

U ovom ću članku govoriti o tome kako se projekt na kojem radim transformirao iz velikog monolita u skup mikroservisa.
Projekt je započeo svoju povijest prilično davno, početkom 2000. godine. Prve verzije su napisane u Visual Basicu 6. S vremenom je postalo jasno da će razvoj na ovom jeziku biti teško podržavati u budućnosti, jer IDE i sam jezik su slabo razvijeni. Krajem 2000-ih odlučeno je prijeći na C# koji više obećava. Nova verzija je pisana paralelno s revizijom stare, postupno je sve više koda pisano u .NET-u. Backend u C# je u početku bio fokusiran na servisnu arhitekturu, ali tijekom razvoja korištene su zajedničke biblioteke s logikom, a servisi su pokrenuti u jednom procesu. Rezultat je bila aplikacija koju smo nazvali "uslužni monolit".
Jedna od rijetkih prednosti ove kombinacije bila je sposobnost usluga da se međusobno pozivaju putem vanjskog API-ja. Postojali su jasni preduvjeti za prelazak na korektniju servisnu, au budućnosti i mikroservisnu arhitekturu.
Započeli smo rad na razgradnji oko 2015. Još nismo došli do idealnog stanja – još uvijek postoje dijelovi velikog projekta koji se teško mogu nazvati monolitima, ali ni oni ne izgledaju kao mikroservisi. Ipak, napredak je značajan.
O tome ću govoriti u članku.
sadržaj
Arhitektura i problemi postojećeg rješenja
U početku je arhitektura izgledala ovako: UI je zasebna aplikacija, monolitni dio je napisan u Visual Basicu 6, .NET aplikacija je skup povezanih usluga koje rade s prilično velikom bazom podataka.
Nedostaci prethodnog rješenja
Jedna točka kvara
Imali smo jednu točku kvara: .NET aplikacija radila je u jednom procesu. Ako bilo koji modul nije uspio, cijela aplikacija nije uspjela i morala se ponovno pokrenuti. Budući da automatiziramo veliki broj procesa za različite korisnike, zbog kvara na jednom od njih svi nisu mogli raditi neko vrijeme. A u slučaju softverske pogreške, čak ni backup nije pomogao.
Red poboljšanja
Ovaj nedostatak je više organizacijski. Naša aplikacija ima mnogo korisnika i svi je žele poboljšati što je prije moguće. Ranije je to bilo nemoguće raditi paralelno i svi su kupci stajali u redu. Taj je proces bio negativan za poduzeća jer su morali dokazati da je njihov zadatak vrijedan. A razvojni tim proveo je vrijeme organizirajući ovaj red. To je oduzimalo puno vremena i truda, a proizvod se u konačnici nije mogao promijeniti onoliko brzo koliko bi željeli.
Neoptimalno korištenje resursa
Prilikom hostinga usluga u jednom procesu, uvijek smo u potpunosti kopirali konfiguraciju s poslužitelja na poslužitelj. Htjeli smo najopterećenije usluge smjestiti odvojeno kako ne bismo rasipali resurse i stekli fleksibilniju kontrolu nad našom shemom postavljanja.
Teško implementirati moderne tehnologije
Problem poznat svim programerima: postoji želja za uvođenjem modernih tehnologija u projekt, ali nema prilike. Uz veliko monolitno rješenje, svako ažuriranje trenutne biblioteke, a da ne spominjemo prijelaz na novu, pretvara se u prilično netrivijalan zadatak. Dugo je potrebno dokazati vođi tima da će to donijeti više bonusa nego izgubljenih živaca.
Poteškoće s izdavanjem izmjena
To je bio najozbiljniji problem - objavljivali smo izdanja svaka dva mjeseca.
Svako izdanje pretvorilo se u pravu katastrofu za banku, unatoč testiranju i naporima programera. Poslovanje je shvatilo da početkom tjedna neke njegove funkcionalnosti neće raditi. I programeri su shvatili da ih čeka tjedan ozbiljnih incidenata.
Svi su imali želju promijeniti situaciju.
Očekivanja od mikroservisa
Izdavanje komponenti kada budu spremne. Isporuka komponenti kada su spremne razgradnjom otopine i odvajanjem različitih procesa.
Mali proizvodni timovi. Ovo je važno jer je bilo teško upravljati velikim timom koji je radio na starom monolitu. Takav tim bio je prisiljen raditi po strogom procesu, ali su htjeli više kreativnosti i samostalnosti. Ovo su si mogli priuštiti samo mali timovi.
Izolacija usluga u zasebne procese. Idealno bi bilo da ga izoliram u kontejnere, ali veliki broj servisa napisanih u .NET Frameworku radi samo pod WindowsServisi temeljeni na .NET Coreu se sada pojavljuju, ali ih je još uvijek malo.
Fleksibilnost implementacije. Htjeli bismo kombinirati usluge onako kako nama treba, a ne kako kodeks forsira.
Korištenje novih tehnologija. Ovo je zanimljivo svakom programeru.
Problemi tranzicije
Naravno, kada bi bilo jednostavno razbiti monolit na mikroservise, ne bi bilo potrebe govoriti o tome na konferencijama i pisati članke. Mnogo je zamki u tom procesu, a ja ću opisati one glavne koje su nas kočile.
