a versión sexa probada. Podes probar manualmente, podes facelo automaticamente, non podes probar; en calquera caso, xurdirán problemas. A forma máis sinxela e correcta de resolvelos é volver á versión de traballo. Só así podes facer fronte aos danos, coas causas e corrixilas.
Entón, que queremos?
Non necesitamos problemas. Se os clientes os atopan máis rápido que nós, prexudicará a súa reputación. Polo tanto debemos atopar problemas máis rápido que os clientes. Traballando de forma proactiva, minimizamos os danos.
Ao mesmo tempo, queremos acelerar a implantaciónpara que ocorra de xeito rápido, sinxelo, natural e sen presión do equipo. Os enxeñeiros, enxeñeiros de DevOps e programadores deben estar protexidos: o lanzamento dunha nova versión é estresante. O equipo non é prescindible, esforzámonos uso racional dos recursos humanos.
Problemas de despregamento
O tráfico de clientes é imprevisible. É imposible prever cando o tráfico de clientes estará no seu nivel máis baixo. Non sabemos onde nin cando comezarán os clientes as súas campañas, quizais esta noite na India, mañá en Hong Kong. Dada a gran diferenza horaria, a implantación incluso ás 2 da mañá non garante que os clientes non se vexan afectados.
Problemas do provedor. Os mensaxeiros e provedores son os nosos socios. Ás veces teñen fallos que provocan erros durante a implantación de novas versións.
Equipos distribuídos. Os equipos que desenvolven o lado do cliente e o backend están en diferentes fusos horarios. Por iso, moitas veces non poden poñerse de acordo entre eles.
Os centros de datos non se poden repetir no escenario. Hai 200 racks nun centro de datos; nin sequera podes repetir isto nun sandbox.
Tempos de inactividadeinaceptable! Temos un Orzamento de erro cando estamos traballando o 99,99% do tempo, por exemplo, e a porcentaxe restante é "marxe de erro". Acadar o 100 % de fiabilidade é imposible, pero é importante supervisar constantemente as caídas e o tempo de inactividade.
Solucións clásicas
Escribir código sen erros. Cando era un programador novo, os xestores achegáronseme para pedirme o lanzamento sen erros, pero isto non sempre é posible.
Escribe probas. As probas funcionan, pero ás veces non como quere a empresa. Gañar cartos non é traballo das probas.
Proba no escenario. Durante 3,5 anos do meu traballo en Infobip, nunca vin que o estado do escenario coincida polo menos parcialmente coa produción.
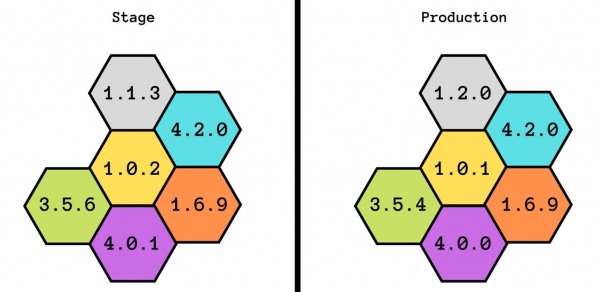
Incluso tentamos desenvolver esta idea: primeiro tivemos escenario, despois preprodución e despois preprodución. Pero isto tampouco axudou: nin sequera coincidiron no poder. Con stage, podemos garantir a funcionalidade básica, pero non sabemos como funcionará baixo cargas.
O lanzamento faise por quen o desenvolveu. Esta é unha boa práctica: aínda que alguén cambie o nome do comentario, engádeo inmediatamente á produción. Isto axuda a desenvolver a responsabilidade e non esquecer os cambios realizados.
Tamén hai complicacións adicionais. É estresante para un programador pasar moito tempo comprobando todo manualmente.
Liberacións acordadas. Esta opción adoita ofrecer a dirección: "Aceptemos que todos os días probarás e engadirás novas versións". Non funciona: sempre hai unha orde agardando por todos os demais, ou viceversa.
Probas de fume
Outra forma de resolver os nosos problemas de implantación. Considere como funcionan as probas de fume no exemplo anterior, cando o equipo A quere implementar unha nova versión.
En primeiro lugar, o equipo desprega unha instancia na produción. Mensaxes á instancia de mocks simula o tráfico realpara igualar o tráfico diario normal. Se todo está ben, o equipo cambia a nova versión ao tráfico de usuarios.
