

Ebben a cikkben arról fogok beszélni, hogy a projekt, amelyen dolgozom, hogyan alakult át egy nagy monolitból mikroszolgáltatások készletévé.
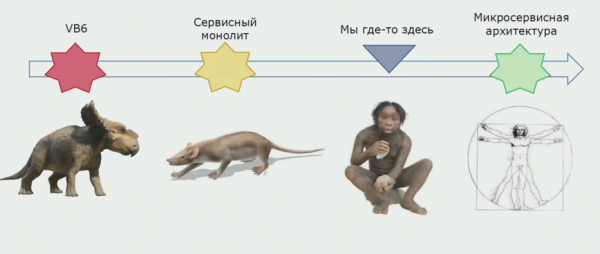
A projekt története meglehetősen régen, 2000 elején kezdődött. Az első verziók Visual Basic 6-ban készültek. Idővel világossá vált, hogy ezen a nyelven a fejlesztést a jövőben nehéz lesz támogatni, mivel az IDE és maga a nyelv is gyengén fejlett. A 2000-es évek végén elhatározták, hogy az ígéretesebb C#-ra váltanak. Az új verzió a régi átdolgozásával párhuzamosan készült, fokozatosan egyre több kód került .NET-be. A C# háttérrendszere eleinte szolgáltatásarchitektúrára összpontosított, de a fejlesztés során közös logikát tartalmazó könyvtárakat használtak, és a szolgáltatások egyetlen folyamatban indultak el. Az eredmény egy olyan alkalmazás lett, amelyet „szolgáltatási monolitnak” neveztünk.
Ennek a kombinációnak az egyik előnye az volt, hogy a szolgáltatások külső API-n keresztül hívhatják egymást. Egy korrektebb szolgáltatásra, a jövőben pedig mikroszolgáltatási architektúrára való átállásnak egyértelmű előfeltételei voltak.
A dekompozícióval kapcsolatos munkánkat 2015 körül kezdtük meg. Még nem jutottunk el az ideális állapothoz - vannak még egy nagy projektnek olyan részei, amelyeket aligha lehet monolitnak nevezni, de ezek sem tűnnek mikroszolgáltatásnak. Ennek ellenére az előrelépés jelentős.
A cikkben fogok beszélni róla.
Tartalom
A meglévő megoldás felépítése és problémái
Az architektúra kezdetben a következőképpen nézett ki: a felhasználói felület egy külön alkalmazás, a monolitikus rész Visual Basic 6-ban van írva, a .NET alkalmazás egy meglehetősen nagy adatbázissal működő kapcsolódó szolgáltatások halmaza.
Az előző megoldás hátrányai
Egyetlen meghibásodási pont
Egyetlen hibapontunk volt: a .NET alkalmazás egyetlen folyamatban futott. Ha valamelyik modul meghibásodott, az egész alkalmazás meghiúsult, és újra kellett indítani. Mivel számos folyamatot automatizálunk különböző felhasználók számára, az egyik meghibásodása miatt egy ideig mindenki nem tudott dolgozni. És szoftverhiba esetén még a biztonsági mentés sem segített.
A fejlesztések sora
Ez a hátrány inkább szervezési jellegű. Alkalmazásunknak sok ügyfele van, és mindannyian szeretnék a lehető leghamarabb javítani. Korábban ezt nem lehetett párhuzamosan megtenni, és minden ügyfél sorban állt. Ez a folyamat negatív volt a vállalkozások számára, mert bizonyítaniuk kellett, hogy a feladatuk értékes. A fejlesztőcsapat pedig időt töltött a sor megszervezésével. Ez sok időt és erőfeszítést igényel, és a termék végül nem tudott olyan gyorsan megváltozni, ahogyan azt szerették volna.
Az erőforrások nem optimális felhasználása
A szolgáltatások egyetlen folyamatban történő tárolása során mindig teljes mértékben átmásoltuk a konfigurációt szerverről szerverre. A legterheltebb szolgáltatásokat külön akartuk elhelyezni, hogy ne pazaroljuk az erőforrásokat, és rugalmasabb irányítást szerezzünk a telepítési rendszerünk felett.
Nehéz megvalósítani a modern technológiákat
Minden fejlesztő számára ismerős probléma: vágynak a modern technológiák bevezetésére a projektbe, de nincs lehetőség. Egy nagyméretű monolitikus megoldással a jelenlegi könyvtár minden frissítése, nem beszélve az újra való átállásról, meglehetősen nem triviális feladattá válik. Sok időbe telik bebizonyítani a csapatvezetőnek, hogy ez több bónuszt fog hozni, mint elvesztegetett idegeket.
A változtatások kiadásának nehézségei
Ez volt a legsúlyosabb probléma – kéthavonta adtunk ki kiadásokat.
A fejlesztők tesztelése és erőfeszítései ellenére minden kiadás valódi katasztrófává vált a bank számára. A vállalkozás megértette, hogy a hét elején egyes funkciói nem működnek. És a fejlesztők megértették, hogy egy hét súlyos incidens vár rájuk.
Mindenki vágyott a helyzet megváltoztatására.
Elvárások a mikroszolgáltatásokkal szemben
Az alkatrészek problémája, ha készen áll. A komponensek készenléti kiszállítása az oldat lebontásával és a különböző folyamatok szétválasztásával.
Kis termékcsapatok. Ez azért fontos, mert a régi monoliton dolgozó nagy csapatot nehéz volt kezelni. Egy ilyen csapat szigorú folyamatok szerint kénytelen volt dolgozni, de több kreativitásra és függetlenségre vágytak. Ezt csak kis csapatok engedhették meg maguknak.
A szolgáltatások elkülönítése külön folyamatokban. Ideális esetben konténerekben szeretném elkülöníteni, de a .NET-keretrendszerben írt szolgáltatások nagy része csak a következő alatt fut: WindowsA .NET Core-on alapuló szolgáltatások most jelennek meg, de még mindig kevés van belőlük.
