

Neste artigo falaremos das dependencias funcionais nas bases de datos: cales son, onde se usan e que algoritmos existen para atopalas.
Consideraremos as dependencias funcionais no contexto das bases de datos relacionais. Para dicilo de xeito moi groso, nestas bases de datos gárdase a información en forma de táboas. A continuación, usamos conceptos aproximados que non son intercambiables na teoría relacional estrita: chamaremos á propia táboa unha relación, ás columnas - atributos (o seu conxunto - un esquema de relación) e ao conxunto de valores de fila nun subconxunto de atributos. - unha tupla.
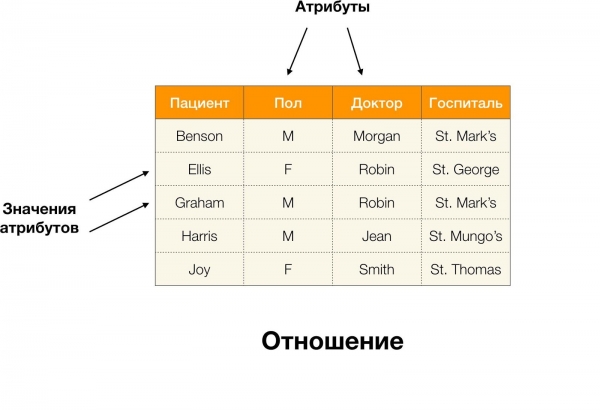
Por exemplo, na táboa anterior, (Benson, M, M órgano) é unha tupla de atributos (Paciente, Paul, Doutor).
Máis formalmente, isto está escrito do seguinte xeito:  [Paciente, Sexo, Médico] = (Benson, M, M órgano).
[Paciente, Sexo, Médico] = (Benson, M, M órgano).
Agora podemos introducir o concepto de dependencia funcional (FD):
Definición 1. A relación R cumpre a lei federal X → Y (onde X, Y ⊆ R) se e só se para calquera tupla  ,
,  ∈ R ten: se
∈ R ten: se  [X] =
[X] =  [X], entón
[X], entón  [Y] =
[Y] =  [Y]. Neste caso, dicimos que X (o determinante ou conxunto definitorio de atributos) determina funcionalmente Y (o conxunto dependente).
[Y]. Neste caso, dicimos que X (o determinante ou conxunto definitorio de atributos) determina funcionalmente Y (o conxunto dependente).
Noutras palabras, a presenza dunha lei federal X → Y significa que se temos dúas tuplas R e coinciden en atributos X, entón coincidirán en atributos Y.
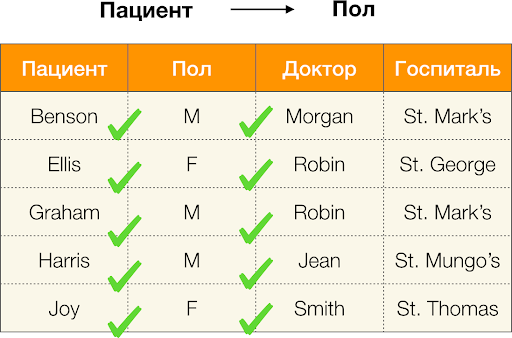
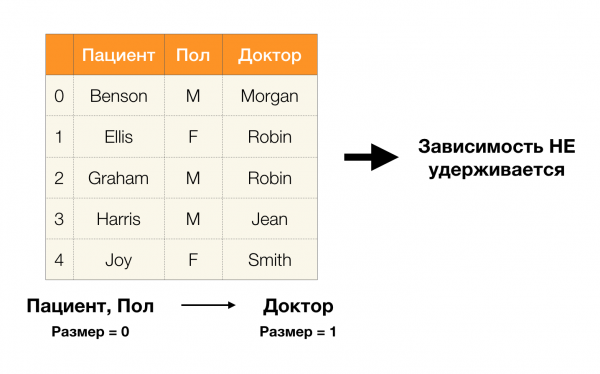
E agora, en orde. Vexamos os atributos Un paciente и Sexo para o que queremos saber se hai ou non dependencias entre eles. Para tal conxunto de atributos, poden existir as seguintes dependencias:
- Paciente → Sexo
- Sexo → Paciente
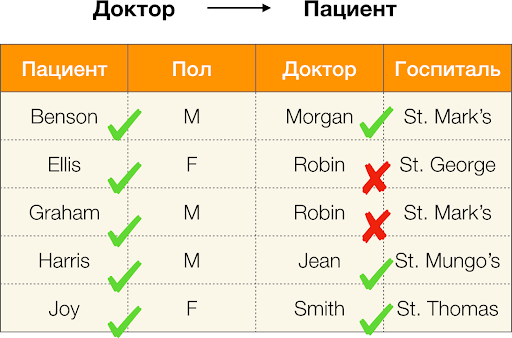
Como se definiu anteriormente, para que se manteña a primeira dependencia, cada valor de columna único Un paciente só debe coincidir un valor de columna Sexo. E para a táboa de exemplo este é realmente o caso. Non obstante, isto non funciona na dirección oposta, é dicir, a segunda dependencia non se satisface e o atributo Sexo non é un determinante para Paciente. Do mesmo xeito, se tomamos a dependencia Médico → Paciente, podes ver que está violado, xa que o valor Robin este atributo ten varios significados diferentes - Ellis e Graham.