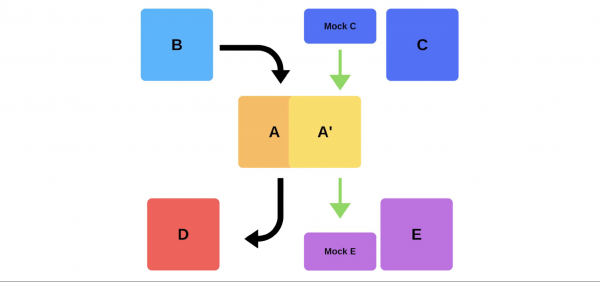
A segunda opción é implantar con ferro extra. O equipo proba para a produción, despois cambia e todo funciona.
Desvantaxes das probas de fume:
- Non se pode confiar nas probas. Onde conseguir o mesmo tráfico que para a produción? Podes usar onte ou hai unha semana, pero non sempre coincide co actual.
- Difícil de manter. Terás que manter contas de proba, restablecelas constantemente antes de cada implantación, cando se envíen rexistros activos ao repositorio. Isto é máis difícil que escribir unha proba no teu propio sandbox.
O único bono aquí é pódese comprobar o rendemento.
Lanzamentos canarios
Debido ás deficiencias das probas de fume, comezamos a usar soltas canarias.
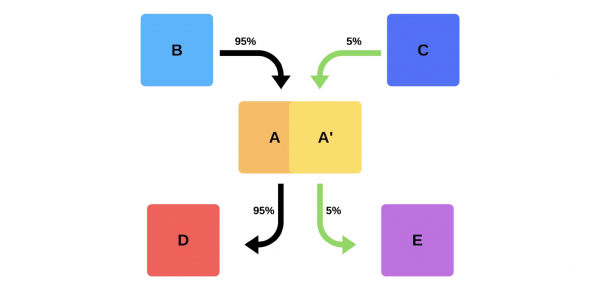
Unha práctica similar a como os mineiros usaban canarios para indicar o nivel de gases atopou o seu camiño na TI. Deixamos algo de tráfico de produción real á nova versiónmentres intenta cumprir o Acordo de Nivel de Servizo (SLA). O SLA é o noso "dereito a cometer un erro", que podemos utilizar unha vez ao ano (ou durante algún outro período de tempo). Se todo vai ben, engadiremos máis tráfico. Se non, devolveremos as versións anteriores.
Implementación e matices
Como implementamos as versións canarias? Por exemplo, un grupo de clientes envía mensaxes a través do noso servizo.
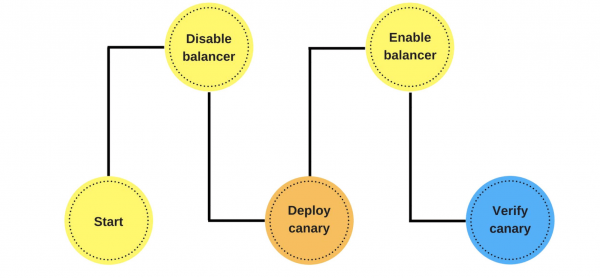
O despregue é así: eliminamos un nodo debaixo do equilibrador (1), cambiamos a versión (2) e deixamos algo de tráfico por separado (3).

En xeral, todos os membros do grupo estarán contentos, aínda que un usuario non estea satisfeito. Se todo está ben, cambiamos todas as versións.
Mostrarei de forma esquemática como se ven os microservizos na maioría dos casos.
Hai Service Discovery e dous servizos máis: S1N1 e S2. O primeiro servizo (S1N1) notifica a Service Discovery cando se inicia, e Service Discovery recórdao. O segundo servizo con dous nodos (S2N1 e S2N2) tamén notifica Service Discovery cando se inicia.
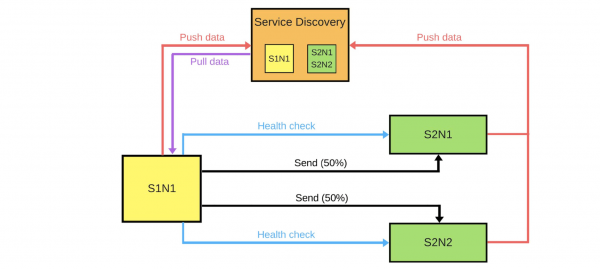
O segundo servizo para o primeiro funciona como servidor. O primeiro pídelle a Service Discovery información sobre os seus servidores e, cando a recibe, búscaos e compróbaos (“comprobación de saúde”). Cando comprobe, enviaralles mensaxes.