A telepítés rugalmassága. A szolgáltatásokat úgy szeretnénk kombinálni, ahogyan szükségünk van rá, és nem úgy, ahogy a kód kényszeríti.
Új technológiák alkalmazása. Ez minden programozó számára érdekes.
Átmeneti problémák
Persze ha könnyű lenne egy monolitot mikroszolgáltatásokra bontani, akkor nem kellene erről konferenciákon beszélni, cikkeket írni. Ennek a folyamatnak számos buktatója van, leírom a főbbeket, amelyek akadályoztak bennünket.
Az első probléma a legtöbb monolitra jellemző: az üzleti logika koherenciája. Amikor monolitot írunk, újra szeretnénk használni az osztályainkat, hogy ne írjunk felesleges kódot. A mikroszolgáltatásokra való átálláskor pedig ez gondot okoz: az összes kód meglehetősen szorosan kapcsolódik, és nehéz szétválasztani a szolgáltatásokat.
A munka megkezdésekor több mint 500 projekttel és több mint 700 ezer kódsorral rendelkezett a repository. Ez elég nagy döntés és második probléma. Nem lehetett egyszerűen átvenni és mikroszolgáltatásokra osztani.
Harmadik probléma — a szükséges infrastruktúra hiánya. Valójában manuálisan másoltuk a forráskódot a szerverekre.
Hogyan térjünk át a monolitról a mikroszolgáltatásokra
Mikroszolgáltatások biztosítása
Először is azonnal megállapítottuk, hogy a mikroszolgáltatások szétválasztása iteratív folyamat. Mindig megkívánták, hogy párhuzamosan dolgozzuk ki az üzleti problémákat. Az már a mi problémánk, hogy ezt hogyan fogjuk technikailag megvalósítani. Ezért egy iteratív folyamatra készültünk. Ez nem fog másképpen működni, ha nagy alkalmazásod van, és kezdetben nem áll készen az újraírásra.
Milyen módszereket alkalmazunk a mikroszolgáltatások elkülönítésére?
Az első út — a meglévő modulok szolgáltatásként való áthelyezése. Ebben a tekintetben szerencsénk volt: voltak már regisztrált szolgáltatások, amelyek WCF protokollal működtek. Külön szerelvényekre osztották őket. Külön portoltuk őket, és minden buildhez hozzáadtunk egy kis indítót. A csodálatos Topshelf könyvtár segítségével készült, amely lehetővé teszi az alkalmazás szolgáltatásként és konzolként történő futtatását. Ez kényelmes a hibakereséshez, mivel nincs szükség további projektekre a megoldásban.
A szolgáltatások üzleti logika szerint kapcsolódtak össze, mivel közös összeállításokat használtak és közös adatbázissal dolgoztak. Tiszta formájukban aligha nevezhetők mikroszolgáltatásoknak. Ezeket a szolgáltatásokat azonban külön-külön, különböző folyamatokban tudnánk nyújtani. Ez önmagában lehetővé tette egymásra gyakorolt befolyásuk csökkentését, csökkentve a problémát párhuzamos fejlesztéssel és egyetlen hibaponttal.
Az összeszerelés a gazdagéppel csak egy kódsor a Program osztályban. A Topshelffel elrejtettük a munkát egy kisegítő osztályban.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
A mikroszolgáltatások kiosztásának második módja: létrehozni őket új problémák megoldására. Ha ugyanakkor a monolit nem növekszik, az már kiváló, ami azt jelenti, hogy jó irányba haladunk. Az új problémák megoldására külön szolgáltatásokat próbáltunk létrehozni. Ha volt ilyen lehetőség, akkor több „kanonikus” szolgáltatásokat hoztunk létre, amelyek teljesen saját adatmodellt kezelnek, külön adatbázist.
Sokakhoz hasonlóan mi is a hitelesítési és engedélyezési szolgáltatásokkal kezdtük. Erre tökéletesek. Függetlenek, általában külön adatmodellel rendelkeznek. Ők maguk nem lépnek kapcsolatba a monolittal, csak az hozzájuk fordul, hogy megoldjon néhány problémát. Ezekkel a szolgáltatásokkal megkezdheti az átállást egy új architektúrára, hibakeresést végezhet rajtuk az infrastruktúrában, kipróbálhat néhány hálózati könyvtárhoz kapcsolódó megközelítést stb. Szervezetünkben nincs olyan csapat, amely ne tudna hitelesítési szolgáltatást létrehozni.
A mikroszolgáltatások kiosztásának harmadik módjaAz általunk használt egy kicsit ránk jellemző. Ez az üzleti logika eltávolítása a felhasználói felület rétegéből. Fő felhasználói felületünk az asztali, amely a háttérhez hasonlóan C# nyelven íródott. A fejlesztők időnként hibákat követtek el, és a logika részeit átvitték a felhasználói felületre, amelyeknek a háttérben kellett volna lenniük, és újra fel kellett volna használni őket.
Ha megnézünk egy valós példát az UI rész kódjából, láthatjuk, hogy ennek a megoldásnak a nagy része valós üzleti logikát tartalmaz, amely más folyamatokban is hasznos, nem csak az UI űrlap felépítéséhez.
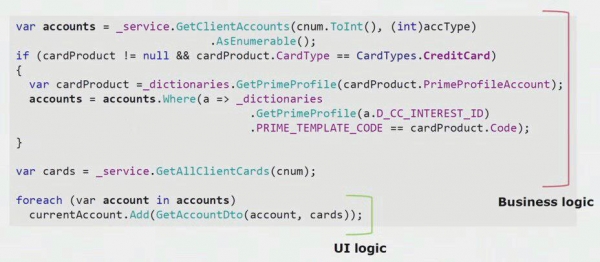
Az igazi UI logika csak az utolsó pár sorban van. Átvittük a szerverre, hogy újra felhasználható legyen, ezáltal csökkentve a felhasználói felületet és elérjük a megfelelő architektúrát.