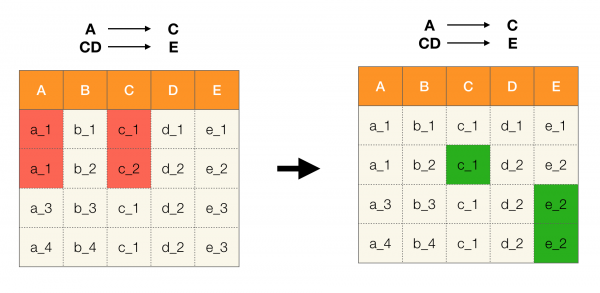
Así, as dependencias funcionais permiten determinar as relacións existentes entre conxuntos de atributos da táboa. A partir de aquí consideraremos as conexións máis interesantes, ou mellor dito X → Ycales son:
- non trivial, é dicir, o lado dereito da dependencia non é un subconxunto da esquerda (Y ̸⊆ X);
- mínima, é dicir, non existe esa dependencia Z → YQue Z ⊂ X.
As dependencias consideradas ata este momento eran estritas, é dicir, non contemplaban ningunha infracción sobre a mesa, pero ademais delas, tamén hai aquelas que permiten certa inconsistencia entre os valores das tuplas. Tales dependencias colócanse nunha clase separada, chamada aproximada, e permítese violar un determinado número de tuplas. Esta cantidade está regulada polo indicador de erro máximo emax. Por exemplo, a taxa de erro  = 0.01 pode significar que a dependencia pode ser violada polo 1% das tuplas dispoñibles no conxunto de atributos considerado. É dicir, para 1000 rexistros, un máximo de 10 tuplas poden violar a Lei Federal. Consideraremos unha métrica lixeiramente diferente, baseada en valores diferentes por pares das tuplas que se están comparando. Por adicción X → Y sobre a actitude r considérase así:
= 0.01 pode significar que a dependencia pode ser violada polo 1% das tuplas dispoñibles no conxunto de atributos considerado. É dicir, para 1000 rexistros, un máximo de 10 tuplas poden violar a Lei Federal. Consideraremos unha métrica lixeiramente diferente, baseada en valores diferentes por pares das tuplas que se están comparando. Por adicción X → Y sobre a actitude r considérase así:

Imos calcular o erro para Médico → Paciente do exemplo anterior. Temos dúas tuplas cuxos valores difiren no atributo Un paciente, pero coinciden Doutor:  [Médico, Paciente] = (Robin, Ellis) E
[Médico, Paciente] = (Robin, Ellis) E  [Médico, Paciente] = (Robin, Graham). Seguindo a definición de erro, debemos ter en conta todos os pares en conflito, o que significa que haberá dous deles: (
[Médico, Paciente] = (Robin, Graham). Seguindo a definición de erro, debemos ter en conta todos os pares en conflito, o que significa que haberá dous deles: ( ,
,  ) e a súa inversa (
) e a súa inversa ( ,
,  ). Substituímolo na fórmula e obteña:
). Substituímolo na fórmula e obteña:

Agora imos tentar responder á pregunta: "Por que é todo para?" De feito, as leis federais son diferentes. O primeiro tipo son aquelas dependencias que son determinadas polo administrador na fase de deseño da base de datos. Adoitan ser poucos, estritos e a principal aplicación é a normalización de datos e o deseño de esquemas relacionais.
O segundo tipo son as dependencias, que representan datos "ocultos" e relacións previamente descoñecidas entre atributos. É dicir, tales dependencias non se pensaron no momento do deseño e atópanse para o conxunto de datos existente, para que posteriormente, en función das moitas leis federais identificadas, se poida extraer calquera conclusión sobre a información almacenada. Son precisamente estas dependencias coas que traballamos. Son tratados por todo un campo de minería de datos con varias técnicas de busca e algoritmos construídos sobre a súa base. Imos descubrir como poden ser útiles as dependencias funcionais atopadas (exactas ou aproximadas) en calquera dato.

Hoxe, unha das principais aplicacións das dependencias é a limpeza de datos. Implica desenvolver procesos para identificar “datos sucios” e posteriormente corrixilos. Exemplos destacados de "datos sucios" son duplicados, erros de datos ou erros tipográficos, valores perdidos, datos obsoletos, espazos adicionais e similares.