Cando alguén quere implantar unha nova versión do segundo servizo, di a Service Discovery que o segundo nodo será un nodo canario: enviarase menos tráfico a el, porque o despregamento terá lugar agora. Eliminamos o nodo canario debaixo do equilibrador e o primeiro servizo non lle envía tráfico.
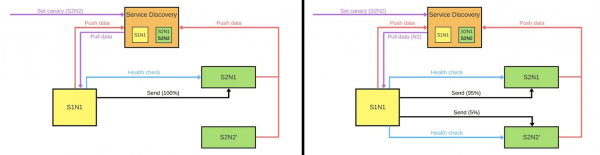
Cambiamos a versión e Service Discovery sabe que o segundo nodo agora é canario: podes darlle menos carga (5%). Se todo está ben, cambiamos a versión, devolvemos as cargas e traballamos.
Para implementar todo isto, necesitamos:
- equilibrio;
- vixilanciaporque é importante saber que espera cada usuario e como funcionan os nosos servizos en detalle;
- análise de versiónscomprender o ben que funcionará a nova versión na produción;
- automatización - escribimos a secuencia de implementación (canalización de implementación).
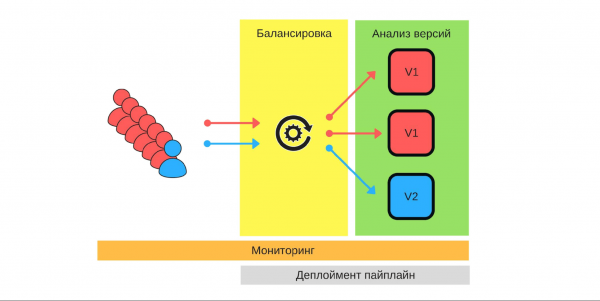
Equilibrio
Isto é o primeiro no que debemos pensar. Hai dúas estratexias de equilibrio.
A opción máis sinxela cando un nodo sempre é canario. Este nodo sempre recibe menos tráfico e desde el comezamos a implantación. En caso de problemas, compararemos o seu traballo antes do despregue e durante o mesmo. Por exemplo, se hai 2 veces máis erros, entón o dano aumentou 2 veces.
O nodo Canary establécese durante o proceso de implantación. Cando remate o despregamento e eliminemos o estado do nodo canario, restaurarase o balance de tráfico. Con menos coches conseguiremos unha distribución xusta.
Seguimento
A pedra angular dos lanzamentos canarios. Debemos entender exactamente por que facemos isto e que métricas queremos recoller.
Exemplos de métricas que recollemos dos nosos servizos.
- Número de erros, que se escriben nos rexistros. Este é un claro indicador de que todo funciona como debería. En xeral, esta é unha boa métrica.
- Tempo de execución da consulta (latencia). Todo o mundo supervisa esta métrica porque todos queren traballar rápido.
- Tamaño da cola (produción).
- Número de respostas exitosas por segundo.
- Prazo de execución do 95% de todas as solicitudes.
- Métricas de negocio: canto diñeiro gaña unha empresa nun determinado período de tempo ou caída de usuarios. Estas métricas para a nosa nova versión poden ser máis importantes que as engadidas polos enxeñeiros.
Exemplos de métricas nos sistemas de monitorización máis populares.
Contador. Este é un valor crecente, por exemplo, o número de erros. Esta métrica é fácil de interpolar e estudar o gráfico: onte houbo 2 erros e hoxe 500, o que significa que algo fallou.
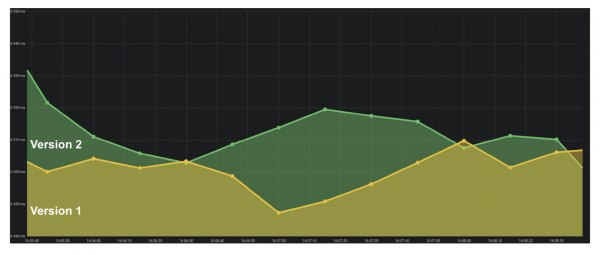
O número de erros por minuto ou por segundo é o indicador máis importante que se pode calcular usando Counter. Estes datos dan unha imaxe clara de como funciona o sistema a distancia. Considere o exemplo dun gráfico do número de erros por segundo para dúas versións do sistema de produción.