A mikroszolgáltatások elkülönítésének negyedik és legfontosabb módja, amely lehetővé teszi a monolit csökkentését, a meglévő szolgáltatások eltávolítása feldolgozással. Ha a meglévő modulokat úgy vesszük ki, ahogy vannak, az eredmény nem mindig tetszik a fejlesztőknek, és előfordulhat, hogy az üzleti folyamat elavulttá vált a funkcionalitás létrehozása óta. A refaktoring segítségével egy új üzleti folyamatot támogathatunk, mert az üzleti követelmények folyamatosan változnak. Javíthatjuk a forráskódot, eltávolíthatjuk az ismert hibákat, és jobb adatmodellt hozhatunk létre. Számos előny halmozódik fel.
A szolgáltatások elválasztása a feldolgozástól elválaszthatatlanul kapcsolódik a korlátozott kontextus fogalmához. Ez a Domain Driven Design koncepciója. Ez a tartománymodell egy részét jelenti, amelyben egyetlen nyelv összes kifejezése egyedileg definiálva van. Példaként nézzük meg a biztosítás és a számlák összefüggéseit. Egy monolitikus alkalmazásunk van, és a biztosítási számlával kell dolgoznunk. Arra számítunk, hogy a fejlesztő talál egy meglévő fiókosztályt egy másik összeállításban, hivatkozzon rá a Biztosítás osztályból, és akkor már működő kódunk lesz. A DRY elvet tiszteletben tartják, a feladat gyorsabban fog elvégezni a meglévő kód használatával.
Ennek eredményeként kiderül, hogy a számlák és a biztosítás összefüggései összefüggenek. Amint új követelmények jelennek meg, ez az összekapcsolás megzavarja a fejlesztést, növelve az amúgy is összetett üzleti logika összetettségét. A probléma megoldásához meg kell találnia a kontextusok közötti határokat a kódban, és el kell távolítania azok megsértését. Például a biztosítási összefüggésben teljesen lehetséges, hogy egy 20 jegyű jegybanki számlaszám és a számlanyitás dátuma elegendő.
Ahhoz, hogy ezeket a korlátozott kontextusokat elkülönítsük egymástól, és megkezdjük a mikroszolgáltatások monolitikus megoldástól való elkülönítésének folyamatát, olyan megközelítést alkalmaztunk, mint például külső API-k létrehozása az alkalmazáson belül. Ha tudtuk, hogy valamilyen modulból mikroszolgáltatássá kell válnia, a folyamaton belül valahogyan módosulva, akkor külső hívásokon keresztül azonnal meghívtuk azt a logikát, amely egy másik korlátozott kontextushoz tartozik. Például a REST-en vagy a WCF-en keresztül.
Határozottan úgy döntöttünk, hogy nem kerüljük el az elosztott tranzakciókat igénylő kódot. A mi esetünkben elég könnyűnek bizonyult betartani ezt a szabályt. Még nem találkoztunk olyan helyzetekkel, amikor valóban szükség lenne szigorú elosztott tranzakciókra - a modulok közötti végső konzisztencia elégséges.
Nézzünk egy konkrét példát. Megvan az orchestrator fogalma – egy folyamat, amely feldolgozza az „alkalmazás” entitását. Felváltva létrehoz egy ügyfelet, egy számlát és egy bankkártyát. Ha az ügyfél és a számla létrehozása sikeresen megtörtént, de a kártya létrehozása sikertelen, az alkalmazás nem lép „sikeres” állapotba, és a „kártya nincs létrehozva” állapotban marad. A jövőben a háttértevékenység felveszi és befejezi. A rendszer egy ideje inkonzisztens állapotban van, de általában elégedettek vagyunk ezzel.
Ha olyan helyzet adódik, amikor az adatok egy részének következetes mentése szükséges, akkor nagy valószínűséggel a szolgáltatás konszolidációját fogjuk igénybe venni, hogy egy folyamatban dolgozzuk fel azokat.
Nézzünk egy példát a mikroszolgáltatás kiosztására. Hogyan lehet viszonylag biztonságosan gyártásba vinni? Ebben a példában a rendszernek van egy külön része - egy bérszámfejtési szolgáltatási modul, melynek egyik kódrészét szeretnénk mikroszolgáltatást készíteni.
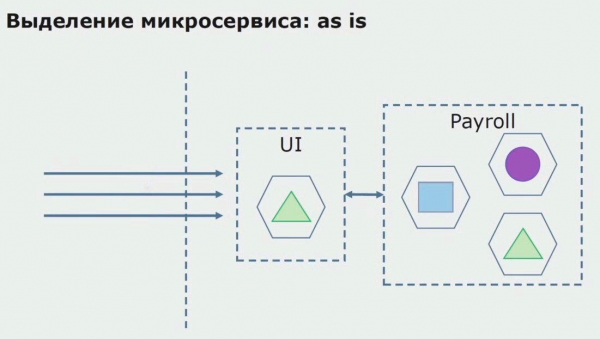
Először is létrehozunk egy mikroszolgáltatást a kód átírásával. Javítunk néhány szempontot, amelyekkel nem voltunk elégedettek. Új üzleti igényeket valósítunk meg az ügyfél részéről. Hozzáadunk egy API-átjárót a felhasználói felület és a háttérrendszer közötti kapcsolathoz, amely hívástovábbítást biztosít.