Exemplo de erro de datos:
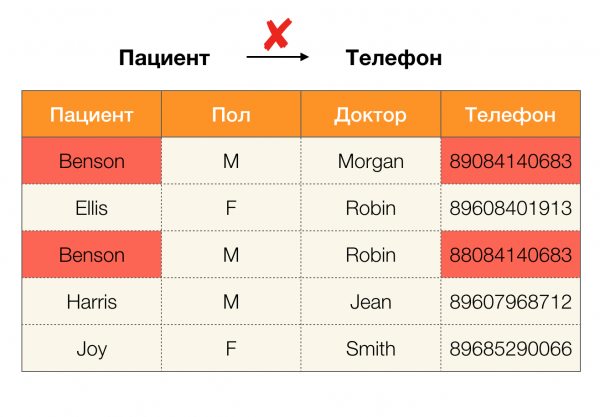
Exemplo de duplicados en datos:
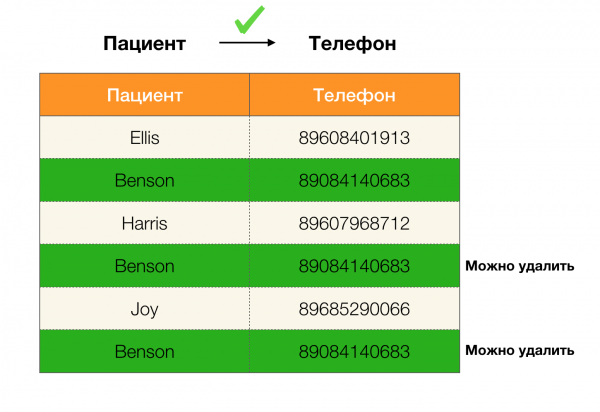
Por exemplo, temos unha táboa e un conxunto de leis federais que hai que executar. A limpeza de datos neste caso implica cambiar os datos para que as leis federais sexan correctas. Neste caso, o número de modificacións debe ser mínimo (este procedemento ten os seus propios algoritmos, nos que non nos centraremos neste artigo). A continuación móstrase un exemplo desta transformación de datos. Á esquerda está a relación orixinal, na que, obviamente, non se cumpren os FL necesarios (resáltase en vermello un exemplo de violación dun dos FL). Á dereita está a relación actualizada, coas celas verdes que mostran os valores modificados. Tras este trámite, comezaron a manterse as dependencias necesarias.
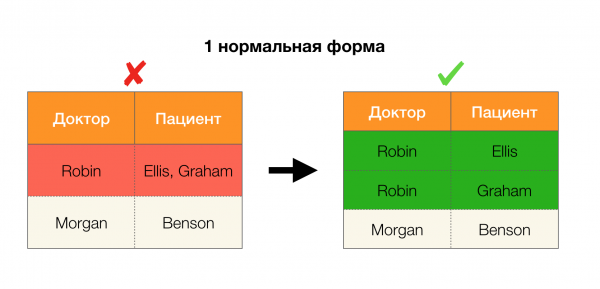
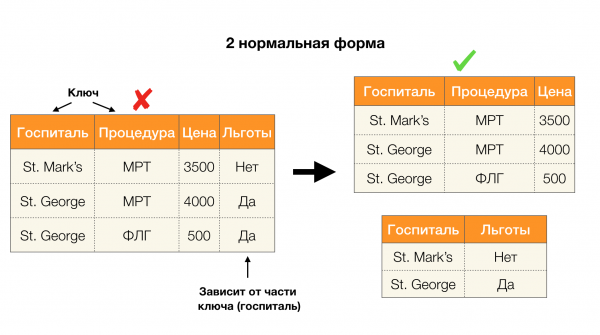
Outra aplicación popular é o deseño de bases de datos. Aquí convén lembrar formas normais e normalización. A normalización é o proceso de poñer unha relación en conformidade cun determinado conxunto de requisitos, cada un dos cales está definido pola forma normal ao seu xeito. Non imos describir os requisitos de varias formas normais (iso faise en calquera libro sobre un curso de base de datos para principiantes), pero só observaremos que cada un deles utiliza o concepto de dependencias funcionais ao seu xeito. Despois de todo, os FL son inherentemente restricións de integridade que se teñen en conta ao deseñar unha base de datos (no contexto desta tarefa, as FL ás veces chámanse superclaves).
Consideremos a súa solicitude para os catro formularios normais na imaxe de abaixo. Lembre que a forma normal de Boyce-Codd é máis estrita que a terceira, pero menos estrita que a cuarta. Non estamos considerando isto último polo momento, xa que a súa formulación require unha comprensión das dependencias multivaloradas, que non nos interesan neste artigo.