Prvi problem tipično za većinu monolita: koherentnost poslovne logike. Kada pišemo monolit, želimo ponovno koristiti svoje klase kako ne bismo pisali nepotreban kod. A kada prijeđete na mikroservise, to postaje problem: sav je kod prilično čvrsto povezan i teško je razdvojiti usluge.
U trenutku početka rada, repozitorij je imao više od 500 projekata i više od 700 tisuća redaka koda. Ovo je prilično velika odluka i drugi problem. Nije ga bilo moguće jednostavno uzeti i podijeliti na mikroservise.
Treći problem — nedostatak potrebne infrastrukture. Zapravo, ručno smo kopirali izvorni kod na poslužitelje.
Kako prijeći s monolita na mikroservise
Pružanje mikrousluga
Prvo, odmah smo za sebe utvrdili da je odvajanje mikroservisa iterativni proces. Od nas se uvijek tražilo da poslovne probleme razvijamo paralelno. Kako ćemo to tehnički provesti, to je već naš problem. Stoga smo se pripremili za iterativni proces. Neće funkcionirati ni na koji drugi način ako imate veliku aplikaciju i nije inicijalno spremna za ponovno pisanje.
Koje metode koristimo za izolaciju mikroservisa?
Prvi način — premjestiti postojeće module kao usluge. Što se toga tiče, imali smo sreće: već su postojale registrirane usluge koje su radile koristeći WCF protokol. Bili su razdvojeni u zasebne sklopove. Prenijeli smo ih zasebno, dodajući mali pokretač svakoj verziji. Napisana je pomoću prekrasne biblioteke Topshelf, koja vam omogućuje pokretanje aplikacije i kao usluge i kao konzole. Ovo je zgodno za otklanjanje pogrešaka budući da u rješenju nisu potrebni dodatni projekti.
Servisi su bili povezani poslovnom logikom, jer su koristili zajedničke sklopove i radili sa zajedničkom bazom podataka. Teško bi se mogli nazvati mikroservisima u svom čistom obliku. Međutim, te bismo usluge mogli pružati odvojeno, u različitim procesima. Samo je to omogućilo smanjenje njihovog utjecaja jednih na druge, smanjujući problem paralelnog razvoja i jedne točke kvara.
Sastavljanje s hostom samo je jedna linija koda u klasi programa. Sakrili smo rad s Topshelfom u pomoćnom razredu.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Drugi način dodjele mikroservisa je: stvoriti ih za rješavanje novih problema. Ako u isto vrijeme monolit ne raste, to je već izvrsno, što znači da se krećemo u pravom smjeru. Kako bismo riješili nove probleme, pokušali smo stvoriti zasebne usluge. Ako je postojala takva prilika, onda smo stvorili više "kanonskih" usluga koje u potpunosti upravljaju vlastitim modelom podataka, zasebnom bazom podataka.
Mi smo, kao i mnogi, započeli s uslugama autentifikacije i autorizacije. Oni su savršeni za ovo. Oni su neovisni, u pravilu imaju zaseban model podataka. Oni sami ne komuniciraju s monolitom, samo se on okreće njima da riješe neke probleme. Korištenjem ovih usluga možete započeti prijelaz na novu arhitekturu, otkloniti pogreške u infrastrukturi na njima, isprobati neke pristupe povezane s mrežnim knjižnicama itd. U našoj organizaciji nema timova koji ne mogu stvoriti uslugu autentifikacije.
Treći način dodjele mikroservisaOvaj koji koristimo je malo specifičan za nas. Ovo je uklanjanje poslovne logike iz sloja korisničkog sučelja. Naša glavna UI aplikacija je desktop; ona je, kao i backend, napisana u C#. Programeri su povremeno činili pogreške i prenosili dijelove logike u korisničko sučelje koje je trebalo postojati u pozadini i ponovno koristiti.
Ako pogledate stvarni primjer iz koda dijela korisničkog sučelja, možete vidjeti da većina ovog rješenja sadrži stvarnu poslovnu logiku koja je korisna u drugim procesima, a ne samo za izradu obrasca korisničkog sučelja.
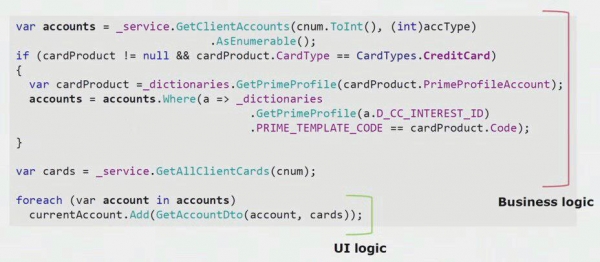
Prava logika korisničkog sučelja postoji samo u zadnjih par redaka. Prenijeli smo ga na server kako bi se mogao ponovno koristiti, čime smo smanjili UI i postigli ispravnu arhitekturu.