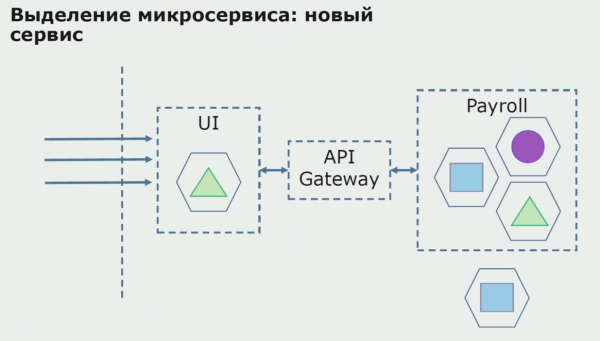
Ezután ezt a konfigurációt üzembe helyezzük, de kísérleti állapotban. Felhasználóink többsége még mindig régi üzleti folyamatokkal dolgozik. Az új felhasználók számára a monolitikus alkalmazás új verzióját fejlesztjük, amely már nem tartalmazza ezt a folyamatot. Lényegében egy monolit és egy mikroszolgáltatás kombinációja működik pilótaként.
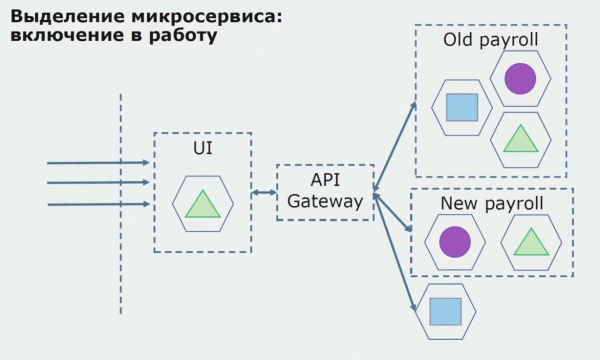
Egy sikeres pilot esetén megértjük, hogy az új konfiguráció valóban működőképes, eltávolíthatjuk a régi monolitot az egyenletből, és az új konfigurációt hagyhatjuk a régi megoldás helyén.
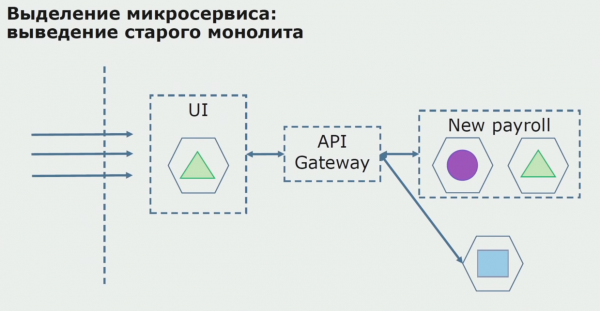
Összességében szinte az összes létező módszert használjuk a monolit forráskódjának felosztására. Mindegyik lehetővé teszi számunkra, hogy csökkentsük az alkalmazás egyes részeinek méretét, és lefordítsuk azokat új könyvtárakba, ezáltal jobb forráskódot készítve.
Munka az adatbázissal
Az adatbázis rosszabbul osztható, mint a forráskód, hiszen nem csak az aktuális sémát, hanem a felhalmozott történeti adatokat is tartalmazza.
Adatbázisunknak, mint sok másnak, volt még egy fontos hátránya - hatalmas mérete. Ez az adatbázis egy monolit bonyolult üzleti logikája és a különféle korlátos kontextusok táblái között felhalmozott kapcsolatok alapján készült.
Esetünkben a bajok tetejébe (nagy adatbázis, sok kapcsolat, néha tisztázatlan határok a táblák között) felvetődött egy sok nagy projektben előforduló probléma: a megosztott adatbázis-sablon használata. Az adatokat a táblákból a nézeten keresztül, a replikáción keresztül vettük át, és más rendszerekbe szállították, ahol erre a replikációra szükség volt. Ennek eredményeként a táblákat nem tudtuk külön sémába helyezni, mert aktívan használták őket.
Ugyanez a kód korlátozott kontextusokra való felosztása segít az elkülönítésben. Általában elég jó képet ad arról, hogyan bontjuk le az adatokat adatbázis szinten. Megértjük, hogy mely táblák tartoznak az egyik korlátos kontextushoz, és melyek a másikhoz.
Az adatbázis-particionálás két globális módszerét alkalmaztuk: a meglévő táblák particionálását és a feldolgozással történő particionálást.
A meglévő táblák szétválasztása akkor jó módszer, ha az adatstruktúra jó, megfelel az üzleti követelményeknek, és mindenki elégedett vele. Ebben az esetben a meglévő táblákat külön sémára különíthetjük el.
Feldolgozó részlegre akkor van szükség, amikor az üzleti modell nagyot változott, és a táblázatok már egyáltalán nem elégítenek ki bennünket.
Meglévő táblák felosztása. Meg kell határoznunk, hogy mit fogunk szétválasztani. Ezen ismeretek nélkül semmi sem fog működni, és itt a kódban a korlátos kontextusok szétválasztása lesz segítségünkre. Általános szabály, hogy ha megérti a forráskód kontextusainak határait, világossá válik, hogy mely táblákat kell felvenni a részleg listájába.
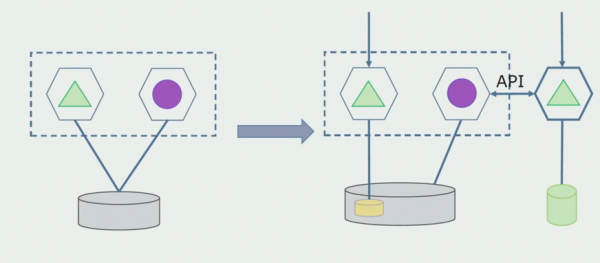
Képzeljük el, hogy van egy megoldásunk, amelyben két monolit modul kölcsönhatásba lép egy adatbázissal. Gondoskodnunk kell arról, hogy csak az egyik modul kommunikáljon az elválasztott táblák részével, a másik pedig az API-n keresztül kezdjen kapcsolatba lépni vele. Először is elég, ha csak a rögzítést végzik az API-n keresztül. Ez szükséges feltétele annak, hogy a mikroszolgáltatások függetlenségéről beszéljünk. Az olvasási kapcsolatok mindaddig megmaradhatnak, amíg nincs nagy probléma.