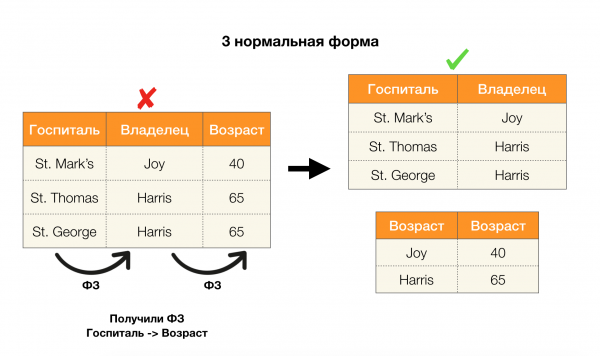
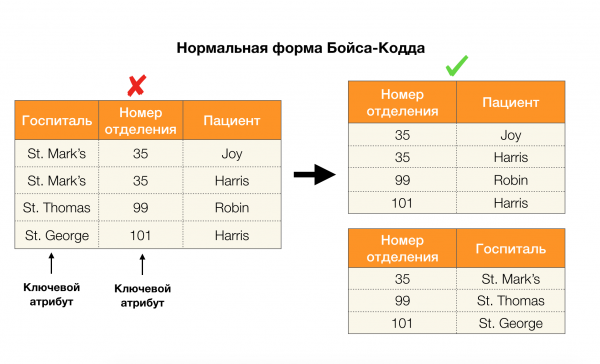
Outra área na que as dependencias atoparon a súa aplicación é a redución da dimensionalidade do espazo de características en tarefas como a construción dun clasificador Bayes inxenuo, a identificación de características significativas e a reparametría dun modelo de regresión. Nos artigos orixinais, esta tarefa chámase determinación da relevancia redundante e das características [5, 6], e resólvese co uso activo dos conceptos de bases de datos. Coa chegada de tales traballos, podemos dicir que hoxe hai unha demanda de solucións que nos permitan combinar a base de datos, a análise e a implementación dos problemas de optimización anteriores nunha soa ferramenta [7, 8, 9].
Existen moitos algoritmos (tanto modernos como non tan modernos) para buscar leis federais nun conxunto de datos. Estes algoritmos pódense dividir en tres grupos:
- Algoritmos que usan o recorrido de redes alxébricas (Algoritmos de recorrido de celosías)
- Algoritmos baseados na busca de valores acordados (algoritmos de conxunto de diferenzas e de acordo)
- Algoritmos baseados en comparacións por pares (algoritmos de indución de dependencias)
Na seguinte táboa preséntase unha breve descrición de cada tipo de algoritmo:
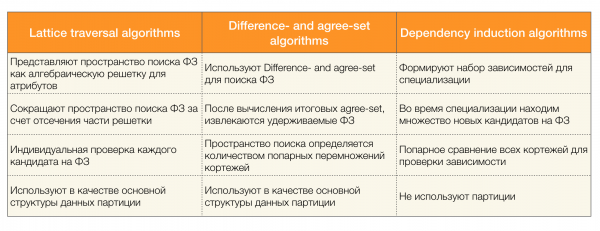
Podes ler máis sobre esta clasificación [4]. Abaixo amósanse exemplos de algoritmos para cada tipo:
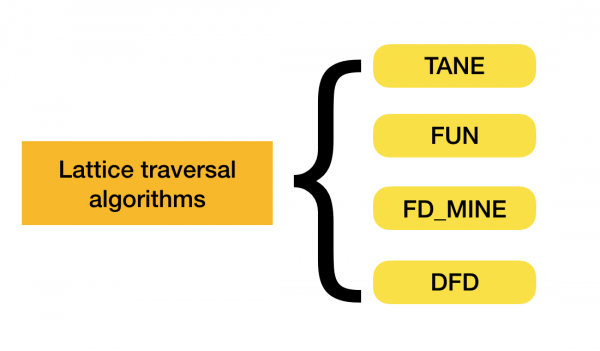
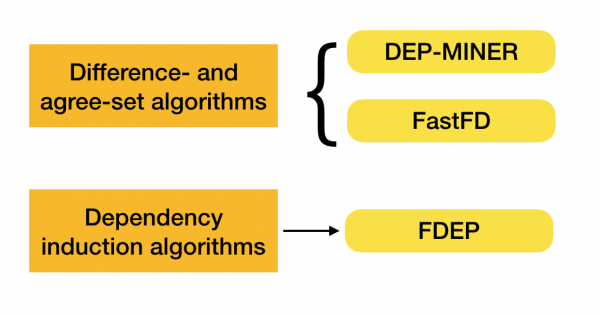
Actualmente, están aparecendo novos algoritmos que combinan varios enfoques para atopar dependencias funcionais. Exemplos deste tipo de algoritmos son Pyro [2] e HyFD [3]. Espérase unha análise do seu traballo nos seguintes artigos desta serie. Neste artigo só examinaremos os conceptos básicos e o lema que son necesarios para comprender as técnicas de detección de dependencias.
Comecemos por un simple - conxunto de diferenzas e de acordo, usado no segundo tipo de algoritmos. O conxunto de diferenzas é un conxunto de tuplas que non teñen os mesmos valores, mentres que o conxunto de acordo, pola contra, son tuplas que teñen os mesmos valores. Cabe sinalar que neste caso estamos considerando só o lado esquerdo da dependencia.
Outro concepto importante que se atopou anteriormente é a rede alxébrica. Dado que moitos algoritmos modernos operan con este concepto, necesitamos ter unha idea do que é.
Para introducir o concepto de celosía, é necesario definir un conxunto parcialmente ordenado (ou conxunto parcialmente ordenado, abreviado como poset).