Četvrti i najvažniji način za izolaciju mikroservisa, koji omogućuje smanjenje monolita, je uklanjanje postojećih usluga s obradom. Kada uklonimo postojeće module kakvi jesu, rezultat nije uvijek po volji programera, a poslovni proces je možda zastario otkad je funkcionalnost stvorena. Refactoringom možemo podržati novi poslovni proces jer se poslovni zahtjevi stalno mijenjaju. Možemo poboljšati izvorni kod, ukloniti poznate nedostatke i stvoriti bolji model podataka. Pristižu mnoge koristi.
Odvajanje usluga od obrade neraskidivo je povezano s konceptom ograničenog konteksta. Ovo je koncept tvrtke Domain Driven Design. To znači dio modela domene u kojem su svi pojmovi jednog jezika jedinstveno definirani. Pogledajmo kontekst osiguranja i računa kao primjer. Imamo monolitnu aplikaciju, a moramo raditi s računom u osiguranju. Očekujemo da programer pronađe postojeću klasu Računa u drugom sklopu, referencira je iz klase Osiguranje i imat ćemo radni kod. Poštivat će se DRY princip, korištenjem postojećeg koda zadatak će biti obavljen brže.
Kao rezultat toga, ispada da su konteksti računa i osiguranja povezani. Kako se pojavljuju novi zahtjevi, ova će sprega ometati razvoj, povećavajući složenost već složene poslovne logike. Da biste riješili ovaj problem, morate pronaći granice između konteksta u kodu i ukloniti njihova kršenja. Na primjer, u kontekstu osiguranja, vrlo je moguće da će 20-znamenkasti broj računa Centralne banke i datum otvaranja računa biti dovoljni.
Kako bismo odvojili ove ograničene kontekste jedan od drugog i započeli proces odvajanja mikroservisa od monolitnog rješenja, upotrijebili smo pristup kao što je stvaranje vanjskih API-ja unutar aplikacije. Ako smo znali da neki modul treba postati mikroservis, na neki način modificiran unutar procesa, onda smo eksternim pozivima odmah pozivali logiku koja pripada drugom ograničenom kontekstu. Na primjer, putem REST-a ili WCF-a.
Čvrsto smo odlučili da nećemo izbjegavati kod koji bi zahtijevao distribuirane transakcije. U našem slučaju pokazalo se da je prilično lako slijediti ovo pravilo. Još se nismo susreli sa situacijama u kojima su stvarno potrebne striktno raspodijeljene transakcije – konačna konzistentnost između modula sasvim je dovoljna.
Pogledajmo konkretan primjer. Imamo koncept orkestratora - cjevovoda koji obrađuje entitet "aplikacije". Redom kreira klijenta, račun i bankovnu karticu. Ako su klijent i račun uspješno kreirani, ali kreiranje kartice ne uspije, aplikacija ne prelazi u status “uspješno” i ostaje u statusu “kartica nije kreirana”. U budućnosti će ga pozadinska aktivnost pokupiti i završiti. Sustav je već neko vrijeme u nekonzistentnom stanju, ali generalno smo time zadovoljni.
Ukoliko dođe do situacije da je potrebno dosljedno čuvati dio podataka, najvjerojatnije ćemo ići na konsolidaciju servisa kako bismo ga obradili u jednom procesu.
Pogledajmo primjer dodjele mikroservisa. Kako ga relativno sigurno dovesti u proizvodnju? U ovom primjeru imamo zaseban dio sustava - servisni modul obračuna plaća, od čijeg jednog kodnog dijela želimo napraviti mikroservis.
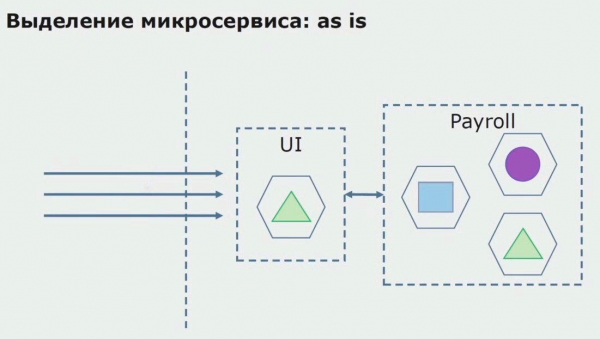
Prije svega, stvaramo mikroservis prepisivanjem koda. Poboljšavamo neke aspekte s kojima nismo bili zadovoljni. Implementiramo nove poslovne zahtjeve kupca. Dodajemo API Gateway vezi između korisničkog sučelja i pozadine, koji će omogućiti prosljeđivanje poziva.
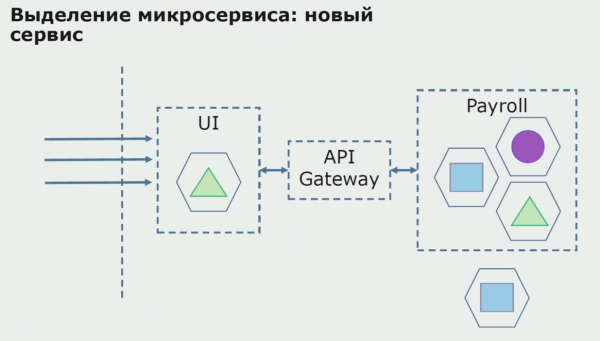
Zatim puštamo ovu konfiguraciju u rad, ali u pilot stanju. Većina naših korisnika još uvijek radi sa starim poslovnim procesima. Za nove korisnike razvijamo novu verziju monolitne aplikacije koja više ne sadrži ovaj proces. U biti, imamo kombinaciju monolita i mikroservisa koji rade kao pilot.
