


O artigo describe como implementar WMS-sistema, atopámonos coa necesidade de resolver un problema de agrupamento en clústeres non estándar e os algoritmos que empregamos. Compartiremos como aplicamos unha abordaxe sistemática e científica para resolver o problema, os desafíos cos que nos atopamos e as leccións que aprendemos.
Esta publicación inicia unha serie de artigos nos que compartimos a nosa experiencia exitosa na implementación de algoritmos de optimización nos procesos de almacén. O obxectivo desta serie é presentarlle ao público os tipos de desafíos de optimización de almacén que xorden en practicamente calquera almacén de tamaño medio e grande, así como compartir a nosa experiencia na resolución de tales desafíos e as dificultades que atopamos ao longo do proceso. Estes artigos serán útiles para aqueles que traballan na industria da loxística de almacén, implementando WMS-sistemas, así como programadores interesados nas aplicacións das matemáticas nos negocios e na optimización dos procesos empresariais.
Pescozo de botella nos procesos
En 2018, rematamos un proxecto para implementar WMS-sistemas no almacén da empresa "Trading House "LD" en Chelyabinsk. O produto "1C-Logistics: Warehouse Management 3" implementouse para 20 postos de traballo: operadores WMS, almacenistas, condutores de carretillas elevadoras. O almacén medio é duns 4 mil m2, o número de celas é de 5000 e o número de SKU é de 4500. O almacén almacena válvulas de bola de produción propia de diferentes tamaños de 1 kg a 400 kg. O inventario no almacén almacénase en lotes, xa que hai que seleccionar os produtos segundo FIFO.
Ao deseñar esquemas de automatización de almacéns, atopámonos co problema continuo do almacenamento de inventario subóptimo. A natureza específica do almacenamento e apilado con grúas significa que cada almacén de pezas só pode conter artigos dun único lote. Os produtos chegan ao almacén diariamente e cada chegada é un lote separado. En consecuencia, no transcurso dun mes de funcionamento do almacén, créanse 30 lotes separados, cada un dos cales debe almacenarse nun almacén separado. Os produtos adoitan recollerse individualmente, en lugar de en palés completos. Como resultado, en moitos almacéns da área de preparación de pezas obsérvase a seguinte situación: un almacén cun volume de máis de 1 m³ contén varias grúas, cada unha das cales ocupa menos do 5-10 % do volume do almacén.
 Fig. 1. Foto de varios elementos nunha cela
Fig. 1. Foto de varios elementos nunha cela
É evidente unha utilización subóptima da capacidade do almacén. Para ilustrar a magnitude do problema, podo proporcionar algunhas cifras: de media, hai entre 100 e 300 contedores deste tipo cunha capacidade de máis dun metro cúbico que conteñen inventario "minúsculo" en diferentes momentos do funcionamento do almacén. Dado que o almacén é relativamente pequeno, este factor convértese nun colo de botella durante as tempadas altas, o que ralentiza significativamente os procesos do almacén.
Idea de solución do problema
Xurdiu unha idea: combinar lotes de residuos coas datas máis próximas nun único lote e colocar eses residuos cun lote unificado de forma compacta nunha cela, ou en varias, se non hai espazo suficiente nunha delas para aloxar o número total de residuos.
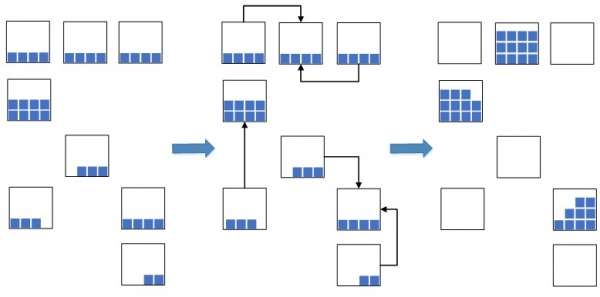
Fig.2. Esquema de compresión de residuos nas células
Isto permite unha redución significativa na cantidade de espazo de almacén necesario para as mercadorías recentemente colocadas. En situacións onde a capacidade do almacén está sobrecargada, esta medida é esencial; se non, pode que simplemente non haxa espazo libre suficiente para aloxar novas mercadorías, o que levaría a un estancamento nos procesos de colocación e reabastecemento do almacén. Anteriormente, antes da implementación WMSAntes, esta operación realizábase manualmente, o que resultaba ineficiente porque a procura de saldos axeitados nos depósitos levaba bastante tempo. Agora, coa implementación dun sistema WMS, decidimos automatizar, acelerar e facer que o proceso sexa intelixente.
