

Mint a , probléma van egy elosztott szolgáltatással, nevezzük ezt a szolgáltatást Alvinnak. Ezúttal nem magam fedeztem fel a problémát, tájékoztattak az ügyféloldali srácok.
Egy nap egy elégedetlen e-mailre ébredtem az Alvinnal való hosszú késések miatt, amelyet a közeljövőben terveztünk elindítani. Pontosabban, az ügyfél a 99. percentilis késleltetést 50 ms körüli tartományban tapasztalta, ami jóval meghaladja a várakozási időkeretünket. Ez meglepő volt, mivel alaposan teszteltem a szolgáltatást, különösen a késleltetést illetően, ami gyakori panasz.
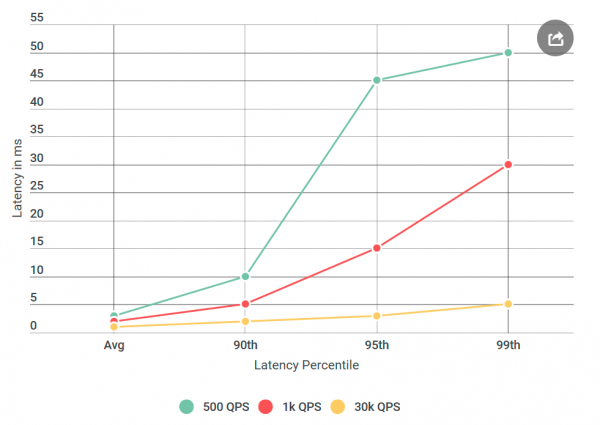
Mielőtt az Alvint teszteltem volna, sok kísérletet futtattam 40 10 lekérdezéssel másodpercenként (QPS), amelyek mindegyike 40 ms-nál kevesebb késleltetést mutatott. Kész voltam kijelenteni, hogy nem értek egyet az eredményeikkel. Ám ha még egyszer megnézem a levelet, valami újat vettem észre: nem teszteltem pontosan az általuk említett körülményeket, a QPS-jük jóval alacsonyabb volt, mint az enyém. Én 1 ezer QPS-en teszteltem, de ők csak XNUMX ezernél. Futtattam egy másik kísérletet, ezúttal alacsonyabb QPS-sel, hogy megnyugtassam őket.
Mióta blogolok erről, valószínűleg már rájöttél, hogy a számuk helyes. Újra és újra teszteltem a virtuális kliensemet, ugyanazzal az eredménnyel: az alacsony kérések száma nemcsak a késleltetést növeli, hanem a 10 ms-nál hosszabb késleltetésű kérések számát is. Más szóval, ha 40k QPS-nél körülbelül 50 kérés másodpercenként haladta meg az 50 ms-ot, akkor 1k QPS-nél másodpercenként 100 kérés volt 50 ms felett. Paradoxon!
A keresés szűkítése
Ha késleltetési problémával szembesül egy sok összetevőt tartalmazó elosztott rendszerben, az első lépés a gyanúsítottak rövid listájának létrehozása. Nézzünk egy kicsit mélyebbre Alvin építészetében:
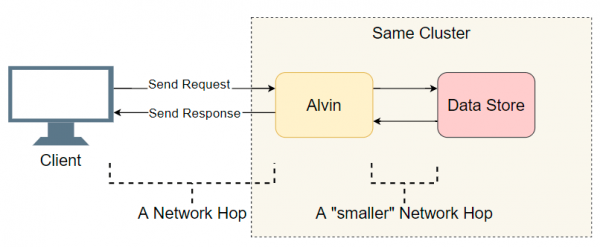
Jó kiindulópont a befejezett I/O átmenetek listája (hálózati hívások/lemezkeresések stb.). Próbáljuk kitalálni, hol van a késés. A klienssel való nyilvánvaló I/O mellett Alvin egy további lépést tesz: hozzáfér az adattárhoz. Ez a tároló azonban ugyanabban a fürtben működik, mint az Alvin, így a késleltetésnek kisebbnek kell lennie, mint az ügyfélnél. Tehát a gyanúsítottak listája:
- Hálózati hívás az ügyféltől Alvin felé.