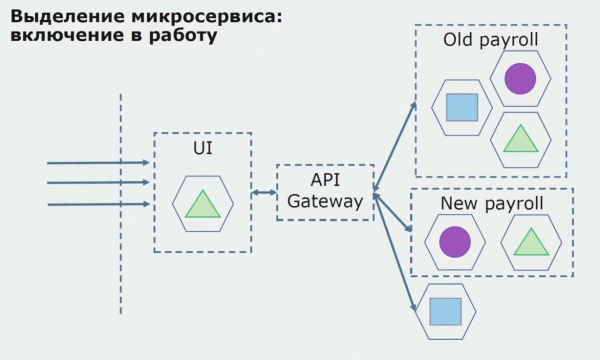
Uz uspješan pilot, razumijemo da je nova konfiguracija doista izvediva, možemo ukloniti stari monolit iz jednadžbe i ostaviti novu konfiguraciju umjesto starog rješenja.
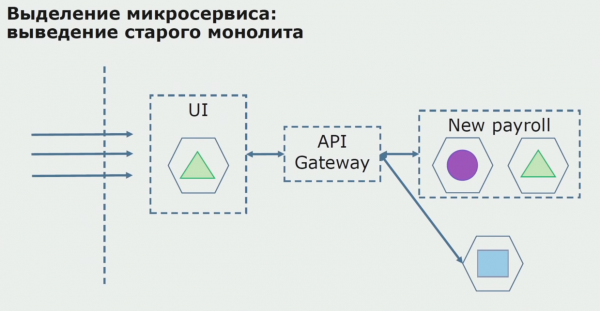
Ukupno koristimo gotovo sve postojeće metode za razdvajanje izvornog koda monolita. Sve nam one omogućuju smanjenje veličine dijelova aplikacije i njihovo prevođenje u nove biblioteke, stvarajući bolji izvorni kod.
Rad s bazom podataka
Baza podataka može se podijeliti gore od izvornog koda, jer sadrži ne samo trenutnu shemu, već i akumulirane povijesne podatke.
Naša baza podataka, kao i mnoge druge, imala je još jedan važan nedostatak - svoju ogromnu veličinu. Ova baza podataka dizajnirana je prema zamršenoj poslovnoj logici monolita, a odnosi su akumulirani između tablica različitih ograničenih konteksta.
U našem slučaju, povrh svega (velika baza podataka, mnogo veza, ponekad nejasne granice između tablica), pojavio se problem koji se javlja u mnogim velikim projektima: korištenje predloška zajedničke baze podataka. Podaci su uzeti iz tablica kroz prikaz, kroz replikaciju i otpremljeni u druge sustave gdje je ova replikacija bila potrebna. Kao rezultat toga, nismo mogli premjestiti tablice u zasebnu shemu jer su se aktivno koristile.
Ista podjela na ograničene kontekste u kodu pomaže nam u razdvajanju. Obično nam daje prilično dobru ideju o tome kako raščlanjujemo podatke na razini baze podataka. Razumijemo koje tablice pripadaju jednom ograničenom kontekstu, a koje drugom.
Koristili smo dvije globalne metode particioniranja baze podataka: particioniranje postojećih tablica i particioniranje s obradom.
Razdvajanje postojećih tablica dobra je metoda ako je struktura podataka dobra, udovoljava poslovnim zahtjevima i svi su s njom zadovoljni. U ovom slučaju možemo odvojiti postojeće tablice u zasebnu shemu.
Odjel s obradom potreban je kada se poslovni model jako promijenio, a stolovi nas više uopće ne zadovoljavaju.
Razdvajanje postojećih tablica. Moramo odrediti što ćemo odvojiti. Bez ovog znanja ništa neće funkcionirati, a tu će nam pomoći odvajanje ograničenih konteksta u kodu. U pravilu, ako možete razumjeti granice konteksta u izvornom kodu, postaje jasno koje tablice trebaju biti uključene u popis za odjel.
Zamislimo da imamo rješenje u kojem dva monolitna modula komuniciraju s jednom bazom podataka. Moramo biti sigurni da samo jedan modul komunicira s odjeljkom odvojenih tablica, a drugi počinje s njim komunicirati putem API-ja. Za početak je dovoljno da se putem API-ja vrši samo snimanje. To je nužan uvjet da bismo mogli govoriti o neovisnosti mikroservisa. Veze za čitanje mogu ostati sve dok nema velikih problema.