Definición 2. Dise que un conxunto S está parcialmente ordenado pola relación binaria ⩽ se para todo a, b, c ∈ S cúmprense as seguintes propiedades:
- Reflexividade, é dicir, a ⩽ a
- Antisimetría, é dicir, se a ⩽ b e b ⩽ a, entón a = b
- A transitividade, é dicir, para a ⩽ b e b ⩽ c segue que a ⩽ c
A tal relación chámase relación de orde parcial (solta), e o propio conxunto chámase conxunto parcialmente ordenado. Notación formal: ⟨S, ⩽⟩.
Como o exemplo máis sinxelo dun conxunto parcialmente ordenado, podemos tomar o conxunto de todos os números naturais N coa relación de orde habitual ⩽. É doado comprobar que se cumpren todos os axiomas necesarios.
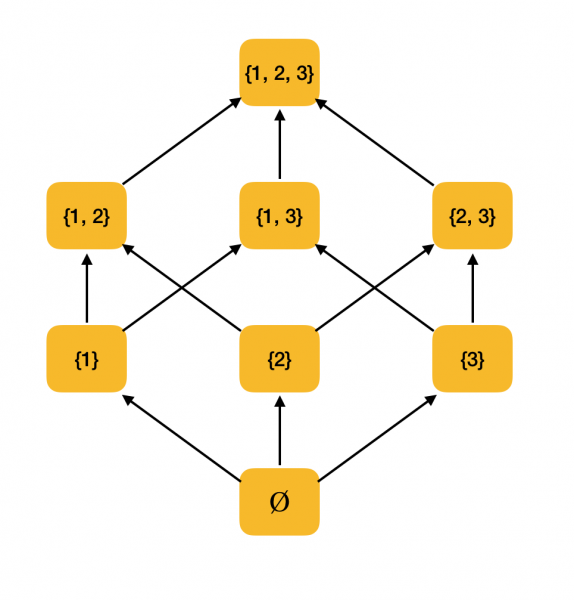
Un exemplo máis significativo. Considere o conxunto de todos os subconxuntos {1, 2, 3}, ordenados pola relación de inclusión ⊆. De feito, esta relación satisface todas as condicións de orde parcial, polo que ⟨P ({1, 2, 3}), ⊆⟩ é un conxunto parcialmente ordenado. A seguinte figura mostra a estrutura deste conxunto: se un elemento pode ser alcanzado mediante frechas a outro elemento, entón están nunha relación de orde.
Necesitaremos dúas definicións máis sinxelas do campo das matemáticas: supremum e infimum.
Definición 3. Sexa ⟨S, ⩽⟩ un conxunto parcialmente ordenado, A ⊆ S. O límite superior de A é un elemento u ∈ S tal que ∀x ∈ S: x ⩽ u. Sexa U o conxunto de todos os límites superiores de S. Se hai un elemento máis pequeno en U, entón chámase supremo e denotase sup A.
O concepto de límite inferior exacto introdúcese de xeito similar.
Definición 4. Sexa ⟨S, ⩽⟩ un conxunto parcialmente ordenado, A ⊆ S. O ínfimo de A é un elemento l ∈ S tal que ∀x ∈ S: l ⩽ x. Sexa L o conxunto de todos os límites inferiores de S. Se hai un elemento maior en L, entón denomínase ínfimo e denotase como inf A.
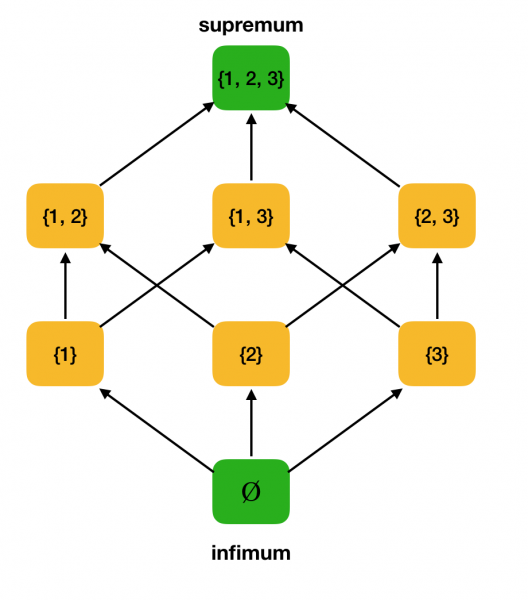
Considere como exemplo o conxunto parcialmente ordenado anterior ⟨P ({1, 2, 3}), ⊆⟩ e atopa o supremo e o ínfimo nel:
Agora podemos formular a definición dunha rede alxébrica.
Definición 5. Sexa ⟨P,⩽⟩ un conxunto parcialmente ordenado tal que cada subconxunto de dous elementos teña un límite superior e inferior. Entón P chámase rede alxébrica. Neste caso, sup{x, y} escríbese como x ∨ y, e inf {x, y} como x ∧ y.
Comprobamos que o noso exemplo de traballo ⟨P ({1, 2, 3}), ⊆⟩ é unha rede. De feito, para calquera a, b ∈ P ({1, 2, 3}), a∨b = a∪b e a∧b = a∩b. Por exemplo, considere os conxuntos {1, 2} e {1, 3} e atope o seu ínfimo e o seu supremo. Se os cruzamos, obteremos o conxunto {1}, que será o ínfimo. Obtemos o supremo combinándoos - {1, 2, 3}.