O proceso de resolución deste problema divídese en 2 etapas:
- Na primeira fase, atopamos grupos de partidos que teñen unha data próxima e que están comprimidos;
- na segunda etapa, para cada grupo de lotes calculamos a colocación máis compacta das mercadorías restantes nas celas.
Neste artigo, centrarémonos na primeira etapa do algoritmo e deixarémos a segunda etapa para o seguinte artigo.
Busca un modelo matemático do problema
Antes de sentarnos a escribir código e reinventar a roda, decidimos abordar este problema de forma científica, é dicir: formulalo matematicamente, reducilo a un problema de optimización discreta ben coñecido e usar algoritmos existentes eficaces para resolvelo, ou tomar estes algoritmos existentes como base e modificalos para axeitalos ás especificidades do problema práctico que se está a resolver.
Dado que do enunciado xeral do problema se deduce claramente que estamos a tratar con conxuntos, formularemos tal problema en termos da teoría de conxuntos.
Deixe  – o conxunto de todos os lotes de mercadorías restantes nun almacén. Sexa
– o conxunto de todos os lotes de mercadorías restantes nun almacén. Sexa  – unha constante dada de días. Sexa
– unha constante dada de días. Sexa  – un subconxunto de partes onde a diferenza nas datas para todos os pares de partes do subconxunto non excede unha constante
– un subconxunto de partes onde a diferenza nas datas para todos os pares de partes do subconxunto non excede unha constante  É necesario atopar o número mínimo de subconxuntos disxuntos
É necesario atopar o número mínimo de subconxuntos disxuntos  , de tal xeito que todos os subconxuntos
, de tal xeito que todos os subconxuntos  xuntos darían moito
xuntos darían moito  .
.
Noutras palabras, precisamos atopar grupos ou clústeres de partes semellantes, onde o criterio de semellanza estea determinado por unha constante  Este problema lémbranos o coñecido problema de agrupamento en clústeres. É importante ter en conta que o problema en cuestión difire do problema de agrupamento en clústeres en que o noso problema ten unha condición estritamente definida para o criterio de semellanza dos elementos do clúster, determinada por unha constante.
Este problema lémbranos o coñecido problema de agrupamento en clústeres. É importante ter en conta que o problema en cuestión difire do problema de agrupamento en clústeres en que o noso problema ten unha condición estritamente definida para o criterio de semellanza dos elementos do clúster, determinada por unha constante.  , pero no problema de agrupamento en clústeres non existe tal condición. O enunciado do problema de agrupamento en clústeres e a información sobre este problema pódense atopar
, pero no problema de agrupamento en clústeres non existe tal condición. O enunciado do problema de agrupamento en clústeres e a información sobre este problema pódense atopar
Entón, conseguimos formular o problema e atopamos un problema clásico cunha formulación similar. Agora temos que considerar algoritmos coñecidos para resolvelo, para non reinventar a roda, senón adoptar as mellores prácticas e aplicalas. Para resolver o problema da agrupación en clústeres, consideramos os algoritmos máis populares, a saber:  -significa,
-significa,  -medias, un algoritmo de extracción de compoñentes conectados e un algoritmo de árbore de expansión mínima. As descricións e análises destes algoritmos pódense atopar en
-medias, un algoritmo de extracción de compoñentes conectados e un algoritmo de árbore de expansión mínima. As descricións e análises destes algoritmos pódense atopar en
Para resolver o noso problema, os algoritmos de agrupamento en clústeres  -medios e
-medios e  As medias non son aplicables en absoluto, xa que o número de clústeres nunca se coñece de antemán
As medias non son aplicables en absoluto, xa que o número de clústeres nunca se coñece de antemán  e eses algoritmos non teñen en conta a restrición de día constante. Inicialmente, descartáronse tales algoritmos.
e eses algoritmos non teñen en conta a restrición de día constante. Inicialmente, descartáronse tales algoritmos.