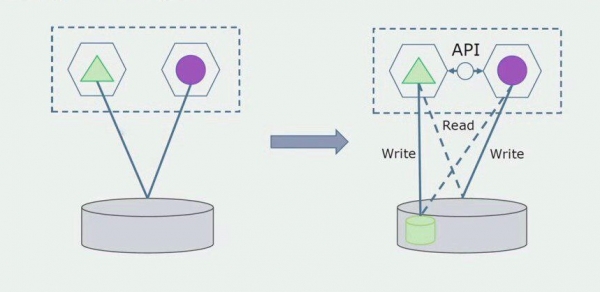
Sljedeći korak je da možemo odvojiti dio koda koji radi s odvojenim tablicama, sa ili bez obrade, u zasebnu mikroservis i pokrenuti ga u zasebnom procesu, spremniku. To će biti zasebna usluga s vezom na monolitnu bazu podataka i one tablice koje se ne odnose izravno na nju. Monolit i dalje djeluje za čitanje s odvojivim dijelom.
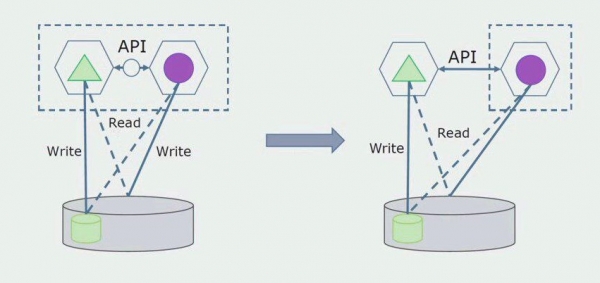
Kasnije ćemo tu vezu ukloniti, odnosno čitanje podataka iz monolitne aplikacije iz odvojenih tablica također će se prenijeti na API.
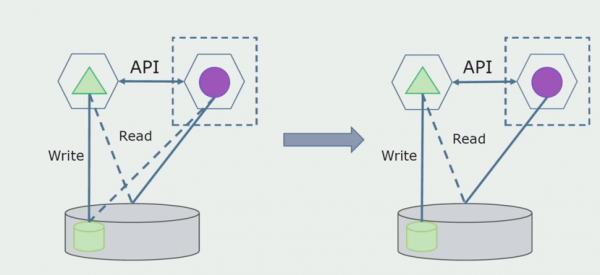
Zatim ćemo iz opće baze podataka odabrati tablice s kojima radi samo novi mikroservis. Tablice možemo premjestiti u zasebnu shemu ili čak u zasebnu fizičku bazu podataka. Još uvijek postoji veza za čitanje između mikroservisa i monolitne baze podataka, ali nema razloga za brigu, u ovoj konfiguraciji može živjeti dosta dugo.
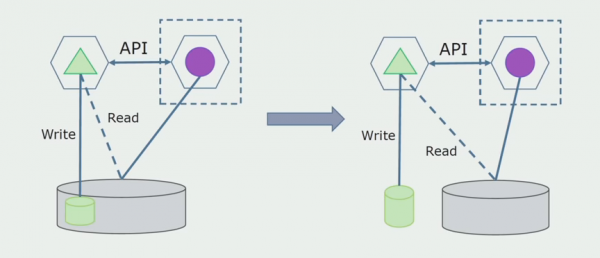
Zadnji korak je potpuno uklanjanje svih veza. U ovom slučaju, možda ćemo morati migrirati podatke iz glavne baze podataka. Ponekad želimo ponovno upotrijebiti neke podatke ili direktorije replicirane iz vanjskih sustava u nekoliko baza podataka. To nam se povremeno događa.
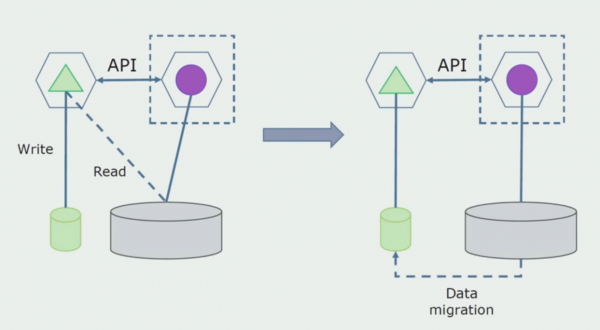
Odjel obrade. Ova metoda je vrlo slična prvoj, samo obrnutim redoslijedom. Odmah dodjeljujemo novu bazu podataka i novu mikrouslugu koja komunicira s monolitom putem API-ja. Ali u isto vrijeme, ostaje skup tablica baze podataka koje želimo izbrisati u budućnosti. Više nam ne treba, zamijenili smo ga u novom modelu.
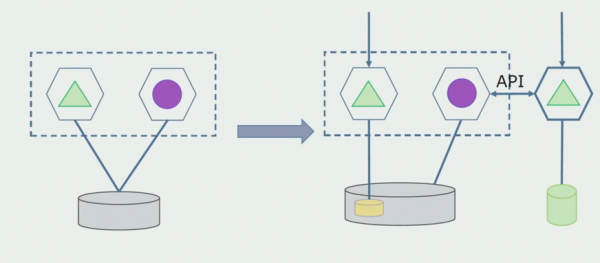
Da bi ova shema funkcionirala, vjerojatno će nam trebati prijelazno razdoblje.
Tada postoje dva moguća pristupa.
Prvi: dupliciramo sve podatke u novoj i staroj bazi podataka. U ovom slučaju imamo redundanciju podataka i mogu se pojaviti problemi sa sinkronizacijom. Ali možemo uzeti dva različita klijenta. Jedan će raditi s novom verzijom, drugi sa starom.