Nos algoritmos para identificar problemas físicos, o espazo de busca adoita representarse en forma de celosía, onde os conxuntos dun elemento (léase o primeiro nivel da rede de busca, onde o lado esquerdo das dependencias consta dun atributo) representan cada atributo. da relación orixinal.
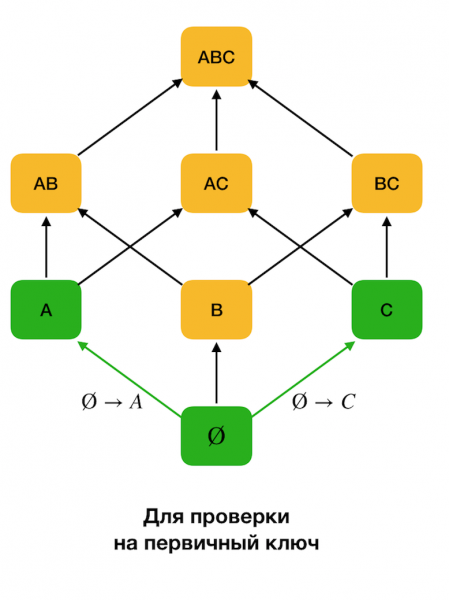
En primeiro lugar, consideramos dependencias da forma ∅ → Atributo único. Este paso permítelle determinar que atributos son claves primarias (para tales atributos non hai determinantes e, polo tanto, o lado esquerdo está baleiro). Ademais, tales algoritmos móvense cara arriba ao longo da rede. Paga a pena notar que non se pode atravesar toda a celosía, é dicir, se se pasa á entrada o tamaño máximo desexado do lado esquerdo, entón o algoritmo non irá máis aló dun nivel con ese tamaño.
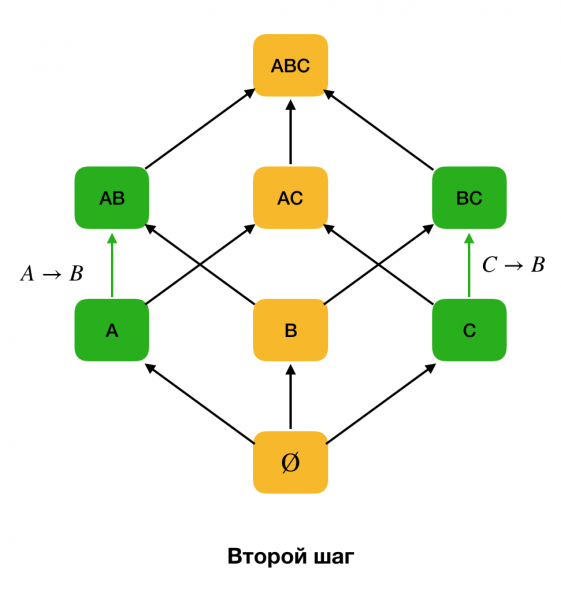
A figura seguinte mostra como se pode usar unha rede alxébrica no problema de atopar unha FZ. Aquí cada borde (X, XY) representa unha dependencia X → Y. Por exemplo, superamos o primeiro nivel e sabemos que a adicción se mantén A → B (mostraremos isto como unha conexión verde entre os vértices A и B). Isto significa que, ademais, cando subimos pola celosía, é posible que non comprobemos a dependencia A, C → B, porque xa non será mínimo. Do mesmo xeito, non comprobariamos se se mantiña a dependencia C → B.
Ademais, como regra xeral, todos os algoritmos modernos para buscar leis federais usan unha estrutura de datos como unha partición (na fonte orixinal - partición desposuída [1]). A definición formal dunha partición é a seguinte:
Definición 6. Sexa X ⊆ R un conxunto de atributos para a relación r. Un cluster é un conxunto de índices de tuplas en r que teñen o mesmo valor para X, é dicir, c(t) = {i|ti[X] = t[X]}. Unha partición é un conxunto de clusters, excluíndo os clusters de lonxitude unitaria:

En palabras simples, unha partición para un atributo X é un conxunto de listas, onde cada lista contén números de liña cos mesmos valores para X. Na literatura moderna, a estrutura que representa as particións chámase índice de lista de posicións (PLI). Os clústeres de lonxitude unitaria están excluídos para fins de compresión PLI porque son clústeres que só conteñen un número de rexistro cun valor único que sempre será fácil de identificar.