- Hálózati hívás Alvintól az adattárba.
- Keresés a lemezen az adattárban.
- Hálózati hívás az adattárházból Alvinhoz.
- Hálózati hívás Alvintól egy ügyfélhez.
Próbáljunk meg néhány pontot áthúzni.
Az adattárolásnak ehhez semmi köze
Az első dolgom az volt, hogy az Alvint ping-ping szerverré alakítottam, amely nem dolgozza fel a kéréseket. Amikor kérést kap, üres választ ad vissza. Ha a várakozási idő csökken, akkor az Alvin vagy az adattárház megvalósításának hibája nem hallatlan. Az első kísérletben a következő grafikont kapjuk:
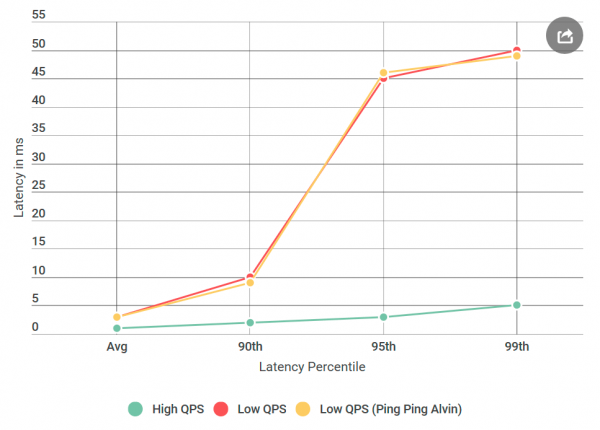
Mint látható, a ping-ping szerver használatakor nincs javulás. Ez azt jelenti, hogy az adattárház nem növeli a késleltetést, és a gyanúsítottak listája felére csökken:
- Hálózati hívás az ügyféltől Alvin felé.
- Hálózati hívás Alvintól egy ügyfélhez.
Nagy! A lista gyorsan zsugorodik. Azt hittem, már majdnem rájöttem az okára.
gRPC
Itt az ideje, hogy bemutassunk egy új játékost: . Ez a Google nyílt forráskódú könyvtára a folyamat közbeni kommunikációhoz . bár gRPC jól optimalizált és széles körben használt, ez volt az első alkalom, hogy ekkora rendszeren használtam, és arra számítottam, hogy a megvalósításom enyhén szólva nem lesz optimális.
elérhetőség gRPC a veremben egy új kérdés merült fel: talán az én megvalósításom vagy én magam gRPC késleltetési problémát okoz? Új gyanúsított felvétele a listára:
- Az ügyfél felhívja a könyvtárat
gRPC - könyvtár
gRPChálózati hívást kezdeményez a kliens könyvtárábagRPCa szerveren - könyvtár
gRPCkapcsolattartó Alvin (ping-pong szerver esetén nincs művelet)
Hogy képet adjunk arról, hogyan néz ki a kód, az én kliens/Alvin implementációm nem sokban különbözik a kliens-szervertől .
Megjegyzés: A fenti lista kissé leegyszerűsített, mert
gRPClehetővé teszi a saját (sablon?) szálfűzési modell használatát, amelyben a végrehajtási verem összefonódikgRPCés a felhasználói megvalósítás. Az egyszerűség kedvéért maradunk ennél a modellnél.
A profilozás mindent megold
Miután áthúztam az adattárakat, azt hittem, már majdnem kész vagyok: „Most már könnyű! Alkalmazzuk a profilt, és derítsük ki, hol van a késés.” én , mert a CPU-k nagyon gyorsak, és legtöbbször nem jelentik a szűk keresztmetszetet. A legtöbb késés akkor fordul elő, amikor a processzornak le kell állítania a feldolgozást, hogy valami mást tegyen. Az Accuracy CPU Profiling pont ezt teszi: mindent pontosan rögzít és egyértelművé teszi, hol fordulnak elő késések.