Drugi: podatke dijelimo prema nekim poslovnim kriterijima. Na primjer, u sustavu smo imali 5 proizvoda koji su bili pohranjeni u staroj bazi podataka. Šesti postavljamo unutar novog poslovnog zadatka u novu bazu podataka. No, trebat će nam API Gateway koji će sinkronizirati ove podatke i pokazati klijentu gdje i što dobiti.
Oba pristupa djeluju, odaberite ovisno o situaciji.
Nakon što se uvjerimo da sve radi, dio monolita koji radi sa starim strukturama baze podataka može se onemogućiti.
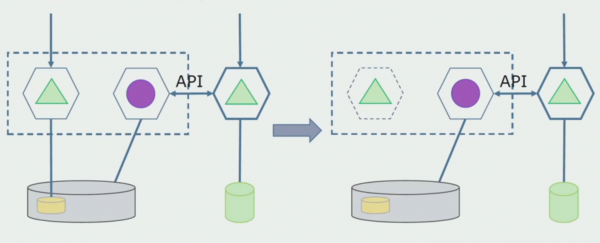
Zadnji korak je uklanjanje starih struktura podataka.
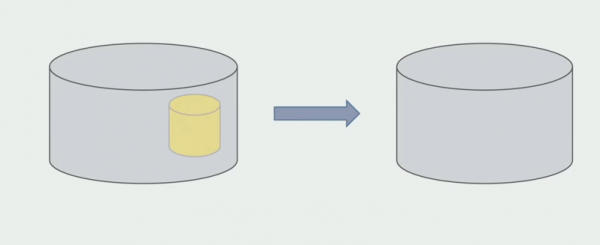
Ukratko, možemo reći da imamo problema s bazom podataka: teško je raditi s njom u odnosu na izvorni kod, teže ju je dijeliti, ali može i treba. Pronašli smo neke načine koji nam to omogućuju prilično sigurno, ali ipak je lakše pogriješiti s podacima nego s izvornim kodom.
Rad s izvornim kodom
Ovako je izgledao dijagram izvornog koda kada smo počeli analizirati monolitni projekt.
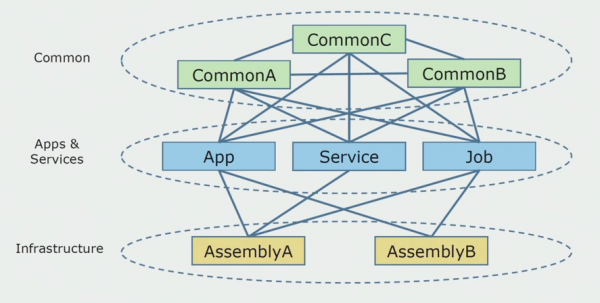
Može se grubo podijeliti u tri sloja. Ovo je sloj pokrenutih modula, dodataka, usluga i pojedinačnih aktivnosti. Zapravo su to bile ulazne točke unutar monolitnog rješenja. Svi su bili čvrsto zapečaćeni zajedničkim slojem. Imao je poslovnu logiku da su usluge bile zajedničke i puno veza. Svaki servis i dodatak koristio je do 10 ili više uobičajenih sklopova, ovisno o njihovoj veličini i savjesti programera.
Imali smo sreće što smo imali infrastrukturne knjižnice koje su se mogle koristiti zasebno.
Ponekad je došlo do situacije da neki uobičajeni objekti zapravo ne pripadaju ovom sloju, već su infrastrukturne knjižnice. To je riješeno preimenovanjem.
Najveća briga bili su ograničeni konteksti. Dešavalo se da se 3-4 konteksta pomiješaju u jednom zajedničkom sklopu i međusobno koriste unutar istih poslovnih funkcija. Bilo je potrebno razumjeti gdje se to može podijeliti i duž kojih granica, te što dalje učiniti s mapiranjem te podjele u sklopove izvornog koda.
Formulirali smo nekoliko pravila za proces dijeljenja koda.
Prvi: Nismo više htjeli dijeliti poslovnu logiku između usluga, aktivnosti i dodataka. Htjeli smo učiniti poslovnu logiku neovisnom unutar mikroservisa. Mikrousluge, s druge strane, idealno se smatraju uslugama koje postoje potpuno neovisno. Vjerujem da je ovaj pristup donekle rastrošan i teško ostvariv, jer će npr. usluge u C# u svakom slučaju biti povezane standardnom bibliotekom. Naš sustav je napisan u C#; druge tehnologije još nismo koristili. Stoga smo odlučili da si možemo priuštiti korištenje uobičajenih tehničkih sklopova. Glavna stvar je da ne sadrže nikakve fragmente poslovne logike. Ako imate prikladni omot preko ORM-a koji koristite, tada je njegovo kopiranje s usluge na uslugu vrlo skupo.
Naš je tim obožavatelj dizajna vođenog domenom, pa nam je onion arhitektura odlično pristajala. Osnova naših usluga nije sloj pristupa podacima, već sklop s domenskom logikom, koji sadrži samo poslovnu logiku i nema veze s infrastrukturom. U isto vrijeme, možemo samostalno modificirati sklop domene kako bismo riješili probleme vezane uz okvire.