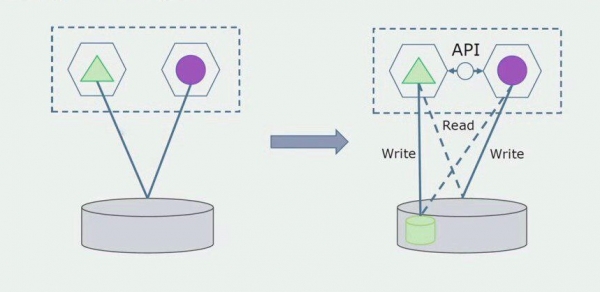
A következő lépés az, hogy az elkülönített táblákkal működő kódszakaszt, feldolgozással vagy anélkül, egy külön mikroszolgáltatásba különíthetjük el, és egy külön folyamatban, egy konténerben futtathatjuk. Ez egy külön szolgáltatás lesz, amely kapcsolódik a monolit adatbázishoz és azokhoz a táblákhoz, amelyek nem kapcsolódnak közvetlenül hozzá. A monolit továbbra is kölcsönhatásban van az olvasás során a levehető résszel.
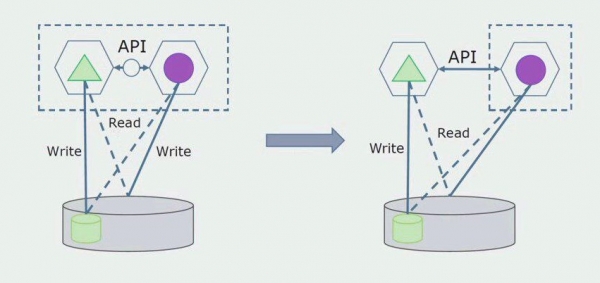
Később ezt a kapcsolatot eltávolítjuk, vagyis a monolitikus alkalmazásból elkülönített táblákból kiolvasott adatok is átkerülnek az API-ba.
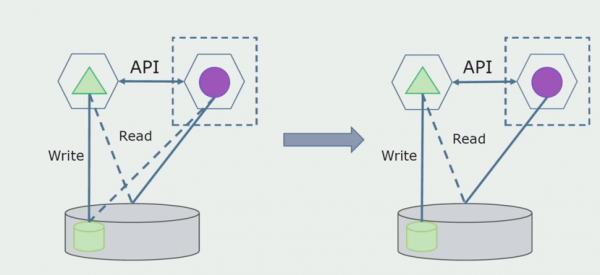
Ezután az általános adatbázisból kiválasztjuk azokat a táblákat, amelyekkel csak az új mikroszolgáltatás működik. A táblákat áthelyezhetjük külön sémába, vagy akár külön fizikai adatbázisba is. Továbbra is van olvasási kapcsolat a mikroszolgáltatás és a monolit adatbázis között, de semmi ok, ebben a konfigurációban elég sokáig élhet.
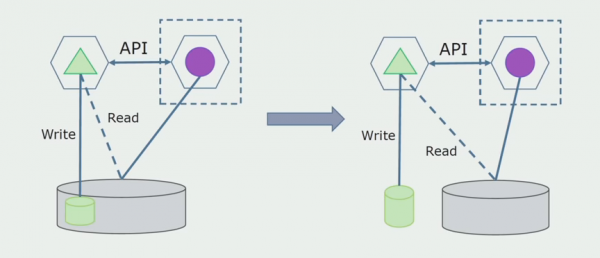
Az utolsó lépés az összes csatlakozás teljes eltávolítása. Ebben az esetben előfordulhat, hogy át kell telepítenünk az adatokat a fő adatbázisból. Néha fel akarunk használni bizonyos adatokat vagy könyvtárakat, amelyeket külső rendszerekről replikáltak több adatbázisban. Ez időnként megtörténik velünk.
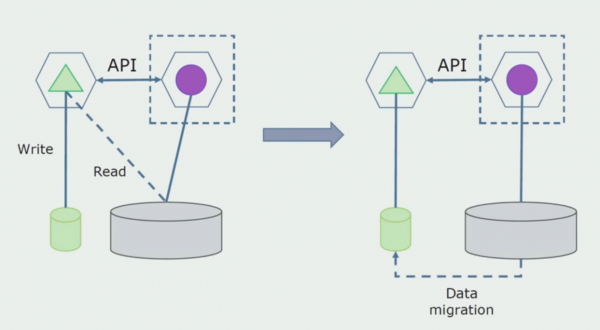
Feldolgozó részleg. Ez a módszer nagyon hasonlít az elsőhöz, csak fordított sorrendben. Azonnal kiosztunk egy új adatbázist és egy új mikroszolgáltatást, amely API-n keresztül kölcsönhatásba lép a monolittal. Ugyanakkor marad egy sor adatbázis-tábla, amelyet a jövőben törölni szeretnénk. Már nincs rá szükségünk, becseréltük az új modellbe.
Ahhoz, hogy ez a rendszer működjön, valószínűleg átmeneti időszakra lesz szükségünk.
Ekkor két lehetséges megközelítés létezik.
Első: minden adatot megduplázunk az új és a régi adatbázisokban. Ebben az esetben adatredundanciánk van, és szinkronizálási problémák léphetnek fel. De két különböző ügyfelet tudunk fogadni. Az egyik az új verzióval fog működni, a másik a régivel.