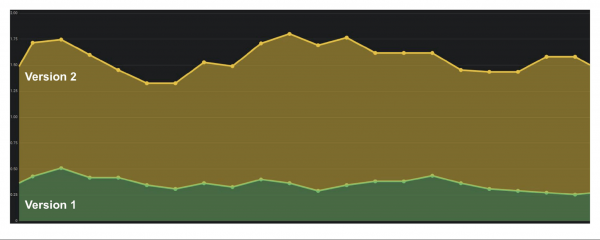
Houbo poucos erros na primeira versión, quizais a auditoría non funcionou. Na segunda versión, todo é moito peor. Podemos dicir con certeza que hai problemas, polo que deberíamos revertir esta versión.
Calibre. As métricas son similares a Counter, pero rexistramos valores que poden aumentar ou diminuír. Por exemplo, o tempo de execución da consulta ou o tamaño da cola.
O gráfico mostra un exemplo de latencia. O gráfico mostra que as versións son similares, podes traballar con elas. Pero se miras detidamente, podes ver como cambia o valor. Se o tempo de execución da consulta aumenta cando se engaden usuarios, inmediatamente queda claro que hai problemas, isto non era o caso antes.
Resumo. Un dos indicadores máis importantes para as empresas son os percentiles. A métrica mostra iso 95% dos casos o noso sistema funciona como queremos. Podemos aceptar se hai problemas nalgún lugar, porque entendemos a tendencia xeral, o bo ou mal que é todo.
Ferramentas
Pila ELK. Podes implementar Canary usando Elasticsearch: escribimos erros nel cando ocorren eventos. Coa chamada API máis sinxela, podes obter o número de erros en cada momento e comparar cos segmentos anteriores: GET /applg/_cunt?q=level:errr.
Prometeo. Mostrouse ben en Infobip. Permite implementar métricas multidimensionais porque se usan etiquetas.
Podemos usalo level, instance, service, combínaos nun só sistema. Con axuda offset podes ver, por exemplo, o valor dun valor hai unha semana cun só comando GET /api/v1/query?query={query}onde {query}:
rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)Análise de versións
Existen varias estratexias de versión.
Consulta só as métricas dos nodos canarios. Unha das opcións máis sinxelas: implementar unha nova versión e estudar só o traballo. Pero se o enxeñeiro neste momento comeza a estudar os rexistros, recargando constantemente as páxinas nerviosamente, entón esta solución non é diferente das outras.
O nodo canario compárase con calquera outro nodo. Esta é unha comparación con outras instancias que se executan a pleno tráfico. Por exemplo, se as cousas son peor cun tráfico reducido, ou non son mellores que en casos reais, algo está mal.
O nodo canario compárase consigo mesmo no pasado. Os nodos asignados a canario pódense comparar con datos históricos. Por exemplo, se todo estaba ben hai unha semana, entón podemos centrarnos nestes datos para comprender a situación actual.
Automatización
Queremos liberar aos enxeñeiros da comparación manual, polo que é importante implementar a automatización. A canalización de implantación adoita ter o seguinte aspecto:
- comezamos;
- eliminar o nodo debaixo do equilibrador;
- configurar un nodo canario;
- acende o equilibrador cunha cantidade limitada de tráfico;
- comparar.
Nesta fase, implementamos comparación automática. Como pode parecer e por que é mellor que a verificación despois da implantación, vexamos un exemplo de Jenkins.
Este é o gasoduto para Groovy.
while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Aquí no bucle establecemos que compararemos o novo nodo durante unha hora. Se o proceso canario aínda non rematou o proceso, chamamos a función. Ela informa que todo está ben ou non: def isOk = compare(srv, canary, time, base, offset, metrics).
Se todo é bo - sleep DEFAULT SLEEP, por exemplo, por un segundo e continúa. Se non, sae: fallou a implantación.
Descrición da métrica. Vexamos como pode ser a función compare no exemplo de DSL.
metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)Digamos que estamos comparando o número de erros e queremos saber o número de erros por segundo nos últimos 5 minutos.