U ovoj smo fazi naišli na prvi ozbiljniji problem. Servis se morao odnositi na jedan sklop domene, željeli smo logiku učiniti neovisnom i tu nas je DRY princip jako kočio. Programeri su htjeli ponovno upotrijebiti klase iz susjednih sklopova kako bi izbjegli dupliciranje, a kao rezultat toga, domene su se ponovno počele povezivati. Analizirali smo rezultate i zaključili da možda problem leži i u području uređaja za pohranu izvornog koda. Imali smo veliki repozitorij koji je sadržavao sav izvorni kod. Rješenje za cijeli projekt bilo je vrlo teško sastaviti na lokalnom stroju. Stoga su stvorena zasebna mala rješenja za dijelove projekta, a nitko nije zabranio dodati im neki zajednički ili domenski sklop i ponovno ih koristiti. Jedini alat koji nam to nije omogućio bio je pregled koda. Ali ponekad je i zatajilo.
Zatim smo počeli prelaziti na model s odvojenim spremištima. Poslovna logika više ne teče od usluge do usluge, domene su doista postale neovisne. Ograničeni konteksti su podržani jasnije. Kako ponovno koristiti infrastrukturne knjižnice? Odvojili smo ih u posebno spremište, zatim stavili u Nuget pakete, koje smo stavili u Artifactory. S bilo kakvom promjenom, sklapanje i objavljivanje odvija se automatski.
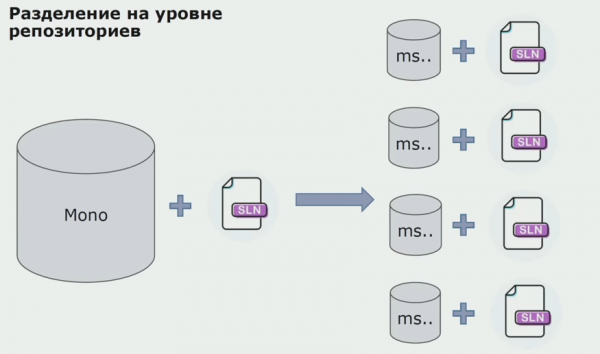
Naše su usluge počele referencirati unutarnje infrastrukturne pakete na isti način kao i vanjske. Preuzimamo vanjske biblioteke s Nugeta. Za rad s Artifactoryjem, gdje smo postavili ove pakete, koristili smo dva upravitelja paketa. U malim repozitorijima koristili smo i Nuget. U spremištima s višestrukim uslugama koristili smo Paket, koji pruža veću dosljednost verzija između modula.
Dakle, radom na izvornom kodu, malom promjenom arhitekture i odvajanjem repozitorija, naše usluge činimo neovisnijima.
Problemi s infrastrukturom
Većina nedostataka prelaska na mikroservise povezana je s infrastrukturom. Trebat će vam automatizirana implementacija, trebat će vam nove biblioteke za pokretanje infrastrukture.
Ručna instalacija u okruženjima
U početku smo ručno instalirali rješenje za okruženja. Kako bismo automatizirali ovaj proces, stvorili smo CI/CD cjevovod. Odabrali smo proces kontinuirane isporuke jer kontinuirana implementacija za nas još nije prihvatljiva sa stajališta poslovnih procesa. Stoga se slanje na rad provodi pomoću gumba, a za testiranje - automatski.
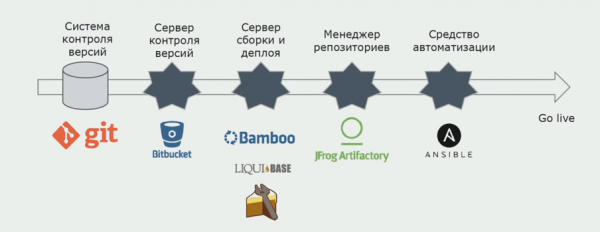
Koristimo Atlassian, Bitbucket za pohranu izvornog koda i Bamboo za izgradnju. Volimo pisati skripte za izgradnju u Cakeu jer je isti kao C#. Gotovi paketi dolaze u Artifactory, a Ansible automatski dolazi do testnih servera, nakon čega se odmah mogu testirati.
Odvojeno bilježenje
Nekada je jedna od ideja monolita bila omogućiti zajedničku sječu. Također smo morali razumjeti što učiniti s pojedinačnim zapisnicima koji su na diskovima. Naši su zapisnici zapisani u tekstualne datoteke. Odlučili smo koristiti standardni ELK stog. Nismo pisali ELK-u izravno preko pružatelja usluga, ali smo odlučili modificirati tekstualne zapisnike i upisati ID praćenja u njih kao identifikator, dodajući naziv usluge, tako da se ti zapisnici kasnije mogu analizirati.