A extracción de compoñentes conectada e os algoritmos de árbore de expansión mínima son máis axeitados para resolver o noso problema, pero resulta que non se poden aplicar directamente ao problema en cuestión e producir unha boa solución. Para aclarar isto, consideremos a lóxica que hai detrás destes algoritmos tal e como se aplican ao noso problema.
Consideremos o gráfico  , no que os vértices son un conxunto de partes
, no que os vértices son un conxunto de partes  , e a aresta entre os vértices
, e a aresta entre os vértices  и
и  ten un peso igual á diferenza en días entre lotes
ten un peso igual á diferenza en días entre lotes  и
и  No algoritmo para extraer compoñentes conectados, especifícase un parámetro de entrada
No algoritmo para extraer compoñentes conectados, especifícase un parámetro de entrada  onde
onde  , e no gráfico
, e no gráfico  todas as arestas para as que o peso é maior elimínanse
todas as arestas para as que o peso é maior elimínanse  Só os pares de obxectos máis próximos permanecen conectados. O propósito do algoritmo é atopar ese valor
Só os pares de obxectos máis próximos permanecen conectados. O propósito do algoritmo é atopar ese valor  , no que o gráfico se "desfará" en varios compoñentes conectados, onde as partes pertencentes a estes compoñentes cumprirán o noso criterio de semellanza, determinado pola constante
, no que o gráfico se "desfará" en varios compoñentes conectados, onde as partes pertencentes a estes compoñentes cumprirán o noso criterio de semellanza, determinado pola constante  Os compoñentes resultantes son clústeres.
Os compoñentes resultantes son clústeres.
O algoritmo da árbore de expansión mínima primeiro constrúe unha árbore no grafo  árbore de expansión mínima e, a seguir, elimina secuencialmente as arestas cos pesos máis altos ata que o gráfico se "desfai" en varios compoñentes conectados, onde as partes pertencentes a estes compoñentes tamén cumpren o noso criterio de semellanza. Os compoñentes resultantes serán os clústeres.
árbore de expansión mínima e, a seguir, elimina secuencialmente as arestas cos pesos máis altos ata que o gráfico se "desfai" en varios compoñentes conectados, onde as partes pertencentes a estes compoñentes tamén cumpren o noso criterio de semellanza. Os compoñentes resultantes serán os clústeres.
Ao empregar estes algoritmos para resolver o problema en cuestión, pode xurdir unha situación como a da Figura 3.
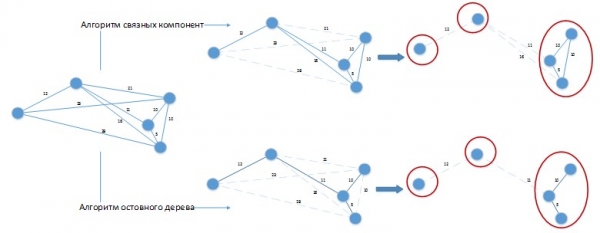
Figura 3. Aplicación dos algoritmos de agrupamento en clústeres ao problema que se está a resolver
Digamos que temos unha diferenza constante en días entre lotes igual a 20 días. Gráfico  representouse espacialmente para facilitar a percepción visual. Ambos algoritmos produciron unha solución con tres clústeres, que se pode mellorar facilmente combinando os lotes colocados en clústeres separados! Claramente, estes algoritmos deben refinarse para o problema específico que se resolve e a súa aplicación na súa forma pura ao noso problema producirá resultados deficientes.
representouse espacialmente para facilitar a percepción visual. Ambos algoritmos produciron unha solución con tres clústeres, que se pode mellorar facilmente combinando os lotes colocados en clústeres separados! Claramente, estes algoritmos deben refinarse para o problema específico que se resolve e a súa aplicación na súa forma pura ao noso problema producirá resultados deficientes.

Entón, antes de comezar a escribir código para algoritmos de grafos modificados para a nosa tarefa e reinventar a roda (nas cuxas siluetas xa se apreciaban os contornos das rodas cadradas), decidimos, de novo, abordar este problema cientificamente, é dicir: tentar reducilo a outro problema de optimización discreta, coa esperanza de que os algoritmos existentes para resolvelo puidesen aplicarse sen modificacións.