Vexamos un exemplo. Volvamos á mesma táboa cos pacientes e construímos particións para as columnas Un paciente и Sexo (apareceu unha nova columna á esquerda, na que están marcados os números de fila da táboa):
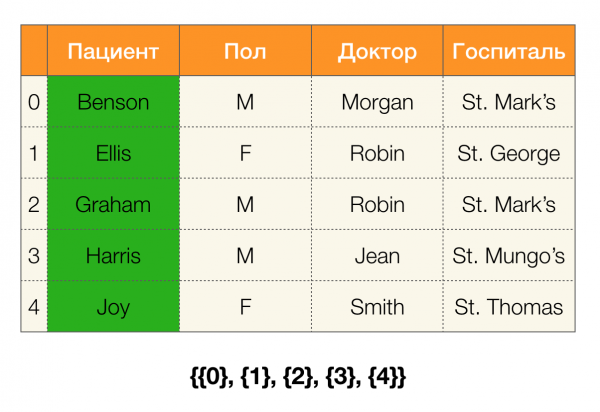
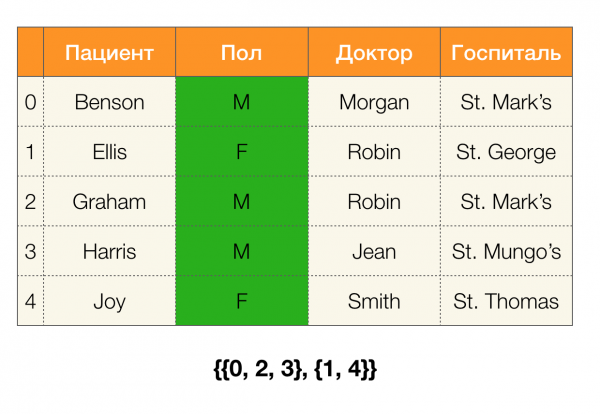
Ademais, segundo a definición, a partición para a columna Un paciente en realidade estará baleiro, xa que os clústeres únicos están excluídos da partición.
As particións pódense obter mediante varios atributos. E hai dúas formas de facelo: percorrendo a táboa, construír unha partición usando todos os atributos necesarios á vez, ou construíla usando a operación de intersección de particións usando un subconxunto de atributos. Os algoritmos de busca da lei federal usan a segunda opción.
En palabras sinxelas, para, por exemplo, obter unha partición por columnas ABC, pode tomar particións para AC и B (ou calquera outro conxunto de subconxuntos disxuntos) e interséctanos entre si. A operación de intersección de dúas particións selecciona clusters de maior lonxitude que son comúns a ambas particións.
Vexamos un exemplo:
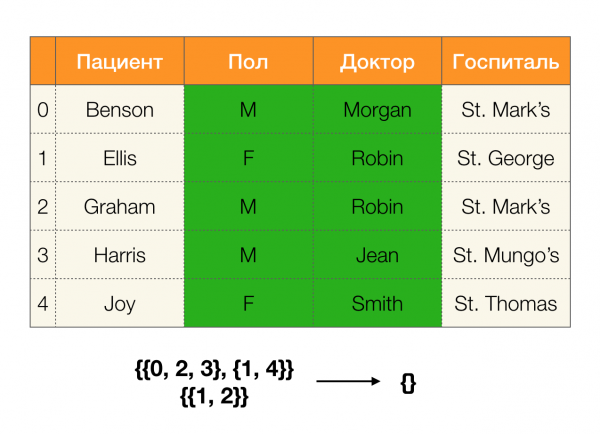

No primeiro caso, recibimos unha partición baleira. Se miras atentamente a táboa, non hai valores idénticos para os dous atributos. Se modificamos lixeiramente a táboa (o caso da dereita), xa obteremos unha intersección non baleira. Ademais, as liñas 1 e 2 conteñen realmente os mesmos valores para os atributos Sexo и Doutor.
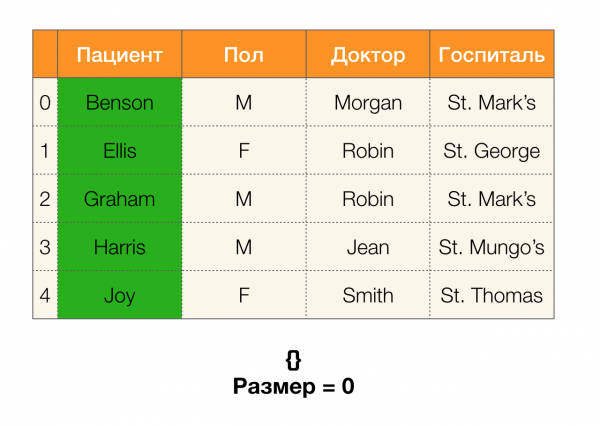
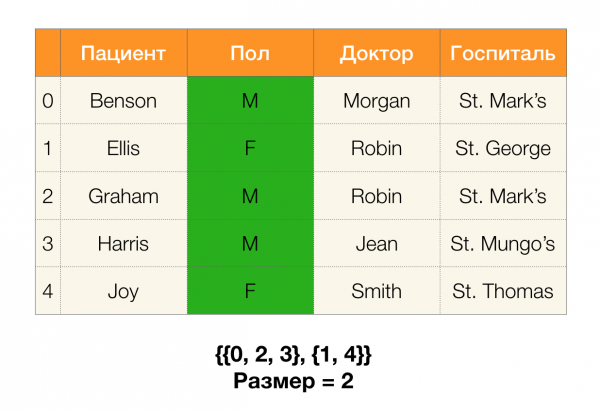
A continuación, necesitaremos un concepto como o tamaño da partición. Formalmente:

Simplemente, o tamaño da partición é o número de clústeres incluídos na partición (lembre que os clústeres individuais non están incluídos na partición!):
Agora podemos definir un dos lemas clave, que para determinadas particións permítenos determinar se se mantén ou non unha dependencia:
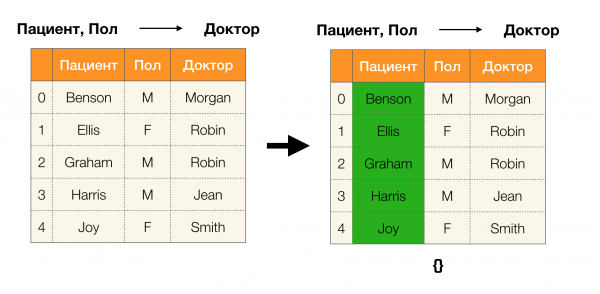
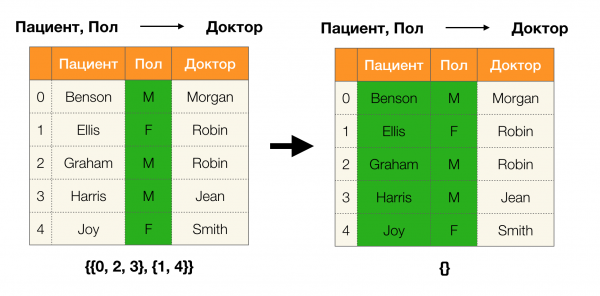
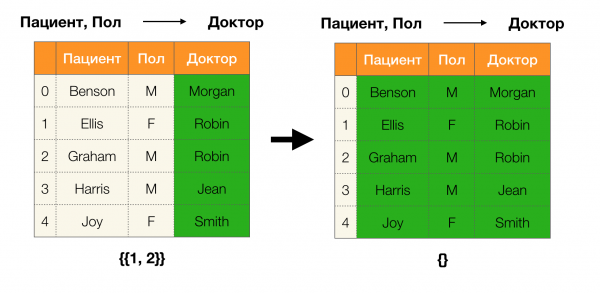
Lema 1. A dependencia A, B → C vale se e só se

Segundo o lema, para determinar se se mantén unha dependencia, hai que realizar catro pasos:
- Calcula a partición para o lado esquerdo da dependencia
- Calcula a partición para o lado dereito da dependencia