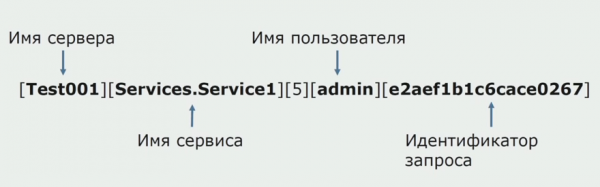
Pomoću Filebeata možemo prikupljati naše logove iz poslužitelji, zatim ih transformirajte, koristite Kibanu za izradu upita u korisničkom sučelju i pogledajte kako je poziv usmjeravan između servisa. ID-ovi praćenja su vrlo korisni za to.
Usluge povezane s testiranjem i otklanjanjem pogrešaka
U početku nismo u potpunosti razumjeli kako otkloniti pogreške u uslugama koje se razvijaju. S monolitom je sve bilo jednostavno; pokrenuli smo ga na lokalnom računalu. Isprva su pokušali učiniti isto s mikrouslugama, ali ponekad za potpuno pokretanje jedne mikrousluge morate pokrenuti nekoliko drugih, a to je nezgodno. Shvatili smo da se moramo prebaciti na model u kojem na lokalnom računalu ostavljamo samo uslugu ili usluge koje želimo otkloniti. Preostale usluge koriste se s poslužitelja koji odgovaraju konfiguraciji s prod. Nakon otklanjanja pogrešaka, tijekom testiranja, za svaki zadatak testnom poslužitelju se izdaju samo promijenjene usluge. Dakle, rješenje se testira u obliku u kojem će se u budućnosti pojaviti u proizvodnji.
Postoje poslužitelji koji pokreću samo proizvodne verzije usluga. Ti su poslužitelji potrebni u slučaju incidenata, za provjeru isporuke prije postavljanja i za internu obuku.
Dodali smo automatizirani postupak testiranja pomoću popularne biblioteke Specflow. Testovi se pokreću automatski koristeći NUnit odmah nakon implementacije iz Ansiblea. Ako je pokrivenost zadatka potpuno automatska, tada nema potrebe za ručnim testiranjem. Iako je ponekad još uvijek potrebno dodatno ručno testiranje. Koristimo oznake u Jiri kako bismo odredili koje testove pokrenuti za određeni problem.
Dodatno, povećana je potreba za testiranjem opterećenja; prije se ono provodilo samo u rijetkim slučajevima. Koristimo JMeter za pokretanje testova, InfluxDB za njihovo pohranjivanje i Grafanu za izradu grafova procesa.
Što smo postigli?
Prvo, riješili smo se pojma "otpuštanje". Nestala su dvomjesečna monstruozna izdanja kada je ovaj kolos bio raspoređen u proizvodnom okruženju, privremeno ometajući poslovne procese. Sada implementiramo usluge u prosjeku svakih 1,5 dan, grupiramo ih jer kreću u rad nakon odobrenja.
U našem sustavu nema fatalnih kvarova. Ako objavimo mikroservis s greškom, tada će funkcionalnost povezana s njim biti prekinuta, a sve druge funkcije neće biti pogođene. Ovo uvelike poboljšava korisničko iskustvo.
Možemo kontrolirati obrazac postavljanja. Po potrebi možete odabrati grupe usluga odvojeno od ostatka rješenja.
Osim toga, značajno smo smanjili problem s velikim nizom poboljšanja. Sada imamo zasebne timove za proizvode koji neovisno rade s nekim uslugama. Scrum proces već dobro pristaje ovdje. Određeni tim može imati zasebnog vlasnika proizvoda koji mu dodjeljuje zadatke.
Rezime
- Mikroservisi su prikladni za dekompoziciju složenih sustava. U tom procesu počinjemo shvaćati što je u našem sustavu, koji ograničeni konteksti postoje, gdje leže njihove granice. To vam omogućuje ispravnu distribuciju poboljšanja među modulima i sprječavanje zabune koda.
- Mikroservisi pružaju organizacijske prednosti. Često se o njima govori samo kao o arhitekturi, no svaka je arhitektura potrebna za rješavanje poslovnih potreba, a ne sama za sebe. Stoga možemo reći da su mikroservisi prikladni za rješavanje problema u malim timovima, s obzirom da je Scrum sada vrlo popularan.
- Odvajanje je ponavljajući proces. Ne možete uzeti aplikaciju i jednostavno je podijeliti na mikroservise. Malo je vjerojatno da će dobiveni proizvod biti funkcionalan. Kod namjene mikroservisa korisno je prepisati postojeće nasljeđe, odnosno pretvoriti ga u kod koji nam se sviđa i koji bolje zadovoljava poslovne potrebe u smislu funkcionalnosti i brzine.
Malo upozorenje: Troškovi prelaska na mikroservise prilično su značajni. Samo za rješavanje problema infrastrukture trebalo je dosta vremena. Dakle, ako imate malu aplikaciju koja ne zahtijeva posebno skaliranje, osim ako nemate veliki broj korisnika koji se natječu za pažnju i vrijeme vašeg tima, mikroservisi možda nisu ono što vam danas treba. Prilično je skupo. Ako proces započnete s mikroservisima, tada će troškovi u početku biti veći nego ako isti projekt započnete s razvojem monolita.
PS Emotivnija priča (i kao za vas osobno) - prema .
Ovdje je potpuna verzija izvješća.
Izvor: www.habr.com