Négy profilt választottam: magas QPS-sel (alacsony késleltetéssel) és egy ping-pong szerverrel alacsony QPS-sel (magas késleltetéssel), mind a kliens, mind a szerver oldalon. És minden esetre vettem egy minta processzorprofilt is. A profilok összehasonlításakor általában egy rendellenes hívási veremre figyelek. Például a magas késleltetésű rossz oldalon sokkal több környezeti kapcsoló van (10-szer vagy többször). De az én esetemben a kontextusváltások száma majdnem ugyanannyi volt. Rémületemre nem volt ott semmi jelentős.
További hibakeresés
kétségbeesett voltam. Nem tudtam, milyen egyéb eszközöket használhatok, és a következő tervem lényegében az volt, hogy megismételjem a kísérleteket különböző változatokkal, ahelyett, hogy egyértelműen diagnosztizálnám a problémát.
Mi van ha
Kezdettől fogva aggódtam a konkrét 50 ms-os késleltetés miatt. Ez egy nagyon nagy idő. Úgy döntöttem, hogy darabokat vágok ki a kódból, amíg ki nem találom, hogy pontosan melyik rész okozza ezt a hibát. Aztán jött egy kísérlet, ami bevált.
Mint általában, utólag úgy tűnik, minden nyilvánvaló volt. A klienst ugyanarra a gépre helyeztem, mint az Alvint – és elküldtem egy kérést localhost. És a látencia növekedése elmúlt!
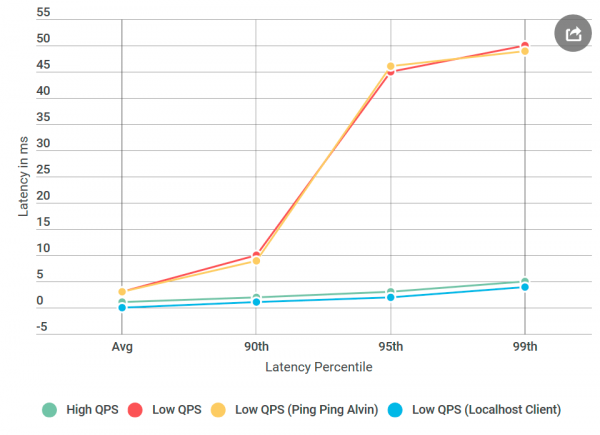
Valami nem stimmelt a hálózattal.
Hálózatmérnöki ismeretek elsajátítása
Be kell vallanom: a hálózati technológiákkal kapcsolatos tudásom borzasztó, főleg, ha figyelembe vesszük, hogy minden nap dolgozom velük. De a hálózat volt az elsődleges gyanúsított, és meg kellett tanulnom a hibakeresést.
Szerencsére az internet szereti a tanulni vágyókat. A ping és a tracert kombinációja elég jó kezdetnek tűnt a hálózati szállítási problémák hibakereséséhez.
Először is elindítottam Alvin TCP portjára. Az alapértelmezett beállításokat használtam - semmi különös. A több mint ezer ping közül egyik sem haladta meg a 10 ms-t, kivéve az elsőt a bemelegítésnél. Ez ellentétes a 50. percentilisnél megfigyelt 99 ms-os késleltetés növekedésével: ott minden 100 kérés után körülbelül egy kérést kellett volna látnunk 50 ms-os késleltetéssel.
Aztán megpróbáltam : Probléma lehet az Alvin és az ügyfél közötti útvonal egyik csomópontjában. De a nyomkövető is üres kézzel tért vissza.
Tehát nem az én kódom, a gRPC implementáció vagy a hálózat okozta a késést. Kezdtem aggódni, hogy ezt soha nem fogom megérteni.
Most milyen operációs rendszert használunk
gRPC széles körben használják Linux, de azért Windows Ez egzotikus. Úgy döntöttem, hogy elvégzek egy kísérletet, ami működik: létrehoztam egy virtuális gépet. Linux, összeállította az Alvint a következőhöz: Linux és kibontotta.