Második: egyes üzleti szempontok szerint osztjuk fel az adatokat. Például 5 termékünk volt a rendszerben, amelyeket a régi adatbázisban tároltunk. A hatodikat az új üzleti feladaton belül egy új adatbázisban helyezzük el. De szükségünk lesz egy API-átjáróra, amely szinkronizálja ezeket az adatokat, és megmutatja a kliensnek, hogy honnan és mit kaphat.
Mindkét megközelítés működik, válasszon a helyzettől függően.
Miután megbizonyosodtunk arról, hogy minden működik, a monolit régi adatbázis-struktúrákkal működő része letiltható.
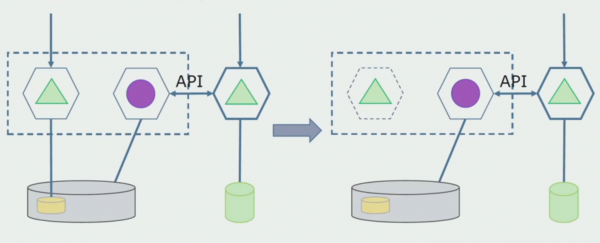
Az utolsó lépés a régi adatszerkezetek eltávolítása.
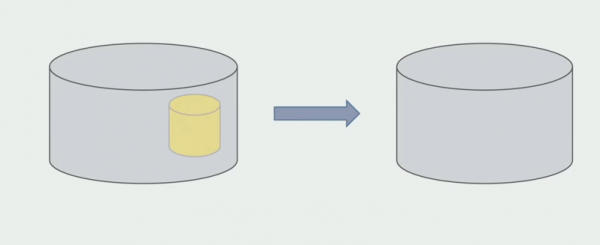
Összefoglalva elmondhatjuk, hogy az adatbázissal vannak gondjaink: a forráskódhoz képest nehéz vele dolgozni, nehezebb megosztani, de meg lehet és kell is. Találtunk néhány módszert, amellyel ezt egészen biztonságosan megtehetjük, de még mindig könnyebb hibázni az adatokkal, mint a forráskóddal.
Munka a forráskóddal
Így nézett ki a forráskód diagram, amikor elkezdtük elemezni a monolitikus projektet.
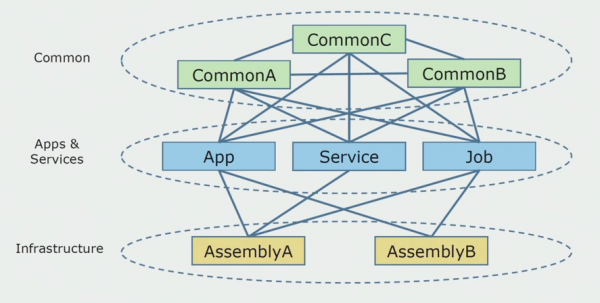
Nagyjából három rétegre osztható. Ez az elindított modulok, bővítmények, szolgáltatások és egyéni tevékenységek rétege. Valójában ezek egy monolitikus megoldáson belüli belépési pontok voltak. Mindegyiket szorosan lezárták egy Common réteggel. Ennek üzleti logikája volt, hogy a szolgáltatások megosztottak, és sok kapcsolat volt. Mindegyik szolgáltatás és bővítmény legfeljebb 10 vagy több közös összeállítást használt, méretüktől és a fejlesztők lelkiismeretétől függően.
Szerencsénk volt, hogy külön is használható infrastrukturális könyvtáraink voltak.
Néha olyan helyzet állt elő, amikor néhány közös objektum valójában nem ebbe a rétegbe tartozott, hanem infrastrukturális könyvtárak voltak. Ezt átnevezéssel oldották meg.
A legnagyobb gondot a korlátozott összefüggések okozták. Előfordult, hogy egy közös összeállításban 3-4 kontextust kevertek össze, és ugyanazon üzleti funkciókon belül használták egymást. Meg kellett érteni, hogy ezt hol és milyen határok mentén lehet felosztani, és mi a következő lépés ennek a felosztásnak a forráskód-összeállításokba való leképezésével.
A kódfelosztási folyamathoz több szabályt is megfogalmaztunk.
Az első: Többé nem akartuk megosztani az üzleti logikát a szolgáltatások, tevékenységek és bővítmények között. Az üzleti logikát szerettük volna függetleníteni a mikroszolgáltatásokon belül. A mikroszolgáltatások viszont ideális esetben teljesen függetlenül létező szolgáltatásoknak tekinthetők. Úgy gondolom, hogy ez a megközelítés némileg pazarló, és nehéz megvalósítani, mert például a C#-ban lévő szolgáltatásokat mindenképpen egy szabványos könyvtár köti össze. Rendszerünk C# nyelven íródott, más technológiát még nem használtunk. Ezért úgy döntöttünk, hogy megengedhetjük magunknak a közös műszaki szerelvények használatát. A lényeg az, hogy ne tartalmazzák az üzleti logika töredékeit. Ha az Ön által használt ORM felett van egy kényelmi csomagolóanyag, akkor annak szolgáltatásról szolgáltatásra másolása nagyon drága.
Csapatunk a domain-vezérelt tervezés híve, így a hagyma építészet remekül passzolt hozzánk. Szolgáltatásaink alapja nem az adatelérési réteg, hanem egy domain logikával rendelkező szerelvény, amely csak üzleti logikát tartalmaz, és nincs kapcsolata az infrastruktúrával. Ugyanakkor a tartomány-összeállítást önállóan módosíthatjuk a keretrendszerekkel kapcsolatos problémák megoldása érdekében.