Outra busca dun problema clásico similar tivo éxito! Atopamos un problema de optimización discreta cuxa formulación é idéntica á nosa. Este problema resultou ser problema de cobertura de conxuntosFormulemos o problema en relación coa nosa situación específica.
Existe un conxunto finito  e familia
e familia  todos os seus subconxuntos disxuntos de partes, de tal xeito que a diferenza nas datas para todos os pares de partes de cada subconxunto
todos os seus subconxuntos disxuntos de partes, de tal xeito que a diferenza nas datas para todos os pares de partes de cada subconxunto  da familia
da familia  non supera unha constante
non supera unha constante  Unha cuberta é unha familia
Unha cuberta é unha familia  de menor potencia, cuxos elementos pertencen
de menor potencia, cuxos elementos pertencen  , de tal xeito que a unión de conxuntos
, de tal xeito que a unión de conxuntos  da familia
da familia  debería dar o conxunto de todas as partes
debería dar o conxunto de todas as partes  .
.
Unha análise detallada deste problema pódese atopar и Pódense atopar outras aplicacións prácticas do problema da cobertura e as súas modificacións
Algoritmo para resolver o problema
Definimos o modelo matemático para o problema que se vai resolver. Agora imos pasar a examinar o algoritmo para resolvelo. Subconxuntos  da familia
da familia  pódese atopar facilmente mediante o seguinte procedemento.
pódese atopar facilmente mediante o seguinte procedemento.
- Ordena as partes do conxunto
 en orde descendente das súas datas.
en orde descendente das súas datas. - Atopa as datas mínimas e máximas dos xogos.
- Para todos os días desde a data mínima ata a máxima, atopa todas as partes cuxas datas difiren de non máis que (polo tanto, o significado é mellor coller un número par).
 en orde descendente das súas datas.
en orde descendente das súas datas. desde a data mínima ata a máxima, atopa todas as partes cuxas datas difiren de
desde a data mínima ata a máxima, atopa todas as partes cuxas datas difiren de  non máis que
non máis que  (polo tanto, o significado
(polo tanto, o significado  é mellor coller un número par).
é mellor coller un número par). A lóxica do procedemento para formar unha familia de conxuntos  en
en  días móstrase na figura 4.
días móstrase na figura 4.

Fig. 4. Formación de subconxuntos de partidos
Nun procedemento deste tipo non é necesario para todos  revisa todos os outros lotes e comproba a diferenza entre as súas datas ou co valor actual
revisa todos os outros lotes e comproba a diferenza entre as súas datas ou co valor actual  móvete á esquerda ou á dereita ata atopar un lote cuxa data sexa diferente de
móvete á esquerda ou á dereita ata atopar un lote cuxa data sexa diferente de  En máis da metade do valor constante. Todos os elementos posteriores, tanto se se moven á dereita como á esquerda, non nos interesarán, xa que a diferenza en días só aumentará para eles, xa que os elementos da matriz foron ordenados inicialmente. Esta estratexia aforrará un tempo significativo cando o número de lotes e a dispersión das súas datas sexan significativamente maiores.
En máis da metade do valor constante. Todos os elementos posteriores, tanto se se moven á dereita como á esquerda, non nos interesarán, xa que a diferenza en días só aumentará para eles, xa que os elementos da matriz foron ordenados inicialmente. Esta estratexia aforrará un tempo significativo cando o número de lotes e a dispersión das súas datas sexan significativamente maiores.
O problema de cobertura de conxuntos é  -difícil, o que significa que non existe un algoritmo rápido (cun tempo de execución igual a un polinomio nos datos de entrada) e exacto para resolvelo. Polo tanto, escolleuse un algoritmo voraz rápido para resolver o problema de cobertura de conxuntos. Aínda que non é exacto, ten as seguintes vantaxes:
-difícil, o que significa que non existe un algoritmo rápido (cun tempo de execución igual a un polinomio nos datos de entrada) e exacto para resolvelo. Polo tanto, escolleuse un algoritmo voraz rápido para resolver o problema de cobertura de conxuntos. Aínda que non é exacto, ten as seguintes vantaxes:
- Para problemas a pequena escala (que é precisamente o noso caso), calcula solucións que están bastante preto do óptimo. A medida que o tamaño do problema aumenta, a calidade da solución deteriórase, pero aínda de forma bastante lenta;
- Moi doado de implementar;
- É rápido porque se estima que o seu tempo de execución é de .