Temos dous valores: nodos base e canario. O valor do nodo canario é o actual. Básico - baseValue é o valor de calquera outro nodo non canario. Comparamos os valores entre si segundo a fórmula, que establecemos en función da nosa experiencia e observacións. Se o valor canaryValue mal, entón fallou a implantación e retrocedemos.
Por que é necesario todo isto?
Unha persoa non pode comprobar centos e miles de métricassobre todo para facelo rapidamente. A comparación automática axuda a comprobar todas as métricas e notifica rapidamente os problemas. O momento da alerta é fundamental: se ocorreu algo nos últimos 2 segundos, o dano non será tan grande como se sucedese hai 15 minutos. Sempre que alguén se dea conta do problema, escriba ao servizo de asistencia técnica e nos apoie para retroceder, podes perder clientes.
Se o proceso pasou e todo está ben, implementaremos todos os outros nodos automaticamente. Durante este tempo, os enxeñeiros non fan nada. Só cando lanzan o canario deciden que métricas tomar, canto tempo facer a comparación, que estratexia usar.
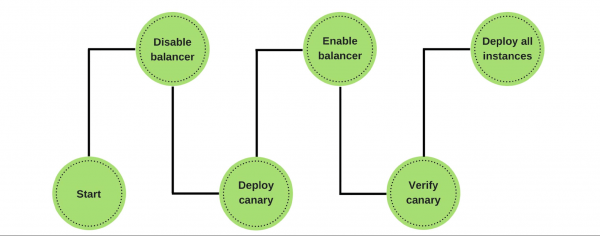
Se hai problemas, retrotraemos automaticamente o nodo canario, traballamos en versións anteriores e corriximos os erros que atopamos. Segundo as métricas, son fáciles de atopar e ver o dano da nova versión.
Obstáculos
Por suposto, isto non é fácil de implementar. En primeiro lugar, necesitas sistema xeral de vixilancia. Os enxeñeiros teñen as súas propias métricas, o soporte e os analistas teñen diferentes métricas, e as empresas teñen outras terceiras. O sistema común é a linguaxe común que falan as empresas e o desenvolvemento.
Debe ser probado na práctica estabilidade métrica. A comprobación axúdache a comprender cal é o conxunto mínimo de métricas necesarias para garantir a calidade.
Como se pode conseguir isto? Use canary-service non no momento da implantación. Engadimos un determinado servizo na versión antiga, que en calquera momento pode levar calquera nodo dedicado, reducir o tráfico sen implantación. Despois de comparar: estudamos os erros e buscamos esa liña cando conseguimos calidade.
Como nos beneficiamos dos lanzamentos canarios?
Minimizada a porcentaxe de danos por erros. A maioría dos erros de implementación débense a inconsistencias nalgúns datos ou prioridade. Hai moitos menos estes erros, porque podemos resolver o problema nos primeiros segundos.
Traballo en equipo optimizado. Os principiantes teñen "dereito a equivocarse": poden implantarse na produción sen medo a equivocarse, hai unha iniciativa adicional, un incentivo para traballar. Se rompen algo, entón non será crítico, e o que comete un erro non será despedido.
Implementación automatizada. Este xa non é un proceso manual, como antes, senón un auténtico automatizado. Pero leva máis tempo.
Métricas importantes destacadas. Toda a empresa, a partir dos negocios e dos enxeñeiros, entende o que é realmente importante no noso produto, que métricas, por exemplo, a saída e a entrada de usuarios. Controlamos o proceso: probamos métricas, introducimos outras novas, vemos como funcionan as antigas para construír un sistema que faga cartos de forma máis produtiva.
Temos moitas prácticas e sistemas interesantes que nos axudan. A pesar diso, esforzámonos por ser profesionais e facer ben o noso traballo, independentemente de que teñamos un sistema que nos axude ou non.
Enfoques e prácticas de enxeñería - . Se conseguiu o éxito no camiño cara á excelencia técnica e está preparado para dicirlle o que lle axudou nisto, — .
Estamos planeando 8 de xuño. Entendemos que agora é difícil tomar decisións sobre a participación na xornada. Pero ao mesmo tempo, cremos que a corentena non é un motivo para deter a comunicación e o desenvolvemento profesional. Polo tanto, en calquera caso, atoparemos unha forma de discutir as tarefas dun responsable técnico e os enfoques para resolvelos.
Fonte: www.habr.com