Ebben a szakaszban találkoztunk az első komoly problémánkkal. A szolgáltatásnak egy tartomány szerelvényre kellett hivatkoznia, a logikát szerettük volna függetleníteni, és a DRY elv itt nagyon hátráltat minket. A fejlesztők újra fel akarták használni a szomszédos szerelvényekből származó osztályokat, hogy elkerüljék a duplikációt, és ennek eredményeként a tartományok újra összekapcsolódtak. Elemeztük az eredményeket, és úgy döntöttünk, hogy a probléma talán a forráskód-tároló eszköz területén is rejlik. Volt egy nagy tárhelyünk, amely az összes forráskódot tartalmazza. Az egész projekt megoldását nagyon nehéz volt összeszerelni egy helyi gépen. Ezért a projekt részeihez külön kis megoldások készültek, és senki sem tiltotta, hogy ezekhez valamilyen közös vagy domain összeállítást adjanak hozzá és újra felhasználják. Az egyetlen eszköz, amely ezt nem tette lehetővé, a kódellenőrzés volt. De néha ez is kudarcot vallott.
Aztán elkezdtünk áttérni egy külön tárolókkal rendelkező modellre. Az üzleti logika már nem folyik szolgáltatásról szolgáltatásra, a tartományok valóban függetlenekké váltak. A korlátozott kontextusok egyértelműbben támogatottak. Hogyan használjuk újra az infrastruktúra-könyvtárakat? Ezeket külön tárolóba különítettük el, majd Nuget csomagokba helyeztük, amelyeket az Artifactory-ba tettünk. Bármilyen változtatás esetén az összeállítás és a közzététel automatikusan megtörténik.
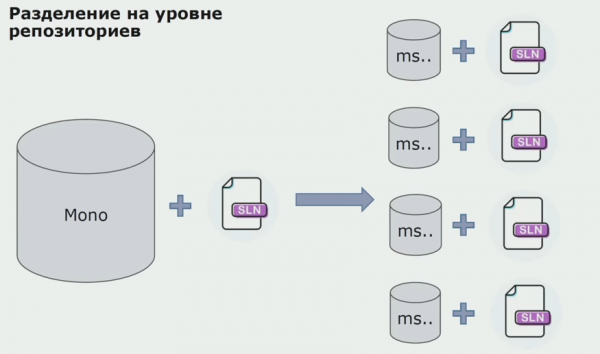
Szolgáltatásaink a belső infrastruktúra-csomagokra ugyanúgy hivatkozni kezdtek, mint a külsőkre. Külső könyvtárakat töltünk le a Nugetről. Az Artifactory-val való együttműködéshez, ahol ezeket a csomagokat helyeztük el, két csomagkezelőt használtunk. Kis tárolókban a Nuget-et is használtuk. A több szolgáltatást kínáló tárolókban a Paketet használtuk, amely nagyobb verziókonzisztenciát biztosít a modulok között.
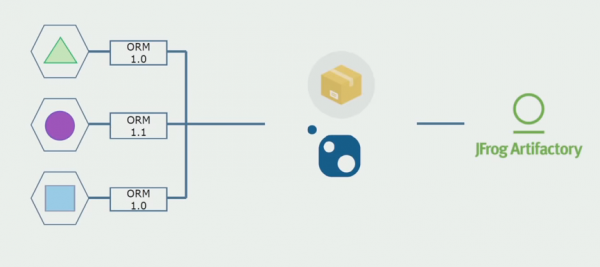
Így a forráskódon dolgozva, az architektúrán kismértékben változtatva és a tárolók szétválasztásával függetlenebbé tesszük szolgáltatásainkat.
Infrastrukturális problémák
A mikroszolgáltatásokra való átállás legtöbb hátránya az infrastruktúrához kapcsolódik. Automatizált telepítésre lesz szüksége, új könyvtárakra lesz szüksége az infrastruktúra működtetéséhez.
Kézi telepítés környezetben
Kezdetben manuálisan telepítettük a megoldást a környezetekhez. A folyamat automatizálása érdekében létrehoztunk egy CI/CD folyamatot. A folyamatos szállítási folyamatot választottuk, mert a folyamatos üzembe helyezés az üzleti folyamatok szempontjából még nem elfogadható számunkra. Ezért a működésre küldés egy gombbal történik, tesztelésre pedig - automatikusan.
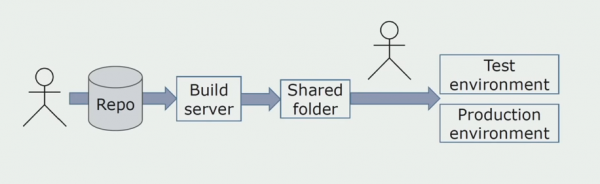
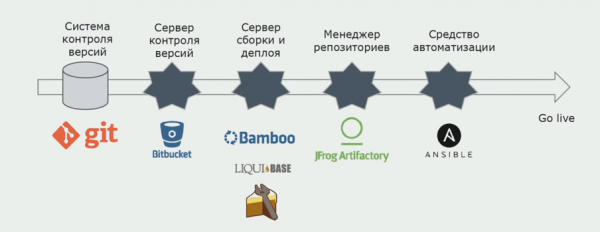
Forráskód tárolására Atlassian, Bitbucket, építkezéshez pedig Bamboo-t használunk. A Cake-ben szeretünk build szkripteket írni, mert az ugyanaz, mint a C#. A kész csomagok érkeznek az Artifactoryba, az Ansible pedig automatikusan a tesztszerverekre jut, ami után azonnal tesztelhetőek.
Külön naplózás
Egy időben a monolit egyik ötlete a közös fakitermelés biztosítása volt. Azt is meg kellett értenünk, hogy mit tegyünk a lemezeken található egyes naplókkal. Naplóink szöveges fájlokba vannak írva. Úgy döntöttünk, hogy szabványos ELK stacket használunk. Nem közvetlenül a szolgáltatókon keresztül írtunk az ELK-nak, hanem úgy döntöttünk, hogy véglegesítjük a szöveges naplókat, és azonosítóként beírjuk a nyomkövetési azonosítót, hozzáadva a szolgáltatás nevét, hogy a naplókat később elemezni lehessen.