 .
.O algoritmo voraz selecciona conxuntos baseándose na seguinte regra: en cada etapa, selecciónase un conxunto que abrangue o número máximo de elementos descubertos. Pódese atopar unha descrición detallada do algoritmo e o seu pseudocódigo
A precisión deste algoritmo voraz nos datos de proba do problema que se está a resolver non se comparou con outros algoritmos coñecidos, como o algoritmo voraz probabilístico, o algoritmo da colonia de formigas, etc. Os resultados da comparación destes algoritmos en datos aleatorios xerados pódense atopar
Implementación e implementación do algoritmo
Este algoritmo foi implementado na linguaxe 1S e incluíuse nun procesamento externo chamado "Compresión de residuos" que estaba conectado a WMS-sistema. Non implementamos o algoritmo na linguaxe C++ e usalo desde un compoñente nativo externo, o que sería máis correcto, xa que a velocidade do código en C ++ varias veces e nalgúns exemplos incluso decenas de veces supera a velocidade de código similar en 1SNa lingua 1S O algoritmo implementouse para aforrar tempo de desenvolvemento e simplificar a depuración no entorno de produción do cliente. O resultado do algoritmo móstrase na Figura 5.
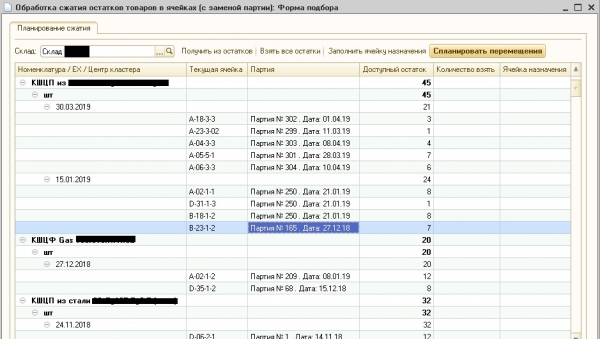
Fig. 5. Procesamento por «compresión» de residuos
A figura 5 mostra que os saldos actuais de inventario nas celas de almacenamento do almacén especificado están divididos en clústeres, dentro dos cales as datas dos lotes non difiren en máis de 30 días. Dado que o cliente fabrica e almacena válvulas de bola metálicas no almacén, que teñen unha vida útil medida en anos, esta diferenza de datas pódese ignorar. Cómpre sinalar que este tipo de procesamento úsase actualmente sistematicamente na produción e os operadores WMS confirmar a boa calidade da agrupación de partidos.
Conclusións e continuación
A principal experiencia que obtivemos da resolución dun problema tan práctico é a confirmación da eficacia do uso do paradigma: formulación matemática do problema  modelo matemático coñecido
modelo matemático coñecido  algoritmo coñecido
algoritmo coñecido  Un algoritmo adaptado ás especificidades do problema. A optimización discreta existe desde hai máis de 300 anos e, durante este tempo, a xente considerou unha ampla gama de problemas e acumulou unha ampla experiencia na súa resolución. É mellor aproveitar esta experiencia primeiro e só despois tentar reinventar a roda.
Un algoritmo adaptado ás especificidades do problema. A optimización discreta existe desde hai máis de 300 anos e, durante este tempo, a xente considerou unha ampla gama de problemas e acumulou unha ampla experiencia na súa resolución. É mellor aproveitar esta experiencia primeiro e só despois tentar reinventar a roda.
No seguinte artigo, continuaremos a nosa análise dos algoritmos de optimización e consideraremos algo máis interesante e moito máis complexo: un algoritmo para a "compresión" óptima de residuos celulares que emprega datos de entrada dun algoritmo de agrupamento por lotes.
Preparado por
Roman Shangin, programador do departamento de proxectos,
Primeira empresa BIT, Cheliábinsk
Fonte: www.habr.com