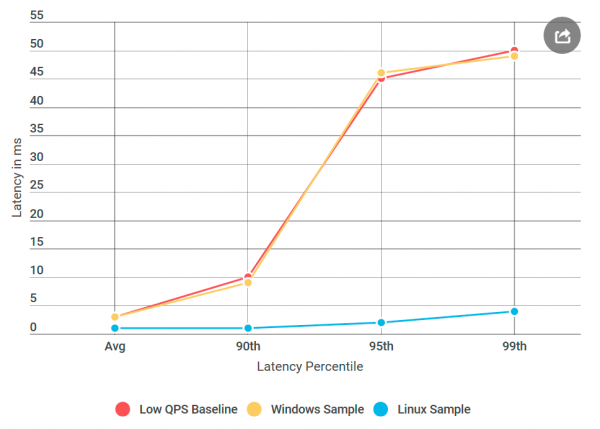
És ez történt: a pingpong szerveren Linux nem voltak késések, mint egy hasonló csomópontnál Windows, bár az adatforrás ugyanaz volt. Kiderült, hogy a probléma a gRPC implementációjában van a következőhöz: Windows.
Nagle algoritmusa
Egész idő alatt azt hittem, hiányzik egy zászló gRPC. Most már értem, mi is ez valójában gRPC a zászló hiányzik WindowsTaláltam egy belső RPC könyvtárat, amiről biztos voltam benne, hogy jól fog működni az összes beállított jelző esetén. Ezután hozzáadtam ezeket a jelzőket a gRPC-hez, és telepítettem Alvint a következőre: Windows, a fix pingpong szerverben alatt Windows!
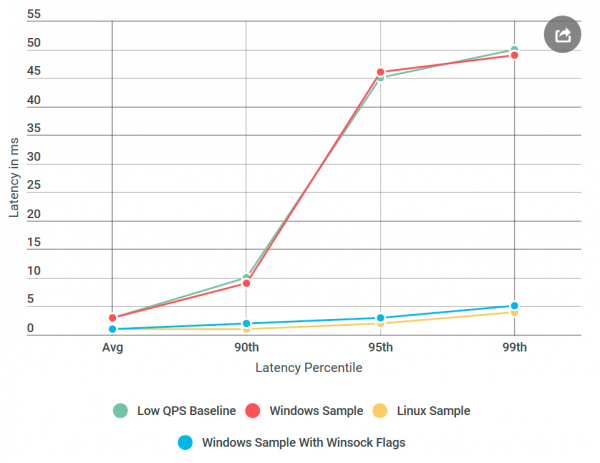
csaknem Kész: Elkezdtem egyenként eltávolítani a hozzáadott jelzőket, amíg a regresszió vissza nem tért, hogy pontosan meghatározhassam az okot. Hírhedt volt , Nagle algoritmus kapcsolója.
megpróbálja csökkenteni a hálózaton keresztül elküldött csomagok számát az üzenetek továbbításának késleltetésével, amíg a csomag mérete meg nem halad egy bizonyos számú bájtot. Bár ez kellemes lehet az átlagfelhasználók számára, romboló hatású a valós idejű szerverek számára, mivel az operációs rendszer késlelteti az üzeneteket, ami késéseket okoz az alacsony QPS-nél. U gRPC ezt a jelzőt a megvalósításban állították be Linux TCP socketekhez, de nem WindowsÉn vagyok ez .
Következtetés
Az alacsony QPS melletti magasabb késleltetést az operációs rendszer optimalizálása okozta. Utólag visszatekintve a profilalkotás nem észlelte a késleltetést, mert kernel módban történt, nem pedig benne . Nem tudom, hogy a Nagle algoritmusa megfigyelhető-e ETW rögzítéseken keresztül, de érdekes lenne.
Ami a localhost kísérletet illeti, valószínűleg nem érintette a tényleges hálózati kódot, és a Nagle algoritmusa nem futott, így a késleltetési problémák megszűntek, amikor a kliens a localhost-on keresztül elérte az Alvint.
A következő alkalommal, amikor a várakozási idő növekedését tapasztalja, ahogy a másodpercenkénti kérések száma csökken, a Nagle algoritmusának szerepelnie kell a gyanúsítottak listáján!
Forrás: will.com