A Filebeat segítségével a naplóinkat a következő helyekről tudjuk összegyűjteni: szervereket, majd alakítsd át őket, használd a Kibanát lekérdezések létrehozásához a felhasználói felületen, és nézd meg, hogyan irányítódott a hívás a szolgáltatások között. A nyomkövetési azonosítók nagyon hasznosak ehhez.
Tesztelés és hibakeresés kapcsolódó szolgáltatások
Kezdetben nem teljesen értettük, hogyan lehet hibakeresni a fejlesztés alatt álló szolgáltatásokat. A monolittal minden egyszerű volt, helyi gépen futtattuk. Eleinte ugyanígy próbálkoztak a mikroszolgáltatásokkal is, de néha egy mikroszolgáltatás teljes elindításához több másikat is el kell indítani, és ez kényelmetlen. Rájöttünk, hogy át kell térnünk egy olyan modellre, ahol a helyi gépen csak azt a szolgáltatást vagy szolgáltatásokat hagyjuk meg, amelyeket hibakeresni akarunk. A fennmaradó szolgáltatásokat olyan szerverekről használják, amelyek megfelelnek a prod konfigurációnak. Hibakeresés után a tesztelés során minden feladathoz csak a megváltozott szolgáltatások kerülnek ki a tesztszerverre. Így a megoldást abban a formában tesztelik, ahogy a jövőben a gyártásban megjelenik.
Vannak olyan szerverek, amelyek csak a szolgáltatások éles verzióit futtatják. Ezekre a kiszolgálókra szükség van incidensek esetén, a telepítés előtti kézbesítés ellenőrzéséhez és a belső képzéshez.
Hozzáadtunk egy automatizált tesztelési folyamatot a népszerű Specflow könyvtár használatával. A tesztek automatikusan lefutnak az NUnit használatával, közvetlenül az Ansible-ből történő telepítés után. Ha a feladatlefedettség teljesen automatikus, akkor nincs szükség manuális tesztelésre. Bár néha még mindig szükség van további kézi tesztelésre. A Jira-ban címkéket használunk annak meghatározására, hogy egy adott probléma esetén mely teszteket kell futtatni.
Emellett megnőtt a terheléses tesztelés igénye, korábban csak ritkán végezték el. A tesztek futtatásához a JMetert, tárolásukhoz az InfluxDB-t, a folyamatgrafikonok készítéséhez pedig a Grafanát használjuk.
Mit értünk el?
Először is megszabadultunk a „kibocsátás” fogalmától. Elmúltak azok a két hónapos szörnyű kiadások, amikor ezt a kolosszust termelési környezetben helyezték üzembe, átmenetileg megzavarva az üzleti folyamatokat. Most átlagosan 1,5 naponta telepítjük a szolgáltatásokat, csoportosítva őket, mert jóváhagyás után lépnek üzembe.
Nincsenek végzetes hibák a rendszerünkben. Ha egy mikroszolgáltatást hibával adunk ki, akkor a hozzá tartozó funkcionalitás tönkremegy, és az összes többi funkciót nem érinti. Ez nagymértékben javítja a felhasználói élményt.
Szabályozhatjuk a telepítési mintát. Szükség esetén a szolgáltatáscsoportokat a megoldás többi részétől külön is kiválaszthatja.
Ráadásul a fejlesztések nagy sorával jelentősen csökkentettük a problémát. Mostantól külön termékcsoportjaink vannak, amelyek egyes szolgáltatásokkal önállóan dolgoznak. A Scrum folyamat már jól illeszkedik ide. Egy adott csapatnak külön terméktulajdonosa lehet, aki feladatokat rendel hozzá.
Összegzés
- A mikroszolgáltatások kiválóan alkalmasak összetett rendszerek lebontására. A folyamat során kezdjük megérteni, mi van a rendszerünkben, milyen korlátozott kontextusok vannak, hol húzódnak a határaik. Ez lehetővé teszi a fejlesztések helyes elosztását a modulok között, és megakadályozza a kódzavarokat.
- A mikroszolgáltatások szervezeti előnyöket biztosítanak. Gyakran csak építészetként beszélnek róluk, de bármilyen architektúra szükséges az üzleti igények megoldásához, és nem önmagában. Ezért elmondhatjuk, hogy a mikroszolgáltatások kiválóan alkalmasak kis csapatok problémáinak megoldására, tekintettel arra, hogy a Scrum manapság nagyon népszerű.
- Az elválasztás iteratív folyamat. Nem lehet egy alkalmazást egyszerűen mikroszolgáltatásokra osztani. A kapott termék valószínűleg nem lesz működőképes. A mikroszolgáltatások dedikálása során előnyös a meglévő örökséget átírni, azaz olyan kóddá alakítani, ami nekünk tetszik, és funkcionalitásban és sebességben jobban megfelel az üzleti igényeknek.
Egy kis figyelmeztetés: A mikroszolgáltatásokra való átállás költségei meglehetősen jelentősek. Hosszú időbe telt egyedül megoldani az infrastrukturális problémát. Tehát ha van egy kis alkalmazása, amely nem igényel speciális skálázást, kivéve, ha nagyszámú ügyfél verseng csapata figyelméért és idejéért, akkor előfordulhat, hogy a mikroszolgáltatásokra ma már nincs szüksége. Elég drága. Ha mikroszolgáltatással indítja el a folyamatot, akkor a költségek kezdetben magasabbak lesznek, mintha ugyanazt a projektet monolit fejlesztésével kezdené.
PS Egy érzelmesebb történet (és mintha személyesen neked szólna) - szerint .
Íme a jelentés teljes verziója.
Forrás: will.com