- Calcula o produto do primeiro e segundo paso
- Compara os tamaños das particións obtidas no primeiro e terceiro pasos
A continuación móstrase un exemplo de verificación de se a dependencia se mantén segundo este lema:
Neste artigo, examinamos conceptos como a dependencia funcional, a dependencia funcional aproximada, analizamos onde se usan, así como que algoritmos para buscar funcións físicas existen. Tamén examinamos en detalle os conceptos básicos pero importantes que se usan activamente nos algoritmos modernos para buscar leis federais.
Referencias:
- Huhtala Y. et al. TANE: Un algoritmo eficiente para descubrir dependencias funcionais e aproximadas //The computer journal. – 1999. – T. 42. – Núm. 2. – páxs 100-111.
- Kruse S., Naumann F. Descubrimento eficiente de dependencias aproximadas // Proceedings of the VLDB Endowment. – 2018. – T. 11. – Núm. 7. – páxinas 759-772.
- Papenbrock T., Naumann F. A hybrid approach to functional dependency discovery //Actas da Conferencia Internacional de Xestión de Datos de 2016. – ACM, 2016. – páxs. 821-833.
- Papenbrock T. et al. Descubrimento da dependencia funcional: unha avaliación experimental de sete algoritmos //Proceedings of the VLDB Endowment. – 2015. – T. 8. – Núm. 10. – páxinas 1082-1093.
- Kumar A. et al. Para unirse ou non unirse?: Pensando dúas veces nas unións antes da selección de funcións //Proceedings of the 2016 International Conference on Management of Data. – ACM, 2016. – páxs 19-34.
- Abo Khamis M. et al. Aprendizaxe en base de datos con tensores escasos //Actas do 37o Simposio ACM SIGMOD-SIGACT-SIGAI sobre os principios dos sistemas de bases de datos. – ACM, 2018. – páxs. 325-340.
- Hellerstein JM et al. A biblioteca de análise MADlib: ou habilidades MAD, o SQL //Proceedings of the VLDB Endowment. – 2012. – T. 5. – Núm. 12. – páxs 1700-1711.
- Qin C., Rusu F. Aproximacións especulativas para a optimización de descenso de gradientes distribuídos a teraescala //Proceedings of the Fourth Workshop on Data analytics in the Cloud. – ACM, 2015. – P. 1.
- Meng X. et al. Mllib: Machine learning en apache spark //The Journal of Machine Learning Research. – 2016. – T. 17. – Núm. 1. – páxinas 1235-1241.
Autores do artigo: , investigador en , и , investigador en
Fonte: www.habr.com
